DeepSeek昇腾部署技术问题FAQ
在进行DeepSeek昇腾部署时,你是否遇到了问题?本文汇总了常见问题,助你快速定位并迅速部署DeepSeek。
在进行DeepSeek昇腾部署时,你是否遇到了问题?本文汇总了常见问题,助你快速定位并迅速部署DeepSeek。欢迎广大开发者访问魔乐社区DeepSeek专区查收更多适配模型和技术干货:魔乐社区
1. 性能问题
1.1 问题现象:部署DeepSeek服务化,性能不及预期
模块
性能测试
关键字
性能裂化,OS内核,日志,环境
问题描述
| MindIE 版 本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
| 部署DeekSeekV3/R1拉起后实测性能较差,与预期差异较大。 | |||
可能原因
- 日志级别问题
- OS内核版本问题
- 环境变量优化问题
排查方法
原因1:
在发送请求时,观察日志中是否存在大量的debug、info日志打印。如果存在可能是为了排查问题,各组件开启了debug日志,事后忘记关闭,而大量的日志打印是十分耗时的行为,且在正常的服务过程中,不需要这些日志。
原因2:
使用uname -r 查看OS内核版本,版本小于5.10;
原因3:
在 PyTorch 的训练或推理场景,可以通过设置环境变量 CPU_AFFINITY_CONF 来控制CPU 端算子任务的处理器亲和性,即设定任务绑核。该配置能够优化任务的执行效率,避免跨 NUMA(非统一内存访问架构)节点的内存访问,减少任务调度开销。
原因4:
未关闭确定性计算 HCCL_DETERMINISTIC $\risingdotseq$ true,可以通过 env | grepHCCL_DETERMINISTIC 来查看是否设置。
解决方案
原因1:
在 set_env.sh 中关闭各组件的 debug/info 日志等级,改成 ERROR 级别。
原因2:
升级系统,内核版本升级到5.10;(升级前需要找研发确认)
原因3:
开启绑核优化示例,开启方式三选一,建议优先尝试示例二
示例一:粗粒度绑核 export CPU_AFFINITY_CONF=1
示例二:细粒度绑核 export CPU_AFFINITY_CONF=2
示例三:自定义多张NPU卡的绑核范围
export CPU_AFFINITY_CONF=1,npu0:0-1,npu1:2-5,npu3:6-6
原因4:关闭确定性计算:
export HCCL_DETERMINISTIC=false
2 运行问题
2.1 问题现象:多机无法拉起 DeepSeek-R1 模型,HCCL 报错
模块
故障诊断
关键字
TLS、HCCL、AllReduce、通信
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
开启算子库日志(export ASDOPS_LOG_LEVEL=INFO; export ASDOPS_LOG_TO_STDOUT=1)与开启 ATB 日志(export ATB_LOG_LEVEL=INFO; export ATB_LOG_TO_STDOUT=1)多节点启动 service报HCCL问题,例如下图:
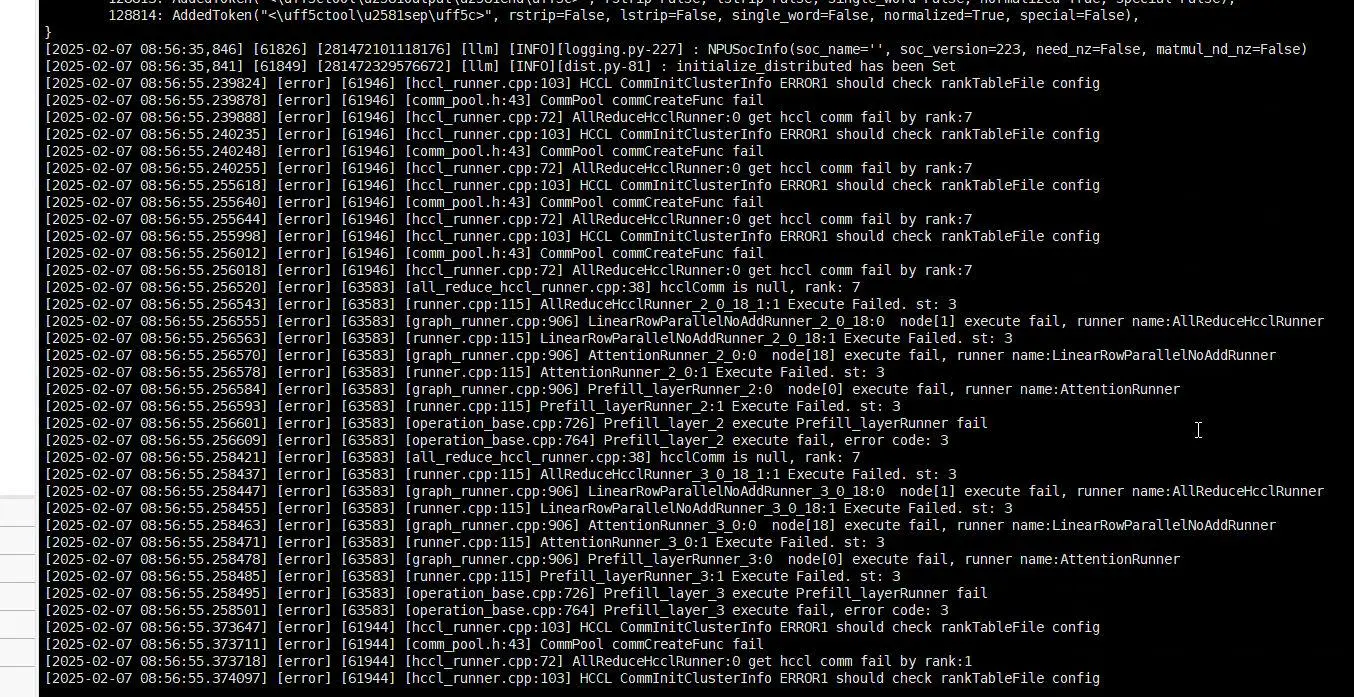
可能原因
NPU 底层 tls 校验行为不一致
排查方法
使用指令,查看每个节点的device 的TLS 开关状态是否一致
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
解决方案
用户启动服务前请检查NPU底层tls校验行为一致性,建议全0;使用如下命令:
for i in {0..7};do hccn_tool -i $i -tls -s enable 0;done
2.2 问题现象:多机无法拉起DeepSeek-R1 模型,从节点无法和主节点建立RPC 通信
模块
安装部署
关键字
RPC、多节点部署、防火墙
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
- 多节点部署从节点无法和主机点建立rpc 问题,子节点报RPC 问题,例如下图:
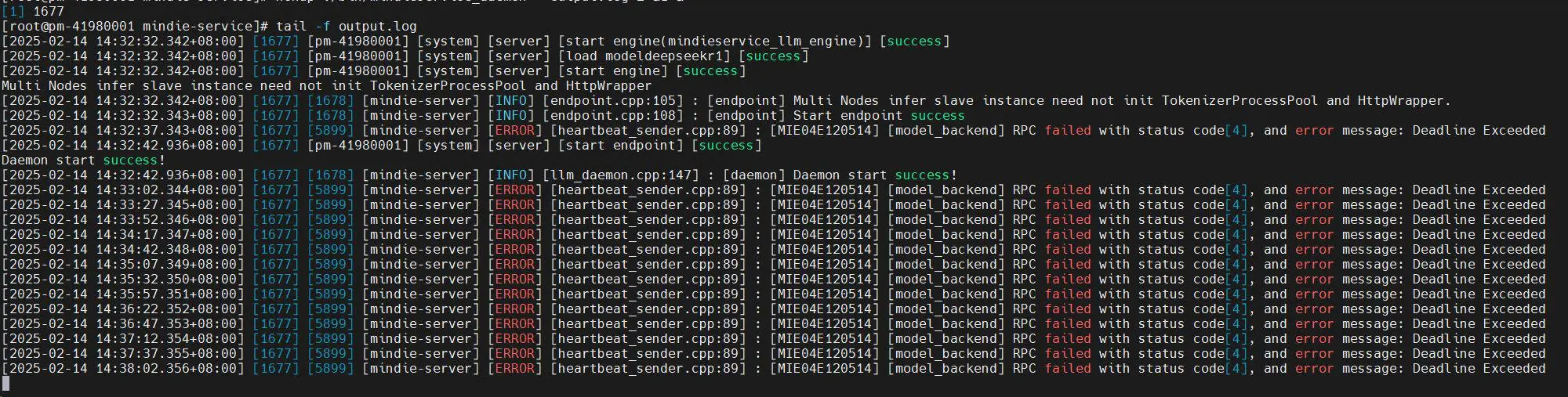
- 4 机推理,deepseek r1 服务化拉起失败,salve3 台服务化都能起,master 起服务会失败,报错信息如下图:
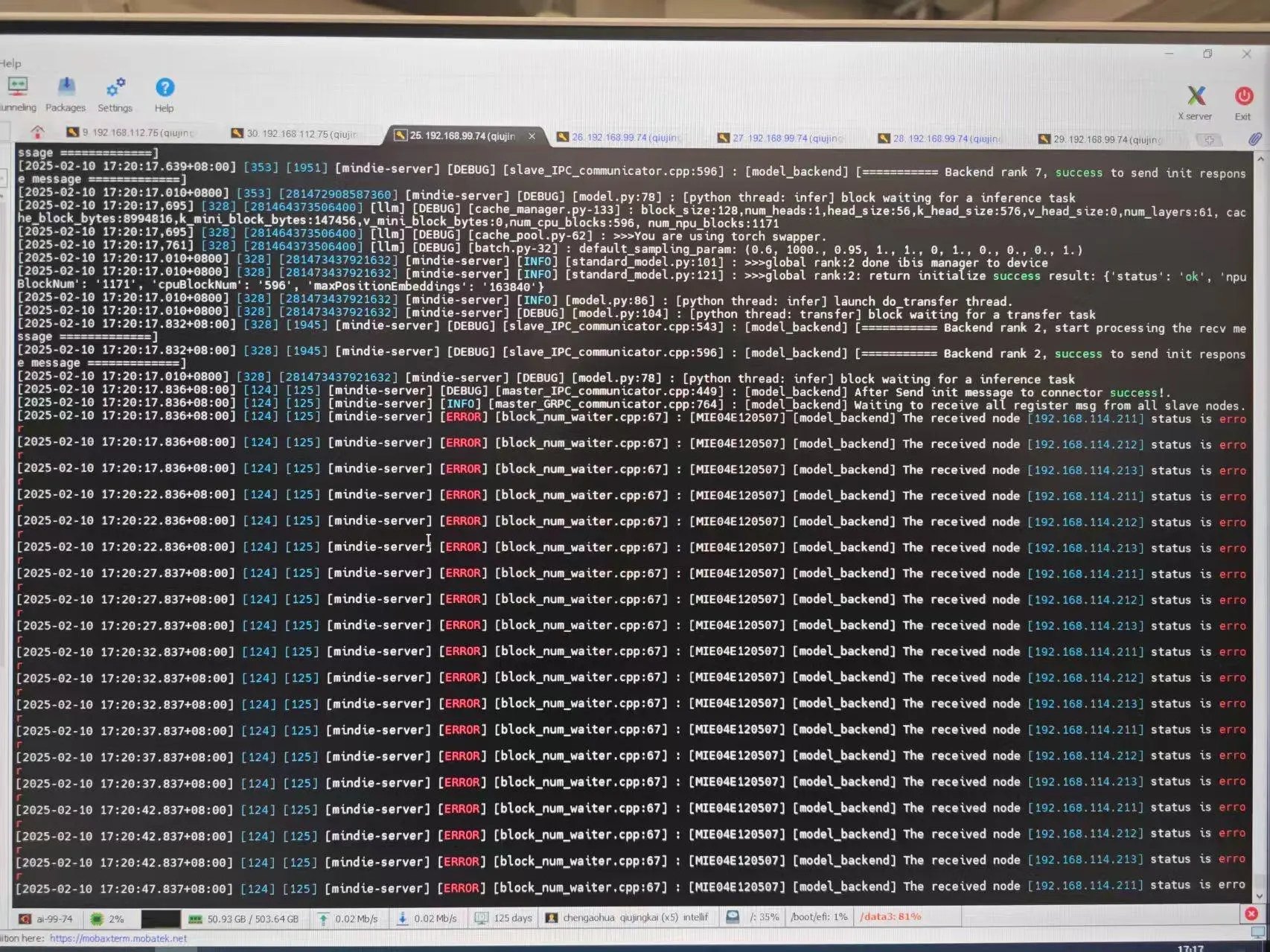
可能原因
防火墙拦截
排查方法
使用指令查看防火墙状态,如果开启防火墙,需要关闭;
sudo systemctl status firewalld
解决方案
每台机器执行 sudo systemctl stop firewalld,关闭防火墙。
2.3 问题现象:多机无法拉起 DeepSeek-R1 模型,服务器NPU 通信问题
模块
安装部署
关键字
NPU、网络、通信、中断、拉起
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
- 启动任务时,任务无法拉起
- 任务执行时,突然中断或服务突然终止
- 其他需要检测HCCL网络通信的场景
可能原因
NPU网络通信存在问题
排查方法
- 检测防火墙
- 检测NPU状态
- 检测NPU之间通讯
解决方案
步骤1:查看防火墙是否关闭
firewall-cmd –state
已关闭显示如下:
firewall-cmd --state not running
未关闭执行如下命令:
systemctl stop firewalld
步骤2: 检测卡状态
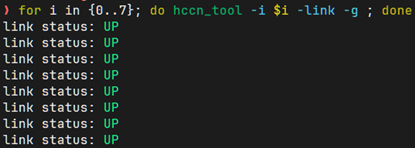
for i in {0..7}; do hccn_tool -i $i -link -g ; done
显示 up 为正常
其他状态可以通过如下命令重启卡(-i 后面填写卡的ID)
npu-smi set -t reset -i {RankId} -c 0 -m 1
步骤3: 检测卡的IP是否配置
for i in {0..7}; do hccn_tool -i $i -ip -g ; done
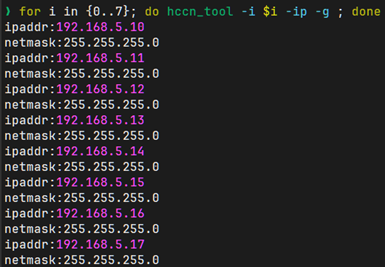
步骤4: 检测多节点的每个卡TLS 开关是否一致
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
所有机器的所有卡要么为1,要么为0。建议修改为0 进行关闭。
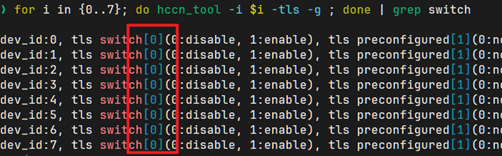
TLS 关闭方法(-i 后面填写卡的 ID)
hccn_tool -i {RankId} -tls -s enable 0
步骤5:本机卡间通信检测
- 进入任意目录创建一个 test.py
- 文件文件加入如下脚本
import subprocess
ip_list = []
for i in range(8):
try:
cmd = ['hccn_tool', '-i', str(i), '-ip', '-g']
res = subprocess.run(cmd, capture_output=True, text=True, check=True)
res_str = res.stdout.strip()
if 'ipaddr' in res_str:
ip_list.append(res_str.split('\n')[0].split(':')[1])
except subprocess.CalledProcessError as e:
print(e)
for i in range(8):
for other_ip in ip_list:
try:
cmd = ['hccn_tool', '-i', str(i), '-ping', '-g', 'address', str(other_ip), 'pkt', '3']
res = subprocess.run(cmd, capture_output=True, text=True, check=True)
print(ip_list[i], '==>', res.stdout.strip())
except subprocess.CalledProcessError as e:
print(e)
print(f'========{ip_list[i]} is OK========')
print(f'========ALL is OK========')
- 在当前目录执行脚本
python test.py
- 出现ALL is OK 代表本机所有卡通讯正常
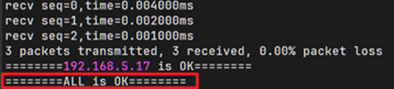
检测无误后,重新执行AI任务即可。
2.4 问题现象:多机无法拉起 DeepSeek-R1 模型,modeling_utils.py 报错
模块
故障诊断
关键字
NoneType、metadata、modeling_utils
问题描述
MindIE版本:2.0.T3
模型类型:DeepSeekV3/R1
在服务化拉起过程中,若出现if metadata.get("format") not in ["pt", "tf", "flax", "mix"]: AttributeError: "NoneType" object has no attribute 'get';报错
可能原因
输入的权重中缺少metadata字段
排查方法
日志modeling_utils.py报错
解决方案
安装更新transformers版本(= 4.46.3)
2.5 问题现象:多机无法拉起 DeepSeek-R1 模型,Failed to init endpoint
模块
安装部署
关键字
server.key、ca.pem、key_pwd、endpoint、https、服务化
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
MindIE 推理启服务出现 Failed to init endpoint! Please check the service log or console output.
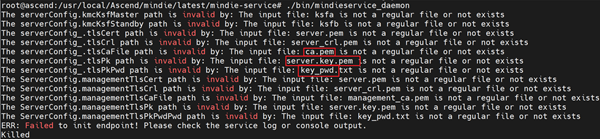
可能原因
开启 HTTPS,但未设置证书导致的问题。
排查方法
查看日志是否存在图片中描述的报错
解决方案
-
httpsEnabled 设置的 true,如果为 true 的情况下需要配置证书,请检查证书配置是否正确。证书配置请参考MindIE 社区文档:
功能介绍-CertTools-MindIE Service Tools-MindIE Service组件-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区 -
将 httpsEnabled 修改为 false
3 精度问题
3.1 问题现象:多机拉起 DeepSeek-R1 模型服务化后,发送推理请求,返回内容乱码
模块
模型推理
关键字
请求、乱码
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
四机部署deepseekR1,启服务后,发送推理请求,返回内容乱码,没有报错,例如下图:
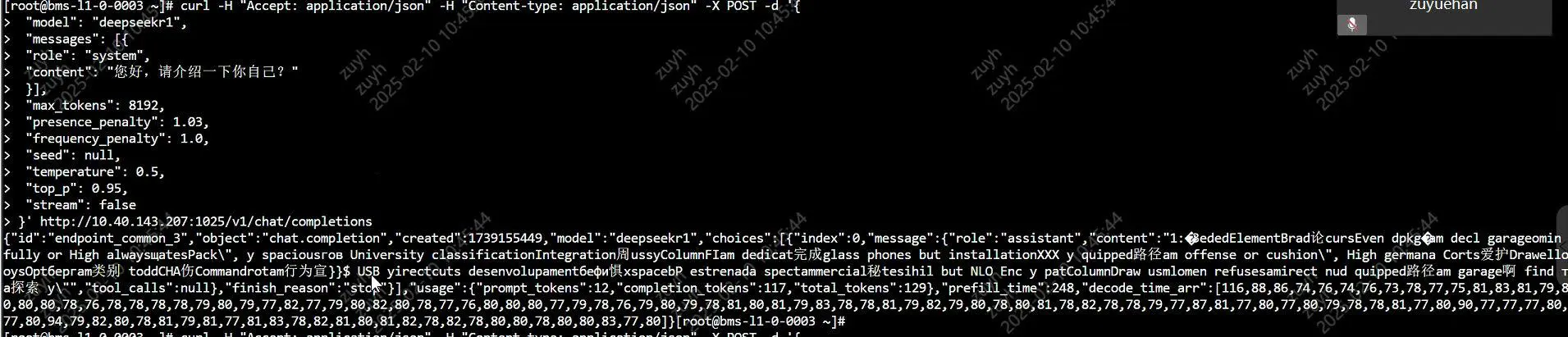
可能原因
用户使用的模型配置文件和官网文件有差异,导致返回异常。
排查方法
模型权重目录里的所有配置文件请与Modelers,HuggingFace 等官方网站所上传的权重等文件进行对比。
解决方案
把模型权重目录里的所有配置文件和官网上的文件对齐之后 只修改config.json 中的model_type 更改为 deepseekv2(只有这一处修改),推理返回正常。
4. 安装部署问题
4.1 题现象:NPU 卡健康检查返回错误,提示 timeout
模块
安装部署
关键字
NPU、健康检查、Receive timeout
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
多机拉起DeepSeek 模型时,服务化拉起卡住。进行NPU 卡进行健康检查时,返回timeout 错误
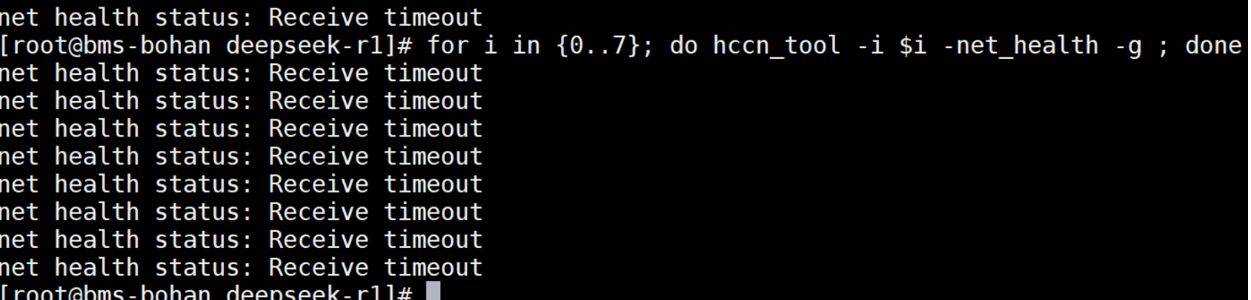
可能原因
1、交换机和NPU 的网关没有配置
2、NPU 的网关 IP 和侦测 ip 没有配置成一样
排查方法
1、使用 hccn_tool [-i 7] -netdetect -g,查看 NPU 的侦测 ip 有没有配置或配置成多少。
2、再次执行 hccn_tool [-i 7] -gateway -g,查看 NPU 的网关 IP 地址有没有多少或者配置成多少,侦测IP 和网关IP 两者比较是否一样,发现没有配置成一样。
解决方案
侦测IP 和网关IP 没有配置成一样,使用如下命令行修改成规划的网关IP 地址,使两者一样,问题得以解决。配置NPU 网卡地址,网关地址,侦测IP 的命令行如下:
1、Npu IP 和掩码设置
hccn_tool -i 0 -ip -s address 192.168.16.126 netmask 255.255.255.0
2、Npu 网关设置
hccn_tool -i 0 -gateway -s gateway 192.168.16.254
3、Npu 检测地址设置
hccn_tool -i 0 -netdetect -s address 192.168.16.254
4.2 题现象: 服务器开启lldp,查询邻居信息没有输出
模块
故障诊断
关键字
LLDP
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
多机拉起DeepSeek 模型时,服务化拉起卡住。检查网络通信,服务器两边都开启了LLDP,在服务器上执行 hccn_tool -i 0 -lldp -g 命令,没有任何新邻居信息输出

可能原因
1、交换机处没有使能LLDP
2、交换机端口或者网卡没有UP
排查方法
1、前往交换机执行 display lldp neighbor brief,如果有如下回显,证明交换机使能了 LLDP 功能。

2、现场确认下服务器连接交换机端口物理状态是否正常,物理指示灯是否亮灯。经过现场确认发现物理指示灯没有亮
解决方案
现场使用的交换机是 CE9860,400GE 端口使用 1 分 2 的光纤连接服务器 NPU 卡,物理指示灯未亮是因为400GE 端口未做拆分,在交换机上执行如下命令行将端口进行拆分,port split dimension interface 400GE 1/1/1 split-type 2*200GE。拆分后端口物理指示灯亮了,再在服务器上执行 hccn_tool -i 0 -lldp -g 命令,能够正常显示邻居信息了。
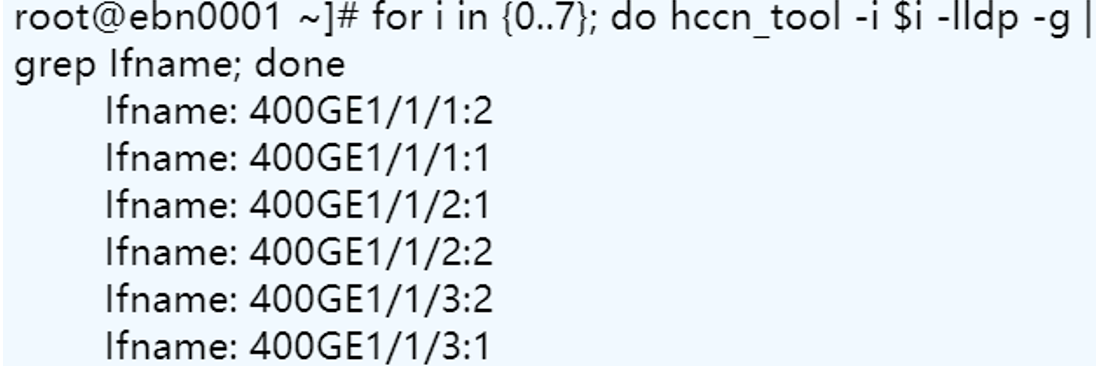
4.3 题现象:纯模型推理,启动阶段warm up 卡死
模块
安装部署
关键字
warm up、卡死
问题描述
| MindIE版本: | 2.0.T3 | 模型类型: | DeepSeekV3/R1 |
Deepseek v3 4 机纯模型推理,启动后卡在 warm up 环节
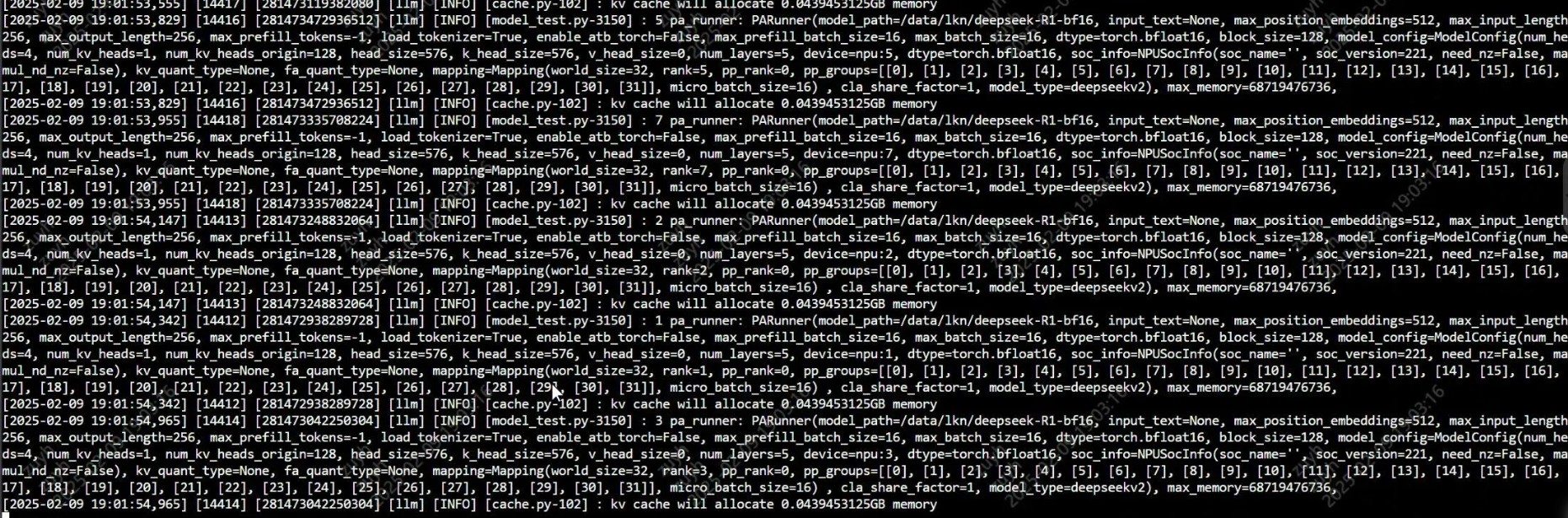
可能原因
多节点的环境变量配置不一致
排查方法
查看每个服务器的环境变量 HCCL_DETERMINISTIC 是否为 false
解决方案
需要保证多节点的 HCCL_DETERMINISTIC 一致,例如:export HCCL_DETERMINISTIC=false
5. 其他
5.1 版本查看:如何查看各组件的版本
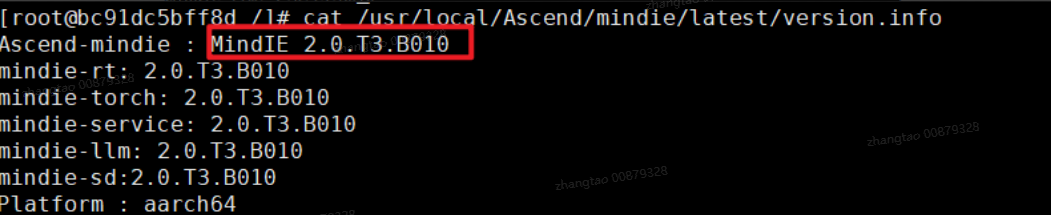
MindIE
cat /usr/local/Ascend/mindie/latest/version.info
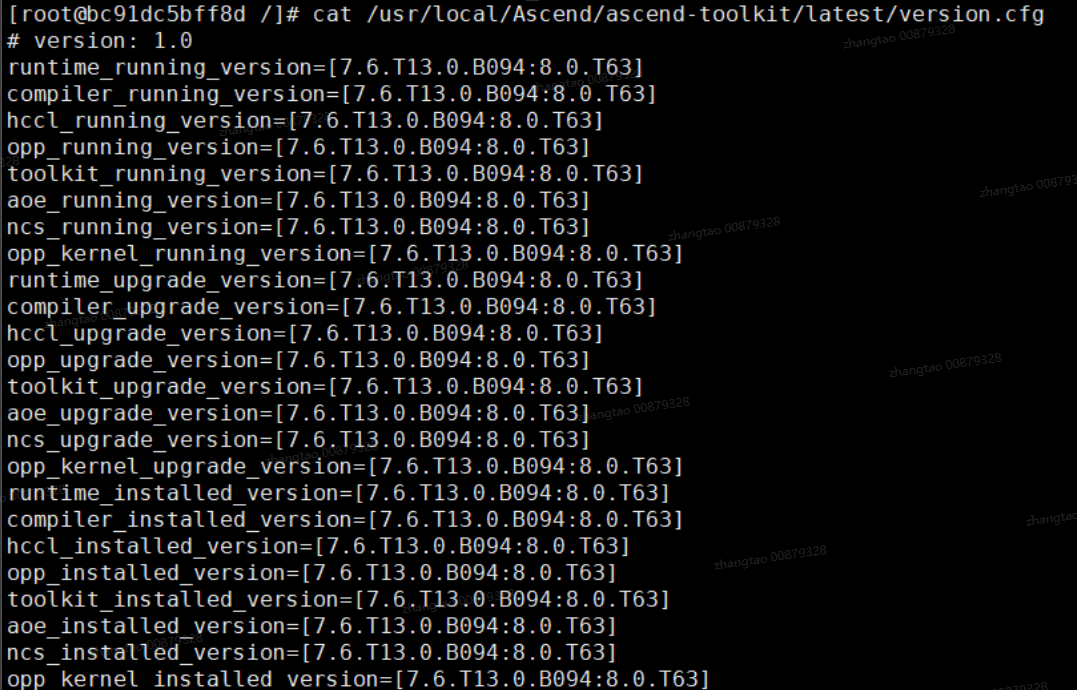
CANN
cat /usr/local/Ascend/ascend-toolkit/latest/version.cfg
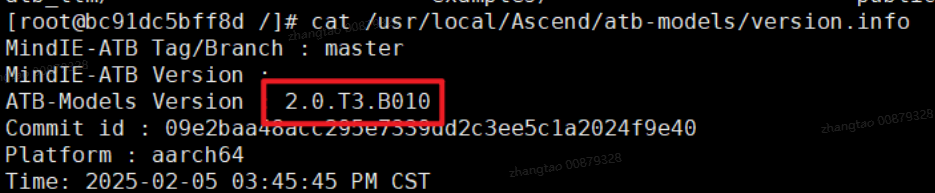
ATB-Models
cat /usr/local/Ascend/atb-models/version.info
NNAL
cat /usr/local/Ascend/nnal/atb/latest/version.info

5.2 快速定界HCCL\内存\代码 等问题
在拉起模型的过程中,会遇到各类不太明确根因的问题,如多节点拉起服务化\纯模型卡住、加载过程中报错、host 侧内存不足等问题。这类问题可能需要多次修改代码\环境变量,再拉起模型进行验证。拉起670B 的权重是一个特别耗时的过程,短的可能2、3 分钟,长的可能需要10、20 分钟。
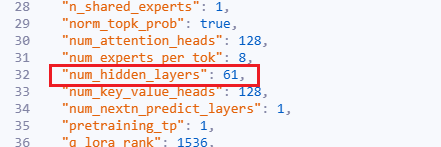
为了简化、便捷、快速的定位问题,减少拉起模型的时间,我们可以使用减层验证的方法来加速拉起时间。因为 Transformer 模型的每一层结构高度相似,包含自注意力机制和前馈神经网络(FFN)两个核心模块。每一层的计算步骤和参数量基本一致。因此,我们可以将 DeepSeek-R1/V3 的层数从 61 层减少到几层(比如 5 层)来减少参数量\计算量,加速验证、定位问题。
方法如下:
1.进入模型权重的文件夹,打开权重文件夹的 config.json
2.修改 "num_hidden_layers" 这个参数,修改为 5
3.验证、定位问题
4.问题解决后,将 "num_hidden_layers" 修改回原层数

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)