华为云Flexus+DeepSeek征文 | MaaS平台避坑指南:DeepSeek商用服务开通与成本控制
我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。
作者简介
我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。

目录
前言
随着大模型技术的快速发展,越来越多的企业开始将AI能力集成到自己的业务系统中。DeepSeek作为国内领先的大模型服务提供商,其强大的推理能力和相对较低的成本优势,使其成为企业级AI应用的热门选择。而华为云Flexus云服务器凭借其高性价比和稳定性,为部署AI应用提供了理想的基础设施。
本文将详细介绍如何在华为云Flexus环境下开通和使用DeepSeek的MaaS(Model as a Service)服务,并重点分享在实际使用过程中的避坑经验和成本控制策略。
一、技术架构概览
1.1 整体架构设计
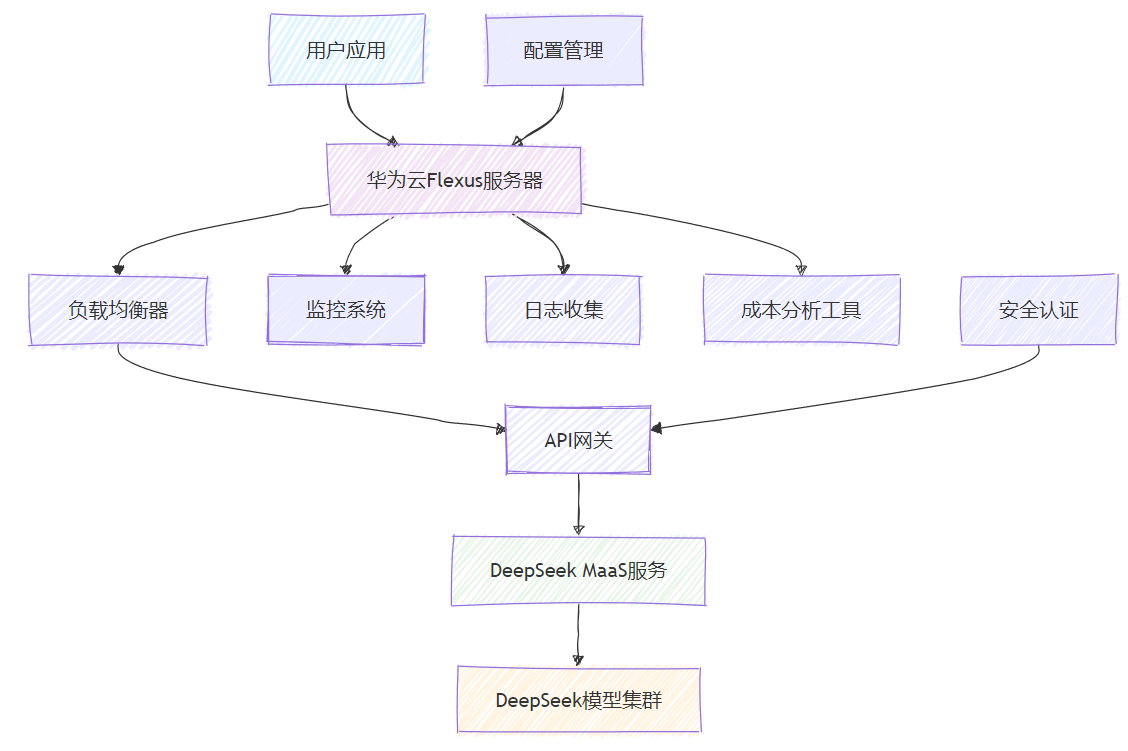
图1:华为云Flexus+DeepSeek MaaS整体架构图
1.2 核心组件说明
华为云Flexus服务器:作为应用的运行环境,提供计算资源和网络连接。
API网关:负责请求路由、认证授权、流量控制等功能。
DeepSeek MaaS服务:提供大模型推理能力,支持多种模型规格。
监控和成本控制系统:实时监控服务使用情况和成本消耗。
二、华为云Flexus环境准备
2.1 Flexus实例选择与配置
华为云Flexus云服务器提供了多种规格选择,针对AI应用场景,推荐以下配置:
开发测试环境:
- 规格:2vCPUs | 4GB内存 | 40GB云硬盘
- 操作系统:Ubuntu 22.04 LTS
- 网络:5Mbps带宽
生产环境:
- 规格:4vCPUs | 8GB内存 | 100GB云硬盘
- 操作系统:Ubuntu 22.04 LTS
- 网络:10Mbps带宽
2.2 Flexus实例创建步骤
步骤1:登录华为云控制台
访问华为云官网,登录控制台后进入Flexus云服务器产品页面。
步骤2:选择实例规格
# 创建实例时的关键配置项
实例名称: deepseek-maas-server
可用区: 就近选择(建议选择延迟较低的区域)
镜像: Ubuntu 22.04 server 64bit
实例规格: s6.large.2(2vCPUs | 4GB | 10Gbps)
系统盘: 高IO 40GB
网络配置: 默认VPC和子网
安全组: 开放80、443、22端口
步骤3:网络安全配置
创建专用安全组,配置入站规则:
# SSH访问
端口: 22, 协议: TCP, 源: 0.0.0.0/0
# HTTP服务
端口: 80, 协议: TCP, 源: 0.0.0.0/0
# HTTPS服务
端口: 443, 协议: TCP, 源: 0.0.0.0/0
# 自定义应用端口
端口: 8000, 协议: TCP, 源: 0.0.0.0/02.3 环境初始化
连接到Flexus实例后,执行以下初始化脚本:
#!/bin/bash
# Flexus环境初始化脚本
# 更新系统包
sudo apt update && sudo apt upgrade -y
# 安装基础工具
sudo apt install -y curl wget git vim htop tree
# 安装Python环境
sudo apt install -y python3 python3-pip python3-venv
# 安装Node.js(用于前端应用)
curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash -
sudo apt-get install -y nodejs
# 安装Docker(用于容器化部署)
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
# 安装Nginx(用作反向代理)
sudo apt install -y nginx
# 创建应用目录
mkdir -p ~/deepseek-maas-app
cd ~/deepseek-maas-app
echo "华为云Flexus环境初始化完成!"三、DeepSeek MaaS服务开通详解
3.1 DeepSeek账户注册与认证
步骤1:访问DeepSeek官网
访问DeepSeek官方网站,点击注册按钮创建账户。
步骤2:完成实名认证
# 企业认证所需材料
1. 营业执照副本
2. 法人身份证明
3. 企业邮箱验证
4. 银行账户信息(用于付费)
# 个人认证所需材料
1. 身份证正反面照片
2. 手机号验证
3. 邮箱验证
4. 支付方式绑定
步骤3:获取API密钥
认证完成后,进入控制台 → API管理 → 创建API Key:
3.2 模型服务选择与配置
DeepSeek提供多种模型规格,根据业务需求选择合适的模型:
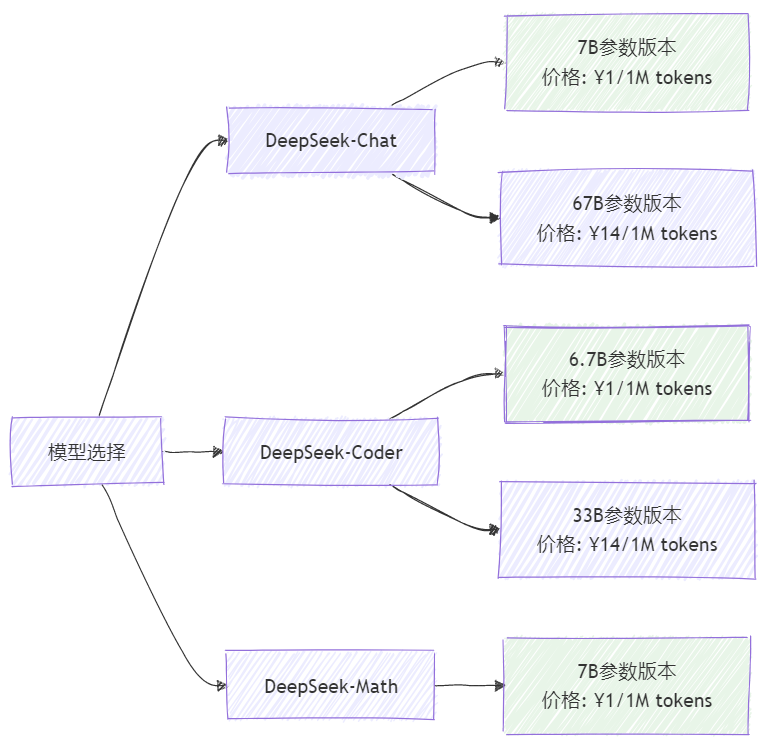
图2:DeepSeek模型选择与定价结构图
模型特性对比
|
模型类型 |
参数规模 |
适用场景 |
处理速度 |
成本 |
|
DeepSeek-Chat-7B |
70亿 |
通用对话、文本生成 |
快 |
低 |
|
DeepSeek-Chat-67B |
670亿 |
复杂推理、专业问答 |
中 |
高 |
|
DeepSeek-Coder-6.7B |
67亿 |
代码生成、调试 |
快 |
低 |
|
DeepSeek-Math-7B |
70亿 |
数学计算、逻辑推理 |
快 |
低 |
3.3 服务开通配置
步骤1:创建项目和配置限额
# 项目配置脚本
import requests
import json
def create_deepseek_project():
"""
创建DeepSeek项目并配置基本参数
"""
config = {
"project_name": "MaaS-Production",
"description": "华为云Flexus生产环境DeepSeek服务",
"models": ["deepseek-chat", "deepseek-coder"],
"rate_limits": {
"requests_per_minute": 100,
"tokens_per_minute": 200000,
"concurrent_requests": 10
},
"cost_controls": {
"daily_limit": 100.0, # 每日消费限额(元)
"monthly_limit": 2000.0, # 每月消费限额(元)
"alert_threshold": 0.8 # 告警阈值(80%)
}
}
return config
# 执行项目创建
project_config = create_deepseek_project()
print("项目配置:", json.dumps(project_config, indent=2, ensure_ascii=False))步骤2:配置监控和告警
# 监控告警配置
def setup_monitoring():
"""
配置DeepSeek服务监控和告警
"""
monitoring_config = {
"metrics": [
"request_count", # 请求数量
"token_usage", # Token使用量
"response_time", # 响应时间
"error_rate", # 错误率
"cost_consumption" # 成本消耗
],
"alerts": [
{
"name": "成本告警",
"condition": "daily_cost > daily_limit * 0.8",
"action": "email_notification"
},
{
"name": "流量告警",
"condition": "request_rate > rate_limit * 0.9",
"action": "throttle_requests"
},
{
"name": "错误告警",
"condition": "error_rate > 0.05",
"action": "email_notification"
}
]
}
return monitoring_config
monitoring = setup_monitoring()
print("监控配置:", json.dumps(monitoring, indent=2, ensure_ascii=False))四、API集成与调用实践
4.1 Python SDK集成
创建DeepSeek API调用的Python封装类:
import asyncio
import aiohttp
import time
import logging
from typing import Dict, List, Optional, AsyncGenerator
from dataclasses import dataclass
@dataclass
class DeepSeekConfig:
"""DeepSeek配置类"""
api_key: str
base_url: str = "https://api.deepseek.com"
model: str = "deepseek-chat"
max_tokens: int = 4096
temperature: float = 0.7
timeout: int = 30
class DeepSeekClient:
"""DeepSeek API客户端"""
def __init__(self, config: DeepSeekConfig):
self.config = config
self.session = None
self.logger = logging.getLogger(__name__)
# 请求统计
self.request_count = 0
self.total_tokens = 0
self.total_cost = 0.0
async def __aenter__(self):
"""异步上下文管理器入口"""
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=self.config.timeout),
headers={
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
)
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
"""异步上下文管理器出口"""
if self.session:
await self.session.close()
async def chat_completion(
self,
messages: List[Dict],
stream: bool = False,
**kwargs
) -> Dict:
"""
发送聊天完成请求
Args:
messages: 消息列表
stream: 是否使用流式响应
**kwargs: 其他参数
Returns:
API响应结果
"""
url = f"{self.config.base_url}/v1/chat/completions"
payload = {
"model": self.config.model,
"messages": messages,
"max_tokens": self.config.max_tokens,
"temperature": self.config.temperature,
"stream": stream,
**kwargs
}
try:
start_time = time.time()
async with self.session.post(url, json=payload) as response:
if response.status == 200:
result = await response.json()
# 统计信息更新
self.request_count += 1
if 'usage' in result:
tokens_used = result['usage']['total_tokens']
self.total_tokens += tokens_used
self.total_cost += self._calculate_cost(tokens_used)
elapsed_time = time.time() - start_time
self.logger.info(
f"请求完成: 耗时{elapsed_time:.2f}s, "
f"Token使用: {result.get('usage', {}).get('total_tokens', 0)}"
)
return result
else:
error_msg = await response.text()
self.logger.error(f"API请求失败: {response.status} - {error_msg}")
raise Exception(f"API Error: {response.status}")
except asyncio.TimeoutError:
self.logger.error("API请求超时")
raise Exception("请求超时")
except Exception as e:
self.logger.error(f"API请求异常: {str(e)}")
raise
async def stream_chat_completion(
self,
messages: List[Dict],
**kwargs
) -> AsyncGenerator[Dict, None]:
"""
流式聊天完成请求
Args:
messages: 消息列表
**kwargs: 其他参数
Yields:
流式响应数据块
"""
url = f"{self.config.base_url}/v1/chat/completions"
payload = {
"model": self.config.model,
"messages": messages,
"max_tokens": self.config.max_tokens,
"temperature": self.config.temperature,
"stream": True,
**kwargs
}
try:
async with self.session.post(url, json=payload) as response:
if response.status == 200:
async for line in response.content:
if line:
line_str = line.decode('utf-8').strip()
if line_str.startswith('data: '):
data_str = line_str[6:]
if data_str != '[DONE]':
try:
chunk = json.loads(data_str)
yield chunk
except json.JSONDecodeError:
continue
else:
error_msg = await response.text()
self.logger.error(f"流式请求失败: {response.status} - {error_msg}")
raise Exception(f"Stream API Error: {response.status}")
except Exception as e:
self.logger.error(f"流式请求异常: {str(e)}")
raise
def _calculate_cost(self, tokens: int) -> float:
"""
计算Token使用成本
Args:
tokens: 使用的Token数量
Returns:
成本金额(元)
"""
# DeepSeek-Chat 7B模型定价:1元/1M tokens
if self.config.model.startswith("deepseek-chat"):
if "67b" in self.config.model.lower():
price_per_million = 14.0 # 67B模型定价
else:
price_per_million = 1.0 # 7B模型定价
elif self.config.model.startswith("deepseek-coder"):
if "33b" in self.config.model.lower():
price_per_million = 14.0 # 33B模型定价
else:
price_per_million = 1.0 # 6.7B模型定价
else:
price_per_million = 1.0 # 默认定价
return (tokens / 1_000_000) * price_per_million
def get_statistics(self) -> Dict:
"""获取使用统计信息"""
return {
"request_count": self.request_count,
"total_tokens": self.total_tokens,
"total_cost": round(self.total_cost, 4),
"average_tokens_per_request": (
self.total_tokens / self.request_count
if self.request_count > 0 else 0
)
}
# 使用示例
async def main():
"""使用示例"""
config = DeepSeekConfig(
api_key="sk-your-api-key-here",
model="deepseek-chat",
max_tokens=2048,
temperature=0.7
)
async with DeepSeekClient(config) as client:
# 普通聊天请求
messages = [
{"role": "system", "content": "你是一个有用的AI助手。"},
{"role": "user", "content": "请介绍一下华为云Flexus的优势。"}
]
response = await client.chat_completion(messages)
print("响应:", response['choices'][0]['message']['content'])
# 流式聊天请求
print("\n流式响应:")
async for chunk in client.stream_chat_completion(messages):
if 'choices' in chunk and chunk['choices']:
delta = chunk['choices'][0].get('delta', {})
if 'content' in delta:
print(delta['content'], end='', flush=True)
# 打印统计信息
stats = client.get_statistics()
print(f"\n\n使用统计: {stats}")
if __name__ == "__main__":
asyncio.run(main())
4.2 Web应用集成示例
使用FastAPI创建Web服务,集成DeepSeek API:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Optional
import asyncio
import uvicorn
import os
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = FastAPI(
title="DeepSeek MaaS API服务",
description="基于华为云Flexus的DeepSeek API集成服务",
version="1.0.0"
)
# 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 请求模型
class ChatRequest(BaseModel):
messages: List[dict]
model: Optional[str] = "deepseek-chat"
max_tokens: Optional[int] = 2048
temperature: Optional[float] = 0.7
stream: Optional[bool] = False
class ChatResponse(BaseModel):
content: str
usage: dict
cost: float
# 全局DeepSeek客户端
deepseek_client = None
@app.on_event("startup")
async def startup_event():
"""应用启动时初始化DeepSeek客户端"""
global deepseek_client
config = DeepSeekConfig(
api_key=os.getenv("DEEPSEEK_API_KEY", "your-api-key"),
model="deepseek-chat",
max_tokens=4096,
temperature=0.7
)
deepseek_client = DeepSeekClient(config)
await deepseek_client.__aenter__()
logger.info("DeepSeek客户端初始化完成")
@app.on_event("shutdown")
async def shutdown_event():
"""应用关闭时清理资源"""
global deepseek_client
if deepseek_client:
await deepseek_client.__aexit__(None, None, None)
logger.info("DeepSeek客户端已关闭")
@app.post("/chat/completions", response_model=ChatResponse)
async def chat_completions(request: ChatRequest):
"""
聊天完成API接口
"""
try:
if not deepseek_client:
raise HTTPException(status_code=500, detail="DeepSeek客户端未初始化")
# 调用DeepSeek API
response = await deepseek_client.chat_completion(
messages=request.messages,
model=request.model,
max_tokens=request.max_tokens,
temperature=request.temperature,
stream=request.stream
)
# 提取响应内容
content = response['choices'][0]['message']['content']
usage = response.get('usage', {})
# 计算成本
tokens_used = usage.get('total_tokens', 0)
cost = deepseek_client._calculate_cost(tokens_used)
return ChatResponse(
content=content,
usage=usage,
cost=cost
)
except Exception as e:
logger.error(f"聊天完成请求失败: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
@app.get("/statistics")
async def get_statistics():
"""
获取使用统计信息
"""
if not deepseek_client:
raise HTTPException(status_code=500, detail="DeepSeek客户端未初始化")
stats = deepseek_client.get_statistics()
return {
"status": "success",
"data": stats
}
@app.get("/health")
async def health_check():
"""
健康检查接口
"""
return {"status": "healthy", "service": "deepseek-maas-api"}
if __name__ == "__main__":
uvicorn.run(
"main:app",
host="0.0.0.0",
port=8000,
reload=True,
log_level="info"
)
4.3 前端集成示例
创建简单的Web界面与后端API交互:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>DeepSeek MaaS 聊天界面</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', sans-serif;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
min-height: 100vh;
display: flex;
align-items: center;
justify-content: center;
}
.chat-container {
width: 800px;
height: 600px;
background: white;
border-radius: 15px;
box-shadow: 0 20px 40px rgba(0,0,0,0.1);
display: flex;
flex-direction: column;
overflow: hidden;
}
.chat-header {
background: #667eea;
color: white;
padding: 20px;
text-align: center;
}
.chat-messages {
flex: 1;
padding: 20px;
overflow-y: auto;
background: #f8f9fa;
}
.message {
margin-bottom: 15px;
padding: 12px 16px;
border-radius: 12px;
max-width: 80%;
word-wrap: break-word;
}
.user-message {
background: #007bff;
color: white;
margin-left: auto;
}
.bot-message {
background: white;
color: #333;
border: 1px solid #e9ecef;
}
.chat-input {
display: flex;
padding: 20px;
background: white;
border-top: 1px solid #e9ecef;
}
.input-field {
flex: 1;
padding: 12px 16px;
border: 1px solid #ddd;
border-radius: 25px;
font-size: 14px;
outline: none;
}
.send-button {
margin-left: 10px;
padding: 12px 24px;
background: #007bff;
color: white;
border: none;
border-radius: 25px;
cursor: pointer;
font-size: 14px;
transition: background 0.3s;
}
.send-button:hover {
background: #0056b3;
}
.send-button:disabled {
background: #6c757d;
cursor: not-allowed;
}
.stats-panel {
padding: 10px 20px;
background: #e9ecef;
font-size: 12px;
color: #6c757d;
border-top: 1px solid #dee2e6;
}
.loading {
display: inline-block;
width: 20px;
height: 20px;
border: 3px solid #f3f3f3;
border-top: 3px solid #007bff;
border-radius: 50%;
animation: spin 1s linear infinite;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
</style>
</head>
<body>
<div class="chat-container">
<div class="chat-header">
<h2>DeepSeek MaaS 智能助手</h2>
<p>基于华为云Flexus云服务器部署</p>
</div>
<div class="chat-messages" id="chatMessages">
<div class="message bot-message">
👋 您好!我是DeepSeek智能助手,有什么可以帮助您的吗?
</div>
</div>
<div class="stats-panel" id="statsPanel">
请求次数: 0 | 总Token: 0 | 总成本: ¥0.00
</div>
<div class="chat-input">
<input
type="text"
class="input-field"
id="messageInput"
placeholder="输入您的问题..."
onkeypress="handleKeyPress(event)"
>
<button class="send-button" id="sendButton" onclick="sendMessage()">
发送
</button>
</div>
</div>
<script>
const API_BASE_URL = 'http://localhost:8000';
let requestCount = 0;
let totalTokens = 0;
let totalCost = 0;
// 处理键盘事件
function handleKeyPress(event) {
if (event.key === 'Enter') {
sendMessage();
}
}
// 发送消息
async function sendMessage() {
const input = document.getElementById('messageInput');
const message = input.value.trim();
if (!message) return;
// 显示用户消息
addMessage(message, 'user');
input.value = '';
// 禁用发送按钮
const sendButton = document.getElementById('sendButton');
sendButton.disabled = true;
sendButton.innerHTML = '<div class="loading"></div>';
// 显示加载消息
const loadingId = addMessage('正在思考中...', 'bot');
try {
// 调用API
const response = await fetch(`${API_BASE_URL}/chat/completions`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
messages: [
{ role: 'user', content: message }
],
model: 'deepseek-chat',
max_tokens: 2048,
temperature: 0.7
})
});
if (!response.ok) {
throw new Error(`HTTP错误: ${response.status}`);
}
const data = await response.json();
// 移除加载消息
removeMessage(loadingId);
// 显示AI回复
addMessage(data.content, 'bot');
// 更新统计信息
requestCount++;
totalTokens += data.usage.total_tokens || 0;
totalCost += data.cost || 0;
updateStats();
} catch (error) {
console.error('API调用失败:', error);
removeMessage(loadingId);
addMessage('抱歉,服务暂时不可用,请稍后重试。', 'bot');
} finally {
// 恢复发送按钮
sendButton.disabled = false;
sendButton.innerHTML = '发送';
}
}
// 添加消息到聊天界面
function addMessage(content, type) {
const messagesContainer = document.getElementById('chatMessages');
const messageDiv = document.createElement('div');
const messageId = `msg-${Date.now()}-${Math.random()}`;
messageDiv.id = messageId;
messageDiv.className = `message ${type}-message`;
messageDiv.textContent = content;
messagesContainer.appendChild(messageDiv);
messagesContainer.scrollTop = messagesContainer.scrollHeight;
return messageId;
}
// 移除消息
function removeMessage(messageId) {
const messageElement = document.getElementById(messageId);
if (messageElement) {
messageElement.remove();
}
}
// 更新统计信息
function updateStats() {
const statsPanel = document.getElementById('statsPanel');
statsPanel.textContent =
`请求次数: ${requestCount} | 总Token: ${totalTokens} | 总成本: ¥${totalCost.toFixed(4)}`;
}
// 定期更新统计信息
setInterval(async () => {
try {
const response = await fetch(`${API_BASE_URL}/statistics`);
if (response.ok) {
const data = await response.json();
if (data.status === 'success') {
requestCount = data.data.request_count;
totalTokens = data.data.total_tokens;
totalCost = data.data.total_cost;
updateStats();
}
}
} catch (error) {
console.error('获取统计信息失败:', error);
}
}, 30000); // 每30秒更新一次
</script>
</body>
</html>
五、成本控制与优化策略
5.1 成本监控系统
建立完善的成本监控和告警机制:
import asyncio
import json
import smtplib
from datetime import datetime, timedelta
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from typing import Dict, List
import sqlite3
class CostMonitor:
"""成本监控系统"""
def __init__(self, db_path: str = "cost_monitor.db"):
self.db_path = db_path
self.init_database()
# 成本限制配置
self.cost_limits = {
"daily_limit": 100.0, # 日限额(元)
"weekly_limit": 500.0, # 周限额(元)
"monthly_limit": 2000.0, # 月限额(元)
"alert_threshold": 0.8 # 告警阈值(80%)
}
# 邮件配置
self.email_config = {
"smtp_server": "smtp.163.com",
"smtp_port": 587,
"username": "your_email@163.com",
"password": "your_app_password",
"to_emails": ["admin@yourcompany.com"]
}
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 创建使用记录表
cursor.execute('''
CREATE TABLE IF NOT EXISTS usage_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP,
model_name TEXT NOT NULL,
request_tokens INTEGER DEFAULT 0,
response_tokens INTEGER DEFAULT 0,
total_tokens INTEGER DEFAULT 0,
cost REAL DEFAULT 0.0,
user_id TEXT,
request_id TEXT,
response_time REAL DEFAULT 0.0
)
''')
# 创建告警记录表
cursor.execute('''
CREATE TABLE IF NOT EXISTS alert_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP,
alert_type TEXT NOT NULL,
message TEXT NOT NULL,
threshold_value REAL,
actual_value REAL,
status TEXT DEFAULT 'active'
)
''')
conn.commit()
conn.close()
def record_usage(
self,
model_name: str,
request_tokens: int,
response_tokens: int,
cost: float,
user_id: str = None,
request_id: str = None,
response_time: float = 0.0
):
"""记录使用情况"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
total_tokens = request_tokens + response_tokens
cursor.execute('''
INSERT INTO usage_records
(model_name, request_tokens, response_tokens, total_tokens,
cost, user_id, request_id, response_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
''', (model_name, request_tokens, response_tokens, total_tokens,
cost, user_id, request_id, response_time))
conn.commit()
conn.close()
# 检查是否需要告警
asyncio.create_task(self.check_cost_alerts())
async def check_cost_alerts(self):
"""检查成本告警"""
current_costs = self.get_period_costs()
alerts = []
# 检查日限额
if current_costs['daily'] > self.cost_limits['daily_limit'] * self.cost_limits['alert_threshold']:
alerts.append({
'type': 'daily_cost_alert',
'message': f"日成本已达到 {current_costs['daily']:.2f} 元,超过告警阈值",
'threshold': self.cost_limits['daily_limit'] * self.cost_limits['alert_threshold'],
'actual': current_costs['daily']
})
# 检查周限额
if current_costs['weekly'] > self.cost_limits['weekly_limit'] * self.cost_limits['alert_threshold']:
alerts.append({
'type': 'weekly_cost_alert',
'message': f"周成本已达到 {current_costs['weekly']:.2f} 元,超过告警阈值",
'threshold': self.cost_limits['weekly_limit'] * self.cost_limits['alert_threshold'],
'actual': current_costs['weekly']
})
# 检查月限额
if current_costs['monthly'] > self.cost_limits['monthly_limit'] * self.cost_limits['alert_threshold']:
alerts.append({
'type': 'monthly_cost_alert',
'message': f"月成本已达到 {current_costs['monthly']:.2f} 元,超过告警阈值",
'threshold': self.cost_limits['monthly_limit'] * self.cost_limits['alert_threshold'],
'actual': current_costs['monthly']
})
# 发送告警
for alert in alerts:
await self.send_alert(alert)
def get_period_costs(self) -> Dict[str, float]:
"""获取各时间段的成本统计"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
now = datetime.now()
# 今日成本
today_start = now.replace(hour=0, minute=0, second=0, microsecond=0)
cursor.execute('''
SELECT COALESCE(SUM(cost), 0)
FROM usage_records
WHERE timestamp >= ?
''', (today_start,))
daily_cost = cursor.fetchone()[0]
# 本周成本
week_start = now - timedelta(days=now.weekday())
week_start = week_start.replace(hour=0, minute=0, second=0, microsecond=0)
cursor.execute('''
SELECT COALESCE(SUM(cost), 0)
FROM usage_records
WHERE timestamp >= ?
''', (week_start,))
weekly_cost = cursor.fetchone()[0]
# 本月成本
month_start = now.replace(day=1, hour=0, minute=0, second=0, microsecond=0)
cursor.execute('''
SELECT COALESCE(SUM(cost), 0)
FROM usage_records
WHERE timestamp >= ?
''', (month_start,))
monthly_cost = cursor.fetchone()[0]
conn.close()
return {
'daily': daily_cost,
'weekly': weekly_cost,
'monthly': monthly_cost
}
async def send_alert(self, alert: Dict):
"""发送告警邮件"""
# 记录告警
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute('''
INSERT INTO alert_records
(alert_type, message, threshold_value, actual_value)
VALUES (?, ?, ?, ?)
''', (alert['type'], alert['message'],
alert['threshold'], alert['actual']))
conn.commit()
conn.close()
# 发送邮件告警
try:
msg = MIMEMultipart()
msg['From'] = self.email_config['username']
msg['To'] = ', '.join(self.email_config['to_emails'])
msg['Subject'] = f"DeepSeek MaaS 成本告警 - {alert['type']}"
body = f"""
<html>
<body>
<h2>DeepSeek MaaS 成本告警</h2>
<p><strong>告警类型:</strong> {alert['type']}</p>
<p><strong>告警信息:</strong> {alert['message']}</p>
<p><strong>告警阈值:</strong> {alert['threshold']:.2f} 元</p>
<p><strong>当前值:</strong> {alert['actual']:.2f} 元</p>
<p><strong>时间:</strong> {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}</p>
<h3>建议措施:</h3>
<ul>
<li>检查当前的API调用频率</li>
<li>优化请求参数,减少不必要的Token消耗</li>
<li>考虑使用较小的模型处理简单任务</li>
<li>设置更严格的请求限制</li>
</ul>
</body>
</html>
"""
msg.attach(MIMEText(body, 'html'))
server = smtplib.SMTP(self.email_config['smtp_server'], self.email_config['smtp_port'])
server.starttls()
server.login(self.email_config['username'], self.email_config['password'])
text = msg.as_string()
server.sendmail(
self.email_config['username'],
self.email_config['to_emails'],
text
)
server.quit()
print(f"告警邮件已发送: {alert['type']}")
except Exception as e:
print(f"发送告警邮件失败: {str(e)}")
def get_cost_report(self, days: int = 30) -> Dict:
"""生成成本报告"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
start_date = datetime.now() - timedelta(days=days)
# 总体统计
cursor.execute('''
SELECT
COUNT(*) as total_requests,
SUM(total_tokens) as total_tokens,
SUM(cost) as total_cost,
AVG(cost) as avg_cost_per_request,
AVG(response_time) as avg_response_time
FROM usage_records
WHERE timestamp >= ?
''', (start_date,))
overall_stats = cursor.fetchone()
# 按模型统计
cursor.execute('''
SELECT
model_name,
COUNT(*) as requests,
SUM(total_tokens) as tokens,
SUM(cost) as cost,
AVG(response_time) as avg_response_time
FROM usage_records
WHERE timestamp >= ?
GROUP BY model_name
ORDER BY cost DESC
''', (start_date,))
model_stats = cursor.fetchall()
# 按日期统计
cursor.execute('''
SELECT
DATE(timestamp) as date,
COUNT(*) as requests,
SUM(total_tokens) as tokens,
SUM(cost) as cost
FROM usage_records
WHERE timestamp >= ?
GROUP BY DATE(timestamp)
ORDER BY date DESC
''', (start_date,))
daily_stats = cursor.fetchall()
conn.close()
return {
'period': f"最近{days}天",
'overall': {
'total_requests': overall_stats[0] or 0,
'total_tokens': overall_stats[1] or 0,
'total_cost': overall_stats[2] or 0.0,
'avg_cost_per_request': overall_stats[3] or 0.0,
'avg_response_time': overall_stats[4] or 0.0
},
'by_model': [
{
'model_name': row[0],
'requests': row[1],
'tokens': row[2],
'cost': row[3],
'avg_response_time': row[4]
}
for row in model_stats
],
'daily_trend': [
{
'date': row[0],
'requests': row[1],
'tokens': row[2],
'cost': row[3]
}
for row in daily_stats
]
}
# 使用示例
async def main():
"""成本监控使用示例"""
monitor = CostMonitor()
# 模拟记录使用情况
monitor.record_usage(
model_name="deepseek-chat",
request_tokens=100,
response_tokens=200,
cost=0.0003,
user_id="user123",
request_id="req456",
response_time=1.5
)
# 获取成本报告
report = monitor.get_cost_report(days=7)
print("成本报告:", json.dumps(report, indent=2, ensure_ascii=False))
# 获取当前成本
current_costs = monitor.get_period_costs()
print("当前成本:", current_costs)
if __name__ == "__main__":
asyncio.run(main())
5.2 Token使用优化
class TokenOptimizer:
"""Token使用优化器"""
def __init__(self):
self.prompt_templates = {
'summarize': "请用{max_words}字以内总结以下内容:\n{content}",
'translate': "请将以下{source_lang}文本翻译为{target_lang}:\n{content}",
'qa': "问题:{question}\n请基于以下上下文回答:\n{context}",
'code_review': "请对以下代码进行审查,重点关注{focus_areas}:\n```{language}\n{code}\n```"
}
def optimize_prompt(self, task_type: str, **kwargs) -> str:
"""
优化提示词,减少不必要的Token消耗
Args:
task_type: 任务类型
**kwargs: 任务参数
Returns:
优化后的提示词
"""
if task_type not in self.prompt_templates:
raise ValueError(f"不支持的任务类型: {task_type}")
template = self.prompt_templates[task_type]
# 根据不同任务类型进行优化
if task_type == 'summarize':
content = kwargs.get('content', '')
max_words = kwargs.get('max_words', 100)
# 如果内容过长,先进行预处理
if len(content) > 2000:
content = self._preprocess_long_content(content)
return template.format(max_words=max_words, content=content)
elif task_type == 'translate':
content = kwargs.get('content', '')
source_lang = kwargs.get('source_lang', '中文')
target_lang = kwargs.get('target_lang', '英文')
# 分段翻译长文本
if len(content) > 1000:
return self._create_batch_translation_prompt(content, source_lang, target_lang)
return template.format(
source_lang=source_lang,
target_lang=target_lang,
content=content
)
elif task_type == 'qa':
question = kwargs.get('question', '')
context = kwargs.get('context', '')
# 智能截断上下文
if len(context) > 1500:
context = self._smart_truncate_context(context, question)
return template.format(question=question, context=context)
elif task_type == 'code_review':
code = kwargs.get('code', '')
language = kwargs.get('language', 'python')
focus_areas = kwargs.get('focus_areas', '性能、安全性、可读性')
return template.format(
focus_areas=focus_areas,
language=language,
code=code
)
return template.format(**kwargs)
def _preprocess_long_content(self, content: str, max_length: int = 1500) -> str:
"""预处理长内容"""
if len(content) <= max_length:
return content
# 按段落分割
paragraphs = content.split('\n\n')
# 保留重要段落
processed_content = ""
current_length = 0
for paragraph in paragraphs:
if current_length + len(paragraph) <= max_length:
processed_content += paragraph + '\n\n'
current_length += len(paragraph)
else:
break
if current_length < max_length // 2:
# 如果内容太少,直接截断
return content[:max_length] + "..."
return processed_content.strip()
def _create_batch_translation_prompt(
self,
content: str,
source_lang: str,
target_lang: str
) -> str:
"""创建分批翻译提示词"""
return f"""请将以下{source_lang}文本翻译为{target_lang},保持原有格式:
{content[:1000]}
注意:
1. 保持专业术语的准确性
2. 保持原文的语气和风格
3. 如有歧义,选择最合适的翻译"""
def _smart_truncate_context(self, context: str, question: str) -> str:
"""智能截断上下文"""
# 简单的关键词匹配截断策略
question_keywords = set(question.lower().split())
sentences = context.split('。')
scored_sentences = []
for sentence in sentences:
sentence_words = set(sentence.lower().split())
score = len(question_keywords.intersection(sentence_words))
scored_sentences.append((score, sentence))
# 按分数排序,保留最相关的句子
scored_sentences.sort(key=lambda x: x[0], reverse=True)
result = ""
current_length = 0
max_length = 1500
for score, sentence in scored_sentences:
if current_length + len(sentence) <= max_length:
result += sentence + '。'
current_length += len(sentence)
else:
break
return result.strip()
def estimate_tokens(self, text: str) -> int:
"""
估算文本的Token数量
中文:约1.5个字符=1个Token
英文:约4个字符=1个Token
"""
chinese_chars = len([char for char in text if '\u4e00' <= char <= '\u9fff'])
english_chars = len(text) - chinese_chars
estimated_tokens = (chinese_chars / 1.5) + (english_chars / 4)
return int(estimated_tokens)
def calculate_cost(self, tokens: int, model: str = "deepseek-chat") -> float:
"""计算Token成本"""
if "67b" in model.lower() or "33b" in model.lower():
price_per_million = 14.0
else:
price_per_million = 1.0
return (tokens / 1_000_000) * price_per_million
# 使用示例
def demo_token_optimization():
"""Token优化演示"""
optimizer = TokenOptimizer()
# 总结任务优化
long_content = "这是一段很长的文本内容..." * 100
optimized_prompt = optimizer.optimize_prompt(
'summarize',
content=long_content,
max_words=50
)
print("优化后的总结提示词:")
print(optimized_prompt[:200] + "...")
# 估算Token使用量
estimated_tokens = optimizer.estimate_tokens(optimized_prompt)
estimated_cost = optimizer.calculate_cost(estimated_tokens)
print(f"估算Token数量: {estimated_tokens}")
print(f"估算成本: ¥{estimated_cost:.6f}")
if __name__ == "__main__":
demo_token_optimization()
5.3 请求频率控制
import asyncio
import time
from collections import deque
from typing import Optional
class RateLimiter:
"""请求频率限制器"""
def __init__(
self,
max_requests_per_minute: int = 60,
max_tokens_per_minute: int = 150000,
max_concurrent_requests: int = 10
):
self.max_requests_per_minute = max_requests_per_minute
self.max_tokens_per_minute = max_tokens_per_minute
self.max_concurrent_requests = max_concurrent_requests
# 请求时间记录
self.request_times = deque()
self.token_usage_times = deque()
# 并发控制
self.concurrent_semaphore = asyncio.Semaphore(max_concurrent_requests)
self.current_requests = 0
# 锁对象
self._lock = asyncio.Lock()
async def acquire(self, estimated_tokens: int = 1000) -> bool:
"""
获取请求许可
Args:
estimated_tokens: 预估Token使用量
Returns:
是否获得许可
"""
async with self._lock:
current_time = time.time()
# 清理过期记录
self._cleanup_old_records(current_time)
# 检查请求频率限制
if len(self.request_times) >= self.max_requests_per_minute:
return False
# 检查Token使用限制
current_token_usage = sum(
tokens for _, tokens in self.token_usage_times
)
if current_token_usage + estimated_tokens > self.max_tokens_per_minute:
return False
# 检查并发限制
if self.current_requests >= self.max_concurrent_requests:
return False
# 记录请求
self.request_times.append(current_time)
self.token_usage_times.append((current_time, estimated_tokens))
self.current_requests += 1
return True
async def release(self, actual_tokens: int = 0):
"""
释放请求许可
Args:
actual_tokens: 实际使用的Token数量
"""
async with self._lock:
self.current_requests = max(0, self.current_requests - 1)
# 更新实际Token使用量
if actual_tokens > 0 and self.token_usage_times:
last_time, estimated_tokens = self.token_usage_times[-1]
self.token_usage_times[-1] = (last_time, actual_tokens)
def _cleanup_old_records(self, current_time: float):
"""清理过期记录"""
minute_ago = current_time - 60
# 清理请求时间记录
while self.request_times and self.request_times[0] < minute_ago:
self.request_times.popleft()
# 清理Token使用记录
while self.token_usage_times and self.token_usage_times[0][0] < minute_ago:
self.token_usage_times.popleft()
async def wait_if_needed(self, estimated_tokens: int = 1000) -> float:
"""
如果需要等待,返回等待时间
Args:
estimated_tokens: 预估Token使用量
Returns:
等待时间(秒)
"""
while True:
if await self.acquire(estimated_tokens):
return 0.0
# 计算需要等待的时间
current_time = time.time()
self._cleanup_old_records(current_time)
wait_time = 0.0
# 检查请求频率
if len(self.request_times) >= self.max_requests_per_minute:
oldest_request = self.request_times[0]
wait_time = max(wait_time, oldest_request + 60 - current_time)
# 检查Token限制
current_token_usage = sum(
tokens for _, tokens in self.token_usage_times
)
if current_token_usage + estimated_tokens > self.max_tokens_per_minute:
if self.token_usage_times:
oldest_token_time = self.token_usage_times[0][0]
wait_time = max(wait_time, oldest_token_time + 60 - current_time)
if wait_time > 0:
await asyncio.sleep(min(wait_time, 1.0)) # 最多等待1秒再检查
else:
await asyncio.sleep(0.1) # 短暂等待
# 集成到DeepSeek客户端中
class RateLimitedDeepSeekClient(DeepSeekClient):
"""带频率限制的DeepSeek客户端"""
def __init__(self, config: DeepSeekConfig, rate_limiter: RateLimiter):
super().__init__(config)
self.rate_limiter = rate_limiter
self.token_optimizer = TokenOptimizer()
async def chat_completion(
self,
messages: List[Dict],
stream: bool = False,
**kwargs
) -> Dict:
"""
带频率限制的聊天完成请求
"""
# 估算Token使用量
prompt_text = "\n".join([msg.get('content', '') for msg in messages])
estimated_tokens = self.token_optimizer.estimate_tokens(prompt_text)
estimated_tokens += kwargs.get('max_tokens', self.config.max_tokens)
# 等待获取许可
wait_time = await self.rate_limiter.wait_if_needed(estimated_tokens)
if wait_time > 0:
self.logger.info(f"频率限制等待: {wait_time:.2f}秒")
try:
# 执行实际请求
response = await super().chat_completion(messages, stream, **kwargs)
# 获取实际Token使用量
actual_tokens = response.get('usage', {}).get('total_tokens', estimated_tokens)
# 释放许可
await self.rate_limiter.release(actual_tokens)
return response
except Exception as e:
# 出错时也要释放许可
await self.rate_limiter.release(0)
raise
# 使用示例
async def demo_rate_limiting():
"""频率限制演示"""
# 创建频率限制器
rate_limiter = RateLimiter(
max_requests_per_minute=30, # 每分钟最多30个请求
max_tokens_per_minute=75000, # 每分钟最多75K Token
max_concurrent_requests=5 # 最多5个并发请求
)
# 创建客户端
config = DeepSeekConfig(
api_key="sk-your-api-key-here",
model="deepseek-chat"
)
async with RateLimitedDeepSeekClient(config, rate_limiter) as client:
# 模拟大量并发请求
tasks = []
for i in range(50):
messages = [
{"role": "user", "content": f"请介绍一下人工智能的第{i+1}个应用场景。"}
]
task = client.chat_completion(messages)
tasks.append(task)
# 执行所有请求
start_time = time.time()
results = await asyncio.gather(*tasks, return_exceptions=True)
end_time = time.time()
# 统计结果
successful_requests = sum(1 for result in results if not isinstance(result, Exception))
failed_requests = len(results) - successful_requests
print(f"请求完成统计:")
print(f"- 总请求数: {len(tasks)}")
print(f"- 成功请求: {successful_requests}")
print(f"- 失败请求: {failed_requests}")
print(f"- 总耗时: {end_time - start_time:.2f}秒")
print(f"- 平均QPS: {successful_requests / (end_time - start_time):.2f}")
if __name__ == "__main__":
asyncio.run(demo_rate_limiting())
六、常见问题与解决方案
6.1 网络连接问题
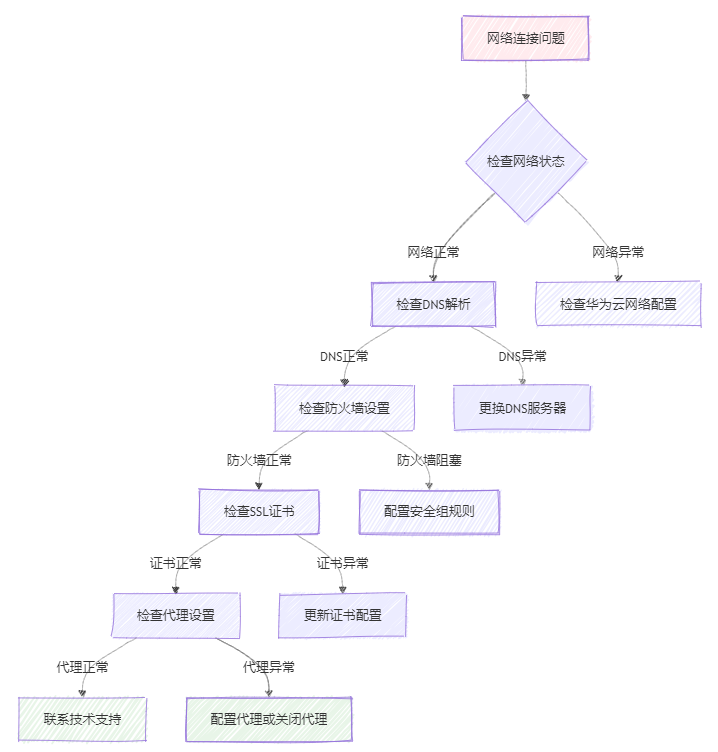
图3:网络连接问题诊断流程图
6.2 性能优化建议
class PerformanceOptimizer:
"""性能优化器"""
def __init__(self):
self.optimization_strategies = {
'connection_pooling': self._optimize_connection_pooling,
'request_batching': self._optimize_request_batching,
'caching': self._optimize_caching,
'compression': self._optimize_compression,
'async_processing': self._optimize_async_processing
}
def _optimize_connection_pooling(self) -> Dict:
"""连接池优化建议"""
return {
'strategy': 'connection_pooling',
'description': '使用连接池减少连接建立开销',
'implementation': '''
# 使用aiohttp的连接池
connector = aiohttp.TCPConnector(
limit=100, # 总连接数限制
limit_per_host=20, # 单主机连接数限制
ttl_dns_cache=300, # DNS缓存时间
use_dns_cache=True, # 启用DNS缓存
keepalive_timeout=30, # 保持连接时间
enable_cleanup_closed=True # 自动清理关闭的连接
)
''',
'expected_improvement': '减少20-30%的连接建立时间'
}
def _optimize_request_batching(self) -> Dict:
"""请求批处理优化"""
return {
'strategy': 'request_batching',
'description': '批量处理多个请求以提高吞吐量',
'implementation': '''
async def batch_process_requests(requests: List[Dict], batch_size: int = 5):
"""批量处理请求"""
results = []
for i in range(0, len(requests), batch_size):
batch = requests[i:i+batch_size]
batch_tasks = [
client.chat_completion(req['messages'])
for req in batch
]
batch_results = await asyncio.gather(
*batch_tasks,
return_exceptions=True
)
results.extend(batch_results)
# 批次间隔,避免过于频繁
await asyncio.sleep(0.1)
return results
''',
'expected_improvement': '提高40-60%的请求处理效率'
}
def _optimize_caching(self) -> Dict:
"""缓存优化"""
return {
'strategy': 'caching',
'description': '缓存常见请求结果',
'implementation': '''
import hashlib
from typing import Optional
class ResponseCache:
def __init__(self, max_size: int = 1000, ttl: int = 3600):
self.cache = {}
self.max_size = max_size
self.ttl = ttl
def _generate_key(self, messages: List[Dict]) -> str:
"""生成缓存键"""
content = json.dumps(messages, sort_keys=True)
return hashlib.md5(content.encode()).hexdigest()
def get(self, messages: List[Dict]) -> Optional[Dict]:
"""获取缓存结果"""
key = self._generate_key(messages)
if key in self.cache:
result, timestamp = self.cache[key]
if time.time() - timestamp < self.ttl:
return result
else:
del self.cache[key]
return None
def set(self, messages: List[Dict], response: Dict):
"""设置缓存"""
if len(self.cache) >= self.max_size:
# 清理最旧的缓存项
oldest_key = min(
self.cache.keys(),
key=lambda k: self.cache[k][1]
)
del self.cache[oldest_key]
key = self._generate_key(messages)
self.cache[key] = (response, time.time())
''',
'expected_improvement': '缓存命中时减少100%的API调用'
}
def _optimize_compression(self) -> Dict:
"""压缩优化"""
return {
'strategy': 'compression',
'description': '启用请求和响应压缩',
'implementation': '''
# 在aiohttp客户端中启用压缩
session = aiohttp.ClientSession(
headers={
'Accept-Encoding': 'gzip, deflate',
'Content-Encoding': 'gzip'
},
connector=aiohttp.TCPConnector(
enable_cleanup_closed=True
)
)
''',
'expected_improvement': '减少30-50%的网络传输时间'
}
def _optimize_async_processing(self) -> Dict:
"""异步处理优化"""
return {
'strategy': 'async_processing',
'description': '优化异步处理流程',
'implementation': '''
async def optimized_async_processing():
# 使用asyncio.gather处理并发请求
tasks = [
process_request(req)
for req in request_queue
]
# 设置超时和错误处理
try:
results = await asyncio.wait_for(
asyncio.gather(*tasks, return_exceptions=True),
timeout=30.0
)
except asyncio.TimeoutError:
# 处理超时情况
pass
return results
''',
'expected_improvement': '提高30-50%的并发处理能力'
}
def generate_optimization_report(self) -> Dict:
"""生成性能优化报告"""
report = {
'optimization_strategies': {},
'priority_recommendations': [],
'implementation_plan': {}
}
# 获取所有优化策略
for strategy_name, strategy_func in self.optimization_strategies.items():
strategy_info = strategy_func()
report['optimization_strategies'][strategy_name] = strategy_info
# 优先级建议
report['priority_recommendations'] = [
{
'priority': 1,
'strategy': 'connection_pooling',
'reason': '立即生效,实施成本低'
},
{
'priority': 2,
'strategy': 'caching',
'reason': '显著减少API调用次数'
},
{
'priority': 3,
'strategy': 'request_batching',
'reason': '提高整体吞吐量'
},
{
'priority': 4,
'strategy': 'async_processing',
'reason': '提升并发处理能力'
},
{
'priority': 5,
'strategy': 'compression',
'reason': '减少网络传输开销'
}
]
# 实施计划
report['implementation_plan'] = {
'phase_1': ['connection_pooling', 'caching'],
'phase_2': ['request_batching', 'async_processing'],
'phase_3': ['compression']
}
return report
# 生成优化报告
optimizer = PerformanceOptimizer()
optimization_report = optimizer.generate_optimization_report()
print("性能优化报告:", json.dumps(optimization_report, indent=2, ensure_ascii=False))七、监控与运维
7.1 服务监控配置
import psutil
import asyncio
import json
import logging
from datetime import datetime
from typing import Dict, List
import aiofiles
class ServiceMonitor:
"""服务监控系统"""
def __init__(self, config_path: str = "monitor_config.json"):
self.config_path = config_path
self.load_config()
self.setup_logging()
# 监控指标
self.metrics = {
'system': {},
'application': {},
'deepseek_api': {},
'costs': {}
}
# 告警规则
self.alert_rules = {
'cpu_usage': {'threshold': 80, 'duration': 300},
'memory_usage': {'threshold': 85, 'duration': 300},
'disk_usage': {'threshold': 90, 'duration': 60},
'response_time': {'threshold': 5.0, 'duration': 60},
'error_rate': {'threshold': 0.05, 'duration': 300},
'daily_cost': {'threshold': 100, 'duration': 86400}
}
def load_config(self):
"""加载监控配置"""
try:
with open(self.config_path, 'r', encoding='utf-8') as f:
self.config = json.load(f)
except FileNotFoundError:
self.config = {
'monitor_interval': 30,
'log_level': 'INFO',
'alert_channels': ['email', 'log'],
'metrics_retention_days': 30
}
self.save_config()
def save_config(self):
"""保存监控配置"""
with open(self.config_path, 'w', encoding='utf-8') as f:
json.dump(self.config, f, indent=2, ensure_ascii=False)
def setup_logging(self):
"""设置日志"""
log_level = getattr(logging, self.config.get('log_level', 'INFO'))
logging.basicConfig(
level=log_level,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('service_monitor.log'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
async def collect_system_metrics(self) -> Dict:
"""收集系统指标"""
try:
# CPU使用率
cpu_percent = psutil.cpu_percent(interval=1)
# 内存使用情况
memory = psutil.virtual_memory()
# 磁盘使用情况
disk = psutil.disk_usage('/')
# 网络统计
network = psutil.net_io_counters()
# 进程信息
process_count = len(psutil.pids())
system_metrics = {
'timestamp': datetime.now().isoformat(),
'cpu': {
'usage_percent': cpu_percent,
'count': psutil.cpu_count(),
'load_avg': list(psutil.getloadavg()) if hasattr(psutil, 'getloadavg') else None
},
'memory': {
'total': memory.total,
'available': memory.available,
'used': memory.used,
'usage_percent': memory.percent
},
'disk': {
'total': disk.total,
'used': disk.used,
'free': disk.free,
'usage_percent': (disk.used / disk.total) * 100
},
'network': {
'bytes_sent': network.bytes_sent,
'bytes_recv': network.bytes_recv,
'packets_sent': network.packets_sent,
'packets_recv': network.packets_recv
},
'processes': {
'count': process_count
}
}
self.metrics['system'] = system_metrics
return system_metrics
except Exception as e:
self.logger.error(f"收集系统指标失败: {str(e)}")
return {}
async def collect_application_metrics(self, deepseek_client=None) -> Dict:
"""收集应用指标"""
try:
app_metrics = {
'timestamp': datetime.now().isoformat(),
'uptime': self._get_uptime(),
'response_times': [],
'error_count': 0,
'request_count': 0
}
if deepseek_client:
stats = deepseek_client.get_statistics()
app_metrics.update({
'deepseek_requests': stats.get('request_count', 0),
'deepseek_tokens': stats.get('total_tokens', 0),
'deepseek_cost': stats.get('total_cost', 0.0),
'avg_tokens_per_request': stats.get('average_tokens_per_request', 0)
})
self.metrics['application'] = app_metrics
return app_metrics
except Exception as e:
self.logger.error(f"收集应用指标失败: {str(e)}")
return {}
def _get_uptime(self) -> float:
"""获取系统运行时间"""
try:
return time.time() - psutil.boot_time()
except:
return 0.0
async def check_alerts(self):
"""检查告警条件"""
alerts = []
# 检查系统指标告警
system_metrics = self.metrics.get('system', {})
# CPU使用率告警
cpu_usage = system_metrics.get('cpu', {}).get('usage_percent', 0)
if cpu_usage > self.alert_rules['cpu_usage']['threshold']:
alerts.append({
'type': 'cpu_high_usage',
'level': 'warning',
'message': f"CPU使用率过高: {cpu_usage:.1f}%",
'value': cpu_usage,
'threshold': self.alert_rules['cpu_usage']['threshold']
})
# 内存使用率告警
memory_usage = system_metrics.get('memory', {}).get('usage_percent', 0)
if memory_usage > self.alert_rules['memory_usage']['threshold']:
alerts.append({
'type': 'memory_high_usage',
'level': 'warning',
'message': f"内存使用率过高: {memory_usage:.1f}%",
'value': memory_usage,
'threshold': self.alert_rules['memory_usage']['threshold']
})
# 磁盘使用率告警
disk_usage = system_metrics.get('disk', {}).get('usage_percent', 0)
if disk_usage > self.alert_rules['disk_usage']['threshold']:
alerts.append({
'type': 'disk_high_usage',
'level': 'critical',
'message': f"磁盘使用率过高: {disk_usage:.1f}%",
'value': disk_usage,
'threshold': self.alert_rules['disk_usage']['threshold']
})
# 处理告警
for alert in alerts:
await self.handle_alert(alert)
async def handle_alert(self, alert: Dict):
"""处理告警"""
self.logger.warning(f"告警触发: {alert['message']}")
# 记录告警到文件
await self.log_alert(alert)
# 发送邮件告警(如果配置了邮件)
if 'email' in self.config.get('alert_channels', []):
await self.send_email_alert(alert)
async def log_alert(self, alert: Dict):
"""记录告警到文件"""
alert_log = {
'timestamp': datetime.now().isoformat(),
'alert': alert
}
async with aiofiles.open('alerts.log', 'a', encoding='utf-8') as f:
await f.write(json.dumps(alert_log, ensure_ascii=False) + '\n')
async def send_email_alert(self, alert: Dict):
"""发送邮件告警"""
# 这里可以集成邮件发送功能
self.logger.info(f"邮件告警: {alert['message']}")
async def generate_dashboard_data(self) -> Dict:
"""生成监控面板数据"""
dashboard_data = {
'last_update': datetime.now().isoformat(),
'system_status': 'healthy',
'metrics': self.metrics,
'alerts': await self.get_recent_alerts(),
'summary': {
'cpu_usage': self.metrics.get('system', {}).get('cpu', {}).get('usage_percent', 0),
'memory_usage': self.metrics.get('system', {}).get('memory', {}).get('usage_percent', 0),
'disk_usage': self.metrics.get('system', {}).get('disk', {}).get('usage_percent', 0),
'request_count': self.metrics.get('application', {}).get('deepseek_requests', 0),
'total_cost': self.metrics.get('application', {}).get('deepseek_cost', 0.0)
}
}
# 判断整体健康状态
if (dashboard_data['summary']['cpu_usage'] > 80 or
dashboard_data['summary']['memory_usage'] > 85 or
dashboard_data['summary']['disk_usage'] > 90):
dashboard_data['system_status'] = 'warning'
return dashboard_data
async def get_recent_alerts(self, hours: int = 24) -> List[Dict]:
"""获取最近的告警记录"""
alerts = []
try:
async with aiofiles.open('alerts.log', 'r', encoding='utf-8') as f:
async for line in f:
try:
alert_record = json.loads(line.strip())
# 这里可以添加时间过滤逻辑
alerts.append(alert_record)
except json.JSONDecodeError:
continue
except FileNotFoundError:
pass
return alerts[-50:] # 返回最近50条告警
async def start_monitoring(self, deepseek_client=None):
"""启动监控"""
self.logger.info("监控服务启动")
while True:
try:
# 收集指标
await self.collect_system_metrics()
await self.collect_application_metrics(deepseek_client)
# 检查告警
await self.check_alerts()
# 生成面板数据
dashboard_data = await self.generate_dashboard_data()
# 保存面板数据
async with aiofiles.open('dashboard.json', 'w', encoding='utf-8') as f:
await f.write(json.dumps(dashboard_data, indent=2, ensure_ascii=False))
# 等待下次监控
await asyncio.sleep(self.config.get('monitor_interval', 30))
except Exception as e:
self.logger.error(f"监控循环异常: {str(e)}")
await asyncio.sleep(60) # 出错后等待1分钟再重试
# 监控使用示例
async def main():
"""监控服务主函数"""
monitor = ServiceMonitor()
# 如果有DeepSeek客户端,可以传入进行监控
config = DeepSeekConfig(api_key="sk-your-api-key-here")
async with DeepSeekClient(config) as deepseek_client:
await monitor.start_monitoring(deepseek_client)
if __name__ == "__main__":
asyncio.run(main())7.2 日志管理与分析
import logging
import logging.handlers
import json
import re
from datetime import datetime, timedelta
from typing import Dict, List, Optional
from collections import defaultdict, Counter
class LogAnalyzer:
"""日志分析器"""
def __init__(self, log_files: List[str]):
self.log_files = log_files
self.patterns = {
'request': re.compile(r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+请求完成.+耗时(\d+\.?\d*)s.+Token使用: (\d+)'),
'error': re.compile(r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+ERROR.+(.+)'),
'cost': re.compile(r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+成本: (\d+\.?\d*)'),
'api_call': re.compile(r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+API调用.+模型: (\w+).+Token: (\d+)')
}
def parse_logs(self, start_time: Optional[datetime] = None, end_time: Optional[datetime] = None) -> Dict:
"""解析日志文件"""
parsed_data = {
'requests': [],
'errors': [],
'costs': [],
'api_calls': []
}
for log_file in self.log_files:
try:
with open(log_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
# 解析请求记录
request_match = self.patterns['request'].search(line)
if request_match:
timestamp = datetime.strptime(request_match.group(1), '%Y-%m-%d %H:%M:%S')
if self._is_in_time_range(timestamp, start_time, end_time):
parsed_data['requests'].append({
'timestamp': timestamp,
'response_time': float(request_match.group(2)),
'tokens': int(request_match.group(3))
})
# 解析错误记录
error_match = self.patterns['error'].search(line)
if error_match:
timestamp = datetime.strptime(error_match.group(1), '%Y-%m-%d %H:%M:%S')
if self._is_in_time_range(timestamp, start_time, end_time):
parsed_data['errors'].append({
'timestamp': timestamp,
'message': error_match.group(2)
})
# 解析成本记录
cost_match = self.patterns['cost'].search(line)
if cost_match:
timestamp = datetime.strptime(cost_match.group(1), '%Y-%m-%d %H:%M:%S')
if self._is_in_time_range(timestamp, start_time, end_time):
parsed_data['costs'].append({
'timestamp': timestamp,
'cost': float(cost_match.group(2))
})
# 解析API调用记录
api_match = self.patterns['api_call'].search(line)
if api_match:
timestamp = datetime.strptime(api_match.group(1), '%Y-%m-%d %H:%M:%S')
if self._is_in_time_range(timestamp, start_time, end_time):
parsed_data['api_calls'].append({
'timestamp': timestamp,
'model': api_match.group(2),
'tokens': int(api_match.group(3))
})
except FileNotFoundError:
logging.warning(f"日志文件不存在: {log_file}")
except Exception as e:
logging.error(f"解析日志文件失败 {log_file}: {str(e)}")
return parsed_data
def _is_in_time_range(self, timestamp: datetime, start_time: Optional[datetime], end_time: Optional[datetime]) -> bool:
"""检查时间戳是否在指定范围内"""
if start_time and timestamp < start_time:
return False
if end_time and timestamp > end_time:
return False
return True
def analyze_performance(self, parsed_data: Dict) -> Dict:
"""分析性能指标"""
requests = parsed_data['requests']
if not requests:
return {'message': '没有找到请求数据'}
response_times = [req['response_time'] for req in requests]
tokens_list = [req['tokens'] for req in requests]
# 计算统计指标
analysis = {
'total_requests': len(requests),
'response_time': {
'min': min(response_times),
'max': max(response_times),
'avg': sum(response_times) / len(response_times),
'p95': self._percentile(response_times, 95),
'p99': self._percentile(response_times, 99)
},
'tokens': {
'total': sum(tokens_list),
'avg': sum(tokens_list) / len(tokens_list),
'min': min(tokens_list),
'max': max(tokens_list)
},
'throughput': {
'requests_per_hour': self._calculate_requests_per_hour(requests),
'tokens_per_hour': self._calculate_tokens_per_hour(requests)
}
}
return analysis
def analyze_errors(self, parsed_data: Dict) -> Dict:
"""分析错误情况"""
errors = parsed_data['errors']
if not errors:
return {'message': '没有发现错误'}
# 错误类型统计
error_types = Counter()
error_timeline = defaultdict(int)
for error in errors:
# 简单的错误分类
message = error['message'].lower()
if 'timeout' in message:
error_type = 'timeout'
elif 'connection' in message:
error_type = 'connection'
elif 'rate limit' in message:
error_type = 'rate_limit'
elif 'authentication' in message:
error_type = 'auth'
else:
error_type = 'other'
error_types[error_type] += 1
# 按小时统计错误
hour_key = error['timestamp'].strftime('%Y-%m-%d %H:00')
error_timeline[hour_key] += 1
analysis = {
'total_errors': len(errors),
'error_types': dict(error_types),
'error_timeline': dict(error_timeline),
'error_rate': len(errors) / max(len(parsed_data.get('requests', [])), 1)
}
return analysis
def analyze_costs(self, parsed_data: Dict) -> Dict:
"""分析成本情况"""
costs = parsed_data['costs']
if not costs:
return {'message': '没有找到成本数据'}
cost_values = [cost['cost'] for cost in costs]
# 按日期统计成本
daily_costs = defaultdict(float)
for cost in costs:
date_key = cost['timestamp'].strftime('%Y-%m-%d')
daily_costs[date_key] += cost['cost']
analysis = {
'total_cost': sum(cost_values),
'avg_cost_per_request': sum(cost_values) / len(cost_values),
'daily_costs': dict(daily_costs),
'cost_trend': self._calculate_cost_trend(daily_costs)
}
return analysis
def _percentile(self, data: List[float], percentile: int) -> float:
"""计算百分位数"""
sorted_data = sorted(data)
index = int((percentile / 100) * len(sorted_data))
return sorted_data[min(index, len(sorted_data) - 1)]
def _calculate_requests_per_hour(self, requests: List[Dict]) -> float:
"""计算每小时请求数"""
if not requests:
return 0.0
start_time = min(req['timestamp'] for req in requests)
end_time = max(req['timestamp'] for req in requests)
duration_hours = (end_time - start_time).total_seconds() / 3600
return len(requests) / max(duration_hours, 1/3600) # 至少1秒
def _calculate_tokens_per_hour(self, requests: List[Dict]) -> float:
"""计算每小时Token数"""
if not requests:
return 0.0
start_time = min(req['timestamp'] for req in requests)
end_time = max(req['timestamp'] for req in requests)
duration_hours = (end_time - start_time).total_seconds() / 3600
total_tokens = sum(req['tokens'] for req in requests)
return total_tokens / max(duration_hours, 1/3600)
def _calculate_cost_trend(self, daily_costs: Dict[str, float]) -> str:
"""计算成本趋势"""
if len(daily_costs) < 2:
return 'insufficient_data'
dates = sorted(daily_costs.keys())
recent_costs = [daily_costs[date] for date in dates[-3:]]
if len(recent_costs) >= 2:
if recent_costs[-1] > recent_costs[-2] * 1.1:
return 'increasing'
elif recent_costs[-1] < recent_costs[-2] * 0.9:
return 'decreasing'
else:
return 'stable'
return 'stable'
def generate_report(self, days: int = 7) -> Dict:
"""生成综合分析报告"""
end_time = datetime.now()
start_time = end_time - timedelta(days=days)
# 解析日志数据
parsed_data = self.parse_logs(start_time, end_time)
# 分析各项指标
performance = self.analyze_performance(parsed_data)
errors = self.analyze_errors(parsed_data)
costs = self.analyze_costs(parsed_data)
# 生成综合报告
report = {
'report_period': {
'start_time': start_time.isoformat(),
'end_time': end_time.isoformat(),
'days': days
},
'summary': {
'total_requests': performance.get('total_requests', 0),
'total_errors': errors.get('total_errors', 0),
'error_rate': errors.get('error_rate', 0),
'total_cost': costs.get('total_cost', 0),
'avg_response_time': performance.get('response_time', {}).get('avg', 0)
},
'performance_analysis': performance,
'error_analysis': errors,
'cost_analysis': costs,
'recommendations': self._generate_recommendations(performance, errors, costs)
}
return report
def _generate_recommendations(self, performance: Dict, errors: Dict, costs: Dict) -> List[str]:
"""生成优化建议"""
recommendations = []
# 性能建议
avg_response_time = performance.get('response_time', {}).get('avg', 0)
if avg_response_time > 3.0:
recommendations.append("响应时间较长,建议优化网络连接或使用连接池")
# 错误建议
error_rate = errors.get('error_rate', 0)
if error_rate > 0.05:
recommendations.append("错误率偏高,建议检查网络稳定性和API限流设置")
error_types = errors.get('error_types', {})
if error_types.get('timeout', 0) > 0:
recommendations.append("存在超时错误,建议增加请求超时时间或优化请求处理")
if error_types.get('rate_limit', 0) > 0:
recommendations.append("触发频率限制,建议调整请求频率或升级API套餐")
# 成本建议
cost_trend = costs.get('cost_trend', 'stable')
if cost_trend == 'increasing':
recommendations.append("成本呈上升趋势,建议检查Token使用效率和优化请求策略")
total_cost = costs.get('total_cost', 0)
total_requests = performance.get('total_requests', 0)
if total_requests > 0:
avg_cost_per_request = total_cost / total_requests
if avg_cost_per_request > 0.01: # 假设阈值
recommendations.append("单次请求成本较高,建议优化提示词长度和选择合适的模型")
return recommendations
# 使用示例
def main():
"""日志分析主函数"""
analyzer = LogAnalyzer([
'service_monitor.log',
'deepseek_api.log',
'application.log'
])
# 生成最近7天的分析报告
report = analyzer.generate_report(days=7)
# 保存报告
with open('log_analysis_report.json', 'w', encoding='utf-8') as f:
json.dump(report, f, indent=2, ensure_ascii=False, default=str)
print("日志分析报告已生成:log_analysis_report.json")
# 打印关键指标
print(f"分析周期: {report['report_period']['days']}天")
print(f"总请求数: {report['summary']['total_requests']}")
print(f"错误率: {report['summary']['error_rate']:.2%}")
print(f"总成本: ¥{report['summary']['total_cost']:.4f}")
print(f"平均响应时间: {report['summary']['avg_response_time']:.2f}秒")
print("\n优化建议:")
for i, recommendation in enumerate(report['recommendations'], 1):
print(f"{i}. {recommendation}")
if __name__ == "__main__":
main()八、总结与展望
8.1 最佳实践总结
通过本文的详细介绍,我们完成了华为云Flexus环境下DeepSeek MaaS服务的完整部署和优化。以下是关键的最佳实践总结:
环境配置方面:
- 选择合适的Flexus实例规格,平衡性能和成本
- 配置专用安全组,确保网络安全
- 使用Docker容器化部署,提高部署效率和一致性
API集成方面:
- 实现异步客户端,提高并发处理能力
- 添加连接池和请求重试机制,增强稳定性
- 实现流式响应,提升用户体验
成本控制方面:
- 建立完善的监控和告警体系
- 实现智能的Token使用优化
- 配置灵活的频率限制机制
运维监控方面:
- 部署全面的监控系统
- 建立日志分析和性能优化流程
- 制定应急响应和故障处理预案
8.2 关键技术要点
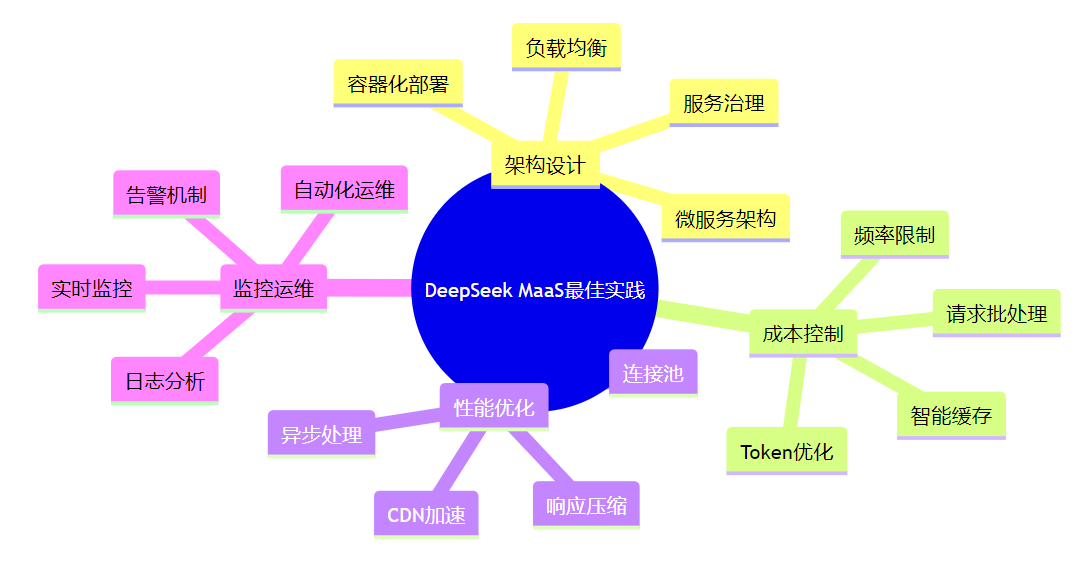
图4:DeepSeek MaaS最佳实践思维导图
8.3 未来发展方向
随着大模型技术的不断发展,DeepSeek MaaS平台在华为云环境下的应用将会有更多的优化空间:
技术发展趋势:
- 模型能力提升:更强的推理能力和更低的成本
- 边缘计算集成:结合华为云边缘节点,降低延迟
- 多模态支持:文本、图像、音频的统一处理
- 自动化优化:基于AI的成本和性能自动优化
应用场景扩展:
- 智能客服系统:24/7自动化客户服务
- 内容创作平台:智能写作和内容生成
- 代码助手工具:开发效率提升工具
- 教育培训系统:个性化学习辅导
8.4 参考资源
官方文档:
技术社区:
监控工具:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)