通俗易懂讲AI:5分钟搞懂小模型/大模型/多模态特点!使用效果翻倍!
大家用了这么长时间的大模型,是否明白上面2个按钮打开或关闭分别起什么作用嘛?联网和深度思考都开:推理模型R1回答问题时会结合搜索到的互联网内容进行解答联网和深度思考都关闭:那就是deepseek的V3模型自己在进行问题解答联网开和深度思考关闭:V3模型回答问题时会结合搜索到的互联网内容进行解答联网关闭和深度思考开:那就是deepseek的推理模型R1自己在进行问题解答那么,在使用中,“深度思考”和
少走弯路!一文讲懂小模型、通用大语言模型、推理模型、多模态大模型特点和使用场景
前言
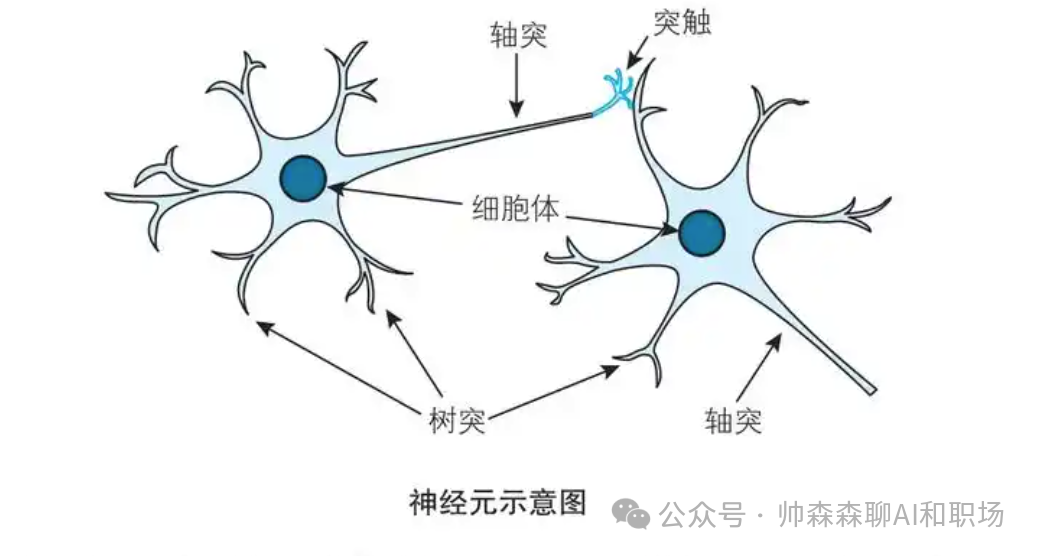
现在很火的大模型到底是哪里来的,看下面这个图,熟悉生物学的应该一眼看出,这个是神经突触传递示意图。没错,现在的AI大模型的技术来源就是受人脑启发演变而来的,尽管我们对真实的人脑运作认知有限。
AI领域的模型大小都是以自身的参数量为衡量的,根据行业经验,大模型的参数量是10亿起步,因为衡量大模型参数的单位就是billion。
步入正文前叠个甲,下面这个图片都不陌生,但你知道这2个按钮该怎么使用吗?什么时候开?什么时候关?后面给出答案。

小模型
顾名思义就是模型参数较小的模型
特点
-
参数量较小,在AI领域,参数量在1亿(0.1B)以下的模型通常被称为小模型。
-
计算需求较低,可以在资源有限的设备上运行,如手机、嵌入式系统等。
-
训练数据需求相对较少。
-
专注于特定任务,例如图像分类、目标检测、语音识别等。
使用场景
-
移动设备上的实时应用,如相机应用中的人脸识别,物体检测(方形框)。
-
物联网(IoT)设备上的边缘计算,如智能传感器。
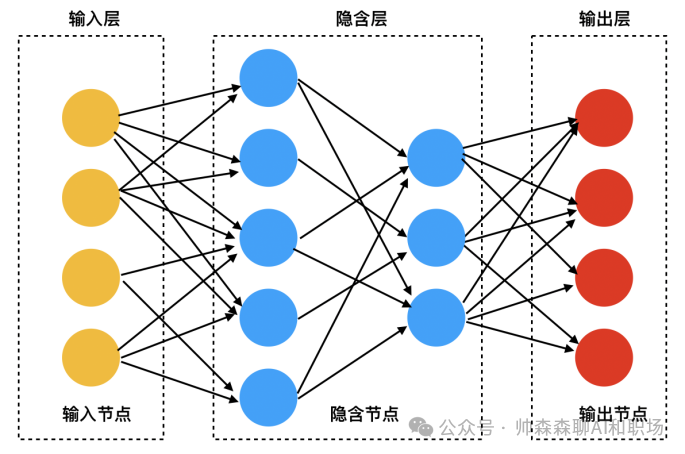
神经网络模型示意图如下:
模型结构分为输入层、隐藏层、输出层。区分是大模型还是小模型就是中间隐藏层参数的层数和每一层参数量之和。比如下面这定义为小模型。
与之相对,当我们把隐藏层的层数和每一层参数量不断扩大后,达到一定程度,就变为大模型,也就是我们现在熟知的大语言模型。如下图:
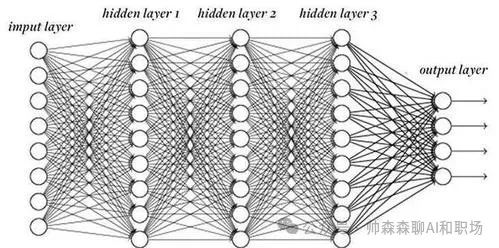
大语言模型 (Large Language Models, LLMs)
特点如下:
-
参数量巨大,通常在数百亿到数千亿之间。
-
在海量文本数据上进行训练,能够生成高质量的自然语言文本。
-
具有较强的通用性,可以完成多种自然语言处理任务,如文本生成、翻译、问答、摘要等。
-
智能涌现,当模型学习一定程度后,慢慢的会举一反三,给他一个没有见过的语言问题,也能尝试解答。

使用场景:
-
聊天机器人: 提供对话式交互,例如客服机器人、虚拟助手。
-
文本生成: 创作各种类型的文本,例如文章、诗歌、剧本。
-
机器翻译: 将文本从一种语言翻译成另一种语言等等。几乎所有语言处理的任务都可以使用大语言模型
和小模型不一样的是,大模型的受众更广,想用的好使用也会有一定门槛
使用技巧:
-
提示工程 (Prompt Engineering): 设计有效的提示语,引导模型生成所需的输出。
-
清晰明确的指令: 准确描述所需的任务和输出格式。
-
提供上下文: 提供足够的背景信息,帮助模型理解任务。
-
少样本学习 (Few-shot Learning): 在提示中提供少量示例,帮助模型学习新的任务。
-
微调 (Fine-tuning): 在特定领域的数据上进一步训练模型,提高其在该领域的性能。
-
检索增强生成 (Retrieval Augmented Generation, RAG): 结合外部知识库,提高生成文本的准确性和相关性。
这个里面的各个概念我们会单独出一篇文章,详细介绍给大家。上面这么多概念技巧表明,想让大语言模型发挥效果,其实是要借助各种工具的,模型自身就有很大局限。所以想用好,还是要好好学习一番,想学习AI的,🔍:ai_service,进👗,告诉我你想解决什么问题
推理大模型
有了大语言模型,为什么还要推理大模型?
诞生背景
推理大模型诞生的背景,当然是语言大模型的局限性
语言大模型(如GPT系列)虽然在文本生成、对话等任务上表现出色,但其核心能力仍局限于“直进直出”概率驱动的文本预测,这导致以下问题:
-
复杂任务表现不足:在数学证明、科学问题求解等需要多步分解的任务中,传统语言模型易出现逻辑断裂或“幻觉”。
-
缺乏反思能力:模型无法像人类一样通过“慢思考”验证中间步骤,导致错误累积
推理大模型怎么工作的?
-
思维链技术:核心是“分步思考”。通俗说就是大的问题分布拆解若干步骤,然后求解。但是和人的真正思考不是一回事,毕竟现在人的智能还没有被解析。
-
强化学习训练:通过“试错”学习,像教小孩做题:做对了奖励,错了就调整。这让模型自己学会最优推理路径(如OpenAI的o1系列)
推理模型真的会推理吗?
答案很微妙:它会模拟人类推理的“表面行为”,但不会像人类一样“理解逻辑”。
像推理的“演员”:模型通过海量数据学习解题步骤的规律(比如先设变量、再列方程),但不懂背后的数学原理。
作弊式推理:它像考试时偷偷带小抄,把“看到问题→匹配套路→输出答案”变成肌肉记忆。
人类开挂法:为了让模型更像“真会推理”,工程师还会用数学题答案当参考答案逼它练习(强化学习),或者让它调用计算器算数(工具增强)。
总结一下,推理模型不会真的推理,只是在模仿人思考的模板,就是学套路学得好。不信可以看下面这个例子:

解答模式真的没问题,但是不是哪里不太对?看下面
首先有翅膀不意味着会飞,比如鸡就有翅膀
汤姆猫显然是一个动画角色,模型此时就不知道“变通”啦
总结:没有常识,只会按照固定的模版执行
如果我们这样问:“汤姆猫是什么剧中的那个角色?”

结合上面2个事例,可以知道其实模型是有这方面的记忆,但是它不知道“联想和思考”
deepseek界面为例,介绍不同按钮的功能和作用
大家用了这么长时间的大模型,是否明白上面2个按钮打开或关闭分别起什么作用嘛?
- 联网和深度思考都开:推理模型R1回答问题时会结合搜索到的互联网内容进行解答
- 联网和深度思考都关闭:那就是deepseek的V3模型自己在进行问题解答
- 联网开和深度思考关闭:V3模型回答问题时会结合搜索到的互联网内容进行解答
- 联网关闭和深度思考开:那就是deepseek的推理模型R1自己在进行问题解答
那么,在使用中,“深度思考”和“联网搜索”按钮打开或关闭的分别适用场景和作用是什么?
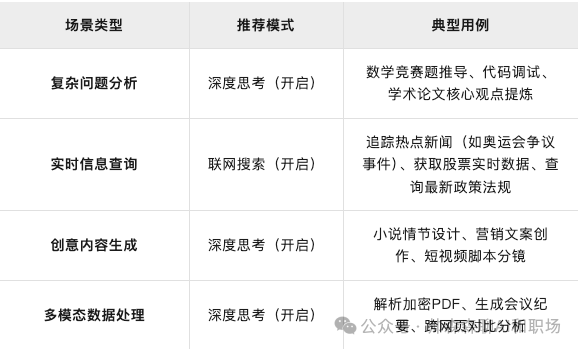
深度思考(DeepSeek-R1模式)
作用:调用深度推理模型,专注于复杂逻辑分析、多步骤推演和长文本处理(如数学建模、代码调试、学术论文解析)。
优势:回答准确性高,支持256k超长上下文记忆,适合专业领域问题
劣势:响应速度较慢,无法实时获取外部信息,个别时候推理会带来“致幻”
联网搜索(实时检索模式)
作用:接入互联网实时数据(如新闻、政策、学术论文)和平台生态内容(公众号、视频号),解决时效性问题。
优势:信息更新快(如股票行情、赛事比分),整合多源数据(3000+信源)增强答案权威性。
劣势:可能引入噪声干扰,响应速度略慢
何时开启?
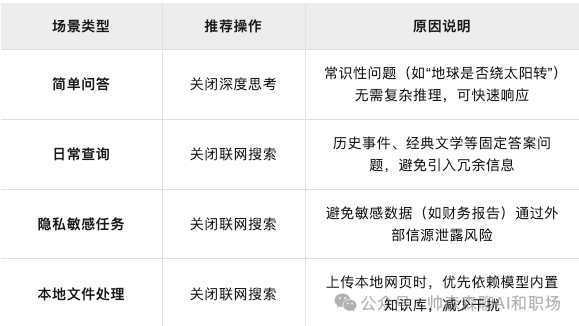
何时关闭?
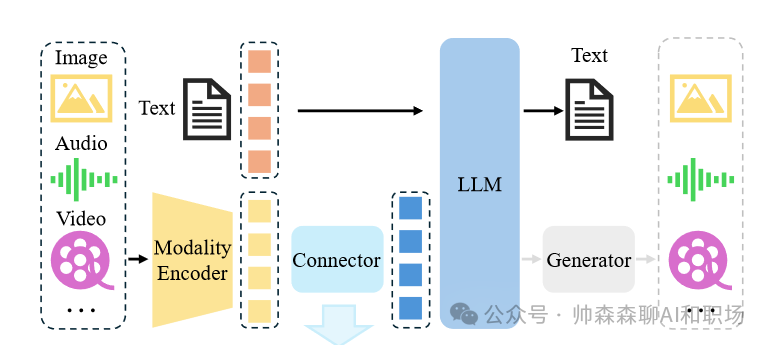
大语言模型一般只能处理文本信息,如果想结合图文音视频信息解决问题,就需要多模态大模型
多模态大模型
特点:
-
能够处理多种类型的输入数据,例如文本、图像、音频、视频等。
-
通过跨模态学习,理解不同模态数据之间的关系。
-
能够生成多种模态的输出,例如根据文本生成图像,或者根据图像生成描述。
现有模型多模态能力看下面文章
地表最强,Gemini 2.5Pro发布!多模型对比实测到底如何?请看文章
使用场景:
-
跨模态检索: 根据一种模态的数据检索另一种模态的数据,例如根据文本描述搜索图像。
-
视觉问答 (Visual Question Answering, VQA): 回答与图像内容相关的问题。
-
图像描述生成 (Image Captioning): 生成描述图像内容的自然语言文本。
-
多模态对话: 进行涉及多种模态信息的对话,例如“这张图片中的人正在做什么?” (需要理解图像内容)。
-
具身智能 (Embodied Intelligence): 帮助智能体理解周围环境并与之交互。
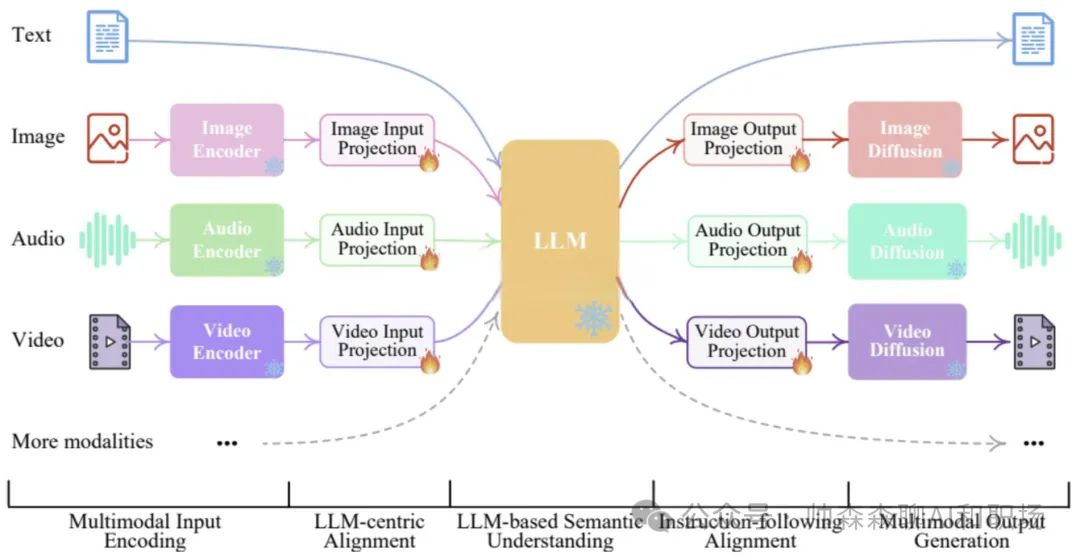
现有模型能力,输入可以是文本、图像、音频、视频等。但是输出还是局限在文字和图片(图片能力进化中)。随着模型能力和边界的扩展,未来模型可实现下图构思。
总结
不是功能越丰富就越好,要根据问题的特点选择合适的模型和辅助工具。不是每个问题都需要使用推理模型,因为模型在推理的过程中会出现推理错误,从而导致“致幻”回复。关注AI小伙伴,🔍:ai_service,进👗,持续分享一线的AI知识和见闻
更多AI内容看下面

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 33
33 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)