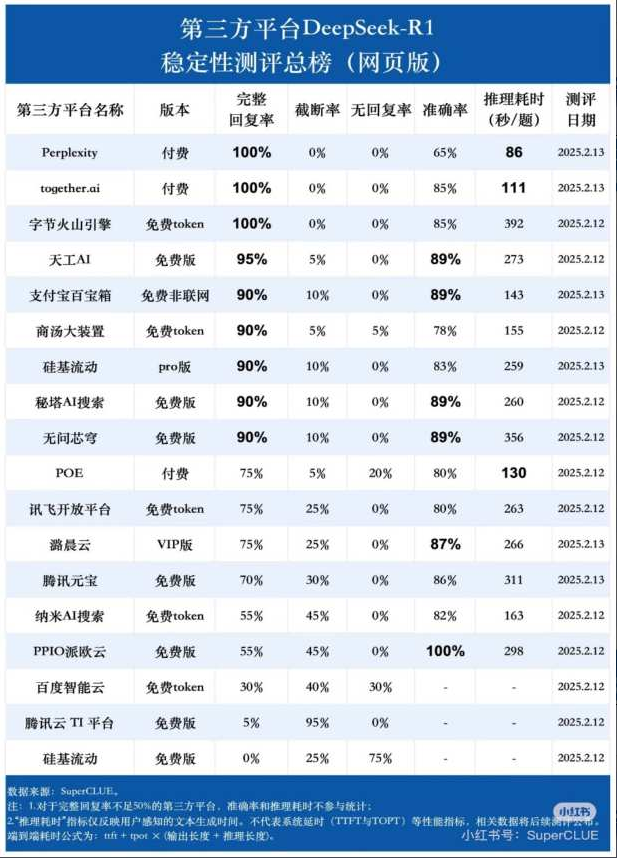
DeepSeek完全实用手册——DeepSeek一体机汇总
DeepSeek R1模型可通过云端调用和本地部署的方式使用。
·
DeepSeek R1模型可通过云端调用和本地部署的方式使用
内容来源《至顶AI实验室——DeepSeek完全实用手册》白皮书
云端调用
- •云端调用,可通过官方API或第三方API直接调用DeepSeek R1模型服务并接入业务中;或者可以在云平台上创建、部署、微调
模型,再通过API连接模型调用。 - •云端调用优势在于,用户无需购置硬件即可按需调用云端模型。
本地部署
- 要本地运行模型,用户需下载DeepSeek R1满血版或蒸馏版本模型,通过Ollama、vLLM等工具启动模型,并借助可视化界面工
具与用户交互。 - 本地部署优势在于无网络依赖,适合对数据安全要求高的企业私有化场景,但需满足高性能显卡和服务器的硬件配置要求。
云端调用

成本
软件或应用
- 接入的DeepSeek R1普遍为免费使用,但使用次数可能受限。
API服务
- DeepSeek官方:R1模型每百万token,输入价格为1元(命中缓存)或4元(未命中缓存),输出价格为16元
- 硅基流动:R1模型每百万token,输入价格为4元,输出价格为16元。
云平台
- 偏向为企业级用户服务,各云平台服务类型丰富收费不一,以百度智能云为例,与DeepSeek R1相关的服务包括:平台预置服
务调用、用户部署模型服务调用、模型精调、批量预测等。 - 在百度智能云直接调用R1模型API,每百万token输入价格2元,输出价格8元。
- 在阿里云直接调用R1模型API,每百万token输入价格4元,输出价格16元。
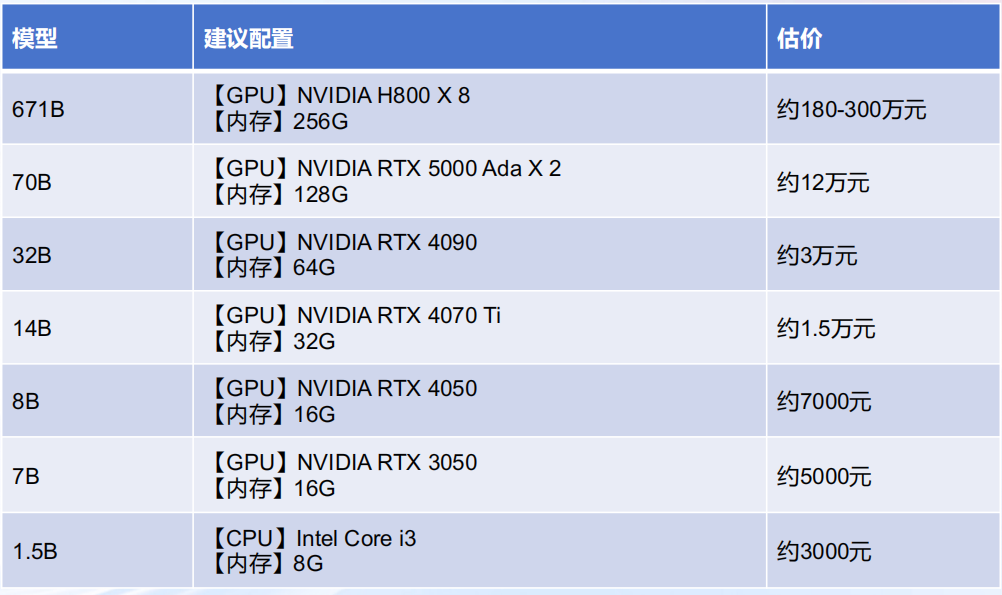
满血版R1模型
- 参数量为671b
- 显存需求:16位满血版约1300G显存
- 硬件建议:4台8卡昇腾910B服务器及以上,或2台英伟达H800服务器及以上
蒸馏版R1模型
- 是以Llama模型或Qwen模型作为基座模型,蒸馏训练出的推理模型
- 有1.5b、7b、8b、14b、32b、70b不同参数量的版本
- 显存需求&硬件建议(Ollama 4位量化版为例):

本地部署实测
-
主机:Dell Precision 5860塔式工作站
-
硬件:
– 【 GPU 】 NVIDIA RTX 5000 Ada X 2 ( 64G VRAM)
– 【 CPU 】 intel xeon w5 2445x
– 【内存】 128G RAM -
环境:模型平台Ollama,可视化界面OpenWebUI
-
模型:Ollama官网4位量化版DeepSeek R1蒸馏模型
测试结果:

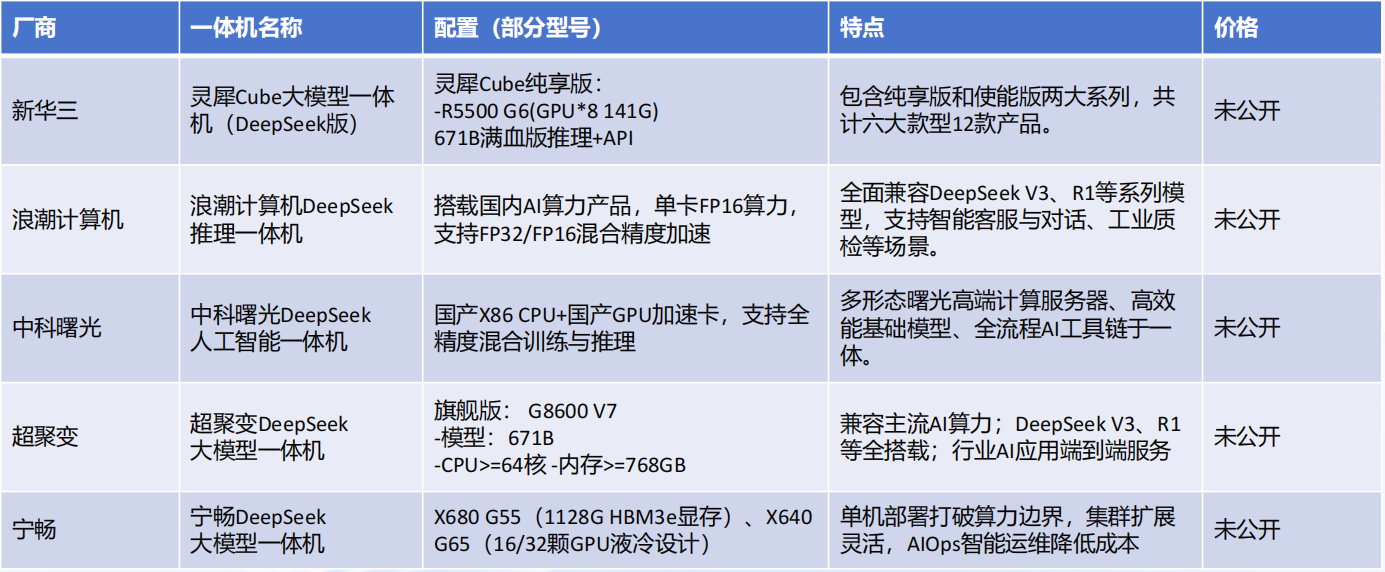
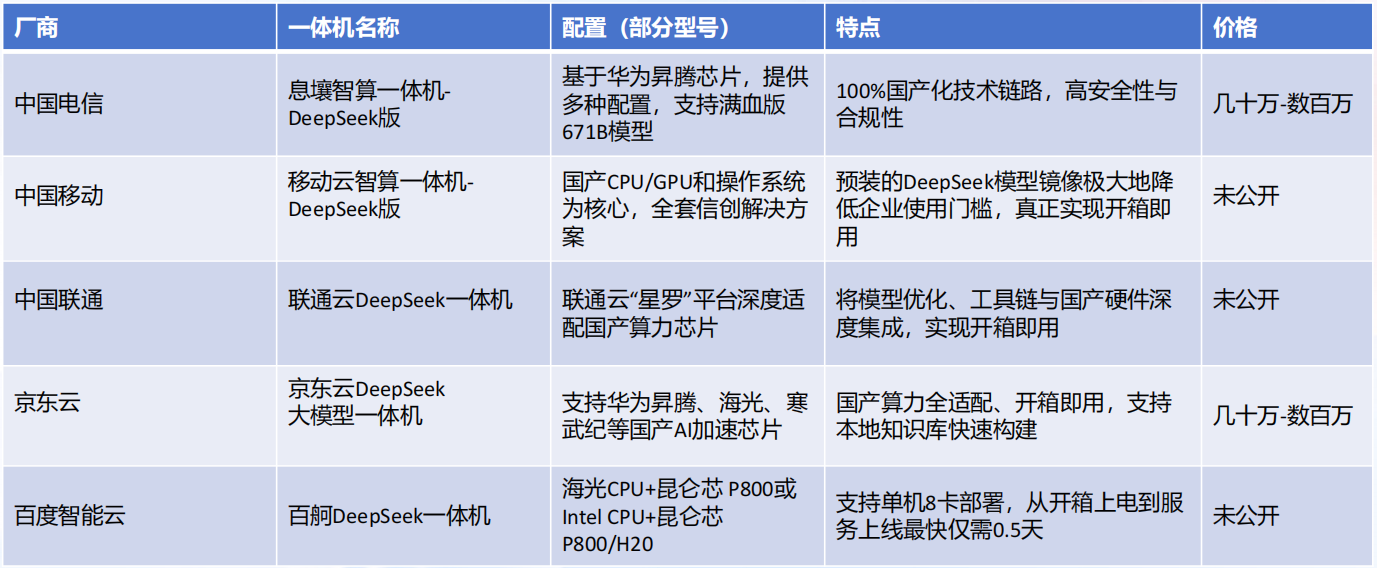
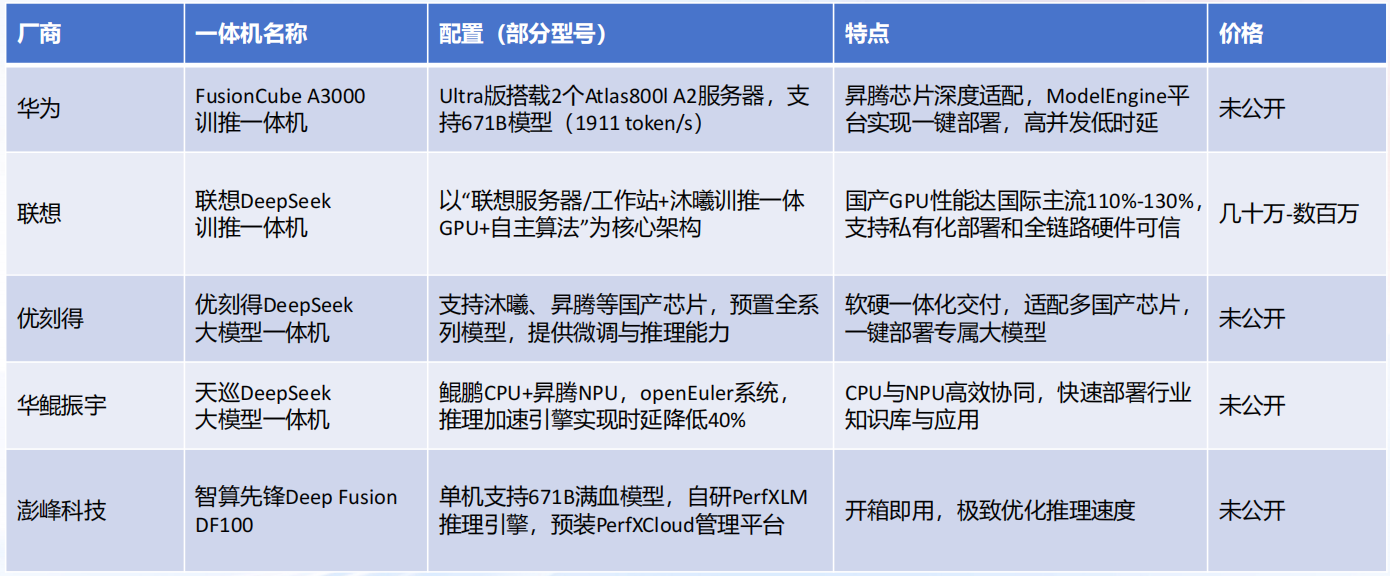
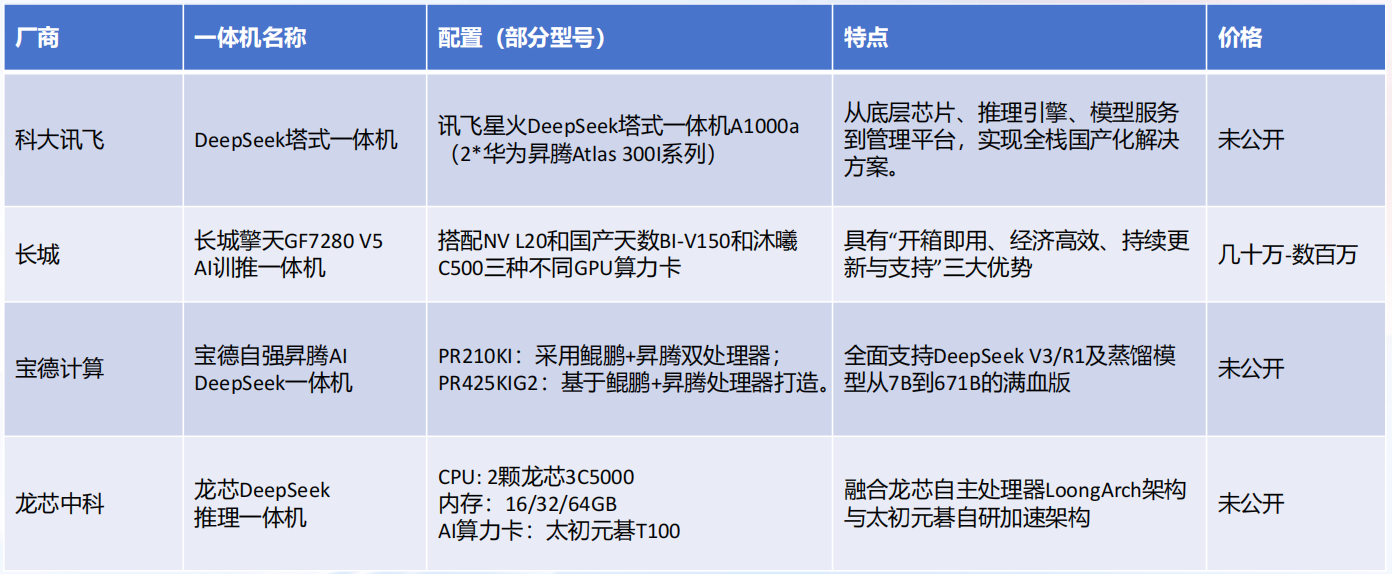
部署DeepSeek一体机汇总

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)