一文搞懂DeepSeek核心技术-MTP(Multi-Token Prediction)
MTP 的核心思想是让模型一次性预测多个 token,以提升模型的训练效率、生成质量和推理速度。模型不仅要学习预测下一个 token 的能力,还需要同时具备预测下 n 个token的能力。
大家好,我是皮先生!!
本文将深入剖析DeepSeek模型核心技术-MTP(Multi-Token Prediction)的工作原理、技术创新,希望对大家的理解有帮助。
目录
MTP
当前主流采用自回归的大模型都是单 token 预测,即根据当前上文预测下一个最可能的 token。每次token生成需要频繁与访存交互,从而因为访存效率形成训练或推理的瓶颈。
而 MTP 的核心思想是让模型一次性预测多个 token,以提升模型的训练效率、生成质量和推理速度。因此,模型不仅要学习预测下一个 token 的能力,还需要同时具备预测下 n 个token的能力。
训练阶段:使训练信号更加密集,可能会提高数据效率;还使模型预先规划,以便更好地预测未来的Token。
推理阶段:主要目的是提升主模型的性能,因此在推理时可以直接移除MTP模块,主模型能够独立且正常运行。
MTP 预测的优势
1.训练过程
在训练过程中,MTP 的训练目标函数同时考虑了多个 token 的估计准确性,因此被认为可以捕捉 token 间的依赖关系,从而提升模型效果。
2.推理维度
这种方式在推理角度的好处也显而易见,一次性生成多个 tokens,减少自回归生成的步数,达到推理加速效果。
3.缓解短视预测问题
- 传统单步预测容易导致模型过度关注局部模式(如语法而非语义)。
- MTP通过强制模型同时优化多个位置的预测,鼓励其建立全局性的文本理解,这在技术报告提及的“性能超越其他开源模型”中起到关键作用。
MTP实现细节
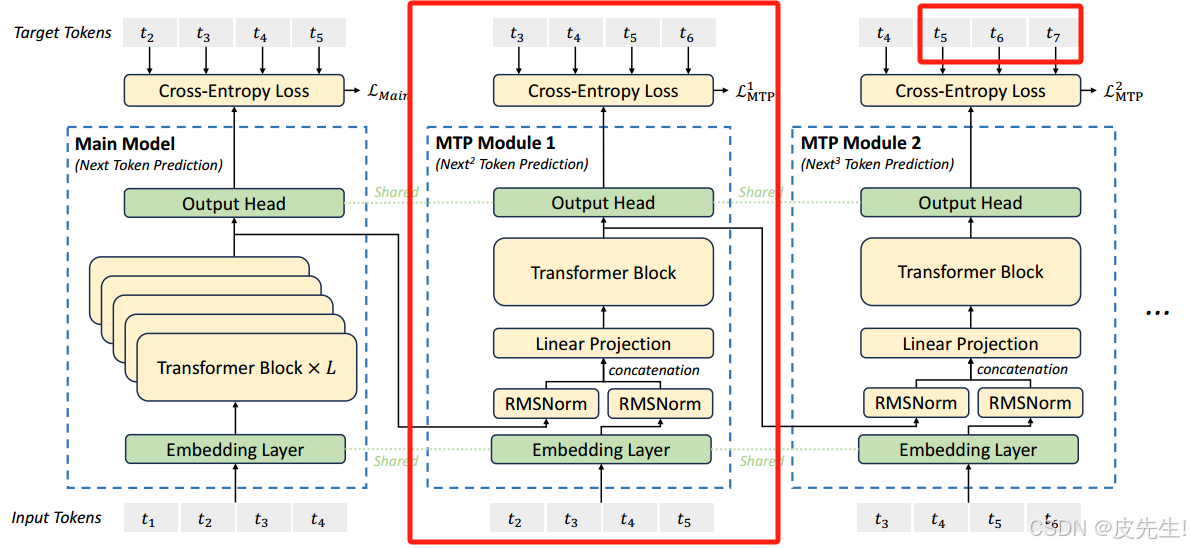
如上图所示,用 D 个顺序的模块,预测 D 个 tokens。每个 MTP 模块的具体结构:
- 输入 token 首先接入一层共享的 embedding layer;
- 对于第 i 个 token 和第 k 个预测深度
- 我们首先将第 k-1 层的隐层输入
做归一化处理
- 再对第 i+k 位置的 token embedding:
做归一化处理:
- 将上述两个结果 concat 后,通过注意力矩阵
做一层线性变换得到
- (当 k=1 时,
对应 main model 的隐层表征)
- 我们首先将第 k-1 层的隐层输入
- 再将
输入 Transformer 层,获得第 k 个预测深度的输出:
。
- 最后将
变换,再经过 softmax() 处理,计算词汇 V 维度的输出概率。
MTP训练目标:计算所有深度的 MTP 损失的平均值,并乘以加权因子𝜆,得出总体 MTP 损失,作为 DeepSeek-V3 的额外训练目标。
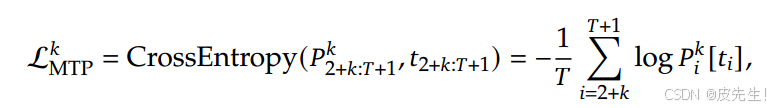
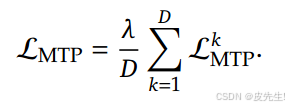
DeepSeek V3 论文中报告了使用 MTP 模块的效果。他们在推理过程中,不使用 MTP 模块,只在训练过程中利用该模块约束模型的优化。
结论
MTP 的核心思想是让模型一次性预测多个 token,以提升模型的训练效率、生成质量和推理速度。模型不仅要学习预测下一个 token 的能力,还需要同时具备预测下 n 个token的能力。
参考资料
DeepSeek-V3:https://arxiv.org/pdf/2412.19437

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 39
39 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)