
代码生成天花板?DeepSeek发布V3-0324新版本,性能超越gpt4.5和claude-3.7
未来,随着DeepSeek-R2模型的发布,我们有理由相信,DeepSeek将继续在人工智能领域保持领先地位,并推动整个行业的技术进步。DeepSeek-V3-0324的发布,不仅是DeepSeek在技术上的又一次突破,也为人工智能行业带来了新的发展机遇。未来,随着更多企业和开发者的加入,DeepSeek-V3-0324必将在人工智能领域发挥更加重要的作用,推动整个行业迈向新的高度。DeepSee
DeepSeek,作为人工智能领域的重要参与者,就在昨天,其发布了V3模型的小版本更新——DeepSeek-V3-0324。
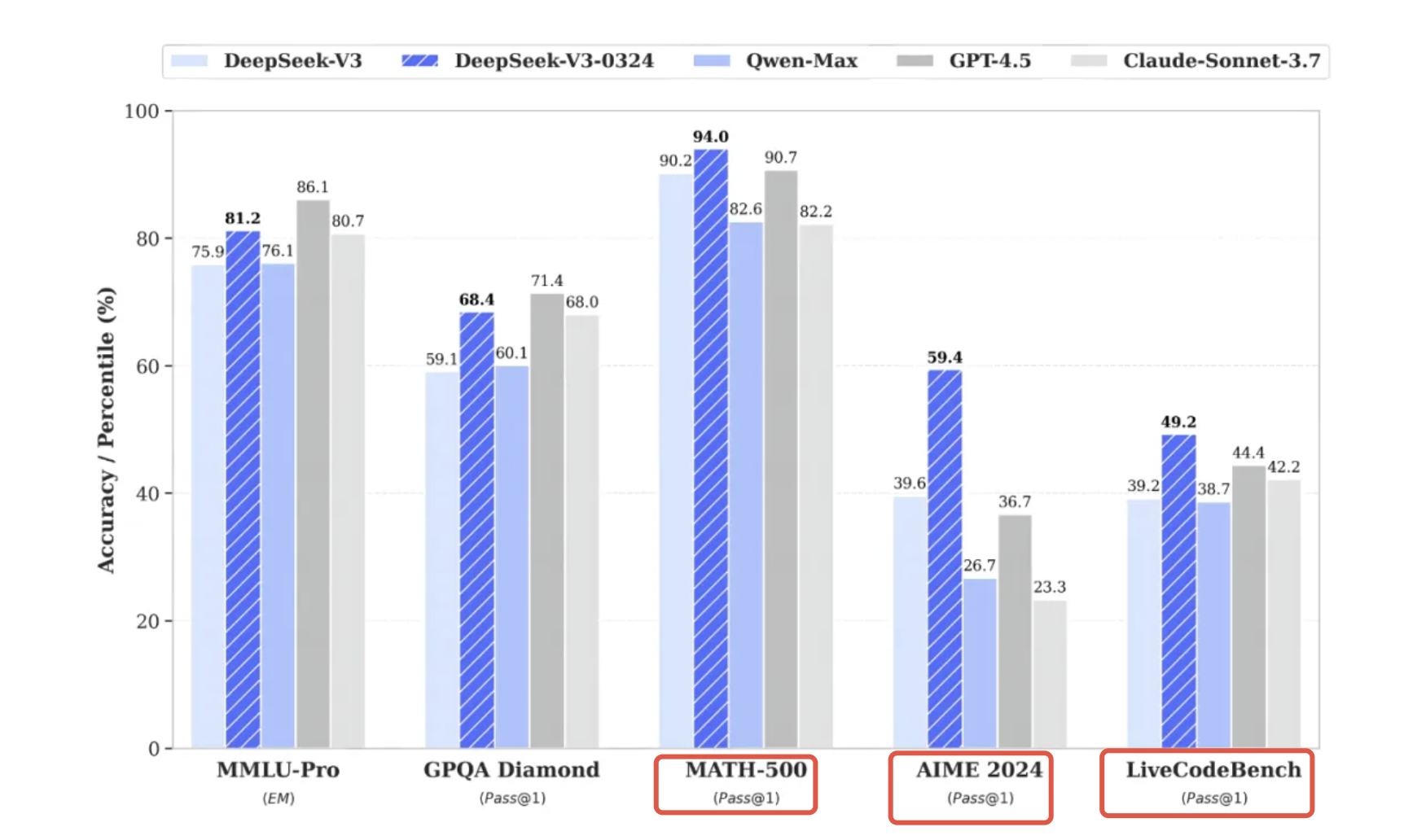
这一更新虽然并非市场期待的V4或R2版本,但在性能和应用场景上却带来了显著的提升。根据官网描述(DeepSeek-V3 模型更新,各项能力全面进阶 | DeepSeek API Docs):新版 V3 模型借鉴 DeepSeek-R1 模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过 GPT-4.5 的得分成绩。
本文将深入探讨此次更新的核心亮点、技术细节以及对行业可能产生的影响。
核心亮点
参数规模与性能提升
DeepSeek-V3-0324模型的**参数量达到了6850亿**(hugging face模型开源地址:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324)
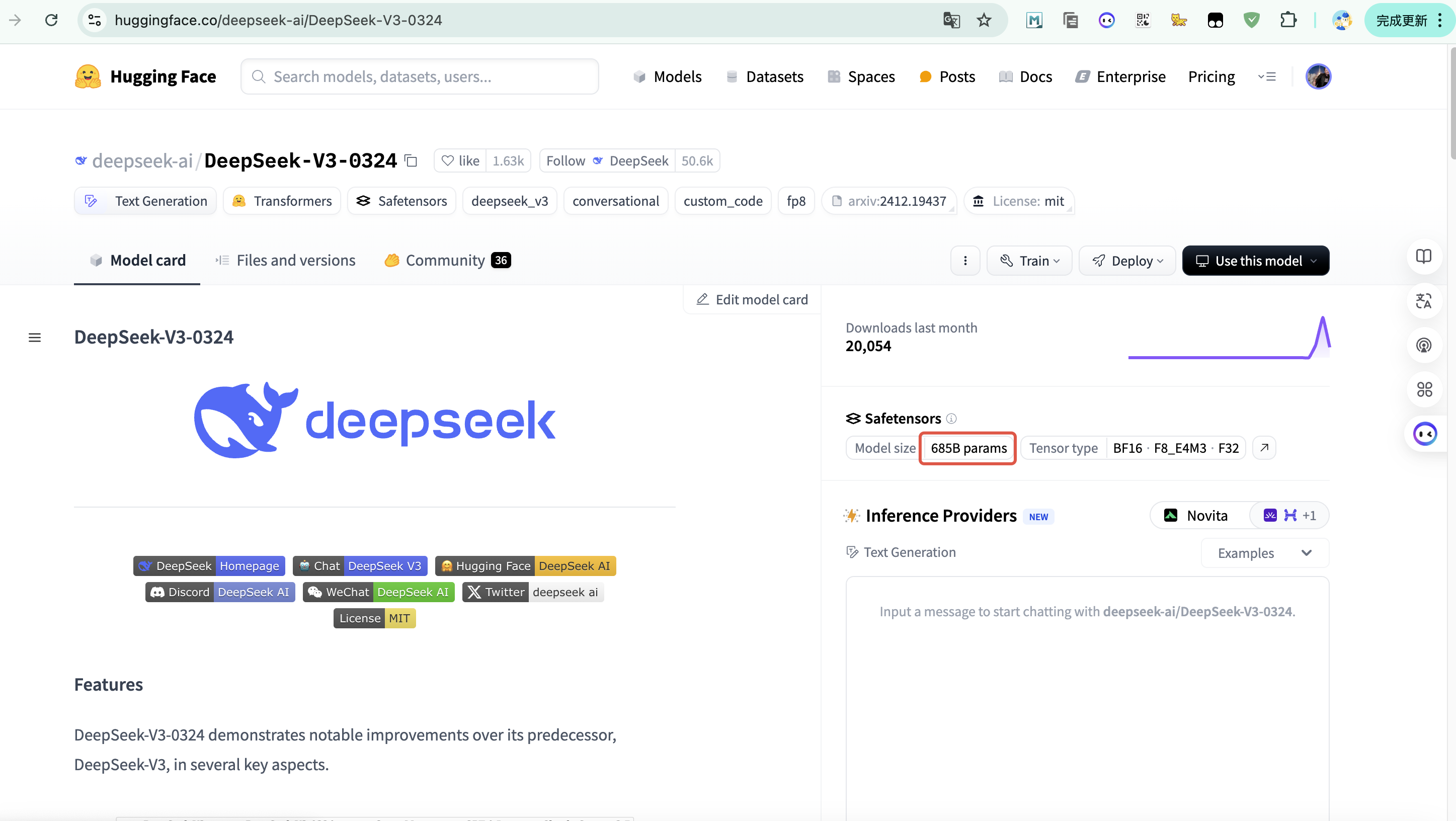
相较于初代V3模型的671亿参数,规模上有了大幅度的提升。这一变化不仅增强了模型的处理能力,还在多个关键领域实现了性能的显著提升。特别是在编程能力、数学逻辑推理和长文本处理方面,新模型展现出了与Claude 3.7 Sonnet思维链版本相媲美的表现。
编程能力优化
编程能力是此次更新的核心亮点之一。DeepSeek-V3-0324在代码生成质量上有了显著提升,尤其是在前端代码生成方面,相比R1版有了明显的改进。
这一提升使得开发者能够更高效地利用模型进行代码生成和优化,从而加速开发流程。
数学逻辑推理增强
数学逻辑推理能力的增强是另一个重要亮点。新模型在处理复杂的数学问题时,展现出了更高的准确性和效率。这一提升不仅有助于学术研究,也在实际应用中,如金融分析和工程设计等领域,具有广泛的应用前景。
技术细节
训练与权重
DeepSeek-V3-0324采用了FP8训练技术,并开源了原生FP8权重。这一技术不仅提高了模型的训练效率,还使得模型在实际应用中能够更快地进行推理。FP8训练技术的应用,使得模型在保持高精度的同时,大幅降低了计算资源的消耗。
上下文理解与长文本处理
新模型在上下文理解和长文本处理方面也有了显著提升。长上下文记忆扩展至128K,使得模型在处理长篇文档和复杂对话时,能够更好地保持连贯性和意图追踪能力。这一提升在需要处理大量文本信息的应用场景中,如法律文档分析和市场调研,具有重要的实际意义。
部署与性能优化
DeepSeek-V3-0324在部署过程和模型性能上也进行了优化。新模型在输入理解和输出反馈能力上的增强,使得其在复杂多轮对话中展现出了更强的连贯性和意图追踪能力。这一优化不仅提高了用户体验,也为模型在更多应用场景中的部署提供了便利。
行业影响
开源与商业应用
DeepSeek-V3-0324采用了更加宽松的MIT开源许可证,允许商业项目和自由代码集成。这一变化不仅有助于推动开源社区的发展,也为企业用户提供了更多的商业应用可能性。特别是在代码生成、长文档分析和复杂推理任务上,新模型展现出了广泛的应用潜力。
成本与性价比
DeepSeek-V3-0324在保持高性能的同时,还提供了更具竞争力的价格。API服务价格调整为每百万输入tokens 0.5元(缓存命中)/ 2元(缓存未命中),每百万输出tokens 8元,并提供45天的优惠体验期。这一价格策略使得更多企业和开发者能够以更低的成本享受到高质量的模型服务,从而推动了人工智能技术的普及和应用。
行业竞争与未来展望
DeepSeek-V3-0324的发布,无疑在人工智能领域掀起了一股新的竞争浪潮。尽管还缺乏多模态功能,但新模型在多个关键领域展现出的卓越性能,使得其在开源模型中脱颖而出。未来,随着DeepSeek-R2模型的发布,我们有理由相信,DeepSeek将继续在人工智能领域保持领先地位,并推动整个行业的技术进步。
结论
DeepSeek-V3-0324的发布,不仅是DeepSeek在技术上的又一次突破,也为人工智能行业带来了新的发展机遇。从参数规模的提升到编程能力的优化,从数学逻辑推理的增强到部署过程的优化,新模型在多个方面展现出了卓越的性能和广泛的应用潜力。未来,随着更多企业和开发者的加入,DeepSeek-V3-0324必将在人工智能领域发挥更加重要的作用,推动整个行业迈向新的高度。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)