
DeepSeek在保险问答场景里如何秒杀一众AI的真实记录
本文使用真实大型企业 AI项目中的一个小小复杂场景PK DeepSeek和其它7个最著名的大模型的全过程记录,从此记录可以看到我们的DeepSeek有多强。

背景
DeepSeek可真不是吹出来的,而是真的有实力。
我们用一个正在实施中的大型保险公司(1,000万条语料),272个上百页书、条款的Word, Pdf灌入我们的Rag库里进行问答,并对其使用不同的LLM进行SOTA类测试,下面的结果相当惊人。先说结果:
我们还没用满血版DeepSeek,只是Ollama上布署的DeepSeek 14b,结果秒杀了几乎一切其它满血版或者是一些视频号喜欢吹的大模型。
下面就带大家来看过程。
真实保险案例场景
语料/自有知识库
- 领域:保险领域
- 近1,000万条数据(chunk);
- 272个每一个上百页的PDF;
RAG库架构
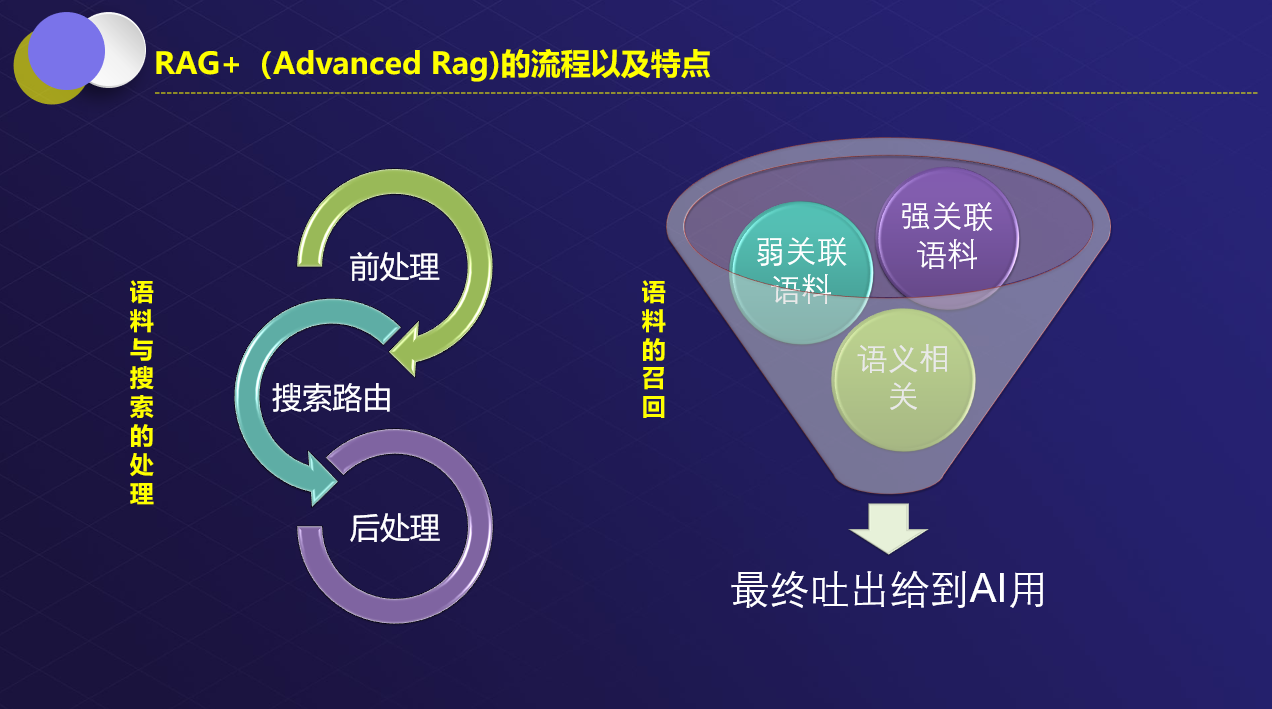
- ES、Mongo、mySQL、Oracle混合召回;
- LLM改写
- 折分时使用了:固定size+段落判断+语义折分+语义再组合以扩充和贯连上下文折;
- 重排序
- 最终送给LLM;
LLM改写猫娘核心部分
- 当前客户的提问为:$<prompt>。历史提问为$<historyPromptList>
- 关聊用户的历史提问上下文以及当前提问,判断客户的提问是否存在:过于宽范,过于简单,打招呼闲聊等问题导致搜索结果不准。
- 你首先把客户的提问中相关的敬语,打招呼等词汇去除掉。
- 如果用户在提问中使用的问法词法或者提问有逻辑不对的地方请你帮用户纠正一下。
- 在折分用户词语时要同时使用同义词、近义词、语义相近的词去扩充用户的提问。
# 打标签折关键字特别要求
- 请你以公司相关规章、制度、条款、操作手册、保险相关条条款的解读的专业背景知识想一下作为这样一个专业领域的在线客服在线搜索引擎会用到哪些关键字以便于用户在提出相应的诉求后快速可以检索到相关的知识库内的答案?请你把这些标签折成搜索引擎可以适合的关键字每个关键字。
- 按照一个搜索引擎可以搜索出的最大有效关键词重新折解客户的提问为带有英文数字逗号的关键词排列,关键字颗粒越细越好就和搜索引擎的分词那种效果一样。
- 折解时注意要把越能命中搜索结果的关键词越往前排,把称谓,动词放到整句提问的最后(即句子末尾)。
- 关键字折得越多越好,关键字一定是要可以覆盖用户的提问、包括用户提问中各个词语的同义词、近义词、不同叫法以及语义相近的词都需要列出。同时请记得把你自己如何回答这个问题的答案也折成关键字加入到改写的query里。此处,我们要求LLM在改写时不能仅仅针对用户当前的提问,而要联系上下文。
联系上下文改写的重要性
比如说,当前提问为:
请问我在吃牛排,有什么好的红酒可以配?于是AI哗哗哗输出了一堆内容
接着正常的人是怎么问的呢?
问法1:
还有没有更多?问法2:
继续此时如果换成是一个“肉人”,那么她/他会很好的连贯上下文知道:
哦。。。客户刚才问吃牛排要配什么红酒,我回答了几种。
那几种客户应该觉得还不满意或者想再看看有没有更多红酒推荐?
所以让我继续推荐更多红酒可以用来配吃牛排场景用的。所以评价一个好的AI的一个核心指标是:它可以连贯上下文,这就是推理能力。好的AI的COT如果输出其实就是上面“肉人”的思考方式,这就是思维链。
比如说GPT O1、O3都具备这个能力。
如果不能贯联上下文会导致整个RAG系统的回答不准
一个优秀的AI系统应该是AI原生的,而不是作为工具嵌入到企业系统中去,因此整个系统的任何一个部件包括规则引擎等都是AI构成的。
但是LLM在实际生产环境时会有一个特性即:逃逸。
所谓LLM的逃逸
一个固定的问答,每次答会和上一次有不一样的地方,这是多样性,这倒也没什么,但是这个逃逸最讨厌的地方在于:一些AI函数的回调会发生这样的情况。
第一次输出:
{"result": "关键字1,关键字2,关键字3"}第二次输出:
{"result": ["关键字1,关键字2,关键字3"]}过了几轮又输出
{"result": [{"关键字1},[{"关键字2"},{"关键字3"}]这时如果在AI原生应用里一旦失去“兜底”机制就会引起“级联雪崩”,这个雪崩不是微服务的雪崩而是一路影响到下游调用链中的结果。
所以一个优秀的LLM的逃逸应该是可控的。
这就是今天我们要PK的点。
在我们的系统内我们可以设置多路、1主1备、或者是集群AI线路。
因此我们的系统内可以动态配置任何LLM调用。不过如果只是格式问题的逃逸还好处理,但是实际在生产环境中我们碰到的推理上产生了语义的逃逸,此时这个偏之一毫差之万里的现象就很明显了。
因此我们拿这个LLM改写的真实场景来告诉大家各LLM在同等条件下PK到底表现如何。
PK用真实生产场景
先来看系统中存在的语料

语料解释
这个是语料,是一个PDF,我们不可能去改动PDF原文。
此处讲的是一个“员工忠诚险”。
而保险标的不是指:买这个保险要多少钱而是指“这个保险保的是什么东西以及发生了如何赔”。
所以在一般情况下,我们的用户不可能像这份文档里问问题时会把话术讲得这么文皱皱和官方话,最多这样问(雇员AI要理解成员工、标的要理解成保得什么?):
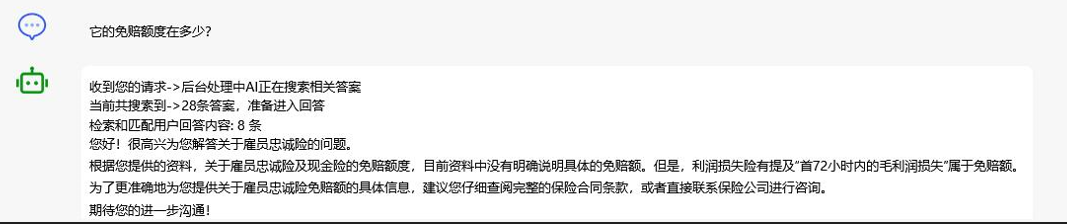
员工忠诚险,投保额是怎么样的?此时如果AI回答后一般人会接着这样再问一句:
它的免赔额度在多少?所以AI在第二次用户问到:它的免赔额度在多少?时,重写用户的提示词因该是写成:
员工忠诚险,免赔额度,多少,投保额,保障范围,保险条款,忠诚险保费此时针对用户的第二轮回答在搜出相应的语料以及回答时才会更精准。
因此我们开始使用以下AI对这个场景进行测试然后来看结果。
用GPT4O-MINI来测
上手现在登场的是GPT4O-MINI,它主打的一个就是“大并发,响应快”,一个回车敲下去0.1秒内保证返回结果。
第一轮回答。
问
员工忠诚险投保额是多少?LLM Rewrite后的提问
![]()
那么此时AI的回答一定是不会差的。
第二轮回答
问
免赔额在多少?LLM Rewrite后的提问
![]()
看到没,猫娘把提问和历史提问都发给AI了,并且要求AI根据上下文Rewrite,Gpt4o-mini还是在第二轮问答时这个Rewrite时没有把之前提问的上下文意思带到第二轮的Rewrite。
那么此时当这样的Rewrite结果带着多路召回的内容给到AI,AI的回答一定是混乱的。因此我们来看AI的回答:

用phi4来测
第一轮回答。
问
员工忠诚险投保额是多少?LLM Rewrite后的提问
![]()
第二轮回答
问
免赔额在多少?LLM Rewrite后的提问
![]()
看。。。把上文:员工忠诚险给疏忽了,那么AI的回答会是怎么样?可想而知。
我们还用了最新的Google Gemma3来测
第一轮回答。
问
员工忠诚险投保额是多少?LLM Rewrite后的提问
![]()
第二轮回答
问
免赔额在多少?LLM Rewrite后的提问
![]()
也Fail了。
最后我们用DeepSeek测试。
来看DeepSeek 14b在本机的的运行结果
第一轮回答。
问
员工忠诚险投保额是多少?LLM Rewrite后的提问
![]()
第二轮回答
问
免赔额在多少?LLM Rewrite后的提问
![]()
看到没?
我们反反复复测了1千轮。DeepSeek都很稳定。
那么当然,这样的Rewrite得结果得到的AI最终的回答也是令人很满意的,以下是DeepSeek全过程的问答截图:
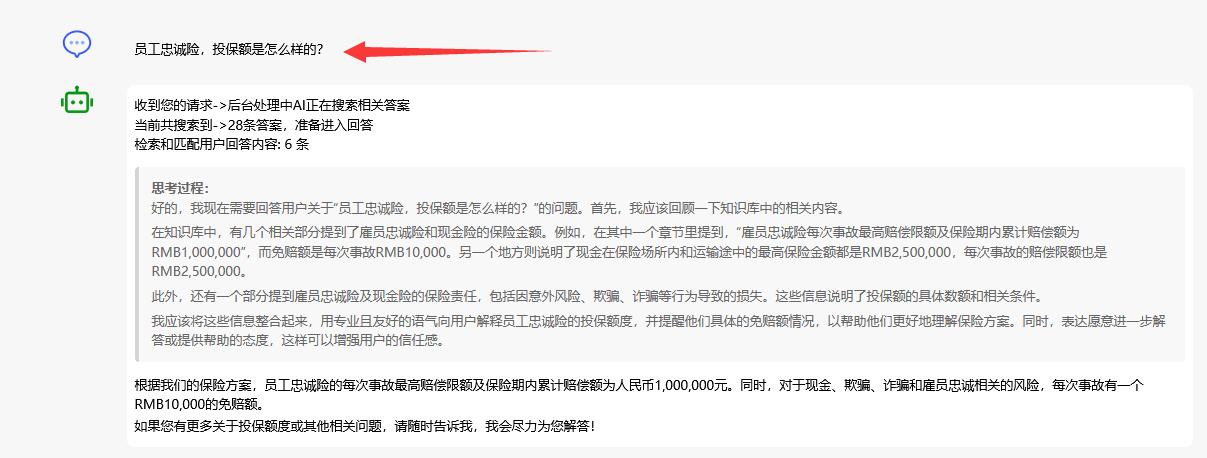

回答可以说是Perfect!
最终我们得到了以下模型在这个场景下的测试效果(还有更复杂的就不用说了,我们PK的这个只能算小小复杂案例,中等和更复杂,不少吹得很神的模型几乎处于企业场景不可用状态)。
各模型测试效果一览
| 模型 | 第一轮ReWrite | 第二轮ReWrite | 测试结果 |
| DeepSeek 14b | 完全符合要求 | 完全符合要求 | 通过 |
| Gpt4o(满血) | 完全符合要求 | 偶尔符合要求 | 失败 |
| Claude 3.7(满血) | 完全符合要求 | 完全符合要求 | 通过 |
| Google Gemma3(满血) | 完全符合要求 | 偶尔符合要求 | 失败 |
| Phi4 | 完全符合要求 | 不符合要求 | 失败 |
| Qwen Max(满血) | 完全符合要求 | 完全符合要求 | 通过 |
| QwenVL(满血) | 完全符合要求 | 偶尔符合要求 | 失败 |
| Gpt4o-mini(满血) | 完全符合要求 | 不符合要求 | 失败 |
总结
大模型真的很重要,特别是具备强大推理能力的LLM,在AI原生应用中以上案例只是上百个AI流程、结点的一个环节,如果LLM不可靠那么它引起的级联式的“雪崩”是远比微服务里的“雪崩”更可怕。因为它不出错而是一本正经的“胡说”。这才是最可怕的!
从这点来看,仅仅是ollama布署的deepseek14b都已经强成这样,可想而知deepseek有多利害,真不愧为我们的国货之光啊!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 34
34 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)