前沿多模态模型开发与应用实战3:DeepSeek-VL2多模态理解大模型算法解析与功能抢先体验
基于飞桨多模态大模型开发套件PaddleMIX,详细解读多模态理解模型DeepSeek-VL2。
多模态理解大模型,是一类可以同时处理和理解多种数据形式(如图像、文本、视频等)的人工智能大模型,可以应用于图文理解、视觉问答、文档理解、场景描述等任务。本文将介绍目前热门的 DeepSeek-VL2 多模态大模型。DeepSeek-VL2是一款基于混合专家(MoE,Mixture of Experts)架构的多模态大模型,结合了混合专家架构和多模态数据处理能力,通过稀疏计算和专家分工的方式高效处理多种模态(如文本、图像、音频等)的数据,推理时只激活部分网络参数。而前两期课程介绍的Qwen2.5VL、Janus-Pro 以及 DeepSeek-VL第一代模型,则是经典的Dense类的多模态理解大模型,会对所有模型参数进行计算和更新。MoE(Mixture of Experts)混合专家模型的核心思想是将模型划分为多个专家子网络(experts),并通过路由机制(router)动态选择合适的专家来处理输入数据。MoE的最大优势就是是稀疏激活,只有少数几个专家网络模块会被激活,这意味着计算量可以显著减少,计算效率得到提升,同时精度指标远远超出相同激活参数量的Dense类模型。

DeepSeek-VL2 在视觉理解上的效果展示
接下来,本篇文章内容将包括模型结构、训练流程、模型能力的展示,并以飞桨多模态开发套件 PaddleMIX 中 DeepSeek-VL2 的实现为例,对代码进行逐步解读。
模型架构
DeepSeek-VL2的前身是去年发布的DeepSeek-VL,其模型结构设计是经典的Dense模型结构,也就是有参数都会进行计算和更新。DeepSeek-VL由三个主要模块组成:
-
Hybrid VisionEncoder:混合视觉编码器,采用SigLIP-L作为视觉编码器,结合SAM-B和SigLIP-L编码器,能够高效处理高分辨率图像(1024×1024),同时保留语义和细节信息。高分辨率特征图经过插值和卷积处理后,与低分辨率特征图连接,生成具有2048个维度的视觉token。
-
VL Adaptor:视觉语言适配器,使用两层混合MLP桥接视觉编码器和语言模型。高分辨率和低分辨率特征分别经过单层MLP处理后沿维度连接,再通过另一层MLP转换到语言模型的输入空间。
-
DeepSeek LLM:语言模型是DeepSeek-LLM,其设计遵循LLaMA,采用Pre-Norm结构和SwiGLU激活函数,使用旋转嵌入进行位置编码。
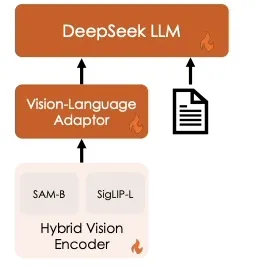
DeepSeek-VL 架构
而近期发布的 DeepSeek-VL2 尽管是MoE架构,但它也是由三部分核心模块组成:视觉编码器Vision Encoder、视觉-语言适配器VL Adaptor 和 DeepSeek-MoE 语言模型。与其前身 DeepSeek-VL 相比,DeepSeek-VL2 在视觉编码器和语言建模部分都有了显著的提升,这主要是因为DeepSeek-VL2引入了两项重大改进:动态切片策略,以及采用多头隐变量注意力(Multi-head Latent Attention,MLA)机制的 DeepSeek-MoE 语言模型。这些创新使得 DeepSeek-VL2 能够更高效地处理高分辨率视觉输入和文本数据。
DeepSeek-VL2 架构
- Vision Encoder:DeepSeek-VL2 采用的也是SigLIP,同时引入了动态切片策略(Dynamic Tiling Strategy),能够处理不同分辨率和长宽比的高分辨率图像。传统的图像编码方法往往固定分辨率,导致在处理较大或不规则图像时性能下降。动态切片策略通过将高分辨率图像分割成多个小块进行处理,减少了计算成本,同时保留了详细的视觉特征。该方法避免了传统视觉编码器的固定分辨率限制,使得模型在处理复杂图像任务(如视觉引导、文档分析等)时具有更好的性能。
- VL Adaptor:DeepSeek-VL2 采用两层多层感知器(MLP),然后再使用 2×2 pixel shuffle 操作压缩每个图像块的 token 数目,用于视觉特征映射到文本空间。
- DeepSeek-MoE LLM:语言模型采用了DeepSeek-MoE(Mixture of Experts)架构,并结合了多头潜在注意力机制(Multi-head Latent Attention,MLA)。MLA 机制能够有效压缩键值缓存(KV Cache),提升推理效率。MoE架构则通过稀疏计算进一步提升了效率,使得模型在处理大规模数据时能够实现更高的吞吐量。
在模型尺寸上,DeepSeek-VL2 系列目前有以下3个参数版本:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small 和 DeepSeek-VL2,分别拥有1B、2.8B 和 4.5B 的激活参数。具体的结构设置如下表所示: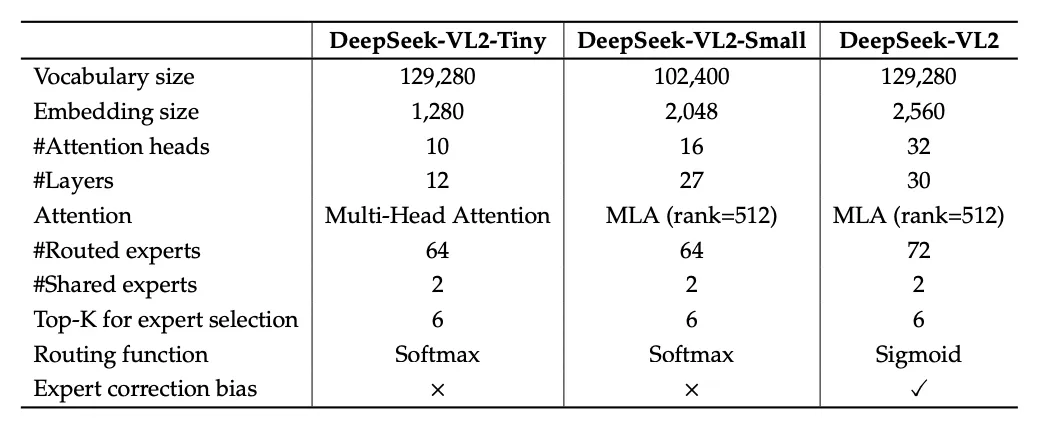
DeepSeek-VL2 三种参数量的模型设置
创新点
Part1
动态图像切片编码策略
- 动态切片策略:
DeepSeek-VL2将一张高分辨率图像切片,为了适应不同长宽比,首先定义了一组候选分辨率:CR={(m⋅384,n⋅384) ∣ m∈N,n∈N,1≤m,n,mn≤9}, m:n表示宽高比。对于一张(H,W)图像,在保证宽高比不变下调整图像分辨率,计算以长边对其到候选分辨率所需要的填充的区域面积。选择面积最小的分辨率 (mi⋅384,ni⋅384),然后将调整大小后的图像划分成 mi×ni个 384×384分辨率的局部图块以及一个全局缩略图块。出于计算效率和上下文长度管理的考虑,在处理多于 2 张图像时,禁用动态图块策略。
DeepSeek-VL2 中的动态切片策略
在将图片切片后,再使用 2×2 pixel shuffle 操作压缩每个图像块的 token 数目, 从 27×27 压缩至 14×14=196 tokens 对于全局缩略图像块(14×14),在每一行的末尾添加14个<tile_newline>标记,从而总共得到14×15=210 个 tokens。当处理 mi×ni 个局部图像块时,在每一行的局部块末尾新增<tile_newline>,共新增mi⋅14 <tile_newline> 个 tokens,完整的 Visual Token 包含 210+1+mi⋅14×(ni⋅14+1) 个视觉标记,这些 Tokens 随后使用两层多层感知器(MLP)投影到语言模型的 Embedding 空间中。
Part2
DeepSeek-MoE语言模型
在语言模型部分,DeepSeek-VL2 使用了 DeepSeek-MoE 语言模型,该模型结合了混合专家(Mixture of Experts, MoE)架构和多头潜在注意力(Multi-head Latent Attention,MLA)机制。MoE 架构通过选择性激活不同的专家网络,实现了计算资源的高效利用和模型性能的提升。而MLA机制MLA机制通过将键值缓存压缩为潜在向量,增强了推理效率,从而提升了吞吐量,且能够在处理多模态信息时,更好地捕捉到视觉和语言之间的复杂关系,进而提升模型在图文理解、问答等任务中的表现。
在MoE训练过程中,为每个专家引入了一个全局偏置项,以经济高效的方式改善专家之间的负载均衡。现有的MoE架构可能存在知识混杂(Knowledge Hybridity)和知识冗余(Knowledge Redundancy)的问题,限制了专家的专业化。在实现思想上,DeepSeek-MoE采用两个主要策略:
- Fine-Grained Expert Segmentation-细粒度的专家分割,通过细化FFN中间隐藏维度,维持参数数量不变的同时激活更多细粒度的专家,使得激活的专家更加灵活和适应性更强;
- Shared Expert Isolation-共享专家隔离,将某些专家隔离为共享专家,始终激活,旨在捕捉和巩固不同上下文中的共同知识。
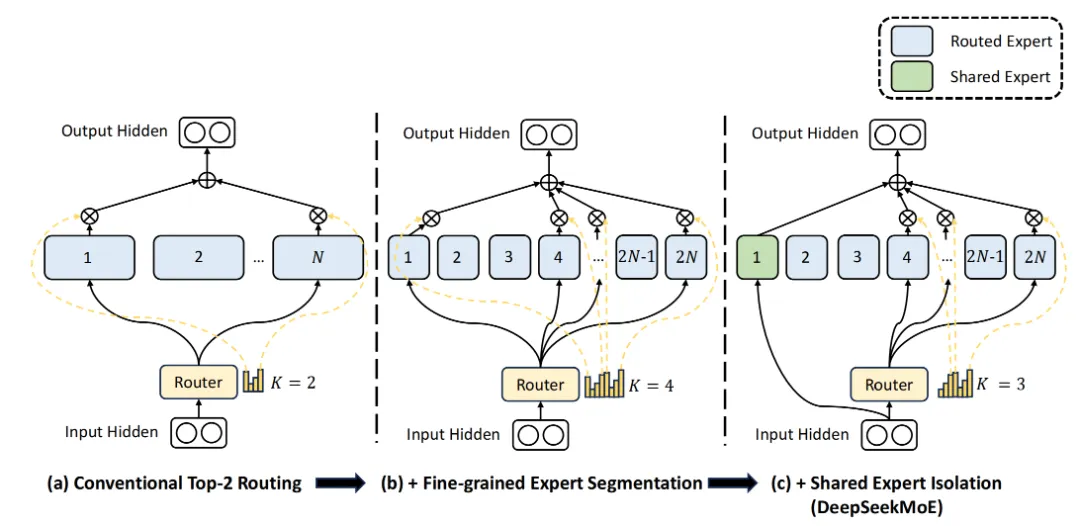
DeepSeek-MOE 的架构
Part3
高效的推理速度与吞吐量
为了提升模型的推理速度,DeepSeek-VL2 在语言部分的处理上引入了键值缓存压缩技术。这项技术能够有效减少计算中的冗余操作,从而提高推理过程的效率,尤其在处理大规模数据时表现出色。通过这种优化,DeepSeek-VL2 在多个任务上不仅表现出了更高的准确率,也大大提升了计算效率。
训练方法
Part1
训练数据
DeepSeek-VL2 从多种来源构建了一个综合性的视觉-语言数据集。训练过程分为三个阶段:(1)视觉-语言对齐(VL alignment);(2)视觉-语言预训练(VL pretraining);3)监督微调(Supervised Fine-Tuning)。
- VL alignment 数据
对齐阶段专注于训练多层感知机(MLP)VL Adaptor,以桥接预训练的视觉编码器和大型语言模型。这一阶段使用了ShareGPT4V数据集,该数据集包含大约120万个描述和对话样本。 - VL-Pretrain 数据
VL-Pretrain 数据结合了视觉-语言数据和纯文本数据,以保持VL能力和纯文本性能之间的平衡。对于DeepSeek-VL2,作者保持了大约70%的VL数据和30%的纯文本数据的比例,后者直接来源于作者基础大型语言模型(LLM)的预训练语料库。
Image-Text 混合数据:
数据收集始于几个开源数据集,包括WIT、WikiHow和OBELICS中的30%随机样本。这一特定的混合比例是通过使用DeepSeek-VL2-Tiny进行初步实验确定的。为了增强多语言能力,在主要以英语为主的数据集中补充了从Wanjuan中提取的中文内容。此外,DeepSeek-VL2 还开发了一个内部数据集,以扩大对一般现实世界知识的覆盖范围。
Image Caption 数据:
图像描述是视觉语言模型(VLM)训练中的基础数据,提供了视觉信息和文本信息之间的直接对齐。因为开源数据集质量差异很大,为了解决这些质量不一致的问题,DeepSeek-VL2开发了一个全面的图像描述流程,该流程考虑了:(1)光学字符识别(OCR)提示;(2)元信息(例如位置、相机设置);(3)原始描述作为提示。DeepSeek-VL2 使用内部Captioner,使用 类似于PixelProse的提示策略重新为图像添加描述,采用不同的指令来指导VLM生成描述。尽管Catpion整体质量有所提高,在大规模标注流程中观察到了重复问题。为了缓解这一问题,DeepSeek-VL2采用一个质量控制流程,使用DeepSeek Chat仅根据 Caption 的写作质量进行评分。
OCR 数据:
LaTex OCR 和 12M RenderedText、包括不同文档类型的大规模内部数据集
VQA 数据:
- DeepSeek-VL 通用的VQA数据。
- 表格、图表和文档理解数据。PubTabNet、FinTabNet 和 Docmatix。
- Web-to-code 和 plot-to-Python 生成。Websight,并遵循DeepSeek-VL的方法,使用公开的Jupyter笔记本中的Python图表。通过使用DeepSeek V2.5对Websight 部分数据增强。作者还利用DeepSeek V2.5生成的Python图表代码来减少plot-to-code 中的噪声。
- 包括视觉提示的 QA数据:参考Vip-llava构建具有不同视觉提示(箭头、方框、圆圈和涂鸦)的数据。
Visual grounding 数据:
基于Kosmos-2和Objects365构建 视觉定位数据,并采用以下模版构建 - Prompt: \texttt{Locate <|ref|><|/ref|> in the given image.}
- Response: \texttt{<|ref|><|/ref|><|det|>[[x1, y1, x2, y2],\ldots]<|/det|>}
Grounded 对话数据:
基于 Kosmos-2 构建视觉定位对话数据 并采用以下模版构建
- Prompt: \texttt{<|grounding|>Can you describe the content of the image?}
- Response: $\texttt{Two <|ref|>dogs<|/ref|><|det|>[[x1, y1,
x2, y2],\ldots]<|/det|> are running on the grass.}
- SFT 数据
DeepSeek-VL2 的SFT数据结合了多种开源数据集与高质量的内部QA对。
General visual question-answering:
虽然VQA数据集种类繁多,但它们通常存在三大局限:(1)回答简短;(2)光学字符识别(OCR)质量不佳;(3)内容虚幻。为解决这些问题,DeepSeek-VL2 综合考虑原始问题、图像和OCR信息来重新生成回答。作者的实验表明,这种方法能产生更全面、更准确的结果。在DeepSeek-VL2的开发过程中早期版本,尤其是Tiny变体,偶尔会在中文回答中不恰当地插入英文单词。这一问题在DeepSeek-VL2 大型模型中并不存在,这表明它源于模型容量有限以及视觉-语言预训练阶段中英文数据的不平衡。为解决小型模型中的这一局限,DeepSeek-VL2团队开发了一个包含多样图像描述和单轮/多轮对话的内部中文问答数据集。该数据集有助于缓解语言混合问题。此外还创建了补充现实世界的和文化相关的视觉知识,包括动漫、网络梗、美食和艺术的内部数据集。
OCR and document understanding:
得益于DeepSeek-VL2先进的Caption Pipeline,DeepSeek-VL2已经展现出比其他最先进的视觉语言模型(VLM)更优越的OCR能力。因此,在SFT阶段未进一步提升OCR性能,而是专注于清理现有的开源数据集,通过移除OCR质量不佳的样本。对于文档理解,DeepSeek-VL2团队从内部数据中筛选了一个多样化的文档页面子集。然后针对文档理解生成了多轮对话式问答对。
Table and chart understanding:
通过对除Cauldron(其已展现出高质量)外的所有公共数据集基于其原始问题重新生成回答,从而增强了基于表格的问答数据。与在视觉语言预训练阶段开发的OCR能力类似,的模型在图表理解方面也表现出色,且无需额外努力。
Textbook and academic questions:
从文档集合中构建了一个专注于教科书的内部数据集。该数据集主要强调多个学科领域的大学水平内容。
Web-to-code and plot-to-Python generation:
网页到代码与图表到Python代码生成。扩展了内部关于网页代码和Python图表代码的数据集,这些数据集超出了预训练期间所使用的范围。对于开源数据集,通过重新生成答案来提高其质量。
纯文本数据
为了保持模型的语言能力,在SFT阶段,还使用了纯文本指令调整数据集。
Part2
训练阶段
DeepSeek-VL2通过三阶段的流程进行训练:
- 初始阶段:使用3.1.1节中详细描述的图文配对数据,训练视觉编码器和视觉-语言适配器MLP,同时保持语言模型固定。
- 预训练阶段:使用3.1.2节描述的数据进行视觉-语言预训练。在此阶段,所有模型参数,包括视觉编码器、视觉-语言适配器和语言模型,都会解锁并同时训练。
- 微调阶段:使用第3.1.3节概述的数据进行有监督的微调,进一步优化模型性能。
在预训练和微调阶段,强调视觉理解能力,并仅在文本标记上计算下一个标记预测损失。
视觉-语言对齐:
基于预训练的语言模型(DeepSeekMoE 3B/16B/27B),的主要目标是建立视觉特征和语言特征之间的稳固连接。这种对齐使得预训练的语言模型能够有效地处理视觉输入。与之前的方法[54, 59]不同,这些方法保持预训练的视觉编码器和语言模型固定,调整固定分辨率的视觉编码器以适应动态高分辨率图像。在这个阶段,优化视觉编码器和视觉-语言适配器,同时保持语言模型冻结。
视觉-语言预训练:
在嵌入空间中建立视觉-语言对齐之后,将大部分计算资源用于视觉-语言预训练。这个阶段的重点是开发跨多种任务的综合性联合视觉-语言知识。解锁所有参数,包括视觉编码器、视觉-语言适配器和语言模型,并同时进行训练。
通过这些阶段的系统训练,DeepSeek-VL2不仅能够处理高分辨率的视觉输入,还能够在多模态任务中表现出色。这种训练方法使得模型在多样化的任务中提高了视觉和语言理解能力。
有监督微调:
在最后阶段,通过有监督的微调来增强预训练模型的指令跟随能力和对话能力。利用内部的视觉语言SFT数据,优化所有参数,但仅对答案和特殊标记进行监督,同时屏蔽系统和用户提示。为了加强对话理解,将多模态数据与来自DeepSeek-V2的纯文本对话数据结合使用。这种方法确保了在各种视觉语言任务中具有强大的性能,包括密集图像描述、通用视觉问答(VQA)、光学字符识别(OCR)、表格/图表/文档/图形理解、视觉到代码、视觉推理、视觉定位和语言理解等。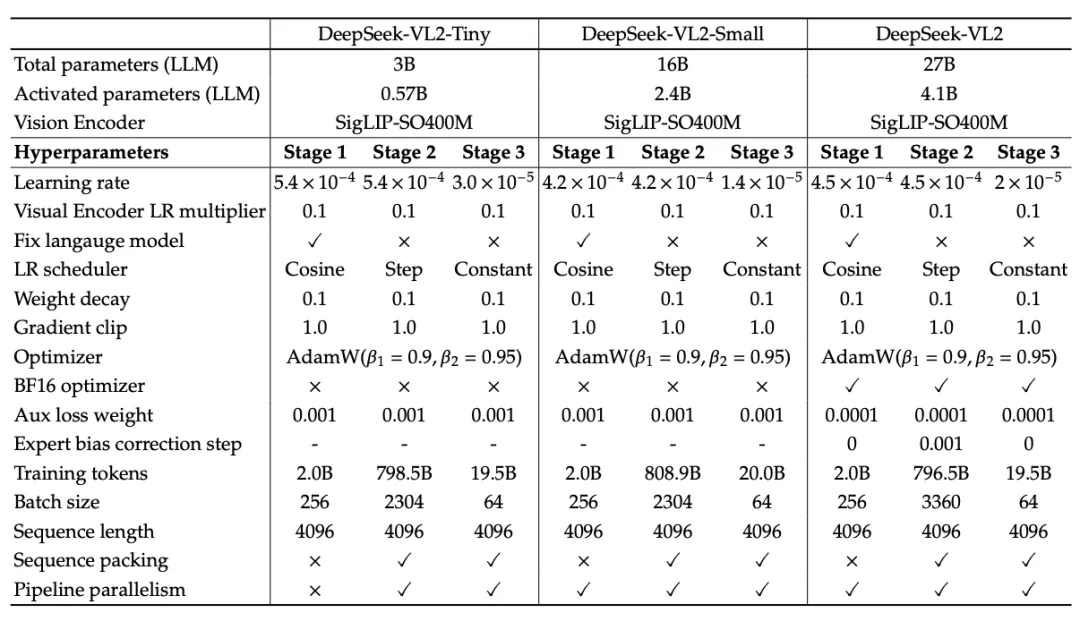
DeepSeek-VL2 的训练超参数
Part3
结果评估
DeepSeek-VL2 在多个常用的多模态基准数据集上进行了评估,包括 DocVQA、ChartQA、InfoVQA、TextVQA 等。这些基准涵盖了从文档理解到逻辑推理等多种任务,全面评估了 DeepSeek-VL2 在不同任务上的表现。
视觉引导能力:
DeepSeek-VL2 在视觉引导任务上展现了强大的能力,能够根据图像中的描述性信息准确定位物体,并生成相应的回答。
多图像对话能力:
DeepSeek-VL2 在处理多图像对话任务时表现突出,能够分析多张图片之间的关系,并基于这些信息进行简单的推理。
视觉故事生成能力:
在视觉故事生成任务中,DeepSeek-VL2 能够根据图片创作出创意十足的故事,并且能够有效结合图像中的细节,如地标识别和 OCR 结果。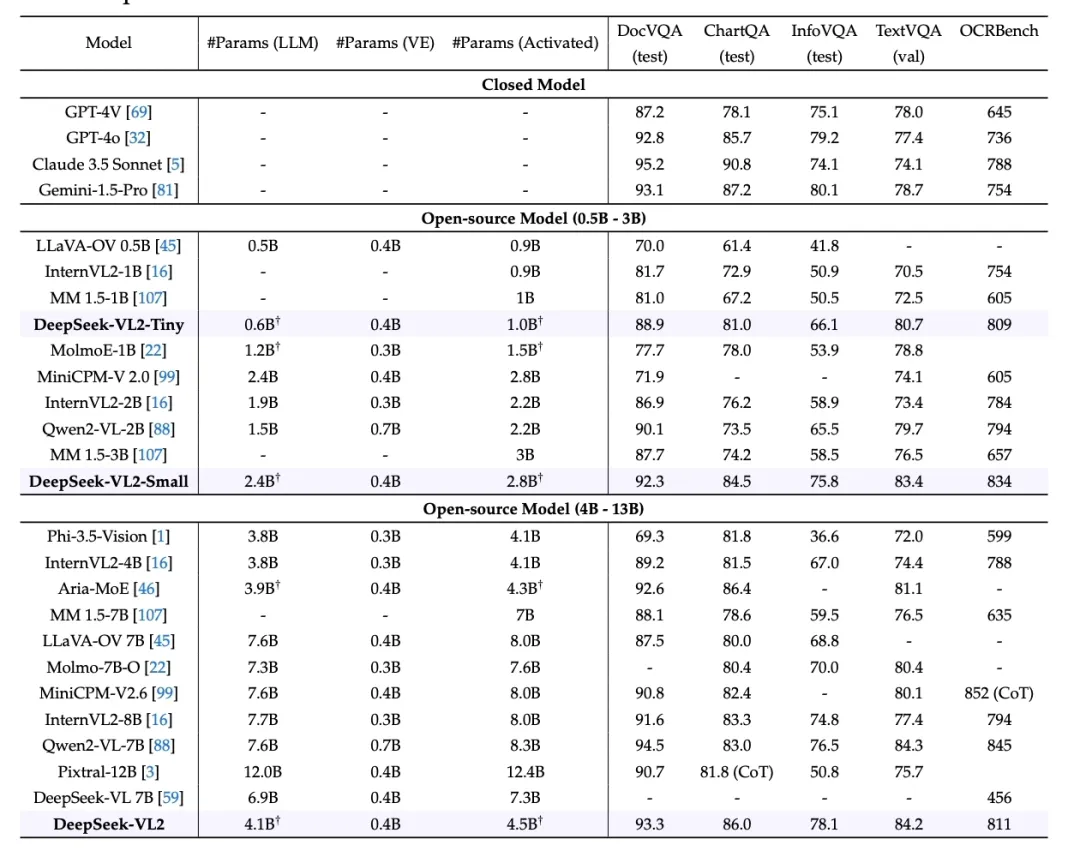
DeepSeek-VL2 OCR相关能力指标结果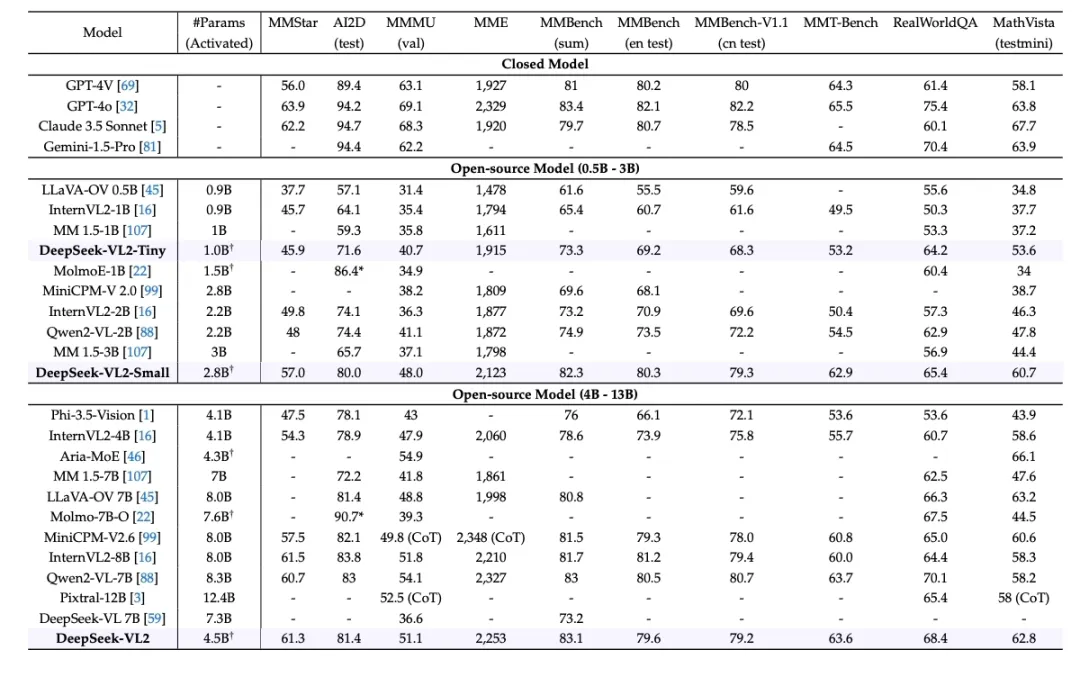
DeepSeek-VL2 通用VQA和数学相关能力指标结果
DeepSeek-VL2 视觉故事生成能力展示
代码解读
下面以PaddleMIX中DeepSeek-VL2的实现为例,对关键创新点的代码实现进行讲解。
PaddleMIX:
https://github.com/PaddlePaddle/PaddleMIX
Part1
动态切片策略
功能:
该函数 select_best_resolution 的目的是在给定的候选分辨率列表中找到最适合原始图像大小的分辨率。
步骤实现:
DeepSeek-VL2 在处理多图像对话任务时表现突出,能够分析多张图片之间的关系,并基于这些信息进行简单的推理。
- 计算缩放比例:对于每个候选分辨率,计算其相对于原始图像尺寸的缩放比例(取宽度和高度缩放比例中的最小值)。
- 计算缩放后的尺寸:使用上述缩放比例计算缩放后的图像宽度和高度。
- 计算有效分辨率:有效分辨率是缩放后的图像分辨率与原始图像分辨率中较小的一个。这是为了确保缩放后的图像不会比原始图像具有更高的分辨率。
- 计算浪费的分辨率:浪费的分辨率是候选分辨率的面积减去有效分辨率的面积。
- 选择最佳匹配:遍历所有候选分辨率,找到有效分辨率最大且浪费分辨率最小的那个作为最佳匹配。如果两个候选分辨率的有效分辨率相同,则选择浪费分辨率较小的那个。
输出:
返回一个元组,代表最佳匹配的分辨率(宽度和高度)。如果没有找到任何合适的分辨率,理论上应该返回 None(尽管在当前的实现中,如果至少有一个候选分辨率,它总是会返回一个结果)。
def select_best_resolution(image_size, candidate_resolutions):
original_width, original_height = image_size
best_fit = None
max_effective_resolution = 0
min_wasted_resolution = float("inf")
for width, height in candidate_resolutions:
scale = min(width / original_width, height / original_height)
downscaled_width, downscaled_height = int(original_width * scale), int(original_height * scale)
effective_resolution = min(downscaled_width * downscaled_height, original_width * original_height)
wasted_resolution = width * height - effective_resolution
if (
effective_resolution > max_effective_resolution
or effective_resolution == max_effective_resolution
and wasted_resolution < min_wasted_resolution
):
max_effective_resolution = effective_resolution
min_wasted_resolution = wasted_resolution
best_fit = width, height
return best_fit
Part2
VL Adapter
方法:
tokenize_with_images
功能:
该函数 tokenize_with_images 的目的是将包含 <image> \texttt{<image>} <image> 标签的文本对话进行分词处理,并同时处理与文本对话相关联的图像。它将文本和图像转换为适合模型处理的格式,包括图像的分辨率调整、裁剪、以及将文本和图像转换为一系列 tokens。
参数:
- conversation: 包含 <image> \texttt{<image>} <image> 标签的原始文本对话。
- images: 与文本对话中的 <image> \texttt{<image>} <image> 标签相对应的图像列表。
- bos: 布尔值,指定是否在分词结果的开头添加开始序列(Begin Of Sequence, BOS) token。默认为 True。
- eos: 布尔值,指定是否在分词结果的末尾添加结束序列(End Of Sequence, EOS)token。默认为 True。
- cropping: 布尔值,指定是否对图像进行裁剪以适应特定的分辨率。默认为 True。
步骤实现:
- 断言检查:确保文本对话中的 <image> \texttt{<image>} <image> 标签数量与提供的图像数量相匹配。
- 文本分割:使用 <image> \texttt{<image>} <image> 标签将文本对话分割成多个部分。
- 初始化列表:用于存储处理后的图像、图像序列掩码、图像空间裁剪信息、图像token数量以及分词后的字符串。
- 遍历文本和图像:对于每个文本部分和对应的图像,执行以下操作:
- 文本分词:将文本部分分词,但不添加 BOS 和 EOS token。
- 图像分辨率选择:根据裁剪标志选择最佳图像分辨率。
- 全局视图处理:将图像调整为固定大小(self.image_size),并填充背景色。
- 局部视图处理:根据最佳分辨率将图像裁剪成多个小块,并对每个小块进行处理。
- 记录裁剪信息:记录每个图像在宽度和高度上被裁剪成的小块数量。
- 添加图像token:为每个图像(全局和局部视图)生成一系列图像token,并添加到分词后的字符串中。
- 更新掩码和token数量:更新图像序列掩码和图像token数量列表。
- 处理最后一个文本部分:对最后一个文本部分进行分词处理(但不添加 BOS 和 EOS token),并更新分词后的字符串和图像序列掩码。
- 添加 BOS 和 EOS token:根据参数设置,在分词结果的开头和末尾添加 BOS 和 EOS token。
- 断言检查:确保分词后的字符串长度与图像序列掩码的长度相匹配。
输出:
返回一个元组,包含以下内容:
- tokenized_str: 分词后的字符串,包含文本和图像token。
- images_list:处理后的图像列表,包括全局视图和局部视图。 images_seq_mask: 图像序列掩码,用于指示哪些token是图像token。
- images_spatial_crop: 图像空间裁剪信息,记录每个图像在宽度和高度上的裁剪小块数量。
- num_image_tokens:每个图像对应的token数量列表。
def tokenize_with_images(
self, conversation: str, images: List[Image.Image], bos: bool = True, eos: bool = True, cropping: bool = True
):
"""Tokenize text with <image> tags."""
assert conversation.count(self.image_token) == len(images)
text_splits = conversation.split(self.image_token)
images_list, images_seq_mask, images_spatial_crop = [], [], []
num_image_tokens = []
tokenized_str = []
for text_sep, image in zip(text_splits, images):
"""encode text_sep"""
tokenized_sep = self.encode(text_sep, bos=False, eos=False)
tokenized_str += tokenized_sep
images_seq_mask += [False] * len(tokenized_sep)
"""select best resolution for anyres"""
if cropping:
best_width, best_height = select_best_resolution(image.size, self.candidate_resolutions)
else:
best_width, best_height = self.image_size, self.image_size
"""process the global view"""
global_view = ImageOps.pad(
image, (self.image_size, self.image_size), color=tuple(int(x * 255) for x in self.image_transform.mean)
)
images_list.append(self.image_transform(global_view))
"""process the local views"""
local_view = ImageOps.pad(
image, (best_width, best_height), color=tuple(int(x * 255) for x in self.image_transform.mean)
)
for i in range(0, best_height, self.image_size):
for j in range(0, best_width, self.image_size):
images_list.append(
self.image_transform(local_view.crop((j, i, j + self.image_size, i + self.image_size)))
)
"""record height / width crop num"""
num_width_tiles, num_height_tiles = (best_width // self.image_size, best_height // self.image_size)
images_spatial_crop.append([num_width_tiles, num_height_tiles])
"""add image tokens"""
h = w = math.ceil(self.image_size // self.patch_size / self.downsample_ratio)
tokenized_image = [self.image_token_id] * h * (w + 1)
tokenized_image += [self.image_token_id]
tokenized_image += [self.image_token_id] * (num_height_tiles * h) * (num_width_tiles * w + 1)
tokenized_str += tokenized_image
images_seq_mask += [True] * len(tokenized_image)
num_image_tokens.append(len(tokenized_image))
"""process the last text split"""
tokenized_sep = self.encode(text_splits[-1], bos=False, eos=False)
tokenized_str += tokenized_sep
images_seq_mask += [False] * len(tokenized_sep)
"""add the bos and eos tokens"""
if bos:
tokenized_str = [self.bos_id] + tokenized_str
images_seq_mask = [False] + images_seq_mask
if eos:
tokenized_str = tokenized_str + [self.eos_id]
images_seq_mask = images_seq_mask + [False]
assert len(tokenized_str) == len(
images_seq_mask
), f"tokenize_with_images func: tokenized_str's length {len(tokenized_str)} is not equal to imags_seq_mask's length {len(images_seq_mask)}"
return (tokenized_str, images_list, images_seq_mask, images_spatial_crop, num_image_tokens)
Part3
MLA(Multi-head Latent Attention)
类名:
DeepseekV2Attention
主要功能:
实现多头注意力机制,用于处理序列数据,支持缓存机制和不同的RoPE(Rotary Position Embedding)缩放策略。
初始化参数 (init):
- config: DeepseekV2Config 类型的配置对象,包含模型的各种配置参数。
- layer_idx: 可选参数,表示当前层的索引,用于缓存机制。
前向传播参数 (forward):
- hidden_states: paddle.Tensor 类型的输入张量,表示隐藏状态。
- attention_mask: 可选参数,paddle.Tensor 类型的注意力掩码,用于屏蔽不需要关注的位置。
- position_ids: 可选参数,paddle.Tensor 类型的位置编码,用于RoPE。
- past_key_value: 可选参数,Tuple[paddle.Tensor] 类型的缓存键值对,用于加速推理。
- output_attentions: 布尔类型,表示是否输出注意力权重。
- use_cache: 布尔类型,表示是否使用缓存机制。
- **kwargs: 其他可选参数。
前向传播 (forward):
实现多头注意力机制,用于处理序列数据,支持缓存机制和不同的RoPE(Rotary Position Embedding)缩放策略。
-
查询投影(Query Projection):
-
如果 q_lora_rank 为 None,则使用 q_proj 对查询进行投影。
-
否则,使用基于 LoRA 的投影(q_a_proj、q_a_layernorm 和 q_b_proj)。
-
键值投影(Key-Value Projection):
-
使用 kv_a_proj_with_mqa 对键和值进行投影。
-
将结果拆分为 LoRA 和 RoPE 组件。
-
RoPE 应用(RoPE Application):
-
计算 RoPE 的余弦和正弦值。
-
将 RoPE 应用于查询和键。
-
缓存(Caching):
如果 use_cache 为 True,则更新缓存的键和值。
注意力权重(Attention Weights):
实现多头注意力机制,用于处理序列数据,支持缓存机制和不同的RoPE(Rotary Position Embedding)缩放策略。
- 使用缩放点积注意力计算注意力分数。
- 应用注意力掩码和 softmax。
- 输出投影(Output Projection):
- 使用注意力权重和投影后的值计算注意力输出。
- 应用输出投影(o_proj)。
class DeepseekV2Attention(paddle.nn.Layer):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: DeepseekV2Config, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
"""
..............
"""
if self.q_lora_rank is None:
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.q_head_dim, bias_attr=False)
else:
self.q_a_proj = nn.Linear(self.hidden_size, config.q_lora_rank, bias_attr=config.attention_bias)
self.q_a_layernorm = DeepseekV2RMSNorm(config=config, hidden_size=config.q_lora_rank)
self.q_b_proj = nn.Linear(config.q_lora_rank, self.num_heads * self.q_head_dim, bias_attr=False)
self.kv_a_proj_with_mqa = nn.Linear(self.hidden_size, config.kv_lora_rank + config.qk_rope_head_dim, bias_attr=config.attention_bias)
self.kv_a_layernorm = DeepseekV2RMSNorm(config=config, hidden_size=config.kv_lora_rank)
self.kv_b_proj = nn.Linear(config.kv_lora_rank, self.num_heads * (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim), bias_attr=False)
self.o_proj = nn.Linear(self.num_heads * self.v_head_dim, self.hidden_size, bias_attr=config.attention_bias)
self._init_rope()
self.softmax_scale = self.q_head_dim**-0.5
if self.config.rope_scaling is not None:
mscale_all_dim = self.config.rope_scaling.get("mscale_all_dim", 0)
scaling_factor = self.config.rope_scaling["factor"]
if mscale_all_dim:
mscale = yarn_get_mscale(scaling_factor, mscale_all_dim)
self.softmax_scale = self.softmax_scale * mscale * mscale
def forward(
self,
hidden_states: paddle.Tensor,
attention_mask: Optional[paddle.Tensor] = None,
position_ids: Optional[paddle.Tensor] = None,
past_key_value: Optional[Tuple[paddle.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
**kwargs,
) -> Tuple[paddle.Tensor, Optional[paddle.Tensor], Optional[Tuple[paddle.Tensor]]]:
bsz, q_len, _ = tuple(hidden_states.shape)
if self.q_lora_rank is None:
q = self.q_proj(hidden_states)
else:
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.reshape([bsz, q_len, self.num_heads, self.q_head_dim]).transpose(perm=[0, 2, 1, 3])
q_nope, q_pe = paddle.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], axis=-1)
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = paddle.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], axis=-1)
compressed_kv = self.kv_a_layernorm(compressed_kv)
k_pe = k_pe.reshape([bsz, q_len, 1, self.qk_rope_head_dim]).transpose(perm=[0, 2, 1, 3])
kv_seq_len = tuple(k_pe.shape)[-2]
if past_key_value is not None:
kv_seq_len += past_key_value[0].shape[1]
cos, sin = self.rotary_emb(q_pe, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
if use_cache and past_key_value is not None:
compressed_kv = compressed_kv.unsqueeze(axis=2)
k_pe = k_pe.transpose(perm=[0, 2, 1, 3]) # (b h l d) to (b l h d)
k_pe = paddle.concat([past_key_value[0], k_pe], axis=1)
compressed_kv = paddle.concat([past_key_value[1], compressed_kv], axis=1)
past_key_value = (k_pe, compressed_kv)
k_pe = k_pe.transpose(perm=[0, 2, 1, 3]) # go back to (b l h d)
compressed_kv = compressed_kv.squeeze(2)
elif use_cache:
past_key_value = (k_pe.transpose([0, 2, 1, 3]), compressed_kv.unsqueeze(axis=2))
else:
past_key_value = None
# shit tranpose liner weight
kv_b_proj = self.kv_b_proj.weight.T.reshape([self.num_heads, -1, self.kv_lora_rank])
q_absorb = kv_b_proj[:, :self.qk_nope_head_dim, :]
out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]
q_nope = paddle.matmul(q_nope, q_absorb)
attn_weights = (
paddle.matmul(q_pe, k_pe.transpose([0, 1, 3, 2])) # [1, 16, 1304, 64] * [1, 1, 1304, 64]
+ paddle.matmul(q_nope, compressed_kv.unsqueeze(axis=-3).transpose([0, 1, 3, 2])) # [1, 16, 1304, 512] * [1, 1, 1304, 512]
) * self.softmax_scale
if tuple(attn_weights.shape) != (bsz, self.num_heads, q_len, kv_seq_len):
raise ValueError(
f"Attention weights should be of size {bsz, self.num_heads, q_len, kv_seq_len}, but is {tuple(attn_weights.shape)}"
)
assert attention_mask is not None
if attention_mask is not None:
if tuple(attention_mask.shape) != (bsz, 1, q_len, kv_seq_len):
raise ValueError(
f"Attention mask should be of size {bsz, 1, q_len, kv_seq_len}, but is {tuple(attention_mask.shape)}"
)
attn_weights = attn_weights + attention_mask
# upcast attention to fp32
attn_weights = F.softmax(attn_weights, axis=-1, dtype="float32").to(q_pe.dtype)
attn_weights = F.dropout(attn_weights, self.attention_dropout, training=self.training)
attn_output = paddle.einsum("bhql,blc->bhqc", attn_weights, compressed_kv)
attn_output = paddle.matmul(attn_output, out_absorb.transpose([0, 2, 1]))
if tuple(attn_output.shape) != (bsz, self.num_heads, q_len, self.v_head_dim):
raise ValueError(
f"`attn_output` should be of size {bsz, self.num_heads, q_len, self.v_head_dim}, but is {tuple(attn_output.shape)}"
)
attn_output = attn_output.transpose([0, 2, 1, 3])
attn_output = attn_output.reshape([bsz, q_len, self.num_heads * self.v_head_dim])
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
Part4
DeepSeekV2-MoE
类名:
DeepseekV2MoE
主要功能:
实现混合专家机制,通过路由机制将输入分配给多个专家网络,并将结果加权组合。
初始化参数 (init):
config: 配置对象,包含模型的各种参数,如专家数量、共享专家数量、中间层大小等。
步骤实现:
-
初始化 (init):
·从配置对象中读取参数,如专家数量、共享专家数量、中间层大小等。
·根据分布式环境(ep_size)分配专家网络到不同的设备上。
·初始化专家网络列表(self.experts)和共享专家网络(self.shared_experts)。
·初始化门控机制(self.gate)。 -
前向传播 (forward):
-
保存输入张量的原始形状和值(identity 和 orig_shape)。
-
使用门控机制(self.gate)计算路由索引(topk_idx)、路由权重(topk_weight)和辅助损失(aux_loss)。
-
将输入张量展平以便处理。
-
训练模式:
·将输入张量复制多次以匹配每个专家的输入。
·根据路由索引将输入分配给对应的专家网络,并计算输出。
·对专家输出进行加权求和,并恢复原始形状。
·添加辅助损失(AddAuxiliaryLoss.apply)。 -
推理模式:
·调用 moe_infer 方法处理输入,并恢复原始形状。
·如果存在共享专家网络,将其输出与专家网络的输出相加。
·返回最终的输出张量。
Part5
MoEGate
类名:
MoEGate
主要功能:
实现混合专家机制的门控逻辑,包括路由权重计算、专家选择和辅助损失计算。
初始化参数 (init):
config: 配置对象,包含模型的各种参数,如专家数量、路由缩放因子、评分函数等。
步骤实现:
- 初始化 (init):
- 从配置对象中读取参数,如专家数量、路由缩放因子、评分函数等。
- 初始化门控权重(self.weight)和路由策略相关参数。
- 如果使用 noaux_tc 路由策略,初始化专家评分校正偏置(self.e_score_correction_bias)。
- 调用 reset_parameters 方法初始化权重。
-
权重初始化 (reset_parameters):
使用 Kaiming 均匀分布初始化门控权重。 -
前向传播 (forward):
- 将输入张量展平以便处理。
- 使用线性变换计算路由得分(logits)。
- 根据评分函数(如 softmax 或 sigmoid)计算路由权重(scores)。
- 根据路由策略(如 greedy、group_limited_greedy、noaux_tc)选择专家并计算路由权重。
- 如果 top_k > 1 且 norm_topk_prob 为 True,对路由权重进行归一化。
- 在训练模式下,计算辅助损失(aux_loss)以优化路由机制。
- 返回路由索引(topk_idx)、路由权重(topk_weight)和辅助损失(aux_loss)。
class MoEGate(paddle.nn.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.top_k = config.num_experts_per_tok
self.n_routed_experts = config.n_routed_experts
self.routed_scaling_factor = config.routed_scaling_factor
self.scoring_func = config.scoring_func
self.alpha = config.aux_loss_alpha
self.seq_aux = config.seq_aux
self.topk_method = config.topk_method
self.n_group = config.n_group
self.topk_group = config.topk_group
# topk selection algorithm
self.norm_topk_prob = config.norm_topk_prob
self.gating_dim = config.hidden_size
self.weight = paddle.base.framework.EagerParamBase.from_tensor(
tensor=paddle.empty(shape=(self.gating_dim, self.n_routed_experts))
)
if self.topk_method == "noaux_tc":
self.e_score_correction_bias = paddle.base.framework.EagerParamBase.from_tensor(
tensor=paddle.empty(shape=[self.n_routed_experts])
)
def forward(self, hidden_states):
bsz, seq_len, h = tuple(hidden_states.shape)
hidden_states = hidden_states.reshape([-1, h])
logits = paddle.nn.functional.linear(
x=hidden_states.astype("float32"), weight=self.weight.astype("float32"), bias=None
)
if self.scoring_func == "softmax":
scores = paddle.nn.functional.softmax(logits, axis=-1, dtype="float32")
elif self.scoring_func == "sigmoid":
scores = logits.sigmoid()
else:
raise NotImplementedError(f"insupportable scoring function for MoE gating: {self.scoring_func}")
if self.topk_method == "greedy":
topk_weight, topk_idx = paddle.topk(k=self.top_k, sorted=False, x=scores, axis=-1)
elif self.topk_method == "group_limited_greedy":
group_scores = scores.reshape(bsz * seq_len, self.n_group, -1).max(dim=-1).values
group_idx = paddle.topk(k=self.topk_group, sorted=False, x=group_scores, axis=-1)[1]
group_mask = paddle.zeros_like(x=group_scores)
group_mask.put_along_axis_(axis=1, indices=group_idx, values=1, broadcast=False)
score_mask = (
group_mask.unsqueeze(axis=-1)
.expand(shape=[bsz * seq_len, self.n_group, self.n_routed_experts // self.n_group])
.reshape([bsz * seq_len, -1])
)
tmp_scores = scores.masked_fill(mask=~score_mask.astype(dtype="bool"), value=0.0)
topk_weight, topk_idx = paddle.topk(k=self.top_k, sorted=False, x=tmp_scores, axis=-1)
elif self.topk_method == "noaux_tc":
assert not self.training
scores_for_choice = scores.reshape([bsz * seq_len, -1]) + self.e_score_correction_bias.unsqueeze(axis=0)
group_scores = scores_for_choice.reshape([bsz * seq_len, self.n_group, -1]).topk(k=2, axis=-1)[0].sum(axis=-1)
group_idx = paddle.topk(k=self.topk_group, sorted=False, x=group_scores, axis=-1)[1]
group_mask = paddle.zeros_like(x=group_scores)
group_mask.put_along_axis_(axis=1, indices=group_idx, values=1, broadcast=False)
# todo
score_mask = (
group_mask.unsqueeze(axis=-1)
.expand(shape=[bsz * seq_len, self.n_group, self.n_routed_experts // self.n_group])
.reshape([bsz * seq_len, -1])
)
tmp_scores = scores_for_choice.masked_fill(mask=~score_mask.astype(dtype="bool"), value=0.0)
_, topk_idx = paddle.topk(k=self.top_k, sorted=False, x=tmp_scores, axis=-1)
topk_weight = scores.take_along_axis(axis=1, indices=topk_idx, broadcast=False)
if self.top_k > 1 and self.norm_topk_prob:
denominator = topk_weight.sum(axis=-1, keepdim=True) + 1e-20
topk_weight = topk_weight / denominator * self.routed_scaling_factor
else:
topk_weight = topk_weight * self.routed_scaling_factor
if self.training and self.alpha > 0.0:
scores_for_aux = scores
aux_topk = self.top_k
topk_idx_for_aux_loss = topk_idx.reshape([bsz, -1])
if self.seq_aux:
scores_for_seq_aux = scores_for_aux.reshape([bsz, seq_len, -1])
ce = paddle.zeros(shape=[bsz, self.n_routed_experts])
ce.put_along_axis_(
axis=1,
indices=topk_idx_for_aux_loss,
values=paddle.ones(shape=[bsz, seq_len * aux_topk]),
reduce="add",
).divide_(y=paddle.to_tensor(seq_len * aux_topk / self.n_routed_experts))
aux_loss = (ce * scores_for_seq_aux.mean(axis=1)).sum(axis=1).mean() * self.alpha
else:
mask_ce = paddle.nn.functional.one_hot(
num_classes=self.n_routed_experts, x=topk_idx_for_aux_loss.reshape([-1])
).astype("int64")
ce = mask_ce.astype(dtype="float32").mean(axis=0)
Pi = scores_for_aux.mean(axis=0)
fi = ce * self.n_routed_experts
aux_loss = (Pi * fi).sum() * self.alpha
else:
aux_loss = None
return topk_idx, topk_weight, aux_loss
上手教程
Part1
DeepSeek-VL2在PaddleMIX里快速体验
通过解析代码我们也更深入地理解模型的实现细节和技术创新,快跟着我们的aistudio教程一起来动手实践一下吧!
AI Studio教程链接:
https://aistudio.baidu.com/projectdetail/8889929
我们以DeepSeek-VL2-tiny为例,在单卡V100上需23G显存可推理完成图像理解。
首先下载 PaddleMIX代码库:
# clone PaddleMIX代码库
git clone https://github.com/PaddlePaddle/PaddleMIX.git
cd PaddleMIX
安装PaddlePaddle:
# 提供三种 PaddlePaddle 安装命令示例,也可参考PaddleMIX主页的安装教程进行安装
# 3.0.0b2版本安装示例 (CUDA 11.8)
python -m pip install paddlepaddle-gpu==3.0.0b2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# Develop 版本安装示例
python -m pip install paddlepaddle-gpu==0.0.0.post118 -f https://www.paddlepaddle.org.cn/whl/linux/gpu/develop.html
# sh 脚本快速安装
sh build_paddle_env.sh
安装PaddleMIX环境依赖包:
# 提供两种 PaddleMIX 依赖安装命令示例
# pip 安装示例,安装paddlemix、ppdiffusers、项目依赖、paddlenlp
python -m pip install -e . --user
python -m pip install -e ppdiffusers --user
python -m pip install -r requirements.txt --user
python -m pip install paddlenlp==3.0.0b3 --user
# sh 脚本快速安装
sh build_env.sh
图像理解
运行以下命令即可:
# Deepseek-vl2-tiny multi image understanding
python paddlemix/examples/deepseek_vl2/multi_image_infer.py \
--model_path="deepseek-ai/deepseek-vl2-tiny" \
--image_file_1="paddlemix/demo_images/examples_image1.jpg" \
--image_file_2="paddlemix/demo_images/examples_image2.jpg" \
--image_file_3="paddlemix/demo_images/twitter3.jpeg" \
--question="Can you tell me what are in the images?" \
--dtype="bfloat16"
输出结果:
<|User|>: This is image_1:
This is image_2:
This is image_3:
Can you tell me what are in the images?
<|Assistant|>: The first image shows a red panda resting on a wooden platform. The second image features a giant panda sitting among bamboo plants. The third image captures a rocket launch at night, with the bright trail of the rocket illuminating the sky.<|end▁of▁sentence|>
总结
DeepSeek-VL2是一个基于MoE架构的前沿多模态大模型。通过引入动态图像切片编码策略,高效处理不同长宽比的高分辨率图像,大幅提升了视觉理解、视觉问答等任务的表现;其语言模型部分DeepSeek-MoE也通过压缩键值缓存的方式优化了推理速度和吞吐量。
百度飞桨团队推出的PaddleMIX套件现已完整实现这个热门模型的推理训练全流程支持,通过深入解析其代码实现,研究人员和开发者能够更透彻地理解模型的核心技术细节与创新突破。我们诚挚推荐您访问AI Studio平台的专项教程(点击以下链接🔗),通过实践演练掌握前沿多模态模型的开发与应用技巧。
论文链接
DeepSeek-VL: Towards Real-World Vision-Language Understanding
https://arxiv.org/pdf/2403.05525
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
https://arxiv.org/pdf/2412.10302
项目地址
DeepSeek-VL2:
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/examples/deepseek_vl2
AI Studio教程链接:
https://aistudio.baidu.com/projectdetail/8889929
为了帮助您通过解析代码深入理解模型实现细节与技术创新,基于PaddleMIX框架实操多模态理解模型DeepSeek-VL2,我们将开展“多模态大模型PaddleMIX产业实战精品课”,带您实战操作多模态理解任务处理。3月24日正式开营,报名即可免费获得项目消耗算力(限时一周),名额有限,立即点击链接报名:https://www.wjx.top/vm/rX4VKX4.aspx?udsid=388305


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)