QwQ-32B:拥抱推理与批判性思维的力量
QwQ是Qwen系列中的一员,它专注于推理能力的提升,尤其擅长处理涉及复杂问题解决的下游任务。QwQ-32B是该系列的一款中型模型,采用了最新的Qwen2.5架构,相较于其他主流推理模型如DeepSeek-R1和o1-mini,QwQ-32B在性能上具有强大的竞争力。QwQ-32B代表了推理模型的一大进步,它的应用不仅限于推理任务本身,还涵盖了各种实际问题的解决方案。通过合理的配置和使用,QwQ-
在人工智能的领域,模型的推理能力一直是研究和应用中的重要课题。近年来,深度学习的模型逐渐从简单的模式识别进化到能够处理更复杂问题的推理任务。在这方面,QwQ系列中的QwQ-32B便成为了一个引人注目的存在。与传统的指令调优模型不同,QwQ-32B将推理和批判性思维融入了模型设计中,使其能够在面对复杂问题时,展现出极为出色的表现。
QwQ-32B模型概述
QwQ是Qwen系列中的一员,它专注于推理能力的提升,尤其擅长处理涉及复杂问题解决的下游任务。QwQ-32B是该系列的一款中型模型,采用了最新的Qwen2.5架构,相较于其他主流推理模型如DeepSeek-R1和o1-mini,QwQ-32B在性能上具有强大的竞争力。
核心特点
-
推理与批判性思维:QwQ模型通过增强推理能力,能够对复杂问题进行深度分析,而不仅仅是依赖简单的规则或模式匹配。这使得QwQ在多个领域中都展现了卓越的性能。
-
与顶级推理模型竞争:QwQ-32B不仅在推理任务中表现突出,还能在生成任务中提供高质量的输出,满足实际应用中的需求。
-
适用广泛的应用场景:无论是复杂的数学推理,还是多步骤的逻辑推理,QwQ-32B都能够高效应对。这使得它在教育、科学研究、智能客服等领域都有广泛的应用前景。
性能评估与优势
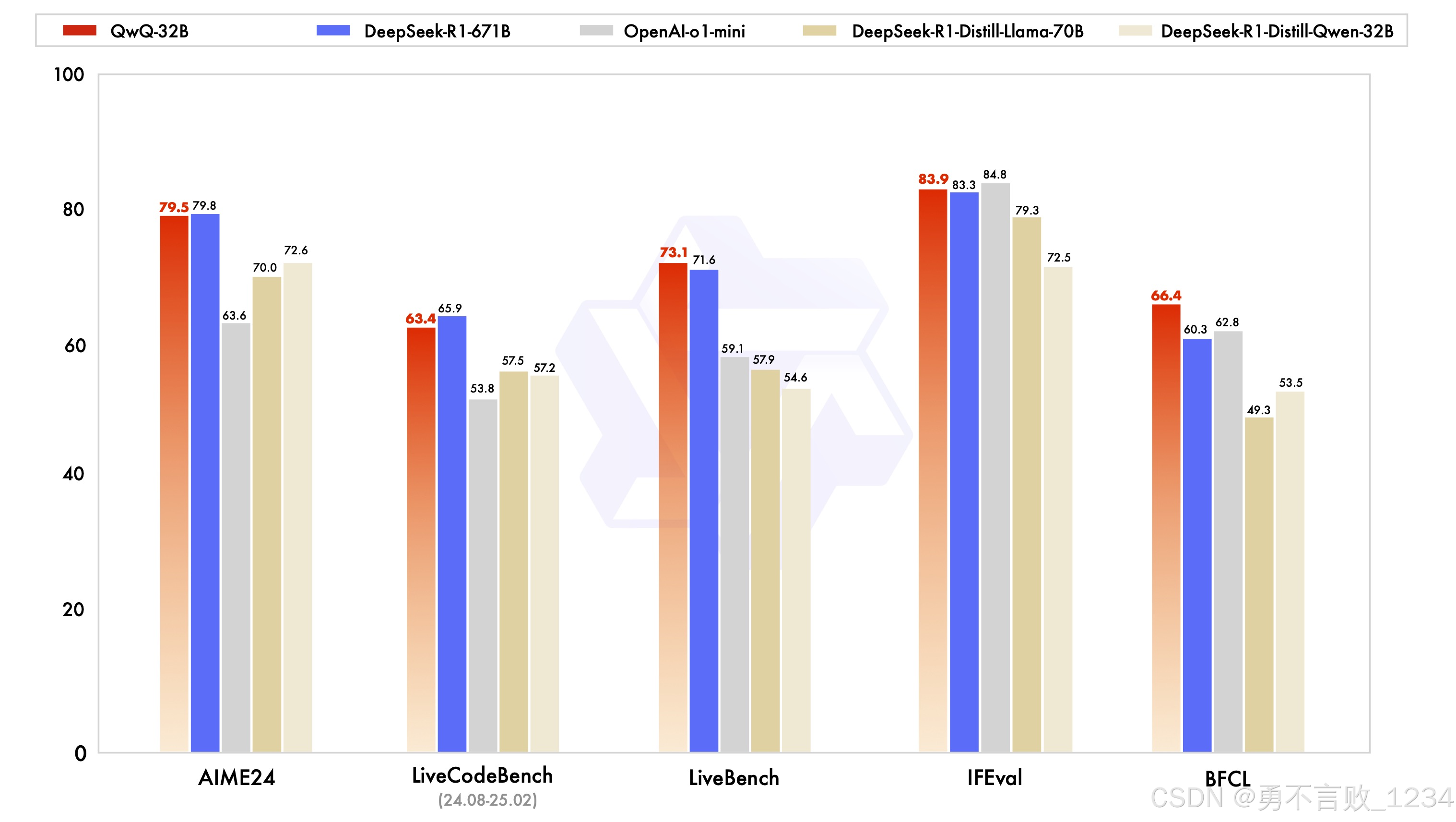
QwQ-32B的优越性能不仅仅体现在其在推理任务上的精准表现,还表现在其与其他同类模型的对比中。与目前顶尖的推理模型DeepSeek-R1和o1-mini相比,QwQ-32B能够在处理复杂推理任务时保持高度的稳定性和准确性。通过对QwQ-32B的实际应用评估,我们发现其在处理需要复杂逻辑推理和细节推敲的任务时,表现优于许多现有的竞争对手。
QwQ-32B性能
快速开始:使用Hugging Face的Transformers框架
QwQ-32B基于Qwen2.5架构,这意味着它已经集成在最新版本的Hugging Face transformers库中。为了确保最佳性能,建议使用最新版的transformers。
加载模型与Tokenizer
在Hugging Face的Transformers中加载QwQ模型非常简单。以下代码展示了如何加载模型并进行推理:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
该代码片段展示了如何使用QwQ-32B模型进行推理。在实际使用中,您可以根据需求调整生成的最大tokens数和其他参数,以便实现最优的推理效果。
使用指南
为了在实际应用中获得最佳性能,我们推荐以下几个使用技巧和设置:
1. 确保输出具有思考内容
在生成内容时,确保模型的输出包含思考过程。这有助于提高生成内容的质量,避免出现空洞的重复内容。通过apply_chat_template方法,您可以自动实现这一点,但有时可能会遇到缺失思考标签的情况,这属于正常现象。
2. 采样参数的设置
为确保输出多样性且不过度重复,建议使用以下采样参数:
- Temperature = 0.6
- TopP = 0.95
- TopK = 40
- MinP = 0
这些设置可以帮助生成既不失准确性,又具备创造性的内容。请注意,避免使用贪婪解码(Greedy decoding),因为它可能导致输出重复。
3. 多轮对话中的输出历史管理
在多轮对话中,历史模型输出应仅包括最后的回答部分,而不包含思考内容。通过apply_chat_template,该功能已得到了自动化支持。
4. 标准化输出格式
对于特定的任务,您可以通过在提示中加入额外的说明来规范化模型的输出。例如:
- 数学问题:在提示中加入“请逐步推理,最终答案放在\boxed{}内。”
- 多项选择问题:在提示中加入JSON结构:“请在
answer字段中展示你的选择字母,例如:\"answer\": \"C\"。”
5. 处理长输入
对于超出8,192个tokens的输入,建议启用YaRN以改善模型对长序列信息的捕捉能力。具体的配置方法请参考QwQ文档,或使用vLLM进行优化。
运行QwQ模型的其他方式
除了使用Hugging Face框架,您还可以通过Ollama或Llama.cpp来运行QwQ-32B模型。
使用Ollama
对于Ollama用户,可以通过以下命令运行QwQ-32B-GGUF模型:
ollama run hf.co/Qwen/QwQ-32B-GGUF:Q4_K_M
使用Llama.cpp
对于Llama.cpp用户,您可以使用以下命令:
./llama-cli \
--model QwQ-32B-GGUF/qwq-32b-q4_k_m.gguf \
--threads 32 \
--ctx-size 32768 \
--seed 1234 \
--temp 0.6 \
--min-p 0.0 \
--top-k 40 \
--top-p 0.95 \
-no-cnv \
--samplers "top_k;top_p;min_p;temperature;" \
--prompt "<|im_start|>user\nHow many r's are in the word \"strawberry\"<|im_end|>\n<|im_start|>assistant\n<think>\n"
使用API
如果您在部署QwQ时遇到困难,可以使用阿里云模型工作室提供的API服务进行测试。
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"))
completion = client.chat.completions.create(
model="qwq-32b",
messages=[{"role": "user", "content": "Which is larger, 9.9 or 9.11?"}],
stream=True
)
for chunk in completion:
if chunk.choices:
print(chunk.choices[0].delta.content, end='', flush=True)
结语
QwQ-32B代表了推理模型的一大进步,它的应用不仅限于推理任务本身,还涵盖了各种实际问题的解决方案。通过合理的配置和使用,QwQ-32B可以在多个领域中展现其强大的推理能力,为您的项目提供强有力的技术支持。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)