大模型评测【DeepSeek】|最新的DeepSeek-v3-0324相比旧版本提升了多少?哪方面提升最多?
DeepSeek-v3-0324总分提高了15%,算是稳步提升。而在法律和行政公务领域却有超出预期的巨幅改进,涨幅分别高达55%、41%。相比之下,在金融领域却只有3%的微小提升。
|
DeepSeek-v3首发于2024年12月底,而最新版本发布于3月24日,即DeepSeek-v3-0324。官方也给出了在主流英文评测集上的前后效果对比,如下:
那么在中文上的效果提升多少呢?我们基于8大领域(300多个细分维度)的中文评测给出回答:
更多细分维度结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark |
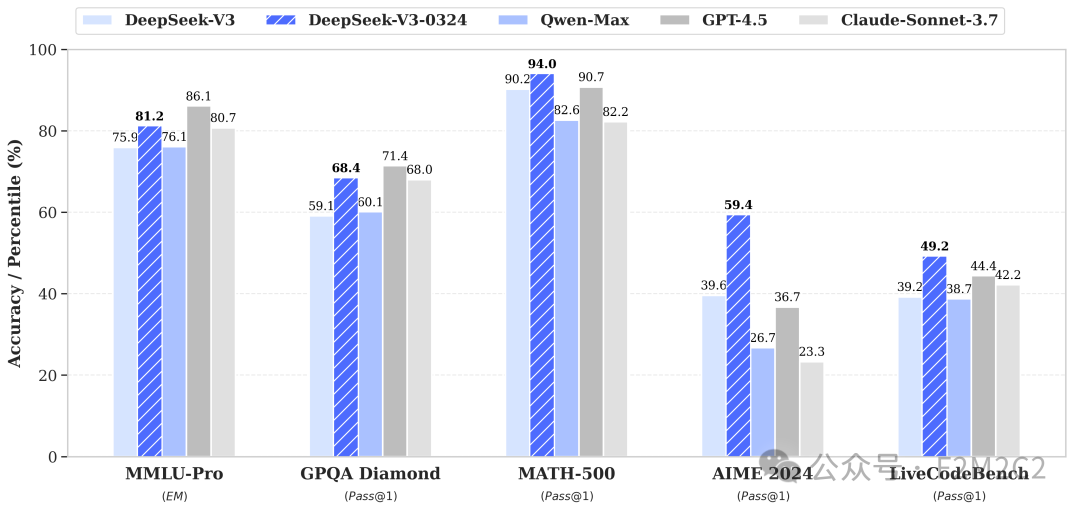
从上表可知:
-
DeepSeek-v3-0324总分提高了15%,算是稳步提升。
-
而在法律和行政公务领域却有超出预期的巨幅改进,涨幅分别高达55%、41%。
-
相比之下,在金融领域却只有3%的微小提升。
关于大模型评测EasyLLM:https://easyllm.site
-
最全——全球最全大模型评测平台,已囊括200+大模型、300+评测维度
-
最新——每周更新大模型排行榜
-
最方便——无需注册/梯子,国内外各个大模型可一键评测
-
结果可见——所有大模型评测的方法、题集、过程、得分结果,可见可追溯
-
错题本——百万级大模型错题本
-
免费——为您的私有模型提供免费的全方位评测服务,欢迎私信


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)