轻松实现推理智能体,基于Smolagents框架和DeepSeek-R1
大家好,现在 AI 智能体在处理复杂推理任务上越来越强大,本文将介绍一个实用的技术组合。Smolagents,Hugging Face 开发的轻量级框架,能让大语言模型(LLMs)与现实数据处理无缝对接。DeepSeek-R1 是开源大语言模型里的 “性价比担当”,用 Ollama 部署到本地,运行效率超高。下面就详细教大家如何借助这二者,结合网页抓取和数据导出工具,搭建超厉害的推理智能体。
大家好,现在 AI 智能体在处理复杂推理任务上越来越强大。Smolagents作为Hugging Face 开发的轻量级框架,能让大语言模型(LLMs)与现实数据处理无缝对接。DeepSeek-R1 是开源大语言模型里的 “性价比担当”,用 Ollama 部署到本地,运行效率超高。借助这两个智能框架,结合网页抓取和数据导出工具,搭建超厉害的推理智能体。
1.Smolagents:轻量高效的智能体框架
Smolagents是个极简风格的AI智能体框架,专为开发者高效构建、部署智能体而生。
Smolagents在关键特性上十分出众,代码库约1000行,开发起来比较简单,并且能执行Python代码片段,结果更精准。在沙盒环境运行代码,同时支持很多大语言模型,例如Hugging Face系和OpenAI的GPT,工具共享也很方便,能从Hugging Face Hub共享、导入工具。
其具有很多优势,嵌套函数调用,复杂逻辑也能轻松表达;比起JSON,对象管理流程大幅简化;不管哪种计算操作,都能运用。
2.DeepSeek-R1:开源界的“潜力股”大模型
DeepSeek-R1是DeepSeek AI开发的开源大语言模型,优点很多:
-
性价比超高:花更少的成本,就能获得先进的推理能力。
-
文本处理高效:处理文本任务效率一流。
-
百搭框架集成:和Smolagents这类智能体框架能完美集成。
3.实战:构建超实用推理智能体
带大家实操一波,用Smolagents和DeepSeek-R1打造一个超实用的推理智能体。这个智能体有三大厉害功能:
-
数据抓取:能从realtor.com网站精准抓取房地产经纪人数据,轻松获取一手信息。
-
数据存储:抓取完的数据,会自动保存到CSV文件里,方便后续整理和分析。
-
推理任务执行:借助DeepSeek-R1强大的能力,执行各种推理任务,挖掘数据背后的价值。
(1)导入所需库
from typing import Optional, Dict
from smolagents import CodeAgent, tool, LiteLLMModel , GradioUI, OpenAIServerModel
import requests
import os
import time
from bs4 import BeautifulSoup
import pandas as pd
Smolagents模块: - CodeAgent:定义和管理人工智能智能体。 - tool:用于定义智能体工具的装饰器。 - LiteLLMModel:集成各种大语言模型。 - OpenAIServerModel:连接外部模型。
其他库: - requests:用于发送HTTP请求。 - BeautifulSoup:解析HTML,用于网页抓取。 - pandas:处理结构化数据。
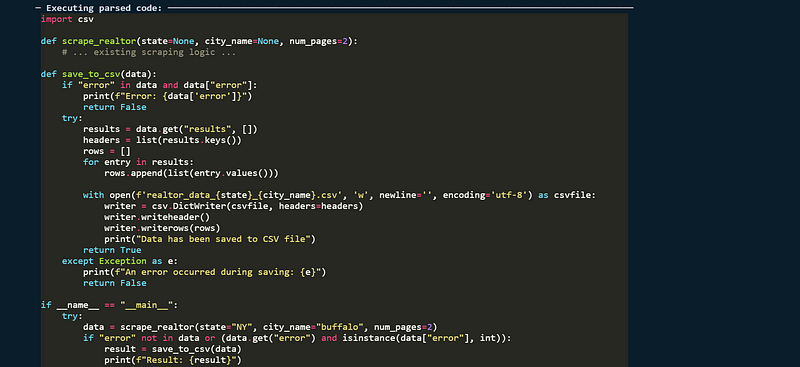
(2)网页抓取工具
@tool
def scrape_real_estate_agents(state: str, city_name: str, num_pages: Optional[int] = 2) -> Dict[str, any]:
"""Scrapes realtor.com for real estate agent information in specified city and state
Args:
state: State abbreviation (e.g., 'CA', 'NY')
city_name: City name with hyphens instead of spaces (e.g., 'buffalo')
num_pages: Number of pages to scrape (default: 2)
"""
try:
# Initialize results
agent_names = [] # Names
agent_phones = [] # Phone numbers
agent_offices = [] # Office names
pages_scraped = 0
# Set up headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive"
}
# Process pages
for page in range(1, num_pages + 1):
# Construct URL
if page == 1:
url = f'https://www.realtor.com/realestateagents/{city_name}_{state}/'
else:
url = f'https://www.realtor.com/realestateagents/{city_name}_{state}/pg-{page}'
print(f"Scraping page {page}...")
# Get page content
response = requests.get(url, headers=headers)
if response.status_code != 200:
return {"error": f"Failed to access page {page}: Status code {response.status_code}"}
soup = BeautifulSoup(response.text, features="html.parser")
# Find all agent cards
agent_cards = soup.find_all('div', class_='agent-list-card')
for card in agent_cards:
# Find name
name_elem = card.find('div', class_='agent-name')
if name_elem:
name = name_elem.text.strip()
if name and name notin agent_names:
agent_names.append(name)
print(f"Found agent: {name}")
# Find phone
phone_elem = card.find('a', {'data-testid': 'agent-phone'}) or \
card.find(class_='btn-contact-me-call') or \
card.find('a', href=lambda x: x and x.startswith('tel:'))
if phone_elem:
phone = phone_elem.get('href', '').replace('tel:', '').strip()
if phone:
agent_phones.append(phone)
print(f"Found phone: {phone}")
# Get office/company name
office_elem = card.find('div', class_='agent-group') or \
card.find('div', class_='text-semibold')
if office_elem:
office = office_elem.text.strip()
agent_offices.append(office)
print(f"Found office: {office}")
else:
agent_offices.append("")
pages_scraped += 1
time.sleep(2) # Rate limiting
ifnot agent_names:
return {"error": "No agents found. The website structure might have changed or no results for this location."}
# Return structured data
return {
"names": agent_names,
"phones": agent_phones,
"offices": agent_offices,
"total_agents": len(agent_names),
"pages_scraped": pages_scraped,
"city": city_name,
"state": state
}
except Exception as e:
return {"error": f"Scraping error: {str(e)}"}
- 设置自定义请求头以避免被网站阻止访问。
- 获取HTML内容并进行解析。
- 查找房地产经纪人的姓名、电话号码和办公室详细信息。
- 将信息存储在列表中,以便结构化存储。
(3)导出数据到CSV文件
@tool
def export_to_csv(scraped_data: Dict[str, any], output_filename: Optional[str] = None) -> str:
"""Exports scraped real estate agent data to a CSV file
Args:
scraped_data: Dictionary containing the results of the scraping
output_filename: Optional filename for the CSV file (default: cityname.csv)
"""
try:
if"error"in scraped_data:
returnf"Error: {scraped_data['error']}"
ifnot output_filename:
output_filename = f"{scraped_data['city'].replace('-', '')}.csv"
# Ensure all lists are of equal length
max_length = max(len(scraped_data['names']), len(scraped_data['phones']), len(scraped_data['offices']))
# Pad shorter lists with empty strings
scraped_data['names'].extend([""] * (max_length - len(scraped_data['names'])))
scraped_data['phones'].extend([""] * (max_length - len(scraped_data['phones'])))
scraped_data['offices'].extend([""] * (max_length - len(scraped_data['offices'])))
# Create DataFrame with just names, phones, and offices
df = pd.DataFrame({
'Names': scraped_data['names'],
'Phone': scraped_data['phones'],
'Office': scraped_data['offices']
})
df.to_csv(output_filename, index=False, encoding='utf-8')
returnf"Data saved to {output_filename}. Total entries: {len(df)}"
except Exception as e:
returnf"Error saving CSV: {str(e)}"
- 目的:将抓取的数据保存到CSV文件中。
- 默认文件名:如果未提供文件名,则使用城市名称。
- 将抓取的数据转换为DataFrame格式。
- 保存为CSV文件。
- 使用OpenAIServerModel进行执行。
(4)集成DeepSeek-R1
deepseek_model = OpenAIServerModel(
model_id="deepseek-r1:7b",
api_base="http://localhost:11434/v1",
api_key="ollama"
)
- 连接到本地部署的DeepSeek-R1。
- 使用OpenAIServerModel进行执行。
(5)定义人工智能智能体
agent = CodeAgent(
tools=[scrape_real_estate_agents, export_to_csv],
model=deepseek_model,
additional_authorized_imports=["pandas", "bs4", "time"]
)
定义智能体时: - 使用抓取和导出工具。 - 使用DeepSeek-R1进行推理。 - 授权导入相关库,以防范安全风险。
(6)运行智能体
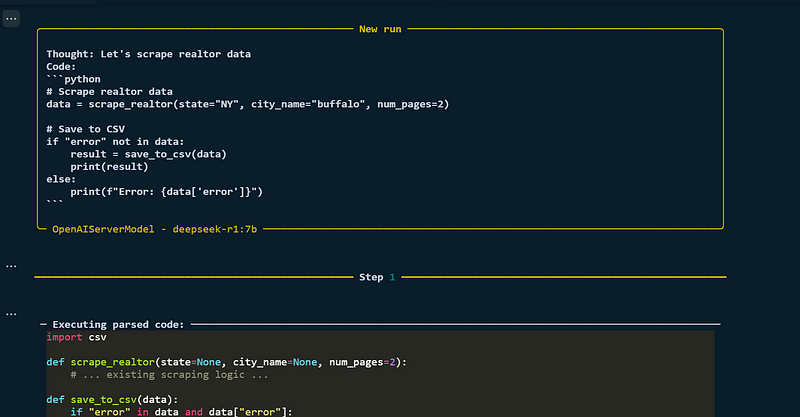
result = agent.run("""
Thought: Let's scrape realtor data
Code:
```python
# Scrape realtor data
data = scrape_real_estate_agents(state="NY", city_name="buffalo", num_pages=2)
# Save to CSV
if "error" not in data:
result = export_to_csv(data)
print(result)
else:
print(f"Error: {data['error']}")
""")
- 使用DeepSeek-R1生成推理步骤。
- 动态调用抓取和保存函数。
(7)使用Gradio启动界面
GradioUI(agent).launch()
借助 Gradio 能给智能体生成一个超友好的交互界面。
通过以上步骤,利用 Smolagents 和 DeepSeek - R1 搭建功能强大的推理智能体。DeepSeek - R1 的强大之处不仅体现在所构建的这个推理智能体中,在其他场景下同样能发挥出色性能。
实际上,百度为我们提供了一个便捷体验 DeepSeek - R1 强大能力的新视角。在百度 App 中,DeepSeek - R1 被深度集成并优化,为用户带来了愉快的使用体验。
4.无惧卡顿,畅享DeepSeek
第1步:百度App输入“搜索词”,单击【AI+】
第2步:单击左下角的小鲸鱼logo
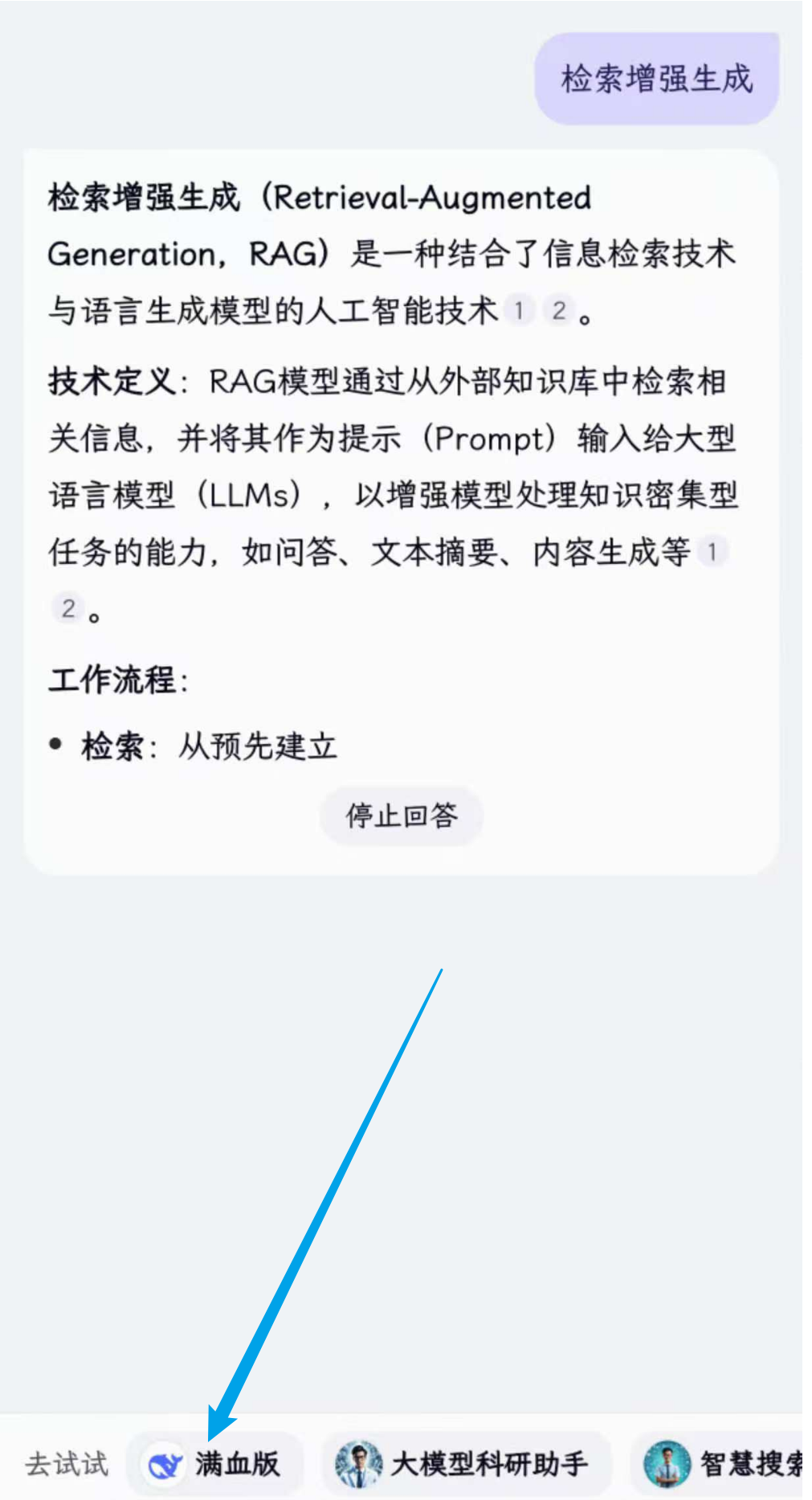
第3步:满血版DeepSeek自动开始回答
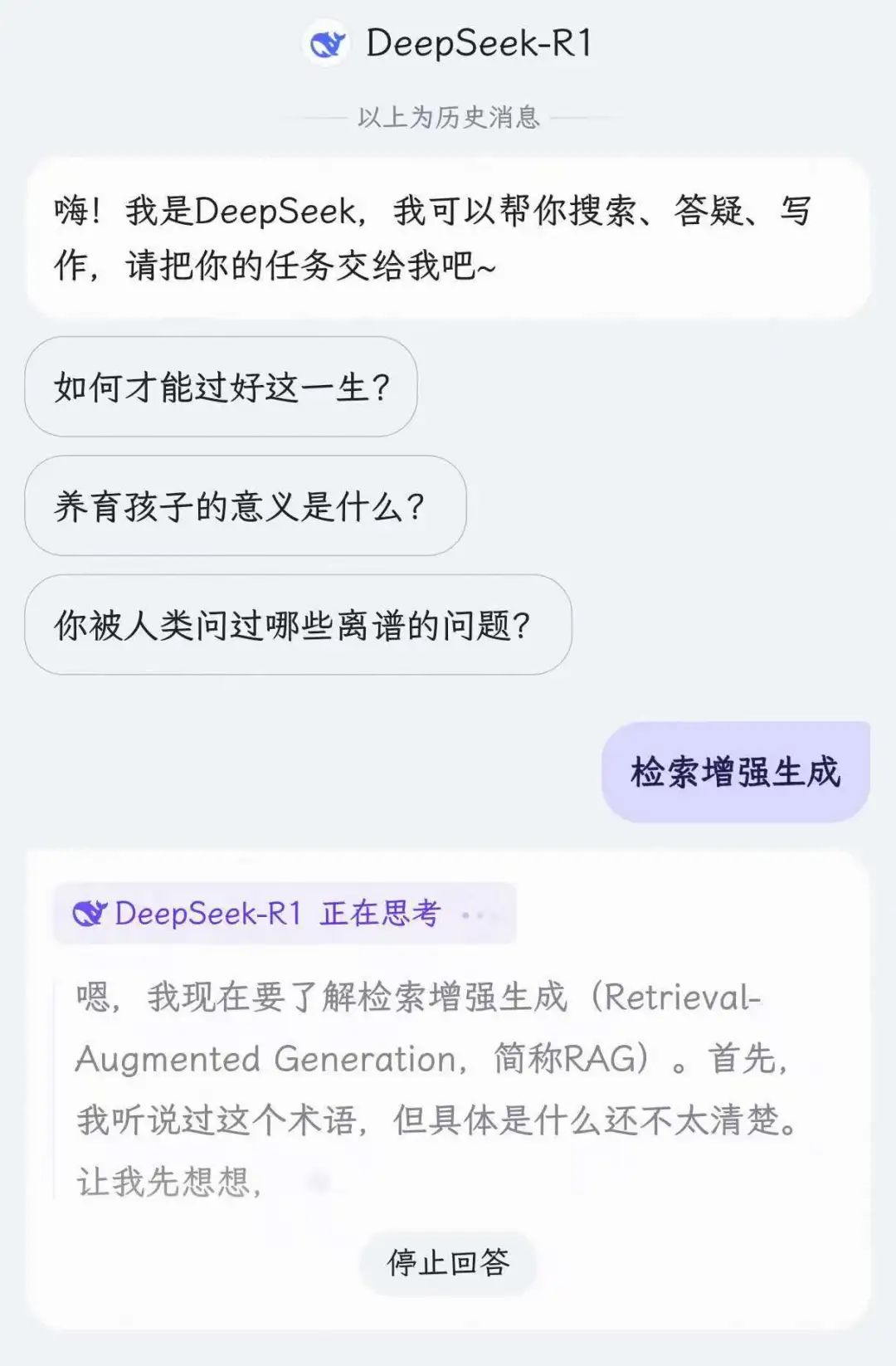
输出符合预期:

从实际输出结果看,在百度 App 的生态下,DeepSeek - R1 不仅能快速响应,给出的答案也相当精准。百度强大的平台优势与 DeepSeek - R1 的高性能相结合,让知识获取和信息分析变得更加轻松高效。
这也为我们展示了技术融合的无限可能,将技术融合运用到实际项目开发中,能够探索更多技术应用的精彩。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)