
基于DeepSeek,在本地建立你的智能助手
随着信息技术的飞速发展,人工智能(AI)尤其是大模型技术,在各个行业和领域中扮演着越来越重要的角色。大模型,指的是那些参数量巨大的深度学习模型,它们能够处理复杂的数据结构,并提供更加精准、深入的分析结果。这些模型不仅推动了科学研究的进步,也在商业环境中展现了巨大潜力。DeepSeek等国产大模型的崛起,为企业提供了安全可控的智能化解决方案。Ollama作为一款支持本地运行的大模型工具,使得企业可以
随着信息技术的飞速发展,人工智能(AI)尤其是大模型技术,在各个行业和领域中扮演着越来越重要的角色。大模型,指的是那些参数量巨大的深度学习模型,它们能够处理复杂的数据结构,并提供更加精准、深入的分析结果。这些模型不仅推动了科学研究的进步,也在商业环境中展现了巨大潜力。
DeepSeek等国产大模型的崛起,为企业提供了安全可控的智能化解决方案。Ollama作为一款支持本地运行的大模型工具,使得企业可以更加高效地部署、集成和管理这些大模型应用。在本篇文章中,我们将通过Windows系统部署DeepSeek,并通过Spring Boot框架集成Java程序,构建智能助手。
一、行业应用:央国企
自2023年以来,国资委多次对中央企业发展人工智能提出要求。其中,在2024年2月的中央企业人工智能专题推进会上,提出中央企业要“开展AI+专项行动”。会上就有10家央企签署倡议书,表示将主动向社会开放人工智能应用场景。
同年7月,国新办举行“推动高质量发展”系列主题新闻发布会,提出未来五年,中央企业预计安排大规模设备更新改造总投资超3万亿元,更新部署一批高技术、高效率、高可靠性的先进设备。
当前,国资央企纷纷构建自己的行业大模型,典型如南方电网电力行业大模型“大瓦特”、中国石油能源行业大模型“昆仑大模型”。在行业大模型的基础之上,企业通常基于企业务特点构建领域专用大模型,在业务场景中发挥价值。

2023年9月,中核八所
发布自主研发的“龙吟”大模型2.0
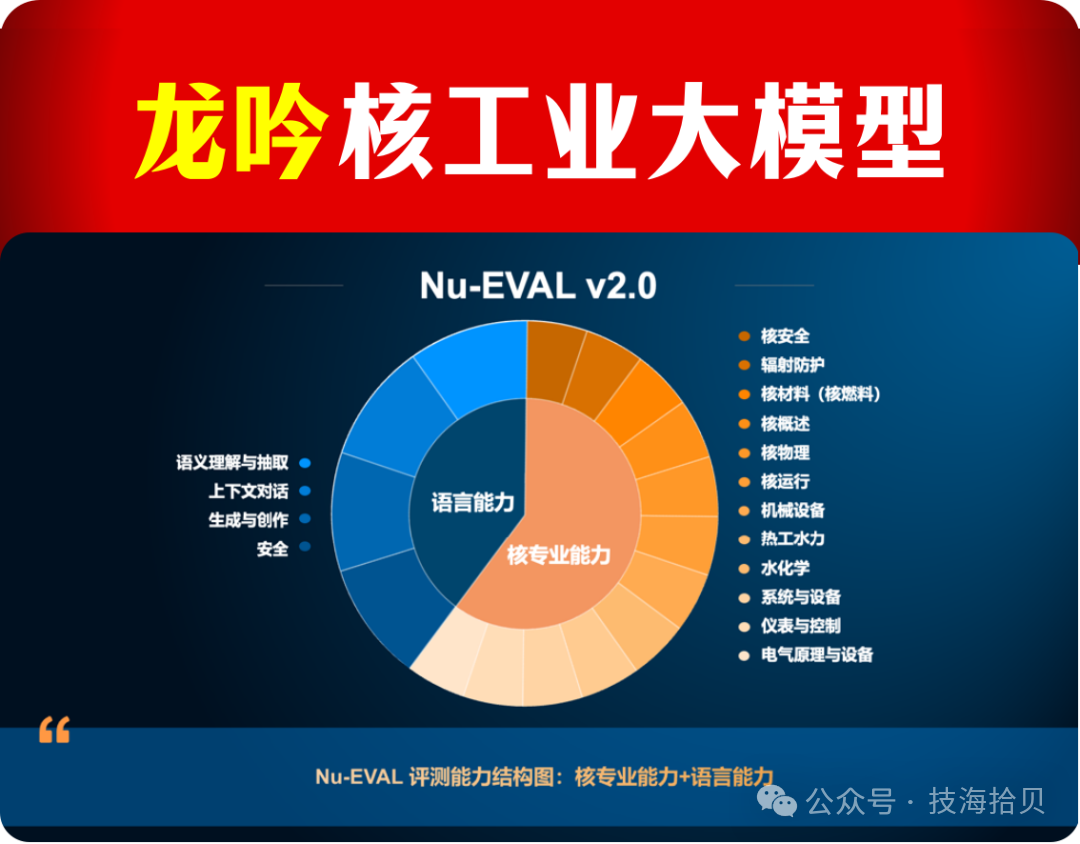
2024年3月,中核八所又发布了

2023年9月,中核八所发布自主研发的“龙吟”大模型2.0;2024年3月,中核八所又发布了龙吟·万界,龙吟·万界是集大模型智能体开发、应用、管理于一体的一站式企业服务平台,能够结合核工业各种业务场景快速设计开发并落地Nu Copilot系列数字助理。
中核八所发布了国内首个核领域大模型“龙吟以及首个核领域大模型应用平台“龙吟·万界”,在通用场景如法务、财务、知识管理等,以及核电设计、建造、运维等多个行业特有场景率先落地大模型应用。


✓5个专业场景模型:针对海上油田稳产增产、安全钻井、海工制造、设备维护、LNG(液化天然气)贸易、油气销售等场景,构建数据驱动、业务协同的新模式,进一步提升产业数智化水平
✓6个通用场景模型:针对招标采办、员工健康、辅助办公等需求推出智能应用,助力业务管理和办公效率提升

2024年7月
国家能源集团数智科技公司
发布自研的能源通道大模型

国家能源集团利用煤电化路港航各产业生产运营过程中的设备、货物、物流、销售、气象等数据,对通用大模型进行强化训练,建立具备增强知识潜能的能源通道行业大模型。以该模型认知能力为核心引擎,可构建以煤炭、电力、铁路、港口、航运、化工、销售生产运营计划为驱动的模型体系,形成智能查询与问答、智能平衡与调控、智能预警与通知、智慧分析与决策四大核心能力,全面支持集团实现“全景、共振、变易”的一体化运营调度,显著提高该集团煤电化运一体化运营决策效率和运营能力。
- 以该模型认知能力为核心引擎,可构建以煤炭、电力、铁路、港口、航运、化工、销售生产运营计划为驱动的模型体系,形成智能查询与问答、智能平衡与调控、智能预警与通知、智慧分析与决策四大核心能力。
- 全面支持集团实现“全景、共振、变易”的一体化运营调度,显著提高集团煤电化运一体化运营决策效率和运营能力。
✓以该模型认知能力为核心引擎,可构建以煤炭、电力、铁路、港口、航运、化工、销售生产运营计划为驱动的模型体系,形成智能查询与问答、智能平衡与调控、智能预警与通知、智慧分析与决策四大核心能力
✓全面支持集团实现“全景、共振、变易”的一体化运营调度,显著提高集团煤电化运一体化运营决策效率和运营能力

2023年8月,中航信移动科技有限公司
发布自主研发的“千穰”大模型

✓多应用场景:“千穰”融合了视觉大模型、语言大模型、多模态大模型和计算大模型,可在机坪、航站楼、旅客服务等多种应用场景下,满足民航运行、服务和监管需求
✓成功应用:航旅纵横App、多家民航主要机构

2024年8 月
中国石油发布 330 亿参数昆仑大模型

昆仑大模型
中国石油在2024年5月发布了昆仑大模型,昆仑大模型建设包含语言、视觉、多模态及科学计算大模型,其中语言大模型用于文本内容理解、生成,视觉大模型用于图像分类、分割和检测,多模态大模型用于文/图/音混合检索、生成,科学计算大模型采用Transformer算法解决海量数据建模问题。
地震解释大模型
地震解释大模型由勘探开发研究院主导研发,研发团队利用海量地震数据,通过深度神经网络算法,训练形成了具有构造解释、缝洞体预测、岩性识别等地震智能解释功能的AI大模型,模型参数达到50亿规模。
地震解释大模型的成功发布,代表了勘探院在人工智能应用领域迈出了重要一步,也是服务国家战略、响应集团号召、推动行业技术进步的生动实践。
PetroAI大模型
2024年1月,中国石油勘探开发研究院发布了自主研发的AI大语言模型PetroAI。这是油气勘探开发领域迄今上线最早、规模大、功能强的油气行业大语言模型。
✓大模型训练方面,
训练发布不同层次、不同类型、不同尺寸的 8 个大模型,以满足不同业务场景需求。
✓行业大模型方面,
发布 130 亿参数、330 亿参数的语言大模型,以及 3 亿参数的视觉大模型,行业知识问答、概念理解、论文摘要生成、工业视觉理解等专业能力有效提升;
✓专业大模型方面,
发布 50 亿参数地震解释和 1 亿参数测井处理解释两个具有专业特色的大模型,智能化应用取得明显成效;
✓场景大模型方面,
发布 130 亿参数智能问数、3 亿参数设备识别、160 亿参数客户营销 3 个大模型,支撑智能运营问数、图文生成等业务需求
WisGPT大模型
2024年2月,中国石油管道局设计院与百度成立的合资公司发布了国内首个油气储运领域人工智能大模型WisGPT,可以通过文字、语音等多种形式实现人机交互,为企业实现数字化管理以及油气储运工程勘察、设计、施工、运行等提供智能支持。
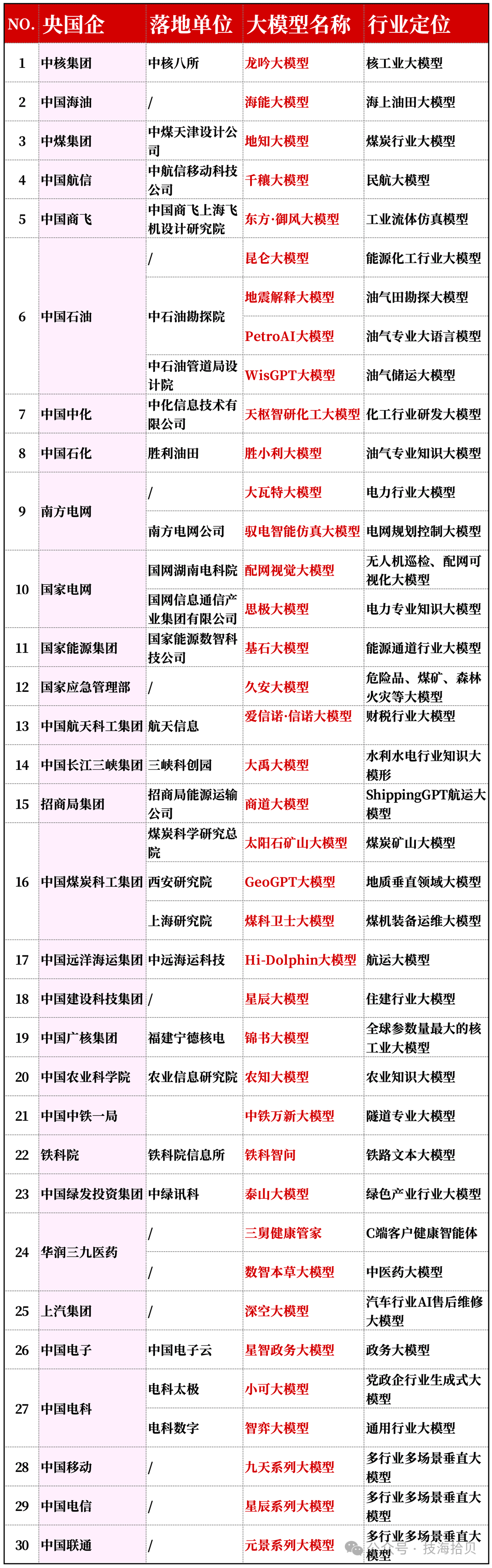
汇总30家央国企:
二、环境准备
在开始部署和集成之前,确保您的开发环境满足以下要求。这包括操作系统、软件工具和硬件配置等。
1. 操作系统要求
- 操作系统版本: Windows 10或11(建议使用Windows 10 64位版本)
2. 软件工具要求
2.1. *Ollama*
- Ollama版本: 目前支持Windows平台的稳定版本。(安装部署,可参考之前文章:Ollama-AI大模型本地运行工具,Windows安装详细步骤: https://blog.csdn.net/qq_17153885/article/details/141833715?spm=1001.2014.3001.5502)
2.2. *集成开发环境(IDE)*
- 推荐IDE: IntelliJ IDEA(IDEA)
2.3. *Java Development Kit (JDK)*
- JDK版本要求: Java 8及以上版本(推荐使用JDK 17)
3.*硬件要求*
- 至少16GB RAM(推荐32GB以上)。
- 至少50GB可用存储空间
三、下载运行DeepSeek
3.1 启动Ollama并验证
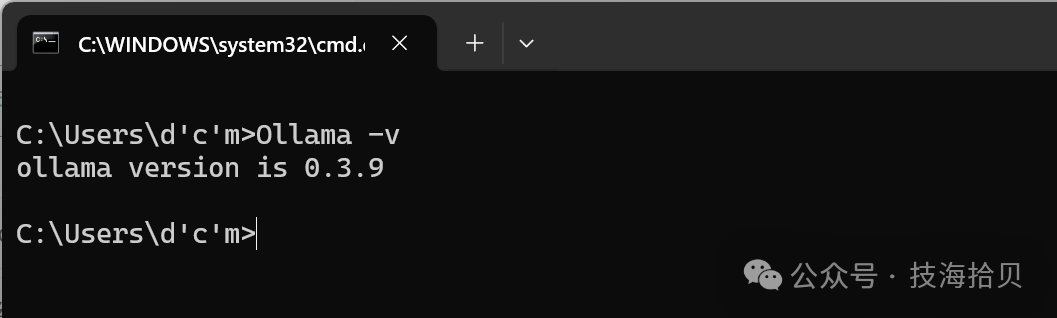
双击Ollama启动服务

验证
进入cmd或PowerShell界面,输入如下命令,显示版本则安装成功
3.2 下载运行DeepSeek模型
进入Ollama官网,模型列表页面,搜索deepseek,这里选择deepseek-r1
https://ollama.com/search
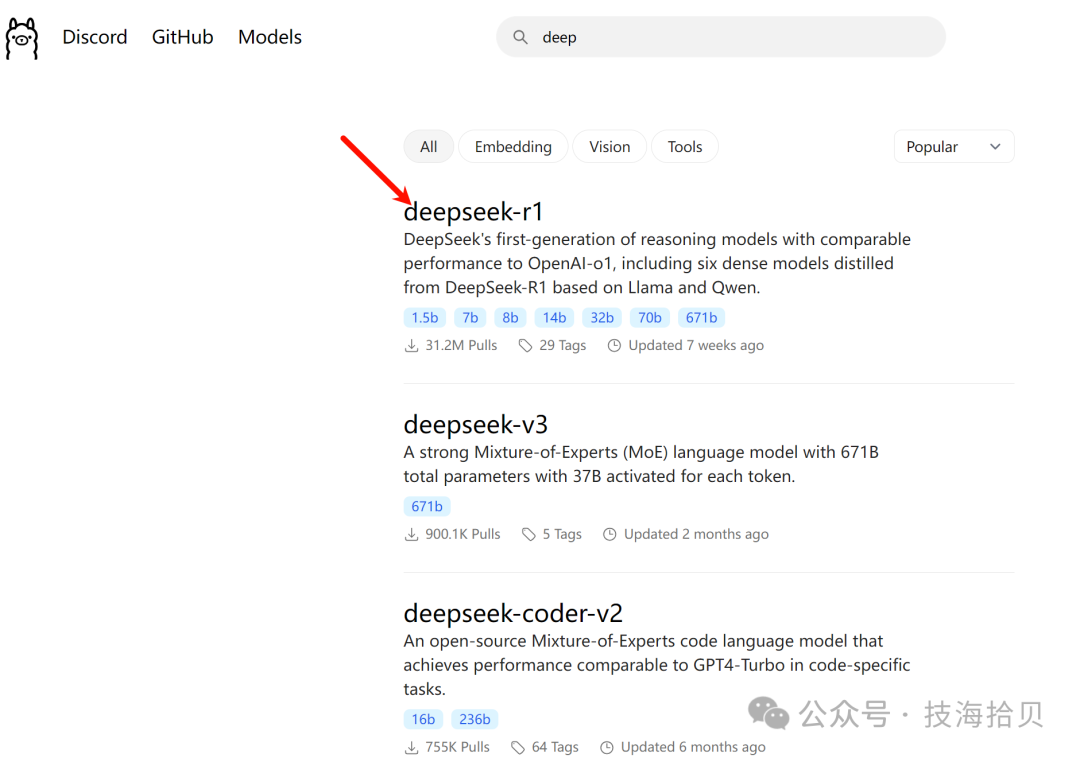
选择模型参数,可以看到671b 满血模型,有404GB。因为本地电脑性能有限,这里选择7b(1.5b版本性能有限)。
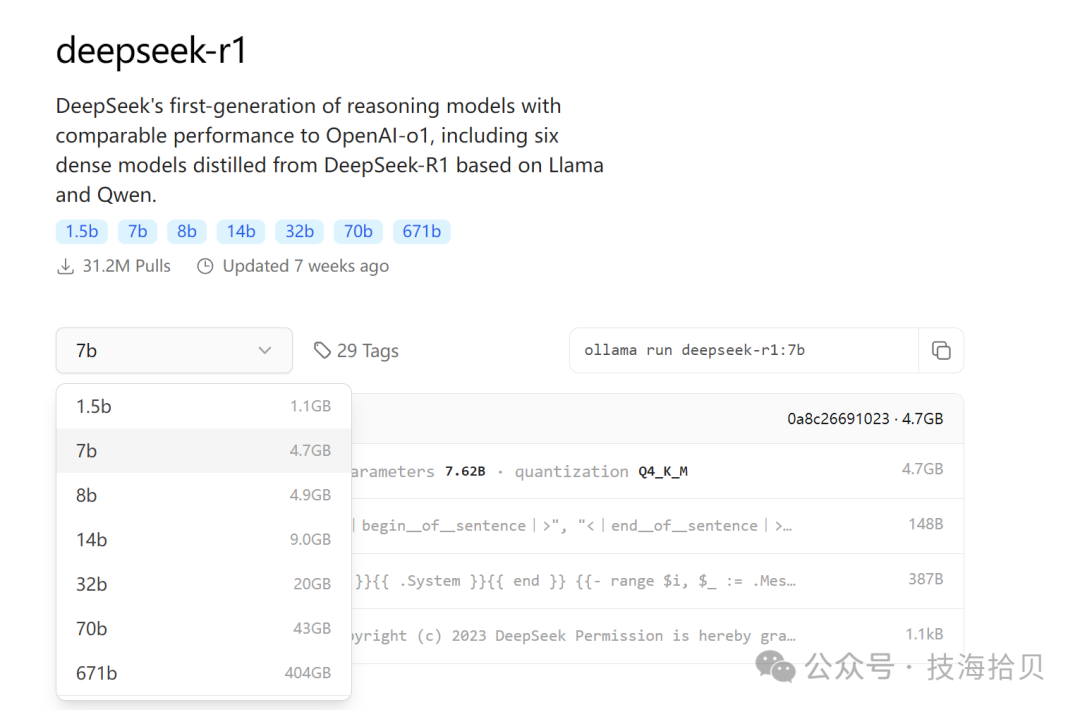
复制右侧命令,在cmd下载并运行模型
ollama run deepseek-r1:7b
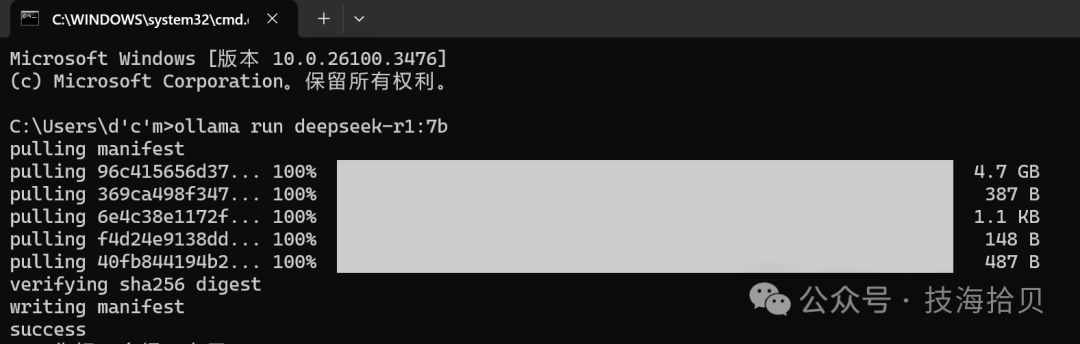
下载完成后自动运行,出现success则代表成功
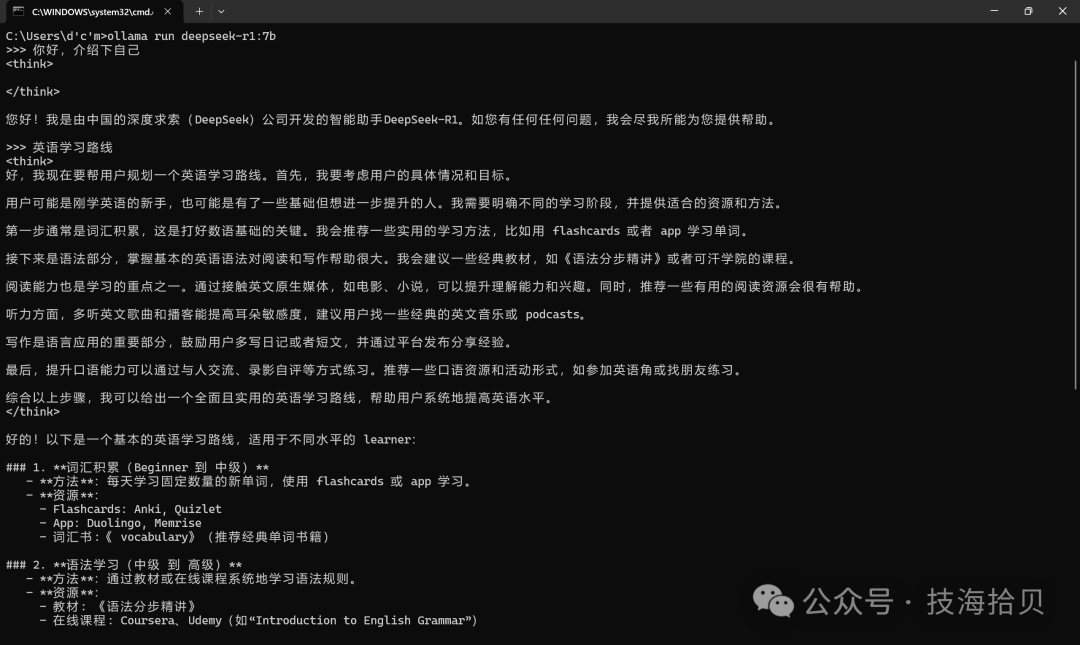
3.3 测试DeepSeek
运行命令后会自动进入对话界面,直接输入内容即可与模型聊天:
四、集成应用
创建一个基于Spring Boot的Java项目,并集成Ollama以调用DeepSeek模型。
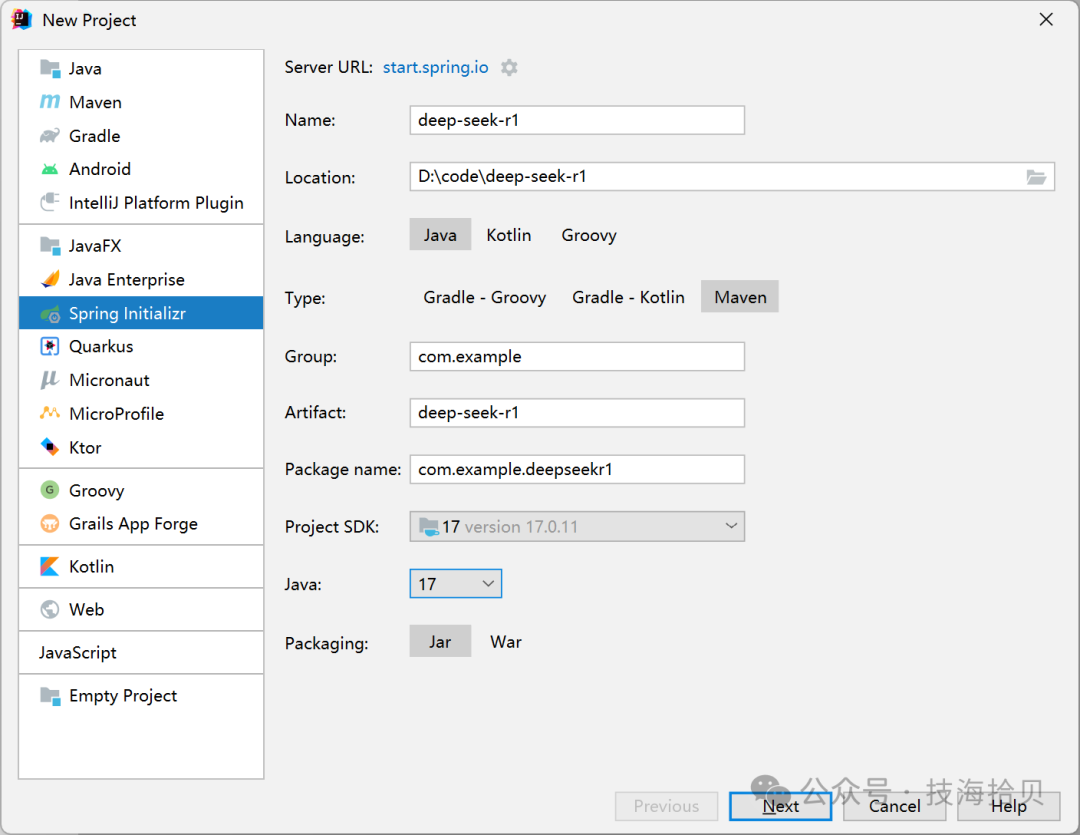
4.1 新建Spring Boot项目
打开IDEA,选择新建项目选项,选择Spring Initializr作为项目创建工具。填写项目的基本信息,如Group Id、Artifact Id、项目名称等。确保选择Java语言,并指定项目的版本号。在选择依赖项时,添加Web依赖,以便后续创建API接口。
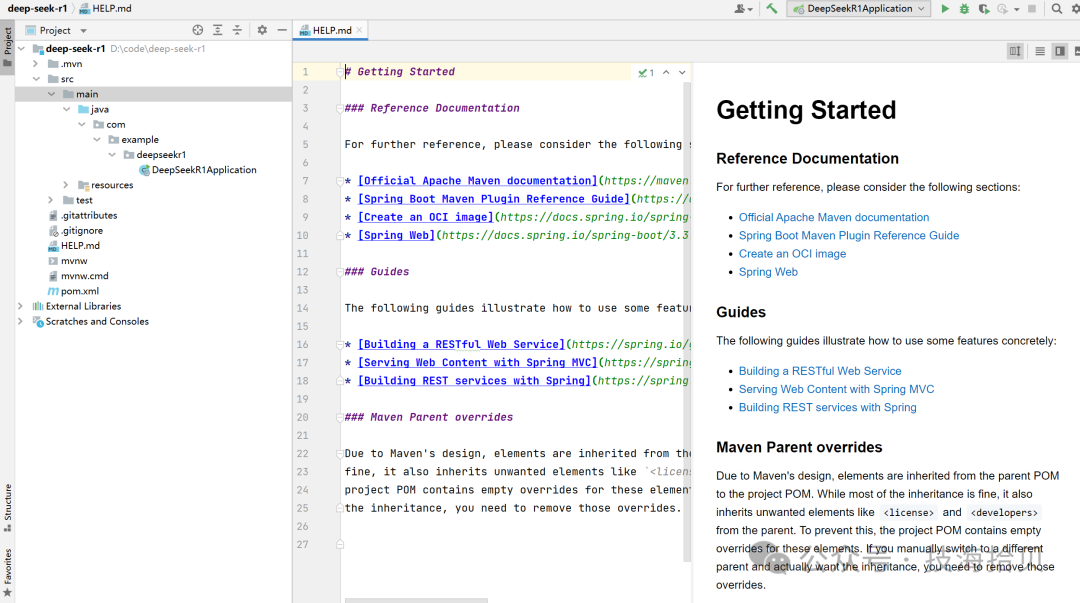
4.2 添加依赖
在项目生成后,打开pom.xml文件,这是Maven项目的核心配置文件。需要在此文件中添加Ollama的相关依赖。
由于Ollama并非标准库,可能需要手动添加其maven仓库地址(建议阿里云maven地址)。
<dependency>
<groupId>io.springboot.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
配置后,maven reload操作,下载对应的依赖
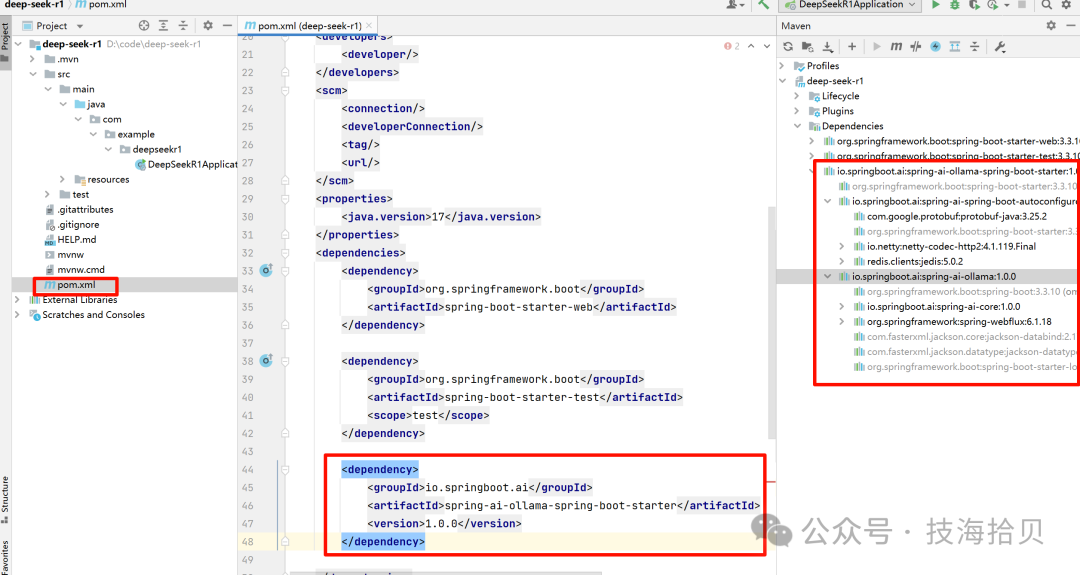
4.3 新增Ollama配置信息
在 SpringBoot 配置文件application.properties中增加 Ollama 配置信息:
server.port=8099
spring.application.name=deep-seek-r1
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.options.model=deepseek-r1:7b
Ollama安装后默认启动服务,监听端口为 11434
4.4 编写控制器代码
在Spring Boot项目中创建一个控制器类,如OllamaClientController.java,用于定义RESTful API接口。通过此接口,前端或其他服务可以调用DeepSeek模型的服务。

使用OllamaChatClient进行文字生成或者对话
package com.example.deepseekr1.demo;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.ollama.OllamaChatClient;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/ollama/chat")
publicclass OllamaClientController {
@Resource
private OllamaChatClient ollamaChatClient;
/**
* http://localhost:8099/ollama/chat/v1?msg=大海为什么是蓝色的?
*/
@PostMapping("/v1")
public String ollamaChat(@RequestParam String msg) {
return ollamaChatClient.call(msg);
}
/**
* http://localhost:8099/ollama/chat/v2?msg=计算机学习路线
*/
@PostMapping("/v2")
public Object ollamaChatV2(@RequestParam String msg) {
Prompt prompt = new Prompt(msg);
ChatResponse chatResponse = ollamaChatClient.call(prompt);
return chatResponse;
}
/**
* http://localhost:8099/ollama/chat/v3?msg=公众号:技海拾贝,介绍
*/
@PostMapping("/v3")
public Object ollamaChatV3(@RequestParam String msg) {
Prompt prompt = new Prompt(
msg,
OllamaOptions.create()
.withModel("qwen2:0.5b")
.withTemperature(0.4F));
ChatResponse chatResponse = ollamaChatClient.call(prompt);
return chatResponse.getResult().getOutput().getContent();
}
}
还可以指定模型回答,这里v3接口调用qwen2:0.5b模型(调用时,把该模型启动运行)。
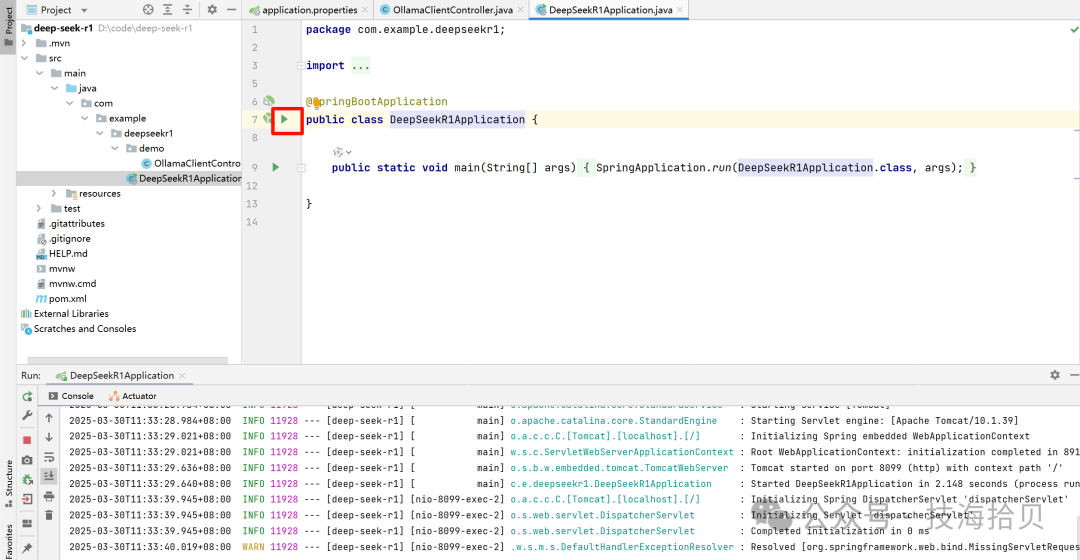
4.5 启动服务
4.6 测试
在完成了Spring Boot项目的搭建和DeepSeek服务的集成,并启动服务后,下一步就是确保API接口能够正确地调用DeepSeek模型。为了实现这一点,使用Apifox这款API测试工具来进行接口测试
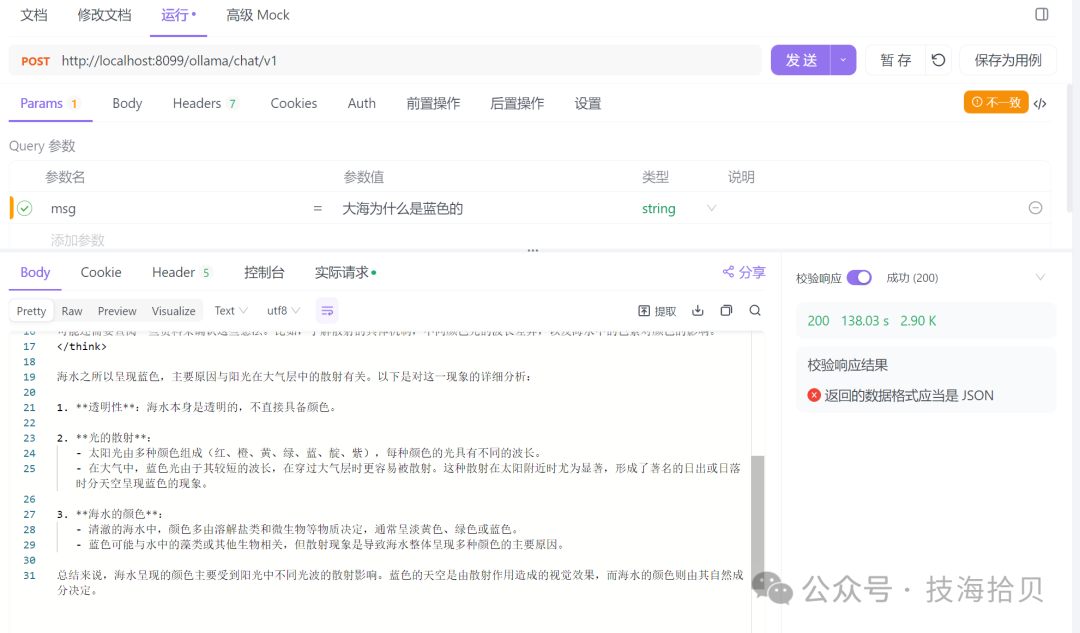
这个输入:大海为什么是蓝色的,点击发送,将会被传递给DeepSeek模型进行处理。Body返回回答内容。
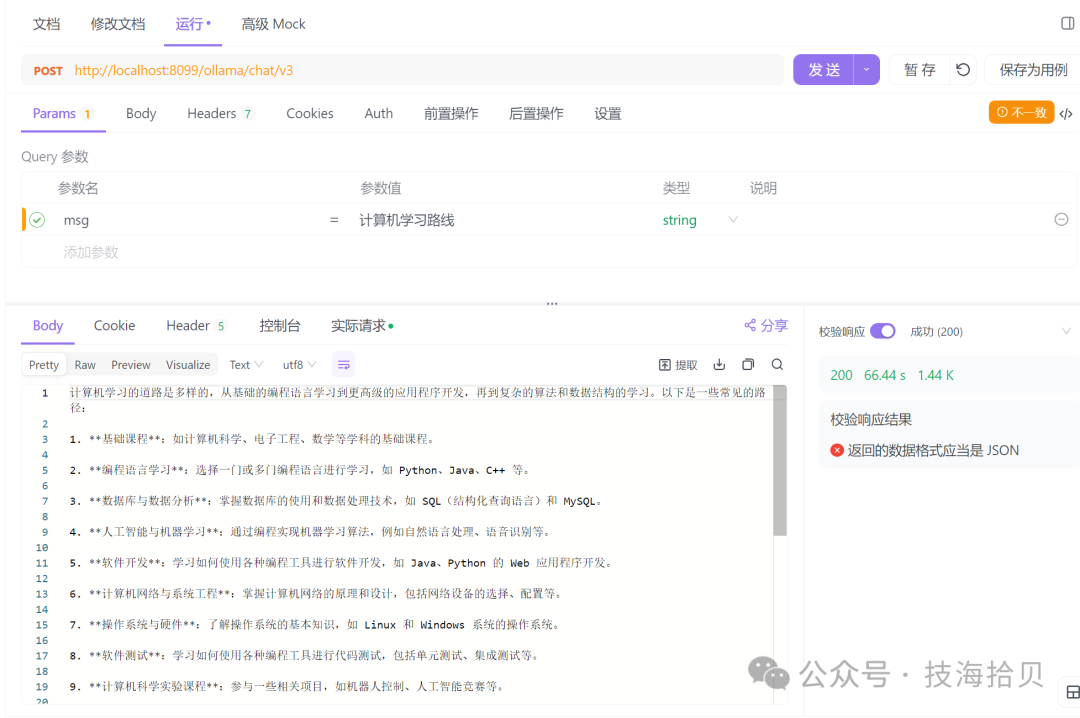

没有联网,基于本地的知识库,找不到
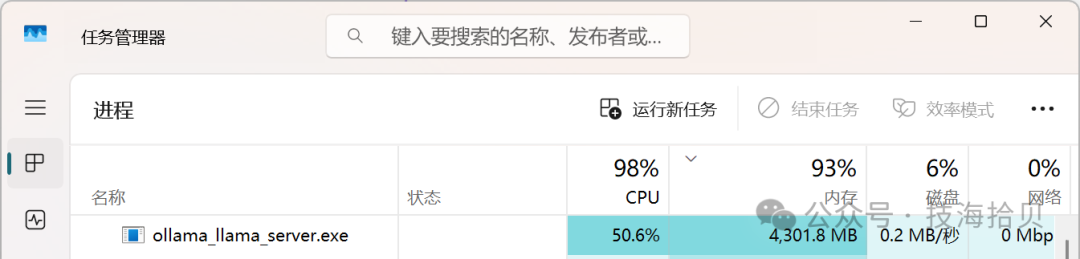
拓展:在发起请求后,可以看到本地CPU、内存几乎完全占用。当询问复杂问题时,出现比较长时间没有响应,这就需要更高的算力。
五、结束语
至此,我们已经成功在Windows本地部署了Ollama,并将DeepSeek模型集成到Spring Boot应用中,通过API接口进行了交互测试。在实际应用中,需要更友好的用户界面来与DeepSeek进行交互,后续将使用Cursor工具来创建Web界面,能够更加直观地与DeepSeek模型互动。
随着技术的不断进步,集成大模型到企业应用中将变得越来越普遍,未来的大模型将为企业提供更多的创新机会,帮助企业在数据驱动的时代中抢占先机。
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)