基于Optuna贝叶斯优化的随机森林RF超参数调优运用
输出结果显示,Optuna 优化后找到的最优随机森林参数组合为:构建 50 棵树(n_estimators=50)、最大深度为 9、每个节点至少包含 3 个样本才可分裂(min_samples_split=3)、叶节点最少 8 个样本(min_samples_leaf=8)、特征选择方式为 'log2',且不采用自助采样(bootstrap=False)截至目前为止,合集已包含200多篇文章,购买
基于Optuna贝叶斯优化的随机森林RF超参数调优运用
原创 Python机器学习AI Python机器学习AI 2025年04月03日 00:00 重庆

✨ 欢迎关注Python机器学习AI ✨
本节介绍:本项目基于Optuna贝叶斯优化方法,对随机森林 (RF) 模型进行超参数调优。数据采用模拟数据,用于算法性能验证,并无实际应用意义。作者根据个人对机器学习的理解进行了代码实现与图表输出,仅供参考。详细数据和代码将在稍后上传至交流群,付费群成员可在交流群中获取下载。需要的朋友可关注公众文末提供的购买方式。购买前请咨询,避免不必要的问题。
✨ 代码实现✨
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltplt.rcParams['font.family'] = 'Times New Roman'plt.rcParams['axes.unicode_minus'] = Falseimport warnings# 忽略所有警告warnings.filterwarnings("ignore")path = r"2025-4-3公众号Python机器学习AI.xlsx"df = pd.read_excel(path)from sklearn.model_selection import train_test_splitX = df.drop(['y'],axis=1)y = df['y']# 划分训练集和测试集X_temp, X_test, y_temp, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 然后将训练集进一步划分为训练集和验证集X_train, X_val, y_train, y_val = train_test_split(X_temp, y_temp, test_size=0.125, random_state=42) # 0.125 x 0.8 = 0.1
读取Excel中的数据,并将其按8:1:1的比例划分为训练集、验证集和测试集,分别用于模型的训练、超参数调优及最终性能评估。通过这种划分方式,可以有效防止模型过拟合,并确保在未知数据上的泛化能力,从而更客观地衡量模型表现
import optuna # 导入Optuna库,用于超参数优化from sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error# 定义目标函数,用于Optuna的优化def objective(trial):# 定义模型的超参数搜索空间,Optuna会在此范围内进行参数采样params = {# 'n_estimators':模型中要构建的树的数量'n_estimators': trial.suggest_categorical('n_estimators', [50, 100, 200, 300]), # 离散的类别选择范围# 'max_depth':控制每棵树的最大深度'max_depth': trial.suggest_int('max_depth', 3, 15, step=1), # 整数范围# 'min_samples_split':拆分节点时所需的最小样本数'min_samples_split': trial.suggest_int('min_samples_split', 2, 10), # 整数范围# 'min_samples_leaf':叶节点中最小的样本数'min_samples_leaf': trial.suggest_int('min_samples_leaf', 1, 10), # 整数范围# 'max_features':每棵树随机选择的特征数'max_features': trial.suggest_categorical('max_features', ['sqrt', 'log2', None]), # 合法的选择# 'bootstrap':是否在训练时进行自助采样(是否使用样本替代)'bootstrap': trial.suggest_categorical('bootstrap', [True, False])}# 使用采样的参数创建RandomForestRegressor模型model = RandomForestRegressor(**params, random_state=42)# 使用训练数据拟合模型model.fit(X_train, y_train)# 使用验证集进行预测y_pred = model.predict(X_val)# 计算并返回均方误差(MSE),作为优化的目标return mean_squared_error(y_val, y_pred)# 创建Optuna的Study对象,并设置优化方向为“minimize”表示最小化均方误差study = optuna.create_study(direction="minimize")# 运行优化,进行100次试验study.optimize(objective, n_trials=100)print("Best parameters:", study.best_params)# 使用最佳参数重新训练模型best_model = RandomForestRegressor(**study.best_params, random_state=42)best_model.fit(X_train, y_train)

通过 Optuna 实现对随机森林回归模型的自动超参数优化。首先在 objective 函数中定义了多个关键超参数的搜索空间,包括树的数量、最大深度、最小样本分裂数、最小叶节点样本数、特征选择方式以及是否使用自助采样等。Optuna 在每一次试验中从这些参数空间中采样组合,并使用训练集训练模型、在验证集上评估性能,以均方误差(MSE)作为优化目标。经过 100 次试验后,Optuna 输出使 MSE 最小的最佳参数组合,随后使用该最优参数重新训练随机森林模型,为后续测试和分析提供更优的预测性能
输出结果显示,Optuna 优化后找到的最优随机森林参数组合为:构建 50 棵树(n_estimators=50)、最大深度为 9、每个节点至少包含 3 个样本才可分裂(min_samples_split=3)、叶节点最少 8 个样本(min_samples_leaf=8)、特征选择方式为 'log2',且不采用自助采样(bootstrap=False)
from sklearn.metrics import mean_squared_error, r2_scorefrom scipy.spatial.distance import jensenshannon# 在测试集上进行预测y_pred = best_model.predict(X_test)# 计算R²r2 = r2_score(y_test, y_pred)# 计算Pearson相关系数pearson_corr = np.corrcoef(y_test, y_pred)[0, 1]# 计算JSD(需要先标准化预测和实际值)# y_test_hist:将实际值(y_test)分成20个区间,并计算每个区间的频率y_test_hist, _ = np.histogram(y_test, bins=20, density=True) # 'bins=20'将数据分为20个区间,'density=True'使得每个区间的值归一化为概率密度# y_pred_hist:将预测值(y_pred)分成20个区间,并计算每个区间的频率y_pred_hist, _ = np.histogram(y_pred, bins=20, density=True) # 'bins=20'将数据分为20个区间,'density=True'使得每个区间的值归一化为概率密度# 计算JSDjsd = jensenshannon(y_test_hist, y_pred_hist)# 创建正方形画布fig, ax = plt.subplots(figsize=(6, 6), dpi=1200)# 绘制测试集散点ax.scatter(y_test, y_pred, color='#828282')# 添加 x=y 参考线(黑色虚线)x_min, x_max = min(y_test.min(), y_pred.min()), max(y_test.max(), y_pred.max())ax.plot([x_min, x_max], [x_min, x_max], 'k--')# 设置标签(英文)并加粗字体和增大字体ax.set_xlabel('True Value', fontsize=16, fontweight='bold')ax.set_ylabel('Predicted Value', fontsize=16, fontweight='bold')ax.set_title('RF Model', fontsize=18, fontweight='bold')# 添加网格线ax.grid(True)# 关闭图例ax.legend().set_visible(False)# 显示测试集评价指标在左上角,使用黑色字体test_metrics_text = f"R²: {r2:.3f}\nPearson's r: {pearson_corr:.3f}\nJSD: {jsd:.3f}"ax.text(0.05, 0.95, f"{test_metrics_text}", transform=ax.transAxes, fontsize=15, fontweight='bold',verticalalignment='top', horizontalalignment='left', color='black')plt.show()
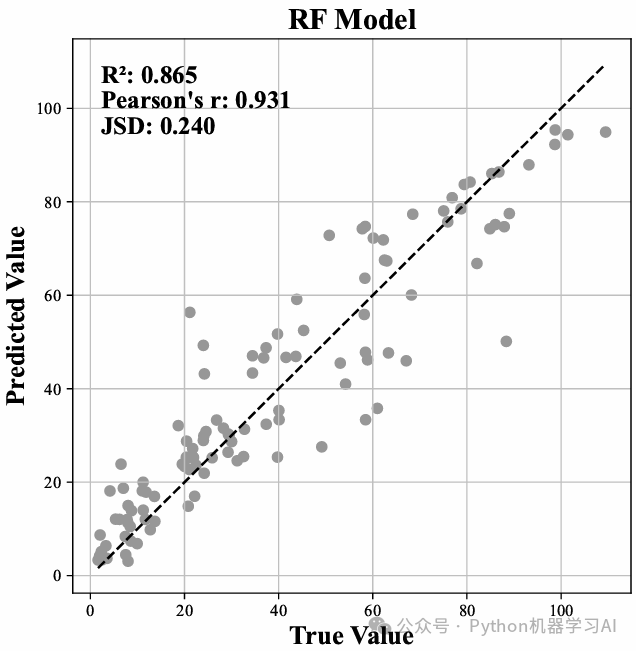
在测试集上评估并可视化了模型的预测性能。它首先使用最优参数训练得到的随机森林模型对测试集进行预测,并计算了常用的三个性能指标:R² 决定系数(衡量拟合优度)、Pearson 相关系数(衡量线性相关性)以及 Jensen-Shannon 距离(衡量预测分布与真实分布之间的差异)。随后绘制了真实值与预测值的散点图,添加了参考线(x=y)以直观反映预测精度,并将三个评价指标显示在图像左上角,为模型效果提供了直观和量化的解释
✨ 该文章案例 ✨

在上传至交流群的文件中,像往期文章一样,将对案例进行逐步分析,确保读者能够达到最佳的学习效果。内容都经过详细解读,帮助读者深入理解模型的实现过程和数据分析步骤,从而最大化学习成果。
同时,结合提供的免费AI聚合网站进行学习,能够让读者在理论与实践之间实现融会贯通,更加全面地掌握核心概念。
✨ 购买介绍 ✨
本节介绍到此结束,有需要学习数据分析和Python机器学习相关的朋友欢迎到淘宝店铺:Python机器学习AI,或添加作者微信deep_ML联系,购买作者的公众号合集。截至目前为止,合集已包含200多篇文章,购买合集的同时,还将提供免费稳定的AI大模型使用,包括但不限于ChatGPT、Deepseek、Claude等。
更新的内容包含数据、代码、注释和参考资料。作者仅分享案例项目,不提供额外的答疑服务。项目中将提供详细的代码注释和丰富的解读,帮助您理解每个步骤。购买前请咨询,避免不必要的问题。
✨ 群友反馈 ✨
✨

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)