DeepSeek 3FS解读与源码分析(3):Storage模块解读
2025年2月28日,DeepSeek 正式开源其颠覆性文件系统Fire-Flyer 3FS(以下简称3FS),重新定义了分布式存储的性能边界。本文将结合代码和design_notes 对storage部分进行分析和探讨。
2025年2月28日,DeepSeek 正式开源其颠覆性文件系统Fire-Flyer 3FS(以下简称3FS),重新定义了分布式存储的性能边界。本文将结合代码和design_notes 对storage部分进行分析和探讨。
架构和整体位置
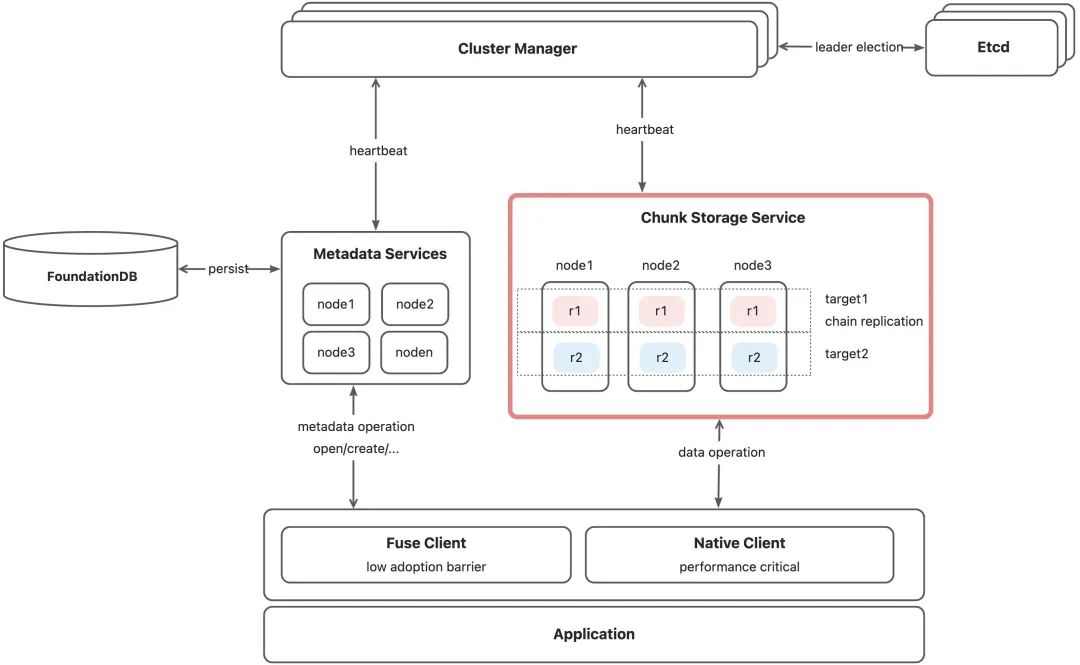
画板
上图中 StorageService 即为本次分析的重点。ChunkStorage 本身提供了三个基础的功能如下:
1. 单机空间池化,空间纳管。
2. 基于 RDMA 的通信链路,数据面 I/O 处理。
3. 提供支撑链式复制(Chained-Replication)在容错、数据一致性方面方面的支持。
其中前两条更偏向单机引擎探讨,第三条侧重 StorageService 对于分布式层面的支持。本文主要从前两个部分做一些分析,分布式部分涉及到容灾以及和 Client/Meta 的联动处理,不在本次讨论范围。
空间纳管
一句话总结: 负责空间池化,以参数可调的方式实现利用率和性能的可调性。
池化概念
chunk 是 3FS 中的重要概念,是文件逻辑 LBA 到池化存储 mapping 的一个"连接"。一个上层文件的LBA会映射成一组 chunks,按 inode_编号确定唯一性{seq} 单调递增。3FS 做的存储池化就是把底层的存储空间打平来承载上层的产生的 chunks。client 按固定大小进行切分 chunk(大小做到可调), 则 StorageService 的工作是尽可能减少空间碎片的目标下提升性能,做好 trade-off。
空间管理
如下图所示一个物理磁盘和逻辑 StorageTarget 是 1 对多的关系,每个 Target 有一个专属的 ChunkEngine 具体负责 Target 内的空间和 I/O 管理。假设把 disk 以及其关联所有 Target 路径关联作为一个抽象的 DiskUnit 来看待,则整体 high-level 关系如下图:
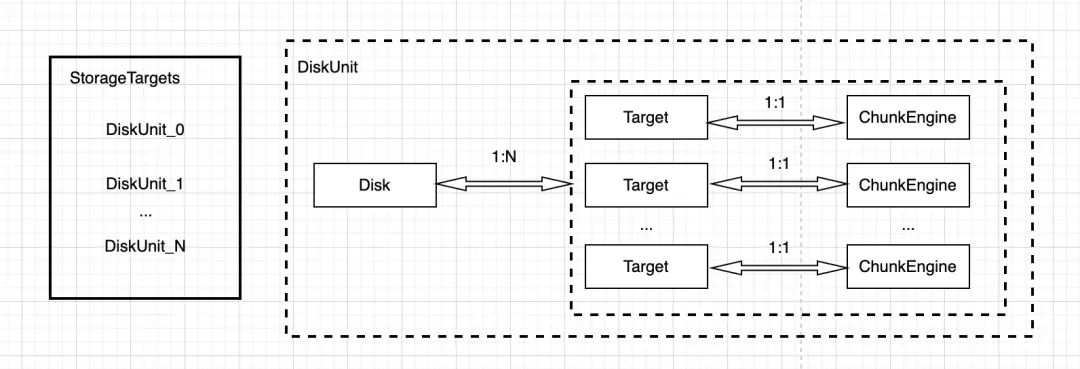
下钻到 ChunkEngine, 主体上包含处理 chunk 空间相关的 Allocator 模块,以及数据面接口。这里只关注空间管理相关的 Allocator 部分逻辑。
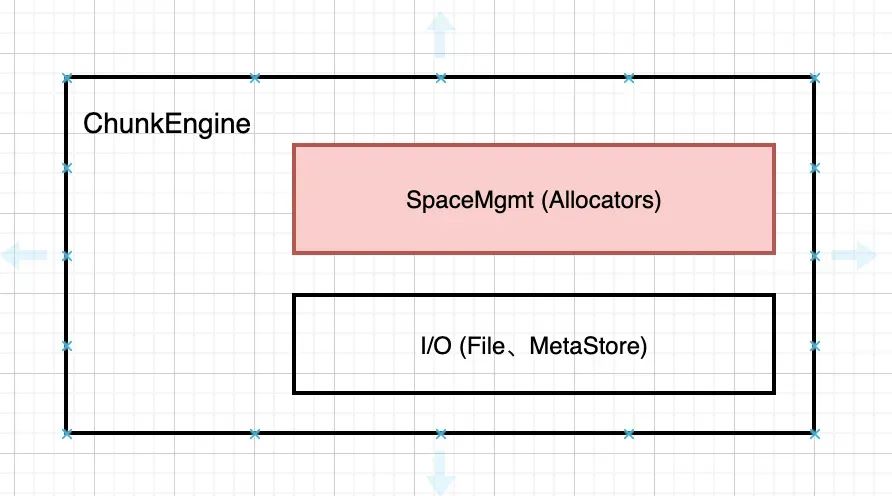
Allocator 和两部分数据打交道,用户 Data 和 元数据 Meta Data。数据 Data 保存在文件系统中。元数据保存在 RocksDB中。
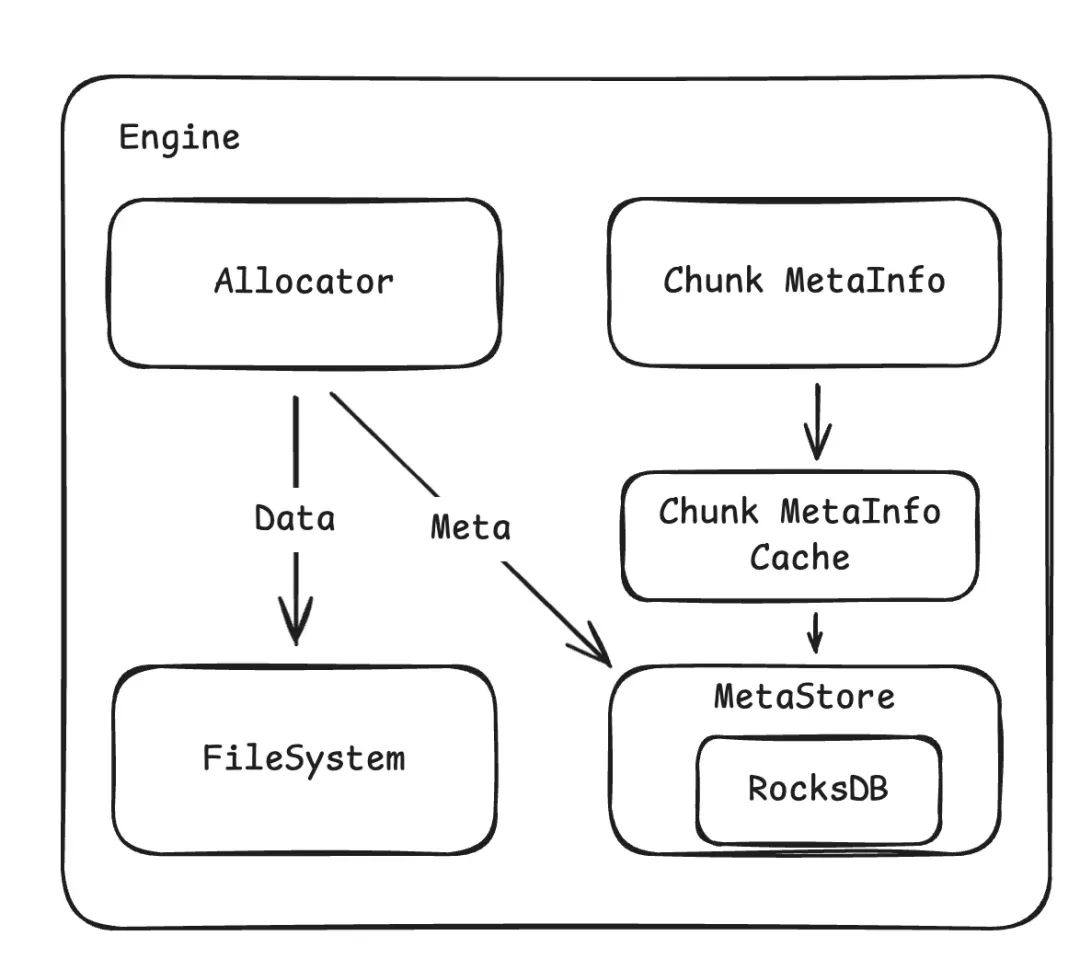
空间分配
下图是 ChunkEngine 中 分配 chunk 的整体流程:
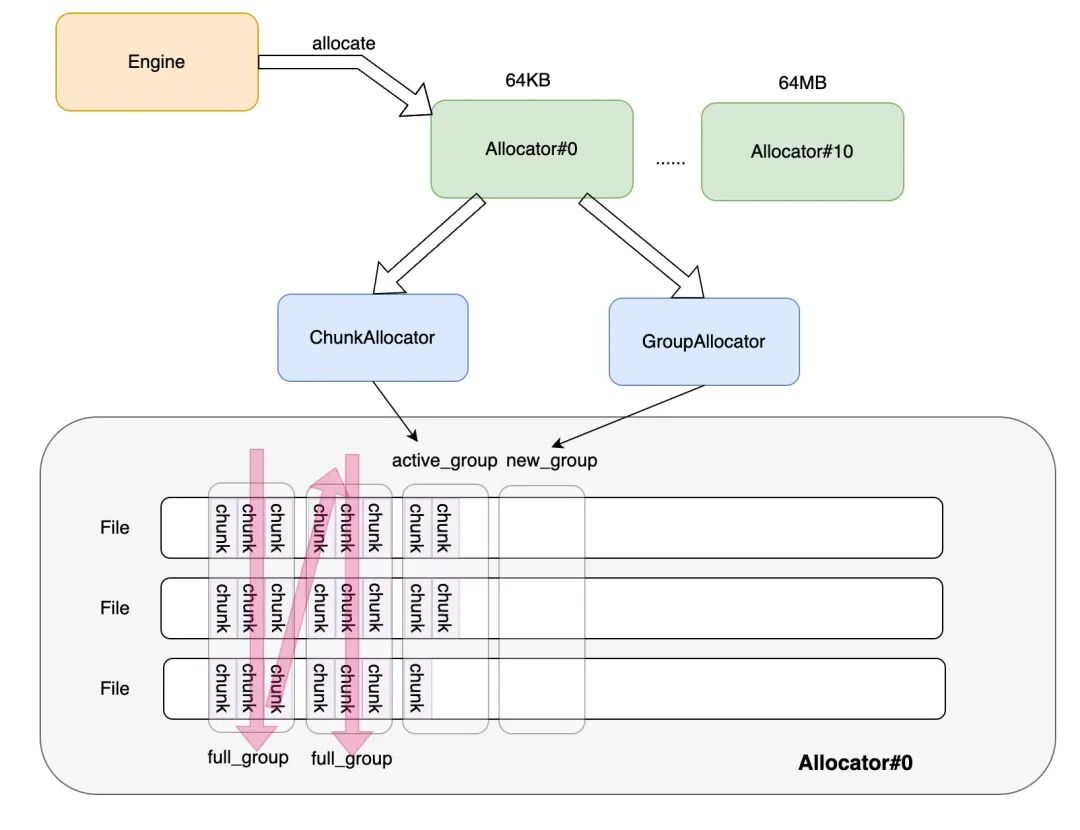
• Allocator 由 11 个实例组成,负责从最小的 64KB 到最大的 64MB 的 chunk 分配。
• 每个 Allocator 会分配 256 个 File,用作真正的数据进行存储,在逻辑上每个 File 按照 Group 组织,一个 Group 包含 256 Chunk(使用 bitmap 索引)
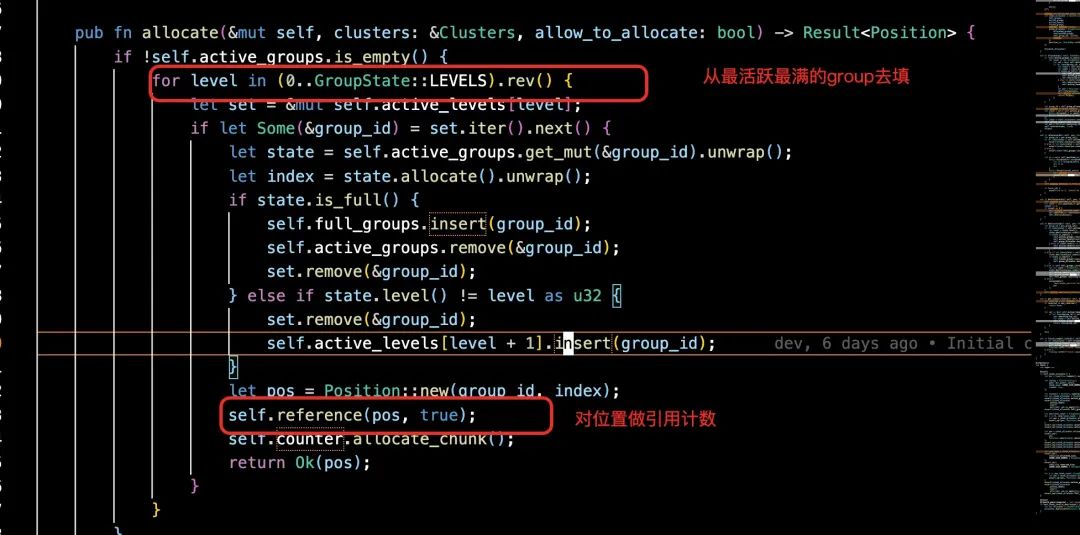
• 分配 Group 的顺序如上图所示,可以保证文件的大小均衡。整体上看,Engine 通过调用 Allocator::allocate 请求分配一个新存储块。Allocator 会检查现有的存储块是否可用,如果没有会通过 ChunkAllocator 和 GroupAllocator 来分配新的块和Group。在 ChunkAllocator 不能满足需求时,例如没有 active_group,全部都是 full_group 时,会请求 GroupAllocator 分配一个新的 Group。
• 此外分配 chunk 的过程如下:
1. 根据调用者提供的 size,选择相应的 allocator。
2. 按照内存状态挑选最不空闲的已分配的 group(如果没有,则分配 group),从 group 中挑选 chunk 进行分配。
3. 在 Engine 中更新 chunk_id 到 chunk 的映射,并且持久化映射关系和 allocator 的分配信息。
理解
1. 上述 a, b 步骤主要是让 Group 的内部碎片收敛进而提升利用率,a 类似操作系统中 slab 的概念;b 采用贪心的方式去尽可能填满 group 内的洞。
1.这种方式非常依赖上层 chunk 切片的固化 pattern,只有相互配合才能 match;一种更灵活的方式是 allocator 按需分配,即收到 chunk 分配请求首次按需分配,灵活但可能存在一些毛刺。
2.在删除或者反复擦写不多的场景下,一般都按照上图的 group 分配走向顺序向后;否则存在空洞的 group 比较分散的时候,按上述策略分配顺序会比较散,从写入的 locality 角度来说不太友好,不过 NVME SSD 的情况下,这个性能问题应该不会太突出。
2. c 是保证上层业务索引(meta service 中索引存储)在底层 chunk 发生位置变更下而不用变化的前提,因为 chunk_id -> chunk location 的映射是底层自治的(存储在本地 rocksdb 中),而上层只按照 chunk id 寻址。
3. 自治性: 每个 Target 都是一个资源自闭包的抽象,拥有自身独立的 MetaDB (rocksdb实例)。
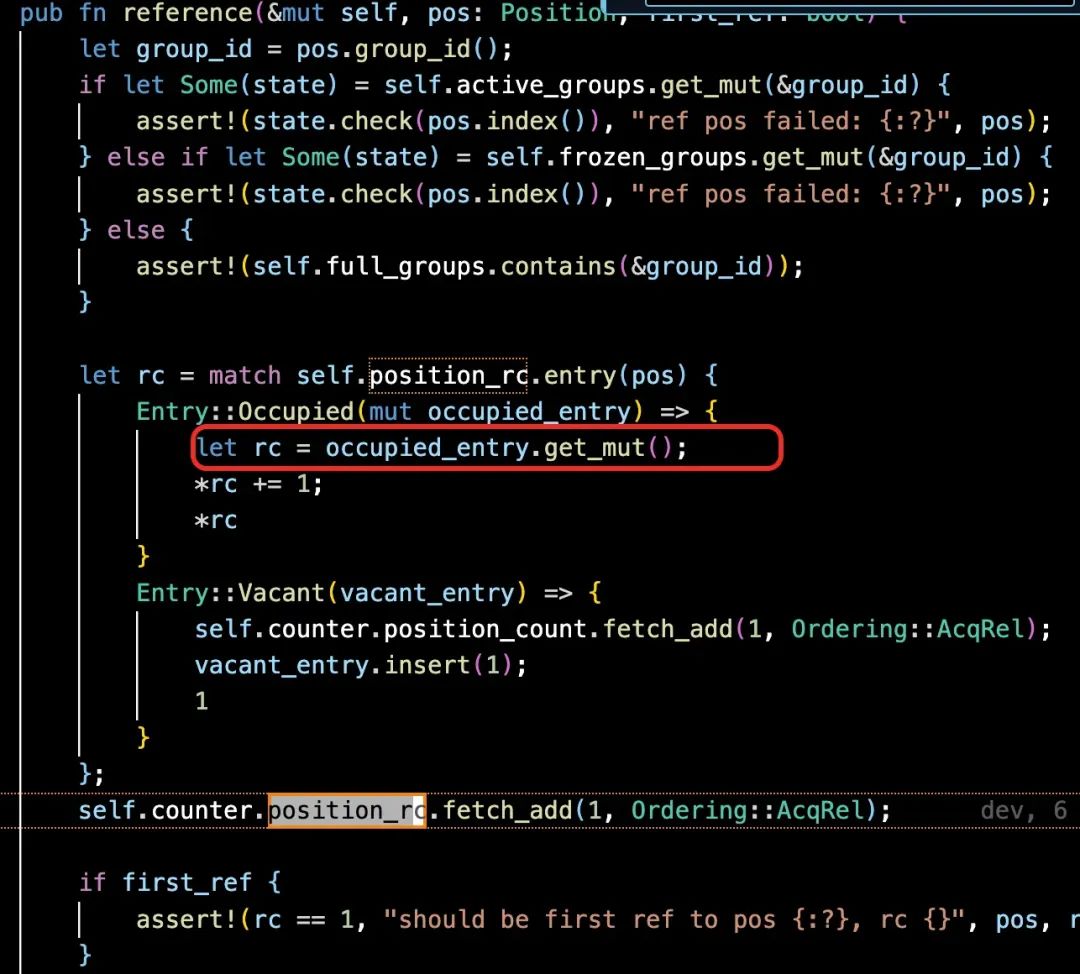
引用计数
当块分配成功,存储块被读写的时候,Engine 会通过 Allocator::reference 引用这个存储块。ChunkAllocator 会增加这个块的 Position reference count。
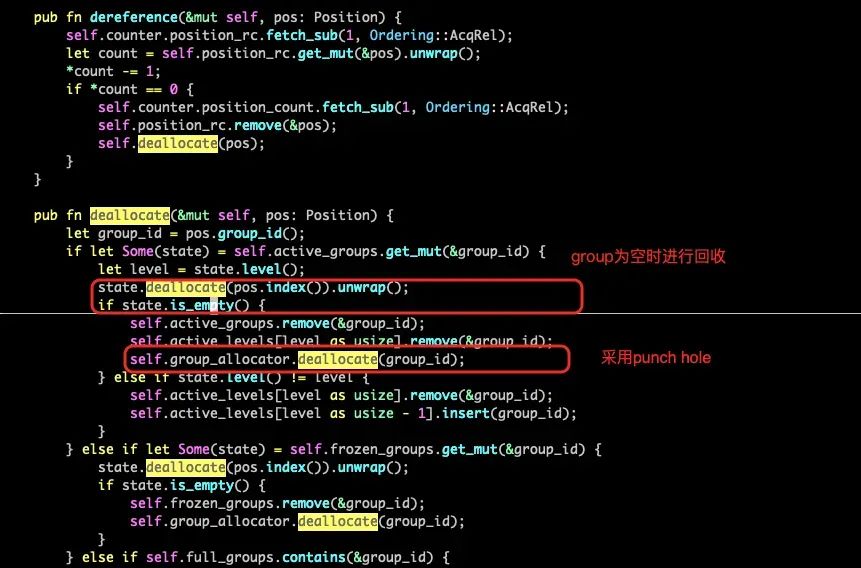
当存储块不再需要的时候, Engine 通过 Allocator::dereference 释放存储块。ChunkAllocator 会减少这个块的 Position reference count。当 reference count 为 0 的时候释放。
当一个 Group 为空时,GroupAllocator 会回收这个组。
碎片整理
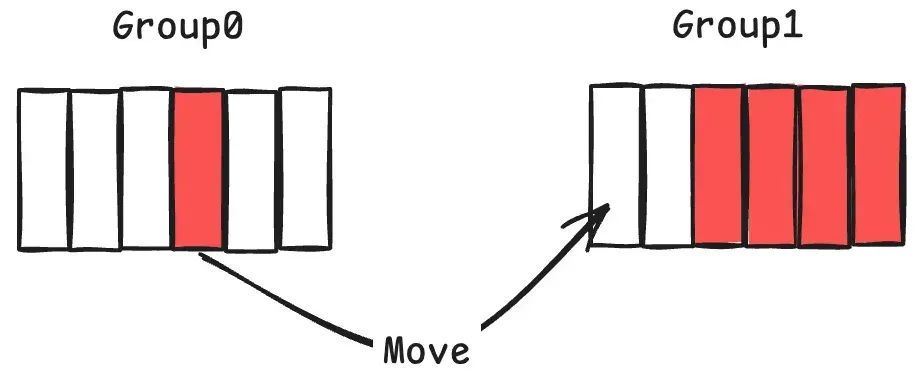
• 当发现申请了过多 chunk 但是已经废弃的情况(可能是删除或者是上层文件层的覆盖),则会针对相应的一些 group 进行碎片整理,整理之前 group 需要进入到 Frozen 态。
• 找到使用但是空闲程度较高的 group(如上图中的group),将其使用到的 chunk move 到另外的 group,并将整理好的 group 从 Frozen 放到 Active 态以供重复。上图中的搬运(Move)本质上是针对文件删除或者随机覆盖写之后所产生的空洞进行回收,让碎片率高的 group 通过整理之后变得连续,但是搬运会产生背景流量,在 Allocator 的空间不能做弹性伸缩的情况下,这样做的意义还不是特别明白。需要说明的是碎片整理是周期性的后台任务,因此在存在较多删除的情况下后台整理的流量应该是需要被考虑 (调整碎片 ratio)。此外考虑到数据搬运的过程中,作为 src 的 Group0 可能还存在读请求,因此基于引用计数的方式是一种常规的做法,即确保在一个 group 被整理完成重新变成 active。在被重复利用之前,其中每个 chunk pos 的 ref count 都为 0。分配逻辑中 ref/unref 的粒度是 group 中的具体一个 chunk pos[group_id, index], 以上图为例,左侧 move 的 src pos 对应 [group_0, 3]。
空间回收上, chunk 对应的 pos 被 unref 之后开始,如果 refcount 降为 0 会进行 deallocate 空间回收,3FS 因为使用了文件系统,在空间回收上可以做一些简化处理,当 group 空间全部回收后,采用的是对 group 进行整体回收空间(punch hole)。

数据面
接口
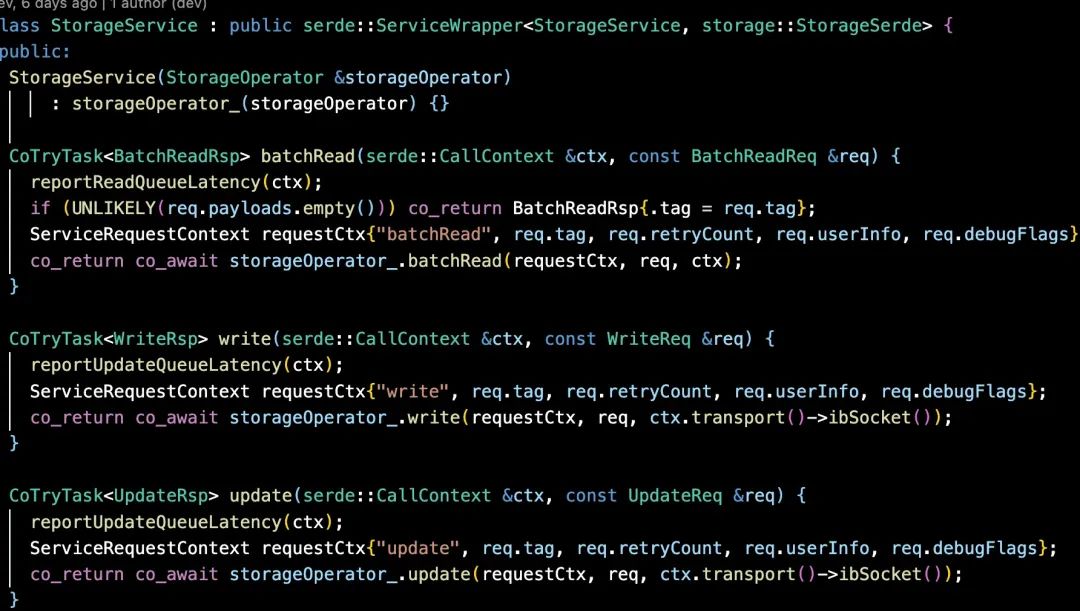
如设计文档中描述,3FS 整体上是一个面向读优化的设计。本次分析主要针对数据面的读写(暂时不涉及控制面),其入口主要是下面三个:
所有的 I/O 请求最终都需要落到 chunk 上,而 chunk 的访问在 ChunkEngine 内部,ChunkEngine 和 Target 1 v 1 绑定,因此所有的请求都涉及到关联 "req -> Target -> ChunkEngine (MetaDB)", 进而根据 chunk id 定位一个 chunk。
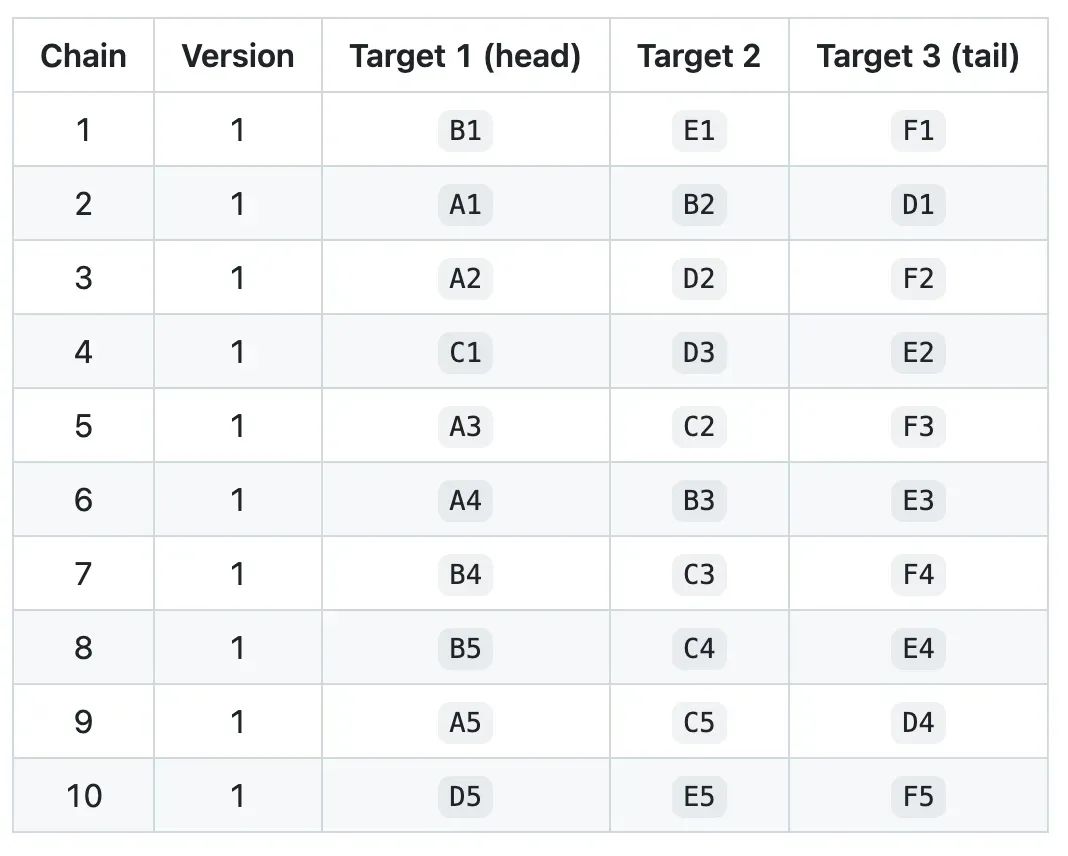
StorageOperator 层会解决 req->Target 的映射解析, 基于 "req.payload.key.vChainId" 去定位 Target。3FS 根据 vChainId 找到 Target 是根据其 Chained 复制组来决定的,因此 req 请求中的 vChainId 加上本地的TargetMap 就可以确定唯一的 Target。如下图所示,如果 B1 是目标读取节点,ChainId 是 1 的话,则 B1 通过TargetMap 的 snapshot 直接找到 Target1 即可。
数据传递
数据面通信完全走 RDMA,读写通过自封装的 net 组件来实现。
读流程概要
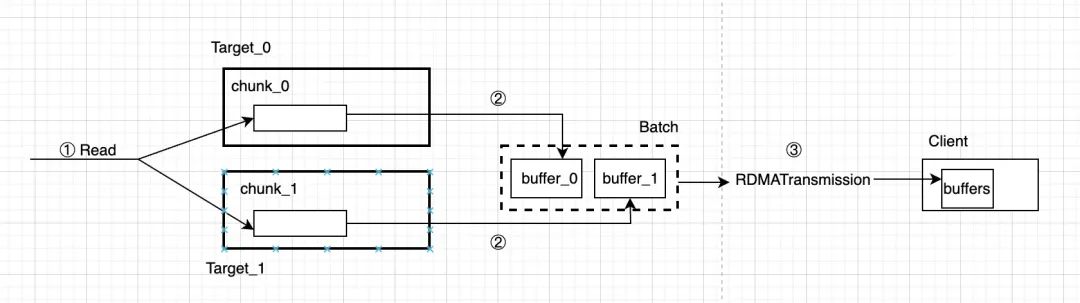
① 从StorgageOperator 中发送 Read 请求,走 AioReadWorker 读取目标 Chunk 即可。
② 读取到的数据会放到 buffer batch 中。
③ 通过 net::RDMATransmission 进行数据传输到 client。
其中 ② 这步骤包括了本地 buffer 池中开的 buffer(用于存储aio读出的数据), 也包含远端 Client IO 中的RDMABuf 信息,因此 ③ 之间的通路可达。
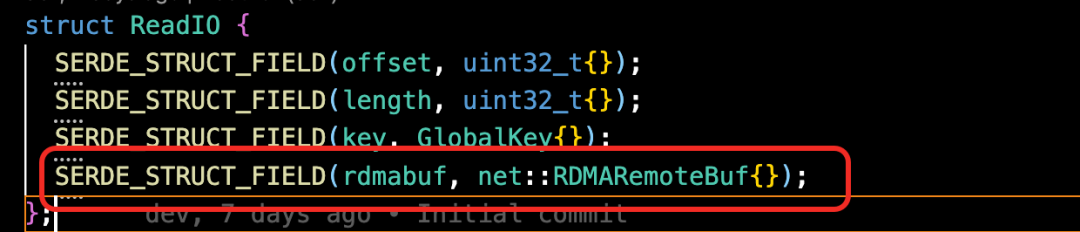
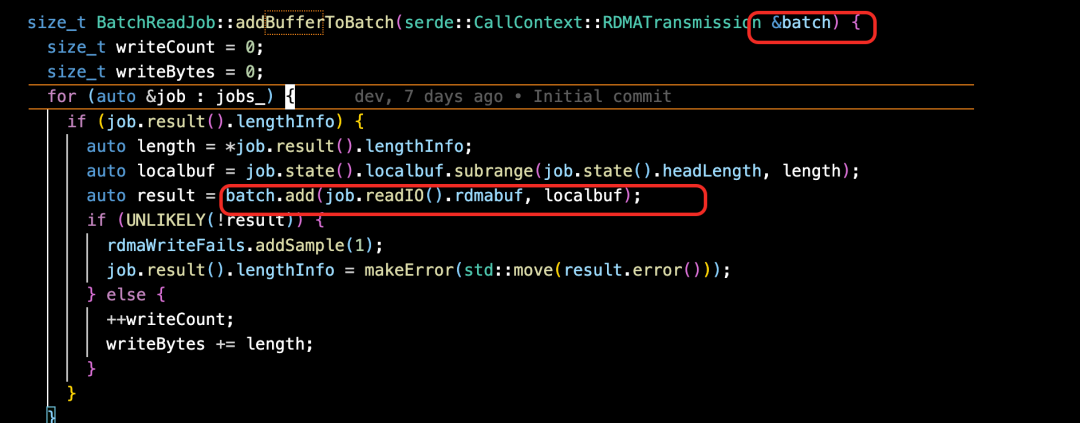


写流程概要
因为 Chain Replication 机制的引入,写流程相较于读要复杂一些。从 Client 的请求首先通过 write() 接口进入到 Chain Head,之后走链式复制直达 Tail 为止。
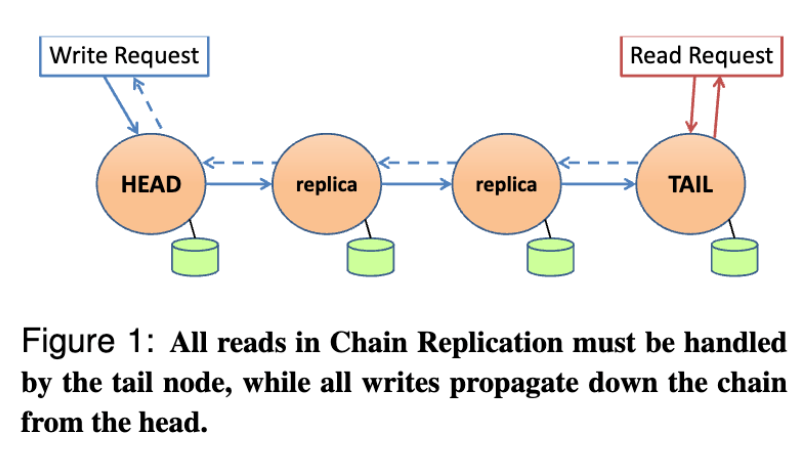
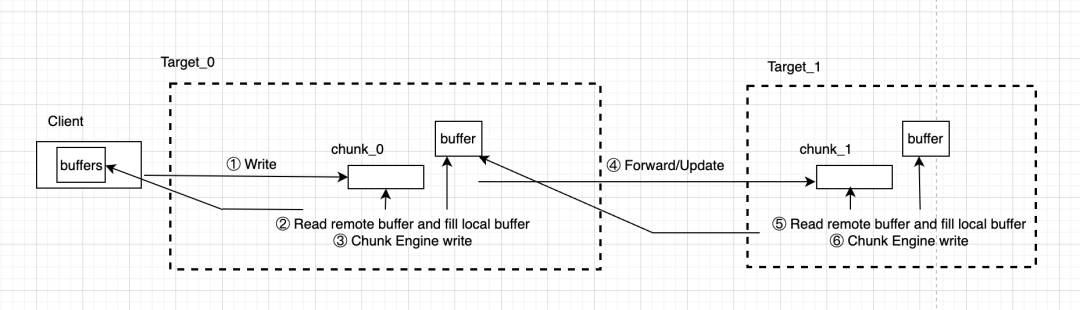
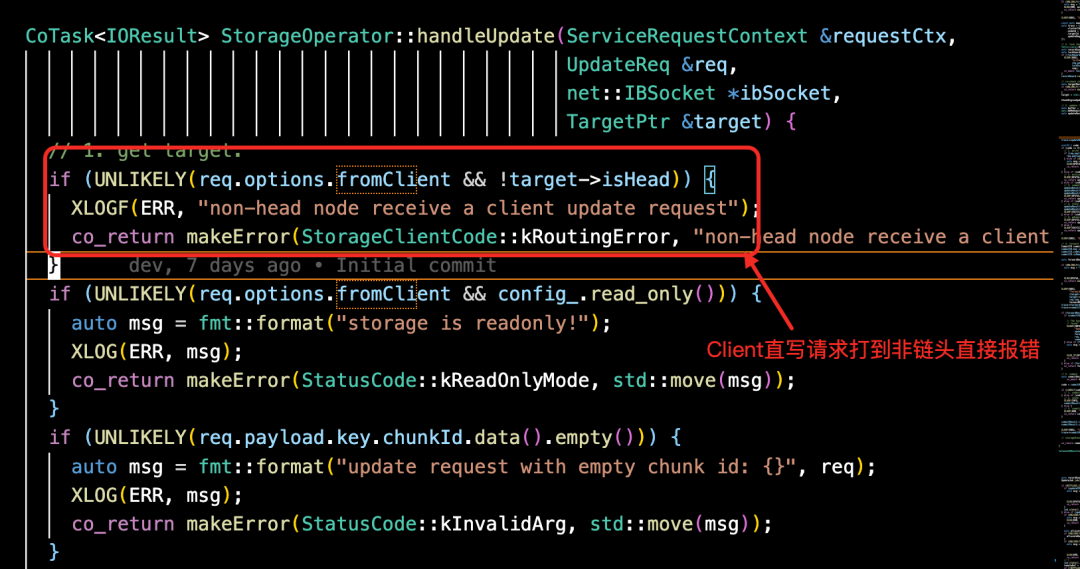
① Client 向 StorageOperator 中提交 write 请求,"fromClient==true" 的请求必须是链头。
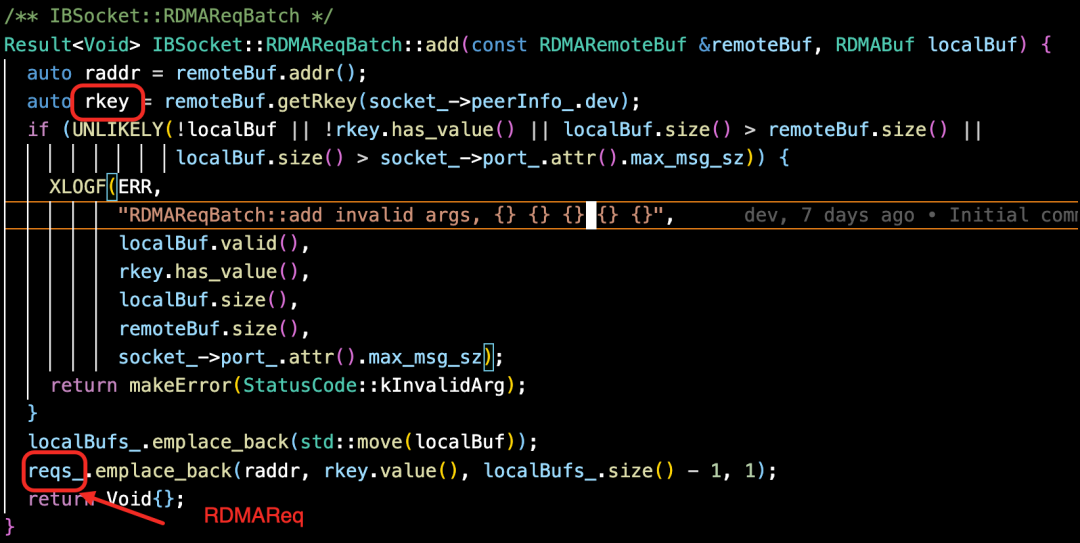
② 通过 RDMA 读取远端 client 中的内存 buffer, TransmissionRead。
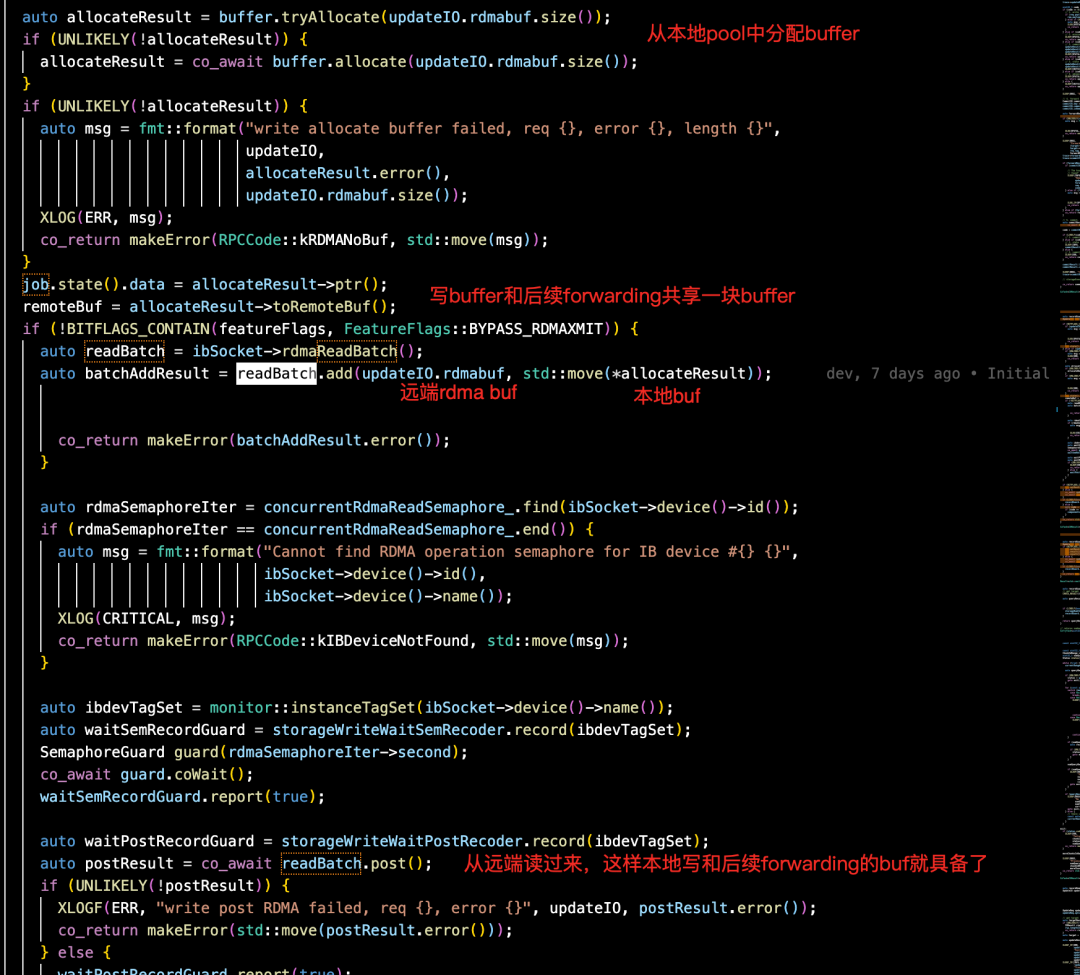
③ 通过 ChunkEngine 进行 DIO 写,走 UpdateWorker.enqueue 后通过后台线程刷盘,后台走 ChunkEngine 写目标 chunk。
④ 写成功后开启 fowarding 将本地 buffer 信息传递给 next peer,便于后续 next peer 的读。
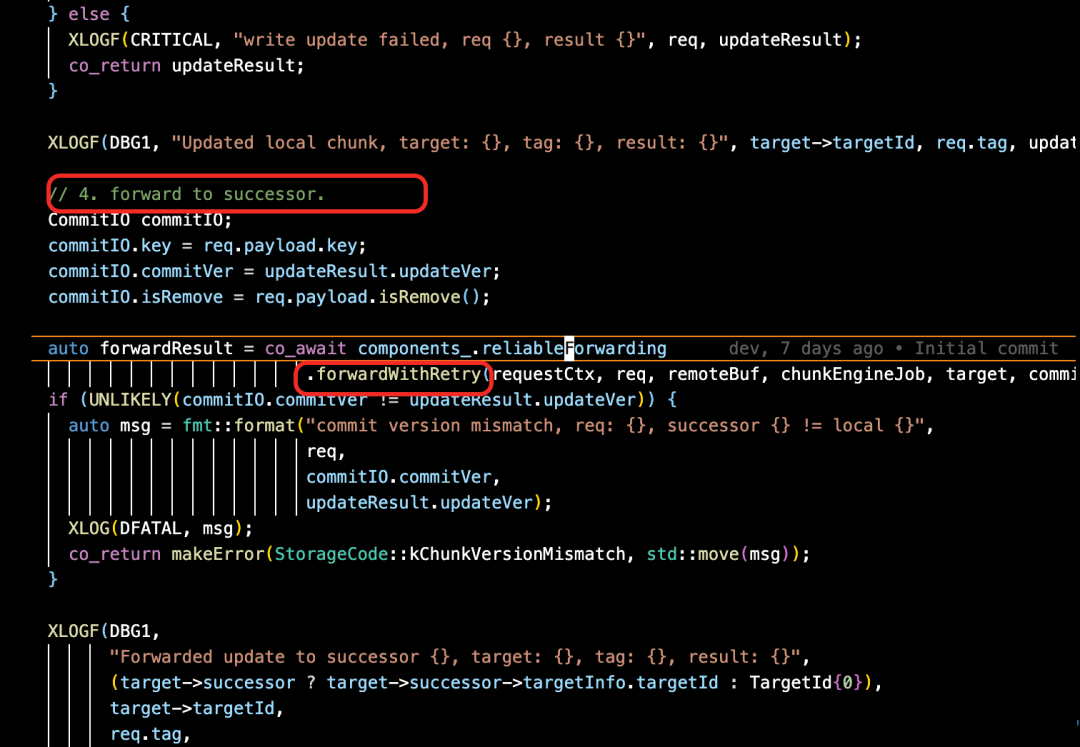
⑤ 重复第一个节点的流程,不同的是请求不是从 client 发过来,而是从 peer 来的,因此 fromClient == false。
设计点
Zero-Copy
3FS 中通过将 IO buffer 和网络传输的 buffer 共享 (RDMABuf),走 net 组件实现了 zero-copy。不过因为当前使用的是 kernel io,因此会存在一次用户态 RDMABuf 到 kernel 态 buffer 的 1 次 copy (kernel DIO,bypass page cache)。之所以不使用类似 SPDK NVMe 用户态存储栈的原因可能是因为需要多分配一块磁盘,另外ChunkEngine 使用 rust 编写,和 SPDK 之间也的协调也带来了额外的工程复杂度。
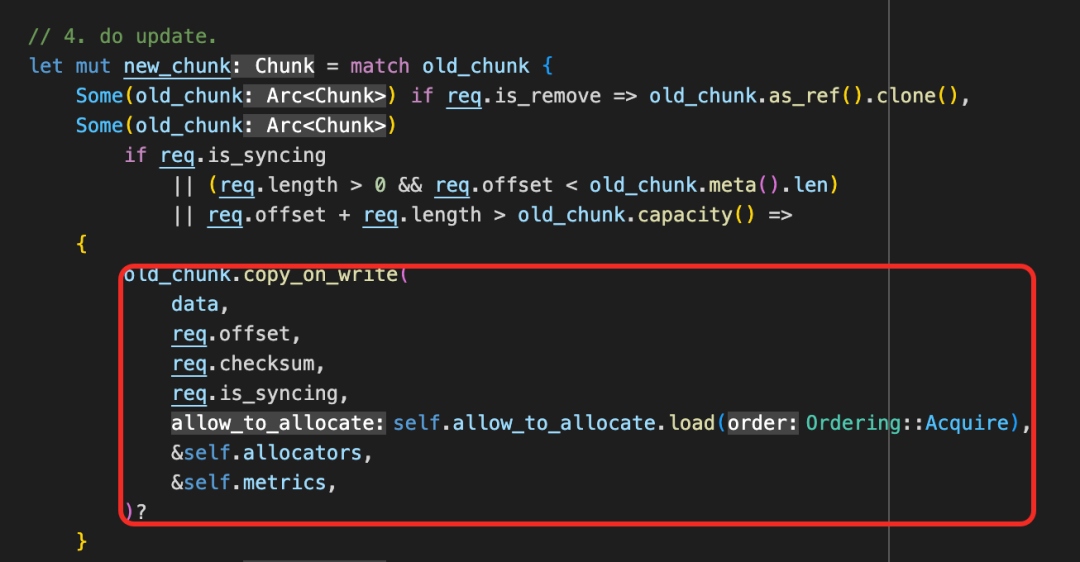
Copy-On-Write
3FS 支持随机写,这个过程中会涉及到 chunk 数据的 copy-on-write。在 ChunkEngine update_chunk 的过程中,会对 old_chunk 进行 copy-on-write。这其中会执行如下动作:1. 分配新 Chunk,2. Read-Modify-Write 3. Copy 元数据
这当中会产生一定的后台数据拷贝,所以在大规模随机写的场景下可能性能不太友好。这对于一个支持 POSIX 语意的分布式文件系统来说是一个难以回避的问题。同时,如果未来需要保存不同 snapshot 版本的文件,将会对元数据管理提出更进一步挑战。
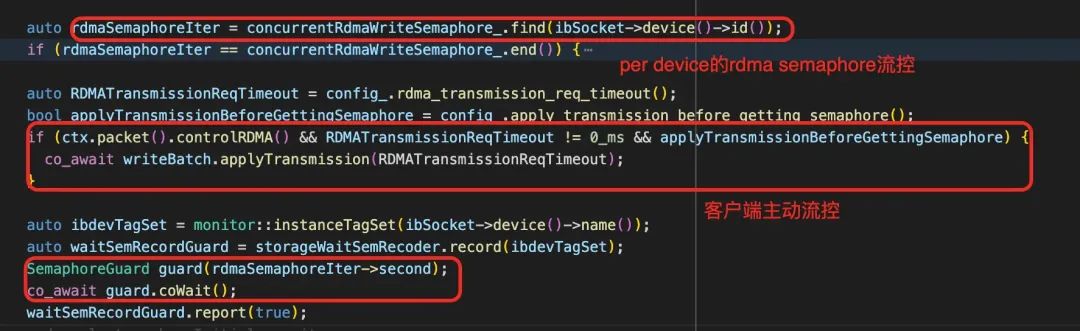
流量控制
从之前分享文章中得知 3FS 的 I/O 原理是在 storage 执行 Transmission 之前收到的请求是不带数据 IO 的。意思是文件写请求是先发一个 RPC 请求让 peer 来反向读,文件读请求 RPC 里面也只带要读取的数据 offset 和 length 等元信息。
文件读请求过程中,当内部通过流控后开始执行发送端的数据通信,将本地数据投递到远端 (Client)。文件读请求的流控发生在从磁盘 AIO 读取数据后到 RDMA WRITE 前。文件读请求有两个流控点:一个是服务器对一个 device 的 inflight RDMA 的流控,另外一个是客户端主动要求服务器流控。在 inflight RDMA 流控这点上,文件写请求也是一致的,就不再赘述。
apply 请求是在 writeBatch.applyTransmission() 中会被调用,向客户端发起一个 RPC 请求,在这当中由 limit_ 产生流控。
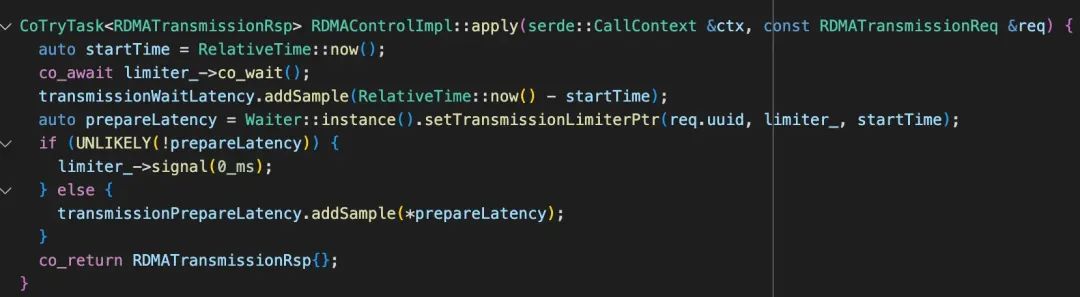
而对于写则是从本地发起读操作从远端(Client/previous peer)拉取数据。文件写请求的流控发生在收到请求后准备 RDMA READ 前。文件写请求流控只在 RDMA READ 过程中并发限制。机制和读请求基本相同。
论文中 request-to-send control mechanism 可能就是上文中描述的流控机制。

写放大和空间放大
3FS 可以为不同目录设置不同的 chunk size, 这样不同 I/O pattern 的业务数据可以选择不同目录进行放置,结合上文分析的 cow 机制,这样能实现空间和 I/O 放大上的良好适配。与此同时在 Storage 层分配 Chunk 的时候会根据不同的 chunk size 选择不同的 Allocator,这或许是为了满足不同 SLA 的考虑。
在删除 chunk 的过程中,由于一定时间内空洞 position 还占据 Group 的位置导致不能分配更大连续空间,这也相当于带来一定的空间放大,而碎片整理尽可能让系统空间利用率得到提升。另外在 SSD 内部本身也会有写放大,而且 3FS 做 GC 过程中产生的 move chunk 这部分逻辑可能和底层 NVMe FTL 产生一定程度的相互影响,因此引入 OC-SSD 和 ZNS SSD 等的介质存储,让上层软件栈和底层存储之间做到协同数据布局也是一个性能优化的方向。
参考资料
[1] 3FS design notes
https://github.com/deepseek-ai/3FS/blob/main/docs/design_notes.md

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)