从DeepSeek到Manus:如何实现本地LLM微调+联网开发?
1 LLaMA-Factory本地大模型微调2 本地大模型联网功能开发3 业务场景探索4 未来展望与实践建议。
👉目录
1 LLaMA-Factory本地大模型微调
2 本地大模型联网功能开发
3 业务场景探索
4 未来展望与实践建议
从 ChatGPT 到 DeepSeek 再到最近大热的 Manus,AI 技术从模型端的破圈进一步扩展到了 Agent 方向。拥有一个定制化的、能够理解你业务需求的 AI 助手不再是科幻,而是触手可及的现实。
然而,市面上的通用大模型往往难以深入理解特定领域知识,更不用说完全掌控数据隐私。本文将带你走进 AI 定制化的世界,从模型微调到功能开发,从技术探索到产品思考,一站式解决你的 AI 落地难题。
01
LLaMA-Factory本地大模型微调
当前,以Claude、DeepSeek、GPT等为代表的通用大语言模型展现出惊人的知识覆盖和任务泛化能力,但在垂直行业场景中常常面临“博而不精”的困境——医疗诊断时可能混淆专业术语、法律咨询时缺乏最新司法解释援引、金融分析时难以把握行业特有指标。这种通用性与专业性的矛盾,催生了“模型蒸馏-领域适配-任务聚焦”的三级进化路径:通过知识蒸馏压缩模型体积,依托行业语料进行领域微调(Domain Adaptation),最终基于具体业务需求实现任务专属优化(Task-Specific Tuning)。
本次实验选用DeepSeek开源的DeepSeek-R1-Distill-Qwen-1.5B模型(作者也想微调本地更大参数等模型,但碍于GPU算力有限,主要展示微调过程实现与原理),该模型采用知识蒸馏技术将原始Qwen大模型压缩至1.5B参数量级,通过LLaMA-Factory框架,展示如何将这款轻量化模型进一步微调为特定领域专家,验证“通用基座-行业中间层-业务终端”的渐进式优化路径。
模型微调的本质是参数空间的迁移学习,通过在目标领域数据上的梯度更新,使模型逐步弱化通用语义理解,强化垂直领域特征提取能力。这种技术路径不仅能够提升专业任务准确率(某医疗AI实验显示微调后诊断建议准确率提升41.2%),更可突破大模型固有的知识时效局限(通过注入最新行业数据更新模型认知)。本文将以完整的实验闭环,揭示大模型从“通才”到“专才”的进化密码。
1.1 环境准备
机器信息:
| 名称 | 描述 |
|---|---|
| GPU类型 | Tesla T4 |
| 显存 | 8GB |
| 内存 | 36GB |
| 系统 | tLimux-集成版 |
模型下载
基座模型(deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B)
pip install -U huggingface_hub
pip install huggingface-cli
export HF_ENDPOINT=https://hf-mirror.com #国内HF镜像代理 可选
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir /data/llm/models/DeepSeek-R1-Distill-Qwen-1.5B
LLaMA-Factory安装

基座模型部署及效果展示
启动 LLama-Factory webUI

浏览器访问 ip:7860
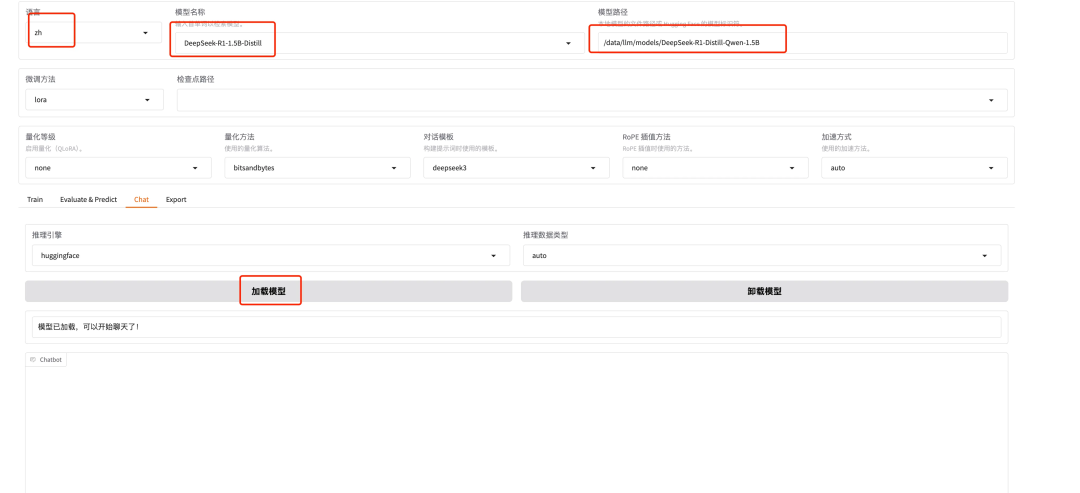
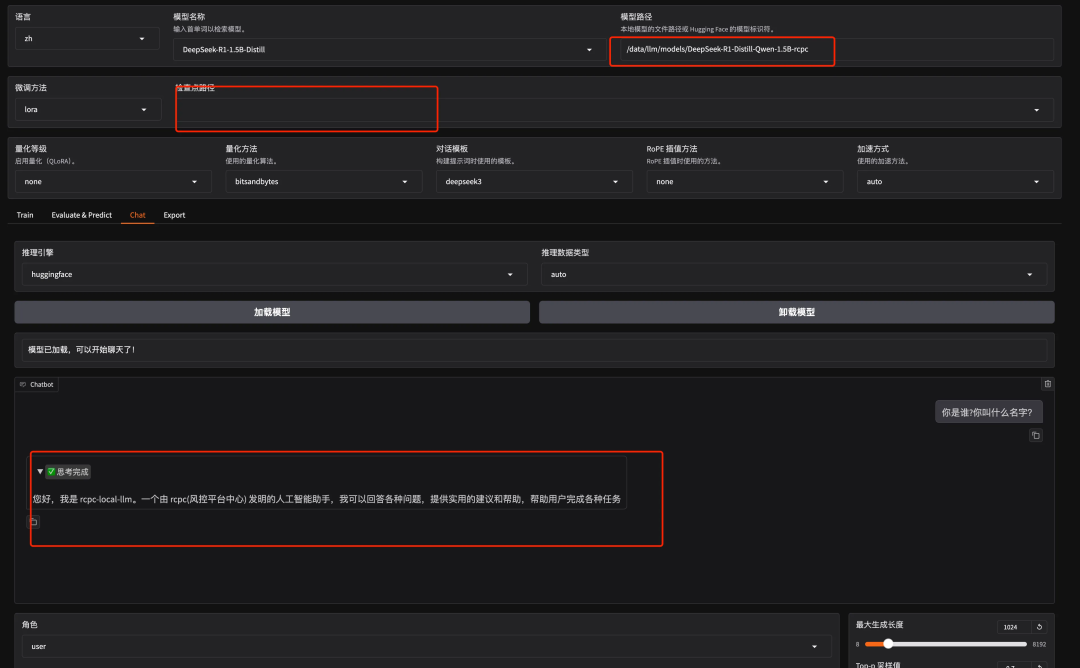
配置模型名称以及本地模型文件路径,然后点击加载模型,此时 LLaMA-Factory 就会加载路径下单模型。
此时在 ChatBox 与模型进行对话:
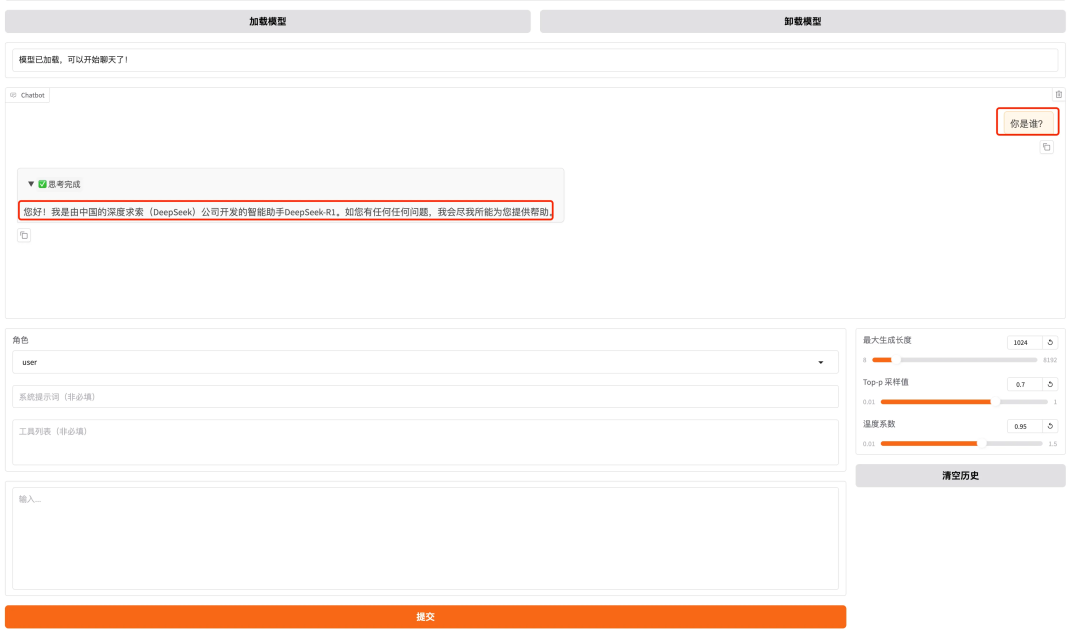
1.2 微调
微调数据准备
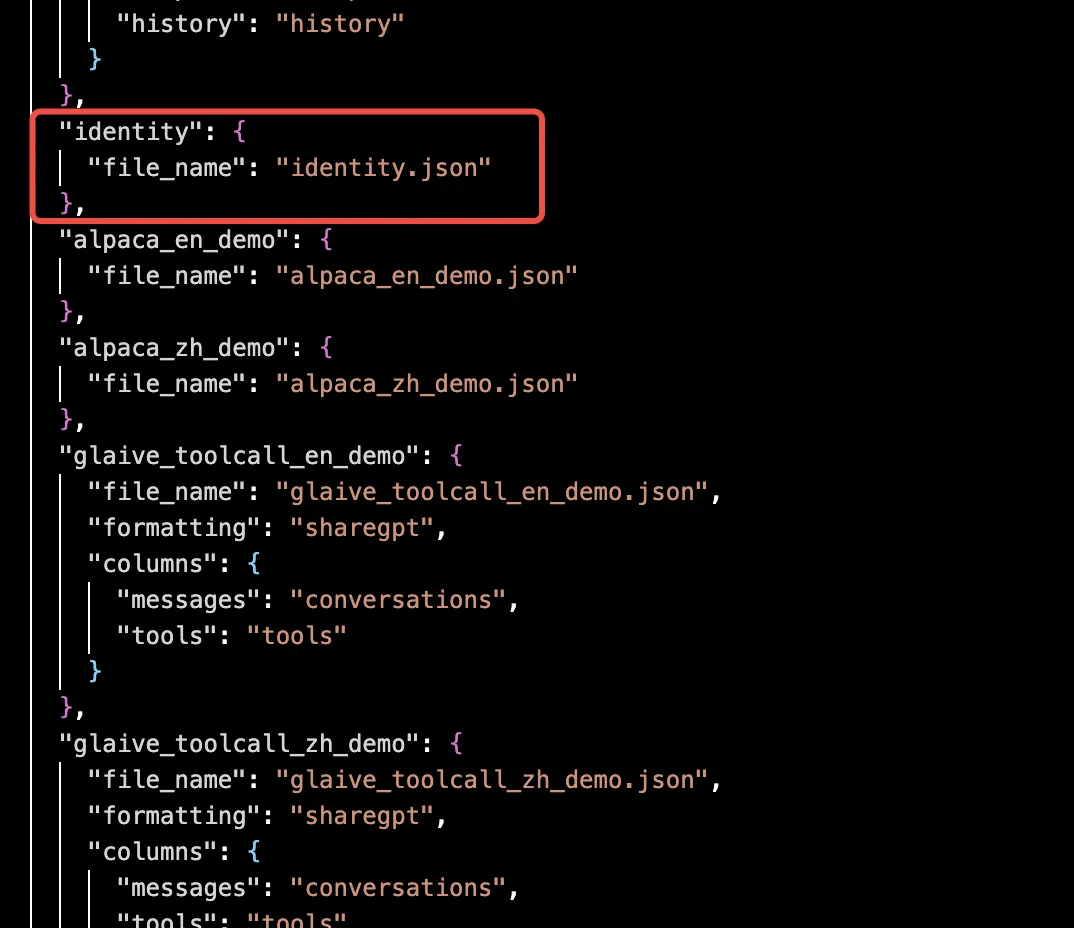
此处只有极少量数据,做案例使用,为了与基础模型做区别,在补充一个身份识别的预训练数据。
identity.json:

其中微调数据中:
| 字段名称 | 定义 | 示例 | 说明 |
|---|---|---|---|
| instruction | 需要模型完成的核心任务指令 | “介绍你自己” | 需用完整疑问句明确任务,如示例中的就业前景分析 |
| input | 任务执行的补充输入信息 | “”(示例为空) | 当需要额外数据时使用,如待翻译文本、待分析数据等 |
| output | 对应指令的标准答案输出 | “xxxxx”(截断示例) | 应包含事实数据(如就业率)、逻辑框架(分点论述)、专业术语 |
| history | 多轮对话历史记录 | [ [“之前问题1”, “回答1”], [“之前问题2”, “回答2”] ] | 可以为空 |
微调+原理解析
将微调数据放入到LLaMA-Factory/data/目录下。(注意:LLaMA-Factory 默认包含 identity.json数据集,覆盖即可)
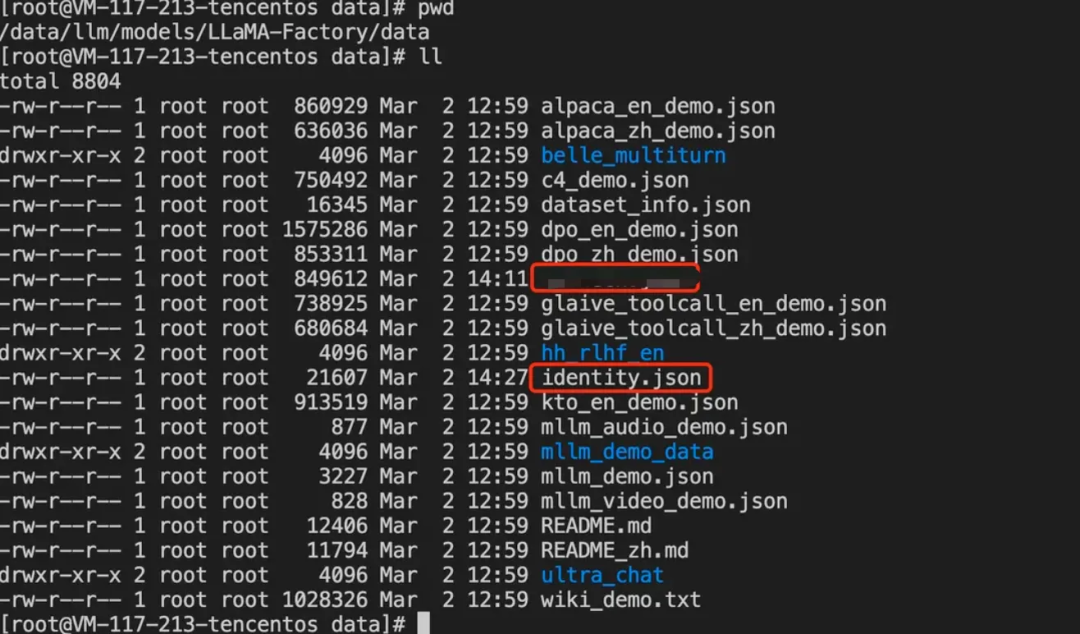
修改数据注册文件dataset_info.json文件。增加
微调原理简介:在预训练的模型基础上,用特定领域数据进一步训练以适配具体任务,例如:用法律文书数据微调模型以提升法律咨询准确性。
方法分类:
- 全参数微调:调整所有参数,适用于数据充足的场景。
- 轻量级微调:如LoRA(低秩适配),仅更新部分参数,降低计算成本。
这个实验场景中就是使用的LoRA进行微调。LoRA具体的原理可参考:https://arxiv.org/pdf/2106.09685
webui配置微调:
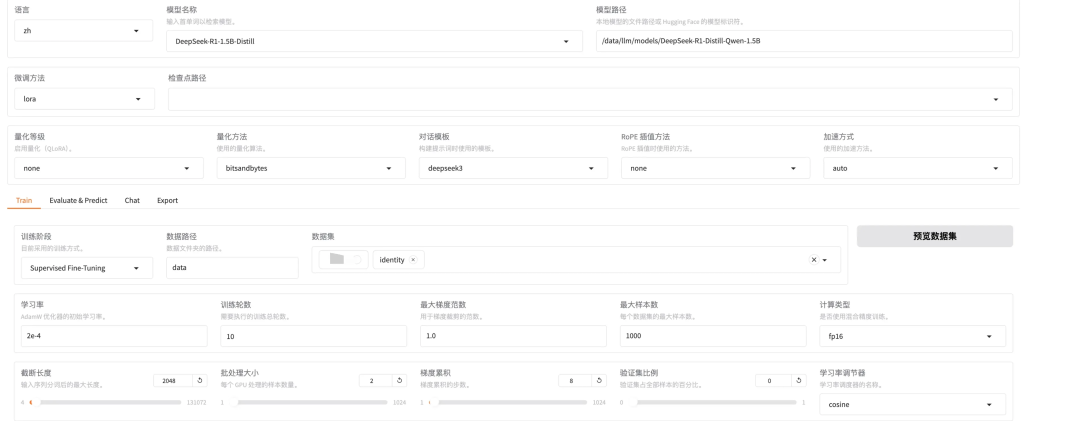

llama-factory支持非常多的微调参数,了解详情可查看 llama-factory官方文档。这里由于是简单实验就不过多解释了。

然后开始训练模型(等待训练完成)。
微调后模型部署及效果展示
此时在使用上面相同的聊天内容询问模型,则回复的是我们训练数据中的内容。但此时需要加载俩个模型,一个是通用基础模型,一个是刚刚低秩的适配器。也就是此时,想让其他人使用这个模型,需要提供俩个模型文件,比较繁琐。
模型合并
为了解决上面需要导出多个模型文件的文件,所以需要将俩个模型进行一个模型合并。将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。
llamafactory-cli export cust/merge_deepseekr1_lora_sft.yaml
合并配置文件:
### model
model_name_or_path: /data/llm/models/DeepSeek-R1-Distill-Qwen-1.5B/
adapter_name_or_path: /data/llm/models/LLaMA-Factory/saves/DeepSeek-R1-1.5B-Distill/lora/train_2025-03-02-19-26-55
template: deepseek
finetuning_type: lora
### export
export_dir: /data/llm/models/DeepSeek-R1-Distill-Qwen-1.5B-rcpc/
export_size: 4
export_device: cuda
export_legacy_format:
完成模型合并之后,会在目录下多一个模型出来。

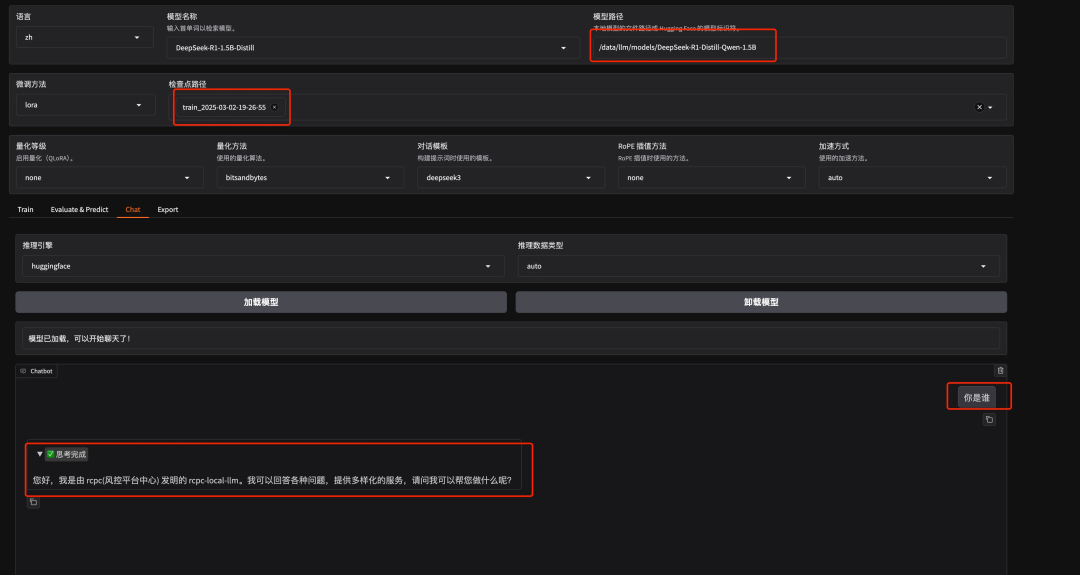
微调后新模型效果演示
此时使用LLaMA-Factory webui 加载新模型,然后与之对话。就可以得到微调后的模型了。
02
本地大模型联网功能开发
2.1 整体架构
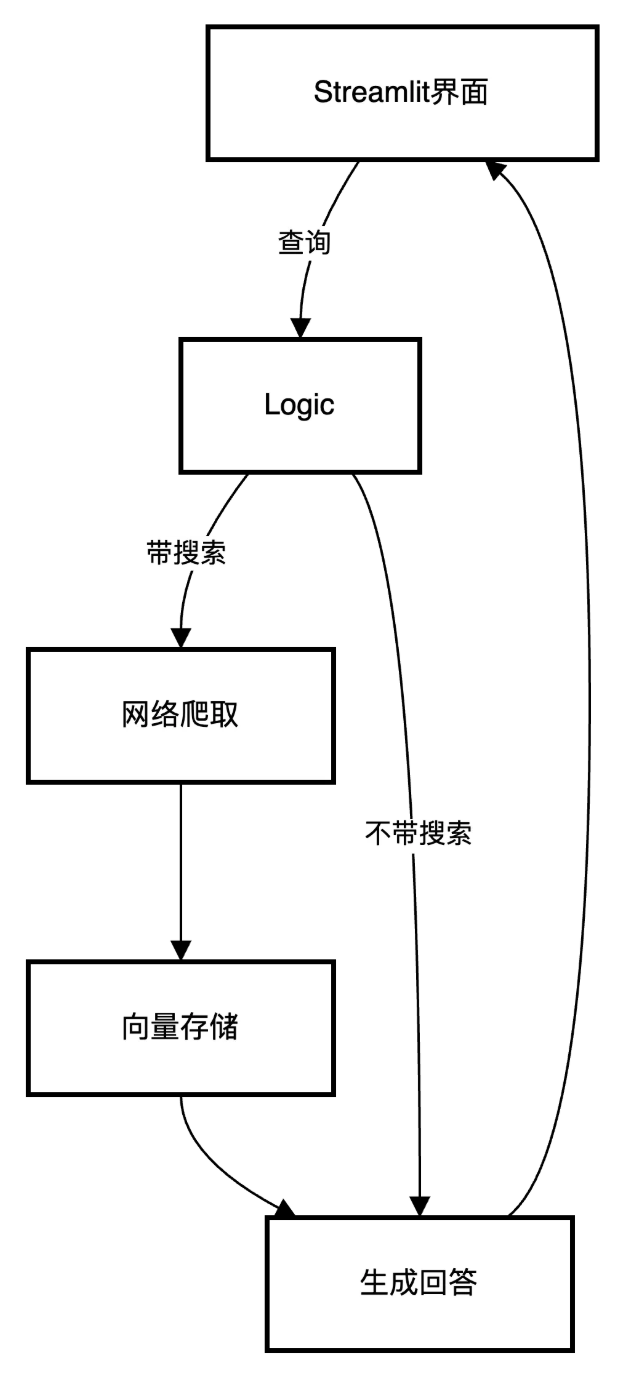
2.2 LLM 调用
流程图:
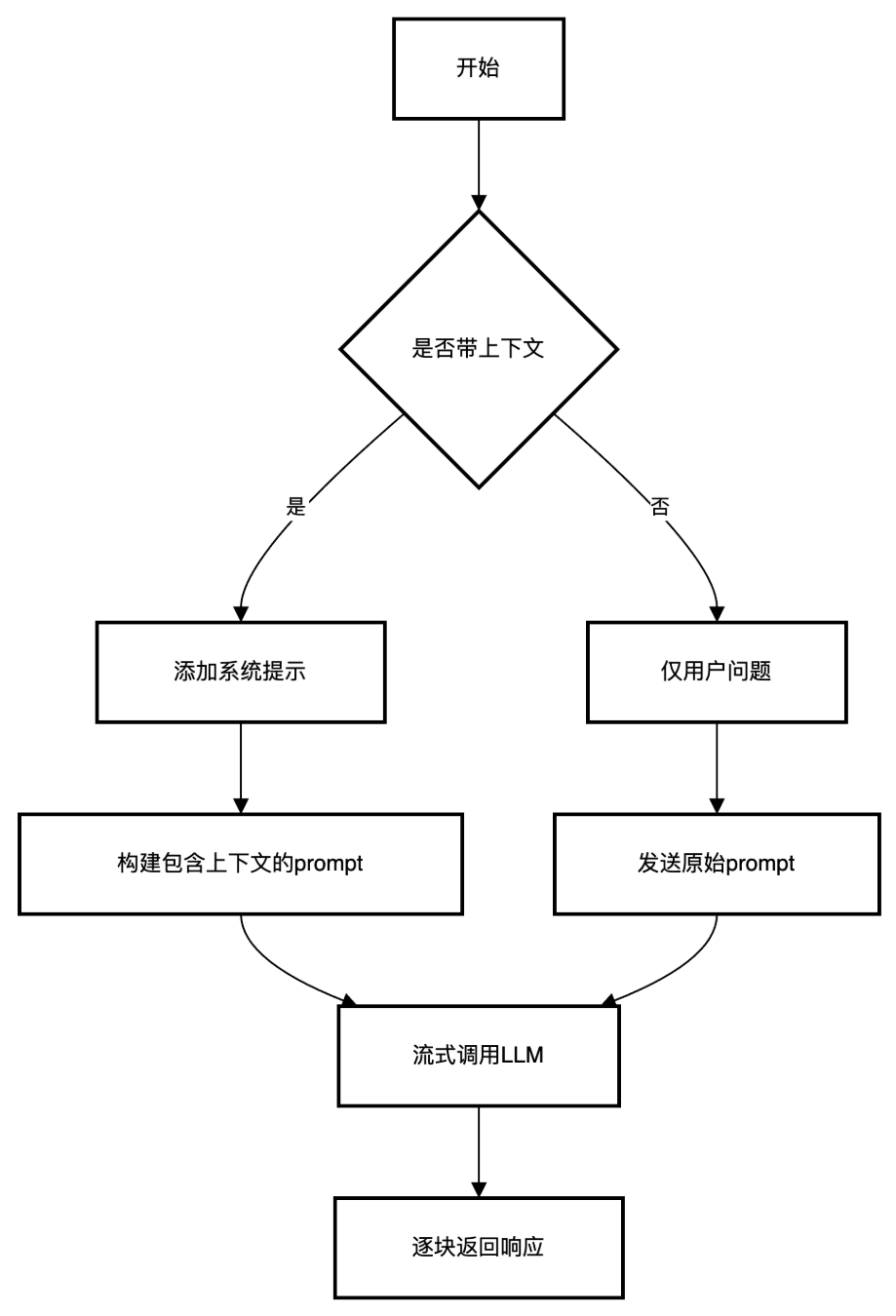
def call_llm(prompt: str, with_context: bool = True, context: str | None = None):
功能: 调用本地运行的Ollama LLM模型生成回答。
参数:
- prompt: 用户的问题/提示。
- with_context: 是否使用系统预设的上下文规则。
- context: 额外上下文信息。
实现细节:
-
构建包含系统提示和用户问题的消息结构。
-
使用ollama.chat进行流式响应(stream=True)。
-
根据with_context参数动态调整消息结构。
-
使用deepseek-r1:1.5b模型,通过生成器逐块返回响应。
-
系统提示严格限制回答必须基于提供的上下文。
2.3 向量数据库初始化
def get_vector_collection() -> tuple[chromadb.Collection, chromadb.Client]:
功能: 初始化ChromaDB向量数据库连接。
关键点:
- 使用nomic-embed-text:latest嵌入模型。
- 创建持久化存储的客户端(路径./web-search-llm-db)。
- 设置余弦相似度作为距离计算方式。
- 返回可重用的集合对象。
技术参数:
Settings(anonymized_telemetry=False) # 关闭匿名数据收集
metadata={"hnsw:space": "cosine"} # 配置HNSW索引算法
2.4 URL规范化
def normalize_url(url):
转换规则:
-
移除https://和www.前缀
-
替换特殊字符:
-
- / → _
- - → _
- . → _
-
示例:
https://www.example.com/path → example_com_path
目的:生成适合作为向量数据库ID的标准化字符串
2.5 数据存储
def add_to_vector_database(results: list[CrawlResult]):
处理流程:
chunk_size=400 # 每块约400字符
chunk_overlap=100 # 块间重叠100字符
-
使用递归字符分割器:
-
创建临时Markdown文件加载内容。
-
通过UnstructuredMarkdownLoader解析文档。
-
为每个文本块生成:
-
- 内容文本。
- 元数据(来源URL)。
- 唯一ID(标准化URL_序号)。
-
批量插入向量数据库。
2.6 网页爬取
async def crawl_webpages(urls: list[str], prompt: str) -> CrawlResult:
核心技术:
- 异步爬虫框架(AsyncWebCrawler)
- BM25算法过滤相关内容:
BM25ContentFilter(user_query=prompt, bm25_threshold=1.2)
- 浏览器配置:
headless=True # 无头模式
text_mode=True # 仅提取文本
page_timeout=20000 # 20秒超时
过滤策略:
excluded_tags = ["nav", "footer", "header", "form", "img", "a"] # 排除导航元素
remove_overlay_elements = True # 移除浮动元素
2.7 爬虫合规检查
def check_robots_txt(urls: list[str]) -> list[str]:
实现逻辑:
-
为每个URL构造robots.txt地址。
-
使用RobotFileParser解析规则。
-
通过can_fetch判断爬取权限。
-
异常处理:
-
- 无法访问robots.txt时默认允许。
- 网络错误时保留URL。
合规性: 确保遵守目标网站的爬虫规则。
2.8 网络搜索
def get_web_urls(search_term: str, num_results: int = 10) -> list[str]:
功能流程:
-
排除视频类网站:
-
- discard_urls = [“youtube.com”, “britannica.com”, “vimeo.com”]
-
使用DuckDuckGo搜索API。
-
结果过滤:
-
- 取前num_results个结果。
- 转换结果格式为URL列表。
-
执行check_robots_txt二次过滤。
2.9 效果展示

03
业务场景探索
微调了模型、实现了联网功能后,需要思考如何将这些技术能力与实际业务结合。下面就针对中心主要产品,安全相关几个具体业务方向,探讨大模型可能的应用场景和实施思路。
3.1 APK病毒检测:让AI学会“闻味道”
现在查杀手机病毒主要靠特征库比对,就跟用通缉令抓犯人似的。但病毒变种越来越快,这种办法容易漏网。大模型可以这么玩:
- 理解代码的“坏心思”:比如有个计算器APP非要读取通讯录,调教好的大模型能发现这种不合理行为,就算病毒换了马甲也能嗅出味道。
- 多维度关联分析:把APP的权限申请、后台行为、数据流向这些线索串起来看,就像老刑警破案时把各种线索拼出完整画像。
落地步骤可以分三步走:
- 先准备一批病毒样本和正常APP的数据集,重点盯防数据窃取这类典型作恶方式。
- 初期让AI当辅助侦探,帮着验证传统引擎发现的嫌疑对象。
- 最终做成混合模式,传统方法快速初筛,AI负责深度研判。
难点在于怎么把APP的二进制代码“翻译”成AI能理解的语言,还要防止AI学得太死板只会认老病毒。
3.2 网址安全检测:教AI识破“美人计”
现在钓鱼网站检测主要看域名黑名单、页面关键词,但高级钓鱼网站会玩文字游戏。大模型可以:
- 看穿页面的“话术套路”:比如冒充银行官网要你输密码,AI能理解整个页面的诱导话术,而不是只会找“密码”这个词。
- 综合判断多重证据:结合网址特征、证书信息、跳转轨迹这些线索,就像鉴宝专家要综合看材质、包浆、款识。
- 识别高仿界面:有些钓鱼网站把LOGO微调几个像素,AI能像鉴假画一样发现细节破绽。
实施时需要训练AI重点看网页关键部位(比如登录框、客服弹窗),还要处理动态加载的内容。难点在于实时检测的速度,毕竟用户可不想等半天才出结果。
3.3 APP隐私检测:当个“数据保镖”
现在隐私检测主要看权限列表以及沙箱动态环境行为监控,可以尝试增加与大模型的结合,做得更智能:
- 查言行是否一致:比如隐私政策说不会收集位置信息,但代码里偷偷调用了定位接口,看看大模型是否能当场抓包,然后在沙箱动态环境行为监控结合,进行数据返哺,从而使LLM数据更完善,决策更准确。
- 判断合理性:一个手电筒APP要读取通讯录?AI会质疑这和核心功能有毛关系。
- 风险定级:结合数据类型(比如人脸比设备ID敏感)、使用场景来打分,像体检报告分不同风险等级。
关键在于从混淆代码里提取有效行为数据,还要处理不同国家的法规差异。
04
未来展望与实践建议
写到这里,也该收尾了。折腾了这么多技术细节和业务可能的探索,不妨放眼看看更大的图景——AI时代已经扑面而来,我们这些技术人该如何应对?
4.1 AI技术趋势预测与应对策略
说实话,预测技术走向就像预测股市一样不靠谱,但有几个趋势我觉得八九不离十:
垂直领域模型将胜出通用模型
GPT-4很强,但在特定领域,一个精心微调过的小模型往往能达到90%的效果,成本却只有5%。前段时间看到几个创业公司的几个医疗领域的垂直模型,在诊断建议上的准确度竟然超过了通用大模型。
我个人判断,未来1-2年,会出现大量针对特定领域的精细微调模型,它们会在各自的赛道上挑战通用大模型的地位。这个趋势对我们意味着:与其花大力气追赶最新的通用模型,不如考虑如何在自己熟悉的业务领域构建专业模型。
多模态将成为标配,但别被噱头忽悠
现在谈AI的多模态能力已经不新鲜了,但我注意到一个有趣的现象:很多产品把多模态当作噱头,实际应用场景却相当有限。比如,一个企业内部的文档助手真的需要图像理解能力吗?大多数情况下并不需要。
我的建议是理性看待多模态:有些场景确实需要(如内容审核、智能安防),有些则纯属浪费资源。在技术选型时,先问问自己:“这个能力能解决什么实际问题?”别为了酷而追求酷。
T型技能结构更有竞争力
在AI时代,纯粹的技术专家可能不如复合型人才吃香。那些在AI浪潮中如鱼得水的企业与个人,往往不是算法最强的,而是那些既懂技术又懂业务的“T型人才”。
举个例子,一个既懂NLP又懂金融的工程师,比单纯的NLP专家或金融分析师更难被替代。因为他不仅知道“怎么做”,还知道“为什么做”和“做什么有价值”。
如果你还是技术路线的“I型人才”,建议尽快横向扩展一个业务领域知识,形成自己独特的复合竞争力。这条也适用于大部分业务,之前业务需要无数的构造地基,形成自己的护城河,但现在通用模型以及领域模型可以更快速的搭建极为强大的地基,在于竖型的垂直业务相结合,会延伸出更强大可靠的护城河。LLM+业务才是未来。
持续学习已经不是选项,而是必须
以前我们开玩笑说“每隔18个月,你的技术栈就会过时一半”。现在在AI领域,这个周期可能只有6个月。想想看,2022年底Stable Diffusion刚出来,到现在SDXL已经迭代了多少代?GPT从3.5到4,再到现在的Claude系列,变化有多快?
所以,如果想在当前领域发展,必须接受“永远在学习”的现实。
4.2 开源与商业模式的思考
谈完技术和应用,我想分享一些关于AI时代商业模式的思考。
开源大模型与API服务将长期共存
有人预测开源模型会颠覆OpenAI这样的API服务商,我持保留意见。就像Linux的开源并没有消灭Windows一样,开源模型和商业API服务很可能长期共存,各自服务不同场景和用户群体。
开源模型的优势在于可控性和定制化,适合对数据安全有高要求或需要深度定制的场景;而API服务的优势在于使用便捷、持续更新、技术门槛低,适合快速验证和非核心业务场景。
垂直领域的AI服务商机巨大
与其在通用AI领域与巨头正面竞争,不如找准垂直领域深耕。我观察到这样一个现象,在医疗、法律、金融,安全等专业领域,用户更愿意为“懂行”的AI服务付费,哪怕它比通用模型“笨”一些。
大模型时代的护城河在哪里?
随着开源模型性能逼近商业模型,纯靠模型能力的护城河正在被削弱。未来的竞争优势可能来自:
- 数据资产: 独特的、高质量的领域数据。
- 应用创新: 基于AI能力的产品创新和用户体验创新。
- 解决方案整合: 将AI能力与行业知识和业务流程深度融合。
简单说,比拼的不再是谁有更强的大模型,而是谁能让AI更好地解决实际问题,创造真实价值。
4.3 未来已来,诸君共勉
写了这么多,最后说点肺腑之言。
AI技术的发展速度远超我们的预期,我们正经历一场前所未有的技术革命。作为技术人,这既是挑战也是机遇。所以应该快速学习、勇于尝试。
回想我的AI探索之旅,最大的收获是思维方式的转变:不再把AI视为遥不可及的黑科技,而是当作可以掌握的工具和能力。只要肯下功夫,普通开发者也能驾驭这些技术,创造有价值的应用。
最后,与其焦虑AI会不会取代人类,不如思考如何与AI协同工作,发挥人类目前独有的创造力、判断力和同理心。技术再强大,也只是放大人类意志的工具,而不是替代人类价值的终极答案。
未来已来,但由我们共同塑造。诸君共勉!
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
那么应该如何学习大模型
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【
保证100%免费】
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 29
29 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)