QWen 和 DeepSeek 入门指南
即便是不会开发AI模型,也必须逐步了解其中的某些概念和一些原理。
我发现最近被 AI 控制了,搜索引擎的使用频率逐渐降低,有问题要查询的时候,第一时间就是找 AI 来询问。
大型语言模型 ( LLMs ) 彻底改变了人工智能领域,使以前被认为是人类独有的自然语言处理任务成为可能。
另外公司组织去微软参观人家的技术,发现不得不紧跟潮流了。
所以我们即便是不会开发AI模型,但是必须逐步了解其中的某些概念和一些原理。
1. 偶然的发现
买了一块 AMD 的显卡,本来是想平常空闲时间,玩玩 AAA 的游戏,欣赏一下里面的风景;有一次逛显卡驱动的官网,发现 AMD 也进军 AI 领域了,并且提供了和 NVIDIA 类似的一套开发工具:AMD HIP SDK 和 AMD ROCm
-
AMD HIP SDK(Heterogeneous-computing Interface for Portability)是 AMD 提供的一套跨平台的 GPU 编程工具,旨在帮助开发者编写能够在 AMD 和 NVIDIA GPU 上运行的高性能计算代码。它是一个类似
CUDA的编程模型,允许开发者以更简单的方式开发 GPU 加速的代码。 -
AMD ROCm(Radeon Open Compute)是 AMD 为高性能计算和机器学习开发的开源 GPU 计算平台。它包含运行时、工具链和库,用于在 AMD GPU 上实现高性能计算任务。
提示
HIP 是 GPU 编程工具
ROCm 是 GPU 计算平台,提供运行时、库、工具和驱动等,其包含 HIP SDK
刚开始接触这几个概念,不免想到几个问题:
如果使用 PyTorch + ROCm 开发,是否要把 HIP 引入到工程中(我当时想当然类比了JDK)
问题来了:官方提供的 HIP 只有Windows版本,ROCm目前只能在Linux环境下;这不是冲突了么,如果使用 PyTorch没法开发呀!官方的架构图如下:
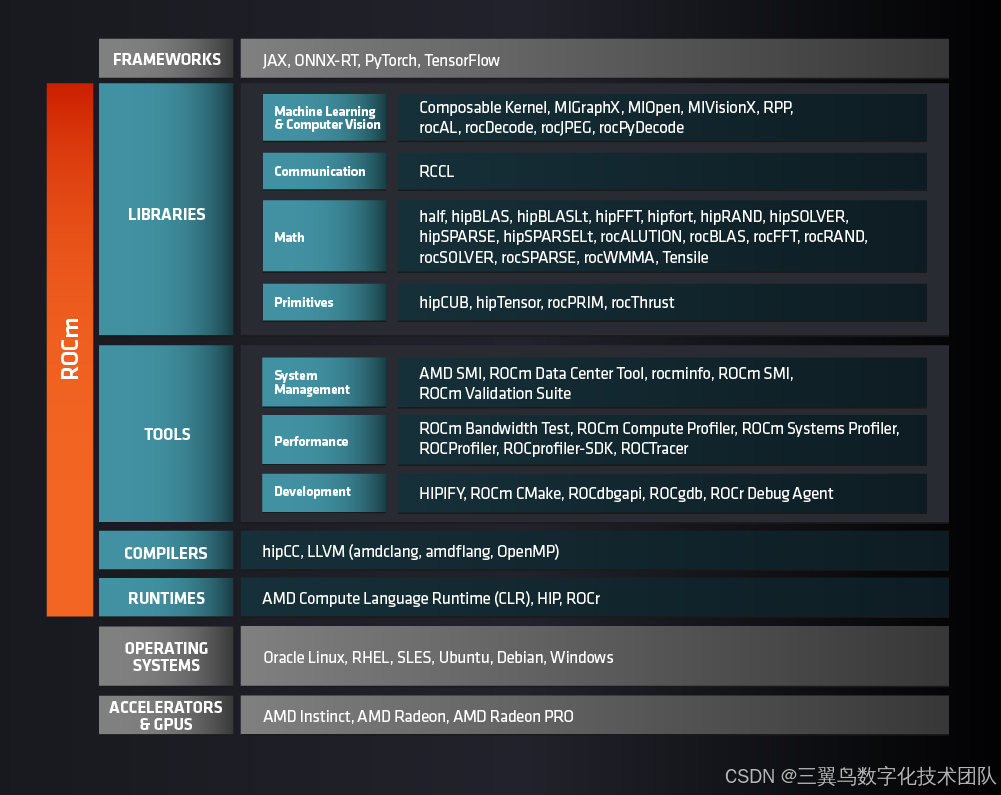
2. 探索
没办法,没在官网找到答案,还是问问AI吧:
-
PyTorch 本身并不直接依赖 HIP,而是通过 ROCm 提供的底层运行时和加速库(例如 MIOpen、 rocBLAS等)完成GPU加速。
-
Windows 上的 HIP SDK 主要用于开发其他 GPU 应用(如科学计算或图形处理),而不是运行 PyTorch 。
开发的问题搞清楚了,那么下一步,开发完成后,模型如何运行?既然是在 Linux 上使用 ROCm 开发的,Windows 又没有 ROCm 环境,这怎么部署呢?使用 ROCm 开发的程序无法使用 NVIDIA 显卡加速么?
AI 模型分为训练和运行两个阶段
训练:在 Linux 上使用 ROCm 和 PyTorch 开发和训练你的深度学习模型。训练完成后,将 PyTorch 模型保存为通用格式(如
.pt或.onnx文件)。运行:在 Windows 系统上重新配置 PyTorch 环境,加载保存的模型并进行推理。如果不依赖 GPU 加速,直接使用 PyTorch CPU 后端。如果需要 GPU 加速,这里以 onnx 文件为例展开具体讨论
2.1 什么是ONNX
ONNX 是一种开放的神经网络交换格式,由微软和 Facebook(现 Meta)联合推出,旨在解决深度学习模型的跨平台和跨框架兼容性问题。
ONNX 模型可以在 Windows、Linux 和 macOS 等操作系统上运行。
对硬件的支持非常广泛,包括 CPU、NVIDIA GPU(基于 CUDA)、AMD GPU(基于 ROCm 或 DirectML)、甚至是特定的 AI 加速器(如谷歌 TPU)。
DirectML 是微软推出的一种通用 GPU 加速推理 API,基于 DirectX 12 构建,支持 AMD、NVIDIA 和 Intel GPU。游戏党肯定知道 DirectX,因为 AAA 游戏中,通常有GPU加速选项,经常有这个哥们的身影。
2.2 在 Linux 上
# 安装 ONNX Runtime(支持 CPU):
pip install onnxruntime
# 安装支持 ROCm 的 ONNX Runtime:
pip install onnxruntime-rocm
# 安装支持 CUDA 的 ONNX Runtime:
pip install onnxruntime-gpu这里需要根据手头的硬件,选择安装哪种 GPU 的 onnx 运行时
2.3 在 Windows 上
# 安装通用的 ONNX Runtime:
pip install onnxruntime
# DirectML 是微软推出的跨厂商 GPU 加速 API,支持 AMD 和 NVIDIA GPU
pip install onnxruntime-directml
# Windows 可直接安装支持 CUDA 的 ONNX Runtime:
pip install onnxruntime-gpu也就是说,如果手头只有 AMD 的 GPU,只能通过 DirectML 来对 PyTorch 训练的模型进行加速
另外,在 macOS 上,ONNX Runtime 目前仅支持 CPU 推理(没有 GPU 加速支持)。
总结,虽然 ONNX 是跨平台的,但硬件加速依赖于具体的运行时支持。例如:
-
NVIDIA GPU 需要 CUDA 和 cuDNN。
-
AMD GPU 在 Windows 上依赖 DirectML。
注意
ONNX 模型的 opset 版本(操作集版本)需要与目标推理引擎兼容。常见的选择是 opset 11 或更新版本(ONNX Runtime 通常支持 opset 版本 11-17)。
如果目标 ONNX Runtime 不支持模型的 opset 版本,则可能无法加载模型。
2.4 ONNX Runtime 的执行提供者(Execution Providers, EPs)
ONNX Runtime 是一个跨平台的推理引擎,支持多种硬件加速方案。为了适配不同的硬件平台,ONNX Runtime 提供了多种执行提供者,每种提供者对应特定的硬件和加速方案:
| Execution Provider (EP) | 支持平台 | 主要用途 |
| CPUExecutionProvider | 所有平台 | 默认执行提供者,不使用硬件加速,适用于没有 GPU 的场景。 |
| CUDAExecutionProvider | NVIDIA GPU | 使用 NVIDIA 的 CUDA 和 cuDNN 来加速推理,适用于 NVIDIA GPU 用户。 |
| ROCMExecutionProvider | AMD GPU(Linux) | 使用 AMD 的 ROCm 平台加速推理,适用于 Linux 环境中的 AMD GPU 用户。 |
| DmlExecutionProvider | DirectML(Windows) | 基于 DirectML 提供跨硬件加速,支持 AMD GPU、NVIDIA GPU 和 Intel GPU,适用于 Windows 用户。 |
| OpenVINOExecutionProvider | Intel 硬件 | 利用 Intel 的 OpenVINO 工具包加速推理,适用于 Intel CPU 和 VPU(如 Movidius)。 |
| TensorrtExecutionProvider | NVIDIA GPU(Linux) | 使用 NVIDIA TensorRT 提供更高效的推理性能,专门针对 NVIDIA GPU 的优化推理引擎。 |
| QNNExecutionProvider | Qualcomm 硬件 | 利用 Qualcomm 的 Hexagon DSP 加速推理,适用于移动设备上的 Qualcomm 芯片。 |
| CoreMLExecutionProvider | Apple 硬件(macOS/iOS) | 使用 Apple 的 CoreML 框架,在 macOS 和 iOS 上加速推理。 |
| DirectML Execution Provider | 跨硬件(Windows) | DirectML 是 Windows 下的通用加速解决方案,适用于 AMD、NVIDIA 和 Intel 的 GPU。 |
3. 进一步梳理
-
开发者小明有一块 NVIDIA GPU;开发者小红有一块 AMD GPU
-
开发者小明使用 NVIDIA GPU,并且通过 CUDA 加速训练了一个模型。训练完成后,小明将模型导出为 ONNX 格式的模型文件(
.onnx)-
ONNX 是一种 跨框架、跨硬件平台的开放格式,因此无论是小明的 NVIDIA GPU 还是小红的 AMD GPU,都能够加载和运行这个 ONNX 文件。
-
ONNX 的设计使得它与硬件无关,因此小明用 CUDA 训练模型的细节(如框架或硬件)对最终的模型运行没有限制。
-
小明可以直接用 NVIDIA GPU 和 ONNX Runtime + CUDAExecutionProvider 来运行他的 ONNX 模型;并通过以下代码执行推理:
pip install onnxruntime-gpuimport onnxruntime as ort # 使用 NVIDIA CUDA 加速 ort_session = ort.InferenceSession("model.onnx", providers=["CUDAExecutionProvider"])
-
-
小红的场景:AMD GPU + DirectML + Windows
-
小红有一台 Windows 电脑,并配备了一块 AMD 显卡
-
小红想要运行小明导出的 ONNX 模型(
.onnx文件) -
虽然小红没有 NVIDIA GPU,也没有 CUDA 环境,但她依然可以通过 DirectML 提供者来利用 AMD GPU 加速运行模型
pip install onnxruntime-directmlimport onnxruntime as ort # 使用 DirectML 提供者(适用于 Windows 平台) ort_session = ort.InferenceSession("model.onnx", providers=["DmlExecutionProvider"]) # 验证当前正在使用的执行提供者 print("当前使用的执行提供者:", ort_session.get_providers())
-
4. 其它概念
4.1 GGUF
GGUF 是 GGML(Georgi Gerganov Machine Learning)系列框架的一种新的模型格式,用于优化大语言模型(LLM)的存储与推理。它是专门为 CPU 和轻量化 GPU 推理场景设计的,特别适合资源受限的设备
PyTorch 或 TensorFlow 等都支持导出或转换为 GGUF 和 ONNX 格式
目前,GGUF 格式主要由 llama.cpp 及相关工具链支持。这意味着将模型转换为 GGUF 格式,需要依赖一些特定工具,而不是直接在深度学习框架中生成 GGUF 文件。
-
支持的工具链:llama.cpp:
-
GGUF 格式是基于 llama.cpp 的生态发展起来的,用于轻量化推理。
-
llama.cpp 提供了工具来将大语言模型(如 LLaMA、Qwen 等)从主流框架(如 PyTorch)转换为 GGUF 格式。
-
官方仓库:llama.cpp
-
-
GGUF 和 ONNX 的运行环境对比
属性 GGUF ONNX 格式设计目标 轻量化推理,适合低资源设备 通用性,支持多任务、多框架、多硬件 操作系统支持 Linux、macOS、Windows(WSL)及安卓 全平台(Linux、Windows、macOS 等) 硬件支持 主要依赖 CPU,初步支持 GPU CPU、GPU、TPU、FPGA,支持复杂硬件加速 工具链依赖 llama.cpp(轻量化工具链) ONNX Runtime、TensorRT、OpenVINO 等 运行优化需求 低资源消耗,适合边缘设备 高性能优化,依赖硬件加速 是否硬件无关 是(取决于 llama.cpp 的实现) 是(取决于 ONNX Runtime 的实现) -
llama.cpp 提供了对 DirectML 的支持(通过调用 DirectML 的 GPU 加速能力),从而实现 GGUF 格式的推理加速。DirectML 支持所有支持 DirectX 12 的 AMD GPU(例如 RX 6000 系列、RX 7000 系列显卡)。
-
llama.cpp 目前还没有直接支持 ROCm
-
llama.cpp 支持 OpenCL 后端;支持 NVIDIA GPU 和 AMD GPU
-
llama.cpp 支持 Vulkan 后端;支持 AMD 和 NVIDIA GPU
-
llama.cpp 尚未直接支持 NVIDIA 的 CUDA 后端
4.2 Q(Quantization,量化)
-
q通常表示 量化(Quantized),常用于描述模型的量化权重或激活值。 -
量化是通过将浮点数(如
FP32或FP16)转换为整数(如INT8)或低比特精度的表示来实现的。目的是减少模型的存储和计算成本,同时尽量保持其精度。 -
例如,
q6和q5可能表示量化为 6 位和 5 位精度的权重或数据。
使用 Qwen2.5-Coder-32B-Instruct-GGUF 这个模型,计算机内存:32GB,GPU显存 24GB;量化方案如何选择?
-
q6_k(6-bit 量化)
-
6-bit 量化后,每参数占用约 0.75 字节。
-
模型占用显存 ≈ 32 × 10⁹ × 0.75 / (1024³) = 22.39GB。
-
总显存需求(包括临时激活值和上下文长度)可能接近或略超过 24GB,因此可能需要优化上下文长度设置。
-
q5_k_m(5-bit 量化)
-
5-bit 量化后,每参数占用约 0.625 字节。
-
模型占用显存 ≈ 32 × 10⁹ × 0.625 / (1024³) = 18.66GB。
-
总显存需求通常在 20GB 左右,在 24GB GPU 显存 内运行较为轻松。
总结:更推荐 q5_k_m,在某些高负载场景(如较长上下文或多批量推理)中,q6_k 可能会超出显存限制
4.3 开源AI库
4.3.1 DeepSeek
逻辑推理,模型:gguf
实测模型:deepseek-r1-distill-llama-8b;内存:32GB,显存:24GB
deepseek-r1-distill-llama-8b:
<think> 好,我需要在 Android 上用 Rust 写一个 FFI 的 Demo,然后调用 C++ 的方法,把结果通过 rust-jni 返回给 Java 层。首先,我应该了解一下 FFI 是什么,它是跨平台的函数调用机制,允许不同语言之间互相调用函数和操作。
接下来,我需要设置项目结构。可能需要一个 main.rs 文件作为 Rust 代码的入口,然后创建一个 Java 类,使用 rust-jni 来暴露功能给 Java 层。由于是在 Android 上运行,我还要处理JNI的相关事务,比如注册Native方法。
然后,我得考虑如何调用 C++ 的方法。或许我可以写一个 C++ 的库,定义一些函数,然后用 Rust 调用这些函数。但是,在 Android 中使用 C++ 可能有点复杂,特别是如果需要动态链接库的话。可能需要构建一个静态库或者共享库,然后让 Rust 在 Android 上找到它。
关于 FFI,我需要在 Rust 中使用 unsafe块来进行指针操作。这部分可能会有点难,因为我要正确地传递参数和返回值,同时处理错误情况。如果遇到问题,可能需要调试一下,用断点或者日志来查看调用是否成功。
然后是如何将结果返回给 Java 层。rust-jni 提供了一些方法,比如 try_from_result 或 on_result ,可以用来从 Rust 的结果转换成 Java 的异常或者可选值。这部分我需要仔细看看 rust-jni 的文档,确保正确地处理数据类型和错误。
在编写代码的时候,我还得注意线程安全问题,因为 Android 应用的主线程可能会被阻塞。如果有长时间的操作,可能需要用到其他线程,并通过JNI来通知 Java 层进度或者结果。
最后,测试每个部分是否正常工作。首先是 Rust 调用 C++ 函数,看看返回值是否正确。然后,再检查 rust-jni 是否正确地将数据传递给 Java 层,确保两层之间的通信没有问题。
总之,这是一个复杂但有趣的项目,我需要一步步来,遇到问题时仔细分析和解决。 </think>
以下是使用 Rust 和 Android 平台开发一个 FFI Demo 的步骤说明:
1. 安装依赖项
首先,我们需要安装一些必要的依赖项。对于 rust-jni,在 Android 上可能需要一些特定的配置。
-
如果你还没有安装 cargo.toml,可以先安装:
cargo install --dev-
安装 rustfmt 以确保代码格式正确:
cargo add rustfmt --all-features-
安装 rust-jni:
cargo add https://github.com/Bytedance/rust-jni2. 创建项目结构
创建一个新的 Rust 项目,并添加必要的配置文件。
-
在 Cargo.toml 中添加以下内容:
[package]
name = "rust_jni_demo"
version = "0.1.0"
edition = "2021"
[dependencies]
rust-jni = "latest"
jni_utils = "0.3"
android_support = "0.4"
[[path]]
name = "src/main.rs"3. 编写 Rust 代码
在 src/main.rs 中,编写一个简单的 FFI Demo。
use jni::JNIEnv;
use jni::sys::System;
#[derive(Debug)]
struct RustStruct {}
impl RustStruct {
fn new() -> Result<Self, Box<dyn std::error::Error>> {
println!("创建了一个Rust结构体");
Ok(RustStruct {})
}
}
#[jni::main]
fn main(
mut env: JNIEnv,
_class: *const u8,
) -> i32 {
// 初始化Android环境
System::initialize(env);
let result = RustStruct::new();
println!("Rust调用成功,结果={}", result);
// 返回结果给Java层
return result.map(|_| 0).try_into().unwrap_or(0);
}4. 编写 Java 层的代码
创建一个 MainActivity 类,并在其中使用 rust-jni 调用 Rust 方法。
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.id.main);
try {
// 调用Rust层的方法
String result = callRustMethod();
Toast.makeText(this, "从Rust返回的结果是:" + result, Toast.LENGTH_LONG).show();
} catch (JNIError e) {
Toast.makeText(this, "JNI错误:" + e.toString(), Toast.LENGTH_LONG).show();
}
}
// 使用 rust-jni 注册一个方法
@Override
public boolean onTouchEvent(MotionEvent event) {
callRustMethod();
return true;
}
// 使用rust-jni创建一个函数,调用Rust层的功能
private static final String METHOD_NAME = "callRustFunction";
private static final int METHOD_ID = JNIEnv.getStaticMethodID(
getClass().getDeclaredClass(),
METHOD_NAME,
new Class<?>[] {}
);
private String callRustMethod() {
try (JNIEnv env = new Env()) {
return env.call-static<java.lang.String>(METHOD_ID);
} catch (JNIError e) {
throw new RuntimeException(e);
}
}
// 为了让rust-jni识别这个类,添加注解
@RustJavaClass(name = "com.example.MainActivity", is_jni=False)
public class Activity extends AppCompatActivity {
// ...
}5. 安装和构建 C++ 库(可选)
如果需要调用C++函数,可以编写一个简单的C++库,并将其编译成.so 文件。例如:
// src/cpp/hello.cpp
#include <string>
using namespace std;
extern "C" {
string sayHello() {
return "Hello from C++";
}
}然后在Cargo.toml中添加构建步骤:
[project]
name = "rust_jni_demo"
[dependencies]
...
// 添加一个构建阶段,编译C++库,并生成.so文件
[target.mk]
all : $(objdir)/$(target)/libmyjnilib.so
$(objdir)/$(target)/libmyjnilib.so: src/cpp/hello.o
g++ -o $@ -shared src/cpp/hello.o6. 编译和运行
在命令行编译:
cargo build7. 注意事项
线程安全:确保JNI操作是在主线程执行的,特别是对于长时间运行的任务,可以考虑在子线程处理,并通过JNI发送回调。
错误处理:rust-jni 提供了丰富的错误处理机制,如 JNIEnv::try 来管理资源。
性能优化:对于频繁调用JNI方法的情况,可能需要优化Rust代码,使其更加高效。
8. 验证和调试
在 Rust 中使用 println! 输出日志信息,以验证调用是否成功。
使用 Android 的 Log utility 输出日志,如 Log.d("TAG", "消息"),方便在Android Studio中查看。
通过以上步骤,你应该能够成功地编写一个跨语言的FFI Demo,并将结果返回给Java层,实现了Rust和C++与Android Java层的高效通信。
4.3.2 QWen
逻辑推理,模型:gguf
实测模型:QWen-Coder-2.5-32B-q5_k_m;内存:32GB,显存:24GB
测试电脑比较吃力,显存全部占满,推理速度还是略微慢了点,但是写代码的能力还是媲美GPT的;相较于 deepseek-r1-distill-llama-8b 模型,写代码能力还是强很多的,毕竟这是一个 Coder 模型,而且体量也大。
QWen:
在Android平台上使用Rust通过FFI调用C++方法,并将结果通过rust-jni返回给Java层,可以按照以下步骤进行:
1. 编写C++代码
首先,编写一个简单的C++库,其中包含要被Rust调用的方法。这个例子中,我们创建一个简单的函数来演示。
// src/native-lib.cpp
extern "C" {
int add(int a, int b) {
return a + b;
}
}然后将此代码编译成动态链接库(例如.so文件)。
2. 在Rust中使用FFI调用C++函数
创建一个Rust项目,并通过FFI调用之前定义的C++函数。这通常需要在Rust中声明外部函数,然后调用它。
// src/lib.rs
#[link(name = "native-lib", kind = "dylib")]
extern {
fn add(a: i32, b: i32) -> i32;
}
pub extern "C" fn rust_add(a: i32, b: i32) -> i32 {
unsafe { add(a, b) }
}3. 使用rust-jni与Java层交互
现在我们需要编写代码,使得Rust的rust_add函数能够被Java调用,并通过JNI返回结果。
首先,在你的Android项目中添加依赖到jni-rs库。在Cargo.toml文件中:
[dependencies]
jni = "0.21"然后创建一个JNI接口,以便Rust和Java之间可以相互操作:
// src/jni_interface.rs
use jni::JNIEnv;
use jni::objects::{JClass, JObject};
use jni::sys::jint;
#[no_mangle]
pub extern "C" fn Java_com_example_myapp_MainActivity_addNumbers(
_env: JNIEnv,
_class: JClass,
a: jint,
b: jint) -> jint
{
rust_add(a, b)
}4. 编译Rust库并集成到Android项目中
编译你的Rust代码为适用于Android的动态链接库(例如.so文件)。你可以使用cargo-ndk工具来简化这个过程。
cargo install cargo-ndk
cargo ndk --target aarch64-linux-android build --release这将生成一个可以在Android设备上运行的.so文件。你需要将其放置在适当的目录中,以便Java层可以加载它(通常是在app/src/main/jniLibs/对应架构下)。
5. 在Java中调用Rust函数
最后,在你的Java代码中加载共享库,并调用我们刚刚暴露的方法:
// MainActivity.java 或者其他适当的Java/Kotlin文件
public class MainActivity extends AppCompatActivity {
static {
System.loadLibrary("your_rust_lib_name"); // 替换为你的.so文件名(不带前缀lib和后缀.so)
}
public native int addNumbers(int a, int b);
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
int result = addNumbers(10, 20); // 调用Rust函数
Log.d("MainActivity", "Result of addition: " + result);
}
}通过以上步骤,你就成功地在Android平台上使用Rust通过FFI调用了C++方法,并将结果返回给了Java层。确保所有路径和库名称都正确无误,以便应用能够顺利运行。
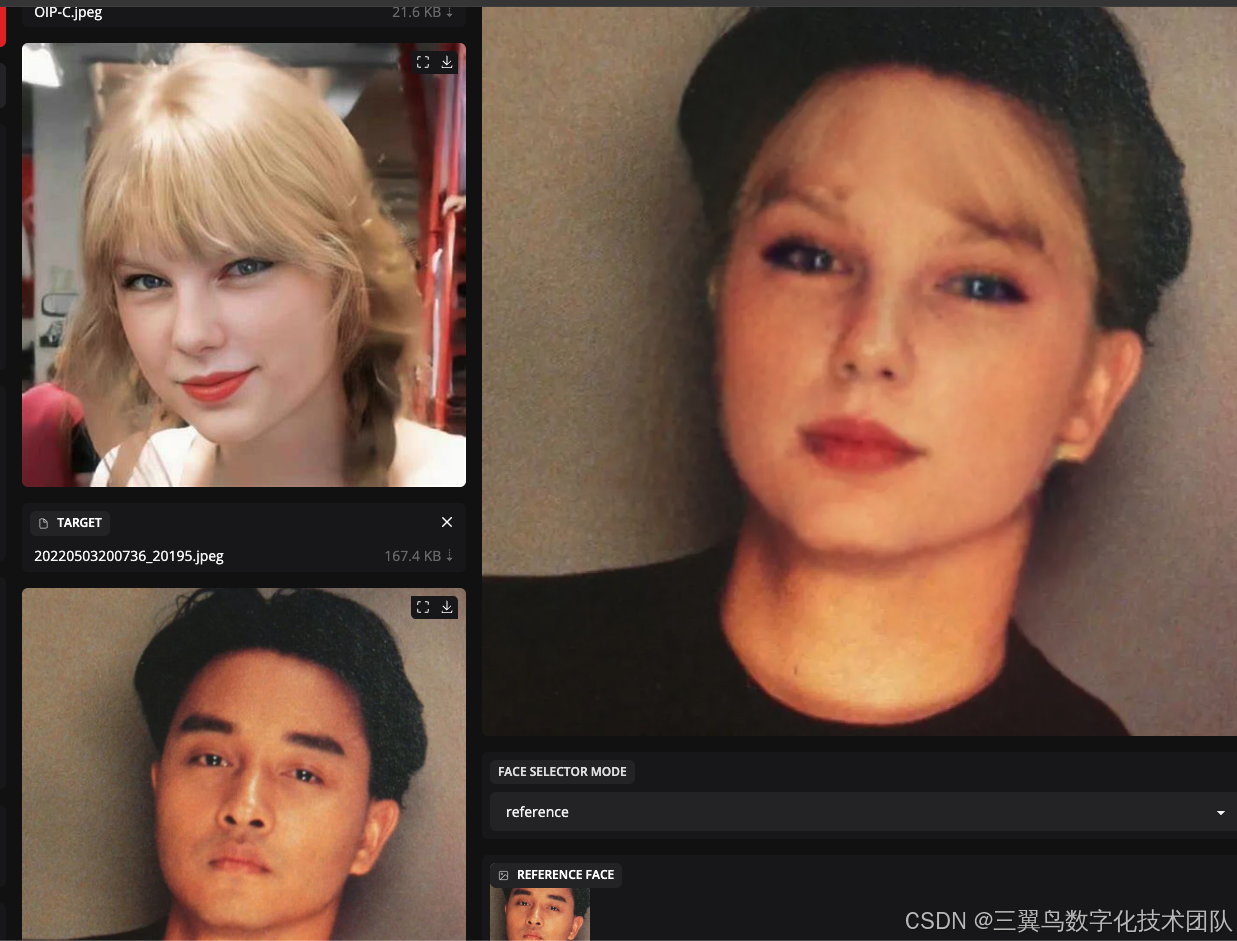
4.3.3 Facefusion
换脸,模型:onnx
python facefusion.py run 24-12-31 - 12:45:17
* Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.换脸效果:参数不太会调,头发有瑕疵
5. 参考
CUDA 工具包和 cuDNN:
6. 团队介绍
「三翼鸟数字化技术平台-智家APP平台」通过持续迭代演进移动端一站式接入平台为三翼鸟APP、智家APP等多个APP提供基础运行框架、系统通用能力API、日志、网络访问、页面路由、动态化框架、UI组件库等移动端开发通用基础设施;通过Z·ONE平台为三翼鸟子领域提供项目管理和技术实践支撑能力,完成从代码托管、CI/CD系统、业务发布、线上实时监控等Devops与工程效能基础设施搭建。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)