LLMs基础学习(七)DeepSeek专题(2)
DeekSeep中的关键技术梳理:MoE、GRPO、MLA、E
LLMs基础学习(七)DeepSeek专题(2)
文章目录
图片和视频链接:https://www.bilibili.com/video/BV1gR9gYsEHY?spm_id_from=333.788.player.switch&vd_source=57e4865932ea6c6918a09b65d319a99a
DeepSeek MoE 架构
整体问题与架构改进概述
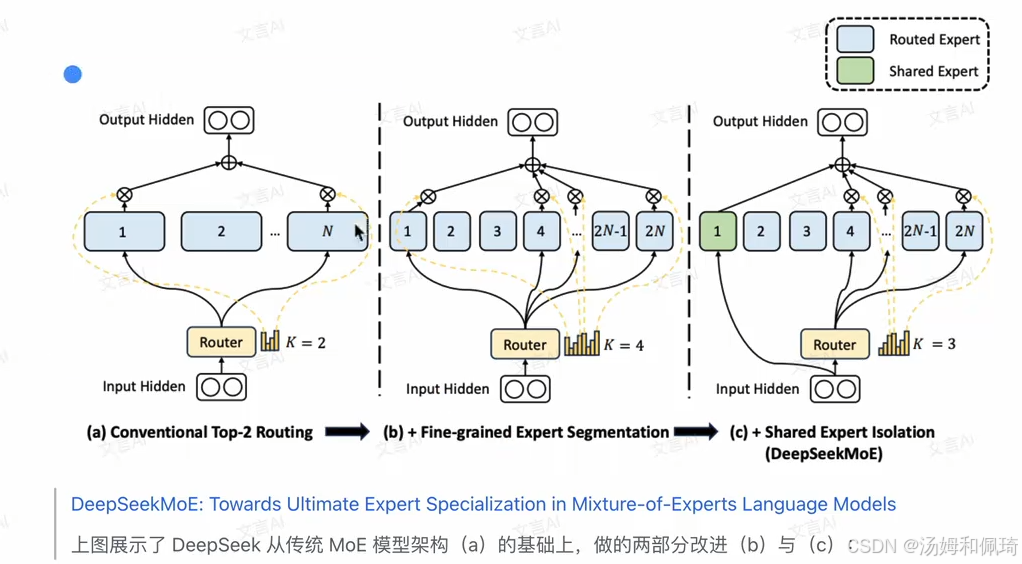
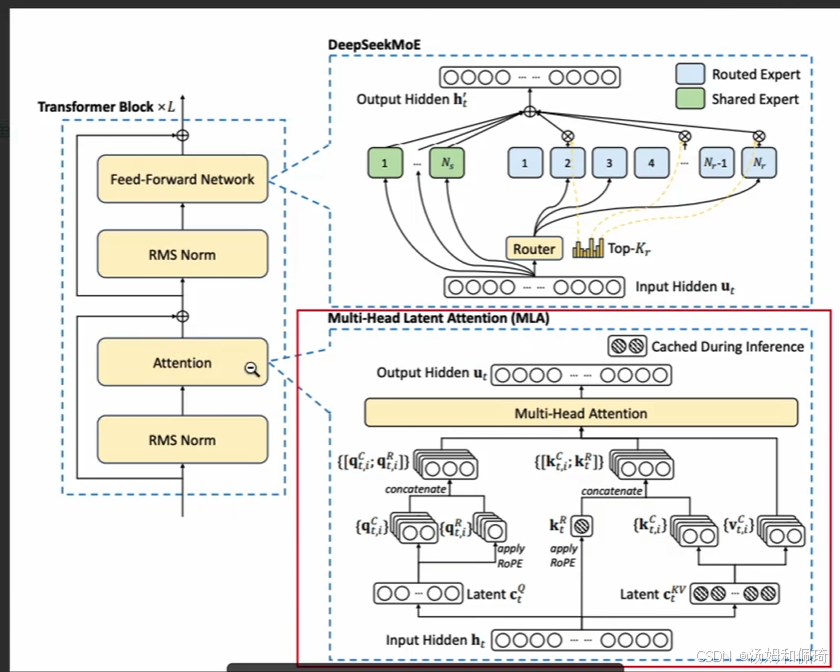
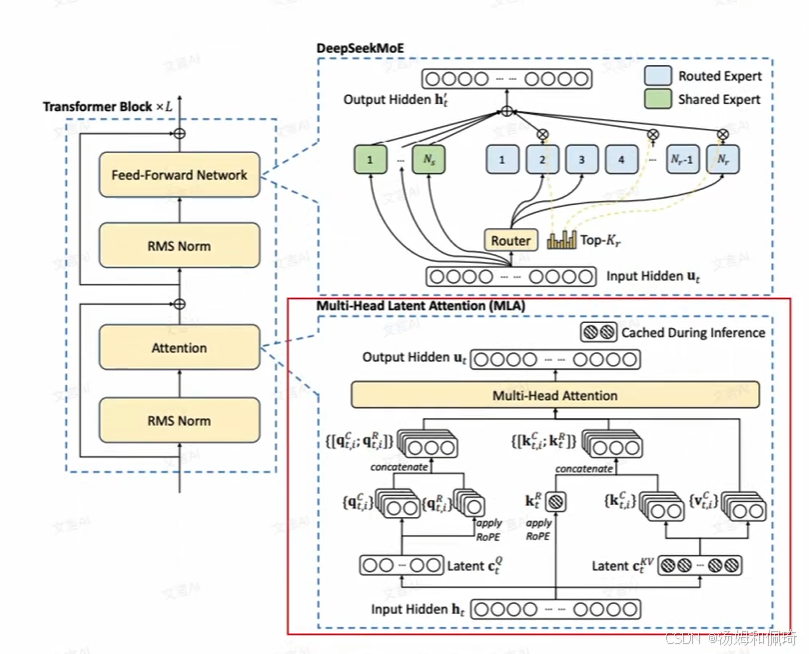
- DeepSeek MoE 架构并非凭空而来,而是在传统 MoE 模型架构(标记为 (a) )的基础上进行创新性改进的成果,改进主要体现在两个关键部分,即细粒度专家划分(标记为 (b) )与共享专家分离(标记为 © )。
传统 MoE 模块
- 构成与机制:MoE 模块犹如一个专家集合体,内部包含 N 个前馈神经网络(Feed - Forward Network, FFN)专家 。每个专家都像是一个身怀绝技的能手,在处理特定类型的数据时展现出独特的优势。
- 在实际运行中,MoE 模块不会让所有专家同时上阵,而是巧妙地通过路由机制来运作。路由机制就像是一个精准的调度员,会依据输入数据的特征,从这 N 个专家里动态地挑选出最合适的 K 个专家来对数据进行处理 。
- 例如,在 Mixtral 8*7B 模型中,它一共包含了 8 个专家,但每次只会从中选择 2 个专家来进行计算 。在这个模型里,总的参数量达到了 46.7B,然而由于每次只激活部分专家,实际参与计算的激活参数量大约只有 12B 左右 。
- 作用:这种独特的机制带来了显著的优势,它有效地减少了不必要的计算量,避免了所有专家同时计算造成的资源浪费和计算冗余。同时,它还能够让模型更加精准地聚焦于合适的专家来处理输入数据,就好比在面对不同病症时,能快速找到最擅长治疗该病症的医生,从而提高了处理数据的效率和针对性。
细粒度专家划分
- 划分方式:与传统 MoE 模块不同,DeepSeek 对专家的划分方式进行了大胆创新。它将原本的 N 个专家进行了更细粒度的拆分,具体做法是把 N 个专家拆分成 m*N 个 。
- 在这个过程中,每个专家的隐层维度相应地变为原来的 1/m 。与此同时,激活的专家数量也从 K 个变为 mK 个 。例如,原本有 N = 4 个专家,K = 2 个激活专家,假设 m = 2,那么就会拆分成 4*2 = 8 个专家,每次激活的专家数量变为 22 = 4 个 。
- 优势:通过这种细粒度的专家划分方式,MoE 模块的总参数量以及激活参数量都能够保持不变。这就像是在不改变仓库总存储量和每次使用量的前提下,将大仓库分割成了更多小仓库,每个小仓库的存储和使用更加灵活。不仅如此,还能够更加灵活地组合多个专家,使得模型在面对复杂多样的数据时,能够像一个技艺精湛的厨师,从众多食材(专家)中挑选出最合适的组合来烹饪出美味佳肴(处理数据),极大地提升了模型处理数据的灵活性和多样性。
共享专家分离
- 专家分类与处理流程:DeepSeek MoE 架构进一步把激活的专家清晰地划分为共享专家(Shared Experts,在图中以绿色标识 )和路由专家(Routed Experts,在图中以浅蓝色标识)。这两类专家在数据处理流程上有着显著的区别。
- 对于共享专家而言,输入数据就像是拥有了一条 “绿色通道”,无需经过路由模块的复杂计算,所有的数据都会直接通过共享专家进行处理。
- 而路由专家则有所不同,输入数据首先会进入路由模块,路由模块就像是一个严格的筛选器,会根据输入数据的特征,运用复杂的算法计算出每个专家与数据的匹配概率,然后从中选择出最合适的专家来进行计算,就像在众多应聘者中挑选出最适合岗位的人才一样。
- 最终,将路由专家和共享专家的计算结果进行相加,从而形成 MoE 模块的最终输出 。
- 效果:通过这种巧妙的设计,模型在处理不同输入数据时,就像是一个经验丰富的观察者,既能敏锐地捕捉到输入数据的共性,如同发现不同水果都含有水分这一共同特征;又能精准地关注到输入数据的差异性,比如区分苹果和香蕉在口感、颜色等方面的不同。这种特性使得模型的泛化能力和适应性得到了极大的提高,就像一个适应能力超强的旅行者,能够在不同的环境中都表现出色。
小结
- 全面总结了 DeepSeek MoE 架构的关键要点 ,重点强调了把激活专家明确区分为共享专家和路由专家这一创新举措,以及详细阐述了不同类型专家处理数据的独特方式。通过这种架构设计,模型具备了兼顾数据共性与差异的强大能力,能够更加高效、精准地处理各种复杂的数据任务,为模型在实际应用中的出色表现奠定了坚实的基础。
负载均衡策略
基本解释和特点介绍
- 问题与策略:在 MoE 结构中,负载不均衡是一个长期存在且影响模型性能的关键问题。DeepSeek - V3 为了解决这个棘手的问题,提出了一种全新的负载均衡策略。
- 具体做法是在用于选择专家的 Gate 模块中引入了一个可学习的偏置项 。这个偏置项就像是一个神奇的调节器,在计算路由得分时,它会动态地被加到每个路由专家的得分上 。
- 例如,假设专家 A 原本的得分是 1,专家 B 的得分是 2,在经过 softmax 计算后,专家 A 被选择的概率相对较低。但是,当给专家 A 引入一个偏置项 3 后,专家 A 的新得分就变成了 4,此时专家 A 在计算概率时被选择的可能性就会大大增加 。
- 特点
- 动态调整路由倾向:
- 通过不断地学习偏置项,模型就像是一个聪明的决策者,能够根据实际情况动态地调整对不同路由专家的偏好。如果某个专家的负载过重,就好比一个工人承担了过多的工作任务,那么其对应的偏置项可能会被学习为负值,这样在计算选择概率时,就会降低该专家被选择的概率,从而减轻其负载;
- 反之,对于那些负载较轻的专家,其偏置项可能会被学习为正值,进而提高其被选择的概率,让其能够承担更多的任务,实现负载的相对均衡 。
- 无额外损耗:
- 这个偏置项的优化方式非常独特,它不是通过一个独立的负载均衡损失函数来实现的,而是直接通过模型的训练目标进行优化。这就意味着模型在努力提升主要任务性能的过程中,会自然而然地学习到一种更加均衡的路由策略。
- 例如,就像一个运动员在训练体能的同时,也顺便提高了自己的技巧,而不会因为额外去训练技巧(独立的负载均衡损失函数)而影响体能(主要任务性能)的提升 。
- 动态调整路由倾向:
公式拆解
-
公式内容:负载均衡计算公式为
g i , t ′ = { s i , t , if s i , t + b i ∈ Topk ( { s j , t + b j ∣ 1 ≤ j ≤ N r } , K r ) 0 , otherwise. g_{i,t}'=\begin{cases}s_{i,t}, & \text{if } s_{i,t}+b_{i}\in \text{Topk}(\{s_{j,t}+b_{j}\mid 1\leq j\leq N_r\},K_r) \\ 0, & \text{otherwise.} \end{cases} gi,t′={si,t,0,if si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr)otherwise.
-
各部分含义
- s i , t s_{i,t} si,t :它代表的是第 i 个专家在处理第 t 个 token 时所得到的得分 ,这个得分反映了专家在处理该数据时的表现情况。
- b i b_{i} bi :是一个动态调整的偏置项,它的主要作用是帮助平衡专家之间的负载 。通过对这个偏置项的调整,可以灵活地改变每个专家被选择的概率,从而实现负载均衡。
- Topk ( ⋅ , K r ) \text{Topk}(\cdot,K_r) Topk(⋅,Kr) :这个符号表示的是一个集合,它包含了针对第 t 个 token 和所有路由专家计算出的分数中 K 个最高分数 。它就像是一个排行榜,筛选出表现最优秀的前 K 个专家。
- g i , t ′ g_{i,t}' gi,t′ :是经过调整后的第 i 个专家的得分,这个得分将直接用于决定该专家是否会被激活参与数据处理 。如果得分满足条件,专家就会被激活;否则,就不会参与此次输入数据的处理。
-
公式进一步解释:
- 在实际计算过程中,对于每个专家,首先要计算其加权得分,也就是 s i , t + b i s_{i,t}+b_{i} si,t+bi 。如果这个加权得分在所有专家的加权得分中能够排在前 K r K_r Kr 名,那么这个得分就会被保留,这也就意味着该专家会被激活,参与到数据处理中;否则,该专家的得分就会被设为 0,即表示该专家不参与此次输入数据的处理 。
- 通过不断地引入偏置项 b i b_{i} bi ,模型就能够根据实际情况灵活地调整每个专家的活跃度,有效地避免了某些专家过度忙碌(负载过重)而其他专家却闲置(负载过轻)的情况,从而实现了较为理想的负载均衡效果 。
- 并且,在整个训练过程中,通过对 b i b_{i} bi 的不断调节,模型能够保证专家负载的均匀分配,在维持计算效率的同时,也确保了模型性能不会因为负载不均衡而受到影响 。
小结
- DeepSeek - V3 解决 MoE 负载不均衡问题,核心要点在于引入了可学习的偏置项到 Gate 模块中,通过动态调整路由得分来实现负载均衡 。
- 这种创新的策略不仅有效地解决了负载不均衡的问题,还在不影响模型主要任务性能的前提下,提高了模型的整体运行效率和稳定性,为 MoE 架构在实际应用中的更广泛使用提供了有力的支持。
GRPO 和 PPO
基本介绍
大型模型训练主要有三种模式:
- 预训练(Pretraining):让模型学习大量通用数据,为后续任务奠定基础。
- 有监督精调(Supervised Fine-Tuning, SFT):通过学习训练数据的分布方式,提升模型在特定任务或指令上的表现。
- 强化学习(Reinforcement Learning):利用人类反馈定义奖励函数,通过强化学习算法优化模型,使模型生成符合人类喜好的回复 。
- 主流的 RL 算法包括 PPO(Proximal Policy Optimization,近端策略优化 )、DPO(Direct Preference Optimization )以及重点介绍的 GRPO(Group Relative Policy Optimization,群体相对策略优化 )。
- GRPO 是 PPO 的计算效率优化版本,能在保持效果的同时降低计算资源消耗。
9.2 PPO(近端策略优化)
-
算法地位:在强化学习领域,PPO 算法是强化学习的基准算法之一。
-
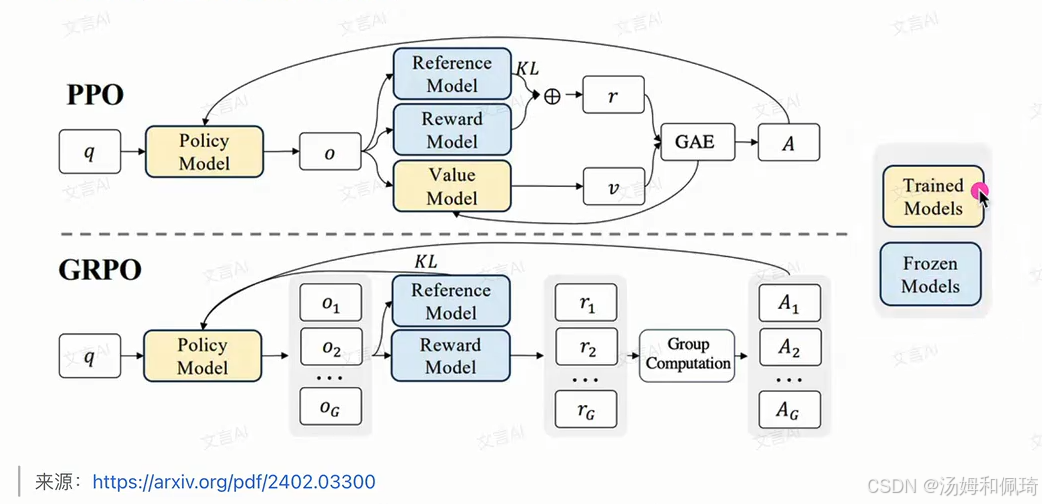
架构说明:采用 Actor - Critic 架构 ,可形象理解为:
- 有个 “演员(actor)” 在舞台表演,“评论家(critic)” 在台下观看。
- 演员目标是调整表演行为获观众认可并得反馈。
- 评论家任务是评估演员表演并提建议。
在自然语言处理场景中,被训练模型是演员,生成回复是表演;有评论家和观众模型来评价回复质量。
-
使用模型:
- Policy 模型(Actor):输入上文,输出下一个 token 的概率分布,是最终要得到的需训练模型,输出下一个 token 即其 “行为”。
- Value 模型(Critic):预估当前模型回复的总收益,不仅考量当前 token 质量,还衡量其对后续文本生成的影响,需训练。
- Reward 模型:事先用偏好数据训练,对 Policy 模型的预测进行打分,评估模型当前输出的即时收益。
- Reference 模型:与 Policy 模型相同,但训练中不优化更新,用于维持模型在训练中的表现,防止更新时出现过大偏差 。
-
举例说明:为更直观理解 Value 模型的总收益和 Reward 模型的即时收益,以 “磨刀不误砍柴工” 举例。钝刀一分钟劈一根柴,锋利的刀一分钟劈两根柴。直接用钝刀砍柴当前收益高,但未来收益低,Value 模型更推崇 “磨刀” 行为,而 Reward 模型会给 “直接砍柴” 更高分数。
9.3 GRPO(群体相对策略优化)
- 针对问题:PPO 在大模型的 RLHF 阶段成功应用,提升模型回复表现,但在计算成本和训练稳定性方面存在挑战,GRPO 对此进行优化。
- 核心目标:去除 Value 模型,减少训练的计算资源。
- 改进方式:传统 PPO 用 Value 模型估计模型回复总收益,是对未来模型回复各种可能性的平均分值估计 。GRPO 让大模型根据当前上文输入多次采样,生成多个预测结果 o i o_i oi ,分别用 Reward 模型对这些结果评分得到 r i r_i ri ,最后取评分平均值替代 Value 模型的预期总收益估计。通过该方式,GRPO 在训练中减少一个模型的前向和反向传播计算,降低计算资源消耗 。
9.4 总结
| 算法 | 特点 |
|---|---|
| 监督微调(SFT) | 1. 在标注的 SFT 数据上对预训练模型进行微调。 |
| 近端策略优化(PPO) | 1. 采用 Actor - Critic 架构,需要 Policy 模型、Value 模型、Reward 模型、Reference 模型。 2. 使用 Value 模型评估模型的预期总收益(模型回复的好坏) |
| 群体相对策略优化(GRPO) | 1. 采用 Actor - Critic 架构,需要 Reward 模型、Reference 模型,但删掉了 Value 模型。 2. 不使用 Value 模型,而是使用一组 LLM 生成的针对同一上文输入的多次采样结果来做预期总收益的估计。 |
多头隐式注意力(Multi - Head Latent Attention, MLA)
KV cache 介绍
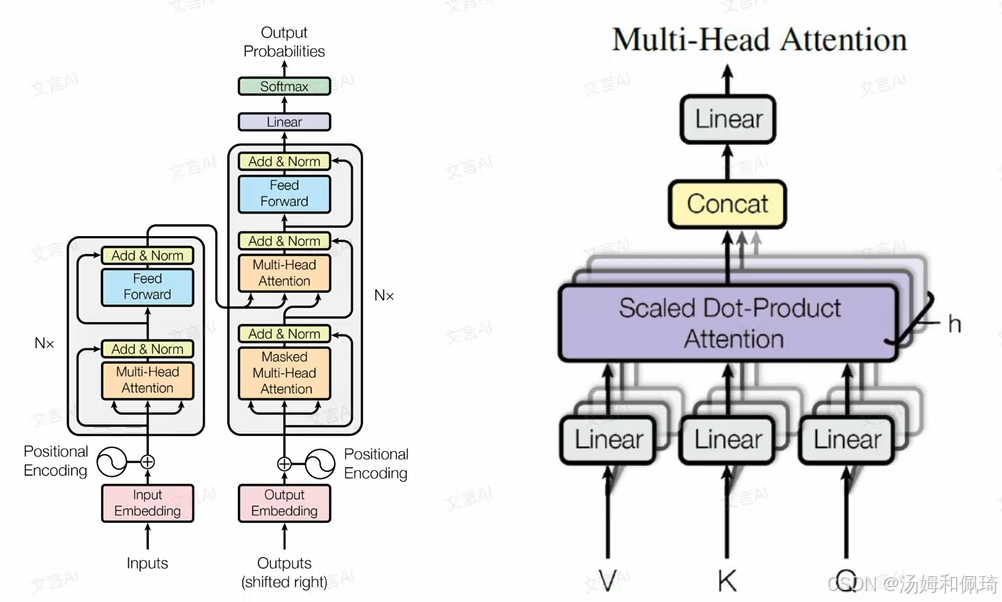
- Transformer 模型结构:
- 左侧图示呈现了 Transformer 模型的整体架构。输入数据首先进入 “Positional Encoding”(位置编码)模块,该模块赋予每个输入 token 位置信息,以弥补模型对序列顺序感知的不足 。接着进入 “Input Embedding”(输入嵌入)层,将离散的 token 转换为连续的向量表示。随后数据流经多个重复的模块,每个模块包含 “Multi - Head Attention”(多头注意力)和 “Feed Forward”(前馈网络)组件,并且都有 “Add & Norm”(残差连接与归一化)操作。这些模块的作用是让模型捕捉输入序列中的长距离依赖关系并进行非线性变换。最终,数据经过 “Linear”(线性层)和 “Softmax” 函数,输出各个 token 的概率分布,用于生成或分类等任务。
- 右侧图示聚焦于多头注意力(Multi - Head Attention)机制的内部结构。它接收查询(Query, Q)、键(Key, K)和值(Value, V)三个输入,首先分别通过线性变换得到不同的投影向量,然后进入 “Scaled Dot - Product Attention”(缩放点积注意力)模块。在该模块中,通过计算查询向量与键向量的点积并缩放,得到注意力分数,再经过 Softmax 函数归一化后与值向量加权求和,最后将多个头的结果拼接并通过线性变换输出。
- KV cache 原理:
- 在标准的 Transformer 模型中,多头注意力机制通过并行计算多个注意力头来捕捉输入序列中的不同特征。每个注意力头都有自己独立的查询(Q)、键(K)和值(V)矩阵。在计算注意力时,对于序列中的每一个 token,都需要分别计算其对应的 Q、K、V 矩阵,进而计算注意力分数。
- 在推理过程中,当前大模型普遍采用 token by token 的递归生成方式。由于上文 token 的 KV 计算不会受到后续生成 token 的影响,因此可以将这些计算结果缓存起来,避免在后续计算中重复计算,从而提高推理效率,这就是 KV cache 的由来。具体来说,当生成第 t + 1 个 token 时,可以直接利用之前事先算好的上文 t 个 token 的 KV 值,而第 t + 1 位置 token 的 KV 值计算出来后也会被保存到 KV cache 中,供后续计算使用。
- KV Cache 的作用:
- 在 Transformer 模型中,KV Cache 的主要作用是存储注意力机制中的键(Key)和值(Value)向量。在后续的推理过程中,当需要计算新 token 与之前 token 的注意力关系时,可以直接从缓存中读取这些键值向量,快速计算注意力分数,从而加速推理过程。
- 然而,随着模型规模的不断增大,尤其是输入序列长度增加时,KV Cache 所占用的显存也会相应增加,成为限制模型推理效率和规模扩展的一个因素。
MLA 简单介绍
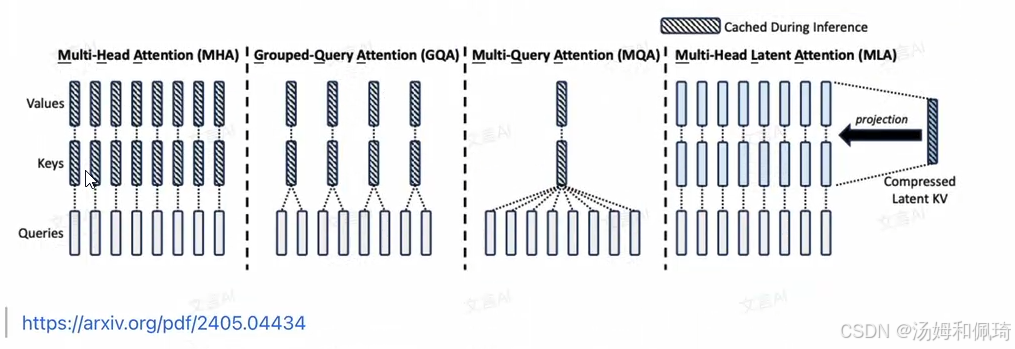
- 改进注意力机制的目的:目前大模型对于注意力机制进行了一系列改进,例如 MQA(Multi - Query Attention,多查询注意力)、GQA(Group Query Attention,分组查询注意力)等,**其核心目的都是想方设法减少 KV Cache 的占用。**DeepSeek 提出的 MLA(多头隐式注意力)同样是基于这一出发点。减少 KV Cache 的占用具有重要意义,一方面可以在更少的设备上推理更长的上下文(Context),提升模型处理长文本的能力;另一方面,在相同的上下文长度下,可以增大推理的批次大小(batch size),从而实现更快的推理速度或者更大的吞吐总量,最终目的是为了降低推理成本,提高模型的性价比和实用性。
- 不同注意力机制对比:通过下方的图示对几种注意力机制进行了直观对比。
- 在多头注意力(MHA)中,每个注意力头都有独立的键(Keys)、值(Values)和查询(Queries)向量组;
- 分组查询注意力(GQA)是将注意力头分组,每组共享键和值向量;
- 多查询注意力(MQA)则是所有注意力头共享一组键和值向量;
- 多头隐式注意力(MLA)的独特之处在于,它对原本 MHA 的 KV Cache 作低秩分解,得到一个低维的隐向量(Latent Vector)。在推理阶段,MLA 只需要缓存这个低维隐向量,由此大大降低了需要缓存的数据量,相较于其他几种机制在显存利用上具有明显优势。
MLA 的细节
-
低秩分解 :
-
概念:低秩分解是一种矩阵分解技术,其基本原理是将一个高维矩阵分解为两个或多个低维矩阵的乘积。在 MLA 中,通过引入降维映射矩阵 W D K V W^{DKV} WDKV和升维映射矩阵 W U K W^{UK} WUK、 W U V W^{UV} WUV来实现这种分解。这种分解方式能够在不损失过多信息的前提下,有效降低模型参数的维度和数量。
-
优势:低秩分解可以显著减少参数数量,从而降低显存压力。例如,假设原始的 K 和 V 矩阵的维度是 d × d d \times d d×d,通过低秩分解后的降维和升维映射矩阵的维度分别变为 d × r d \times r d×r和 r × d r \times d r×d(其中 r ≪ d r \ll d r≪d)。这样一来,参数数量将从原本的 O ( d 2 ) O(d^2) O(d2)降低到 O ( d r ) O(dr) O(dr),当d远大于r时,这种参数数量的减少效果非常显著,能够有效缓解模型在存储和计算上的压力,提高模型的运行效率。
-
-
降维映射:在 MLA 中,某一层的 token 表征为高维向量 h t h_t ht(假设其维度为d)。
- 为了降低维度,使用降维矩阵 W D K V W^{DKV} WDKV(维度为 r × d r \times d r×d,且 r ≪ d r \ll d r≪d)对 h t h_t ht进行压缩,得到低维隐向量 c t K V = W D K V h t c_t^{KV} = W^{DKV}h_t ctKV=WDKVht 。
- 以 DeepSeek - V3 为例,其中 r = 512 r = 512 r=512,而原始维度 d = 7168 d = 7168 d=7168,通过这种降维操作,大大减少了数据的维度和存储需求,同时保留了关键信息用于后续计算。
-
升维还原:在前向计算时,需要将低维隐向量还原为原始的键(K)和值(V)向量,以便进行注意力计算。
- 这一过程通过升维矩阵 W U K W^{UK} WUK(维度为 d k × r d_k \times r dk×r)和 W U V W^{UV} WUV(维度为 d v × r d_v \times r dv×r)来实现,具体计算方式为 k t C = W U K c t K V k_t^C = W^{UK}c_t^{KV} ktC=WUKctKV, v t C = W U V c t K V v_t^C = W^{UV}c_t^{KV} vtC=WUVctKV 。
- 经过这样的升维操作后,得到的 k t C k_t^C ktC和 v t C v_t^C vtC维度与原始的 K、V 向量维度一致,从而能够无缝接入后续的注意力计算流程,保证模型计算的准确性和一致性。
实际应用中的设置和效果表现
- DeepSeek - V3 中的设置:
- 在 DeepSeek - V3 模型中,对低维潜在向量的维度进行了精心设置。对于 K 和 V 向量,其压缩维度d**c设置为 512,而原始嵌入维度d=7168,压缩比例约为141 。之所以采用如此大的压缩比例,是因为键(K)和值(V)在推理时需要被缓存,降低它们的维度能够显著减少内存开销,提高推理效率。
- 对于查询(Q)向量,其压缩维度dcq设置为 1536,压缩比例约为4.71 。这是因为 Q 向量在训练时需要频繁计算,采用相对较小的压缩比例可以保留更多的信息,确保模型在训练过程中的性能不受太大影响,在保证计算效率的同时兼顾模型的准确性。
- 使用 MLA 的效果:通过实际对比实验,使用了 MLA 的 DeepSeek V2(总参数量 236B,激活参数量 21B)与 DeepSeek 67B 相比,展现出了显著的优势。在模型效果上有明显提升,同时节省了 42.5% 的训练成本,这主要得益于 MLA 在参数利用和计算优化方面的优势。在显存利用方面,减少了 93.3% 的 KV Cache 占用,大大降低了模型对显存的需求。在推理速度上,将最大生成吞吐量提高了 5.76 倍,使得模型在处理大规模文本生成任务时能够更加高效快速地运行。
小结
- MLA 提出的核心作用是对原本多头注意力机制(MHA)中的 KV Cache 作低秩分解,通过特定的矩阵运算得到一个低维的隐向量(Latent Vector) 。这种分解方式改变了传统 KV Cache 的存储和计算方式,从根本上优化了模型对键值信息的处理。
- 在推理阶段,MLA 只需要缓存这个低维的隐向量,而不是像传统方式那样缓存大量高维的键值向量。由此大大降低了需要缓存的数据量,使得模型在推理时能够以更低的显存开销运行,同时保持甚至提升了模型的推理速度和性能,在实际应用中具有重要的价值和广泛的应用前景。
降维映射矩阵和升维映射矩阵的学习方式
低秩分解的参数化实现
-
MLA 在处理生成 Key(K)和 Value(V)的过程中,对原始的线性变换矩阵进行独特处理。它将这一过程巧妙地分解为两个步骤,具体通过降维映射矩阵 W D K V W^{DKV} WDKV和升维映射矩阵 W U K W^{UK} WUK、 W U V W^{UV} WUV来实现。
- 从数学表达式 k t C = W U K ⋅ W D K V h t k_t^C = W^{UK} \cdot W^{DKV}h_t ktC=WUK⋅WDKVht 以及 v t C = W U V ⋅ W D K V h t v_t^C = W^{UV} \cdot W^{DKV}h_t vtC=WUV⋅WDKVht 可以看出,通过这两个步骤,原始高维的矩阵运算被转化为相对低维的操作。
- 这里的 W D K V W^{DKV} WDKV、 W U K W^{UK} WUK 、 W U V W^{UV} WUV 均是可学习的参数矩阵,在模型训练过程中不断调整优化。这种低秩分解的本质,使得模型在存储和计算时,能够以更低的成本处理关键信息,在不损失过多重要特征的前提下,有效降低了资源消耗。
-
初始化与训练方法
-
初始化方式:
-
随机初始化:可以采用正态分布或者其他合适的分布方式对相关矩阵进行初始化。这种方式简单直接,为模型参数赋予初始值,让模型从一个随机的起点开始学习。
-
基于预训练模型的分解(更常见):通过对原始的 W K W^K WK、 W V W^V WV 矩阵进行奇异值分解(SVD) ,能够得到近似的 W D K V W^{DKV} WDKV和 W U K W^{UK} WUK 矩阵。这种基于预训练模型知识的初始化方式,能够使模型在训练初期就具备一定的合理性,利用预训练过程中积累的信息,更快地朝着最优解的方向收敛,减少训练所需的时间和资源。
-
-
训练过程:
-
端到端学习:MLA 采用端到端的学习方式,这意味着在训练过程中,通过梯度下降算法联合优化所有相关矩阵。模型将输入直接映射到输出,在整个过程中对所有可学习参数进行统一调整,使得模型能够从整体上学习到数据的特征和规律,而不是孤立地优化某个部分,从而提升模型的整体性能。
-
参数共享: W D K V W^{DKV} WDKV 矩阵被 Key/Value 共享,这种强制共享低维空间的方式,进一步减少了模型中参数的数量,降低了计算量。同时,也使得模型在处理 Key 和 Value 时,能够在同一个低维空间中进行信息交互和特征提取,增强了模型的一致性和稳定性。
-
-
-
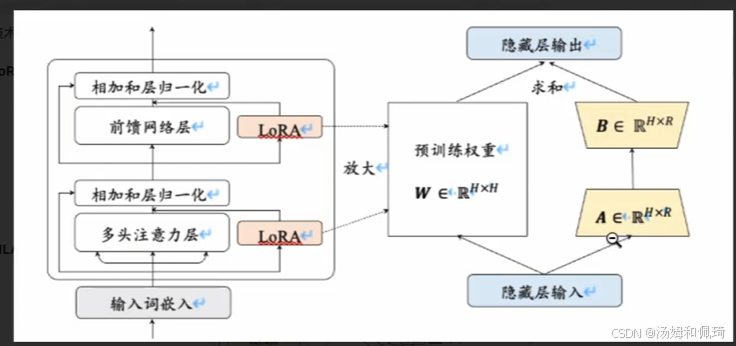
与 LoRA 对比
- LoRA:其核心区别在于在原始权重旁增加低秩旁路。在模型结构上,并不直接改变原始的权重矩阵,而是通过添加一个低秩的旁路矩阵,在训练过程中只对旁路矩阵的参数进行更新。这种方式在微调模型时,能够在不改变原始模型权重的基础上,灵活地调整模型的输出,具有高效、轻量级的特点。从图形对比中可以看到,LoRA 模块与原始的前馈网络层和多头注意力层并行存在,通过特定的计算方式与原始权重相互作用。
-
MLA:MLA 则是直接修改原始权重。通过对原始生成 K、V 的矩阵进行低秩分解,改变了原始权重的结构和计算方式。在图形对比中,展示了 MLA 在 Transformer Block 中的具体位置和作用方式,它直接参与到多头注意力机制的计算过程中,对输入的隐向量进行降维和升维等操作,以达到减少显存占用和计算量的目的。
-
科普版理解:以搬运百科全书为例进行类比。将原始的 K、V 生成矩阵比作一本百科全书,直接搬运全书(即存储高维的 K、V 矩阵)成本过高。MLA 的解决方法是:首先请一位专家( W D K V W^{DKV} WDKV )将全书浓缩为几页摘要(即低维隐向量 c t K V c_t^{KV} ctKV ),这个过程实现了信息的压缩和提炼;然后另一位专家( W U K W^{UK} WUK、 W U V W^{UV} WUV )根据摘要快速还原出需要的章节(即 K、V 向量),实现了信息的按需恢复。通过这种形象的比喻,能够更直观地理解 MLA 中低秩分解以及降维和升维操作的过程和作用。
-
总结:降维和升维矩阵是通过模型训练学习得到的参数,其本质是对原始 K、V 生成矩阵的低秩分解。通过合理的初始化方式,如利用 SVD 分解预训练权重,以及端到端的优化策略,MLA 在显著减少显存占用的同时,尽可能地保留了模型的性能。这种设计在处理长序列推理场景时,能够有效地降低计算资源的需求,提高模型的运行效率,具有极高的实用价值。
旋转位置编码(Rotary Position Embedding, RoPE)
基本概念
旋转位置编码(Rotary Position Embedding, RoPE)具有诸多巧妙特性。
- 旋转代替加法:在 RoPE 中,假设每个词的向量是一个 “箭头”,RoPE 会依据这个词在序列中的位置,将箭头 “旋转” 一个特定的角度。例如,位置 1 的词向量旋转 10 度,位置 2 的词向量旋转 20 度,以此类推。这种独特的旋转方式为模型提供了一种全新的表示位置信息的手段,与传统的加法式位置编码不同,它从角度变换的维度来体现位置差异。
-
相对位置自动显现:当计算两个词之间的关系时(比如 “猫” 和 “狗” ),模型会观察它们旋转后的角度差。例如,“猫” 在位置 1(旋转 10 度),“狗” 在位置 3(旋转 30 度),它们之间的角度差是 20 度,而这个差值直接反映了它们的相对距离(间隔 2 个位置)。通过这种方式,RoPE 能够让模型更直观地感知词与词之间的相对位置关系,增强了模型对序列结构的理解能力。
-
数学上的优势:从数学角度来看,旋转操作保持了向量的长度不变,只改变方向,这有效地避免了数值不稳定的问题。同时,RoPE 通过旋转矩阵来实现,这种实现方式在计算上具有高效性,尤其适合大规模模型的计算需求,能够在不增加过多计算负担的前提下,为模型提供准确的位置编码信息。
举例
-
句子示例:给出句子 “苹果 喜欢 阳光” ,用于说明传统位置编码方法和 RoPE 的差异。
-
传统方法:传统位置编码是直接给每个词加上对应的位置编码,如给 “苹果” 加上位置 1 的编码 ,给 “喜欢” 加上位置 2 的编码,通过简单相加来体现位置信息。这种方式较为直观,但在处理复杂语义关系和长文本时可能存在局限 。
-
RoPE 方法:RoPE 则是把 “苹果” 的向量旋转 10 度 ,“喜欢” 的向量旋转 20 度,“阳光” 的向量旋转 30 度。当模型计算 “苹果” 和 “阳光” 的关系时,会发现它们旋转角度存在 20 度的差异,这个差异对应着它们在句子中的位置差。RoPE 通过旋转向量角度来体现位置信息,能让模型更自然地捕捉词间相对位置关系 。
优点
被广泛采用:指出 LLAMA、GLM 等模型均选择了 RoPE 这种方法 ,说明其在实际应用中得到认可。
- 长文本友好:RoPE 的旋转角度可以无限延伸 ,这一特性使其在处理长句子时优势明显。长文本中位置编码范围可能超出传统方法的处理能力,而 RoPE 不受此限制,能持续准确表示位置信息 。
- 相对位置优先:RoPE 让模型更关注词之间的相对距离,如 “相邻” 或 “隔了三个词” 等关系 ,而非绝对位置。在自然语言中,词间相对位置对语义理解很关键,RoPE 能更好契合语义理解需求,帮助模型把握文本结构和语义关联 。
- 兼容性强:RoPE 可以直接嵌入到注意力计算中 ,不需要对模型结构进行大幅修改。这使得在现有模型架构中应用 RoPE 较为便捷,降低了使用门槛,提高了其在不同模型中应用的可行性 。
MLA 中针对位置编码的处理方式
- MLA 专门针对旋转位置编码 RoPE 进行了特殊处理。原因在于,如果在隐向量 h t h_t ht 中直接包含 RoPE 信息,经过升降维操作后,会对位置信息造成破坏。为了解决这个问题,MLA 提出了 “解耦 RoPE” 的方法。
- 具体而言,对于隐向量 c t K V c_t^{KV} ctKV ,不再将位置编码包含在其中,而是专门为注意力头的 Query 和 Key 新增向量维度,以此来添加 RoPE 的位置信息。
- DeepSeek 进一步将 Query 和 Key 进行拆分,分别表示为 [ q t R , q t C ] [q_t^R, q_t^C] [qtR,qtC]和 [ k t R , k t C ] [k_t^R, k_t^C] [ktR,ktC] 。其中一部分进行压缩处理( q t C q_t^C qtC , k t C k_t^C ktC ),另一部分进行 RoPE 编码( q t R q_t^R qtR , k t R k_t^R ktR ) 。
- 这里的 R 可以理解为 RoPE 的标识符,通过这种拆分和处理方式,实现了位置信息与压缩操作的分离,保证了位置信息的完整性和准确性。
- 在具体操作流程上,先对 KV 进行联合压缩(Low - Rank Key - Value Joint Compression),然后进行升维操作;
- 接着再对 Q 进行压缩降维,之后同样进行升维操作。
- 此外,考虑到在模型训练过程中,queries 等中间数据维度高、占用内存大的问题,为了降低训练过程中的激活内存(activation memory) ,DeepSeek - V2 还对 queries 进行低秩压缩,尽管这种压缩方式并不能直接降低 KV Cache,但通过与 K、V 一致的先降维再升维的操作,在整体上优化了模型的内存使用效率。
小结
- 在隐向量 h t h_t ht 中包含 RoPE,经过升降维操作后会对位置信息造成破坏这一问题。
- MLA 提出的 “解耦 RoPE” 方法,通过不将位置编码包含在隐向量 c t K V c_t^{KV} ctKV中,而是为 Query 和 Key 新增向量维度来添加 RoPE 位置信息的方式,有效地解决了这一问题,确保了模型在处理位置信息时的准确性和稳定性,进一步提升了 MLA 在实际应用中的性能表现。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 49
49 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)