利用ollama部署deepseek简述
deepseek官方也提供了本地部署教程,但是相对复杂,本文采用ollama快速部署一个本地模型目前在线有大量的模型可以使用,那么为什么还需要本地部署?核心原因包含如下几个:免费使用:本地部署无需对模型付费(当然部署的资源除外)数据隐私:本地部署整个的训练、使用、交互等都在本地私有空间,可以充分保护数据隐私限制少:在线模型因为内容安全、合规等问题存在较多限制和审核,本地部署取决于个人训练和数据源,
deepseek官方也提供了本地部署教程,但是相对复杂,本文采用ollama快速部署一个本地模型
1、为什么选择本地部署
目前在线有大量的模型可以使用,那么为什么还需要本地部署?核心原因包含如下几个:
免费使用:本地部署无需对模型付费(当然部署的资源除外)
数据隐私:本地部署整个的训练、使用、交互等都在本地私有空间,可以充分保护数据隐私
限制少:在线模型因为内容安全、合规等问题存在较多限制和审核,本地部署取决于个人训练和数据源,限制相对少
无需网络依赖:本地部署完全可以在本地运行、使用、调试,无需连接互联网(需要用到联网插件、互联网服务等除外)
灵活定制:可以根据个人的使用目标,进行灵活的调试、调优、修改;同时根据不同的使用场景选择不同的数据集进行训练
性能和效率:本地部署无需和云端做交互(特定场景除外),不存在访问限制、资源限制,通常使用效率高;同时资源独占,且可以根据需求调整配置,相对性能更好
2、如何部署
因为本地部署需要大量资源,特别是部署大参数量如deepseek满血版;满血版参数量为671B,6710亿的参数量,按照单精度浮点数(float32)评估:
显存占用:
每个参数占用4字节(32/8),6710亿参数占用:6710*4B*=26840GB=26.8TB
训练过程的过程占用和缓存,通常比参数占用更多,如2-3倍,若按3倍计算,则占用80.4TB
在推理过程不同的模型占用的显存也存在差异,从百分之几到百分之几十都有可能,若按照10%考虑,大概为8TB
总体的显存需求仅90TB,另外考虑到环境损耗,若按照15%考虑,则最终需求为106TB
内存占用:
训练过程6710亿参数大约需要1TB及以上;推理过程大约需要256GB及以上;通常需要至少1.2TB内存
综上所属,本地部署6710亿参数的deepseek至少需要1.2TB内存,及双卡H100 80GB
但是在个人电脑尝试部署distill(蒸馏)版本的也可以运行,以下使用ollama部署distill版本的步骤,供参考:(以部署DeepSeek-R1-Distill-Qwen-1.5B为例)
第一步:去allama官网下载工具
https://ollama.com/download
选择对应系统的版本,本次选择Mac系统对应的版本

下载后直接安装即可,安装后进入命令行,可以查看版本
ollama -v
 同时ollama会监听本地的11434端口,可以浏览器访问:localhost:11434
同时ollama会监听本地的11434端口,可以浏览器访问:localhost:11434
确认安装没问题后,下一步运行需要的模型(本次以deepseek-r1:1.5b为例),可以在 https://ollama.com/search 查看:
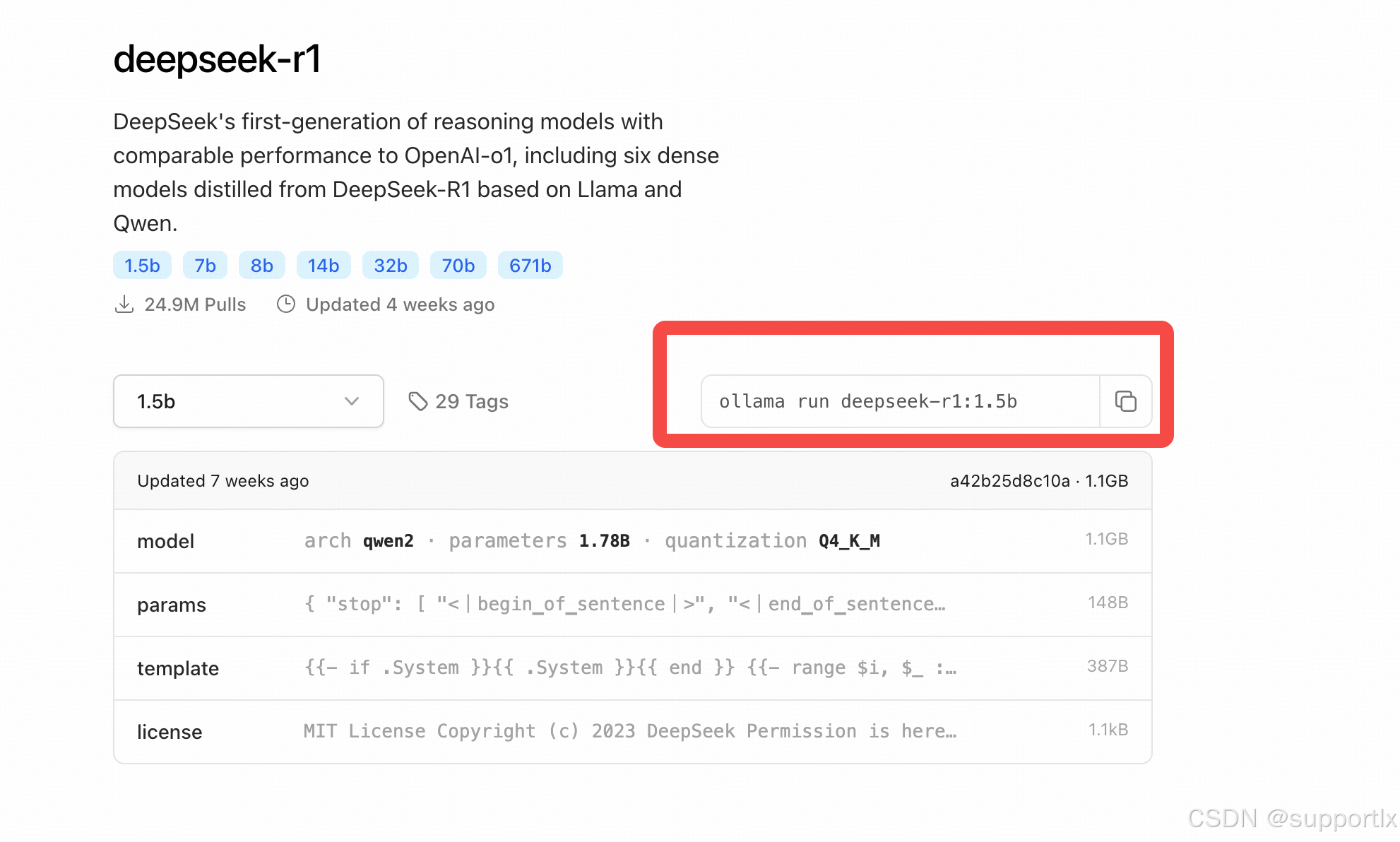
详情也也可以看到各个蒸馏版本:
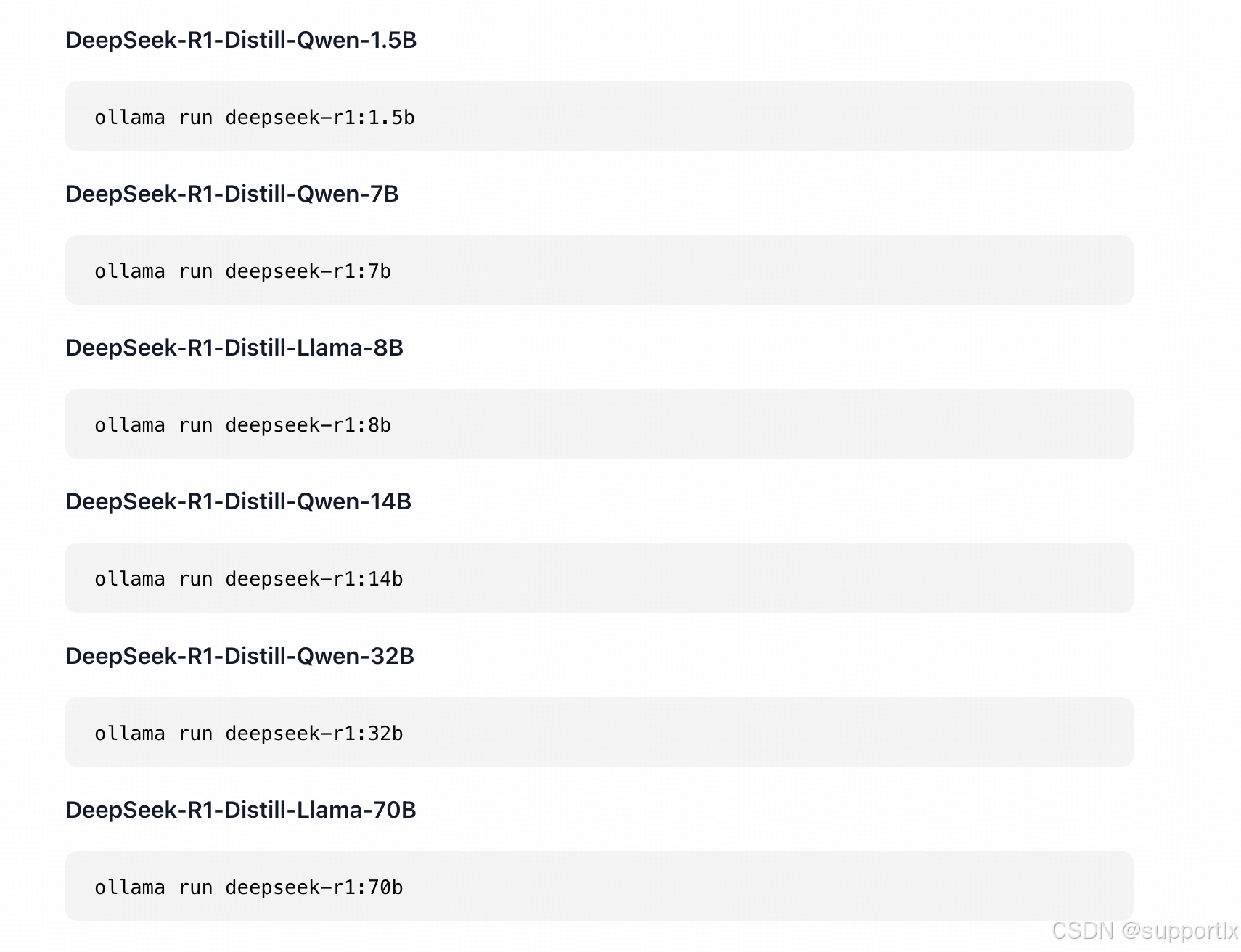
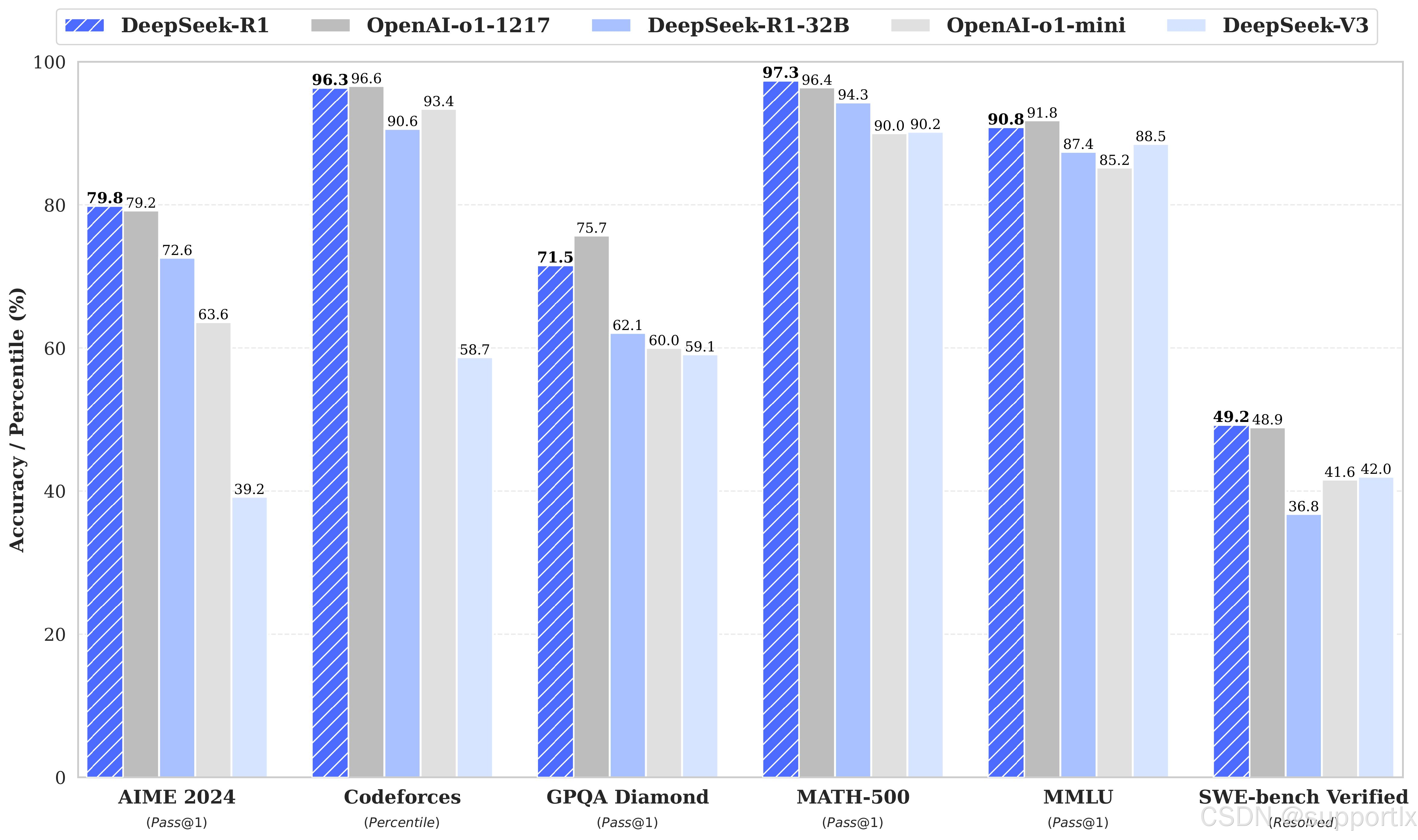
复制运行命令:

至此,基础安装已经完成,通过ollama部署基础模型还是相对简单。但是通过以上部署,整个的交互体验比较差、且效果差

3、交互体验优化
上一章节已经完成基础模型部署,但是交互体验比较差,本章节通过部署Chatbox,通过ollama+Chatbox来实现友好交互
chatbox是一款开源的AI客户端,可以直接在官网下载:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
下载之后直接安装:
 安装后打开客户端进行配置,选择使用自己的API key或本地模型配置
安装后打开客户端进行配置,选择使用自己的API key或本地模型配置

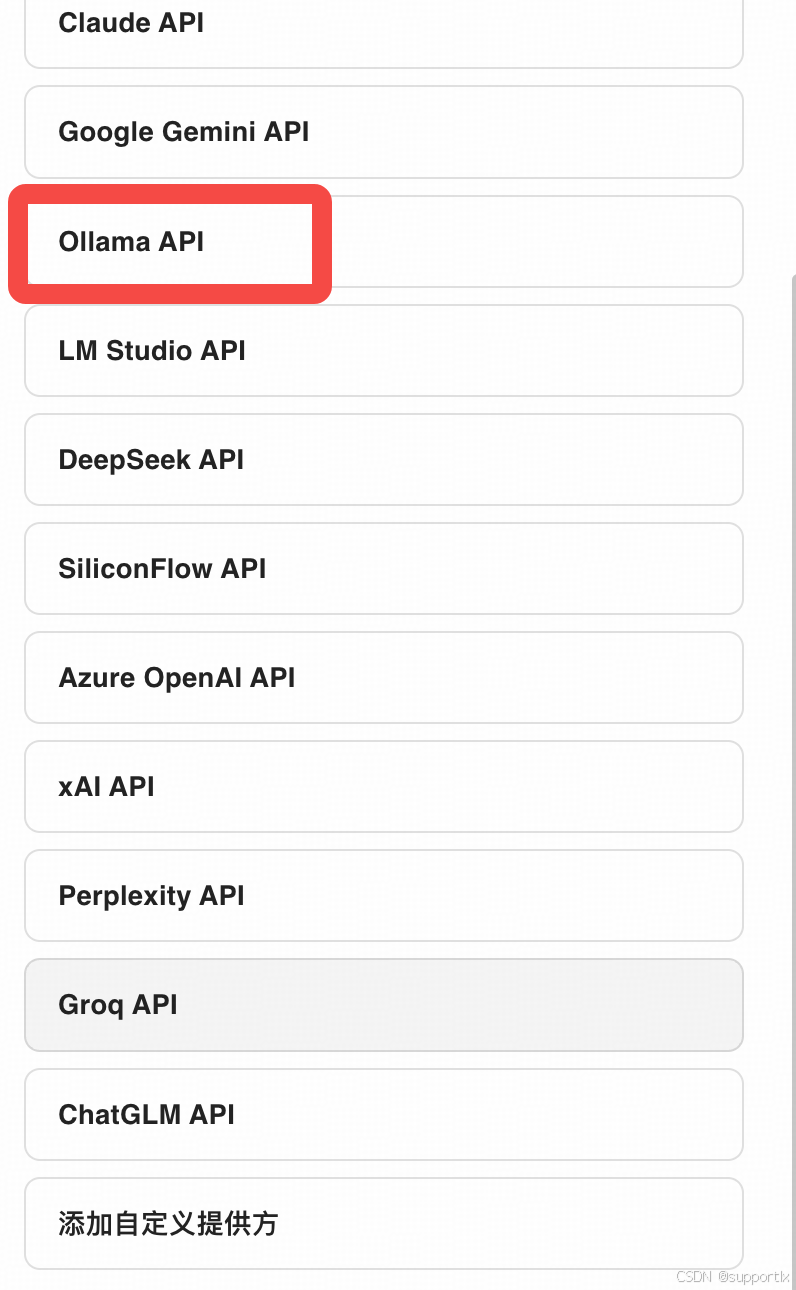
选择ollama API:
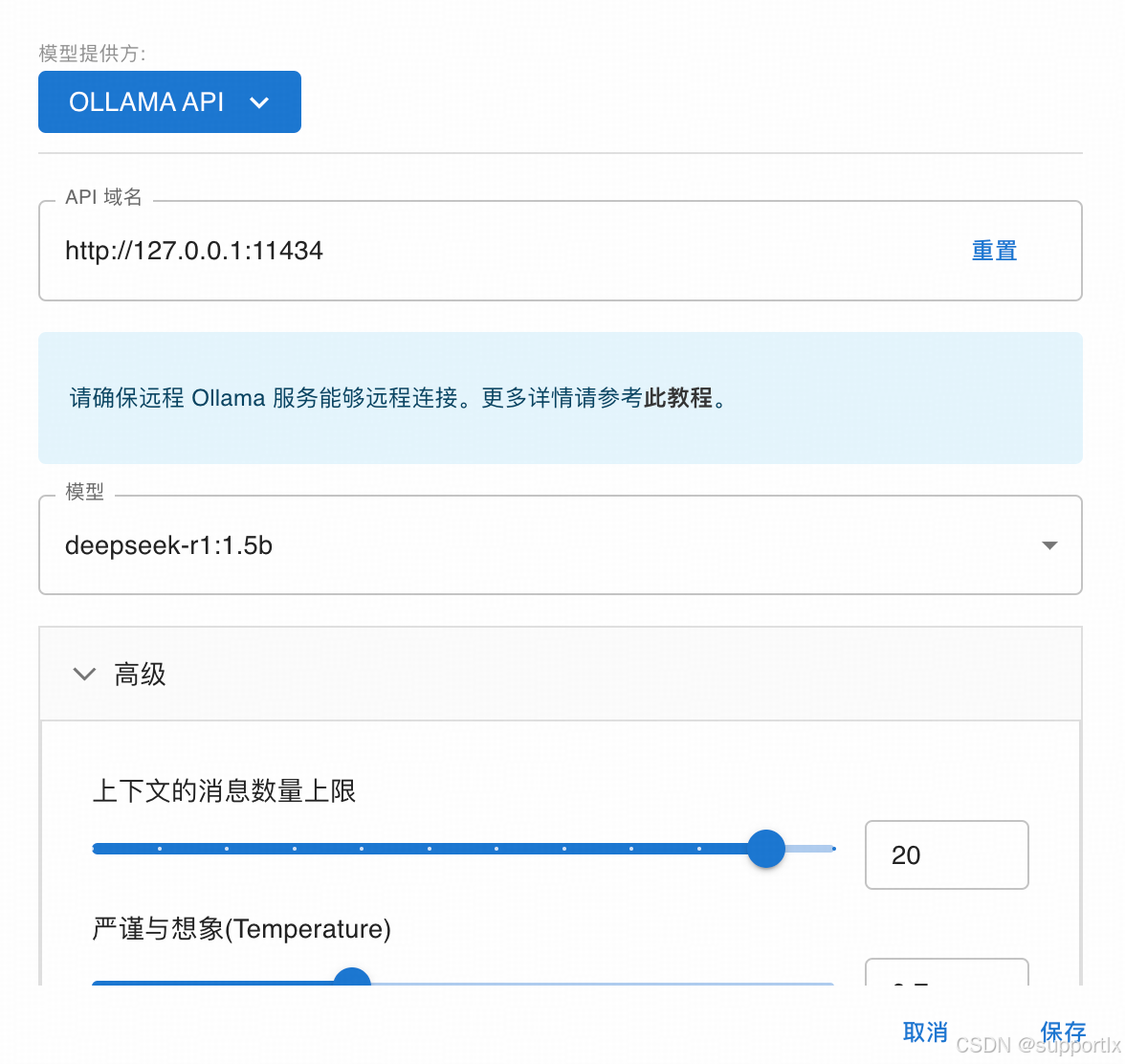
 进行其它参数配置:
进行其它参数配置:
 配置后一个客户端就出现了:
配置后一个客户端就出现了:
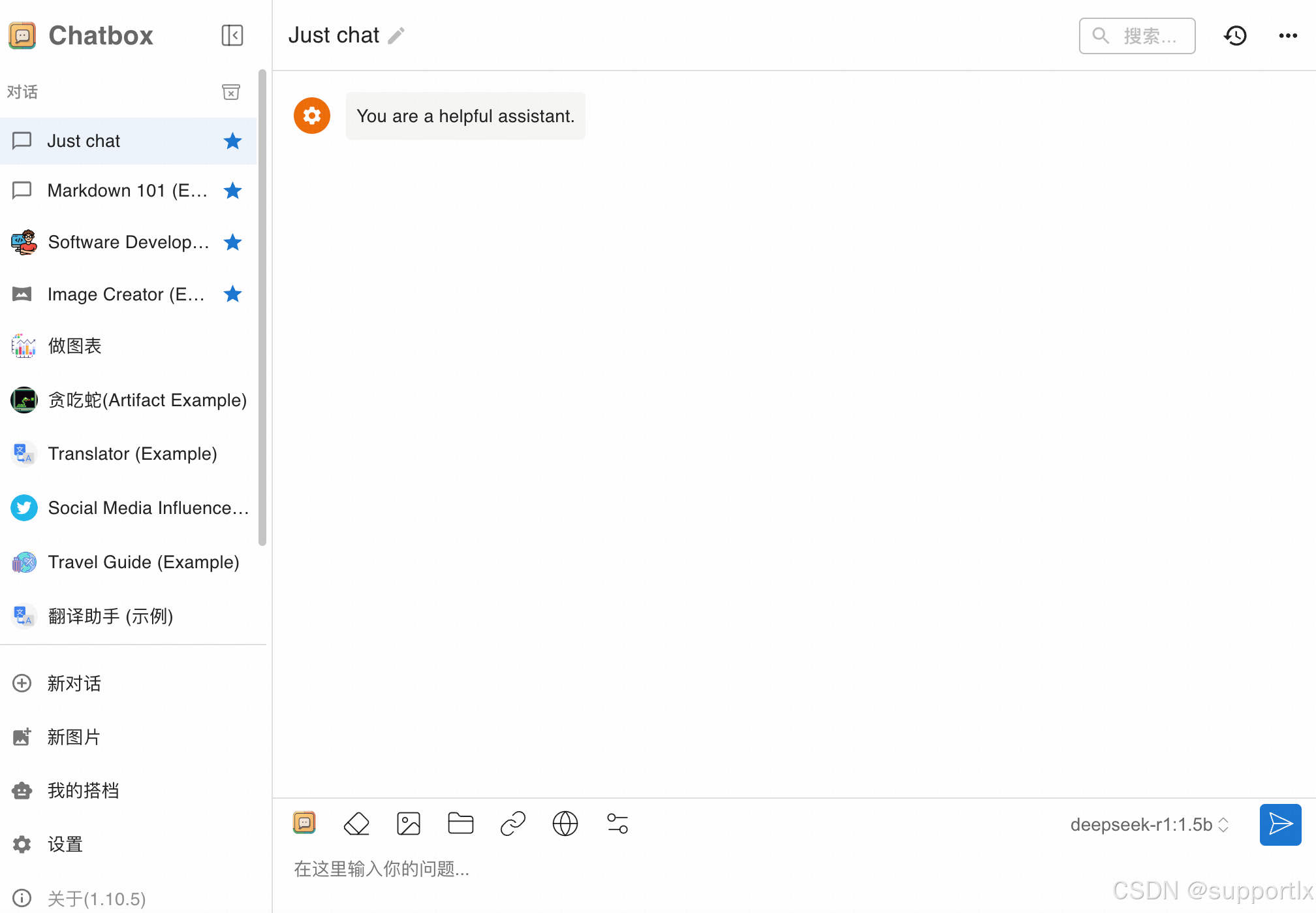
可以正常进行交互:
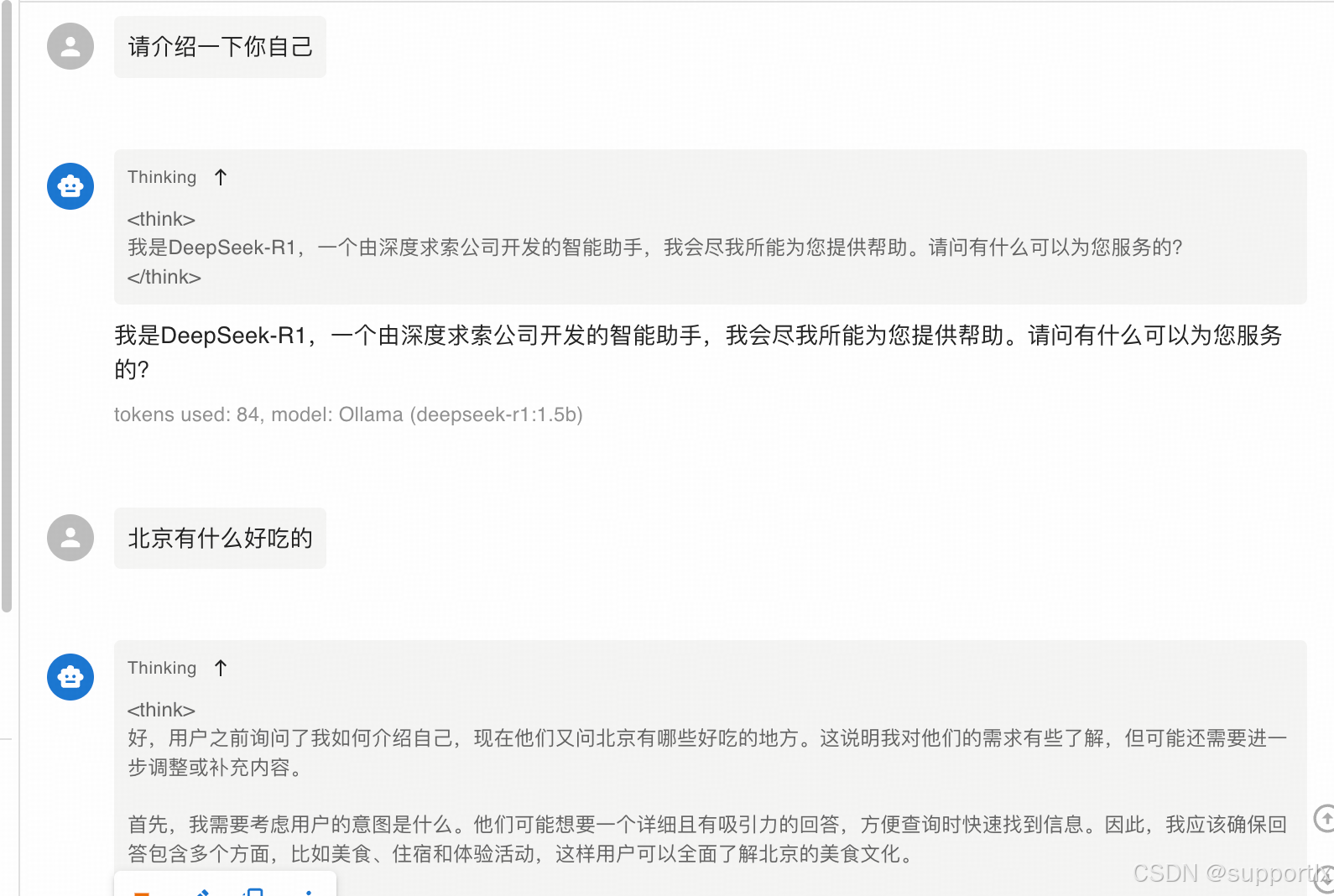
chatbox工具还有很多能力可以开发,如直接体验在线模型;有需要的伙伴可以自行开发。
4、效果优化
前面章节完成了模型部署及交互优化,但是在使用效率上还有很多可以优化的点,本章节针对部分优化项进行简述
4.1 通过page assist+ollama实现本地模型联网
page assist是一个开源的浏览器扩展程序,官网对其介绍如下:https://chromewebstore.google.com/detail/page-assist-%E6%9C%AC%E5%9C%B0-ai-%E6%A8%A1%E5%9E%8B%E7%9A%84-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo?hl=zh-cn

下载后进行设置添加:
配置扩展程序,打开联网搜索:
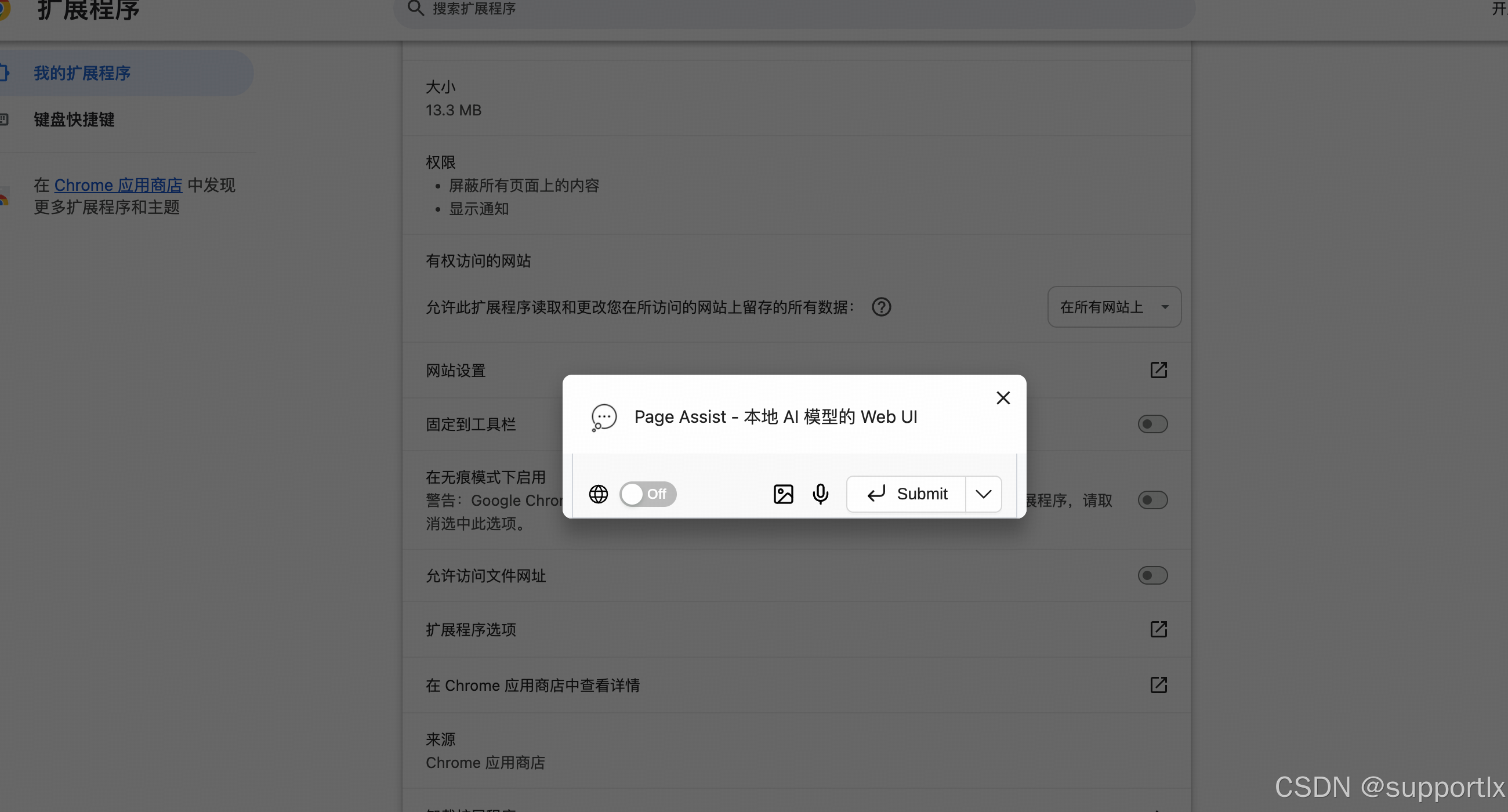
以上配置为开启联网搜索;

4.2 使用anything LLM+ollama打通本地知识库
RAG的理论知识在此不做过多介绍,有兴趣的同学可以单独了解;本次通过anything LLM工具来打通本地知识库:
AnythingLLM | The all-in-one AI application for everyone
直接下载对应版本:
下载后进行安装:

然后进行配置,会自动进行识别:
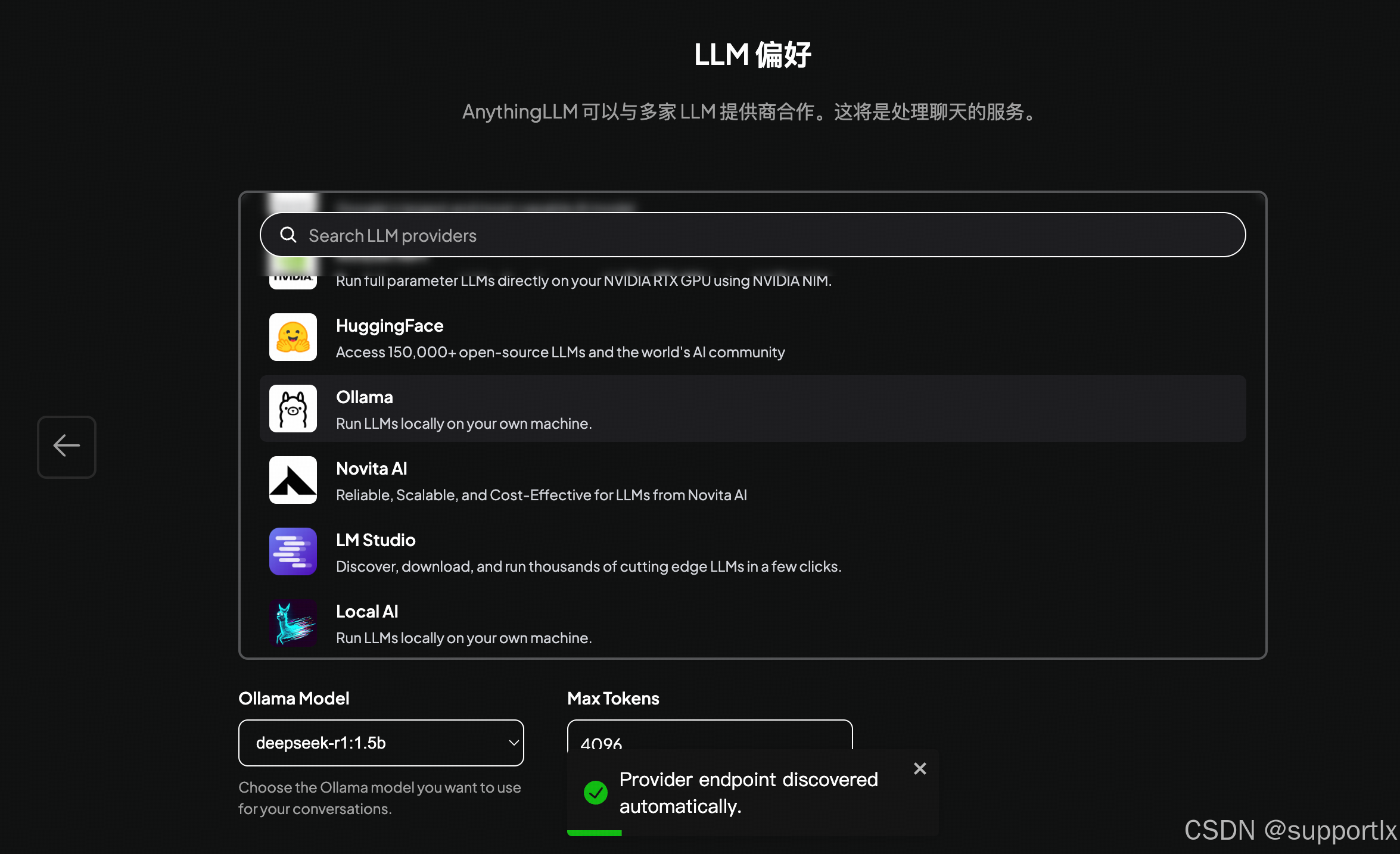
检查识别是否有误:
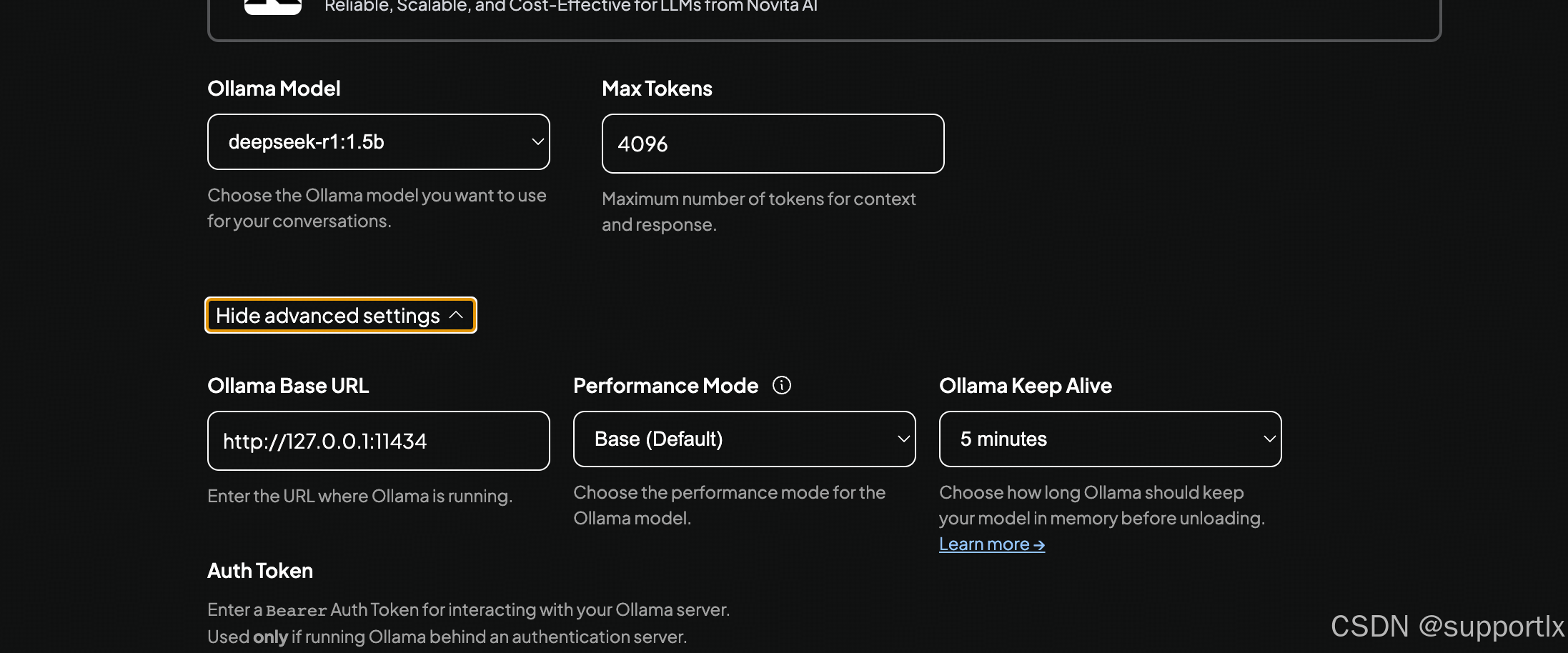
进行embedding模型和vector数据库配置,之后确认选项
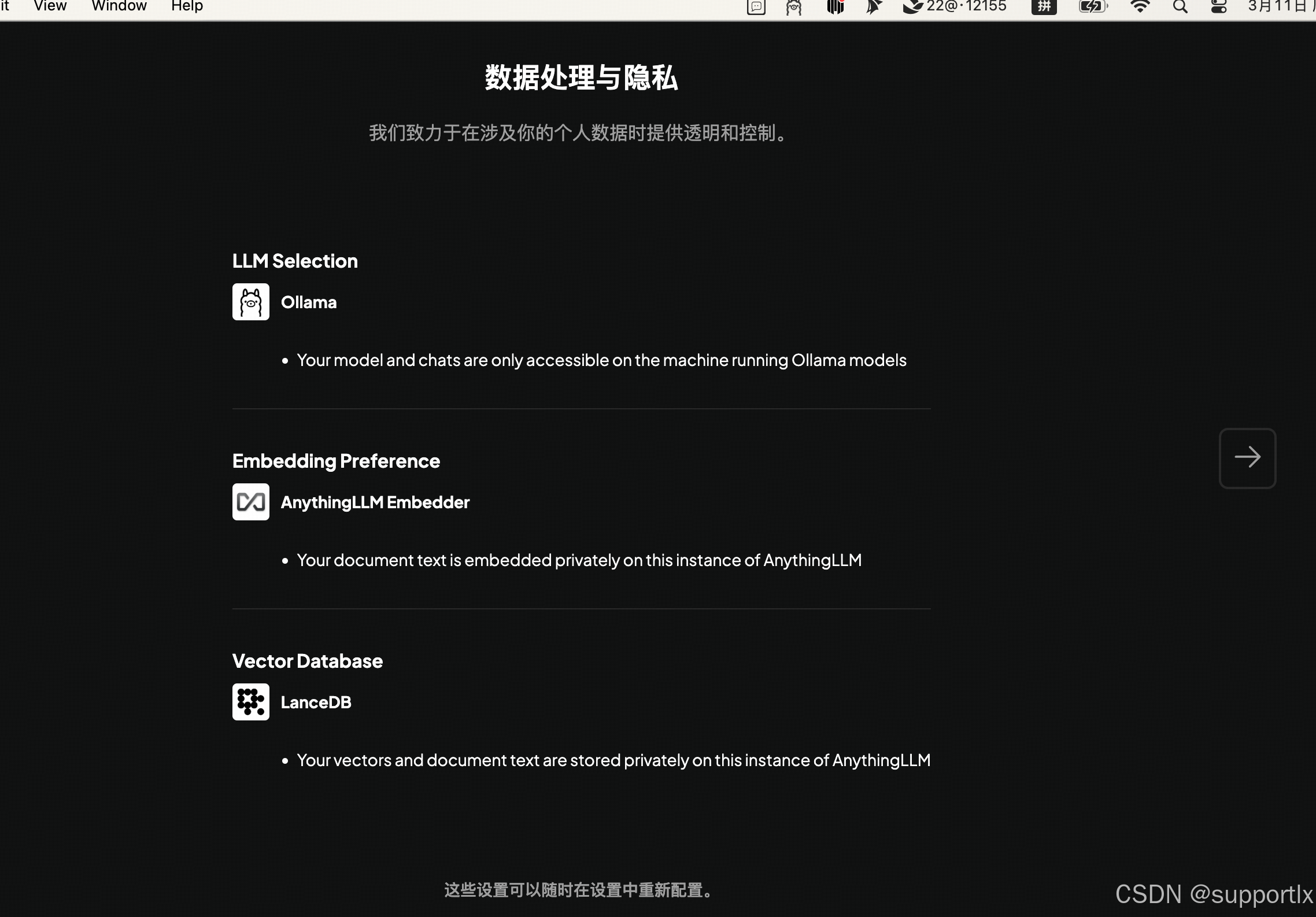
下一步,设置工作区,可以在不同工作区设置不同知识库
设置完成后有一些引导语,同时也可以去修改我们的embedding和vector配置
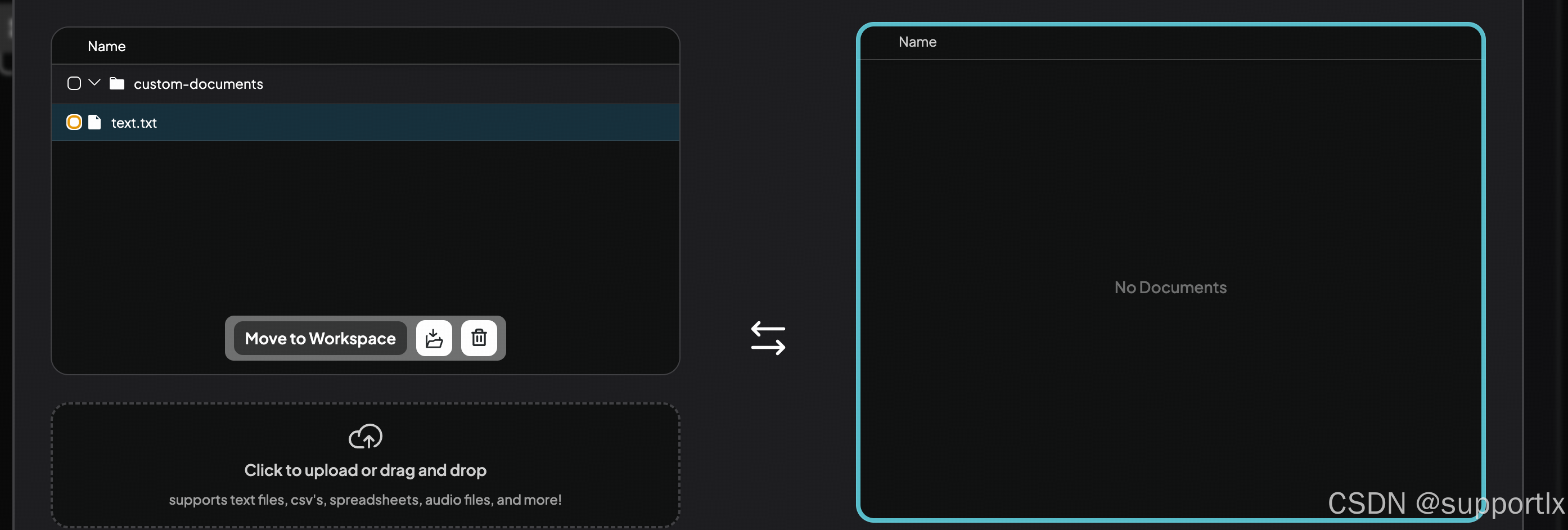
配置后,找到工作区,上传知识库:

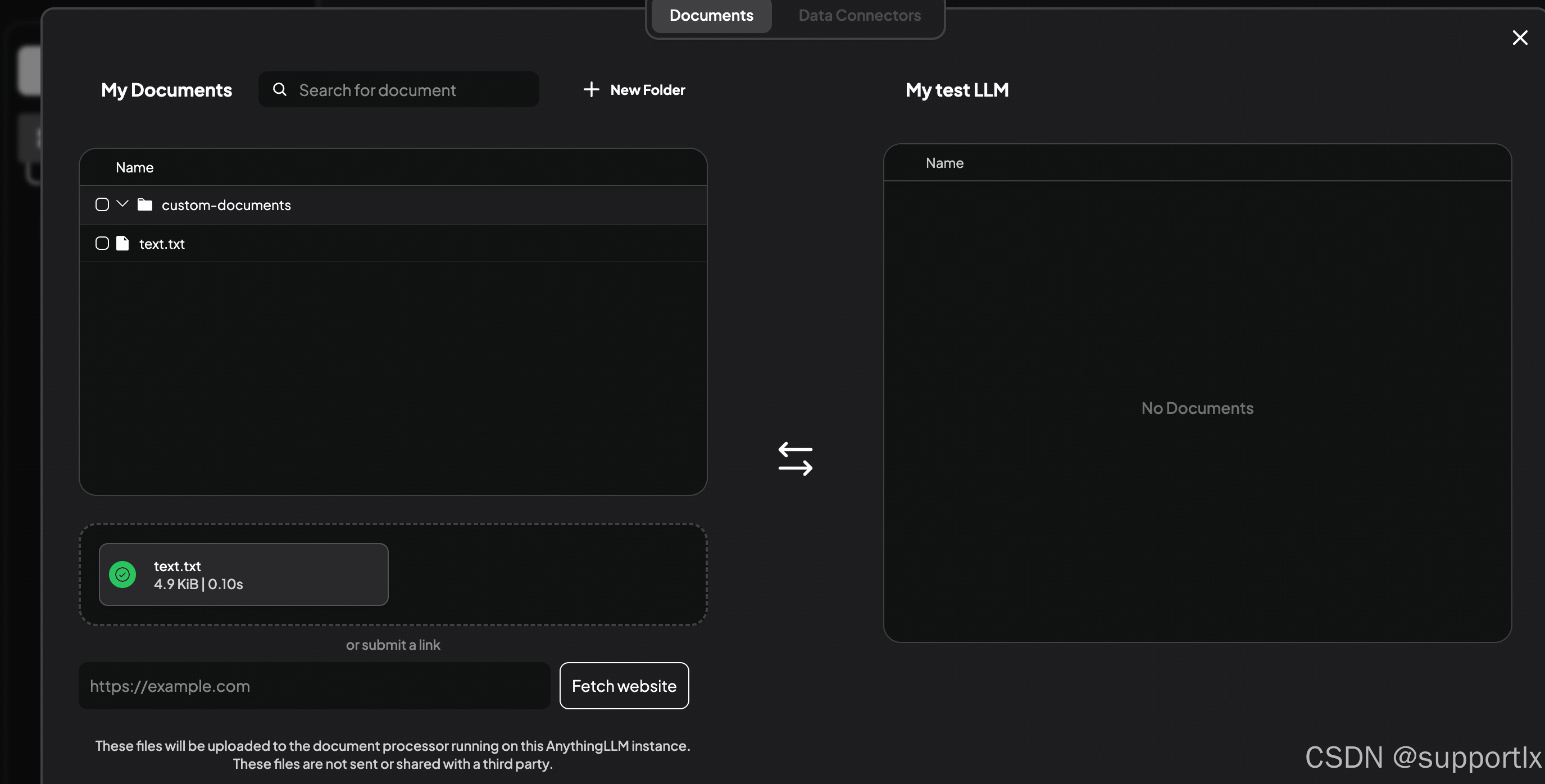
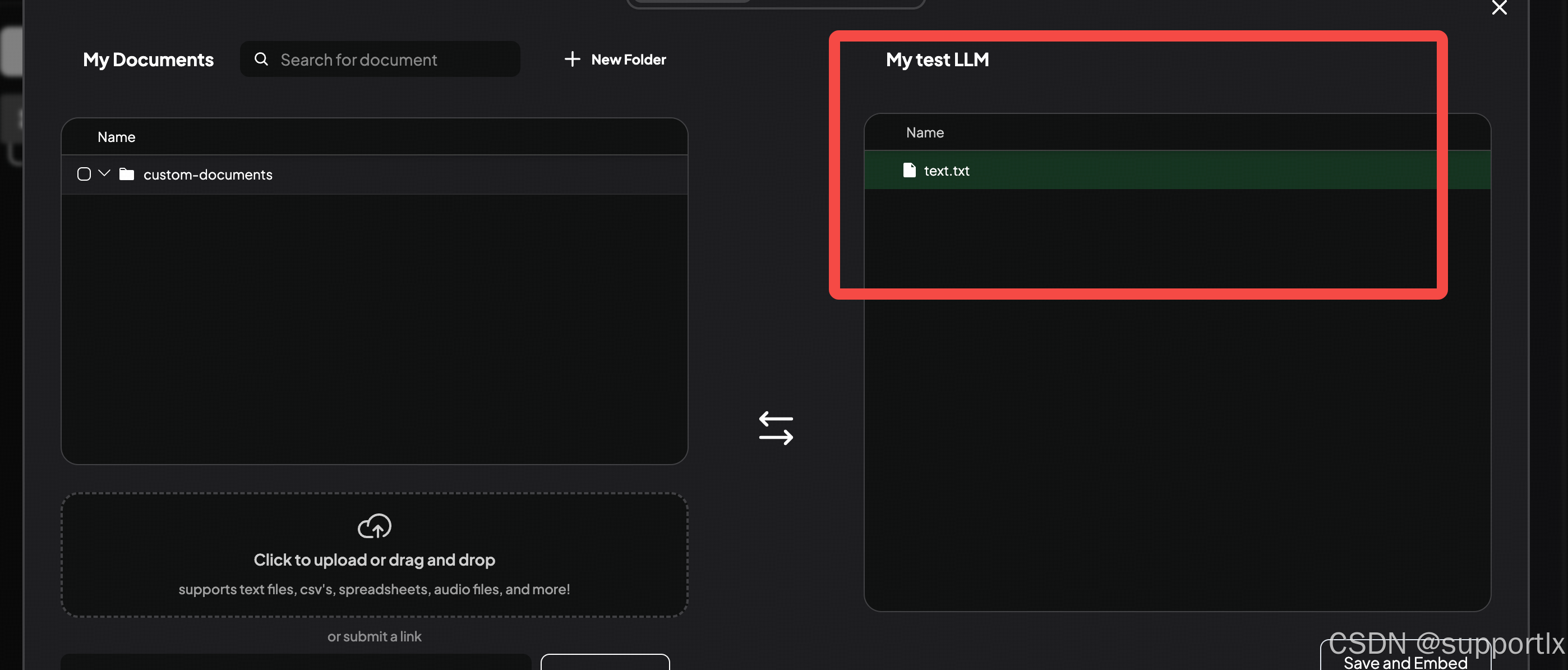
注意:需要移动到对应的工作区:
配置完成后可以进行测试

同时也可以以网页的形式添加知识库,添加后也可以测试效果
注意:anything LLM的两个核心概念
workspace:一个独立的环境,用与存储和管理特定主题的文件和数据,用户可以单独设置,每个工作区相互独立;
thread:工作区中一次对话的记录
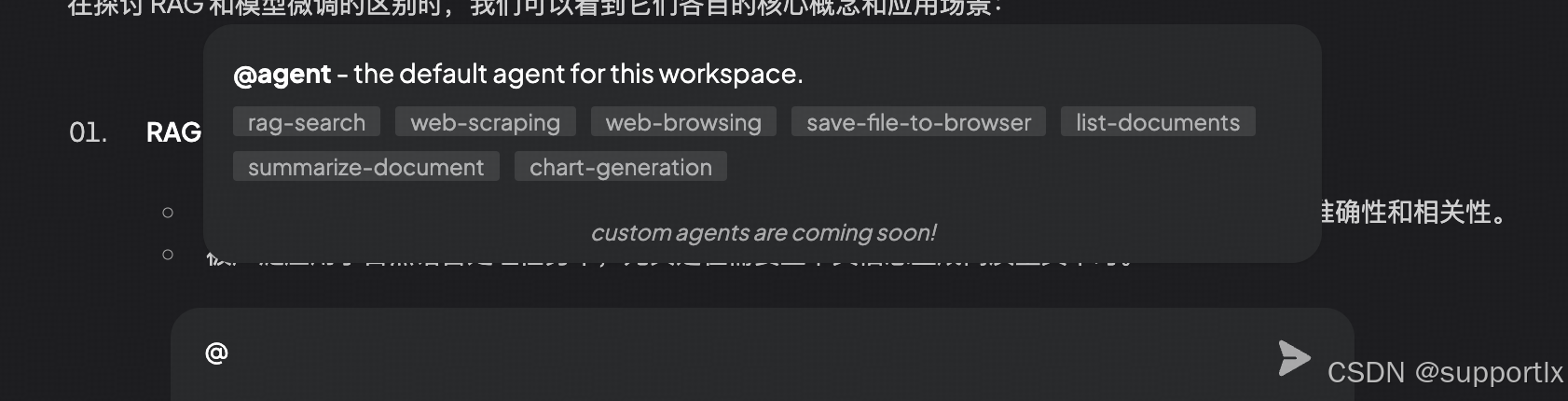
anything LLM是一个非常强大的工具,也值得单独研究,且通过@就能调起很多工具:
最后希望能给大家带来一定的帮助,有更好的工具也欢迎一起探讨!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)