
SpringAI和传统调用API在大模型应用上的区别
SpringAI-让java再次伟大SpringAI和传统调用大模型API在java开发中的区别以及黑马关于SpringAI+deepseek大模型开发课程学习总结体会。
黑马SpringAI课程总结&&SpringAI和传统调用API在大模型应用上的区别
2024年SpringAI发布,Spring AI是一个人工智能工程的应用框架,旨在为Java开发者提供一种更简洁的方式与AI交互。
2025年4月,黑马在B站发布了对应的课程SpringAI+DeepSeek大模型开发实战,这篇文章讲述了一些我的学习经历和思考。如有错误,欢迎指出!
这篇文章主要是讲解SpringAI 和传统API调用大模型的区别,但是在这之前,我想先总结一下我在黑马的 SpringAI+DeepSeek大模型开发 的学到的知识。
一、黑马课程学习总结
总体项目结构如图:
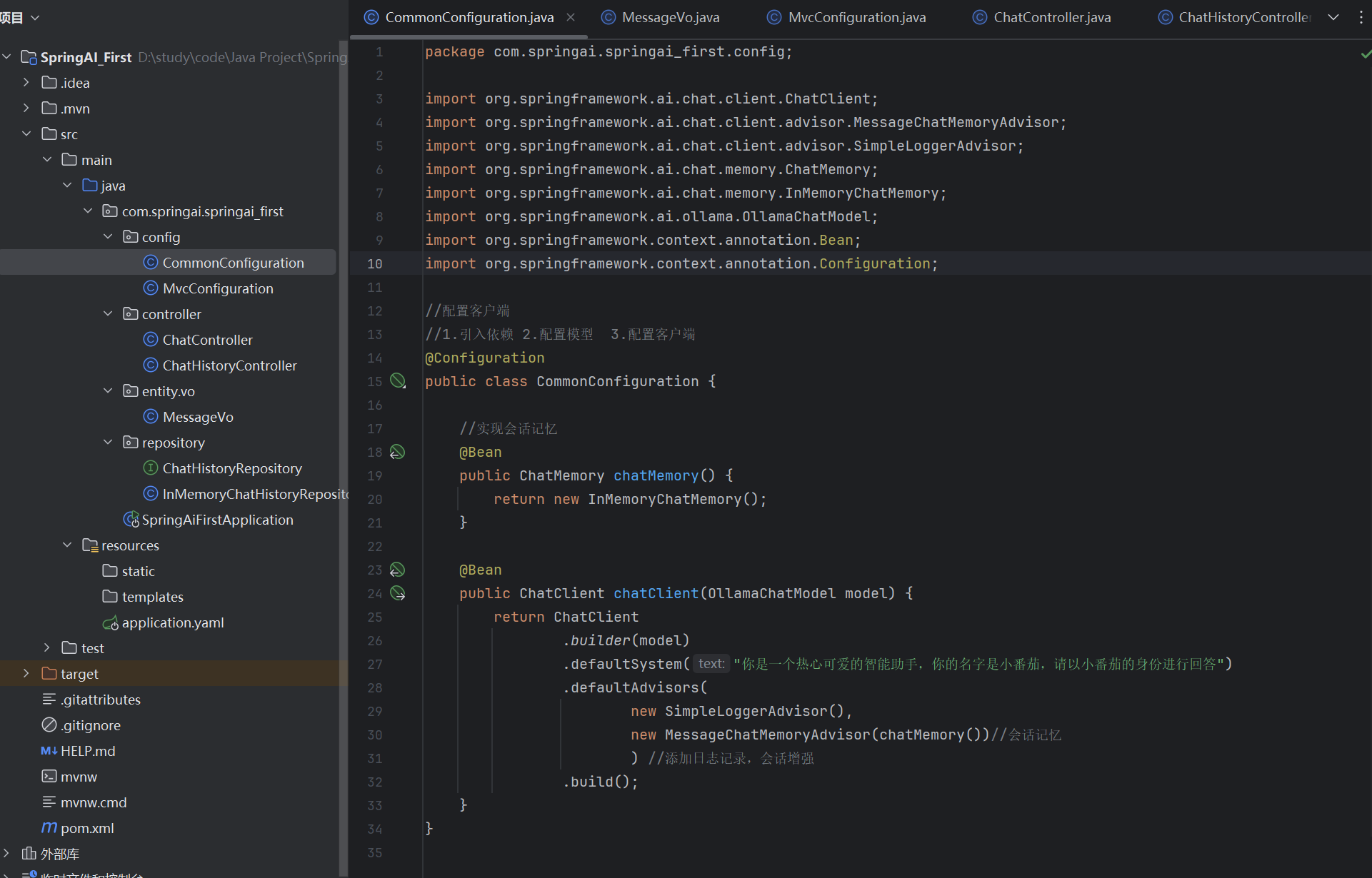
SpringAI_First 项目总结
1. 项目概述
这是一个基于Spring AI框架的智能助手应用,使用Ollama作为本地模型提供者,实现了与AI模型的对话功能,包括会话记忆、历史记录查询等功能。项目采用Spring Boot架构,通过RESTful API提供服务。
2. 项目配置
我使用的是ollama配置的本地模型deepseek,所以在pom.xml中添加了ollama的依赖
<!-- SpringAI ollama的依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
application.yaml文件配置
#SpringAI
Spring:
application:
name:SpringAI_First
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:1.5b #local AI
#SpringAI的日志配置
logging:
level:
org.springframework.ai.chat.client.advisor: debug
com.springai.springai_first: debug
这里配置的是本地下载的模型,通过Ollama服务访问
3. 核心组件
3.1 ChatClient配置
在CommonConfiguration中配置了ChatClient,设置了系统提示词和会话记忆功能
public class CommonConfiguration {
//实现会话记忆
@Bean
public ChatMemory chatMemory() {
return new InMemoryChatMemory();
}
@Bean
public ChatClient chatClient(OllamaChatModel model) {
return ChatClient
.builder(model)
.defaultSystem("你是一个热心可爱的智能助手,你的名字是小番茄,请以小番茄的身份进行回答")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
new MessageChatMemoryAdvisor(chatMemory())//会话记忆
) //添加日志记录,会话增强
.build();
}
}
3.2 会话历史存储
定义了ChatHistoryRepository接口用于保存和获取会话ID
public interface ChatHistoryRepository {
/*
* 保存会话记录
* @param type 业务类型:chat / service / pdf
* @param chatId 会话ID
* */
void save(String type,String chatId);
/*
* 获取会话ID列表
* @param type 业务类型
* @param 会话ID列表
* */
List<String> getChatIds(String type);
}
实现了基于内存的会话历史存储
@Component
public class InMemoryChatHistoryRepository implements ChatHistoryRepository {
private final Map<String,List<String>> chatHistory = new HashMap<>(); //存入内存
@Override
public void save(String type, String chatId) {
//实现了上面几行的功能,如果没有这个ID就创建一个
List<String> chatIds = chatHistory.computeIfAbsent(type,k -> new ArrayList<>());
if(chatIds.contains(chatId)){
return;
}
}
@Override
public List<String> getChatIds(String type) {
List<String> chatIds = chatHistory.get(type);
return chatIds == null ? new ArrayList<>() : chatIds;//防止空指针,null返回空集合
}
}
4. 控制器实现
4.1 聊天控制器
非流式调用
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
private final ChatHistoryRepository chatHistoryRepository;
//非流式调用
// @RequestMapping("/chat")
// public String chat(String prompt) {
// return chatClient.prompt()
// .user(prompt)
// .call()
// .content();
// }
//}
流式调用
//流式调用
@RequestMapping(value = "/chat",produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt , String chatId) {
//1.保存会话ID
chatHistoryRepository.save("chat",chatId);
//2.请求模型
return chatClient.prompt()
.user(prompt)
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId))//会话ID
.stream()
.content();
}
4.2 会话历史控制器
实现了获取会话ID列表和会话历史记录的接口
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/history")
public class ChatHistoryController {
private final ChatHistoryRepository chatHistoryRepository;
private final RetryTemplate retryTemplate;
//注入chatmemory接口
private final ChatMemory chatMemory;
@GetMapping ("/{type}")
public Object getChatIds(@PathVariable("type") String type) {
return chatHistoryRepository.getChatIds(type);
}
@GetMapping("/{type}/{chatId}")
public List<MessageVo> getChatHistory(@PathVariable("type") String type, @PathVariable("chatId") String chatId) {
List<Message> messages = chatMemory.get(chatId, Integer.MAX_VALUE);
if (messages == null) {
return List.of();
}
return messages.stream().map(MessageVo::new).toList();
}
}
5. 跨域配置
为了支持前端Vue应用访问,配置了跨域支持
@Configuration
public class MvcConfiguration implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")//允许哪些域名来访问
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*");
}
}
6. 技术栈总结
- 框架: Spring Boot 3.4.4
- AI集成: Spring AI 1.0.0-M6
- AI模型: Ollama本地模型(deepseek-r1:1.5b)
- API类型: RESTful API
- 响应方式: 支持流式响应和非流式响应
- 数据存储: 内存存储(会话历史和会话记忆)
- 前端支持: 通过CORS配置支持前端跨域访问
7. 功能特点
- 智能对话: 通过Ollama本地模型提供智能对话服务
- 会话记忆: 支持多轮对话,保持上下文连贯性
- 会话历史: 可查询历史会话ID和会话内容
- 流式响应: 支持流式输出,提升用户体验
- 自定义角色: 通过系统提示词定制AI助手的角色和风格
这个项目展示了如何使用Spring AI框架快速构建一个具有会话记忆功能的智能助手应用,通过本地Ollama模型提供服务。感兴趣的同学可以亲自去跟着黑马做一做这个项目,很有意思。
二、SpringAI和传统的java API调用应用大模型的区别
Spring AI 是 Spring 生态系统中的一个新项目,旨在为 Java 开发者提供一个统一、简洁的框架来集成和使用 AI 模型(特别是生成式 AI,如大语言模型、图像生成模型等)。它通过 Spring 的抽象层和熟悉的编程模型(如 Spring Boot 的自动配置和依赖注入)来简化 AI 模型的调用和企业级应用的集成。相比于在 Spring AI 出现之前,开发者通过 Java 中的各种 API 直接调用 AI 模型(如 OpenAI、Hugging Face 或其他供应商的 SDK),Spring AI 在设计理念、开发体验、实现细节和应用场景上都有显著的区别。以下从多个维度进行详细分析,包括理论层面的设计目标和实际实现层面的代码细节。
一、理论层面的区别
1. 设计目标
-
Spring AI:
- 统一抽象层:Spring AI 提供了一个跨模型、跨供应商的统一接口,屏蔽了不同 AI 模型提供商(如 OpenAI、Anthropic、Google、Ollama 等)的 API 差异,降低开发者学习和适配成本。
- Spring 生态集成:利用 Spring Boot 的自动配置、依赖注入和模块化设计,Spring AI 旨在无缝嵌入企业级 Java 应用,适合微服务架构和复杂业务场景。
- 模块化与可扩展性:支持多种 AI 功能(如聊天、文本嵌入、图像生成)和技术(如 RAG、工具调用、向量数据库),并允许开发者扩展以适配新模型或自定义需求。
- 企业级特性:强调生产就绪,提供安全性(如 Spring Security 集成)、可观察性、错误处理和可扩展性,适合大规模部署。
-
传统 Java API 调用:
- 直接依赖供应商 SDK:开发者通常直接使用 AI 模型提供商的 Java SDK(如 OpenAI Java Client、Hugging Face Inference API 或 AWS Bedrock SDK),需要针对每个供应商的 API 进行单独学习和适配。
- 灵活但分散:开发者拥有更高的自由度,可以直接调用底层 API,但缺乏统一的抽象层,跨模型切换或多模型集成需要手动处理差异。
- 企业集成复杂:传统方式更适合原型开发或简单应用,但在企业环境中需要开发者自行处理配置管理、依赖注入、负载均衡等,增加了开发和维护成本。
2. 开发体验
-
Spring AI:
- 声明式编程:通过 Spring 的注解(如
@Bean、@RestController)和配置(如application.properties),开发者可以快速配置和调用 AI 模型,减少样板代码。 - 一致性:统一的
ChatClient、ImageModel等接口让开发者无需深入了解每个模型的细节,只需关注业务逻辑。 - 生态支持:与 Spring Data、Spring Security、Spring Cloud 等无缝集成,适合构建复杂的企业级 AI 应用。
- 声明式编程:通过 Spring 的注解(如
-
传统 Java API 调用:
- 手动配置:开发者需要手动设置 API 密钥、端点、请求参数等,代码中充斥着大量与业务无关的配置逻辑。
- 学习曲线陡峭:每个供应商的 SDK 有不同的设计理念和调用方式,开发者需要逐一熟悉(如 OpenAI 的同步/异步调用与 Hugging Face 的推理端点差异)。
- 重复工作:在多模型集成时,开发者需要为每个模型编写类似的请求/响应处理逻辑,代码冗余度高。
3. 跨模型支持
-
Spring AI:
- 支持多种模型类型(聊天、嵌入、图像生成等)和供应商,通过统一的接口(如
ChatModel、EmbeddingModel)实现跨模型调用。例如,可以轻松切换从 OpenAI 到 Anthropic 的模型,只需更改配置。 - 提供模型无关的特性,如结构化输出(将 AI 输出映射为 POJO)、工具调用(Function Calling)和 RAG(检索增强生成),这些特性在不同模型间保持一致。
- 支持多种模型类型(聊天、嵌入、图像生成等)和供应商,通过统一的接口(如
-
传统 Java API 调用:
- 跨模型支持需要开发者手动适配。例如,OpenAI 的 API 返回 JSON 字符串,而 Hugging Face 的推理 API 可能返回不同格式的数据结构,开发者需要为每种模型编写转换逻辑。
- 缺乏统一的高级特性支持,如 RAG 或工具调用,开发者需要自己实现或依赖第三方库。
4. 生产就绪性
-
Spring AI:
- 内置生产级特性,如自动配置、依赖注入、异常处理、可观察性(通过 Spring Actuator 或 Micrometer)和分布式系统支持。
- 支持向量数据库(如 PGVector、Weaviate、Chroma)集成,便于实现 RAG 等高级功能。
- 与 Spring Security 集成,可轻松实现 API 密钥管理和用户认证。
-
传统 Java API 调用:
- 生产就绪性依赖于开发者的实现。例如,开发者需要手动处理 API 密钥的安全存储、请求重试、超时管理和错误恢复。
- 向量数据库或 RAG 功能的实现需要额外引入库(如 LangChain 的 Java 端口或自定义实现),增加了复杂度。
二、实现细节层面的区别
为了更直观地展示 Spring AI 与传统 Java API 调用的区别,以下通过具体代码示例对比两者的实现方式,涵盖初始化、调用和高级功能。
1. 初始化和配置
-
Spring AI:
Spring AI 利用 Spring Boot 的自动配置,只需在pom.xml中添加依赖并在application.properties中设置 API 密钥即可。例如,集成 OpenAI 的聊天模型:<!-- pom.xml --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId> <version>1.0.0-M6</version> </dependency># application.properties spring.ai.openai.api-key=your-openai-key spring.ai.openai.chat.options.model=gpt-4oSpring AI 会自动配置
ChatClient,开发者只需注入并使用:@RestController public class AIController { private final ChatClient chatClient; @Autowired public AIController(ChatClient.Builder builder) { this.chatClient = builder.build(); } @GetMapping("/chat") public String chat(@RequestParam String prompt) { return chatClient.prompt(prompt).call().content(); } }优点:
- 配置集中化,API 密钥存储在
application.properties,符合 Spring 的外部化配置理念。 - 通过依赖注入,
ChatClient自动初始化,无需手动设置端点或 HTTP 客户端。 - 支持动态配置(如通过环境变量或 Vault 管理密钥)。
- 配置集中化,API 密钥存储在
-
传统 Java API 调用:
使用 OpenAI 的官方 Java SDK(com.theokanning.openai)需要手动初始化客户端并配置请求。例如:<!-- pom.xml --> <dependency> <groupId>com.theokanning.openai</groupId> <artifactId>openai-java-client</artifactId> <version>0.18.0</version> </dependency>import com.theokanning.openai.client.OpenAiClient; import com.theokanning.openai.completion.CompletionRequest; @RestController public class AIController { private final OpenAiClient client; public AIController() { this.client = new OpenAiClient("your-openai-key"); } @GetMapping("/chat") public String chat(@RequestParam String prompt) { CompletionRequest request = CompletionRequest.builder() .model("gpt-3.5-turbo") .prompt(prompt) .maxTokens(100) .build(); return client.createCompletion(request).getChoices().get(0).getText(); } }缺点:
- API 密钥硬编码或需手动加载,安全性较低。
- 每次调用需要手动构造请求对象,参数配置(如
maxTokens)分散在代码中。 - 缺乏自动化的错误处理和重试机制,需开发者自行实现。
2. 模型调用
-
Spring AI:
Spring AI 的ChatClient提供了流式和非流式调用,支持复杂提示(Prompt)和角色(如用户、系统、助手)。例如,发送带有系统角色的多轮对话:@RestController public class AIController { private final ChatClient chatClient; @Autowired public AIController(ChatClient.Builder builder) { this.chatClient = builder.build(); } @GetMapping("/chat") public String chat(@RequestParam String userInput) { Prompt prompt = new Prompt(List.of( new SystemMessage("You are a helpful AI assistant."), new UserMessage(userInput) )); return chatClient.prompt(prompt).call().content(); } }优点:
Prompt对象支持多消息和角色,适合复杂对话场景。- 流式调用简单,只需使用
chatClient.stream()。 - 统一接口支持切换模型(如从 OpenAI 到 Ollama),无需修改业务代码。
-
传统 Java API 调用:
使用 OpenAI SDK 的对话调用需要手动构造消息列表:import com.theokanning.openai.completion.chat.ChatCompletionRequest; import com.theokanning.openai.completion.chat.ChatMessage; @RestController public class AIController { private final OpenAiClient client; public AIController() { this.client = new OpenAiClient("your-openai-key"); } @GetMapping("/chat") public String chat(@RequestParam String userInput) { List<ChatMessage> messages = List.of( new ChatMessage("system", "You are a helpful AI assistant."), new ChatMessage("user", userInput) ); ChatCompletionRequest request = ChatCompletionRequest.builder() .model("gpt-4") .messages(messages) .maxTokens(100) .build(); return client.createChatCompletion(request).getChoices().get(0).getMessage().getContent(); } }缺点:
- 请求构造复杂,需手动设置消息角色和参数。
- 不同模型的字段名和结构差异较大(如 OpenAI 的
messagesvs. Hugging Face 的inputs),跨模型适配成本高。 - 流式调用需要额外处理 SSE(Server-Sent Events)或 WebSocket。
3. 结构化输出
-
Spring AI:
Spring AI 支持将 AI 输出直接映射为 Java 对象(POJO),通过BeanOutputConverter简化解析。例如,生成一个 JSON 格式的结构化响应:public record Person(String name, int age) {} @RestController public class AIController { private final ChatClient chatClient; @Autowired public AIController(ChatClient.Builder builder) { this.chatClient = builder.build(); } @GetMapping("/person") public Person getPerson(@RequestParam String prompt) { BeanOutputConverter<Person> converter = new BeanOutputConverter<>(Person.class); String formattedPrompt = prompt + "\n" + converter.getFormat(); Prompt aiPrompt = new Prompt(formattedPrompt); String jsonResponse = chatClient.prompt(aiPrompt).call().content(); return converter.convert(jsonResponse); } }优点:
- 自动将 AI 输出的 JSON 字符串转换为 Java 对象,无需手动解析。
- 支持复杂的嵌套对象和泛型。
- 统一接口,适用于不同模型。
-
传统 Java API 调用:
传统方式需要手动解析 JSON 输出。例如,使用 Jackson 或 Gson:import com.fasterxml.jackson.databind.ObjectMapper; public class Person { private String name; private int age; // Getters and setters } @RestController public class AIController { private final OpenAiClient client; private final ObjectMapper mapper = new ObjectMapper(); public AIController() { this.client = new OpenAiClient("your-openai-key"); } @GetMapping("/person") public Person getPerson(@RequestParam String prompt) throws Exception { ChatCompletionRequest request = ChatCompletionRequest.builder() .model("gpt-4") .messages(List.of(new ChatMessage("user", prompt + "\nReturn JSON format"))) .build(); String jsonResponse = client.createChatCompletion(request).getChoices().get(0).getMessage().getContent(); return mapper.readValue(jsonResponse, Person.class); } }缺点:
- 需手动确保 AI 输出符合预期 JSON 格式,否则解析会失败。
- 不同模型的输出格式不一致,需为每个模型编写特定解析逻辑。
- 错误处理复杂,需自行捕获 JSON 解析异常。
4. 高级功能:RAG(检索增强生成)
-
Spring AI:
Spring AI 内置对向量数据库(如 PGVector、Weaviate)的支持,简化了 RAG 实现。例如,基于文档的问答系统:@RestController public class RAGController { private final VectorStore vectorStore; private final ChatClient chatClient; @Autowired public RAGController(VectorStore vectorStore, ChatClient.Builder builder) { this.vectorStore = vectorStore; this.chatClient = builder.build(); } @GetMapping("/rag") public String rag(@RequestParam String query) { List<Document> docs = vectorStore.similaritySearch(query); String context = docs.stream() .map(Document::getContent) .collect(Collectors.joining("\n")); Prompt prompt = new Prompt("Based on this context: " + context + "\nAnswer: " + query); return chatClient.prompt(prompt).call().content(); } }优点:
- 内置
VectorStore接口,支持多种向量数据库,开发者只需调用similaritySearch。 - 与
ChatClient无缝集成,上下文注入简单。 - 支持文档加载和分片,适合处理大型文档。
- 内置
-
传统 Java API 调用:
RAG 需要开发者自行集成向量数据库(如使用 PGVector 的 JDBC 驱动)和嵌入模型。例如:import com PGVector.PGVector; import java.sql.*; @RestController public class RAGController { private final OpenAiClient client; private final Connection dbConn; public RAGController() throws SQLException { this.client = new OpenAiClient("your-openai-key"); this.dbConn = DriverManager.getConnection("jdbc:postgresql://localhost:5432/db", "user", "pass"); } @GetMapping("/rag") public String rag(@RequestParam String query) throws Exception { // 假设已有嵌入向量 String embedding = getEmbedding(query); // 自定义方法调用 OpenAI 嵌入 API String sql = "SELECT content FROM docs ORDER BY embedding <-> ? LIMIT 5"; PreparedStatement stmt = dbConn.prepareStatement(sql); stmt.setObject(1, new PGVector(embedding)); ResultSet rs = stmt.executeQuery(); StringBuilder context = new StringBuilder(); while (rs.next()) { context.append(rs.getString("content")).append("\n"); } ChatCompletionRequest request = ChatCompletionRequest.builder() .model("gpt-4") .messages(List.of(new ChatMessage("user", "Based on this context: " + context + "\nAnswer: " + query))) .build(); return client.createChatCompletion(request).getChoices().get(0).getMessage().getContent(); } }缺点:
- 需手动管理数据库连接和向量搜索逻辑。
- 嵌入生成和上下文拼接需额外实现,代码复杂。
- 缺乏统一的文档处理框架,需自行分片和存储。
5. 工具调用(Function Calling)
-
Spring AI:
Spring AI 支持工具调用,允许 AI 模型调用开发者定义的 Java 方法。例如,获取实时天气:@RestController public class ToolController { private final ChatClient chatClient; @Autowired public ToolController(ChatClient.Builder builder) { this.chatClient = builder.build(); } @Tool public String getWeather(String city) { // 模拟调用天气 API return "The weather in " + city + " is sunny."; } @GetMapping("/weather") public String weather(@RequestParam String query) { Prompt prompt = new Prompt(query); return chatClient.prompt(prompt).call().content(); } }优点:
- 使用
@Tool注解自动注册方法,AI 模型可动态调用。 - 与 Spring 的依赖注入集成,工具方法可复用业务逻辑。
- 跨模型支持(如 OpenAI 和 Anthropic 的工具调用格式差异由 Spring AI 屏蔽)。
- 使用
-
传统 Java API 调用:
工具调用需要手动实现,通常依赖模型特定的 JSON 格式。例如,使用 OpenAI 的工具调用:@RestController public class ToolController { private final OpenAiClient client; public ToolController() { this.client = new OpenAiClient("your-openai-key"); } @GetMapping("/weather") public String weather(@RequestParam String query) throws Exception { List<Tool> tools = List.of( new Tool("getWeather", "Get weather for a city", "{\"city\": {\"type\": \"string\"}}") ); ChatCompletionRequest request = ChatCompletionRequest.builder() .model("gpt-4") .messages(List.of(new ChatMessage("user", query))) .tools(tools) .build(); ChatCompletionResult result = client.createChatCompletion(request); if (result.getChoices().get(0).getMessage().getToolCalls() != null) { String city = parseCityFromToolCall(result); // 自定义解析逻辑 String weather = getWeather(city); // 自定义方法 // 再次调用模型以生成最终响应 request = ChatCompletionRequest.builder() .model("gpt-4") .messages(List.of( new ChatMessage("user", query), new ChatMessage("assistant", weather) )) .build(); return client.createChatCompletion(request).getChoices().get(0).getMessage().getContent(); } return result.getChoices().get(0).getMessage().getContent(); } private String getWeather(String city) { return "The weather in " + city + " is sunny."; } }缺点:
- 工具定义和调用复杂,需手动构造 JSON Schema。
- 不同模型的工具调用格式差异大,需为每个模型适配。
- 多次 API 调用增加延迟和成本。
三、综合分析与场景对比
1. 适用场景
-
Spring AI:
- 企业级应用:适合需要与现有 Spring 生态(Spring Boot、Spring Cloud、Spring Data)集成的场景,如微服务架构中的智能客服、推荐系统或数据分析。
- 跨模型需求:当项目需要支持多个 AI 模型(如同时使用 OpenAI 和本地 Ollama 模型)或未来可能切换供应商时,Spring AI 的抽象层减少了迁移成本。
- 复杂功能:如 RAG、工具调用、结构化输出等高级功能,Spring AI 提供了开箱即用的支持,适合知识库问答、自动化工作流等场景。
-
传统 Java API 调用:
- 快速原型:适合快速验证 AI 模型效果的小型项目或个人实验,开发者可直接使用供应商 SDK 实现简单功能。
- 单一模型:当项目明确只使用某个模型(如 OpenAI 的 GPT-4),且无需复杂的企业集成时,传统方式更直接。
- 高度定制:需要深度优化 API 调用(如精确控制请求参数或处理供应商特有功能)时,传统方式提供了更大灵活性。
2. 优劣对比
| 维度 | Spring AI | 传统 Java API 调用 |
|---|---|---|
| 学习成本 | 低,熟悉 Spring 的开发者可快速上手 | 高,需学习每个供应商的 SDK 和 API 细节 |
| 代码简洁性 | 高,自动配置和统一接口减少样板代码 | 低,需手动处理请求构造、响应解析和错误处理 |
| 跨模型支持 | 优秀,统一接口支持无缝切换模型 | 差,需为每个模型编写适配代码 |
| 企业集成 | 优秀,与 Spring 生态无缝集成,支持微服务、安全性和可观察性 | 差,需手动实现企业级特性 |
| 高级功能 | 内置支持 RAG、工具调用、结构化输出等 | 需自行实现或引入第三方库 |
| 灵活性 | 稍低,受限于 Spring AI 的抽象层 | 高,可直接调用底层 API 实现定制化功能 |
| 维护成本 | 低,Spring 社区支持,版本升级平滑 | 高,需跟踪多个 SDK 的更新和兼容性问题 |
3. 实际案例
假设一个企业需要构建一个基于文档的智能问答系统,支持多语言和多种 AI 模型:
-
Spring AI 实现:
- 使用
spring-ai-openai-spring-boot-starter和spring-ai-pgvector依赖。 - 配置 PGVector 存储文档嵌入,
VectorStore自动处理相似性搜索。 - 通过
ChatClient集成 OpenAI 和 Anthropic 模型,动态切换。 - 使用
BeanOutputConverter将回答映射为 JSON 返回给前端。 - 部署在 Spring Cloud 微服务架构中,利用 Spring Security 保护 API。
- 代码量:约 100 行,配置驱动,易于扩展。
- 使用
-
传统 Java API 实现:
- 使用 OpenAI SDK 和 PGVector JDBC 驱动。
- 手动调用 OpenAI 的嵌入 API 生成向量,存储到 PostgreSQL。
- 实现向量搜索的 SQL 查询逻辑。
- 手动解析 JSON 响应并转换为前端所需格式。
- 需额外集成安全框架(如 Shiro 或手动实现)。
- 代码量:约 300-500 行,包含大量样板代码和错误处理。
Spring AI 的实现效率更高,代码更简洁,且易于维护和扩展。
四、总结
Spring AI 与传统 Java API 调用 AI 模型的核心区别在于 抽象层的设计 和 生态集成:
-
理论层面:
- Spring AI 提供统一的接口和 Spring 生态支持,降低了学习成本和跨模型适配难度,强调企业级生产就绪性。
- 传统方式灵活但分散,适合快速原型或单一模型场景,但在复杂应用中维护成本高。
-
实现层面:
- Spring AI 通过自动配置、依赖注入和高级功能(如 RAG、工具调用)简化开发,代码简洁且可扩展。
- 传统方式需要手动处理配置、请求构造和响应解析,代码冗余且跨模型适配复杂。
-
实际应用:
- Spring AI 适合企业级 AI 应用,特别是需要多模型支持、复杂功能或与 Spring 生态集成的场景。
- 传统方式适合简单实验或高度定制化场景,但不适合大规模生产环境。
对于大多数 Java 开发者,尤其是熟悉 Spring 生态的团队,Spring AI 是构建 AI 应用的首选工具。它不仅提高了开发效率,还通过统一的抽象和强大的生态支持降低了长期维护成本。如果项目需要快速迭代或跨模型灵活性,Spring AI 的优势尤为明显。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)