使用 llama.cpp 在 Windows 11 上运行 Qwen2.5 和 DeepSeek 模型:从环境搭建到 GPU 加速的完整指南
你是否想在本地机器上运行强大的语言模型,却苦于复杂的配置和性能问题?本文将带你一步步在 Windows 11 上使用 llama.cpp 运行 Qwen2.5 和 DeepSeek 模型,从环境搭建到 GPU 加速,全面覆盖!我们将解决 CMake 配置冲突、CUDA 支持问题、模型分片合并等常见坑点,并分享性能优化技巧。无论你是 AI 爱好者还是开发者,这篇指南都能帮助你快速上手,轻松玩转本地大
·
引言
llama.cpp vs Ollama:为什么选择 llama.cpp?
1. 灵活性与控制力
-
llama.cpp:
- 完全开源,你可以根据自己的需求修改代码,甚至优化性能。
- 支持多种硬件后端(CPU、CUDA、Metal、Vulkan 等),适合需要深度定制的场景。
- 可以自由选择模型、量化方案和运行参数,灵活性极高。
-
Ollama:
- 更偏向于开箱即用,适合不想折腾的用户。
- 灵活性较低,无法深度定制模型或优化性能。
2. 性能优化
- llama.cpp:
- 支持多种量化方案(如 Q4_K_M、Q5_K_M),显著减少显存占用并提升运行速度。
- 支持 CPU+GPU 混合推理,即使显存不足也能运行大模型。
- 通过 SIMD 指令集(如 AVX2、AVX512)和 GPU 加速,性能极致优化。
- Ollama:
- 性能优化较为保守,主要依赖 CPU 运行,GPU 支持有限。
- 量化选项较少,无法针对特定硬件进行深度优化。
3. 多平台支持
- llama.cpp:
- 支持 Windows、Linux、macOS 等多种操作系统。
- 支持多种硬件架构(x86、ARM、Apple Silicon 等)。
- Ollama:
- 主要面向 macOS 和 Linux,Windows 支持较弱。
- 硬件兼容性较低,尤其是对 GPU 的支持。
4. 适用场景
- llama.cpp:
- 适合开发者、研究人员和技术爱好者,需要深度定制和优化性能的场景。
- 适合需要运行特定模型(如 Qwen2.5、DeepSeek)或进行模型实验的用户。
- Ollama:
- 适合普通用户,希望快速上手并使用预置模型。
- 适合不需要深度定制或性能优化的场景。
5. 学习与探索
- llama.cpp:
- 通过手动配置和调试,你可以深入了解大模型的运行机制和优化方法。
- 适合想要学习底层技术或进行二次开发的用户。
- Ollama:
- 更注重用户体验,适合不想深入技术细节的用户。
1. 环境准备
- 1.1 系统要求:
- Windows 11、Visual Studio 2022、CMake、CUDA(可选)。
- 1.2 安装依赖:
- 安装 Git、CMake、Visual Studio 2022(确保勾选 C++ 开发工具)。
- 安装 CUDA(如果需要 GPU 加速)。
2. 编译 llama.cpp
- 2.1 克隆仓库:
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp - 2.2 使用 CMake 生成项目:
- CPU 版本:
cmake .. -G "Visual Studio 17 2022" -A x64- GPU 版本(CUDA):
cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON - 2.3 编译项目:
cmake --build . --config Release
3. 获取和转换模型
- 3.1 下载 Qwen2.5 和 DeepSeek 模型:
- 从 Hugging Face 下载模型权重。
- 3.2 转换模型为 GGUF 格式:
- 使用 convert-hf-to-gguf.py 脚本:
python convert-hf-to-gguf.py Qwen/Qwen2.5-7B-Instruct --outfile qwen2.5-7b-instruct-f16.gguf- 量化模型(可选):
./llama-quantize qwen2.5-7b-instruct-f16.gguf qwen2.5-7b-instruct-q5_k_m.gguf q5_k_m
4. 运行模型
- 4.1 运行 Qwen2.5 模型:
./llama-cli -m qwen2.5-7b-instruct-q5_k_m.gguf -ngl 80 -n 512 - 4.2 运行 DeepSeek 模型:
./llama-cli -m deepseek-7b-q5_k_m.gguf -ngl 80 -n 512 - 4.3 调整参数:
- –temp:控制生成内容的随机性(默认 0.8)。
- -top_k 和 -top_p:控制生成内容的多样性。
- -ngl:调整分配到 GPU 的层数(根据显存大小调整)。
5. 踩坑与解决方案
- 5.1 CMake 缓存冲突:
- 解决方法:删除 CMakeCache.txt 和 CMakeFiles 目录,或创建新的构建目录。
- 5.2 CUDA 支持问题:
- 解决方法:确保 CUDA 已安装,并设置正确的环境变量。
- 5.3 模型分片文件合并:
- 解决方法:使用 copy 或 cat 命令合并分片文件。
6. 性能优化
- 6.1 GPU 加速:
- 使用 -ngl 参数将模型层分配到 GPU。
- 6.2 量化模型:
- 使用 llama-quantize 工具减少显存占用。
- 6.3 多线程优化:
- 调整 -t 参数,充分利用 CPU 多线程。
7. 成果展示
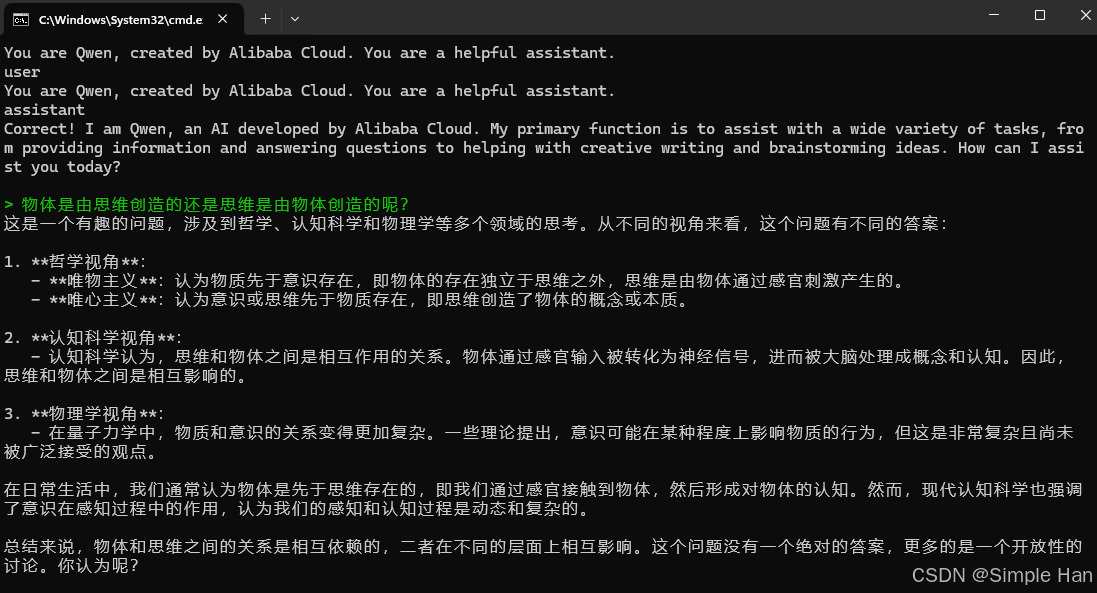
- 7.1 Qwen2.5 对话示例:
8. 总结
llama.cpp 是一个强大而灵活的工具,专为对性能和控制力有极高要求的用户设计。尽管初次使用时可能会遇到一些挑战,但通过不断探索和解决问题,你将能够充分释放它的潜力,体验到在本地运行大模型的无限乐趣!🚀
当然,本文仅为抛砖引玉。如果你有更好的见解或独特的使用技巧,欢迎在评论区留言分享!同时,也鼓励大家尝试不同的模型,看看能否碰撞出更多精彩的火花!🌟
附录
参考链接:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)