DeepSeek-R1解读
和DeepSeek-R1是在模型基础上微调来的,模型参数是671B,每个token激活参数37B,支持的上下文长度是128K。是一种通过大规模强化学习(RL)训练的模型,无需监督微调 (SFT) 作为初步步骤,在推理方面表现出色。借助 RL,DeepSeek-R1-Zero 自然而然地出现了许多强大而有趣的推理行为。然而,DeepSeek-R1-Zero 遇到了诸如无休止重复、可读性差和语言混合等
1. 摘要
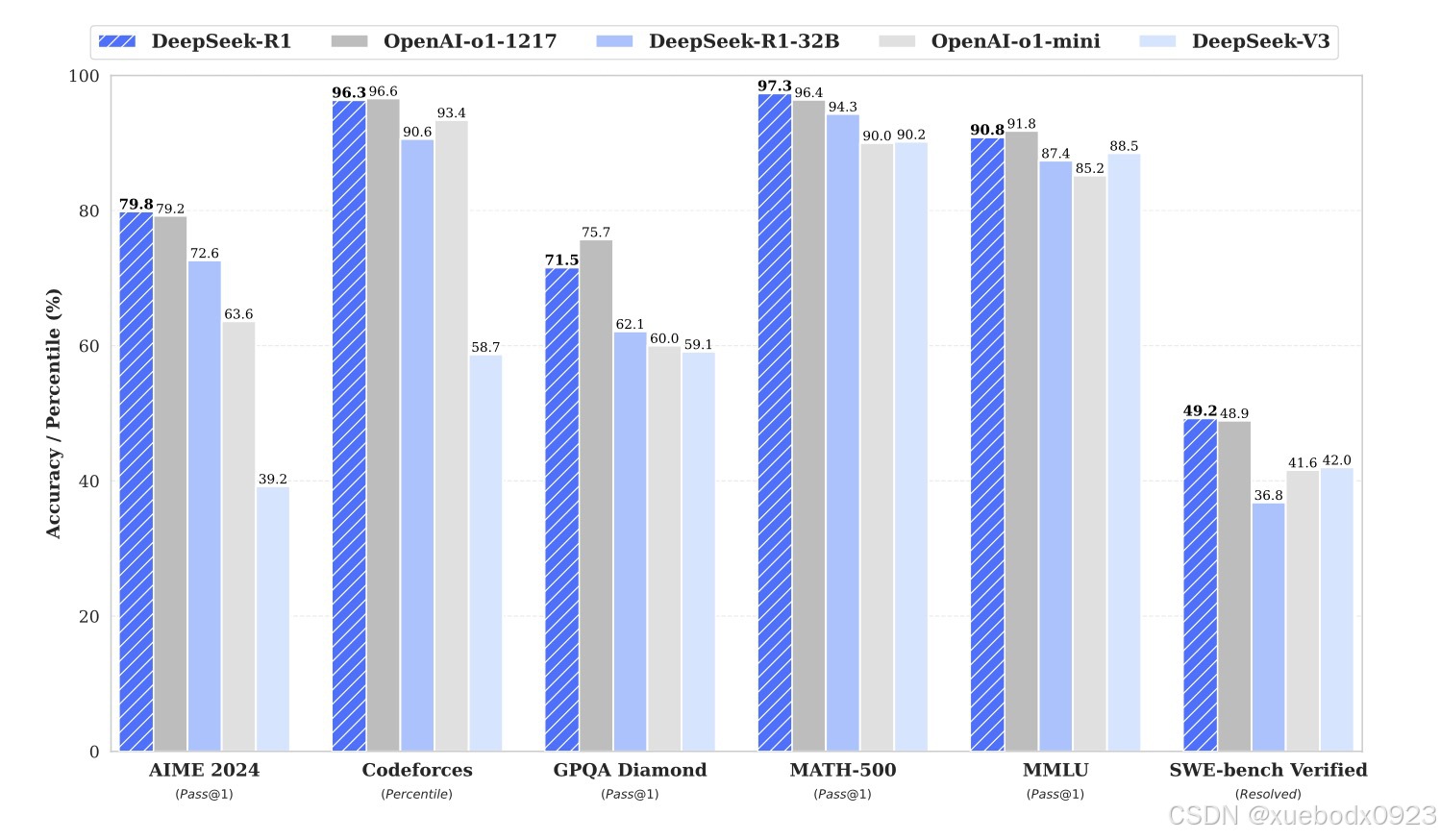
DeepSeek-R1-Zero和DeepSeek-R1是在DeepSeek-V3-Base模型基础上微调来的,模型参数是671B,每个token激活参数37B,支持的上下文长度是128K。DeepSeek-R1-Zero是一种通过大规模强化学习(RL)训练的模型,无需监督微调 (SFT) 作为初步步骤,在推理方面表现出色。借助 RL,DeepSeek-R1-Zero 自然而然地出现了许多强大而有趣的推理行为。然而,DeepSeek-R1-Zero 遇到了诸如无休止重复、可读性差和语言混合等挑战。为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它在RL之前整合了冷启动数据。DeepSeek-R1在数学、代码和推理任务中实现了与OpenAI-o1相当的性能。DeepSeek-R1-Distill-Qwen-32B在各种基准测试中均优于OpenAI-o1-mini。
2. 算法改进
和传统的RLHF相比DeepSeek-R1-Zero纯RL训练,无冷启动、无SFT。为了节约强化学习的训练成本,把PPO算法(近端策略优化)改成GRPO算法。GRPO算法直接去掉了PPO算法中的critic模型(PPO算法是Actor-Critic算法的一种)。
对于每个问题q,GRPO从旧策略![]() 中抽取一组输出
中抽取一组输出![]()
然后通过最大化以下目标来优化策略模型πθ
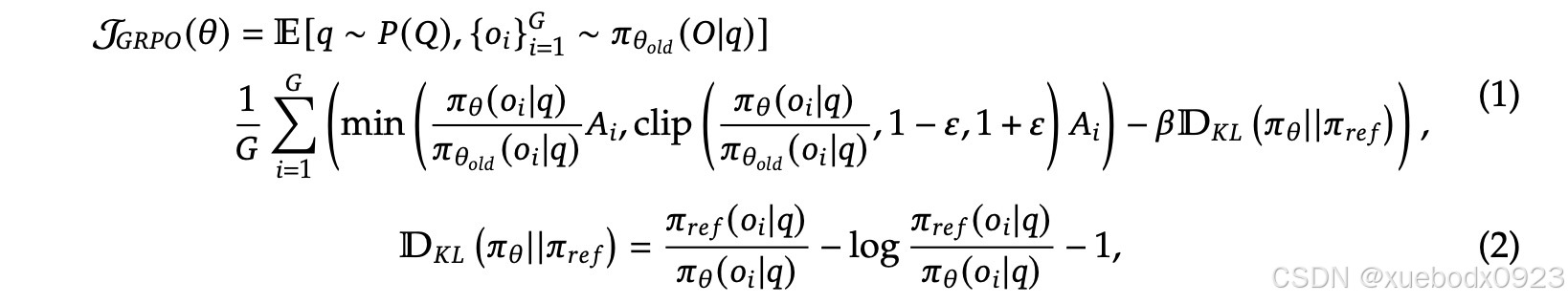
其中,![]() 和
和![]() 是超参数,而
是超参数,而![]() 是优势,使用一组奖励
是优势,使用一组奖励![]() 计算,该奖励对应于每个组内的输出。
计算,该奖励对应于每个组内的输出。
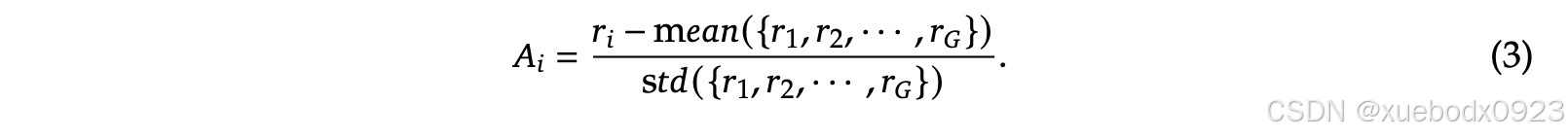
3. 模型蒸馏
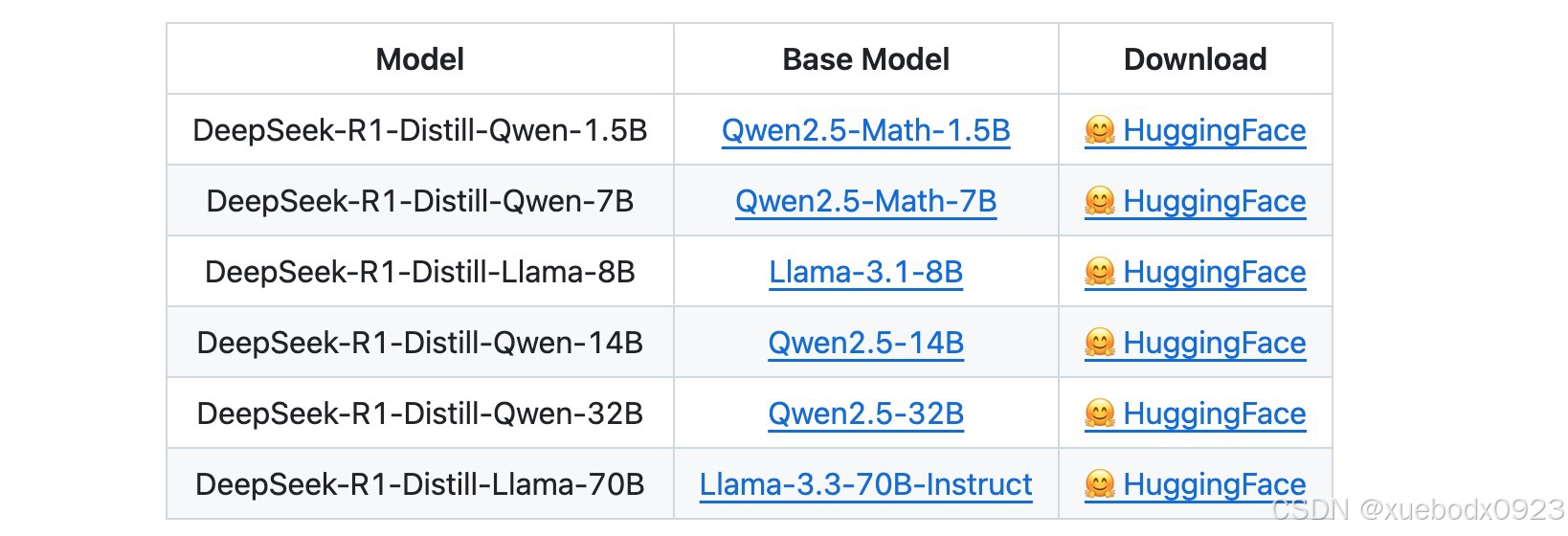
使用DeepSeek-R1生成的样本,对Llama和Qwen开源模型进行微调,蒸馏出六个模型。
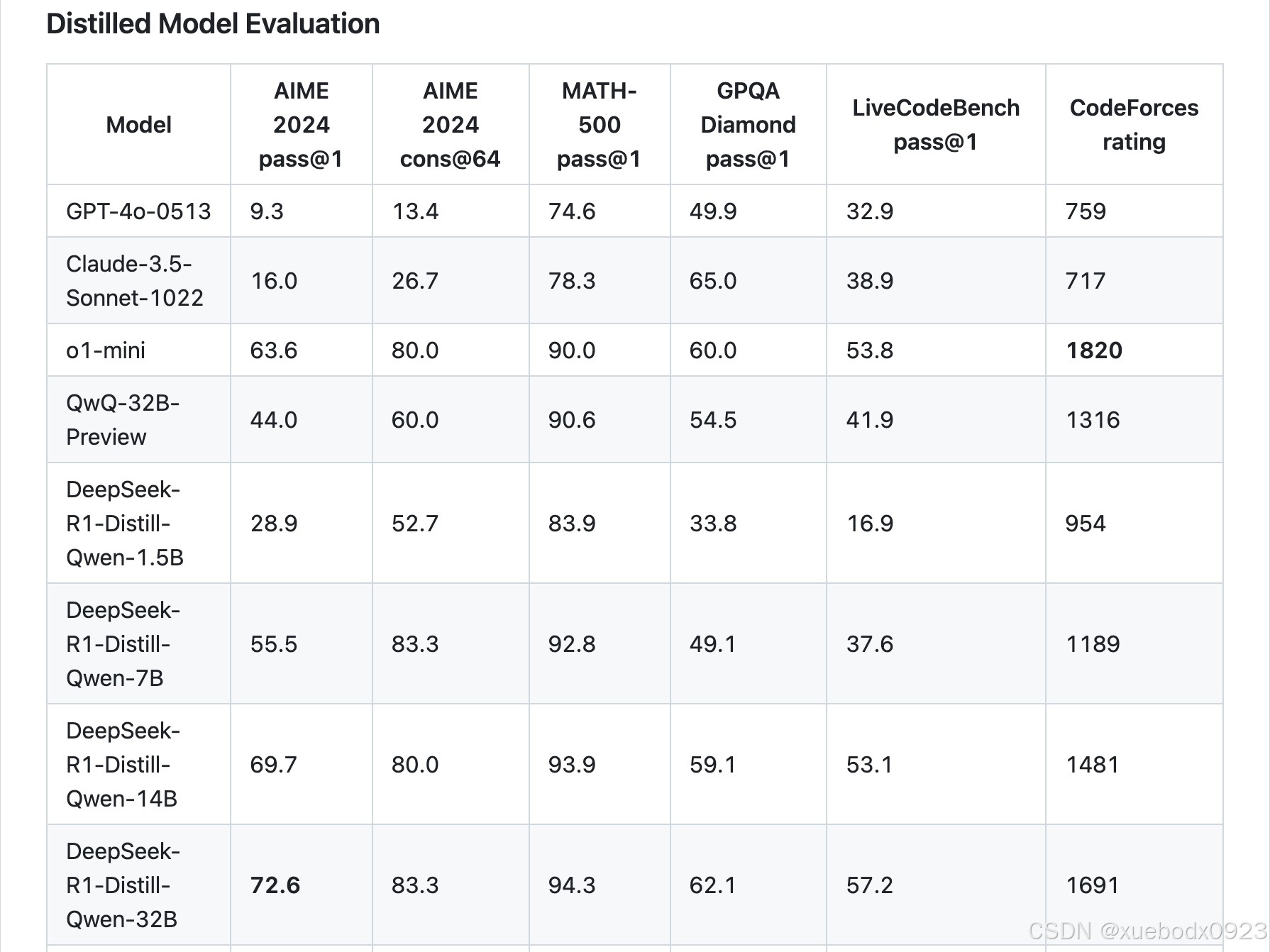
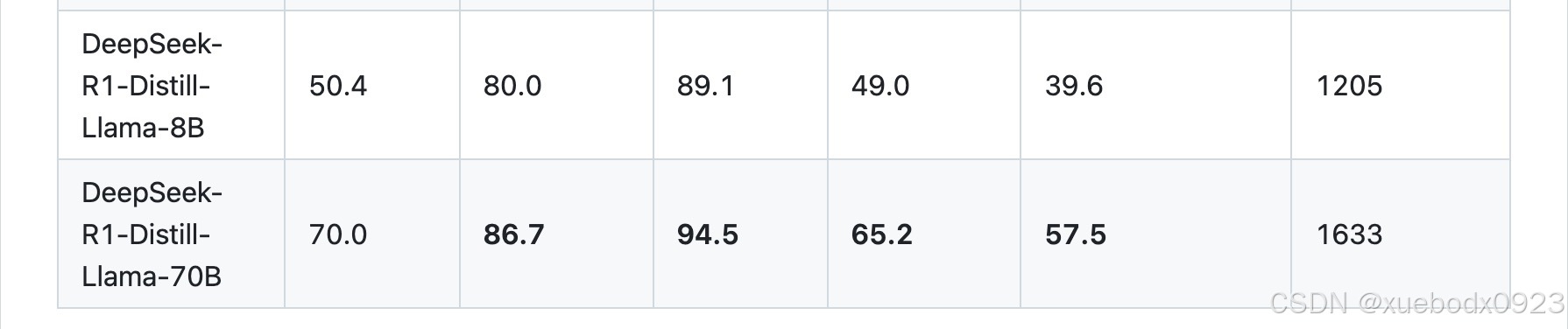
3. 本地部署模型
3.1 模型下载
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/tree/main
3.2 模型启动
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)