试用Claude 3.7等大模型后:专用大模型是一条捷径
但Claude 3.7在推理能力很菜的情况下,分析代码、写代码方面的表现能够跟Grok 3 Beta相当,这让我想起“豆包”和“豆包爱学”,也是推理能力有欠缺,但因为积累了更多在中小学习题方面的材料和数据(语料),对于一些标准的语文、数学、英语方面的习题,只需要扫描问题的一个局部,就能够把整个问题完整还原出来,并大部分情况下能够给出准确的解答。比如以DeepSeek R1或V3的推理能力,加上自己
Claude 3.7推理能力待加强的我的证明方法
试用的时候发现Claude 3.7实际上推理能力不行,比DeepSeek R1/V3的完整版、Grok 3 Beta还有差距。主要体现在这道小学数学应用题,即使最新版本仍然无法一次性给出正确答案。
加强版的比较绕一点的数学应用题进一步升级之后,仍然能够挑战其推理能力。但我在聊天互动提交代码、代码理解、代码修改的过程中,也容易体会到一个大模型chatbot到底推理能力有多强、推理层次能够达到什么样的深度。所以,主要是通过实际问题来检验。
推理能力不错,然而吝啬算力、在输出上过于俭省,可能导致问题,这是DeepSeek R1目前显著的不足。
Claude 3.7修改和直接完成的代码不错
认识到推理能力方面的不足,我也仍然尝试了Claude 3.7在写代码方面的表现,结果居然是,非常不俗,至少跟Grok 3 Beta相当,似乎优于DeepSeek R1
因为我用的都是免费版,可能大语言模型没有充分发挥能力,只有Grok 3 Beta毫不吝啬?
但Claude 3.7在推理能力很菜的情况下,分析代码、写代码方面的表现能够跟Grok 3 Beta相当,这让我想起“豆包”和“豆包爱学”,也是推理能力有欠缺,但因为积累了更多在中小学习题方面的材料和数据(语料),对于一些标准的语文、数学、英语方面的习题,只需要扫描问题的一个局部,就能够把整个问题完整还原出来,并大部分情况下能够给出准确的解答。这实际上仍然是产品定位的一个正确的突围的方向。
所以,我用简单的例子、简单地论证了我的标题。
其它领域或其它大模型如何借鉴这种经验?
法律法规审批裁决等方向其实完全可以借鉴豆包的经验。比如以DeepSeek R1或V3的推理能力,加上自己相关方面的语料、案例、数据等,完全可以生成强大的大模型,大大提高相关部门的工作效率、降低错误率。非常值得尽快开展准备、部署和试点工作。工作方法转型对人员、软件和硬件设备设施、工作流程等方面都会产生深远影响,要想做好不是那么容易的,需要很多经验积累维护和调整,所以,试点是必不可少的。
借助不同大语言模型接力追加到字体生成上的功能
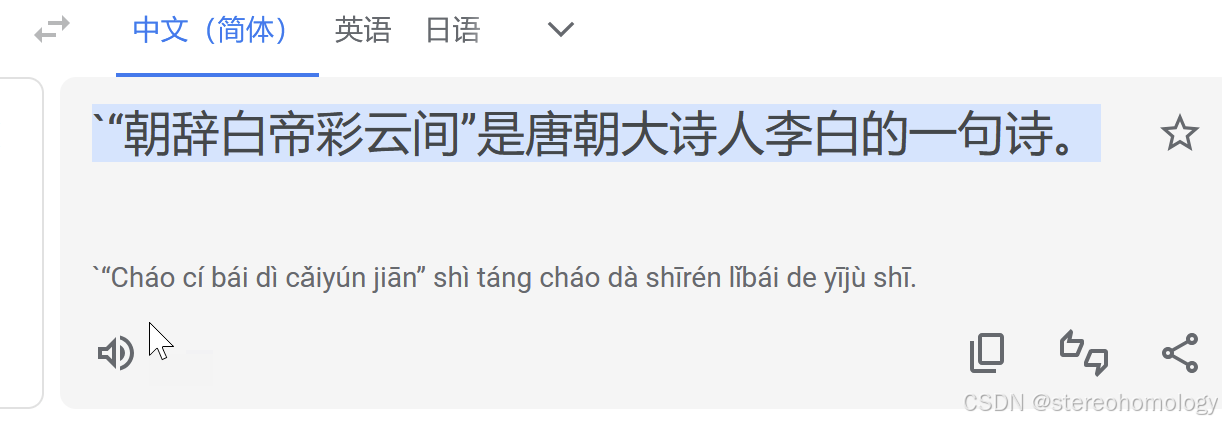
多音字注音(我发现translate.google.com的注音功能,也还是解决不了下面这句话注音的问题:“朝辞白帝彩云间”是唐朝大诗人李白的一句诗。 在谷歌里面是这样的:)
 我现在所用的开源工具,是这样的:
我现在所用的开源工具,是这样的: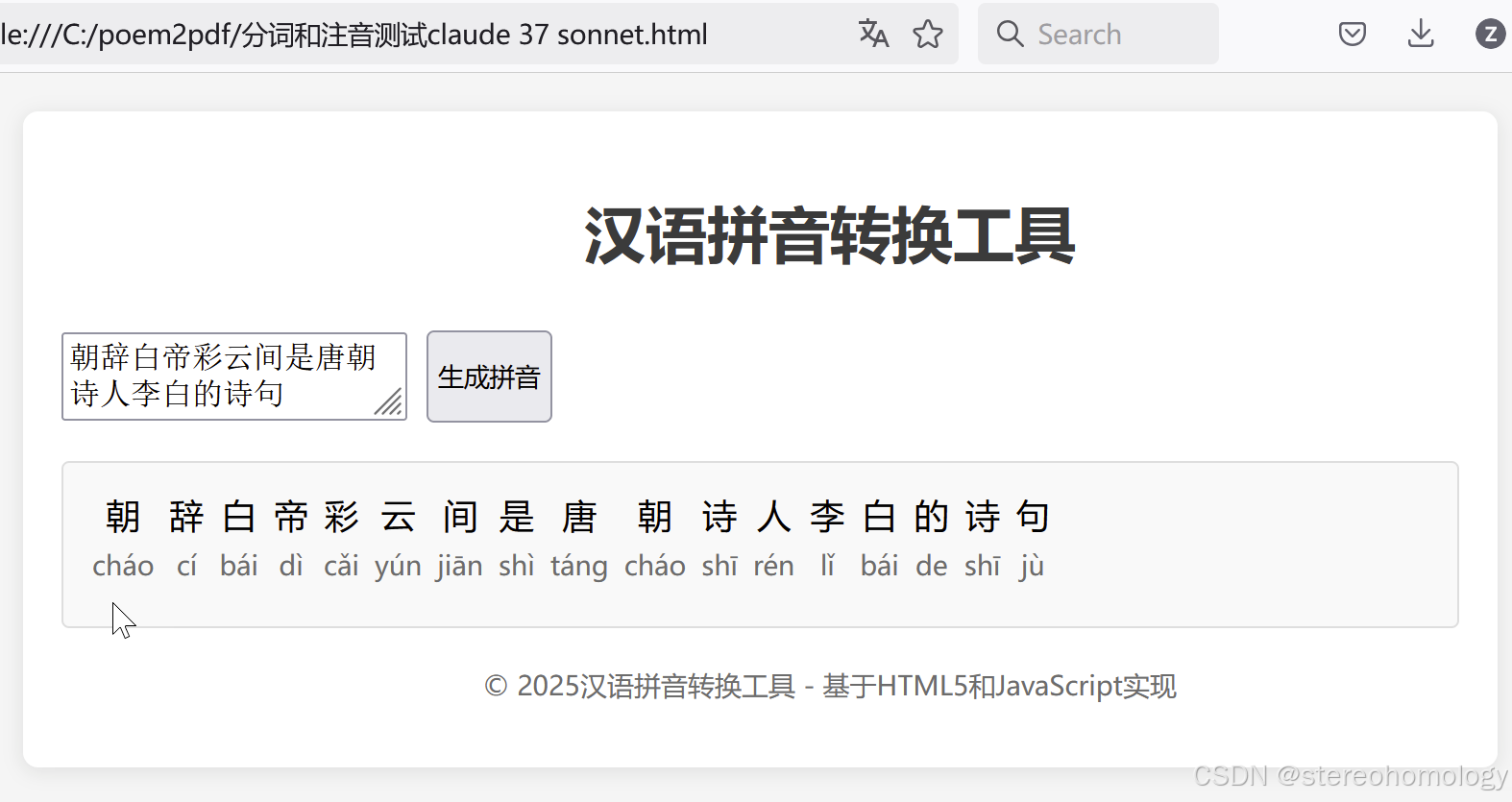
在不进行人工介入修订的情况下,已经达到跟谷歌这个工具相当的水平了——我认识到,用这个表达方式来对代码中的缺陷进行描述,就可以大言不惭了——(组词其实可以自定义,拼音主要还是靠开源工具),下面展示的是包含多音字的部分,全部都是一键自动生成的结果,尚未人工干预:
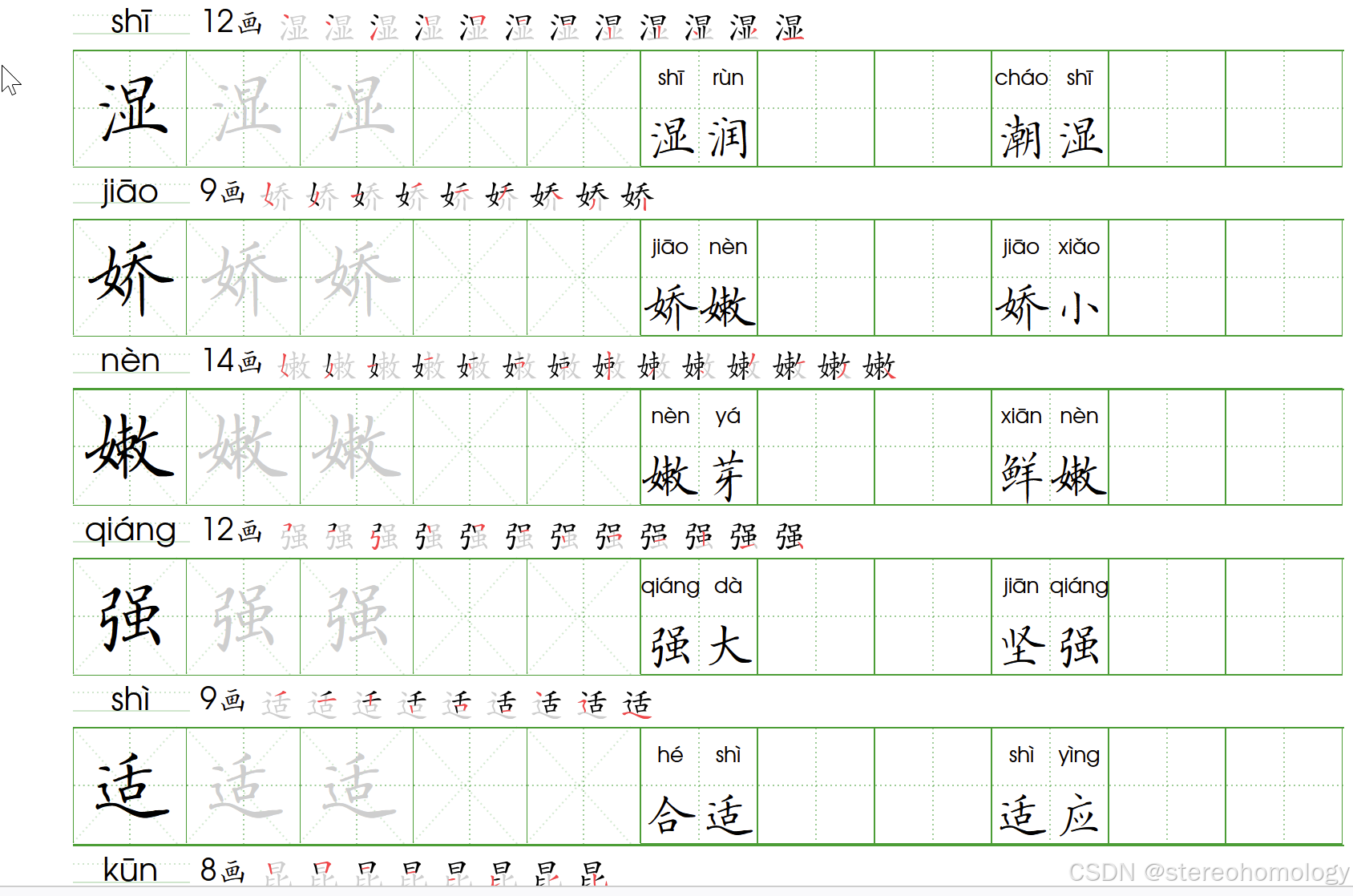
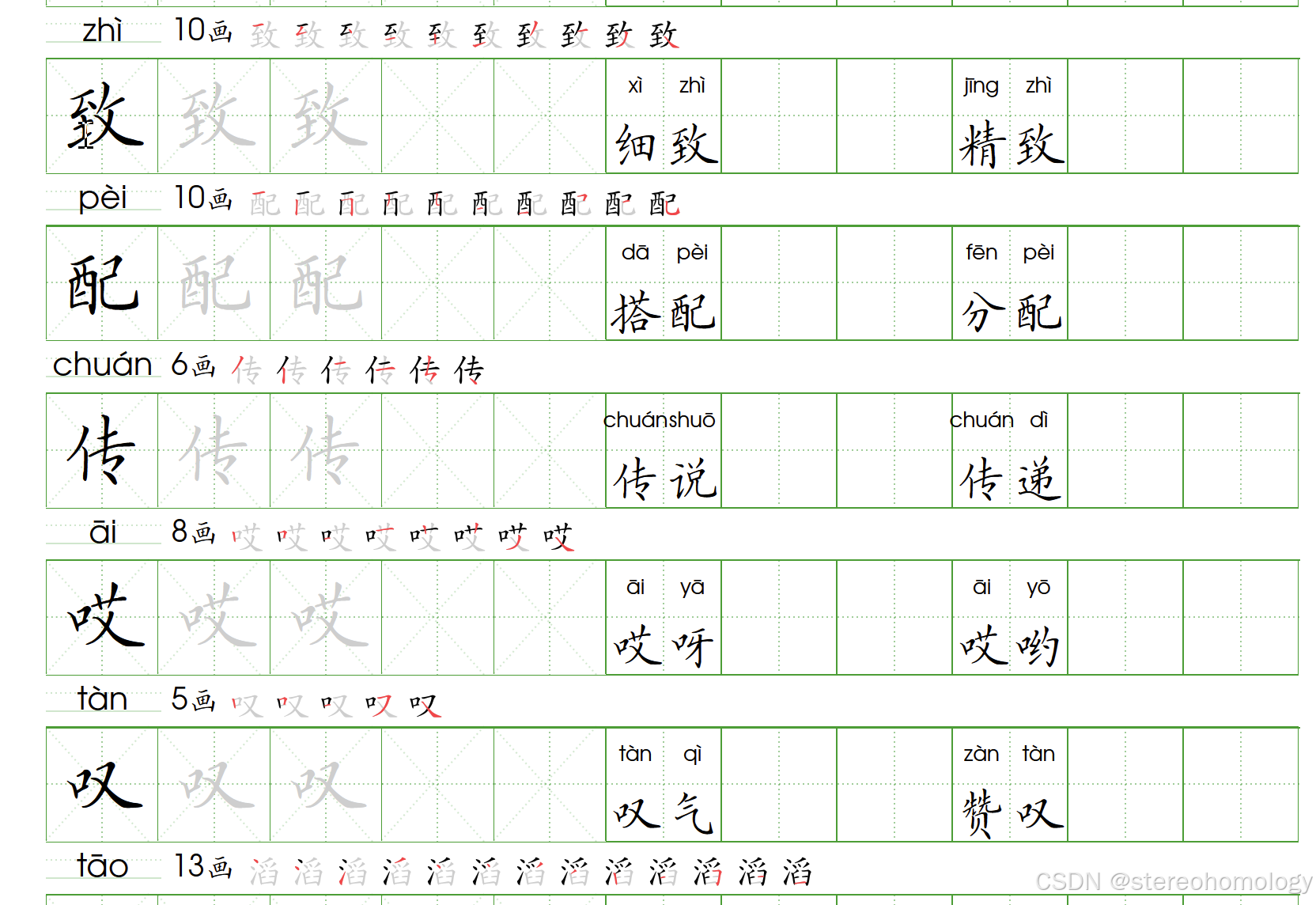
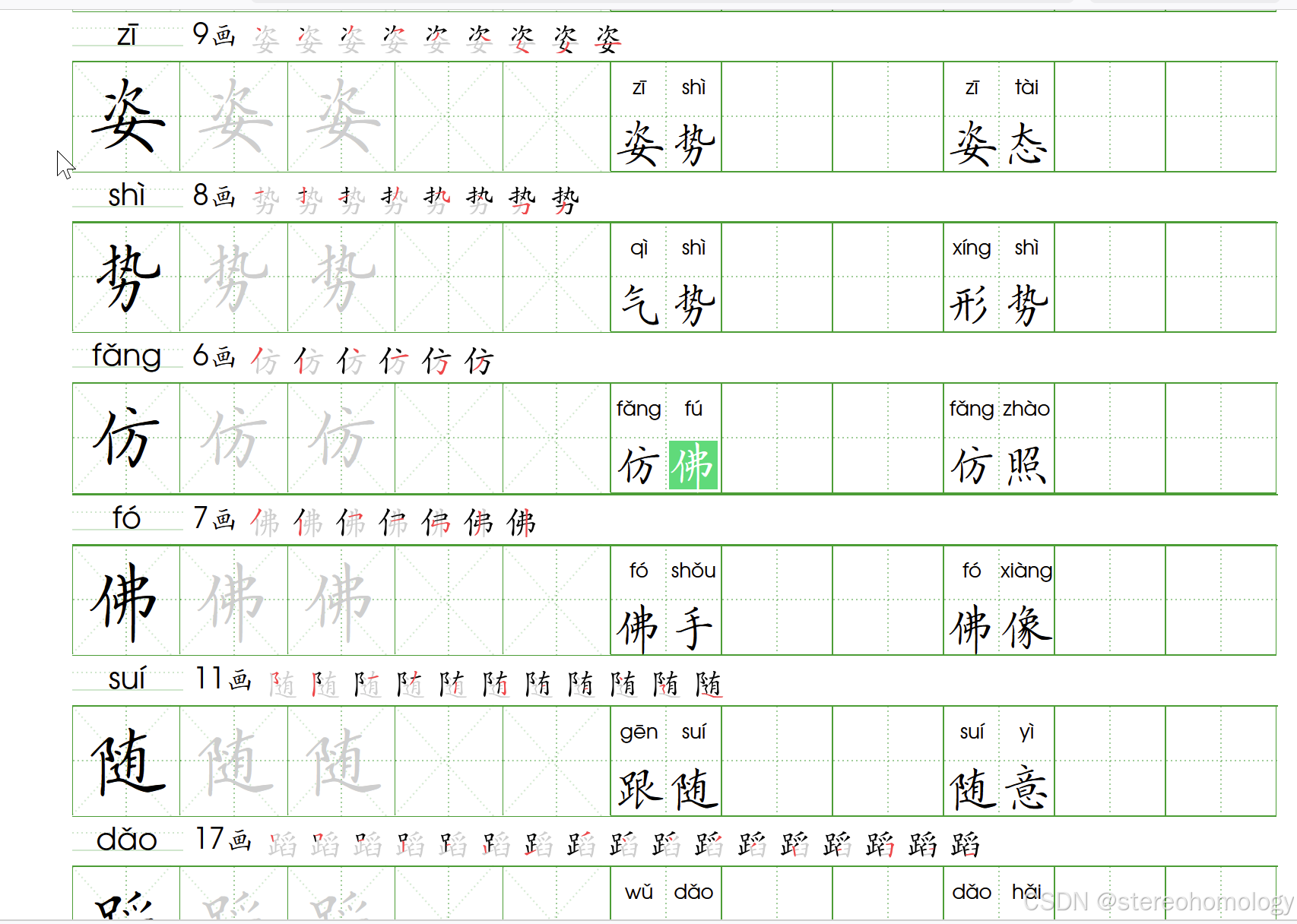
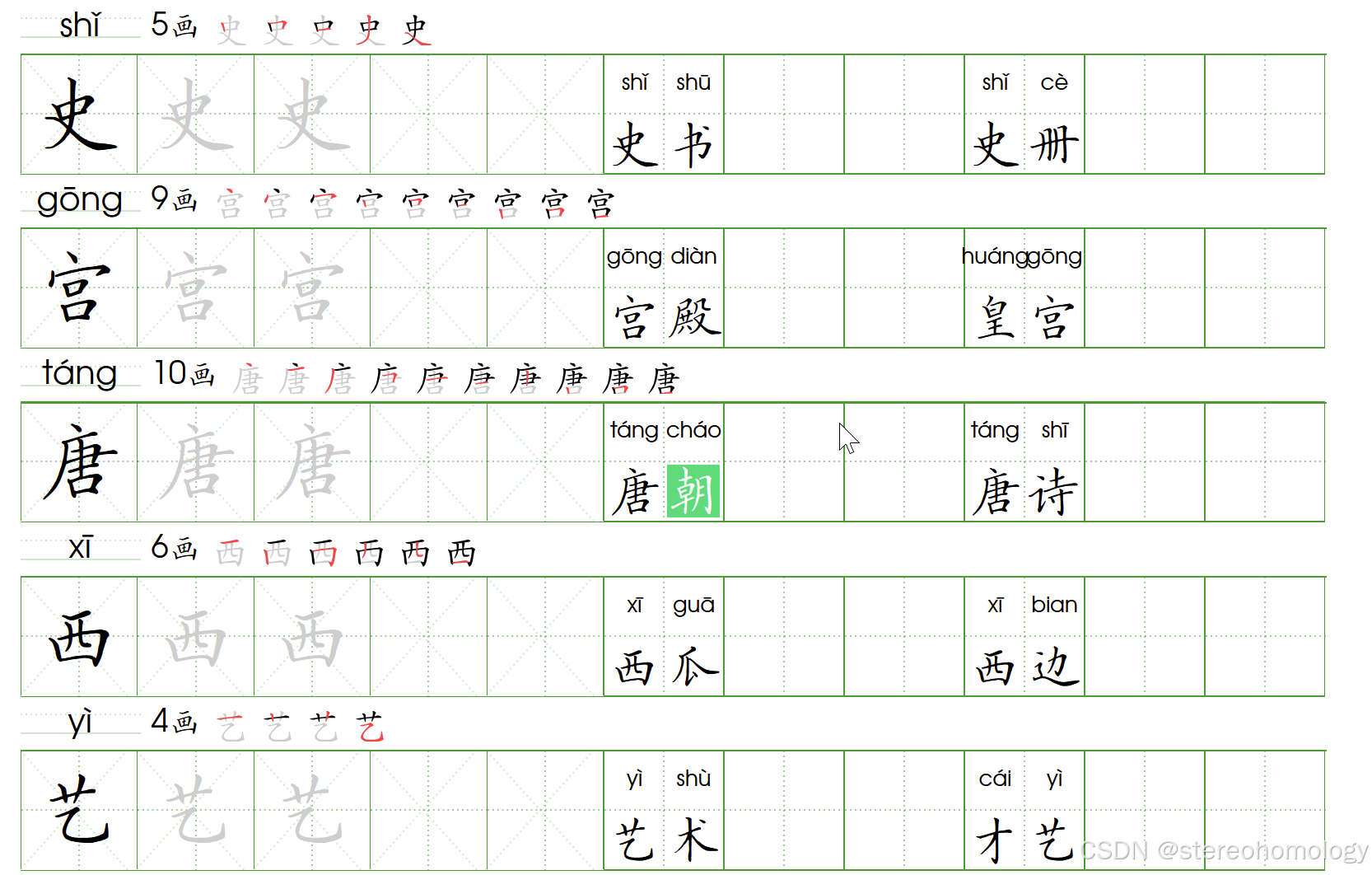
分词和注音,因为歧义太多,自动化的确不容易。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)