【大模型】Deepseek R1论文解读
Deepseek R1
- 论文: https://arxiv.org/abs/2501.12948 (2025.1.22)
- 代码: https://github.com/deepseek-ai/DeepSeek-R1
- web: https://www.deepseek.com/
论文总结
文章介绍了通过强化学习提升大语言模型推理能力的研究,提出DeepSeek-R1-Zero和DeepSeek-R1模型,探索了强化学习在模型训练中的应用,展示了模型在多种任务上的优异性能,并讨论了研究中的经验和未来方向。
方法
论文的 2.Approach 主要介绍了DeepSeek-R1系列模型的构建方法,包括不依赖监督微调的DeepSeek-R1-Zero、基于冷启动数据训练的DeepSeek-R1,以及将推理能力蒸馏到小模型的方法,旨在提升大语言模型的推理能力。
- 研究概述:以往研究多依赖大量监督数据提升模型性能,本研究则证明大规模强化学习(RL)可显著提升模型推理能力,且无需监督微调作为冷启动。在此基础上,引入少量冷启动数据能进一步优化性能。研究内容包括直接在基础模型上应用RL训练的DeepSeek-R1-Zero、使用冷启动数据微调后进行RL训练的DeepSeek-R1,以及将DeepSeek-R1的推理能力蒸馏到小模型的方法。
- DeepSeek-R1-Zero:基于基础模型的强化学习
- 强化学习算法:采用Group Relative Policy Optimization(GRPO)算法,该算法通过从旧策略模型采样一组输出,优化策略模型以最大化目标函数,从而节省RL训练成本。公式 J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G ( m i n ( π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) A i , c l i p ( π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) , 1 − ε , 1 + ε ) ) A i ) − β D K L ( π θ ∥ π r e f ) ) \mathcal{J}_{GRPO}(\theta) = \mathbb{E}[q \sim P(Q),\{o_{i}\}_{i = 1}^{G} \sim \pi_{\theta_{old}}(O | q)]\frac{1}{G} \sum_{i = 1}^{G}(min(\frac{\pi_{\theta}(o_{i} | q)}{\pi_{\theta_{old}}(o_{i} | q)} A_{i}, clip(\frac{\pi_{\theta}(o_{i} | q)}{\pi_{\theta_{old}}(o_{i} | q)}, 1 - \varepsilon, 1 + \varepsilon))A_{i}) - \beta \mathbb{D}_{KL}(\pi_{\theta} \| \pi_{ref})) JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε))Ai)−βDKL(πθ∥πref)) 展示了其优化目标,其中 ε \varepsilon ε和 β \beta β是超参数, A i A_{i} Ai是优势,通过一组奖励计算得出。
- 奖励建模:采用基于规则的奖励系统,包含准确性奖励和格式奖励。准确性奖励用于评估模型回答是否正确,如数学问题按指定格式输出答案可通过规则验证;格式奖励要求模型将思考过程放在‘’和‘’标签内,以规范输出格式。不采用结果或过程神经奖励模型,因其在大规模RL过程中可能出现奖励劫持问题,且重新训练会增加资源成本和训练复杂性。
- 训练模板:设计简单训练模板,要求模型先输出推理过程,再给出最终答案,以此引导模型按规范输出,避免内容特定偏差,便于观察模型在RL过程中的自然发展。
- 性能、自进化过程和顿悟时刻:在AIME 2024基准测试中,DeepSeek-R1-Zero的平均pass@1分数从15.6%显著提升至71.0%,达到与OpenAI-o1-0912相当的水平,且通过多数投票可进一步提升至86.7%,超越OpenAI-o1-0912。训练过程中,模型的思考时间不断增加,能够自然地学习解决更复杂的推理任务,还出现了如反思和探索替代解题方法等复杂行为。在训练过程中,模型还出现了“aha moment”,学会重新评估初始方法,展示了RL可使模型自主发展出先进的解题策略。
- DeepSeek-R1:基于冷启动的强化学习
- 冷启动:为解决DeepSeek-R1-Zero早期训练不稳定、可读性差等问题,收集少量高质量长思维链(CoT)数据对DeepSeek-V3-Base进行微调。这些冷启动数据通过多种方式收集,如少样本提示、直接提示模型生成带反思和验证的详细答案等。冷启动数据具有可读性强的特点,输出格式为|special_token|<reasoning_process>|special_token|,且在性能上优于DeepSeek-R1-Zero。
- 推理导向的强化学习:在冷启动微调后,使用与DeepSeek-R1-Zero相同的大规模RL训练过程,专注于提升模型在编码、数学等推理密集型任务中的能力。训练中引入语言一致性奖励,以缓解思维链中的语言混合问题,该奖励通过计算目标语言单词在思维链中的比例得出,虽会使模型性能略有下降,但符合人类偏好,使输出更易读。最终将推理任务的
训练
该部分主要介绍了DeepSeek-R1系列模型的构建方法,通过强化学习和多阶段训练提升模型推理能力,具体包括DeepSeek-R1-Zero和DeepSeek-R1的训练过程,以及模型蒸馏的相关内容。
- DeepSeek-R1-Zero:基于基础模型的强化学习
- 强化学习算法:以DeepSeek-V3-Base为基础模型,运用Group Relative Policy Optimization(GRPO)强化学习框架,在无监督微调的情况下,通过与环境交互学习,不断优化策略以提升推理任务性能。
- 奖励建模:采用基于规则的奖励模型,利用多个可靠的Python库(如SymPy、NumPy、SciPy和OpenAI的Code Interpreter API)验证模型生成答案的正确性,将结果作为训练信号,激励模型探索有效的推理路径。
- 训练模板:设计简单模板引导模型输出,要求模型按特定格式进行推理,如先输出“Thought: ”,接着给出推理过程,再输出“Answer: ”,最后得出答案,规范模型输出形式,促进推理过程的结构化。
- 性能表现与自进化:在训练中,DeepSeek-R1-Zero自然展现出强大推理行为,如自我验证(通过多种方法验证答案)、反思(识别推理错误并重新思考)和生成长推理链。在AIME 2024基准测试中,pass@1分数从15.6%提升到71.0%,多数投票后达86.7%,与OpenAI-o1-0912相当,但存在可读性差(推理过程冗长复杂)和语言混杂(中英文夹杂)的问题。
- DeepSeek-R1:基于冷启动的强化学习
- 冷启动:为解决DeepSeek-R1-Zero的问题并进一步提升性能,收集数千条高质量冷启动数据对DeepSeek-V3-Base模型进行微调。这些数据涵盖数学、编程、科学推理等任务,使模型初步具备一定推理能力,为后续强化学习奠定基础。
- 面向推理的强化学习:冷启动微调后,与DeepSeek-R1-Zero类似,进行以推理为导向的强化学习。利用GRPO框架和基于规则的奖励模型,持续优化模型在推理任务中的策略,提升推理性能。
- 拒绝采样与监督微调:强化学习接近收敛时,在RL检查点上进行拒绝采样。结合DeepSeek-V3的监督数据(包括写作、事实问答、自我认知等领域),生成新的监督微调数据并重新训练模型,改善模型在多种任务中的表现,提升模型输出的可读性和规范性。
- 全场景强化学习:微调完成后,检查点继续进行强化学习,以涵盖所有场景的提示,使模型能更好地应对各种实际应用场景,全面提升模型性能。最终得到的DeepSeek-R1在推理任务上与OpenAI-o1-1217性能相当。
- 蒸馏:为小模型赋能推理能力:探索将DeepSeek-R1的推理能力蒸馏到小型密集模型的方法。以Qwen2.5-32B为基础模型,从DeepSeek-R1蒸馏的效果优于在小模型上直接应用强化学习。使用DeepSeek-R1生成的800k样本对Qwen和Llama系列的开源模型进行微调,得到的蒸馏小模型在推理基准测试中表现出色。如DeepSeek-R1-Distill-Qwen-7B在AIME 2024上超越QwQ-32B-Preview;DeepSeek-R1-Distill-Qwen-32B在多个任务上显著超越先前开源模型,与o1-mini相当 。还开源了基于Qwen2.5和Llama3系列的多个蒸馏模型的检查点,推动相关研究发展。
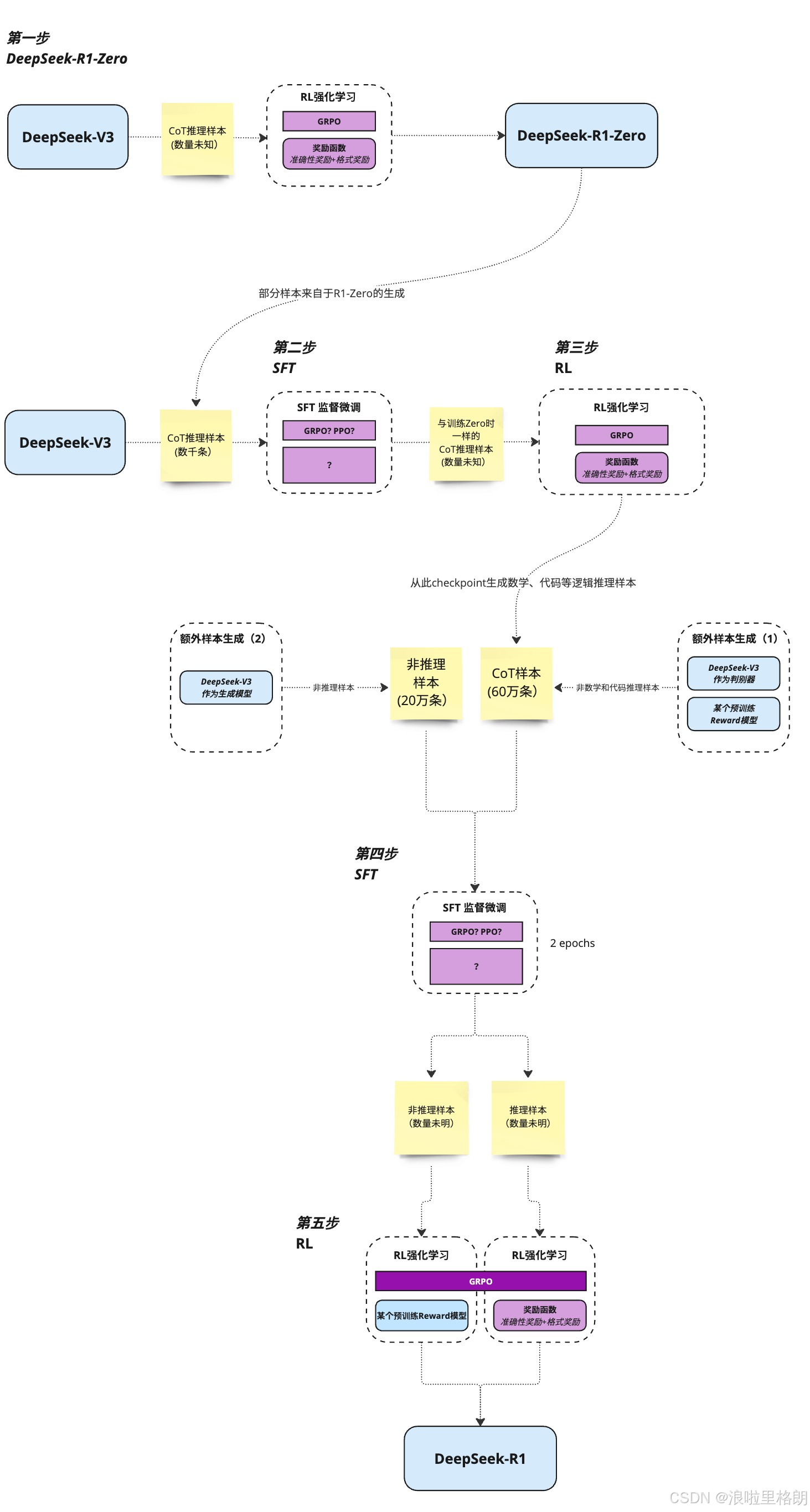
R1训练流程图
关于训练的部分论文虽然写了很多,但还不够详细,这里偷用张老师[2]的一张,总结的R1训练流程图。
其中,蓝色为模型,黄色为数据、紫色为训练。
这张图展示了DeepSeek R1的训练过程,主要包含以下步骤:
- 第一步:以DeepSeek-V3为基础,结合数量未知的CoT推理样本,通过RL强化学习(使用GRPO算法和准确性奖励 + 格式奖励),生成DeepSeek-R1-Zero模型。部分样本来自于R1-Zero的生成。
- 第二步:仍以DeepSeek-V3为起点,使用数千条CoT推理样本进行SFT(监督微调),微调算法可能是GRPO或PPO(图中未明确),同时使用与训练Zero时相同但数量未知的样本。
- 第三步:对第二步的结果再进行RL强化学习,使用GRPO算法和准确性奖励 + 格式奖励,从checkpoint生成数学、代码等逻辑推理样本。
- 第四步:DeepSeek-V3作为生成模型,产生非推理样本(20万条)和CoT样本(60万条),然后进行SFT监督微调,微调算法未明确,训练2个epochs,之后分为非推理样本和推理样本(数量均未知)两条路径。
- 第五步:第四步的结果再进行RL强化学习,使用GRPO算法、某个预训练Reward模型和准确性奖励 + 格式奖励,最终生成DeepSeek-R1模型。
总体来看,DeepSeek R1的训练过程是多次交替使用SFT监督微调和RL强化学习,并结合不同类型和数量的样本,逐步优化模型 。
实验结果
该部分主要介绍了DeepSeek-R1模型的实验设置、评估指标以及实验结果,通过与多个基线模型对比,全面评估了DeepSeek-R1及其蒸馏模型的性能。
- 实验设置
- 评估基准:选用多个权威基准测试评估模型,包括MMLU、MMLU-Redux、MMLU-Pro、C-Eval、CMMLU等知识理解类测试;IFEval、FRAMES等长文本理解和指令遵循测试;GPQA Diamond、SimpleQA、C-SimpleQA等问答测试;SWE-Bench Verified、Aider、LiveCodeBench、Codeforces等编码测试;还有中国高中数学奥林匹克竞赛(CNMO 2024)和美国数学邀请赛(AIME 2024)等数学测试。此外,使用AlpacaEval 2.0和Arena-Hard进行开放式生成任务评估。
- 评估提示:大部分标准基准测试(如MMLU、DROP、GPQA Diamond、SimpleQA )使用simple-evals框架的提示;MMLU-Redux采用Zero-Eval提示格式进行零样本设置评估;MMLU-Pro、C-Eval和CLUE-WSC等少样本提示的数据集,被调整为零样本设置;其他数据集则遵循原始评估协议和默认提示。对于代码和数学基准测试,HumanEval-Mul数据集涵盖多种主流编程语言,LiveCodeBench使用思维链(CoT)格式评估,Codeforces数据集结合特定竞赛题目和专家测试用例评估,SWE-Bench Verified通过无代理框架评估,AIDER相关基准测试使用“diff”格式评估,DeepSeek-R1输出最大长度限制为32,768 tokens。
- 基线模型:选择DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini、OpenAI-o1-1217等作为基线模型,对于蒸馏模型还对比了开源的QwQ-32B-Preview。因OpenAI-o1-1217 API访问受限,其性能数据基于官方报告。
- 评估方法:设置模型最大生成长度为32,768 tokens,采用pass@𝑘评估方法(默认报告pass@1),使用0.6的采样温度和0.95的top-P值生成多个响应(数量根据测试集大小在4到64之间),计算正确响应比例得到pass@1分数。对于AIME 2024,还报告使用64个样本的多数投票(consensus,cons@64)结果。
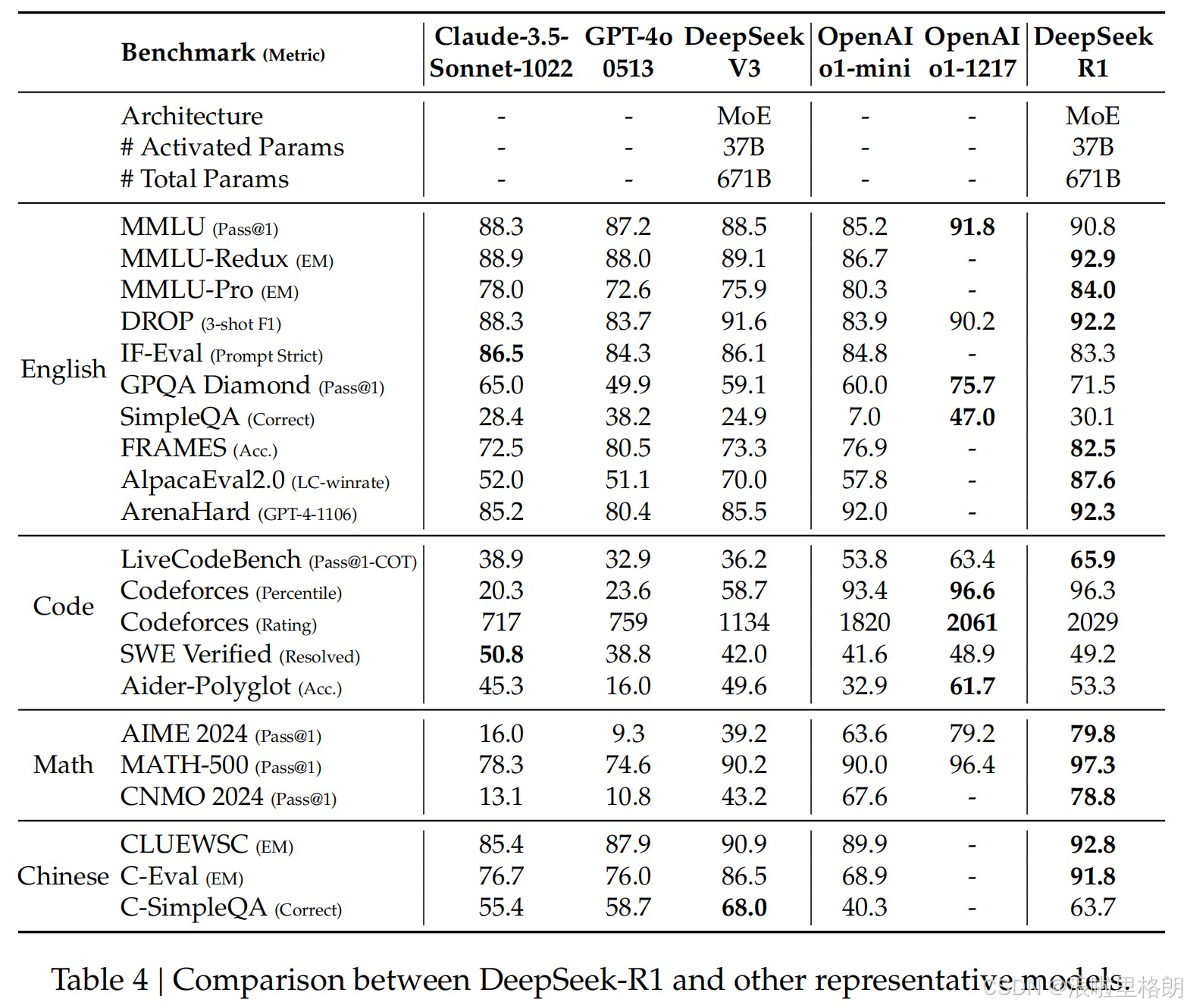
- DeepSeek-R1评估结果(Table 4)
- 知识基准测试:在教育知识基准测试(如MMLU、MMLU-Pro、GPQA Diamond)中,DeepSeek-R1表现优于DeepSeek-V3,在STEM相关问题上准确性更高;在事实性基准测试SimpleQA上也超越了DeepSeek-V3,但在Chinese SimpleQA基准测试中,由于安全强化学习导致其拒绝回答部分问题,表现不如DeepSeek-V3。在FRAMES长文本问答任务中表现出色,展示了强大的文档分析能力。
- 指令遵循评估:在IFEval基准测试中,DeepSeek-R1表现良好,这得益于训练后期融入的指令遵循数据。在AlpacaEval 2.0和Arena-Hard测试中,DeepSeek-R1在写作任务和开放域问答方面表现突出,显著超越DeepSeek-V3,且生成的摘要长度简洁,在基于GPT的评估中避免了长度偏差。
- 数学和编码任务:在数学任务(如AIME 2024、MATH-500、CNMO 2024)中,DeepSeek-R1与OpenAI-o1-1217性能相当,大幅超越其他模型;在编码算法任务(如LiveCodeBench和Codeforces)中表现优异;在工程编码任务上,OpenAI-o1-1217在Aider上表现更优,但在SWE Verified上二者性能相近,随着相关RL训练数据的增加,DeepSeek-R1在工程性能方面有望提升。
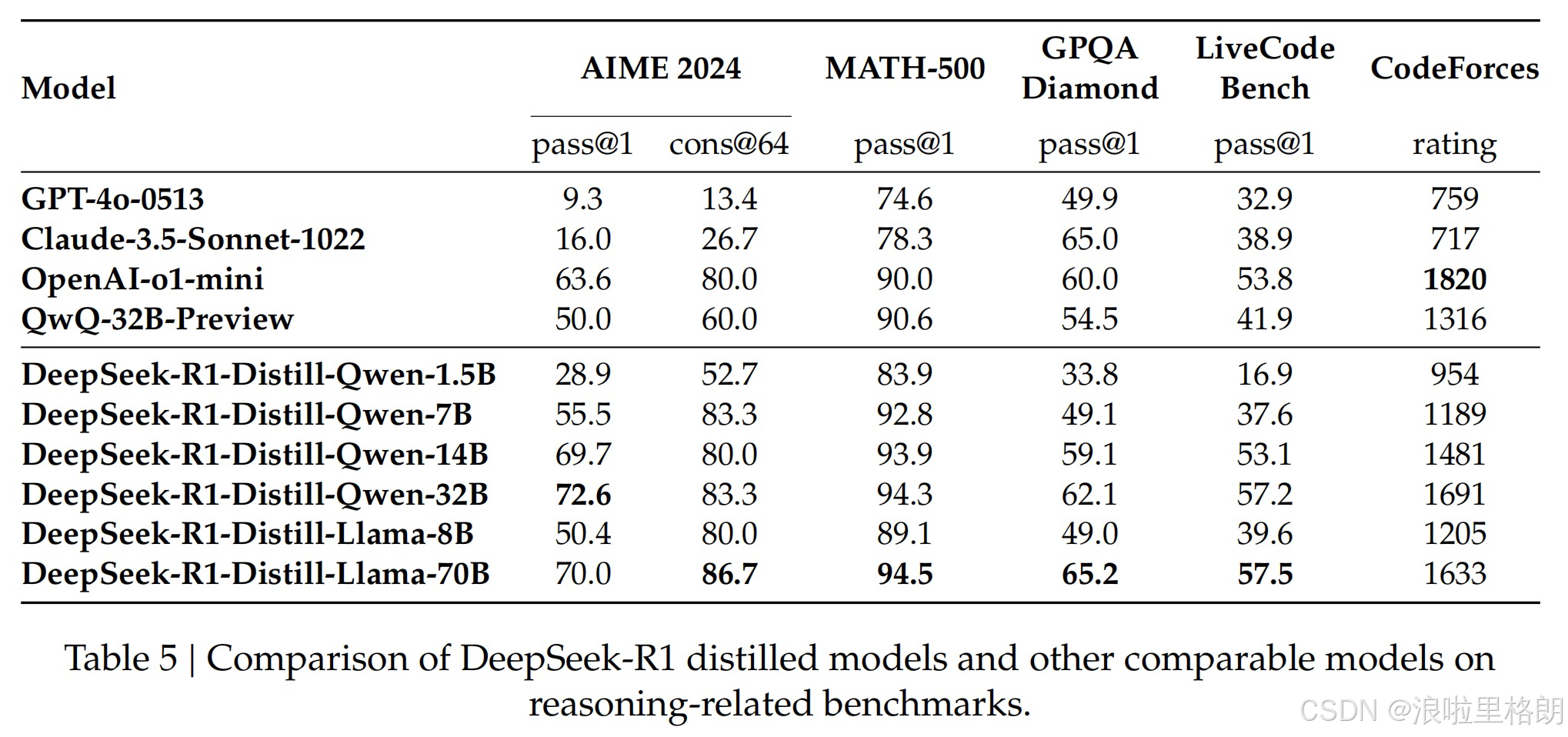
- 蒸馏模型评估结果:蒸馏后的小模型表现出色,DeepSeek-R1-Distill-Qwen-7B在AIME 2024上的成绩超越了QwQ-32B-Preview。DeepSeek-R1-Distill-Qwen-14B在所有评估指标上均超过QwQ-32B-Preview,DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Llama-70B在大多数基准测试中显著超越o1-mini。这些结果表明,将DeepSeek-R1的知识蒸馏到小模型中,可以有效提升小模型的推理能力。此外,研究发现对这些蒸馏模型应用RL训练还能进一步提升性能,但文章仅展示了简单SFT蒸馏模型的结果,后续对RL阶段的探索留给研究社区。
不成功的尝试
该部分主要讲述了在开发DeepSeek-R1过程中尝试过但未成功的方法,分析其失败原因,为后续研究提供经验教训。
- 过程奖励模型(PRM):PRM本是用于引导模型找到更好推理方法的合理方式,但在实际应用中存在显著缺陷。一般推理任务难以明确界定精细步骤,且判断当前中间步骤的正确性颇具挑战,自动标注效果欠佳,人工标注又不利于大规模应用。引入基于模型的PRM会引发奖励劫持问题,重新训练奖励模型不仅耗费额外资源,还会使整体训练流程更为复杂。虽然PRM在对模型生成的前N个响应重新排序或辅助引导搜索方面有一定作用,但在大规模强化学习过程中,其优势相较于引入的额外计算开销显得微不足道。
- 蒙特卡洛树搜索(MCTS):受AlphaGo和AlphaZero启发,尝试用MCTS提升测试时计算的可扩展性。具体做法是将答案拆分为小部分,让模型系统地探索解决方案空间,训练时借助预训练的值模型通过MCTS寻找答案,再用生成的问答对训练模型。然而,在大规模训练时该方法遇到诸多难题。与棋类游戏不同,令牌生成的搜索空间呈指数级增长,即便设置节点最大扩展限制,模型仍易陷入局部最优解。同时,值模型对生成质量影响重大,但其精细训练难度大,导致模型难以通过迭代实现有效改进。尽管MCTS结合预训练值模型在推理时能提升性能,但通过自我搜索迭代提升模型性能仍困难重重。
引用
[1] https://zhuanlan.zhihu.com/p/20240802247
[2] https://www.bilibili.com/video/BV1EmF9e6EdG/?vd_source=82e234619e3040198362a07a7117a0c9

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)