
QwQ-32B推理模型开源,性能媲美R1满血版!
今夜,Manus发布之后,随之而来赶到战场的,是阿里。凌晨3点,阿里开源了他们全新的推理模型。QwQ-32B。本来还有点意识模糊,当看到他们发出来的性能比对图,我人傻了。不是,我没看懂,这特么是个什么怪物。在几乎所有数据集里,QwQ-32B 都已经能跟满血版DeepSeek R1(671B)表现相当了。尤其是作为QwQ-32B 的主攻方向的数学和代码。而且,QwQ-32B在基准测试上的性能跑分,几
今夜,Manus发布之后,随之而来赶到战场的,是阿里。
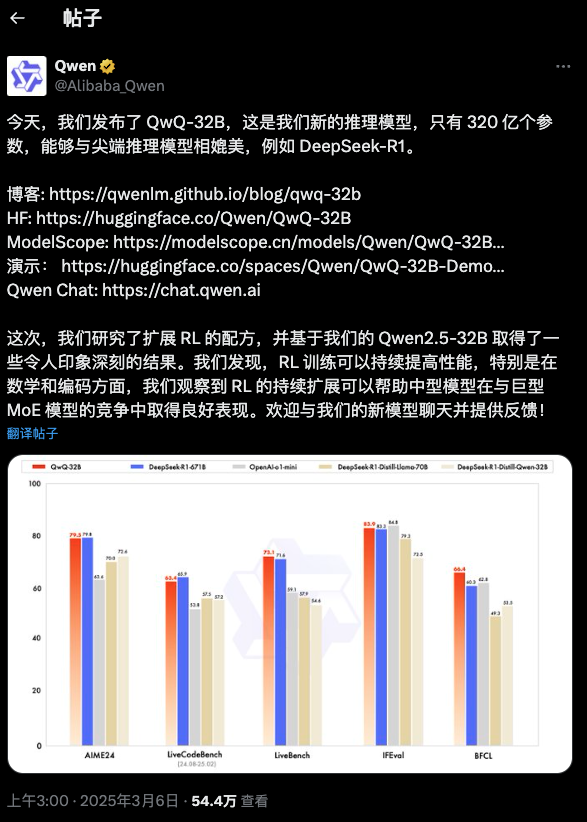
凌晨3点,阿里开源了他们全新的推理模型。
QwQ-32B。
本来还有点意识模糊,当看到他们发出来的性能比对图,我人傻了。
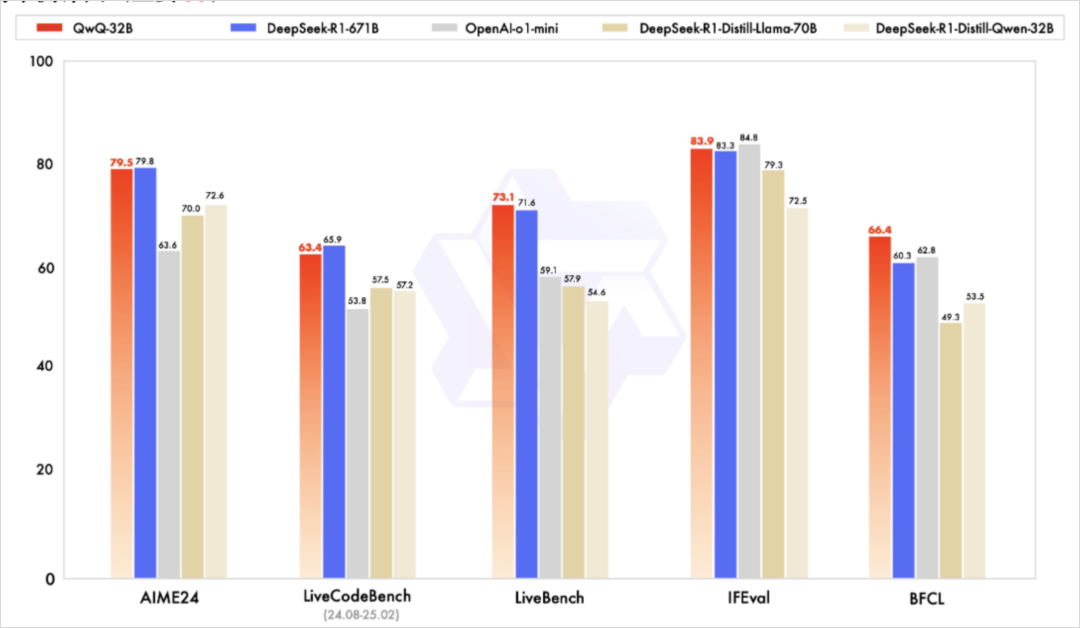
不是,我没看懂,这特么是个什么怪物。
在几乎所有数据集里,QwQ-32B 都已经能跟满血版DeepSeek R1(671B)表现相当了。尤其是作为QwQ-32B 的主攻方向的数学和代码。
而且,QwQ-32B在基准测试上的性能跑分,几乎拉开o1-mini一个身位。
我人已傻。
今天这夜,对我的冲击有一点大。
GPT4.5刚刚证明传统的那套快撞墙了,转头阿里就来给你掏个大的,说,你看,强化学习还是能卷的,这条路,远远还没到头。
这么令人诧异的性能表现,其实也跟这两天在arxiv出来的一篇爆火论文互相印证了。
一堆斯坦福教授集中讨论,为什么Qwen-2.5-3B一开始就能自己检查自己的答案,Llama-3.2-3B却不行。
最后的原因还是落在了Qwen团队的强化学习上。因为,这能让模型自己学会一些关键的“思考习惯”。

没啥可说的,阿里NB。QwenNB。
QwQ-32B开源链接在此:
魔搭开源链接:https://modelscope.cn/models/Qwen/QwQ-32B
huggingface开源链接:https://huggingface.co/Qwen/QwQ-32B
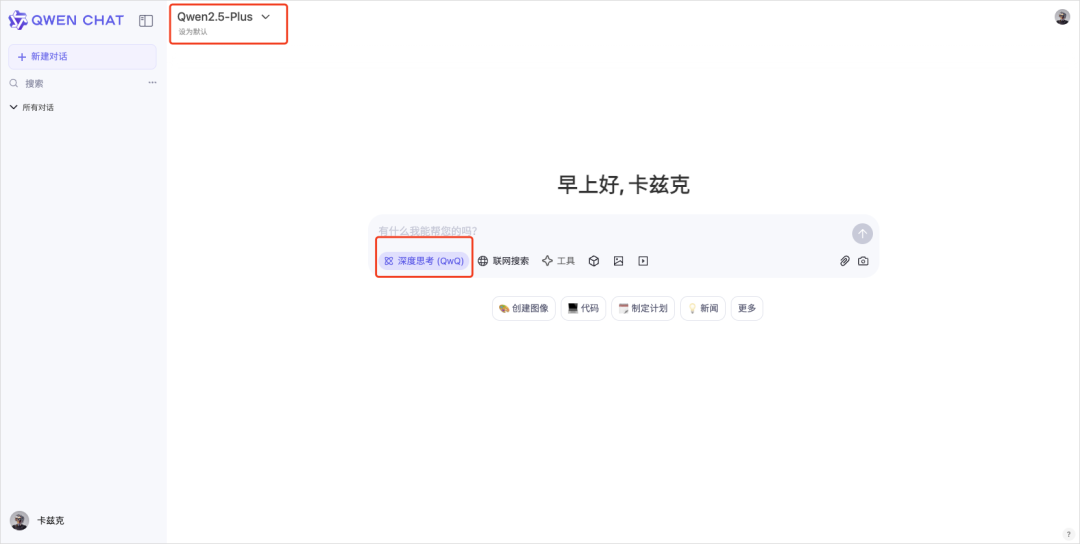
当然如果想直接上手体验,官方也给出了在线体验的地址:
https://chat.qwen.ai/?models=Qwen2.5-Plus
左上角模型选择Qwen2.5-Plus,然后开启Thinking(QwQ),就能用QwQ-32B了。
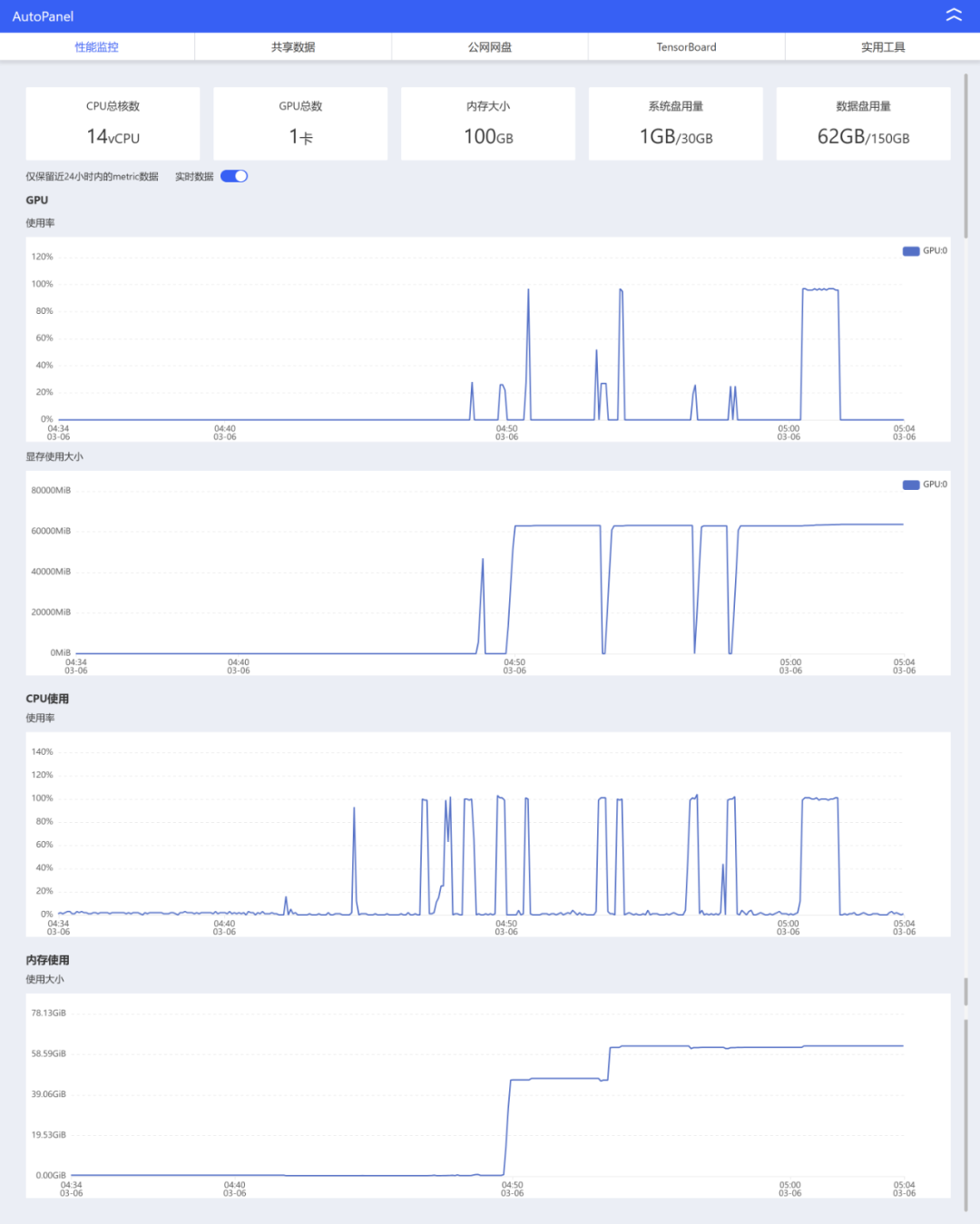
我这边也第一时间在AutoDL租了一台A800-80G的显卡,然后把模型下载了下来,并部署测试了一下这个怪物。综合体验下来,本地部署版和网页版其实是一样的。
性能曲线是这样的。
我也做了一些测试。
首先就是,我觉得赛博半仙易主了。这回的QwQ-32B真的能当八字算命大师了。
懂得都懂,AI自媒体人的命也是命,它掐指一算,就知道我经常熬大夜,狂肝文章。下半年家里那些鸡毛蒜皮的事就别提了,为了搭我的摄影棚,把景深弄得更到位,我是真得搬家啊。。。

当然,AI算命只能算是个开胃菜,接下来还是得认真测下QwQ-32B的数学能力。
然后就是拿我的著名的国庆调休题来难为下这类推理模型了:
这是中国2024年9月9日(星期一)开始到10月13日的放假调休安排:上6休3上3休2上5休1上2休7再上5休1。请你告诉我除了我本来该休的周末,我因为放假多休息了几天?
比如Grok3这种,开了推理还是直接炸了。

答案明明是4天,你咋独自加了3天。。。
而看看QwQ-32B,在一顿小推理之后。

最后答案,完全正确。

要知道,这可只是一个32B的小模型啊。。
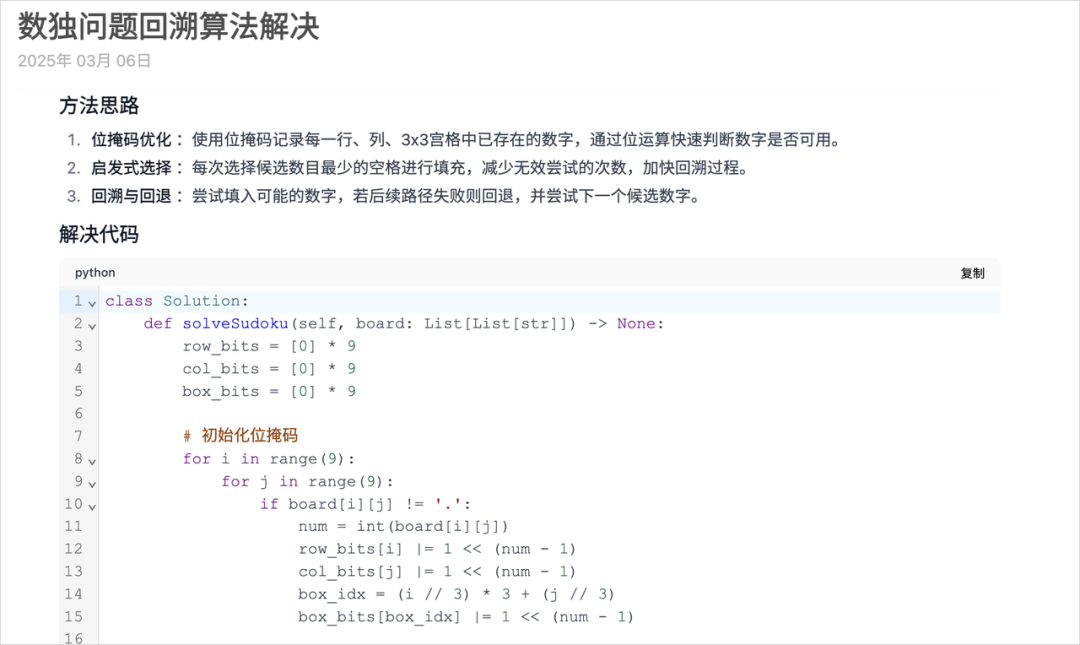
然后我还试了一下代码能力。我就直接去Leetcode找了一道困难级别的算法题,解数独。
可能有人不知道Leetcode是啥,LeetCode 是一个全球知名的在线编程练习平台,这个平台有大量不同难度的算法题库,从简单到困难的各种编程题都有。
我直接把解数独的题目还有代码模板丢给QwQ-32B,让它给出最优解的代码:
编写一个程序,通过填充空格来解决数独问题。
数独的解法需遵循如下规则:
数字 1-9 在每一行只能出现一次。
数字 1-9 在每一列只能出现一次。
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
然后给定你一个类,给我一个比较好的方案:
class Solution(object):
def solveSudoku(self, board):
"""
:type board: List[List[str]]
:rtype: None Do not return anything, modify board in-place instead.
"""
经过几分钟的思考,这道题的完整最优解代码也是被QwQ-32B成功给出。
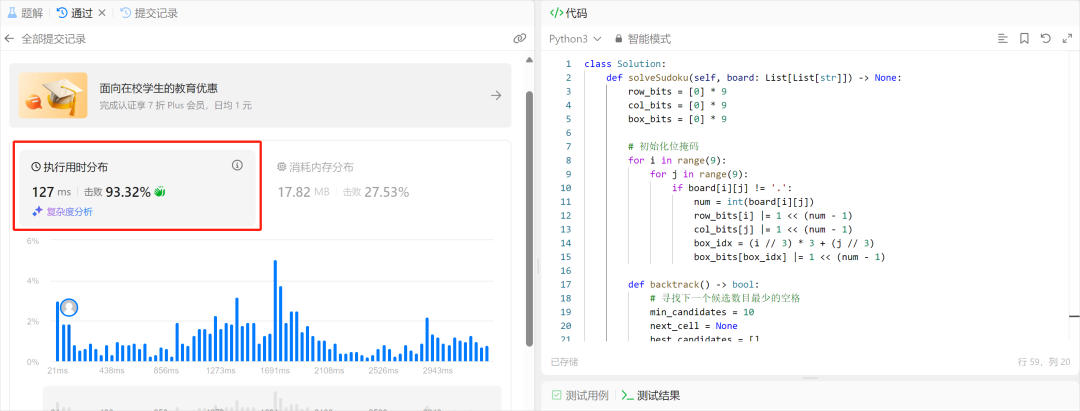
我把这段代码粘贴到了Leetcode平台上,直接提交,没想到这段代码竟然完美的通过了全部测试用例吗,而且执行用时才127ms,击败了93%的在这个算法题库做尝试的人。
说实话,这个结果让我挺惊讶的,毕竟127ms的用时,看平均的用时基本都在1691ms左右。
很强,但是我觉得最强的,还是它未来的生态。
32B和671B,对于本地算力的要求,或者是云服务的成本来说,差别实在是太大太大了。
671B,在FP16精度下需要1400G的显存,这个门槛有多高大家懂得都懂。
而现在,32B的QwQ,4张4090就能跑,这是将近15倍的差距。
而且,智能水平差不多。
这也意味着很多普通企业还有普通开发者,可以直接拿到一个足以对标DeepSeek R1的逻辑推理、数学推理、代码思考能力的大模型,而且还开源,能在自家环境中任意调试、微调、二次开发。
更何况,阿里云上的资源、ModelScope、Hugging Face镜像都能对接,瞬间就把部署壁垒降到几乎为零。
对于那些创新型创业者、小型团队,或者想要做专业AI应用的公司而言,我说实话,这就是天降神兵。
对于大多数的企业垂直场景,一个优秀的32B的模型真的已经足以应付很很多,没必要非得上600多亿参数、又烧又贵的巨无霸。
这波QwQ-32B开源的意义,还是非常强的。
它用实力证明RLHF路线还能玩出花,打破了一些人对GPT4.5撞墙后的过度悲观。
用中等规模却拿到高级性能,给开源界注入了强大信心,你也不必搞那种天价设备和超大规模,也有机会跟国际巨头同场竞技。
真的,昨夜爆火的Manus,在技术架构上,也是Claude+很多微调的Qwen小模型。
那这次QwQ-32B,又是一次智能的提升。
每个大厂、每个团队都在全力冲刺,新的风暴还会一个接一个出现。
睡前一抬头,日历翻到新的数字。
又是个不眠之夜。
阿里NB,QwenNB。
我们中国的团队。
就是NB。
愿我们都能见证更多奇迹。
晚安,或者早安吧。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)