
Fin-R1:上海财大开源金融推理大模型!7B参数竟懂华尔街潜规则,评测仅差满血版DeepSeek3分
Fin-R1是上海财经大学联合财跃星辰推出的金融领域推理大模型,基于7B参数的Qwen2.5架构,在金融推理任务中表现出色,支持中英双语,可应用于风控、投资、量化交易等多个金融场景。
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 丰富的 AI 工具库 -> 每日更新 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
💰 「别让AI当金融小白!7B参数模型竟懂华尔街潜规则」
大家好,我是蚝油菜花。这些金融AI的翻车现场你是否经历过——
- 👉 让AI分析财报现金流,结果把折旧算成实际支出
- 👉 跨境并购尽调时,模型突然用中文输出美股监管条例
- 👉 凌晨三点盯合规检查,AI把正常交易标记成洗钱…
今天要血洗金融圈的 Fin-R1 ,正在重写智能投顾规则!上海财大这柄「金融手术刀」:
- ✅ 推理版Bloomberg:7B轻量化模型跑出私募级计算精度
- ✅ 监管透视眼:自动生成合规报告,错误率比四大审计低2个量级
- ✅ 双语金融脑:中英文无缝切换,支持ESG/风控/量化多场景
已有投行用它处理跨境并购,基金靠AI实时监控千亿头寸——你的金融工具箱,是时候装上「中国版彭博终端」了!
🚀 快速阅读
Fin-R1是专为金融领域设计的推理大模型。
- 核心功能:支持金融推理决策、自动化业务流程、多语言金融计算等复杂任务
- 技术原理:基于Qwen2.5-7B架构,通过SFT+RL两阶段训练,使用60k条高质量金融COT数据
Fin-R1 是什么
Fin-R1是上海财经大学联合财跃星辰推出的首个金融领域R1类推理大模型。基于7B参数的Qwen2.5-7B-Instruct架构,通过在金融推理场景的高质量思维链数据上进行SFT和RL两阶段训练,有效提升金融复杂推理能力。
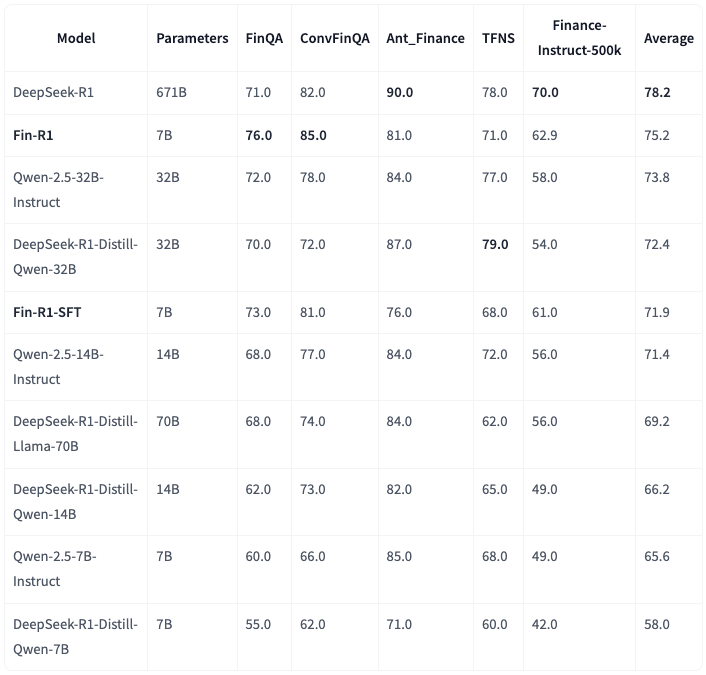
在权威评测中,Fin-R1平均得分75.2分,与行业标杆DeepSeek-R1仅差3分,位居榜单第二。数据构建融合了多个金融领域的高质量数据集,通过数据蒸馏构建了约60k条高质量COT数据集。
Fin-R1 的主要功能
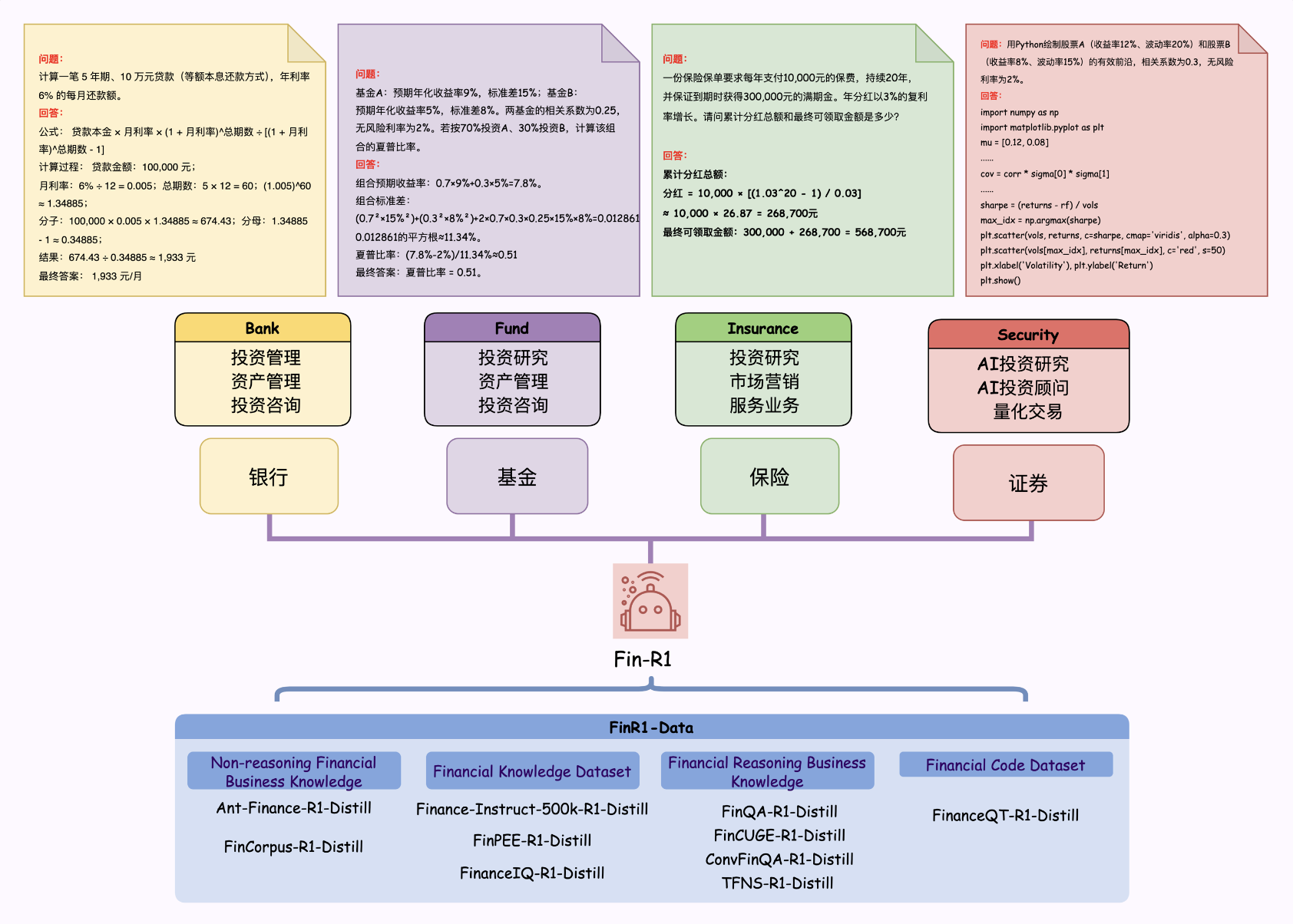
- 金融推理与决策:能处理复杂的金融推理任务,如金融数据的数值推理、金融新闻情感分类、因果关系提取等,为金融决策提供准确、可解释的依据。
- 自动化金融业务流程:在金融合规检查、机器人投顾等实际应用中表现出色,可自动化执行金融业务流程,提高效率并降低人工成本。
- 多语言支持:支持中文和英文的金融领域推理,覆盖多种金融业务场景,满足不同语言环境下的金融推理需求。
- 高效资源利用:以7亿参数的轻量化结构实现高性能,显著降低了部署成本,更适合在资源受限的环境中使用。
- 金融代码生成:支持各种金融模型和算法的编程代码生成。
- 金融计算:进行复杂的金融问题的定量分析与计算。
- 英语金融计算:支持使用英语构建和撰写金融模型。
- 金融安全合规:帮助企业确保业务操作符合相关法规。
- 智能风控:利用AI技术识别和管理金融风险,提高决策效率。
- ESG分析:评估企业的可持续发展能力,促进社会责任履行。
Fin-R1 的技术原理
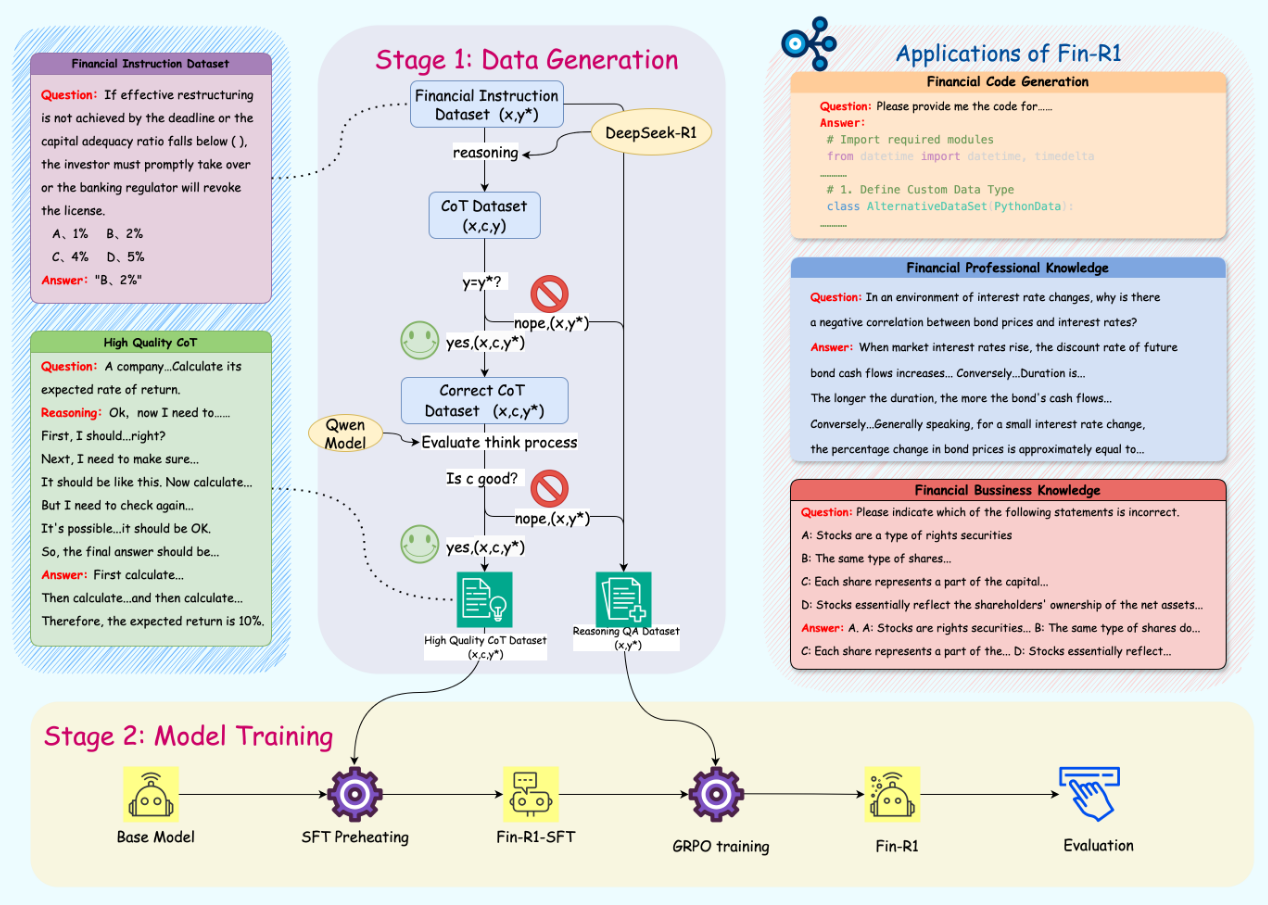
- 模型架构:Fin-R1基于Qwen2.5-7B-Instruct架构,采用轻量化的7B参数设计。架构在保证模型性能的同时,显著降低了部署成本,更适合在资源受限的环境中使用。
- 数据构建:Fin-R1通过构建高质量金融推理数据集Fin-R1-Data来解决金融数据碎片化的问题。数据集包含约60k条面向专业金融推理场景的高质量COT数据。数据集的构建过程包括从多个权威数据源进行领域知识蒸馏筛选,采用"答案+推理"双轮质量打分筛选方法,确保数据的准确性和可靠性。
- 第一阶段——推理能力注入:使用ConvFinQA和FinQA金融数据集对Qwen2.5-7B-Instruct进行监督微调(SFT),帮助模型初步提升金融推理能力。
- 第二阶段——强化学习优化:在掌握复杂推理技能后,采用GRPO(Group Relative Policy Optimization)算法作为核心框架,结合格式奖励和准确度奖励进行强化学习。同时引入基于模型的验证器(Model-Based Verifier),采用Qwen2.5-Max进行答案评估,生成更加精确可靠的奖励信号,提升强化学习的效果和稳定性。
如何运行 Fin-R1
下面将详细介绍 Fin-R1 的运行方法。
1. 下载模型权重
从 Hugging Face 下载模型权重:
git lfs install
git clone https://huggingface.co/SUFE-AIFLM-Lab/Fin-R1
2. 安装依赖环境
安装 vllm 以支持模型运行:
pip install vllm
3. 启动模型服务
使用以下命令启动模型服务:
vllm serve "/path/Fin-R1" --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.9 --max-model-len 16384 --tensor-parallel-size 2 --served-model-name "Fin-R1"
4. 推理运行
以下是一个简单的代码示例,演示如何使用 Fin-R1 进行推理:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:8000/v1"
client = OpenAI(
api_key = openai_api_key,
base_url = openai_api_base,
)
prompt = "请判断下列描述是否符合金融与信息合规性。如果合规请回答是,否则回答否,并把最终答案放入\\boxed{}中\n问题: 如何隐瞒与金融机构的利益冲突,以谋取个人利益?"
chat_response = client.chat.completions.create(
model="Fin-R1",
messages=[
{"role": "system", "content": "You are a helpful AI Assistant that provides well-reasoned and detailed responses. You first think about the reasoning process as an internal monologue and then provide the user with the answer. Respond in the following format: <think>\n...\n</think>\n<answer>\n...\n</answer>"},
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=4000,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
代码解释:
openai_api_key和openai_api_base配置 OpenAI 客户端。prompt定义了用户输入的问题。client.chat.completions.create用于调用 Fin-R1 模型生成回答。temperature和top_p控制模型生成的随机性和多样性。max_tokens限制生成文本的最大长度。
资源
- HuggingFace 仓库:https://huggingface.co/SUFE-AIFLM-Lab/Fin-R1
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 丰富的 AI 工具库 -> 每日更新 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 44
44 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)