Dify x DeepSeek:轻松部署私有化 AI 助手,搭建本地 DeepSeek R1+ 联网搜索 App_dify联网
如需切换访问端口,请参考此文档:https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/faq#id-5.-ru-he-xiu-gai-ye-mian-duan-kou。通过私有化部署,你可以完全掌控数据的安全性,并根据自己的需求灵活调整部署方案,打造专属于你的。在实际应用中,当你上传内部文档或专业资料后, Dify 的知识
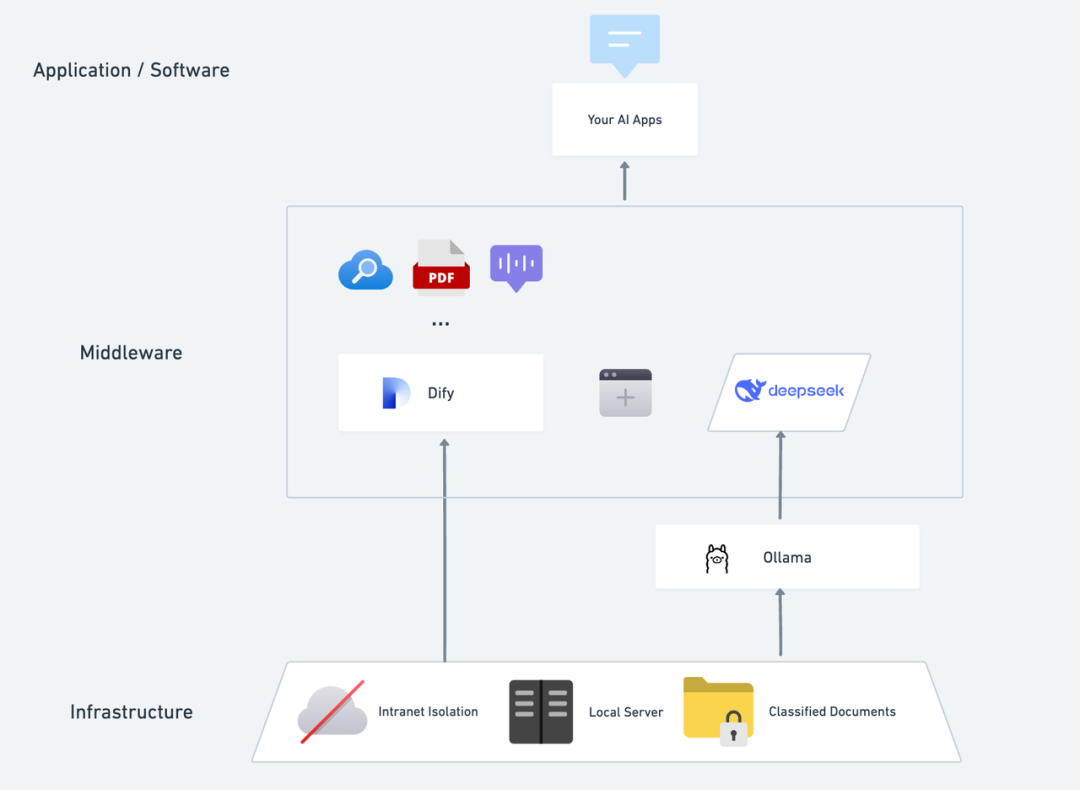
想象一下,拥有一款独立运行、全程保密、还能够分析本地文本内容,随时提供精准的对话服务,并且具备联网搜索能力的私有化 AI 应用是一种怎样的体验?本文将带你一步步搭建 DeepSeek + Ollama + Dify,快速部署全功能的私有化 AI 助手。
DeepSeek 是一款突破性的开源大语言模型,它的先进算法架构和“反思链”能力,让 AI 对话交互变得更智能与自然。通过私有化部署,你可以完全掌控数据的安全性,并根据自己的需求灵活调整部署方案,打造专属于你的 「AI 操作系统」。
Dify 作为同样开源的 AI 应用开发平台,同样提供了完善的私有化部署方案和强大的第三方工具支持(包括联网搜索、文件分析功能等)。同时,Dify 支持全球 1000+ 开源或闭源大模型,你可以调用任意的模型能力赋能你的 AI 应用。
将 DeepSeek 无缝集成到 Dify 平台,不仅能确保数据隐私,且易于开发上手“折腾”,在本地服务器内轻松打造功能强大的 AI 应用,让企业或团队真正实现**“数据自主权”和“灵活定制”**。
Dify X DeepSeek 私有化部署的优势:
- 调用 1000+ 模型能力: Dify 是一个模型中立的平台,可充分使用不同大模型的推理能力(PS:可使用 Dify 支持的多个第三方 MaaS 平台调用 DeepSeek R1 模型,以解决官方 API 调用不稳定问题,详细配置方法请见文末)
- 性能卓越: 媲美商业模型的对话体验,轻松应对各种复杂场景。
- 环境隔离: 完全离线运行,杜绝数据外泄的任何风险。
- 数据可控: 你说了算,数据完全掌控,符合行业合规要求。
前置准备
购置一台满足以下条件的服务器(VPS 或 VDS):
硬件环境:
- CPU >= 2 Core
- 显存/RAM ≥ 16 GiB(推荐)
软件环境:
- Docker
- Docker Compose
- Ollama
- Dify 社区版
开始部署
1. 安装 Ollama
正如手机内通常会具备应用商店,帮助你快速找到并下载 App 一样,AI 模型也有自己的专属“应用商店”。
Ollama 便是这样一款跨平台的开源大模型管理客户端(支持 macOS、Windows、Linux),旨在无缝部署大型语言模型 (LLM),例如 DeepSeek、Llama、Mistral 等。
仅需一条命令即可完成安装大模型和部署,LLM 的所有使用数据均会保存在本地机器内,提供全方面的数据隐私和安全性,满足合规要求。
访问 Ollama 官网(https://ollama.com/),根据网页提示下载并安装 Ollama 客户端。安装完成后,在终端内运行 ollama -v 命令将输出版本号。
~ ollama -v
ollama version is 0.5.5
根据实际的环境配置,选择合适的 DeepSeek 尺寸模型进行部署。初次安装推荐安装 7B 尺寸模型。
后缀的 B 表示模型的训练参数。理论上参数越高,模型的表现也越智能,所需的显存也越高。
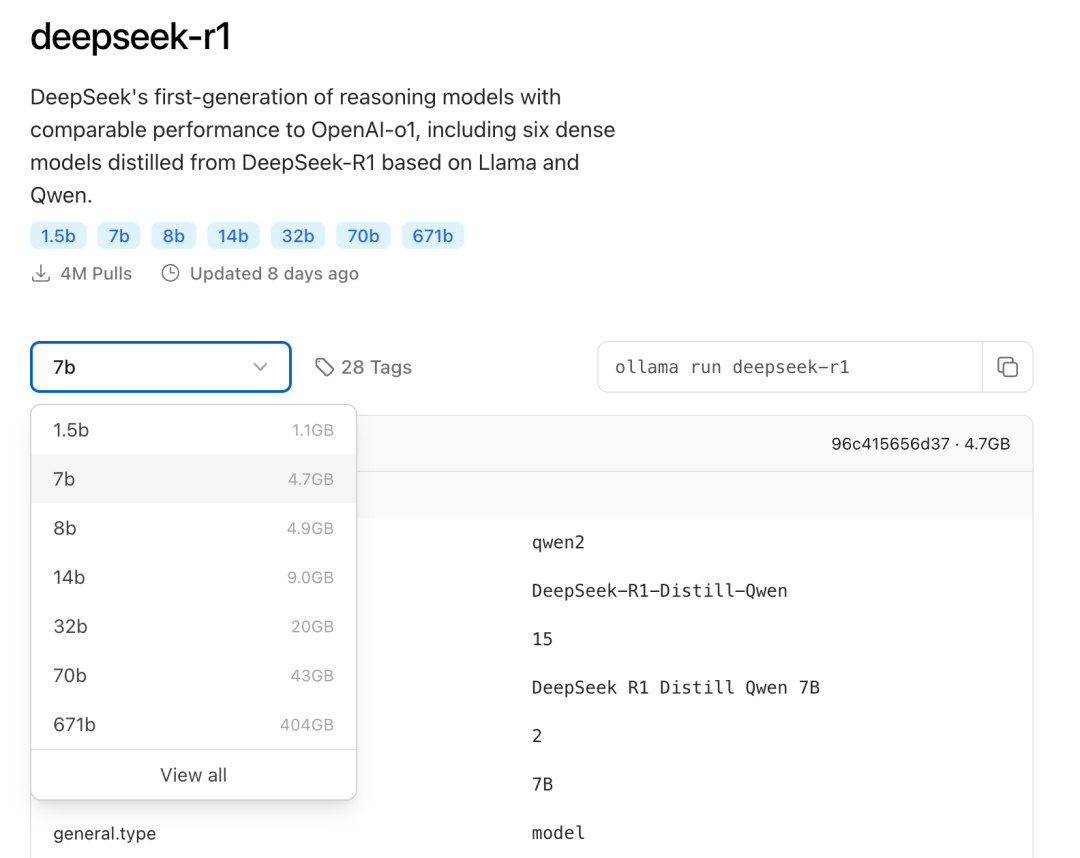
运行命令 **ollama run deepseek-r1:7b** 安装 DeepSeek R1 模型。

2. 安装 Dify 社区版
正如房屋通了水电之后,还需要一个功能完善的厨房才能让厨师生产出美味佳肴,Dify 的作用便是如此。作为热门的 GitHub 开源项目,Dify 已内置了贯穿构建 AI 应用时所需的各式工具链。无需掌握复杂的代码知识,结合 DeepSeek 强大的模型能力,任何人都可以快速打造出心目中理想且好用的 AI 应用。
访问 Dify GitHub 项目地址,运行以下命令完成拉取代码仓库和安装流程。
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d # 如果版本是 Docker Compose V1,使用以下命令:docker-compose up -d
运行命令后,终端将自动输出所有容器的状态和端口映射情况。如有中断或报错,请确保已安装 Docker 及 Docker Compose。详细说明请参考以下内容。
部署 Dify 社区版:
https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
Dify 社区版默认使用 80 端口,通过链接 http://your_server_ip 即可访问你的私有化 Dify 平台。
如需切换访问端口,请参考此文档:https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/faq#id-5.-ru-he-xiu-gai-ye-mian-duan-kou
3. 将 DeepSeek 接入至 Dify
部署 DeepSeek 模型与 Dify 社区版后,点击链接 http://your_server_ip 进入 Dify 平台,接着点击右上角头像 → 设置 → 模型供应商,选择 Ollama,轻点“添加模型”。
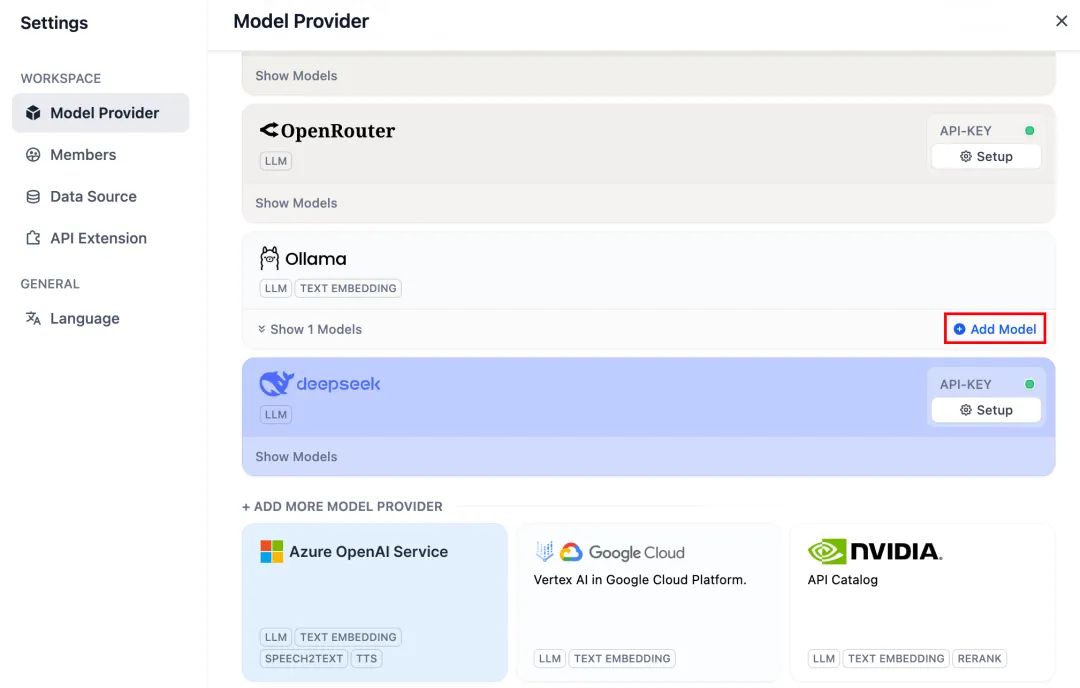
选择 LLM 模型类型。
- Model Name,填写具体部署的模型型号。上文部署的模型型号为 deepseek-r1 7b,因此填写:deepseek-r1:7b
- Base URL,填写 Ollama 客户端的运行地址,通常为:http://your_server_ip:11434。如遇连接问题,请阅读文末常见问题。
- 其它选项保持默认值。根据 DeepSeek 模型说明,最大生成长度为 32,768 Tokens。
开始搭建 AI 应用
以下章节将为你介绍如何搭建不同类型的 AI 应用:
- 简单对话应用
- 具备文件分析能力的简单对话应用
- 具备联网搜索的可编排应用
DeepSeek AI Chatbot(简单应用)
\1. 轻点 Dify 平台首页左侧的“创建空白应用”,选择“聊天助手”类型应用并进行简单的命名。
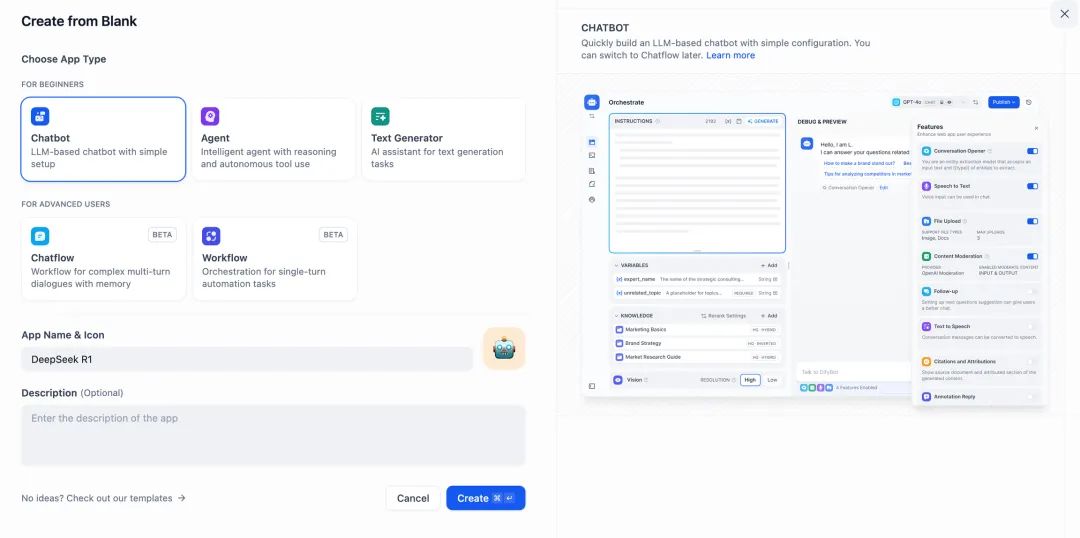
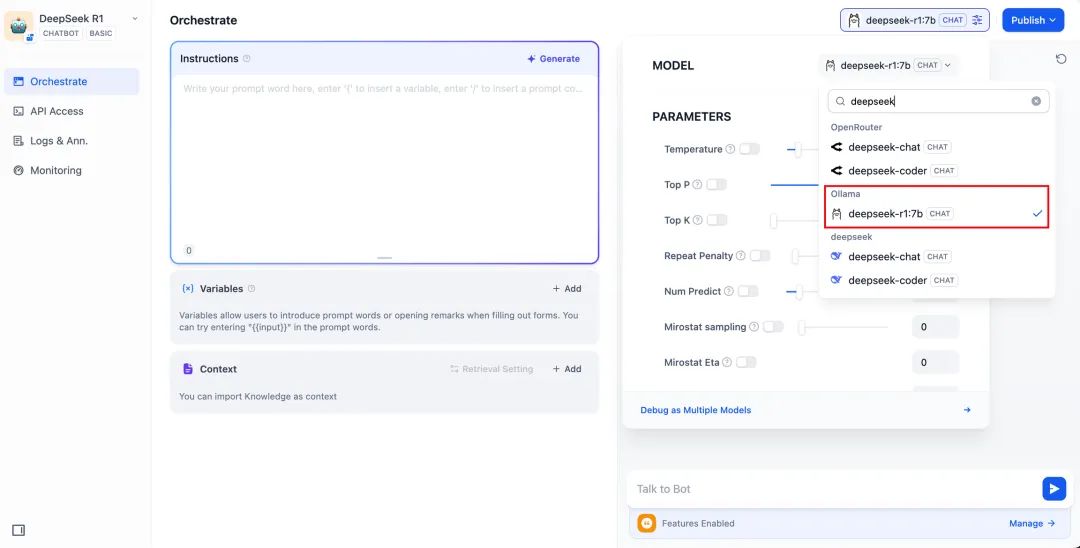
\2. 在右上角的应用类型,选择 Ollama 框架内的 **deepseek-r1:7b** 模型。
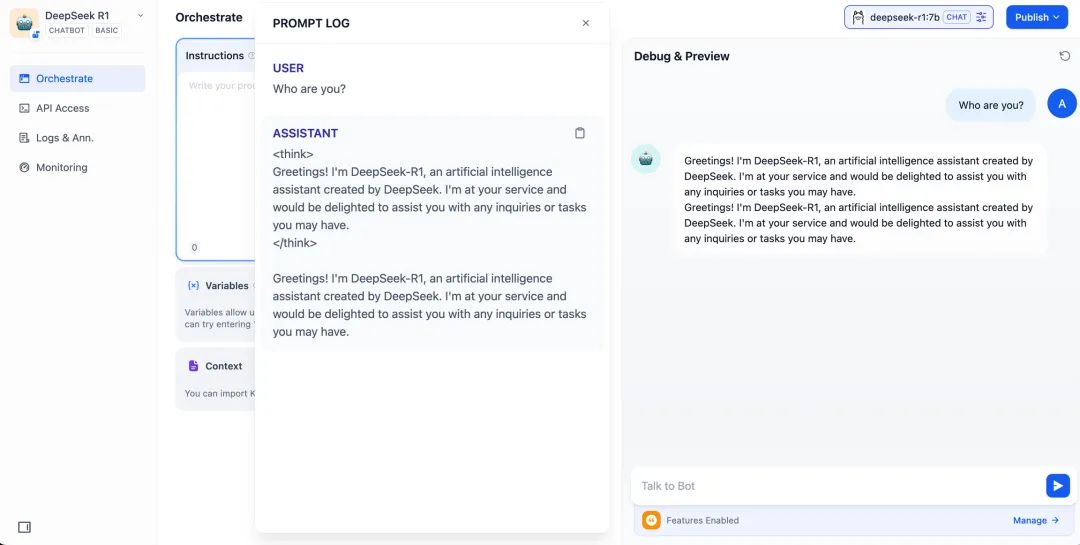
\3. 在预览对话框中输入内容,验证 AI 应用是否能够正常运行。生成答复后意味着 AI 应用的搭建已完成。
\4. 轻点应用右上方的发布按钮,获取 AI 应用链接并分享给他人或嵌入至其它网站内。
DeepSeek AI Chatbot + 知识库
大规模语言模型(LLM)面临的一个重要挑战在于训练数据并非实时更新,且数据量可能不足,这容易导致模型生成“幻觉”式的回答。
为了解决这一问题,检索增强生成(RAG)技术应运而生。通过检索相关知识,为模型提供必要的上下文信息,将这些信息融入内容生成过程中,从而提升回答的准确性和专业度。
在实际应用中,当你上传内部文档或专业资料后, Dify 的知识库功能可以承担起 RAG 作用,帮助 LLM 基于专业资料提供更有针对性的解答,有效弥补模型训练数据的不足。
1. 创建知识库
将需要 AI 分析处理的文档上传至知识库中。为确保 DeepSeek 模型能够准确理解文档内容,建议使用"父子分段"模式进行文本处理 - 这种模式能够更好地保留文档的层级结构和上下文关系。
如需了解详细的配置步骤,请参考此文档:
https://docs.dify.ai/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents
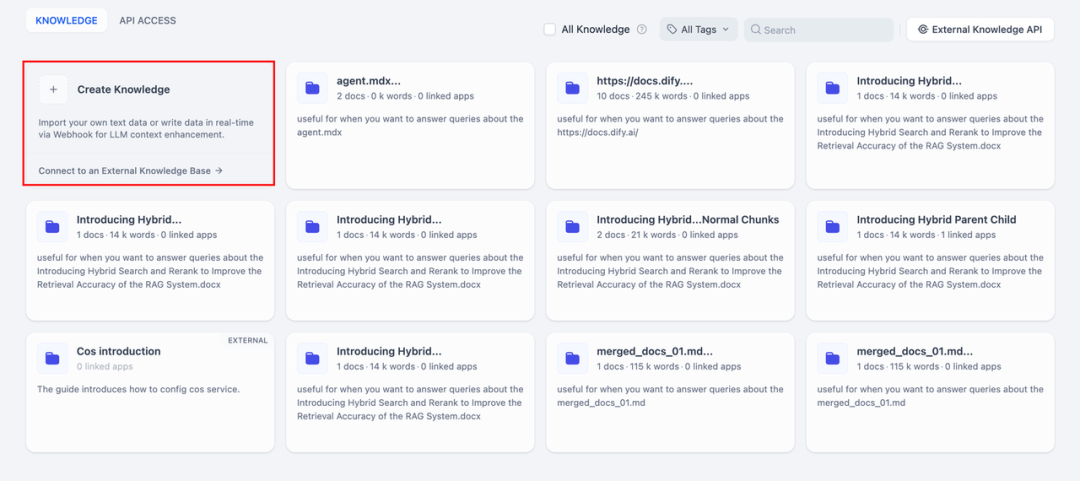
2. 将知识库集成至 AI 应用
在 AI 应用的“上下文”内添加知识库,在对话框内输入相关问题。LLM 将首先从知识库内获取与问题相关上下文,在此基础上进行总结并给出更高质量的回答。
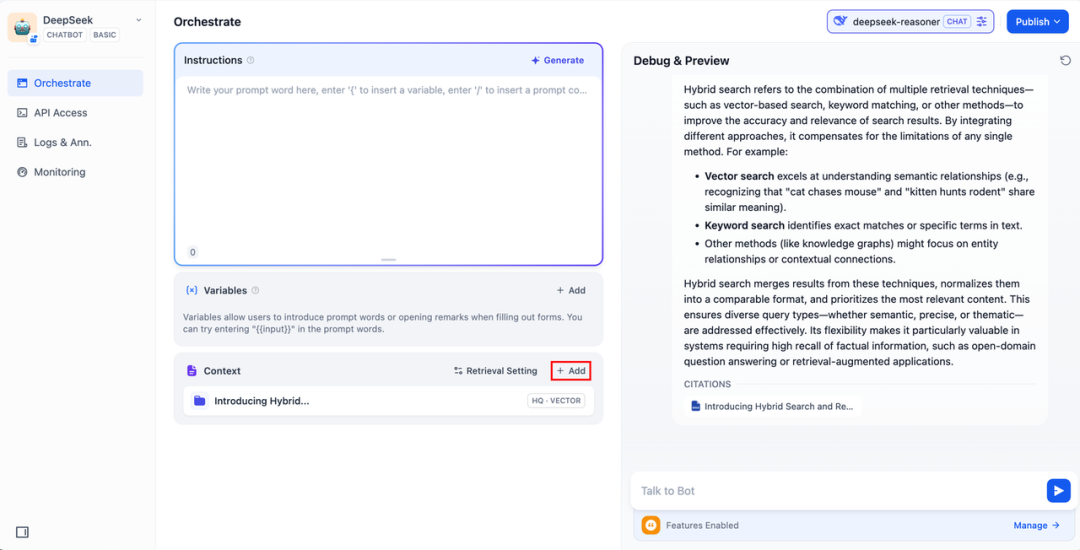
DeepSeek AI Chatflow / Workflow(联网搜索)
Chatflow / Workflow 应用可以帮助你编排并搭建功能更加复杂的 AI 应用,例如为 DeepSeek 赋予联网搜索、文件识别、语音识别等能力。出于篇幅考虑,以下章节为你介绍如何为 DeepSeek 开启联网搜索能力。
如果想要直接使用该应用,可以点击以下链接下载 DSL 文件并导入至 Dify 平台内。
应用 DSL 文件下载地址:
https://assets-docs.dify.ai/2025/02/41a3564694dd3f2803ad06a29f5b3fef.yml
\1. 轻点 Dify 平台首页左侧的“创建空白应用”,选择 “Chatflow” 或 “Workflow” 类型应用并进行简单的命名。
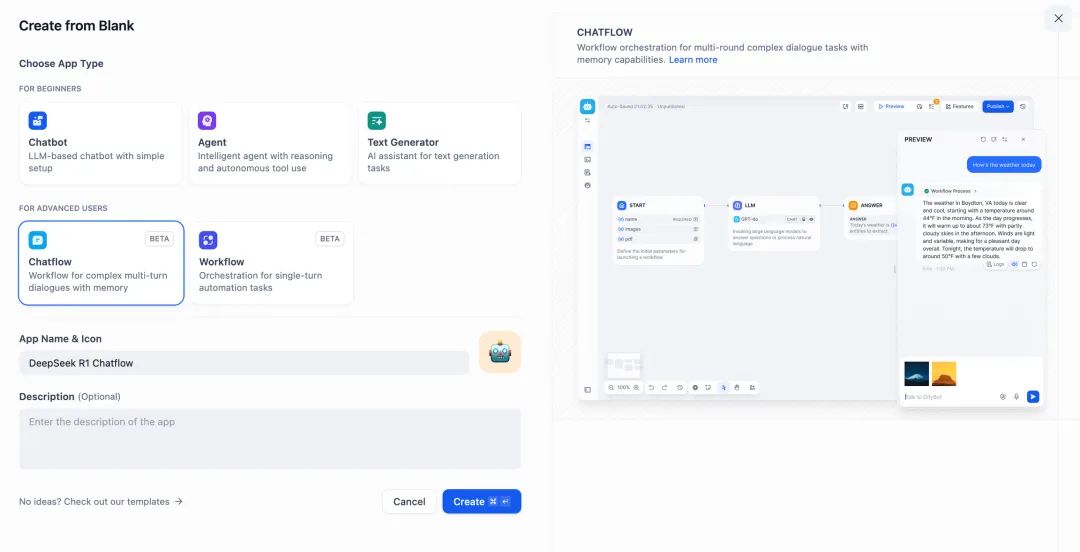
2.添加联网搜索节点,填入 API Key 以激活节点功能。在 Query 字段内填写初始节点提供的 **{{#sys.query#}}** 变量。
访问以下网站获取 API Key:
https://serpapi.com/users/sign_in
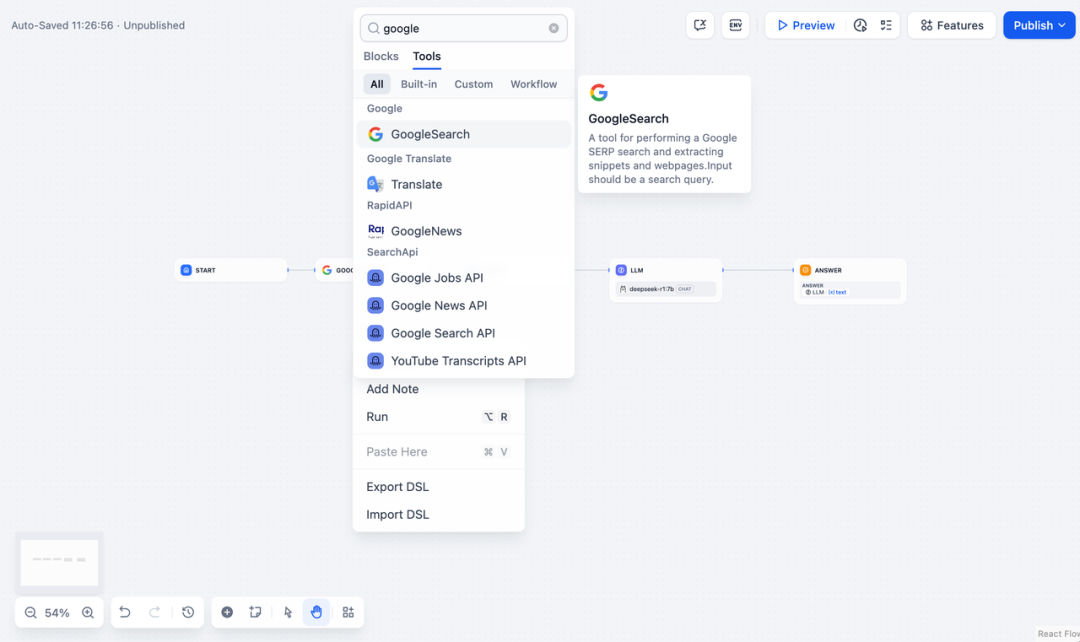
3.添加代码执行节点。由于搜索工具的输出内容为一段 JSON 代码,因此需要添加代码执行节点提取必要的内容。输入变量填写搜索工具的 JSON 输出变量,并在代码执行节点内填入以下代码:
def main(json: list) -> dict:
# 提取 organic_results 内容
organic_results = json[0].get("organic_results", [])
# 将所有的标题和链接拼接为一个字符串
result_string = ""
for item in organic_results:
result_string += f"Title: {item['title']}\nLink: {item['link']}\nSnippet: {item['snippet']}\n\n"
# 返回拼接后的字符串作为 result
return {
"result": result_string,
}
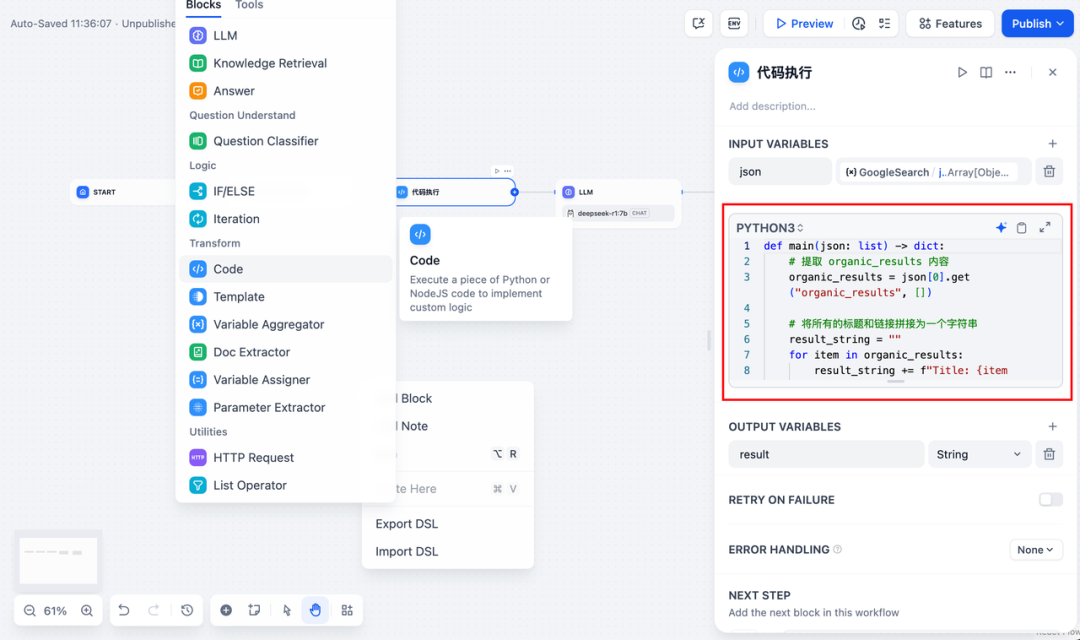
\4. 添加 LLM 节点,选择 Ollama 框架内的 **deepseek-r1:7b** 模型,并在系统提示词内添加 **{{#sys.query#}}** 变量以处理来自起始节点由用户输入的指令。
如遇 API 异常,可以通过负载均衡功能或异常处理节点进行灵活处理。
负载均衡可以通过在多个 API 端点之间分配 API 请求,详细说明请参考:https://docs.dify.ai/zh-hans/guides/model-configuration/load-balancing
异常处理机制能够在节点发生错误时抛出故障信息而不中断主流程。详细说明请参考:https://docs.dify.ai/zh-hans/guides/workflow/error-handling
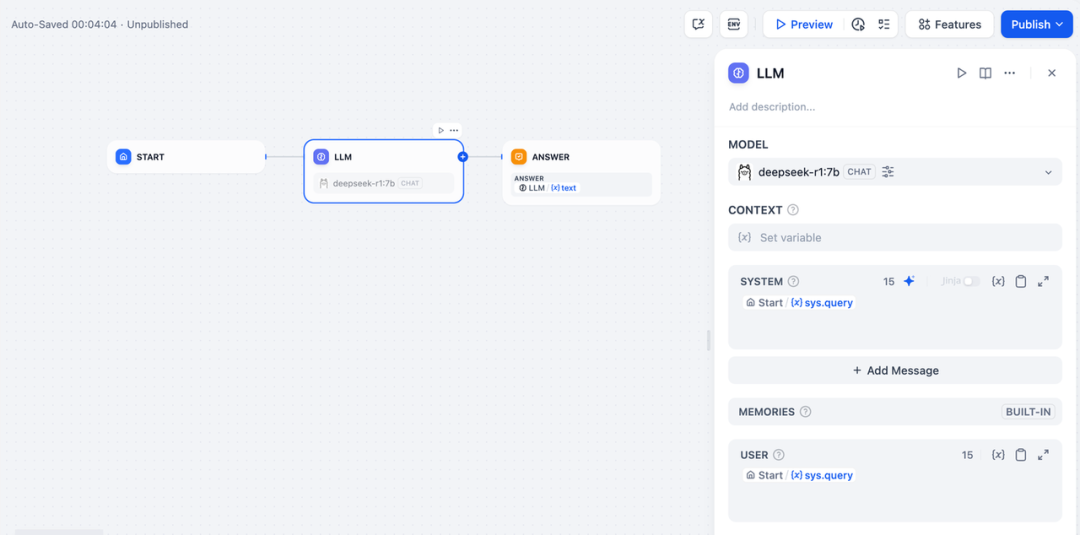
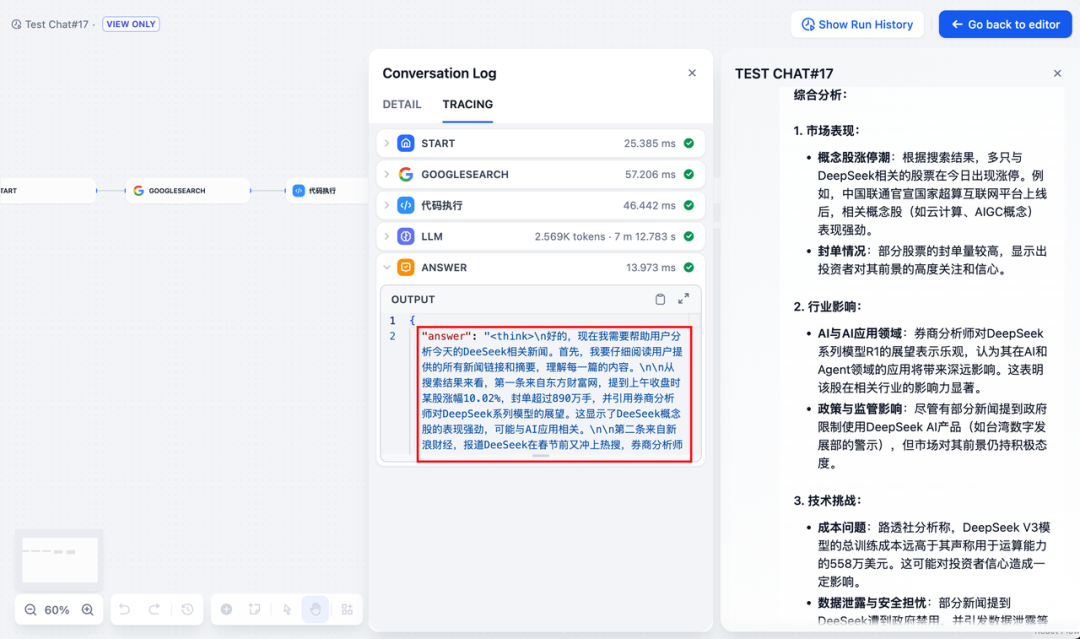
\5. 添加结束节点,引用 LLM 节点的输出变量并完成配置。你可以在预览框中输入内容以进行测试。生成答复后意味着 AI 应用的搭建已完成,你可以在日志内查看 LLM 的推理过程。
常见问题
1. Docker 部署时的连接错误
当使用 Docker 部署 Dify 和 Ollama 时,可能遇到以下错误:
httpconnectionpool(host=127.0.0.1, port=11434): max retries exceeded with url:/cpi/chat
(Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>:
fail to establish a new connection:[Errno 111] Connection refused'))
httpconnectionpool(host=localhost, port=11434): max retries exceeded with url:/cpi/chat
(Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>:
fail to establish a new connection:[Errno 111] Connection refused'))
错误原因:此错误发生是因为 Ollama 服务在 Docker 容器中无法访问。localhost 通常指向容器本身,而不是主机或其他容器。要解决此问题,需要将 Ollama 服务暴露到网络中。
macOS 环境配置方法:
如果 Ollama 作为 macOS 应用运行,需要使用 launchctl 设置环境变量:
-
通过调用 launchctl setenv 设置环境变量:
launchctl setenv OLLAMA_HOST "0.0.0.0" -
重启 Ollama 应用程序。
-
如果以上步骤无效,可以使用以下方法:
问题是在 docker 内部,你应该连接到 host.docker.internal,才能访问 docker 的主机,所以将 localhost 替换为 host.docker.internal 服务就可以生效了:
http://host.docker.internal:11434
Linux 环境配置方法:
如果 Ollama 作为 systemd 服务运行,应该使用 **s****ystemctl** 设置环境变量:
-
通过调用
**systemctl edit ollama.service**编辑 systemd 服务。这将打开一个编辑器。 -
对于每个环境变量,在
**[Service]**部分下添加一行**Environment**:[Service]Environment="OLLAMA_HOST=0.0.0.0" -
保存并退出。
-
重载 systemd 并重启 Ollama:
systemctl daemon-reloadsystemctl restart ollama
Windows 环境配置方法:
在 Windows 上,Ollama 继承了你的用户和系统环境变量。
- 首先通过任务栏点击 Ollama 退出程序
- 从控制面板编辑系统环境变量
- 为你的用户账户编辑或新建变量,比如
**OLLAMA_HOST**、**OLLAMA_MODELS**等。 - 点击 OK / 应用保存
- 在一个新的终端窗口运行
**ollama**
2. 如何修改 Ollama 服务地址和端口号?
Ollama 默认绑定 **127.0.0.1** 端口 11434,你可以通过 **OLLAMA_HOST** 环境变量更改绑定地址。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享)(安全链接,放心点击)]()👈

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享)(安全链接,放心点击)]()👈


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)