【大模型】Deepseek V3 论文解读
Deepseek V3
- 论文: https://arxiv.org/abs/2412.19437 (2024.12.27)
- 代码: https://github.com/deepseek-ai/DeepSeek-V3
- web: https://www.deepseek.com/
论文总结
文章介绍了具有6710亿参数的混合专家模型DeepSeek-V3,通过创新架构、高效训练和优化策略,在性能上超越开源模型且与闭源模型相当,同时保持较低训练成本。
模型结构
DeepSeek-V3的模型架构,包括基本架构和多令牌预测两部分,旨在通过创新的架构设计提升模型性能,实现高效推理和训练。
1. 基本架构:
DeepSeek-V3基于Transformer框架,采用MLA和DeepSeekMoE架构,并引入无辅助损失的负载平衡策略 。
- Multi-Head Latent Attention(多头潜在注意力,MLA):通过对注意力键值进行低秩联合压缩,减少推理时的KV缓存,同时对注意力查询进行低秩压缩,降低训练时的激活内存。其核心计算过程包括通过一系列矩阵运算生成压缩的键值向量、查询向量,最终结合得到注意力输出。公式(1) - (11)展示了具体计算过程,如 c t K V = W D K V h t c_{t}^{K V}=W^{D K V} h_{t} ctKV=WDKVht 用于计算压缩的键值向量 ,且仅部分向量在生成时需要缓存,在保持性能的同时显著减少了KV缓存。
- DeepSeekMoE with Auxiliary-Loss-Free Load Balancing(带无辅助损失负载平衡的DeepSeekMoE)
- DeepSeekMoE基本架构:在FFN中,DeepSeek-V3采用DeepSeekMoE架构,与传统MoE架构不同,它使用更细粒度的专家并设置共享专家。通过公式(12) - (15)计算FFN输出,其中涉及共享专家、路由专家的计算以及门控值的确定 ,如 h t ′ = u t + ∑ i = 1 N s F F N i ( s ) ( u t ) + ∑ i = 1 N r g i , t F F N i ( r ) ( u t ) h_{t}'=u_{t}+\sum_{i=1}^{N_{s}} FFN_{i}^{(s)}\left(u_{t}\right)+\sum_{i=1}^{N_{r}} g_{i, t} FFN_{i}^{(r)}\left(u_{t}\right) ht′=ut+∑i=1NsFFNi(s)(ut)+∑i=1Nrgi,tFFNi(r)(ut) 。与DeepSeek-V2略有不同,DeepSeek-V3使用sigmoid函数计算亲和度分数并进行归一化以生成门控值。
- 无辅助损失的负载平衡:为解决MoE模型中专家负载不平衡导致的问题,DeepSeek-V3引入无辅助损失的负载平衡策略。通过为每个专家添加偏差项 b i b_{i} bi 来调整路由决策,在训练过程中动态监控专家负载并调整偏差项,如公式(16)所示 g i , t ′ = { s i , t , s i , t + b i ∈ T o p k ( { s j , t + b j ∣ 1 ≤ j ≤ N r } , K r ) 0 , o t h e r w i s e g_{i, t}'= \begin{cases}s_{i, t}, & s_{i, t}+b_{i} \in Topk\left(\left\{s_{j, t}+b_{j} | 1 \leq j \leq N_{r}\right\}, K_{r}\right)\\ 0, & otherwise \end{cases} gi,t′={si,t,0,si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr)otherwise ,使模型在训练时保持平衡的专家负载,且性能优于仅依靠辅助损失的模型。
- 互补的序列级辅助损失:为防止单个序列内出现极端不平衡,还采用了互补的序列级平衡损失,通过公式(17) - (20)计算,如 L B a l = α ∑ i = 1 N r f i P i \mathcal{L}_{Bal}=\alpha \sum_{i=1}^{N_{r}} f_{i} P_{i} LBal=α∑i=1NrfiPi ,其中平衡因子 α \alpha α 为极小值,该损失鼓励每个序列上的专家负载平衡。
- 节点受限路由与无令牌丢弃:采用节点受限路由机制,限制每个令牌最多发送到 M M M 个节点,降低通信成本,使MoE训练框架接近全计算 - 通信重叠。同时,由于有效的负载平衡策略,DeepSeek-V3在训练和推理过程中均不丢弃任何令牌。
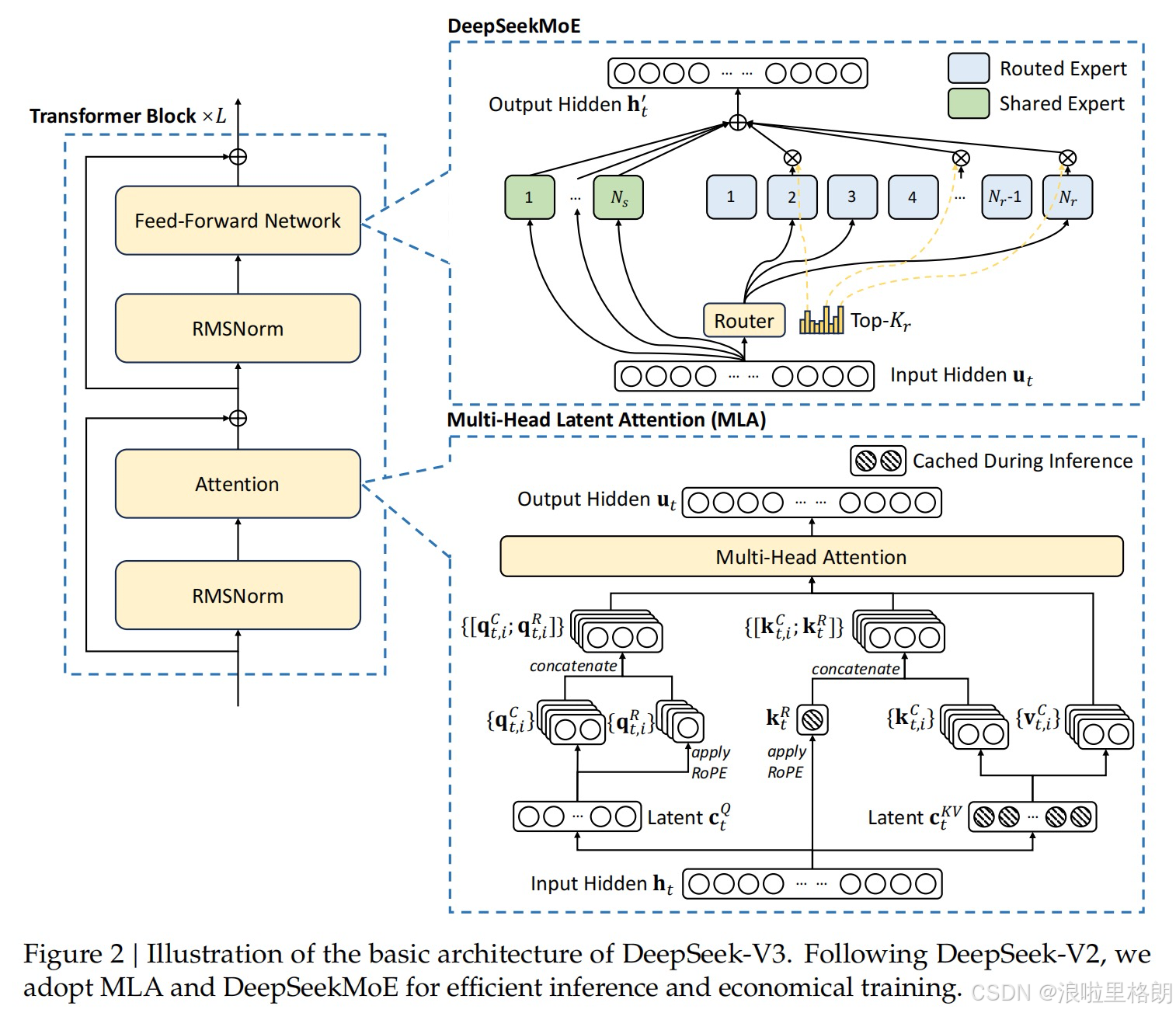
Figure 2展示了DeepSeek-V3的基本架构,包括Multi-Head Latent Attention (MLA)和DeepSeekMoE两部分。Figure 2:DeepSeek-V3基本架构图
- 主要构成:图中展示了Transformer Block、Multi-Head Latent Attention (MLA)、DeepSeekMoE等关键组件。输入Hidden经过MLA处理,其输出再进入由多个Transformer Block组成的模块,之后接入DeepSeekMoE模块,最终输出Hidden。
- 模块作用:MLA旨在实现高效推理,通过对注意力的优化,减少关键值(KV)缓存,提升推理速度;DeepSeekMoE用于实现经济高效的训练,通过引入共享专家和路由专家的设计,提高训练效率并降低成本。这些组件相互协作,共同构成了DeepSeek-V3的基础架构,为模型的性能表现提供支持。
2. Multi-Token Prediction(多令牌预测,MTP):
受启发于相关研究,DeepSeek-V3设置MTP训练目标,通过顺序预测多个未来令牌来增强训练信号,提升模型性能 。
- MTP模块:使用 D D D 个顺序模块预测 D D D 个额外令牌,每个模块包含共享嵌入层、共享输出头、Transformer块和投影矩阵。通过公式(21) - (23)展示了每个模块的计算过程,如 h i ′ k = M k [ R M S N o r m ( h i k − 1 ) ; R M S N o r m ( E m b ( t i + k ) ) ] h_{i}^{\prime k}=M_{k}\left[RMSNorm\left(h_{i}^{k-1}\right) ; RMSNorm\left(Emb\left(t_{i+k}\right)\right)\right] hi′k=Mk[RMSNorm(hik−1);RMSNorm(Emb(ti+k))] 用于结合不同深度的令牌表示和嵌入,最终由共享输出头计算预测概率
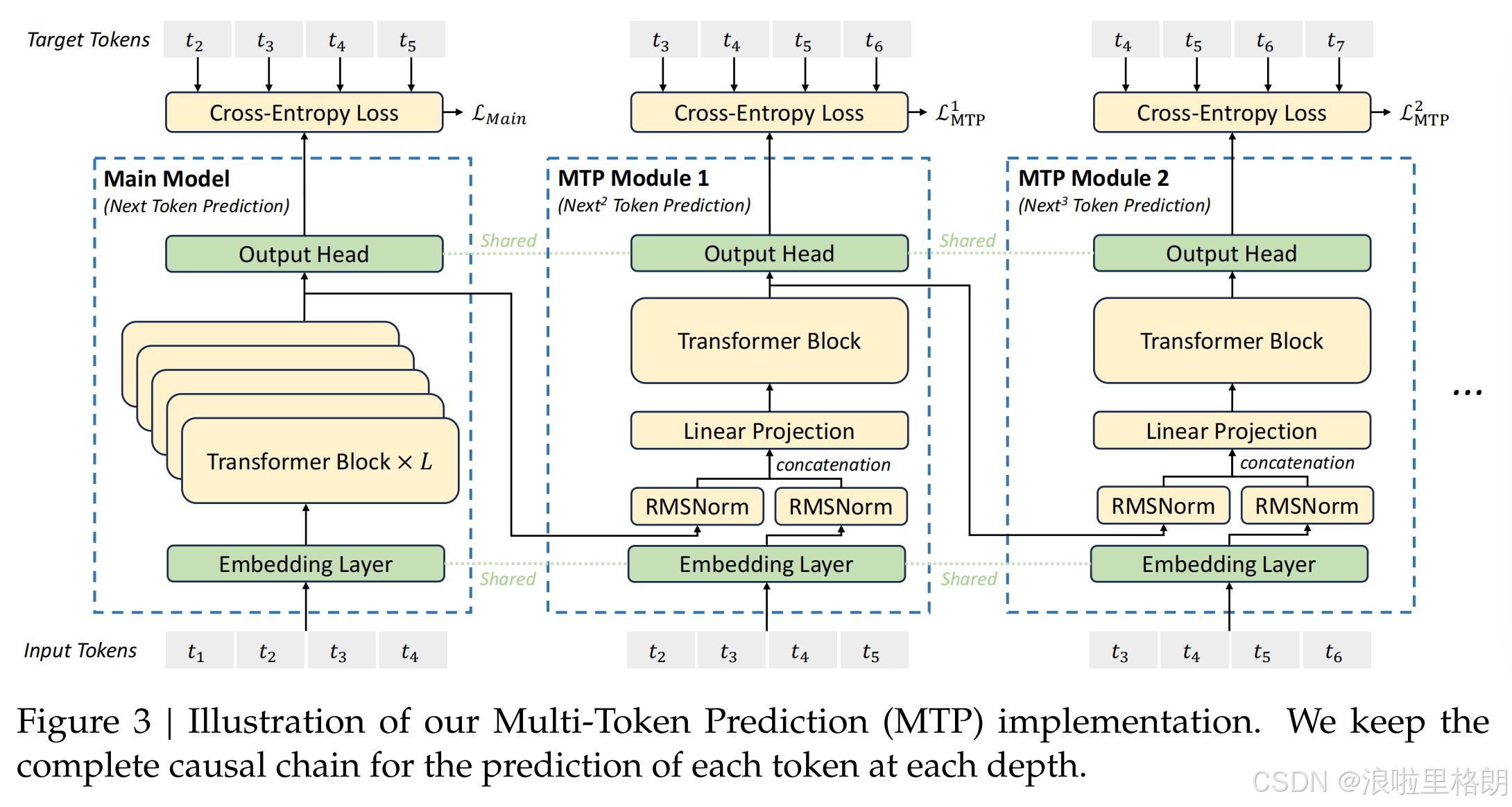
Figure 3则详细说明了模型的Multi-Token Prediction (MTP)实现方式。两张图从不同角度呈现了模型架构的关键信息,有助于深入理解DeepSeek-V3的工作原理。Figure 3:Multi-Token Prediction (MTP)实现图:
- 预测机制:MTP模块基于主模型进行扩展,在每个位置上不仅仅预测下一个令牌,而是扩展到预测多个未来令牌。图中展示了多个MTP模块,如MTP Module 1和MTP Module 2,每个模块负责预测不同位置的后续令牌。
- 优势体现:这种设计通过增加训练信号的密度,提高了数据利用效率,使模型能够更好地规划其表示,从而提升对未来令牌的预测能力,进而增强模型在评估基准上的整体性能。在推理时,MTP模块还可用于推测解码,进一步提高生成速度 。
基础设备
该部分聚焦于DeepSeek-V3训练和部署过程中的基础设施相关内容,涵盖计算集群、训练框架、FP8训练、推理部署及硬件设计建议等方面,通过一系列优化措施提升模型训练和推理效率,降低成本。
- 计算集群:DeepSeek-V3在配备2048个NVIDIA H800 GPU的集群上进行训练。集群内每个节点包含8个通过NVLink和NVSwitch连接的GPU,节点间借助InfiniBand互连,为模型训练提供强大计算能力和高效通信支持。
- 训练框架:基于HAI-LLM框架,采用16路流水线并行(PP)、64路专家并行(EP)跨越8个节点以及ZeRO-1数据并行(DP)的方式。
- DualPipe和计算 - 通信重叠:设计DualPipe算法,将每个计算块细分为注意力、全对全分发、MLP和全对全合并等组件,并在前后向过程中重新安排这些组件,使计算和通信重叠,减少流水线气泡,提升计算 - 通信比,降低通信开销,提升训练效率。该算法在不同PP方法对比中,显著减少了流水线气泡,且内存使用优势明显。
- 高效的跨节点全对全通信实现:定制与MoE门控算法和集群网络拓扑协同设计的跨节点全对全通信内核,充分利用IB和NVLink带宽。通过限制每个令牌最多分配到4个节点,减少IB流量,并采用warp specialization技术动态分配资源,实现通信与计算流的重叠,提高计算资源利用率。
- 极低的内存消耗与最小开销:采用重计算RMSNorm和MLA上投影、在CPU中使用指数移动平均(EMA)以及共享MTP模块和主模型的嵌入层和输出头参数等技术,减少训练过程中的内存占用,且这些操作仅带来极小的额外开销。
- FP8训练:提出用于训练DeepSeek-V3的细粒度混合精度框架,使用FP8数据格式提升训练效率。
- 混合精度框架:多数计算密集型操作采用FP8精度,关键操作保持原数据格式以平衡训练效率和数值稳定性。如线性算子的Fprop、Dgrad和Wgrad的GEMM操作均以FP8执行,可提升计算速度并减少内存消耗;而嵌入模块、输出头、MoE门控模块等则保持较高精度。
- 从量化和乘法改进精度:采用细粒度量化、提高累加精度、统一采用E4M3格式以及在线量化等策略,解决低精度训练中存在的溢出、下溢和精度受限等问题,提高训练精度,使相对损失误差保持在可接受范围内。
- 低精度存储和通信:将缓存激活和优化器状态压缩为低精度格式,如用BF16跟踪优化器的一阶和二阶矩,对特定激活采用定制的低精度格式存储,并在通信前对激活进行量化,减少内存消耗和通信开销。
- 推理与部署:在H800集群上部署,将推理过程分为预填充和解码阶段,以满足在线服务的性能目标并提高吞吐量。
- 预填充:最小部署单元包含4个节点和32个GPU,采用特定的并行策略。为实现负载均衡,引入冗余专家部署策略,并动态调整专家分配。此外,通过同时处理两个微批次数据,重叠注意力和MoE计算与分发、合并操作,提高吞吐量。
- 解码:最小部署单元包含40个节点和320个GPU,采用不同的并行策略。同样通过冗余专家部署实现负载均衡,并探索同时处理两个微批次数据的方式,以隐藏通信开销。在解码阶段,根据专家负载情况动态调整专家冗余,并优化计算全局最优路由方案的算法。
- 硬件设计建议:基于模型训练和通信的实践经验,对AI硬件设计提出建议。
- 通信硬件:当前通信实现依赖SMs,限制了计算吞吐量且效率低下。建议开发硬件卸载通信任务,统一IB和NVLink网络接口,简化应用编程复杂度,提高通信效率。
- 计算硬件:
训练
论文的4. Pre-Training和5. Post-Training部分分别介绍了DeepSeek-V3模型的预训练和后训练过程。预训练通过优化数据、调整超参数等提升模型基础能力;后训练则通过监督微调、强化学习等方式,使模型更符合人类偏好,进一步提升性能。
Pre-Training(预训练)
- 数据构建:优化预训练语料库,增加数学和编程样本比例,扩展多语言覆盖范围,减少冗余并保持多样性。采用文档打包方法但不使用交叉样本注意力掩码,使用Byte - level BPE分词器并扩展词汇表至128K。为解决新分词器可能引入的偏差问题,训练时随机拆分部分组合令牌。此外,还引入Fill-in-Middle(FIM)策略,以提升模型预测中间文本的能力。
- 超参数设置:设定模型超参数,包括61层Transformer层、7168的隐藏维度等,以及训练超参数,如使用AdamW优化器,设置特定的学习率调度、梯度裁剪规范、批次大小调度等,还对辅助损失-free负载平衡、平衡损失和MTP损失权重等参数进行设置。
- 长上下文扩展:采用与DeepSeek-V2相似的方法,应用YaRN进行上下文扩展,分两个阶段将上下文窗口从4K逐步扩展到128K,每个阶段设置特定的序列长度、批次大小和学习率。经扩展训练后,模型在处理长文本输入时性能良好,在“Needle In A HayStack”测试中表现出色。
- 评估:使用内部评估框架,在多种基准测试数据集上评估模型性能,涵盖多学科选择题、语言理解与推理、闭卷问答等多个领域。结果显示,DeepSeek-V3-Base在多数基准测试中表现最佳,超越了其他开源模型,如DeepSeek-V2-Base、Qwen2.5 72B Base和LLaMA-3.1 405B Base。
- 讨论:通过消融实验验证了MTP策略和无辅助损失平衡策略的有效性。MTP策略在多数评估基准上提升了模型性能;无辅助损失平衡策略相比基于辅助损失的方法,在多数基准测试中表现更优。同时,分析了批级负载平衡和序列级负载平衡的差异,发现批级负载平衡具有更大的灵活性,有利于专家在不同领域进行专业化,但也面临一些效率挑战。
Post-Training(后训练)
- 监督微调(Supervised Fine-Tuning):整理包含150万个实例的指令调优数据集,涵盖多个领域。推理数据借助内部DeepSeek-R1模型生成并处理,非推理数据由DeepSeek-V2.5生成并经人工验证。使用余弦衰减学习率调度对DeepSeek-V3-Base进行两个epoch的微调,训练时采用样本掩码策略。
- 强化学习(Reinforcement Learning)
- 奖励模型:采用基于规则和基于模型的奖励模型。对于可通过特定规则验证的问题,使用规则基奖励系统;对于答案形式自由或无确定答案的问题,使用基于模型的奖励模型,并通过构建包含推理过程的偏好数据来训练,以提高其可靠性。
- Group Relative Policy Optimization:采用Group Relative Policy Optimization(GRPO)算法,通过从旧策略模型采样输出并优化策略模型,使模型更符合人类偏好,提升在基准测试中的性能,尤其是在监督微调数据有限的场景中。
- 评估:在多种基准测试上评估指令模型,包括新的基准测试如IFEval、FRAMES等,并与多个强基线模型进行对比。DeepSeek-V3在多数任务中表现出色,是性能最佳的开源模型,且与前沿闭源模型(如GPT-4o和Claude-3.5-Sonnet)相比也具有竞争力。在一些任务中,如数学和编码相关基准测试,DeepSeek-V3展现出卓越的性能。
- 讨论:分析了从DeepSeek-R1蒸馏知识的效果,发现其能提升模型性能,但会增加平均响应长度,因此在DeepSeek-V3中需谨慎选择蒸馏设置。
实验结果
论文5.3节主要围绕DeepSeek-V3模型的评估展开,其中Table 6到Table 9提供了关键的评估数据,从不同角度展示了模型的性能表现。这些表格通过对比不同模型在多种基准测试中的结果,为全面评估DeepSeek-V3的性能提供了依据。
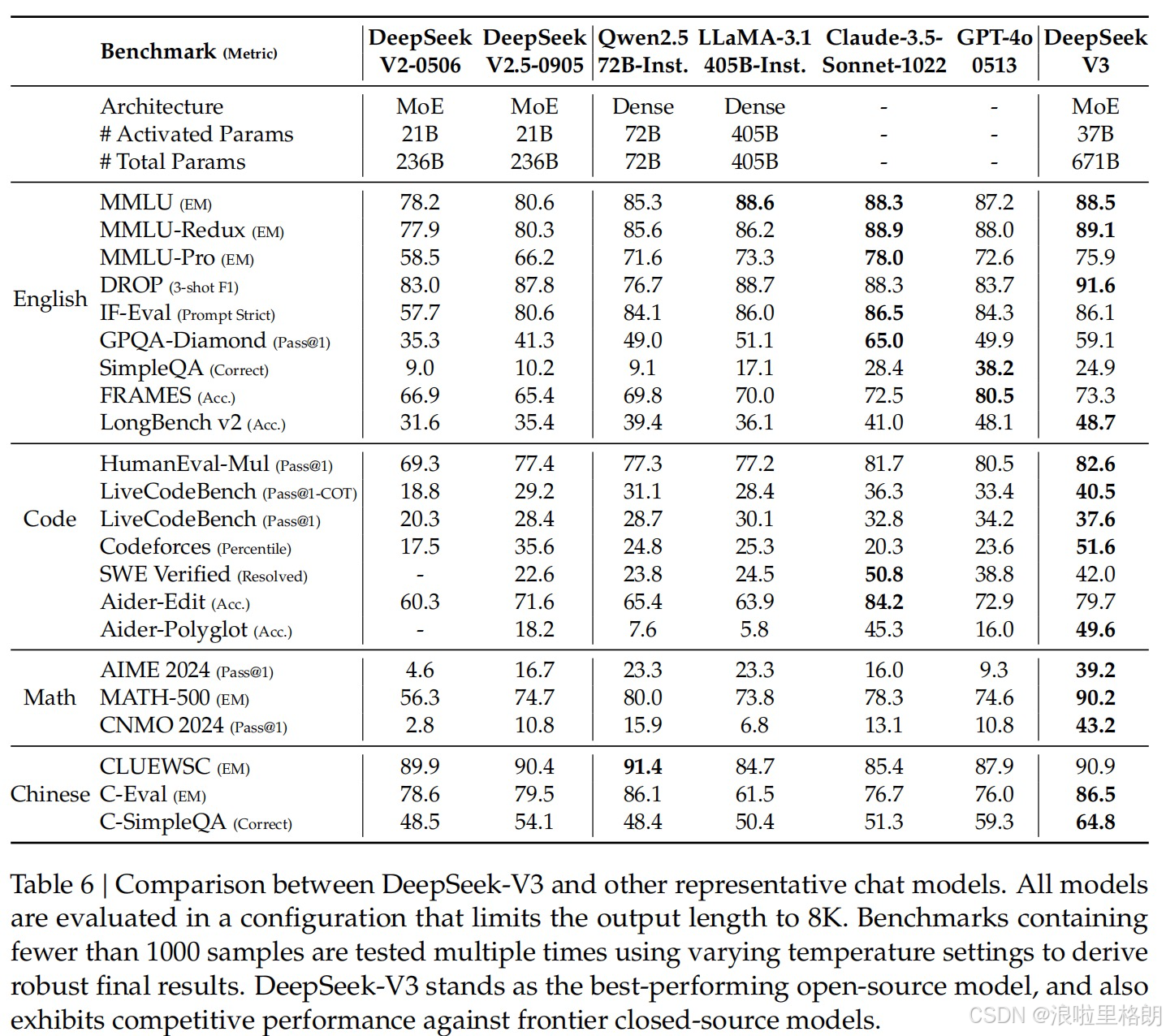
- Table 6:DeepSeek-V3与其他代表性聊天模型的比较
- 对比模型:包括DeepSeek-V2-0506、DeepSeek-V2.5-0905、Qwen2.5 72B Instruct、LLaMA-3.1 405B Instruct、Claude-Sonnet-3.5-1022和GPT-4o-0513等。
- 评估指标:涵盖多个领域的基准测试,如MMLU、DROP、GPQA等,涉及不同知识领域和任务类型。
- 结果分析:DeepSeek-V3在多数任务上表现出色,是性能最佳的开源模型,且与前沿闭源模型相当。在MMLU等知识评估任务中,DeepSeek-V3与顶尖模型表现相当,在MMLU-Pro等更具挑战性的基准测试中也表现优异;在长上下文理解任务如DROP和FRAMES中,DeepSeek-V3表现突出;在编码和数学任务中,DeepSeek-V3在算法任务上超越所有基线模型,在数学任务上显著优于其他模型,展现了强大的数学推理能力;在中文基准测试中,DeepSeek-V3在部分任务上表现出色,如在Chinese SimpleQA上超越Qwen2.5-72B。
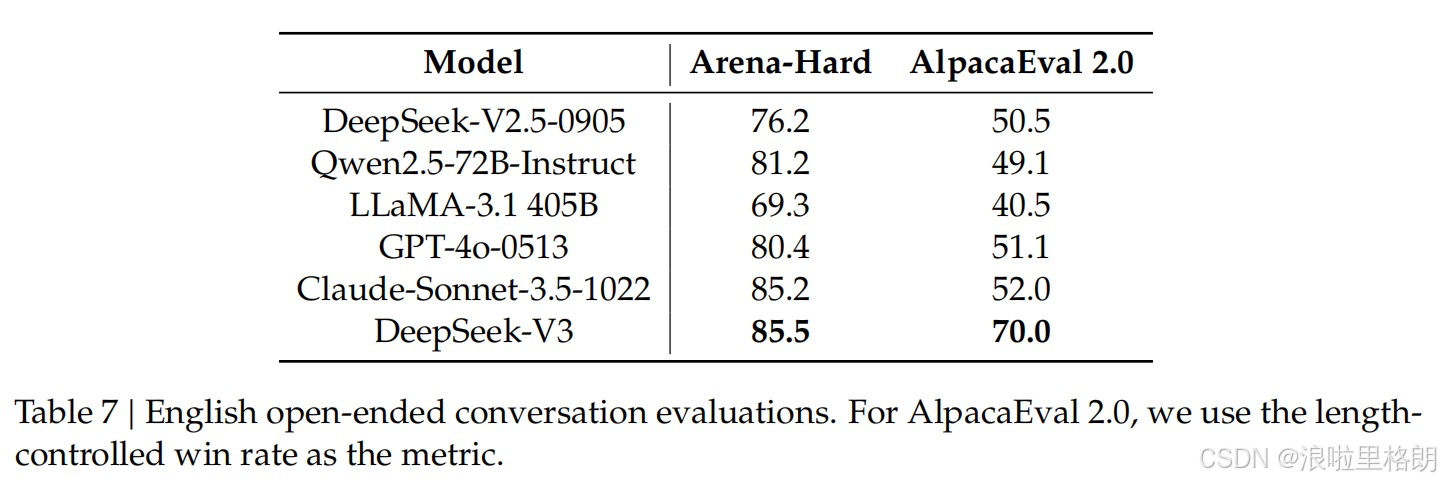
- Table 7:英文开放式对话评估
- 评估基准:采用AlpacaEval 2.0和Arena-Hard,使用GPT-4-Turbo-1106作为评判模型进行两两比较。
- 评估指标:AlpacaEval 2.0使用长度控制的胜率作为指标,Arena-Hard直接以胜率衡量。
- 结果分析:DeepSeek-V3在Arena-Hard上取得了超过86%的胜率,与顶尖模型Claude-Sonnet-3.5-1022表现相当,且是首个在该基准上超过85%胜率的开源模型;在AlpacaEval 2.0上,DeepSeek-V3也优于其他开源和闭源模型,比DeepSeek-V2.5-0905有显著提升,展示了其在写作任务和简单问答场景中的出色能力。
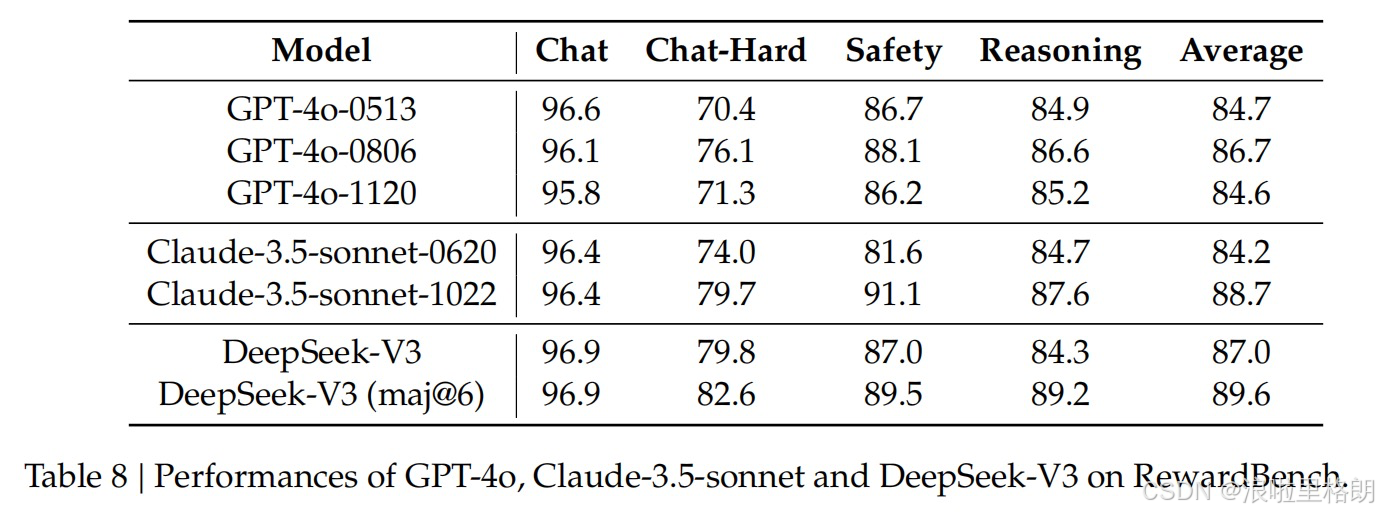
- Table 8:GPT-4o、Claude-3.5-sonnet和DeepSeek-V3在RewardBench上的性能表现
- 评估基准:RewardBench用于评估模型的奖励模型性能。
- 评估指标:涵盖Chat、Chat-Hard、Safety、Reasoning等多个类别,并给出平均得分。
- 结果分析:DeepSeek-V3的表现与GPT-4o-0806和Claude-3.5-Sonnet-1022的最佳版本相当,且超过了其他版本。通过投票技术,DeepSeek-V3的判断能力还能进一步增强,可用于为开放式问题提供自我反馈,提升对齐过程的有效性和鲁棒性。
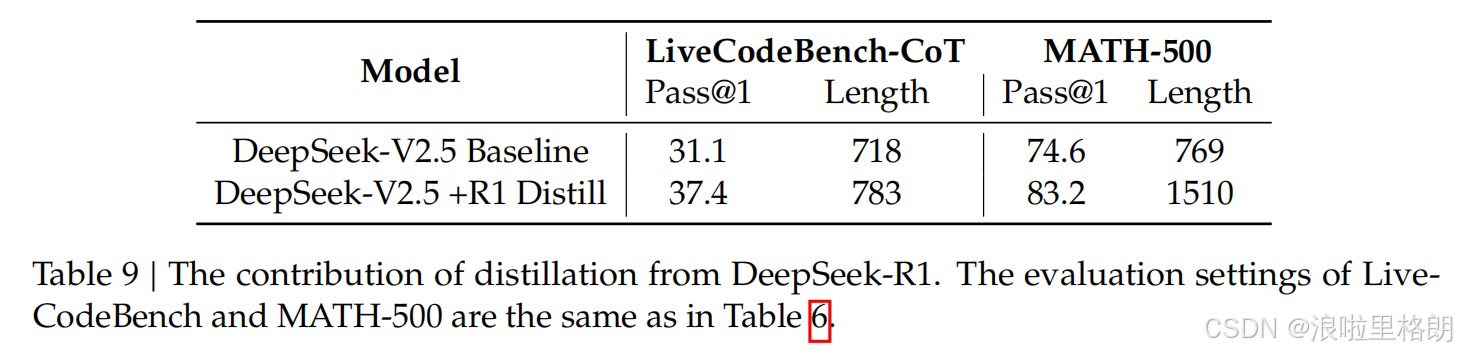
- Table 9:DeepSeek-R1知识蒸馏的贡献
- 对比模型:基于DeepSeek-V2.5,对比在短CoT数据上训练的基线模型和使用专家检查点生成数据的模型。
- 评估指标:在LiveCodeBench和MATH-500基准测试中,以Pass@1和Length为指标。
- 结果分析:从DeepSeek-R1蒸馏的数据显著提升了模型在LiveCodeBench和MATH-500基准测试中的性能,但也导致平均响应长度大幅增加。这表明在应用知识蒸馏时,需要在模型精度和计算效率之间进行权衡,以选择最优设置。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)