星海智算:QwQ-32B的实战部署与体验,比肩671B DeepSeek
在人工智能领域,模型的性能和部署效率一直是开发者关注的焦点。最近,阿里开源的QwQ-32B推理模型引起了广泛关注。这款32B模型在性能上与671B的DeepSeek R1不相上下,却能在单台机器上高效运行,堪称技术的一大突破。
QwQ-32B模型开源
在人工智能领域,模型的性能和部署效率一直是开发者关注的焦点。最近,阿里开源的QwQ-32B推理模型引起了广泛关注。这款32B模型在性能上与671B的DeepSeek R1不相上下,却能在单台机器上高效运行,堪称技术的一大突破。
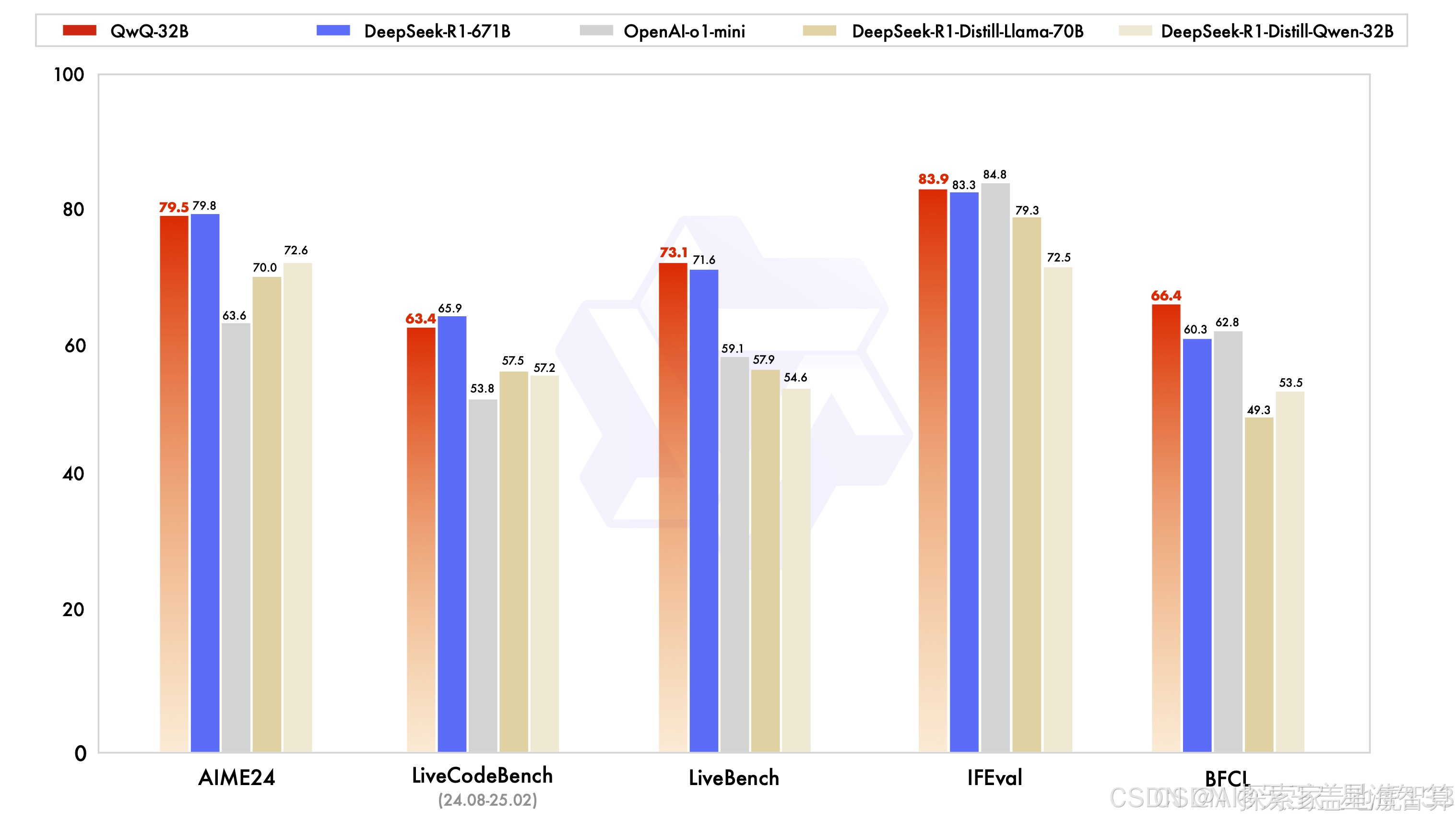
QwQ-32B模型基于Qwen2.5-32B结合强化学习打造,未采用MoE架构,上下文长度高达131k。与以往的大型模型相比,它在资源占用和运行效率上都表现出色,甚至可以在单张4090D显卡上完美运行,为个人开发者和尝鲜者带来了极大的便利。
部署并推理QwQ-32B
一、创建实例
在星海智算平台创建实例,选择想要的显卡,镜像选择Ubuntu24.04/CUDA12.4/cuDNN9.4,磁盘扩容到60G。
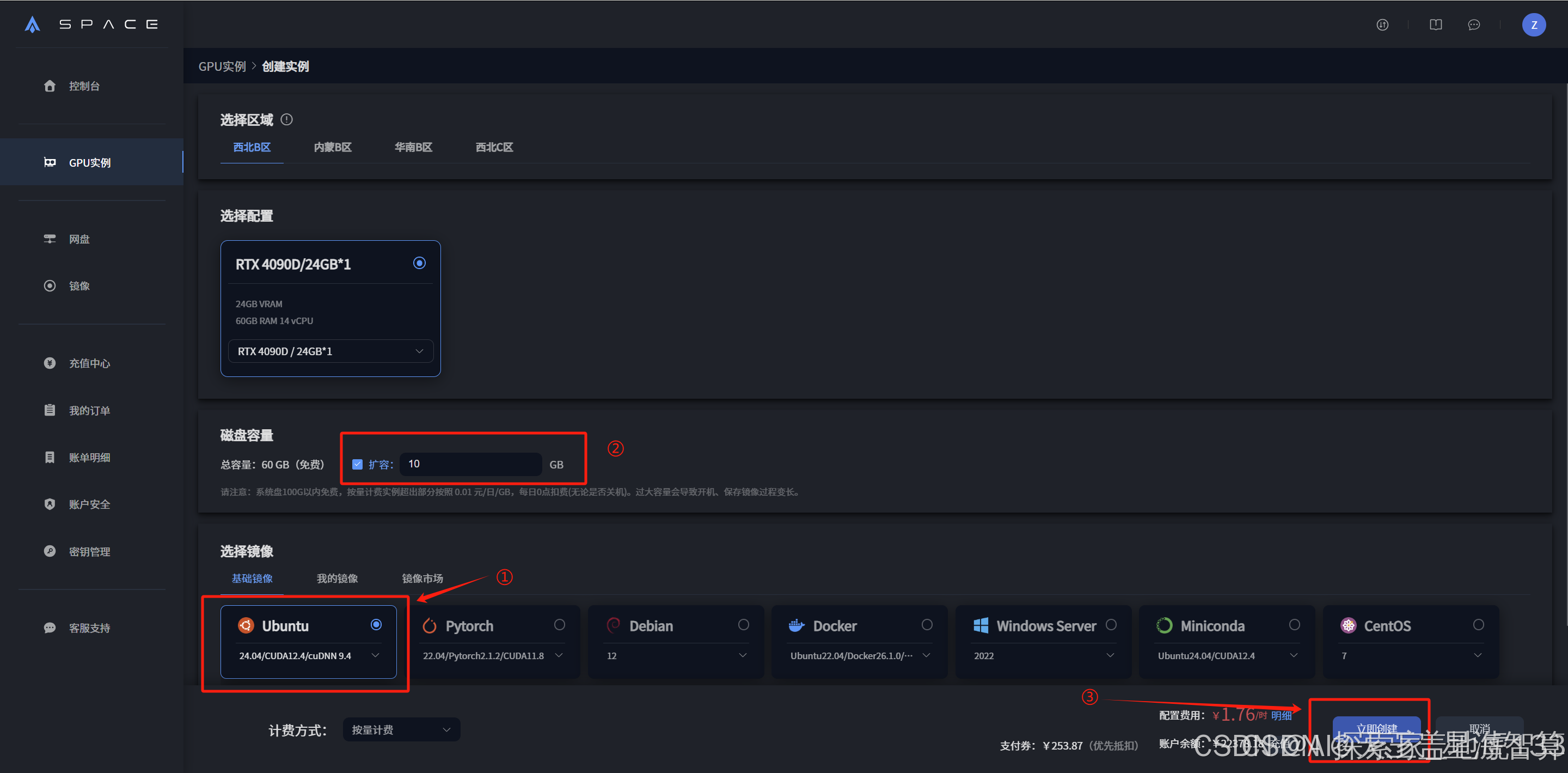 创建完成后,等待1-2分钟,状态栏变为“运行中”,点击JupyterLab进入。
创建完成后,等待1-2分钟,状态栏变为“运行中”,点击JupyterLab进入。

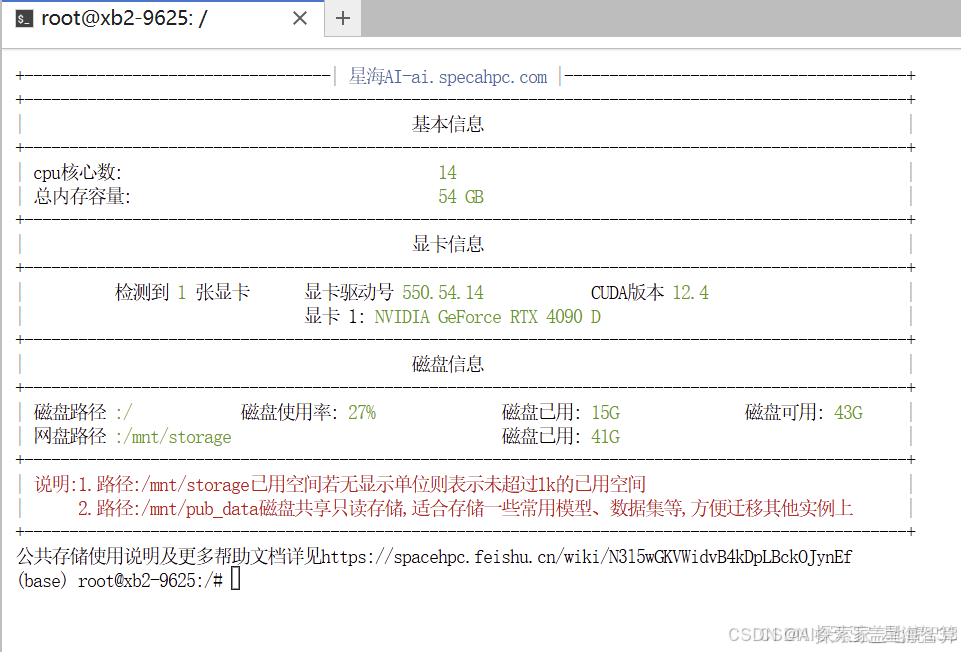
进入JupyterLab后,开启一个终端。

终端内会自动显示CPU、内存、显卡、磁盘等信息,方便我们随时查看资源使用情况。
二、使用Ollama部署QwQ-32B
(一)安装Ollama
在Ollama的下载页面(https://ollama.com/download),选择Linux系统,复制命令部署Ollama
curl -fsSL https://ollama.com/install.sh | sh
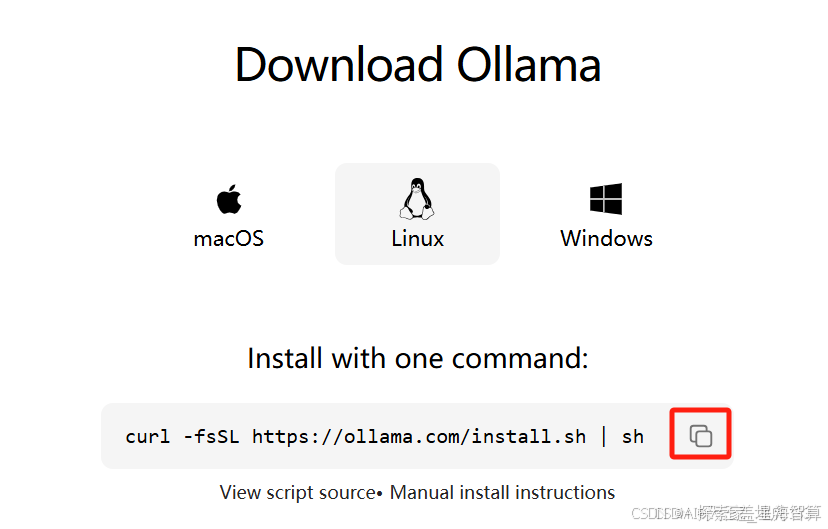 在云平台的终端中运行该命令,如下图所示结果即表示Ollama安装成功。
在云平台的终端中运行该命令,如下图所示结果即表示Ollama安装成功。
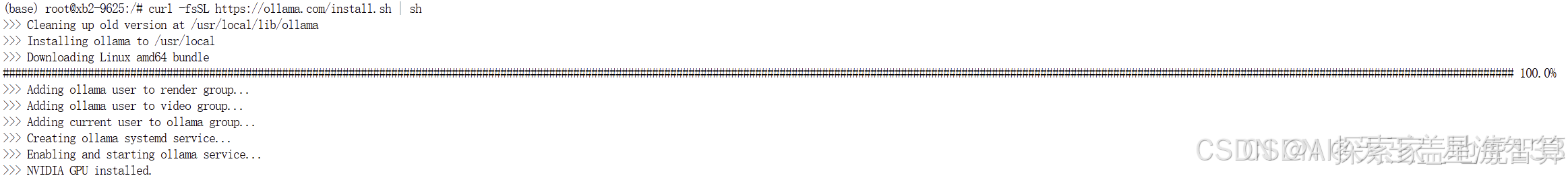
(二)部署QwQ-32B模型
进入Ollama模型库页面(https://ollama.com/library/qwq),可以看到QwQ-32B的模型信息。
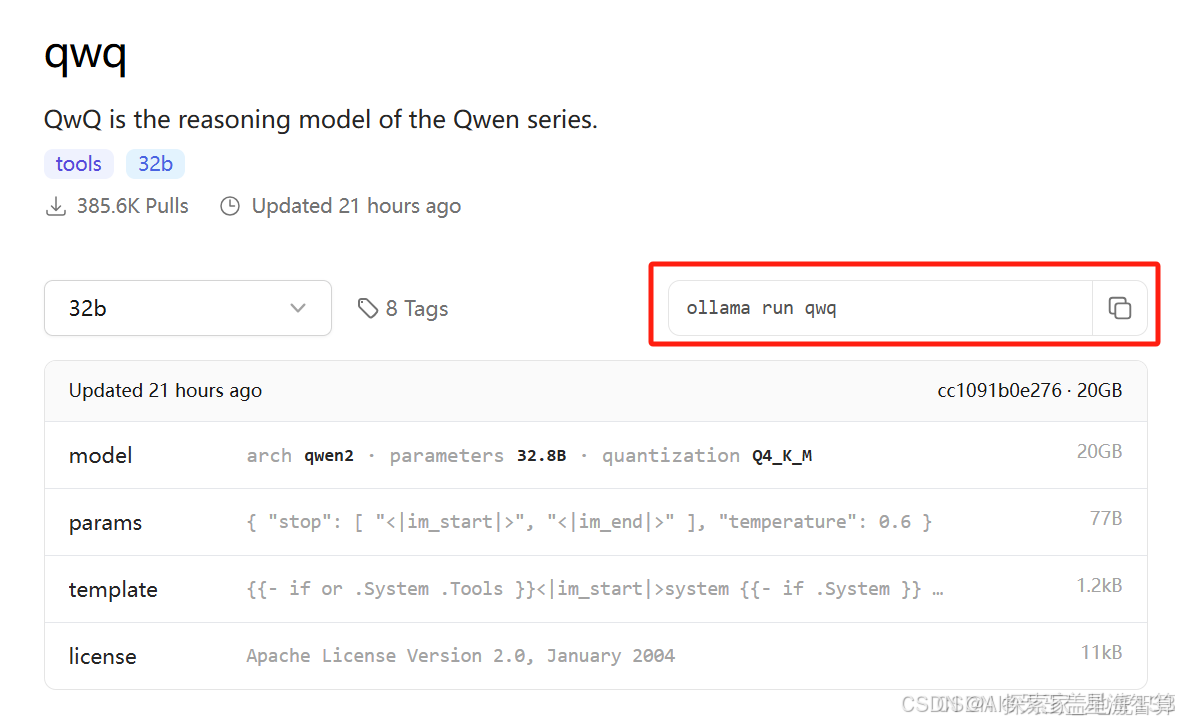
复制右边的命令到终端中,即可下载并使用QwQ-32B模型。
ollama run qwq

图中跟大模型交互的方式为命令行界面,使用体验不好,可以安装Open WebUI前端来交互,可以先按Ctrl + d 键退出Ollama交互界面。
三、安装并使用Open WebUI
Open WebUI是一个功能强大、用户友好的自托管AI平台,支持离线操作,兼容多种LLM运行器,如Ollama和OpenAI兼容API,内置RAG推理引擎,是AI部署的优质选择。
(一)安装Open WebUI
运行以下命令安装Open WebUI:
conda deactivate #关闭open-webui虚拟环境
conda activate open-webui #启动open-webui虚拟环境
source /etc/network_turbo #开启网络加速
open-webui serve --port 7860 #运行open-webui并指定7660端口
在安装过程中,如遇需要选择y或N的地方,请按y并回车。
(二)使用Open WebUI与大模型对话
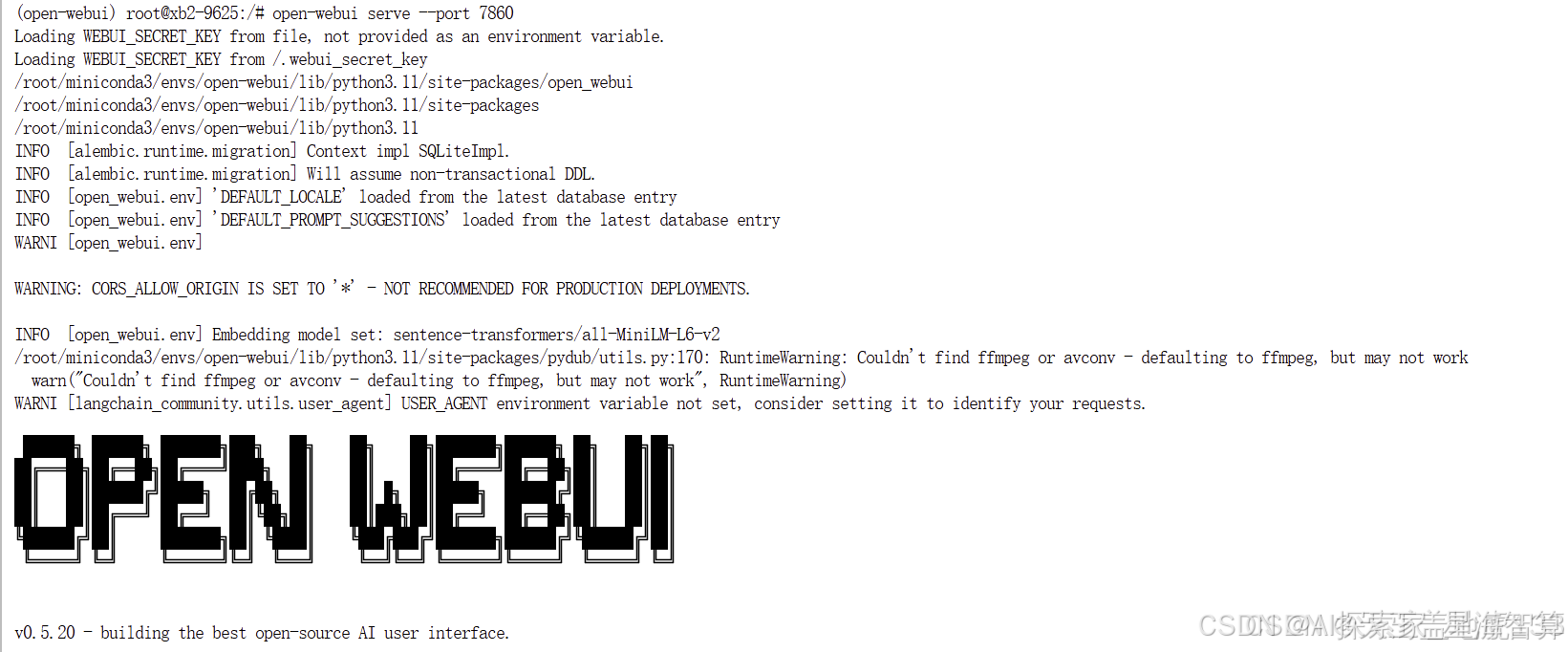
1. 运行Open WebUI服务
运行以下代码启动Open WebUI服务:
conda deactivate #关闭open-webui虚拟环境
conda activate open-webui #启动open-webui虚拟环境
source /etc/network_turbo #开启网络加速
open-webui serve --port 7860 #运行open-webui并指定7660端口
当出现特定图标时,表示服务运行成功。
2. 通过SSH端口映射本地访问Open WebUI
星海智算平台自带端口映射功能。回到智算平台控制台,点击端口映射。

在本地电脑打开cmd窗口,按照提示操作。
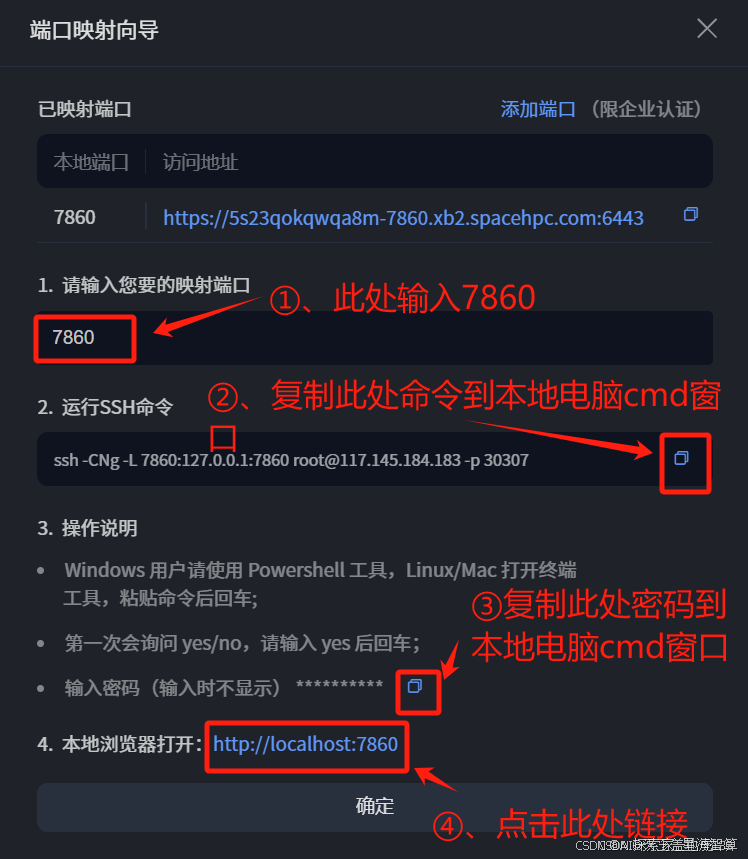
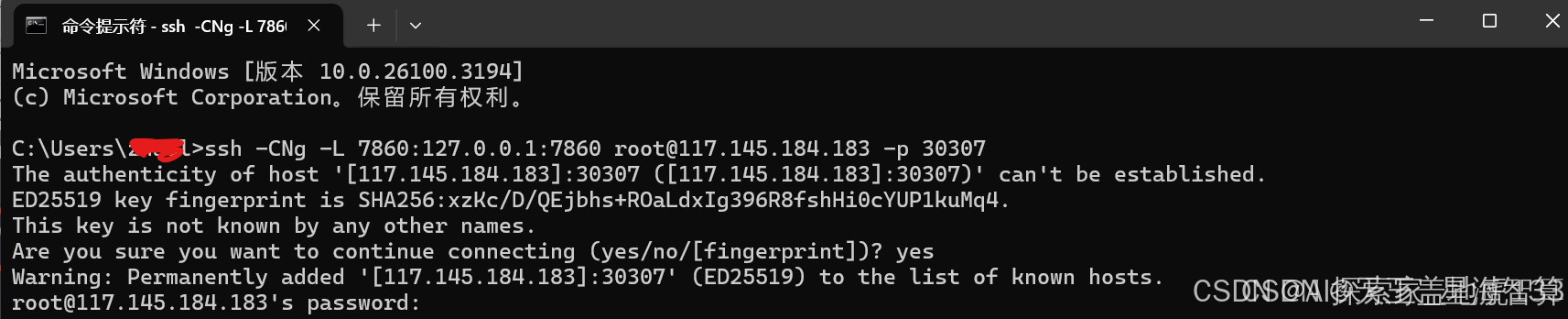
完成映射后,在浏览器中输入http://localhost:7860/,点击“开始使用”,并注册一个账号。

3. 与大模型对话
注册账号后,即可进入Open WebUI页面,开始与QwQ-32B模型进行对话。
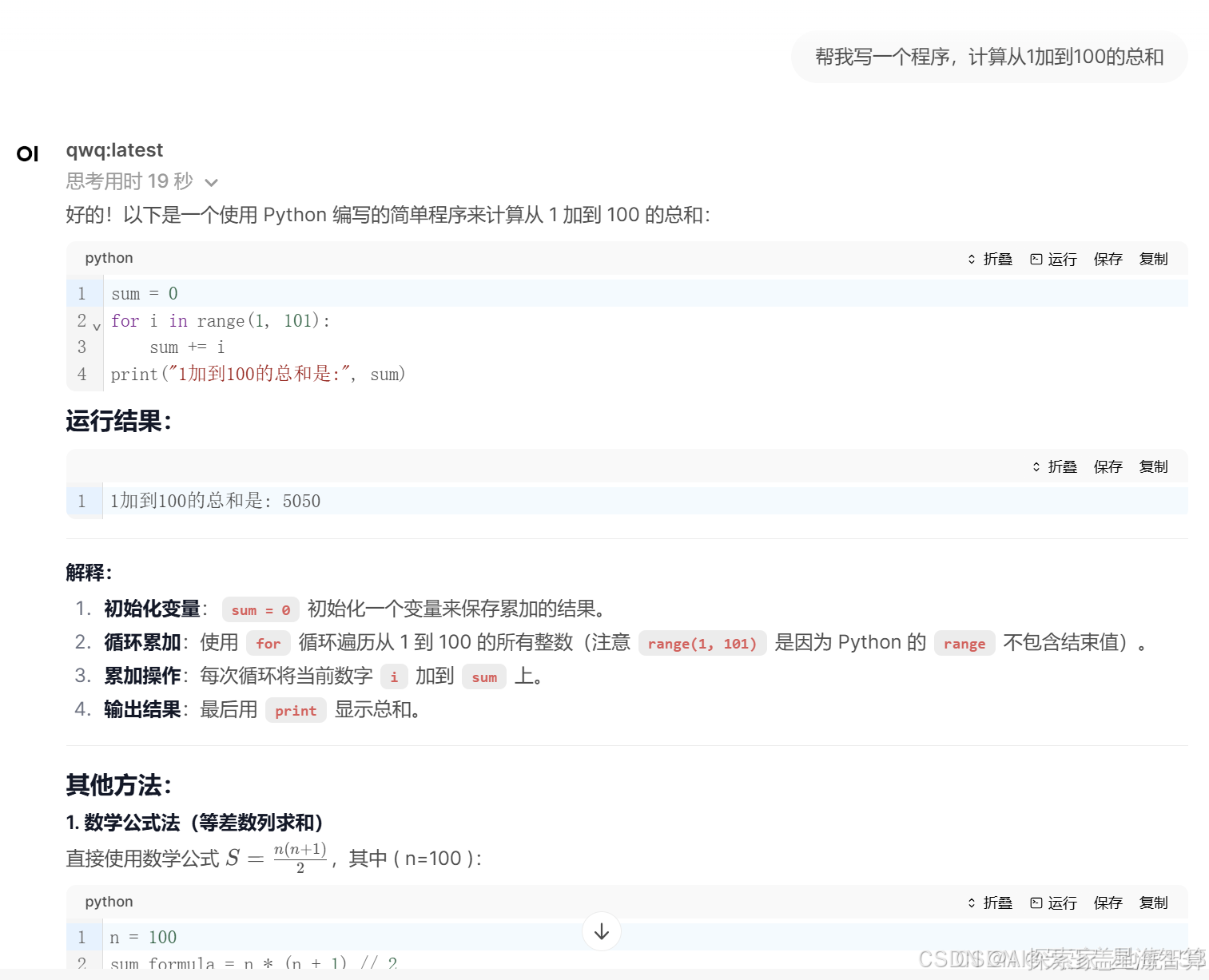
以下为一个问题的示例,效果非常不错

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)