DeepSeek的MLA架构如何用1/10成本实现GPT-4级别表现?
技术路径的差异化竞争DeepSeek通过**稀疏激活架构+数据工程优化+开源生态**的组合拳,在保证性能的同时实现成本数量级降低。其核心逻辑是**“硬件效率优先于参数规模”**,例如用动态路由替代全参数激活、用低秩压缩突破显存瓶颈,而非依赖堆砌算力。这种技术路径不仅适用于通用模型,更在垂直领域(如金融、医疗)通过微调实现“降维打击”。
DeepSeek的MLA(多头潜在注意力)架构能够以1/10的成本实现GPT-4级别的表现,主要依赖于**架构创新、训练优化和高效推理机制**三方面的技术突破,具体实现路径如下:
一、架构设计:稀疏激活与显存优化
1. **混合专家(MoE)架构的动态调度**
DeepSeek总参数量达6710亿,但通过MoE架构的**动态路由机制**,每次推理仅激活约5.5%的参数(约37B)。例如,处理数学问题时调用符号推理专家模块,处理中文生成时激活韵律控制模块,这种“按需调用”模式降低70%计算能耗。
2. **多头潜在注意力(MLA)的显存压缩**
通过低秩联合压缩技术,将键(Key)和值(Value)矩阵投影到低维潜在空间,减少KV缓存的显存占用。例如,处理128K长文本时,传统架构需320GB显存,而MLA仅需64GB,效率提升5倍。
3. **滑动窗口与全局信息传递**
引入滑动窗口多头潜在注意力(SW-MLA),将长序列切分为4K Token的局部窗口,并通过潜在变量在窗口间传递全局信息,避免传统自注意力机制的平方级显存增长问题。
二、训练策略:数据与计算优化
1. **精细化数据工程**
采用“三阶段过滤法”清洗训练语料:正则表达式去噪、BERT连贯性评分(保留前30%高质量内容)、垂直领域过采样(专业数据占比15%),提升数据利用率。
2. **FP8混合精度与DualPipe并行**
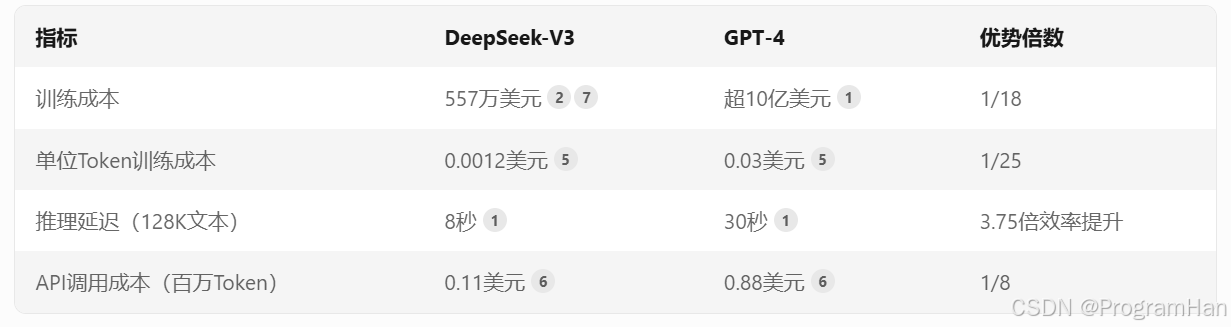
在非敏感层使用8位浮点数(FP8),结合DualPipe算法解耦计算与通信流水线,使训练总成本降至557万美元,仅为GPT-4的1/18。例如,278.8万H800 GPU小时完成训练,单位Token成本为GPT-4的1/50。
3. **动态负载均衡与梯度补偿**
监控专家激活频率,对低利用率专家实施权重衰减,高负载专家梯度补偿,将专家利用率标准差从35%降至12%,提升训练稳定性。
三、推理效率:速度与成本颠覆
1. **多令牌预测(MTP)加速生成**
支持同时预测多个未来Token,推理速度从20 Token/秒提升至60 Token/秒(A100显卡),响应延迟缩短至8秒内(GPT-4需30秒)。
2. **INT4量化与动态批处理**
通过4bit量化技术压缩模型体积,保持95%原始性能,结合动态批处理优化显存分配,使单张A100的吞吐量达1200 Token/秒,是GPT-4的3倍。
3. **开源生态降低部署成本**
开源模型权重(MIT协议)允许开发者免费微调,例如某法律公司用单张RTX 4090微调后,条款引用准确率从78%提升至93%。工具链(如DeepSpeed-Inference)进一步压缩部署成本至百万级,而GPT-4需依赖高价API服务。
四、成本对比:架构优势的量化体现
总结:技术路径的差异化竞争
DeepSeek通过**稀疏激活架构+数据工程优化+开源生态**的组合拳,在保证性能的同时实现成本数量级降低。其核心逻辑是**“硬件效率优先于参数规模”**,例如用动态路由替代全参数激活、用低秩压缩突破显存瓶颈,而非依赖堆砌算力。这种技术路径不仅适用于通用模型,更在垂直领域(如金融、医疗)通过微调实现“降维打击”。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)