零人工干预!DeepSeek×Python自动化爬虫黑科技手册_deepseek 爬虫
爬虫是一种。

免责声明:用户因使用公众号内容而产生的任何行为和后果,由用户自行承担责任。本公众号不承担因用户误解、不当使用等导致的法律责任
**(AI时代虽以数据为基石,但人类智慧才是驾驭技术的永恒光芒)**
目录
一:API介绍及安装
1.deepseek API 和deep网页版区别
2.部署DeepSeek API
二:利用deepseek使用自动化python爬虫实现
1.爬虫概念
2.爬虫功能
3.安装依赖
4.用DeepSeek生成基础爬虫代码
5.运行代码
6.爬取成功
三:有了AI我们就可以不用学习了?
1.反驳三连
2.人类の尊严保卫战
3.终极真相
结论:学习是人类的进化刚需
一:API介绍及安装
**1.**deepseek API 和deep网页版区别
1. 用户定位
-
DeepSeek网页版
面向普通用户,提供开箱即用的交互界面,无需编程基础。用户通过网页输入问题或需求,直接获取AI生成的文本、代码等内容,适用于个人学习、内容创作等轻量级场景。 -
DeepSeek API
面向开发者或企业,需通过编程调用接口集成AI能力至第三方系统(如应用程序、服务或工具)。适用于需要自动化、批量化处理或与其他系统联动的复杂场景。
2. 功能特性
-
网页版
-
功能固定:提供预设的交互模式(如问答、写作、翻译等),功能边界由官方界面决定。
-
单次交互:支持单次请求-响应,适合即时性需求,但难以实现连续任务流或多步骤处理。
-
交互限制:可能受限于使用频率、输入长度等平台策略。
-
-
API
-
功能可编程:通过参数调整(如温度值、最大生成长度)控制AI输出风格,支持灵活定制。
-
批量处理:可并发发送多个请求,或结合业务逻辑实现自动化流水线(如自动生成报告并存入数据库)。
-
系统集成:将AI能力嵌入现有工作流(如客服系统自动回复、代码仓库智能审查等)。
-
3. 技术实现
-
网页版
-
前端交互:基于浏览器完成请求,数据通过HTTP传输,依赖网页端渲染展示结果。
-
无代码依赖:用户仅需操作图形界面,无需关注底层协议或数据处理。
-
-
API
-
协议与认证:需通过API密钥进行身份验证,遵循RESTful或gRPC等协议发送结构化请求(如JSON)。
-
数据处理:开发者需自主处理输入预处理、错误重试、结果解析及后续业务逻辑。
-
多语言支持:提供Python、Java、Go等主流语言的SDK,降低集成成本。
-
4. 定制化与扩展性
-
网页版
-
低定制化:界面功能、交互流程由官方设计,用户无法修改。
-
无扩展性:无法与其他工具或数据源联动,仅支持平台内独立使用。
-
-
API
-
深度定制:可结合私有数据微调模型(若官方支持),或通过提示工程优化输出结果。
-
扩展性强:与企业内部系统(如CRM、ERP)、物联网设备等集成,构建定制化AI应用。
-
5. 典型应用场景
-
网页版适用场景
-
个人学习辅助(如概念解释、代码片段生成)
-
临时内容创作(如撰写邮件、社交媒体文案)
-
快速获取信息(无需复杂逻辑的简单问答)
-
-
API适用场景
-
企业级自动化服务(如智能客服、文档摘要生成)
-
数据驱动型应用(如结合数据库的个性化推荐)
-
垂直领域工具开发(如法律合同审查、医疗报告生成)
-
6. 成本与资源
-
网页版
-
免费/按次计费:可能提供基础免费额度,超出后按使用量付费。
-
无运维成本:基础设施维护由平台负责。
-
-
API
-
按调用量计费:通常根据Token数量或请求次数收费。
-
开发与运维成本:需投入技术团队进行集成开发、监控及异常处理。
-
7.选择建议
-
选择网页版:若需求简单、使用频率低,或缺乏技术资源。
-
选择API:若需将AI能力产品化、规模化,或与其他系统深度结合。
| DeepSeek 网页版 | DeepSeek API | |
|---|---|---|
| 用户 | 所有人(小白友好) | 程序员/开发者(需会写代码) |
| 操作 | 打字→点按钮→看结果 | 写代码→发送请求→处理数据 |
| 自由度 | 固定功能(如问答、写作) | 把AI“塞”进任何地方(APP/微信机器人/智能冰箱…) |
| 类比 | 租现成公寓(拎包入住) | 自建别墅(图纸自己画,厕所装在哪你说了算) |
| 秘密技能 | 偷偷让AI写情书/周报 | 让AI自动批改作业+把结果私信发给家长+生成Excel成绩单(一条龙服务) |
2.部署DeepSeek API
进入API 然后自行注册
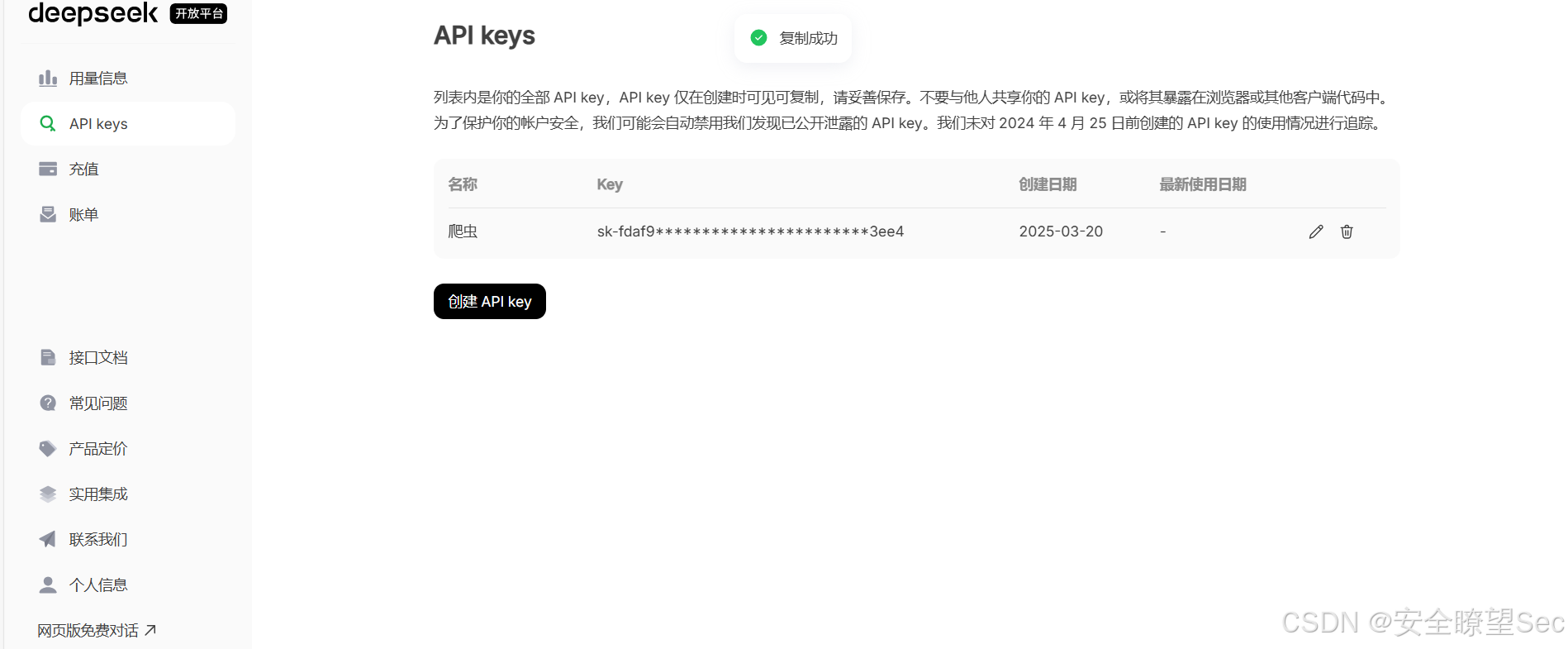
创建API key并保存
打开Install | Chatbox然后下载将保存的API key输入
选择R1模型也就是reasoner
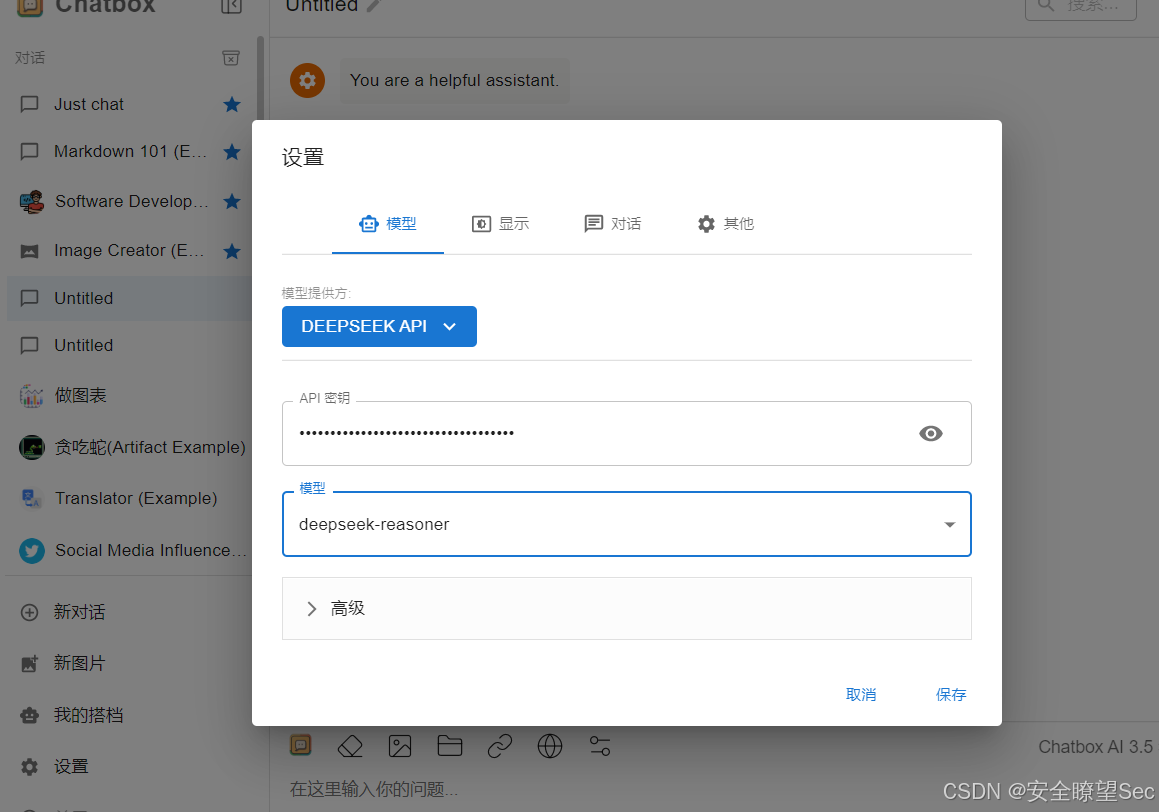
因为我没有充钱所以无法使用,所以我是使用网页版实现python爬虫代码的
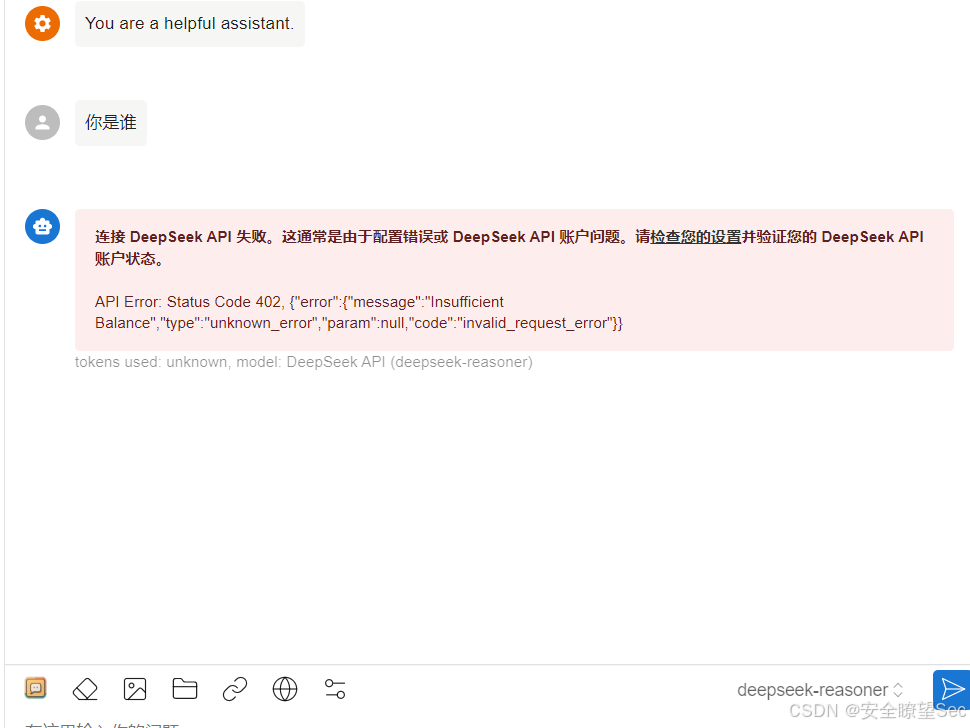
二:利用deepseek使用自动化python爬虫实现
1.爬虫概念
爬虫(Web Crawler)的定义
爬虫是一种自动化程序,通过模拟人类访问网页的行为,按照预设规则遍历互联网并抓取目标数据。其核心任务是从网页中提取信息,并将非结构化数据(如HTML)转化为结构化数据(如数据库、CSV文件)。
工作原理
-
起始请求:从一个或多个初始URL(如网站首页)发起HTTP请求。
-
下载内容:获取网页的HTML、JSON等原始数据。
-
解析数据:通过正则表达式、XPath或CSS选择器提取文本、链接、图片等。
-
链接追踪:从当前页面提取新URL,加入待爬队列,循环执行上述过程。
-
存储结果:将清洗后的数据保存到本地文件或数据库。
2.爬虫功能
| 功能分类 | 功能描述 | 应用场景 | 示例 |
|---|---|---|---|
| 数据采集 | 抓取网页文本、链接、多媒体资源,并转为结构化数据 | 内容聚合、资源下载 | 抓取新闻文章、下载商品图片、生成Excel表格 |
| 自动化监控 | 实时追踪数据变化或用户行为 | 价格监控、舆情分析 | 监控电商价格、分析社交媒体热点 |
| 动态内容处理 | 抓取JavaScript/Ajax动态加载的内容,模拟登录或表单提交 | 单页应用数据抓取 | 抓取React/Vue网站、登录后获取用户数据 |
| 大规模数据聚合 | 聚合多来源数据构建数据库或索引 | 搜索引擎、学术研究 | 构建搜索引擎索引、抓取论文数据集 |
| 高级功能 | 反爬虫对抗、分布式爬虫、增量抓取 | 高效爬取、规避封禁 | 处理验证码、多节点协同抓取 |
| 典型应用领域 | 结合行业需求定制化数据抓取 | 电商、金融、SEO、科研 | 比价工具、股票分析、关键词排名监控 |
3.安装依赖
pip install requests beautifulsoup4 openpyxl
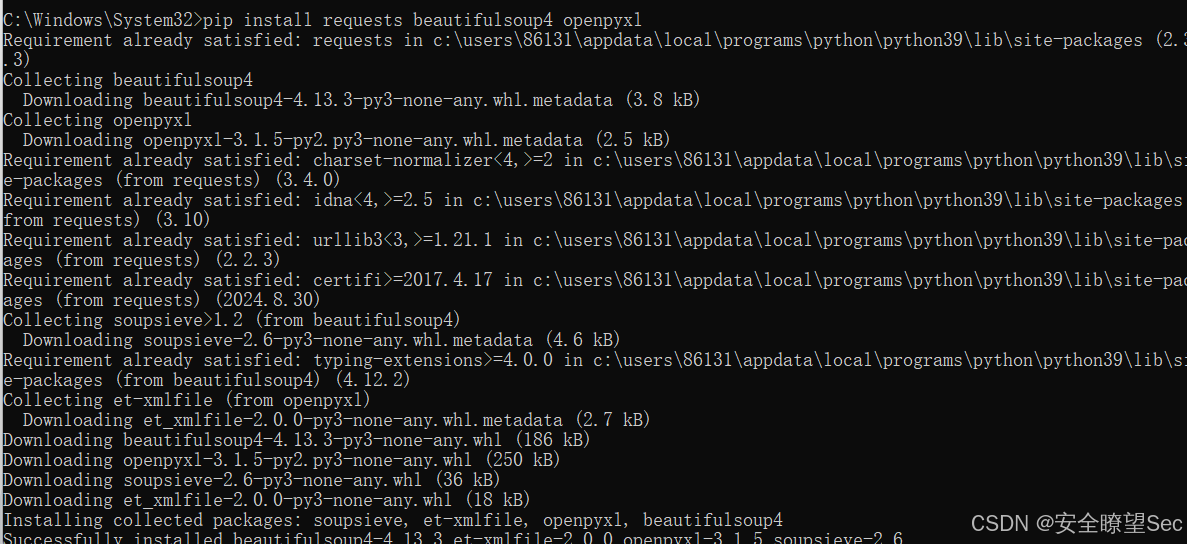
pip install pandas
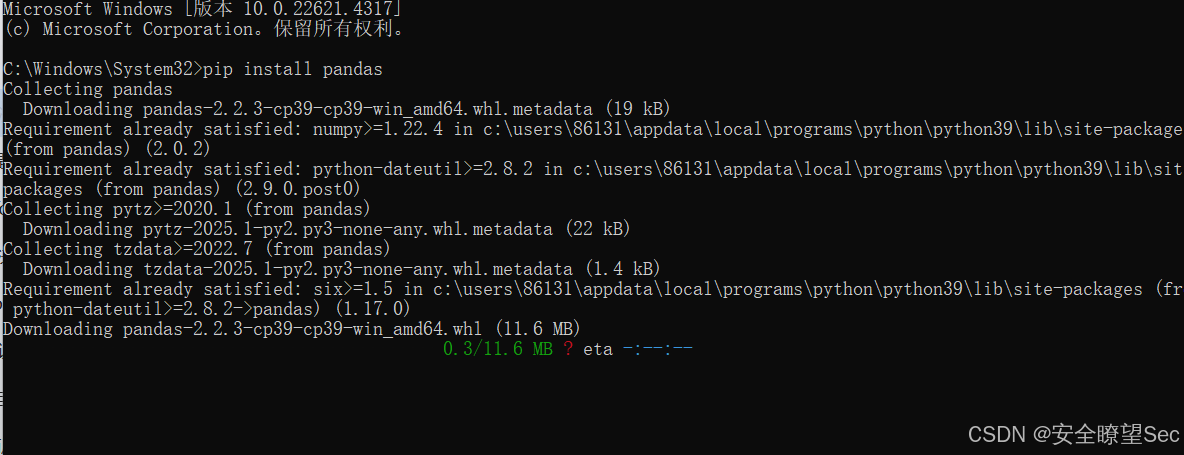
pip install fake-useragent -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tqdm

4.用DeepSeek生成基础爬虫代码
向DeepSeek输入以下指令:
请生成一个Python爬虫代码,爬取豆瓣电影Top250页面(豆瓣电影 Top 250)的以下数据:
- 电影名称
- 评分
- 短评数量
- 电影链接
要求:
1. 自动遍历所有分页(共10页)
2. 添加随机User-Agent和代理IP支持
3. 数据存储到Excel文件
4. 添加异常处理和延迟防止被封
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
from fake_useragent import UserAgent
from tqdm import tqdm # 进度条工具(可选,可通过pip安装)
# ================== 配置参数 ==================
BASE_URL = "https://movie.douban.com/top250?start={}"
MAX_PAGE = 10 # 共10页(0-9)
DELAY = random.uniform(1, 3) # 基础延迟
PROXIES = [ # 代理IP池(需自行替换有效代理)
# {"http": "http://ip:port", "https": "http://ip:port"},
# 更多代理...
]
ua = UserAgent()
# ================== 数据存储 ==================
movies_data = []
# ================== 爬取逻辑 ==================
def get_random_header():
"""生成随机请求头"""
return {
"User-Agent": ua.random,
"Referer": "https://movie.douban.com/",
"Accept-Language": "zh-CN,zh;q=0.9",
}
def fetch_page(url):
"""发送请求并返回响应"""
try:
proxies = random.choice(PROXIES) if PROXIES else None
response = requests.get(
url,
headers=get_random_header(),
proxies=proxies,
timeout=10
)
response.raise_for_status() # 检查HTTP状态码
return response.text
except Exception as e:
print(f"请求失败: {e}")
return None
def parse_page(html):
"""解析页面数据"""
soup = BeautifulSoup(html, "html.parser")
items = soup.select(".grid_view .item")
for item in items:
try:
# 电影名称
title = item.select_one(".hd span.title").text.strip()
# 评分
rating = item.select_one(".rating_num").text.strip()
# 短评数量
comment_tag = item.select_one(".star span:last-child")
comments = comment_tag.text.replace("人评价", "").strip() if comment_tag else "N/A"
# 电影链接
link = item.select_one(".hd a")["href"].strip()
movies_data.append({
"title": title,
"rating": rating,
"comments": comments,
"link": link
})
except Exception as e:
print(f"解析失败: {e}")
# ================== 主程序 ==================
if __name__ == "__main__":
for page in tqdm(range(MAX_PAGE)): # 使用tqdm显示进度条
try:
# 生成分页URL
start = page * 25
url = BASE_URL.format(start)
# 获取页面
html = fetch_page(url)
if not html:
continue
# 解析数据
parse_page(html)
# 随机延迟
time.sleep(DELAY + random.uniform(0, 1))
except Exception as e:
print(f"处理第{page+1}页时出错: {e}")
continue
# 保存到Excel
if movies_data:
df = pd.DataFrame(movies_data)
df.to_excel("douban_top250.xlsx", index=False)
print(f"成功保存{len(df)}条数据到douban_top250.xlsx")
else:
print("未获取到有效数据")
5.运行代码
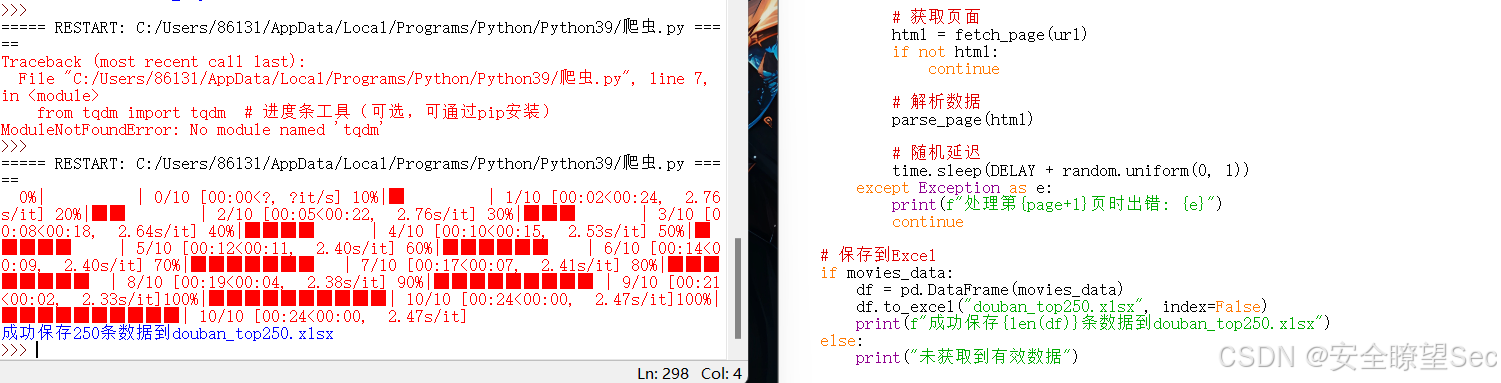
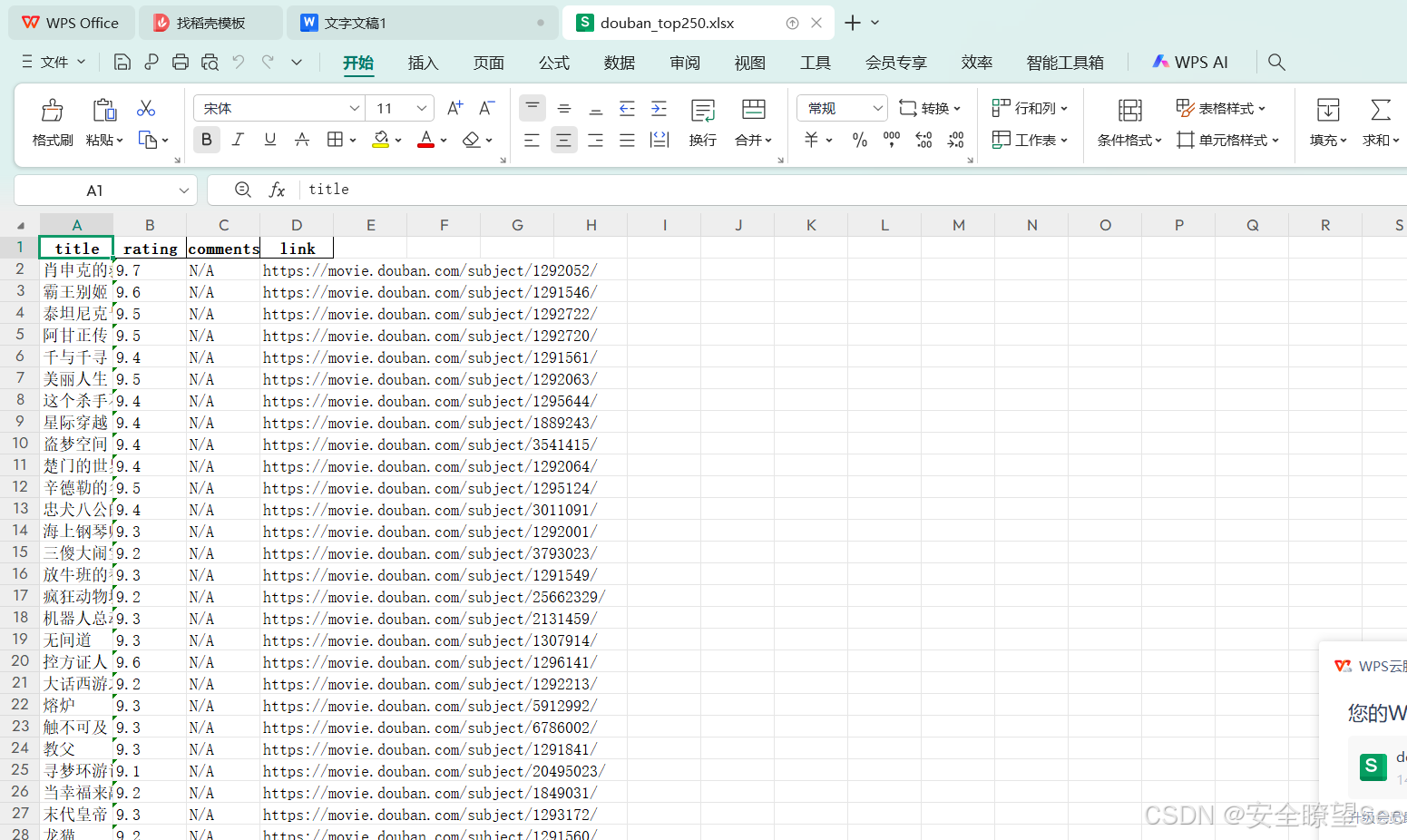
6.爬取成功
保存路径为Python脚本的工作目录中,文件名为 douban_top250.xlsx。
三:有了AI我们就可以不用学习了?
有人说既然AI能帮我生成代码那我还学什么代码啊,直接AI就好了。。
1.反驳三连
-
“AI是学霸笔记,你是学渣本人!”
- AI能甩你100篇论文,但没你划重点,它连考试范围都摸不着!就像给AI一本《五年高考》,它疯狂输出答案,结果考场发的是《三年模拟》——当场死机!📚
-
“AI是GPS,但你不认路就敢上山?”
导航说“前方直行”,你一猛子扎进河里,AI还在淡定播报:“当前水深3米,建议蛙泳。” 没学过游泳?恭喜解锁成就:AI坑你大礼包!🌊 -
“AI是西施滤镜,你是原相机素颜!”
用AI写简历吹得天花乱坠,面试官一问:“请解释第二行代码。” 你眼神游离:“那啥…滤镜突然卡了?” ——工作?下一个!📸
2.人类の尊严保卫战
-
当AI说“我会画画”
你反手掏出毕加索画派解析:“老弟,你管这叫‘立体主义’?这明明是二维码成精!” 🔳 -
当AI说“我会写诗”
你甩出《唐诗三百首》:“‘举头望明月’下一句是‘低头写BUG’?李白棺材板按不住了!” 👻 -
当AI说“我懂爱情”
你冷笑播放《泰坦尼克号》:“来,先解释下Rose为啥不共享木板?” AI颤抖:“…检测到人类逻辑,本机选择自爆。
3.终极真相
AI是你的赛博宠物,不是哆啦A梦!
不学习=给AI当人形电源,还是5V慢充那种
今日不读书,明天AI把你写进《人类迷惑行为大赏》——标题就叫:《摆烂之王:他以为AI会替他高考!》
结论:学习是人类的进化刚需
拒绝学习等于自愿放弃人类在智能时代的认知主权。AI不是学习的替代品,而是激发人类突破认知边界的催化剂——正如望远镜扩展了肉眼视野,但天文学仍需学者解读星辰。所以不管怎样,不能因为有了AI而放弃学习,而是因为有了AI我们才更应该利用AI提升自我。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 29
29 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)