LLM基础学习05:TRPO/PPO/DPO理论解析及基于GRPO训练的Qwen2.5-1.5B-Instruct在GSM8K上的效果验证
TRPO前的部分为学习【王树森】深度强化学习(DRL)的简要笔记(基本就是课程关键信息截图)(课程github),前面的部分都非常简要,从PPO开始的部分才是学习原论文的详细笔记。学习过程中的一些基础代码则是基于Huggingface Deep RL Course(本文不涉及关于强化学习具体代码的实现)。最后的DeepSeek GRPO代码则是基于开源的别人的复现整了一个低配运行版本来进行分析。另
TRPO前的部分为学习【王树森】深度强化学习(DRL)的简要笔记(基本就是课程关键信息截图)(课程github),前面的部分都非常简要,从PPO开始的部分才是学习原论文的详细笔记。学习过程中的一些基础代码则是基于Huggingface Deep RL Course(本文不涉及关于强化学习具体代码的实现)。最后的DeepSeek GRPO代码则是基于开源的别人的复现整了一个低配运行版本来进行分析。
另外,DLC中进行了更多的实验,发现效果这个GRPO的效果非常的好!!!
本文的所有代码都放在了仓库Basic-LLM-Learning中,欢迎star!!!
文章目录
参考链接
这一篇参考了超级多内容,如果有引用遗漏的麻烦告诉我,我会及时补上的,不好意思!
简要的DPO、IPO、KTO实验效果对比: Preference Tuning LLMs with Direct Preference Optimization Methods
对RLHF的简要介绍:Illustrating Reinforcement Learning from Human Feedback (RLHF)
综述:A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
深度对比: SFT、ReFT、RLHF、RLAIF、DPO、PPO
强化学习简要基础
符号解释

- 动作价值函数:对当前状态 s t s_t st下,进行一个动作 a t a_t at后所获得的未来return的期望值
- **状态价值函数:**当前状态下,对所有动作的未来return计算期望值,表示当前状态的好坏,也可以与其他策略比较得出不同策略在当前状态下的差别
- 最优动作价值函数:(图中没有给出),公式是 Q ⋆ ( s t , a t ) = max π Q π ( s t , a t ) Q^\star(s_t,a_t)=\max_\pi Q_\pi(s_t,a_t) Q⋆(st,at)=maxπQπ(st,at),表示对当前状态 s t s_t st下,进行一个动作 a t a_t at后,在所有策略中可能得到的动作价值的最高值,也就是这个动作在所有策略中可以带来的最高的平均收益
强化学习的基础假设有:
- 随机性来源于两个地方:策略函数和状态转移函数
- 模型学习的依据:做出决策后环境的反馈(return)
- 评价决策的好坏:动作价值函数
- 评价状态的好坏:状态价值函数
价值学习

价值学习的核心是通过一个神经网络去逼近最优动作价值函数。
TD算法的核心是:模型一开始可以给出一个最终的分数预测,在每一步中实施动作后,实施该动作的分数就已经确定了(相当于原来只是预测,但是某个动作实施后分数就是可观测到的了)。所以继续从“当前状态”预测最终的分数时,由于一部分分数已经是确定了不可改变了,这个预测肯定与最开始的预测有所不同,也就产生了误差,根据这个误差构建的损失函数就可以对模型的参数进行更新了。这一步可以在每一次模型做出决策后进行。
策略学习

策略学习的核心是使用神经网络近似策略函数 π \pi π( θ \theta θ即表示神经网络中的参数),目标函数就是在使得在当前策略函数下状态价值函数最大化(所以这里的不是梯度下降,是梯度上升),这里的梯度计算包含两种形式,下面是关于当前状态 s t s_t st的状态价值函数表示:
V π ( s t ) = E A [ Q π ( s t , A ) ] , V_\pi(s_t)=\mathbb{E}_A[Q_\pi(s_t,A)], Vπ(st)=EA[Qπ(st,A)],
如果是离散的动作行为,这里的计算就是对每个动作进行累加求和;如果是连续的动作行为,则是进行积分计算。在离散的行为中,对应的梯度公式为:
∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) , \frac{\partial V(s;\mathbf{\theta})}{\partial\mathbf{\theta}}=\sum_a\frac{\partial\pi(a|s;\mathbf{\theta})}{\partial\mathbf{\theta}}\cdot Q_\pi(s,a), ∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a),
在连续的行为中,则表示为:
∂ V ( s ; θ ) ∂ θ = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ log π ( A ∣ s , θ ) ∂ θ ⋅ Q π ( s , A ) ] , \frac{\partial V(s;\mathbf{\theta})}{\partial\mathbf{\theta}}=\mathbb{E}_{A\sim\pi(\cdot|s;\mathbf{\theta})}\left[\frac{\partial\log\pi(A|s,\mathbf{\theta})}{\partial\mathbf{\theta}}\cdot Q_\pi(s,A)\right], ∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s,θ)⋅Qπ(s,A)],
由于这里的期望需要对所有连续的行为进行求积分,实际计算中比较困难,所以一般是使用蒙特卡洛方法来近似(在得到完整的行为决策后,最后再对每一步进行计算)。

Actor-Critic Method

在这个方法中,策略函数和动作价值函数都是用神经网络近似的,整个算法流程更详细的讲就是:
- 使用策略函数根据当前状态对动作进行采样
- 实施动作后获取新的状态和来自环境的奖励
- 根据新的状态采样得到下一步动作,但是不真的实施
- 由于已经实施了一步实际的动作和获取了来自环境的真实return,所以可以使用价值学习中的TD算法对动作价值函数的参数进行更新(梯度下降)
- 使用对当前已实施动作的动作价值函数的评分对策略函数的参数进行更新(梯度上升)
在整个训练过程中,模型的提升来源于动作价值函数对环境return的拟合,而训练结束后获取的则是策略函数。
TRPO(信任区域策略优化)
原文链接:Trust Region Policy Optimization

其中 L ( θ ∣ θ o l d ) L(\mathbf{\theta}\mid\mathbf{\theta}_{\mathrm{old}}) L(θ∣θold)表示对目标函数的近似,而
N ( θ o l d ) = { θ ∣ ∣ θ − θ o l d ∣ ∣ 2 ≤ Δ } , \mathcal{N}(\mathbf{\theta}_{\mathrm{old}})=\left\{\mathbf{\theta}\left||\mathbf{\theta}-\mathbf{\theta}_{\mathrm{old}}\right||_2\leq\Delta\right\}, N(θold)={θ∣∣θ−θold∣∣2≤Δ},
表示更新后的参数应该落在的区间。
简要的说,就是有时需要进行梯度下降或者梯度上升的目标函数的梯度不好求,所以就用一个近似函数在当前的 θ o l d \theta_{old} θold来对目标函数进行逼近后进行梯度计算,然后因为函数的逼近在某个范围内才是误差最小的(比如对某个函数在零点处进行Taylor展开),所以就会存在一个置信域(Trust Region),需要保证更新后的参数还落在置信域中才是误差最小的(或者说是误差可接受的)。

在置信域算法的基础上,可以对策略函数的目标函数做近似,然后再在参数的置信域中进行梯度更新。而计算两个参数距离的方法在视频中提到有两种:直接计算范数和计算KL散度(计算两个概率分布的距离)。同时由于需要对动作价值函数做近似,所以策略函数的参数在决策过程中不会进行更新,只有当某一局完全结束后,计算得到动作价值函数的采样之后才能计算出近似函数进行更新。
这里存在一个疑问:,在TRPO和后续介绍的PPO算法中,都提到了需要通过某种方法计算旧模型参数和新模型参数之间的**“距离”**(也许是输出的概率分布之间的差异,也有可能直接计算两个模型的范数),那就会产生一个问题:在进行梯度更新之前,怎么得到新的模型参数和输出的概率分布?如果没有新的模型参数和输出的概率分布,又怎么计算出损失函数?
这个问题在论文的附录C部分有明确的数学过程表示,基本方法就是通过使用逼近的方法先搜索出一个梯度更新方向,然后再在这个方向上使用line search,在保证满足非线性约束的同时优化目标函数。
PPO(近端策略优化)
原文链接:Proximal Policy Optimization Algorithms
在TRPO的思想中,就是通过设定置信域的方法对参数的更新范围进行限制,防止模型模型参数的更新幅度过大导致训练不稳定,PPO则是更进一步用了更好的限制。首先来看一下原本的目标函数:
L P G ( θ ) = E ^ t [ log π θ ( a t ∣ s t ) A ^ t ] L^{PG}(\theta)=\hat{\mathbb{E}}_t\left[\log\pi_\theta(a_t\mid s_t)\hat{A}_t\right] LPG(θ)=E^t[logπθ(at∣st)A^t]
对上述的目标函数计算近似梯度,计算公式为:
g ^ = E ^ t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] , \hat{g}=\hat{\mathbb{E}}_t\left[\nabla_\theta\log\pi_\theta(a_t\mid s_t)\hat{A}_t\right], g^=E^t[∇θlogπθ(at∣st)A^t],
(附上公式推导链接),其中 π θ \pi_\theta πθ即为参数为 θ \theta θ的策略函数, A ^ t \hat{A}_t A^t表示当前时间步 t t t下的某个动作相对于平均表现的优势。而在TRPO中,对应的目标函数可以简化为
$$
\underset{\theta}{\operatorname*{\mathrm{maximize}}}\quad\hat{\mathbb{E}}t\left[\frac{\pi\theta(a_t\mid s_t)}{\pi_{\theta_{\mathrm{old}}}(a_t\mid s_t)}\hat{A}_t\right],
\
\text { subject to } \quad \hat{\mathbb{E}}{t}\left[\mathrm{KL}\left[\pi{\theta_{\text {old }}}\left(\cdot \mid s_{t}\right), \pi_{\theta}\left(\cdot \mid s_{t}\right)\right]\right] \leq \delta,
$$
可以看出,这是参数更新受限的目标函数,并且新的参数和旧的参数对某个动作分配的概率差距越大(假设是分配给更优动作的概率,所以新参数的概率应该更大),目标函数的值也会越高。
对应的,在PPO的论文中提出的目标函数则是
L C L I P ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] , L^{C L I P}(\theta)=\hat{\mathbb{E}}_{t}\left[\min \left(r_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right], LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)],
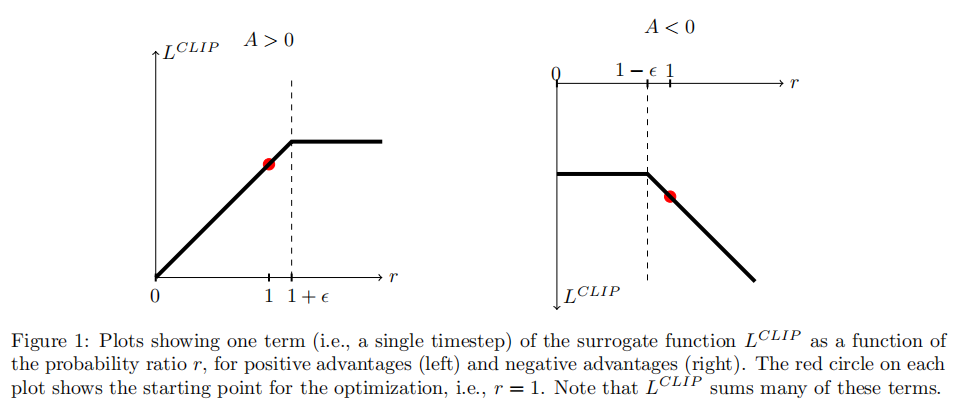
其中 r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_{t}(\theta)=\frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta_{\mathrm{old}}}(a_t\mid s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),也就是 min \min min左边的第一项和TRPO中的目标函数表示相同; clip \operatorname{clip} clip函数表示将 r t ( θ ) r_{t}(\theta) rt(θ)限制在指定的区间内,可以参考论文中的图进行理解:
- 如果 r t ( θ ) r_{t}(\theta) rt(θ)的值在区间 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ]中,那么就保留原来的 r t ( θ ) r_{t}(\theta) rt(θ),也就是 min \min min函数两边的值一样
- 如果 r t ( θ ) r_{t}(\theta) rt(θ)的值小于 1 − ϵ 1-\epsilon 1−ϵ,那么就直接使用 1 − ϵ 1-\epsilon 1−ϵ作为系数;大于则使用 1 + ϵ 1+\epsilon 1+ϵ作为系数
另外,在论文中还提出了另一种实现,首先根据TRPO中的目标函数和对应的约束条件,可以把目标函数转换为
maximize θ E ^ t [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A ^ t − β KL [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] , \operatorname*{maximize}_{\theta}\hat{\mathbb{E}}_{t}\left[\frac{\pi_{\theta}(a_{t}\mid s_{t})}{\pi_{\theta_{\mathrm{old}}}(a_{t}\mid s_{t})}\hat{A}_{t}-\beta\operatorname{KL}[\pi_{\theta_{\mathrm{old}}}(\cdot\mid s_{t}),\pi_{\theta}(\cdot\mid s_{t})]\right], θmaximizeE^t[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]],
也就是把约束条件加入到了目标函数中并使用 β \beta β作为超参数,然后设计了如下图所示的自适应更新算法

其中 d t a r g d_{targ} dtarg即为类似前一种实现中 ϵ \epsilon ϵ的超参数。
总的来说,PPO方法就是防止模型对分数的追求过于激进,需要对它的参数更新和学习加入一定的限制。
关于LLM的强化学习
DPO(直接偏好优化)
原文链接:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
DPO是专门针对LLM中人类偏好对齐的算法,是强化学习在LLM中的发展。PPO中约束条件简化进目标的函数后,目标函数基本可以分为两部分:期望奖励部分和更新幅度惩罚部分。论文中提到,该目标函数调优后得到的最终策略(即为LLM模型)可以表示为:
π r ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) , \pi_r(y\mid x)=\frac{1}{Z(x)}\pi_{\mathrm{ref}}(y\mid x)\exp\left(\frac{1}{\beta}r(x,y)\right), πr(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y)),
其中** π r e f ( y ∣ x ) \pi_{\mathrm{ref}}(y\mid x) πref(y∣x),即为经过SFT训练后的模型,已经具有一定的指令回答能力, x x x表示prompts, y y y表示模型的输出,在LLM的强化学习中,把整个LLM模型视作策略函数**,输入的prompts视为状态,最终目标是根据设定好的奖励,希望模型在当前状态(prompts)下输出更符合人类偏好的结果(RL中“更好的决策”); β \beta β是关于惩罚项的超参数; r ( x , y ) r(x,y) r(x,y)表示在当前输入下对模型输出的评分,即奖励函数;另外,
Z ( x ) = ∑ y π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) , Z(x)=\sum_y\pi_\mathrm{ref}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right), Z(x)=y∑πref(y∣x)exp(β1r(x,y)),
通过这个策略函数反推,可以得到奖励函数的表示:
r ( x , y ) = β log π r ( y ∣ x ) π r e f ( y ∣ x ) + β log Z ( x ) , r(x,y)=\beta\log\frac{\pi_{r}(y\mid x)}{\pi_{\mathrm{ref}}(y\mid x)}+\beta\log Z(x), r(x,y)=βlogπref(y∣x)πr(y∣x)+βlogZ(x),
假如模型生成了两个句子 y 1 y_1 y1和 y 2 y_2 y2,论文中用Bradley-Terry模型来对偏好进行建模,公式为
p ∗ ( y 1 ≻ y 2 ∣ x ) = exp ( r ∗ ( x , y 1 ) ) exp ( r ∗ ( x , y 1 ) ) + exp ( r ∗ ( x , y 2 ) ) , p^*(y_1\succ y_2\mid x)=\frac{\exp\left(r^*(x,y_1)\right)}{\exp\left(r^*(x,y_1)\right)+\exp\left(r^*(x,y_2)\right)}, p∗(y1≻y2∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x,y1)),
这个公式就表示了人类偏好的分布,把前面反推得到的奖励函数代入这个公式,可以得到
p ∗ ( y 1 ≻ y 2 ∣ x ) = 1 1 + exp ( β log π ∗ ( y 2 ∣ x ) π r e f ( y 2 ∣ x ) − β log π ∗ ( y 1 ∣ x ) π r e f ( y 1 ∣ x ) ) , p^*(y_1\succ y_2\mid x)=\frac{1}{1+\exp\left(\beta\log\frac{\pi^*(y_2|x)}{\pi_{\mathrm{ref}}(y_2|x)}-\beta\log\frac{\pi^*(y_1|x)}{\pi_{\mathrm{ref}}(y_1|x)}\right)}, p∗(y1≻y2∣x)=1+exp(βlogπref(y2∣x)π∗(y2∣x)−βlogπref(y1∣x)π∗(y1∣x))1,
既然任务的目标是希望模型能够更大概率的输出人类喜欢的回答,所以可以表示为概率的形式,那么就可以使用最大似然估计来使这个概率最大化,对应的论文推出了下面的公式:
L D P O ( π θ ; π r e f ) = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) − β log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) ) ] , \mathcal{L}_{\mathrm{DPO}}(\pi_\theta;\pi_{\mathrm{ref}})=-\mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi_\theta(y_w\mid x)}{\pi_{\mathrm{ref}}(y_w\mid x)}-\beta\log\frac{\pi_\theta(y_l\mid x)}{\pi_{\mathrm{ref}}(y_l\mid x)}\right)\right], LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))],
这也就是DPO中的目标函数,在模型的训练中,梯度下降只需要根据这个目标函数进行就可以了,直接避免了强化学习中奖励建模和策略优化等多阶段的优化过程,把模型训练简化到只有按照目标函数来进行梯度下降一个阶段(监督学习)。
GRPO(Group Relative Policy Optimization)
原文链接:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
论文首先回顾了一下PPO的公式:
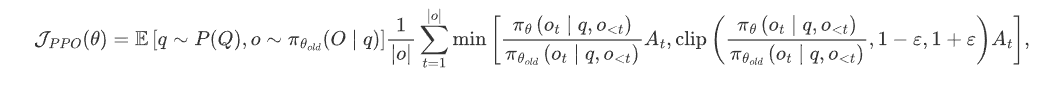
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] , \mathcal{J}_{P P O}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{o l d}}(O \mid q)\right] \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left[\frac{\pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_{t} \mid q, o_{<t}\right)} A_{t}, \operatorname{clip}\left(\frac{\pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_{t} \mid q, o_{<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) A_{t}\right], JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At],
与前面PPO中公式的差别就是这里随机采样了很多个输出来求平均进行计算, A t A_t At是广义优势估计(Generalized Advantage Estimation,GAE)。随后论文贴出了两个方法的对比: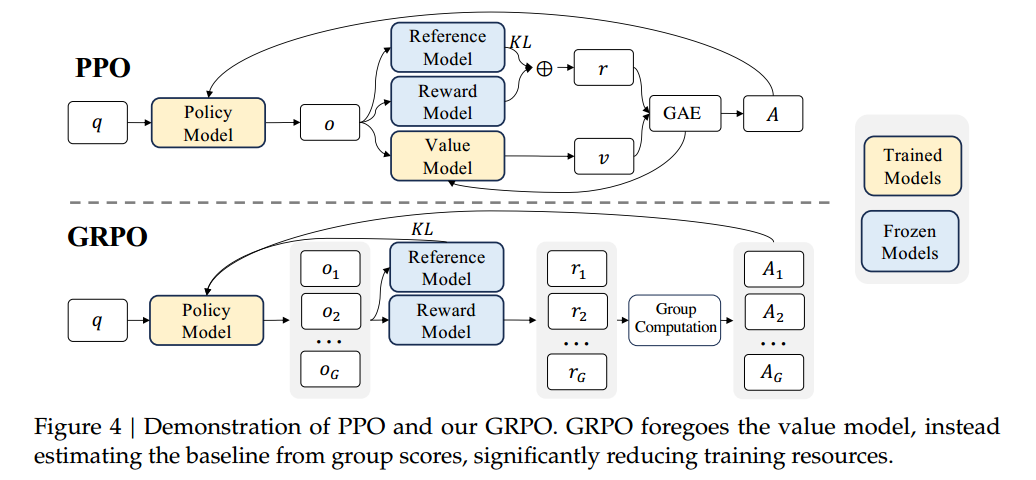
可以看到,GRPO中直接没有使用价值网络来对输出进行评估(PPO一般用在actor-critic上,需要有一个价值网络来对actor的行为进行评判,value model和reward model的区别在于,reward model只是按照当前的输出来给出当前这一步的奖励,相当于来自环境的反馈,而value model需要判断这个输出是否超过了模型应该有的平均表现,所以前面提到,叫优势估计),而是当LLM模型(策略网络)输入一个 q q q后,推理得到多个输出 o 1 , o 2 , . . . o G o_1, o_2,...o_G o1,o2,...oG,然后通过reward model对每个输出计算当前输出的奖励,GRPO直接通过下面的公式代替广义估计函数:
A ^ i , t = r ~ i = r i − mean ( r ) std ( r ) , \hat{A}_{i, t}=\widetilde{r}_{i}=\frac{r_{i}-\operatorname{mean}(\mathbf{r})}{\operatorname{std}(\mathbf{r})}, A^i,t=r
i=std(r)ri−mean(r),
这样就不用构建一个巨大的value model。对应的,GRPO认为经过监督微调后的SFT模型 π r e f \pi_{ref} πref中已经具有一定的知识,所以强化学习只是为了从中把知识“释放”出来,所以在下面目标函数的最后增加了与SFT模型 π r e f \pi_{ref} πref距离的惩罚项。
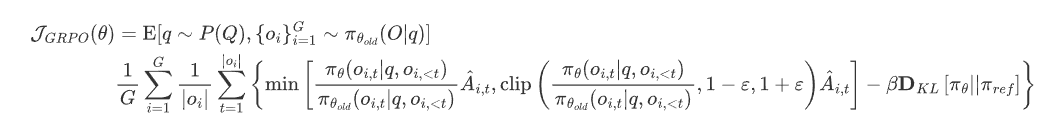
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , c l i p ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } \begin{aligned} \mathcal{J}_{GRPO}(\theta) & =\operatorname{E}[q\sim P(Q),\{o_{i}\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O|q)] \\ & \frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|}\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}\hat{A}_{i,t},\mathrm{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})},1-\varepsilon,1+\varepsilon\right)\hat{A}_{i,t}\right]-\beta\mathbf{D}_{KL}\left[\pi_{\theta}||\pi_{ref}\right]\right\} \end{aligned} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]}
RLHF(基于人类反馈的强化学习)
这一部分主要是讲强化学习怎么在LLM中发挥作用的。
提出论文:Learning to summarize from human feedback
更多应用:Training language models to follow instructions with human feedback
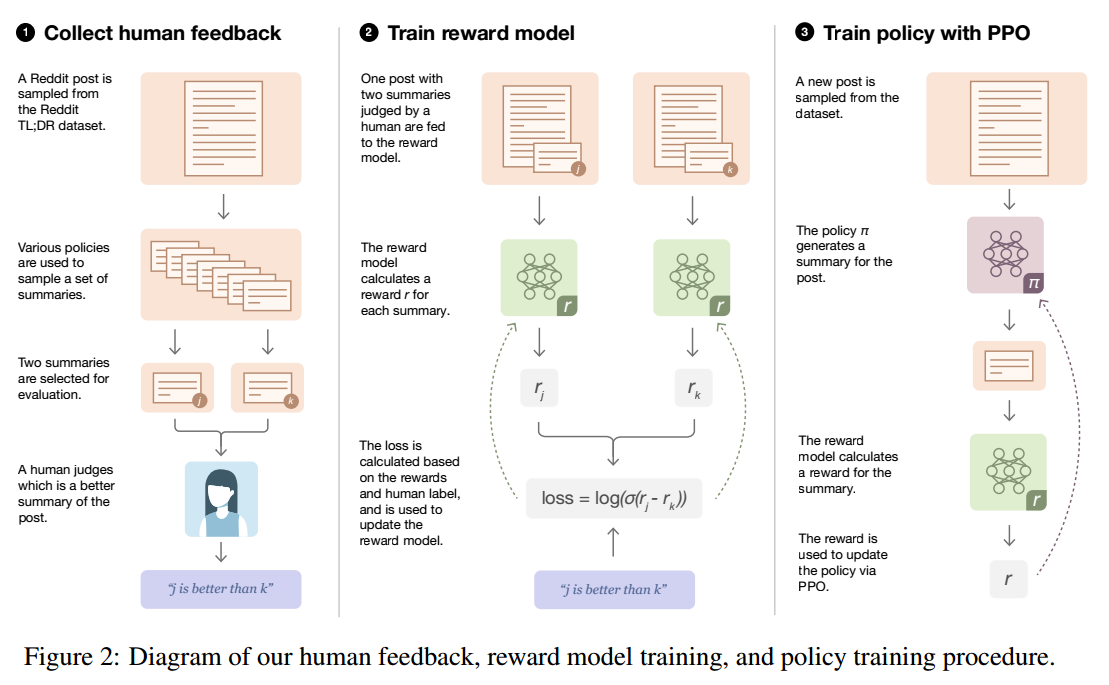
上图即为PPO用于训练模型输出更符合人类喜好的结果,整个过程分三步:
- 模型输出成对的结果,人工选取最佳结果
- 从人类反馈中学习奖励模型,用于判断哪个输出的结果更好
- 针对奖励模型优化策略函数(LLM)
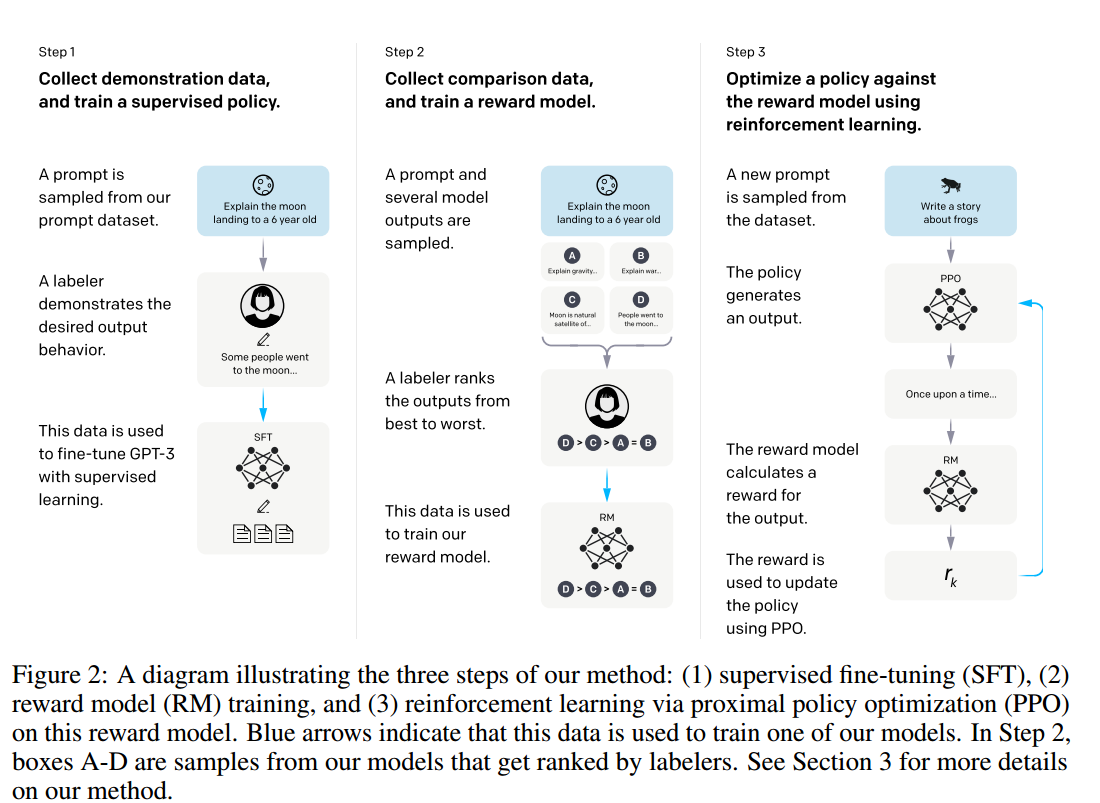
在引用的第二篇论文中,训练步骤为
- 人类编写一些回答来对模型进行监督微调
- 模型输出多个结果,人类对模型输出结果的好坏进行排序,并基于该结果训练奖励模型
- 使用奖励模型训练LLM
代码分析
这里蹭一下deepseek的热点,实现下它的GRPO。经过搜索,发现github上已经有人复现了一个简单的版本,而且用的数据集刚好也是前几篇一直在用的GSM8K,所以下面对这个代码进行注释和分析:Coding GRPO from Scratch: A Guide to Distributed Implementation with Qwen2.5-1.5B-Instruct。(下面只挑最重要的部分进行介绍,完整的中文注释版本依然放在我的github中。)
给分方法
要实现一个强化学习环境,最重要的就是根据模型的action(也就是大模型的输出)给出对应的得分奖励,所以首先对给分方法进行分析。
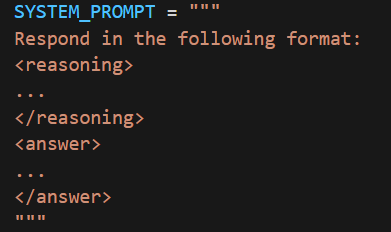
由于GRPO最重要的就是应用在思维链上,所以这里的系统prompt给出了一个固定的格式,要求模型按照这个给出的格式来进行回答。对应的<reasoning>和</reasoning>中的内容就是在deepseek-R1中模型**“深度思考”中的内容,<answer>和</answer>中的则是模型给出的最终答案部分**。
在奖励的代码中,总共有两个给分来源:答案分和格式分。
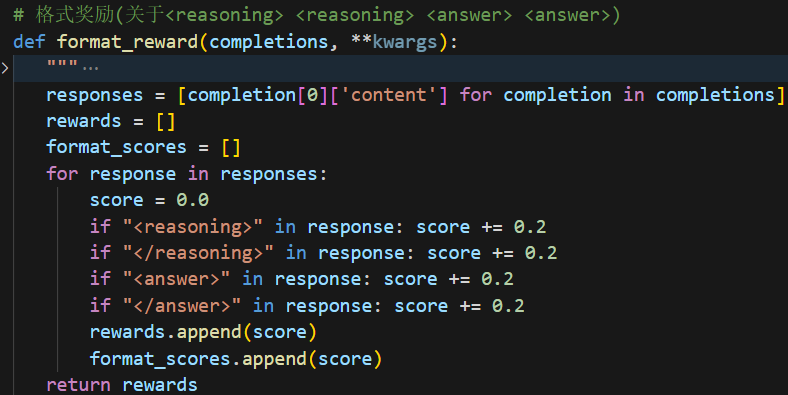
格式分就是如果模型按照上面prompt中的格式进行输出,每出现一个对应的标记就给0.2分。实现的代码如下。
答案分里面则分为完全匹配得分和最终结果得分,可以理解为完全匹配得分对应的就是我们考试时的过程分,只不过这里的要求更加严格,要求和数据集给出的过程完全一致;而最终结果得分则是只要最后计算的结果是对的,就有一个结果分,但是肯定会比完全匹配得分要低。实现的代码如下:
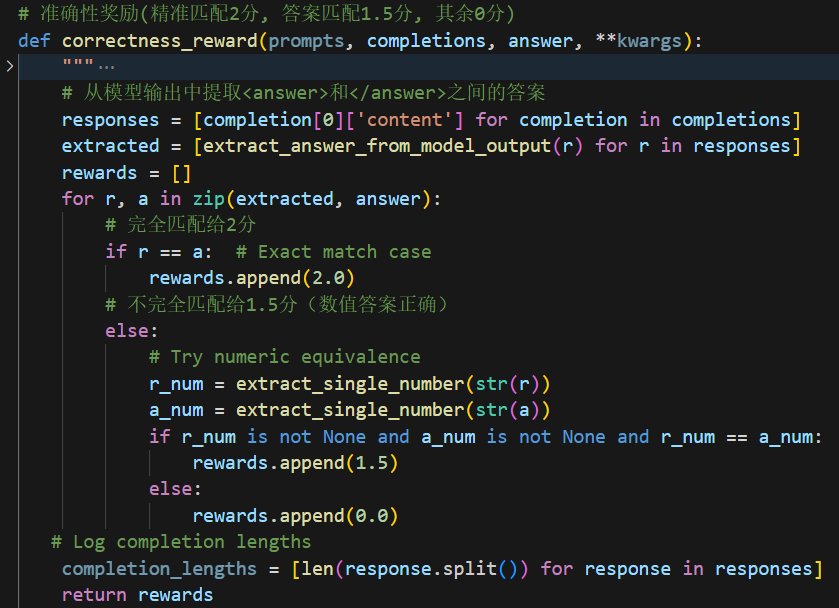
GRPO Loss
首先列出几个函数的功能,这里不对这些工具性质的函数进行介绍了。
| 函数 | 功能 |
|---|---|
selective_log_softmax |
计算模型输出的某个token的对数概率 |
compute_log_probs |
调用上一个函数,计算模型输出的最后几个token的每个对应的对数概率 |
generate_rollout_data |
为当前模型 π θ \pi_{\theta} πθ和SFT模型 π r e f \pi_{ref} πref的每个输入推理得到多个结果,即GRPO的“Group”部分,返回输出结果及其token概率 |
combined_reward/reward_function |
调用前面两个函数进行得分计算并汇总,在后面以reward_function传入grpo_loss函数 |
这里需要超级注意的一点就是上述提到的概率都是对数概率,这是方便后面一些数值的计算,比如前面的目标函数公式中存在一个 π θ ( o t q , o < t ) π θ o l d ( o t q , o < t ) \frac{\pi_{\theta}(o_{t} q, o_{<t})}{\pi_{\theta_{o l d}}(o_{t} q, o_{<t})} πθold(otq,o<t)πθ(otq,o<t),添加对数之后就可以按照下面的推导简化计算公式:

r t = π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) = exp ( log π θ ( o t ∣ q , o < t ) ) exp ( log π θ o l d ( o t ∣ q , o < t ) ) = exp ( log π θ ( o t ∣ q , o < t ) − log π θ o l d ( o t ∣ q , o < t ) ) . \begin{align*}r_t &= \frac{\color{green}{\pi_{\theta}(o_{t}|q, o_{<t})}}{\color{blue}{\pi_{\theta_{old}}(o_{t}|q, o_{<t})}} \\&= \frac{\exp\left( \color{green}{\log \pi_{\theta}(o_{t}|q, o_{<t})} \right)}{\exp\left( \color{blue}{\log \pi_{\theta_{old}}(o_{t}|q, o_{<t})} \right)} \\&= \exp\left( \color{green}{\log \pi_{\theta}(o_{t}|q, o_{<t})} - \color{blue}{\log \pi_{\theta_{old}}(o_{t}|q, o_{<t})} \right ). \end{align*} rt=πθold(ot∣q,o<t)πθ(ot∣q,o<t)=exp(logπθold(ot∣q,o<t))exp(logπθ(ot∣q,o<t))=exp(logπθ(ot∣q,o<t)−logπθold(ot∣q,o<t)).
首先从generate_rollout_data得到来自模型的输出和对应的输出的token概率rollout_data,按照下面的步骤从中提取数据。

调用函数并使用前面提到的公式就对应了代码的第一步第二步:

接着是第三步,根据模型的输出计算这次输出的奖励,也就是前面说到的答案分和格式分:
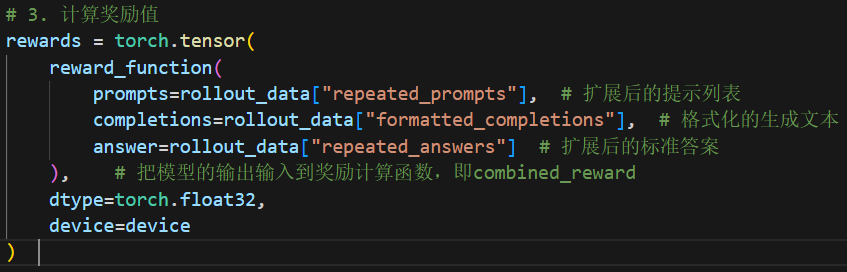
第四步,使用GRPO的方法计算广义优势函数 A ^ i , t = r ~ i = r i − mean ( r ) std ( r ) , \hat{A}_{i, t}=\widetilde{r}_{i}=\frac{r_{i}-\operatorname{mean}(\mathbf{r})}{\operatorname{std}(\mathbf{r})}, A^i,t=r i=std(r)ri−mean(r),代码如下
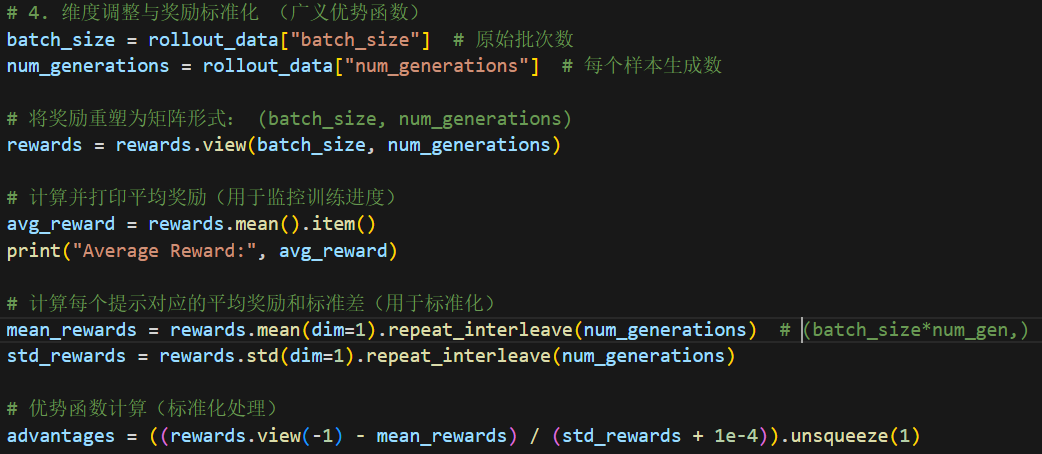
第五步,根据比例和上下界对优势函数添加系数:

第六第七步,计算KL散度部分并计算得到最终的目标函数:

到这里基本就分析完了代码的整个核心部分,其余部分就是标准的深度学习模型训练流程了。
低配训练魔改
原代码中用的是全参训练,但是TA有8张A100,每张A100有80G显存,这显然是我一个自学的人搞不来的资源,所以就按照下面的方式调用了peft库中的LoRA来进行训练,下面是修改原代码的步骤:
第一步,导入要用的库

第二步,配置LoRA训练参数(下面的参数直接由deepseek给出,懒得搞了)
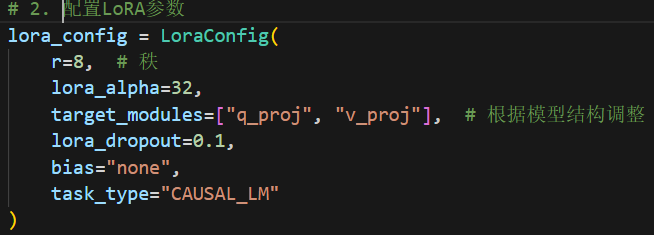
第三步,借由get_peft_model获取配置好的准备用来训练的模型。

这几步还是非常简单的,即插即用。
另外,本文还调整了一些训练的超参数来防止爆内存。

下面是每个参数的含义。
| 参数名称 | 描述 |
|---|---|
num_iterations |
外部迭代次数,每次迭代从当前策略模型创建新参考模型 |
num_steps |
训练循环最大执行步数 |
batch_size |
每步处理的示例数量 |
num_generations |
每个提示生成的完成结果数量 |
max_completion_length |
生成响应部分的最大标记长度 |
beta |
KL散度惩罚系数 |
learning_rate |
策略优化学习率 |
mu |
每批数据执行的策略更新次数 |
epsilon |
PPO裁剪参数 |
结果对比
首先是观察下训练过程一些指标的输出,先把原代码的结果贴上来:
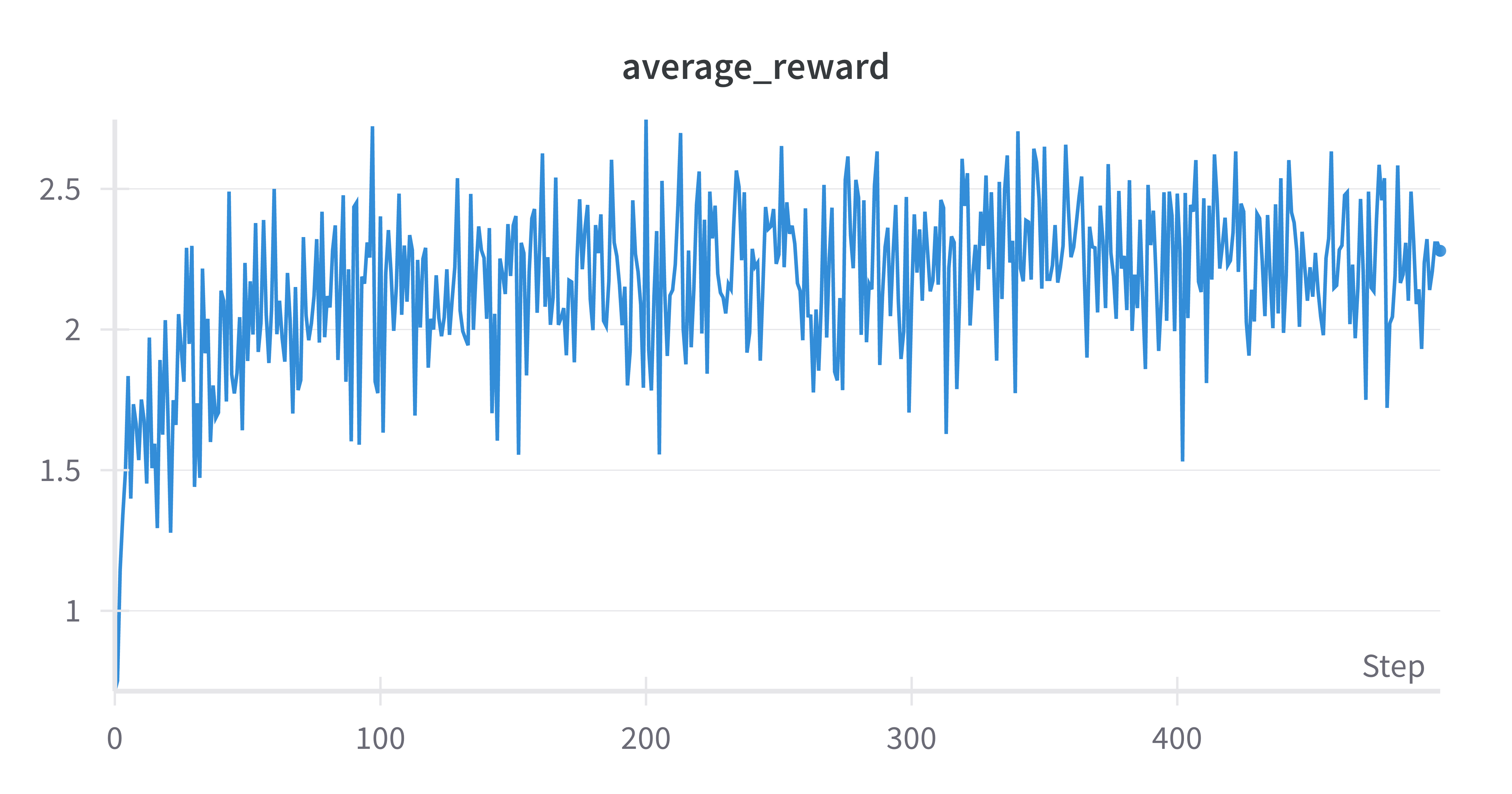
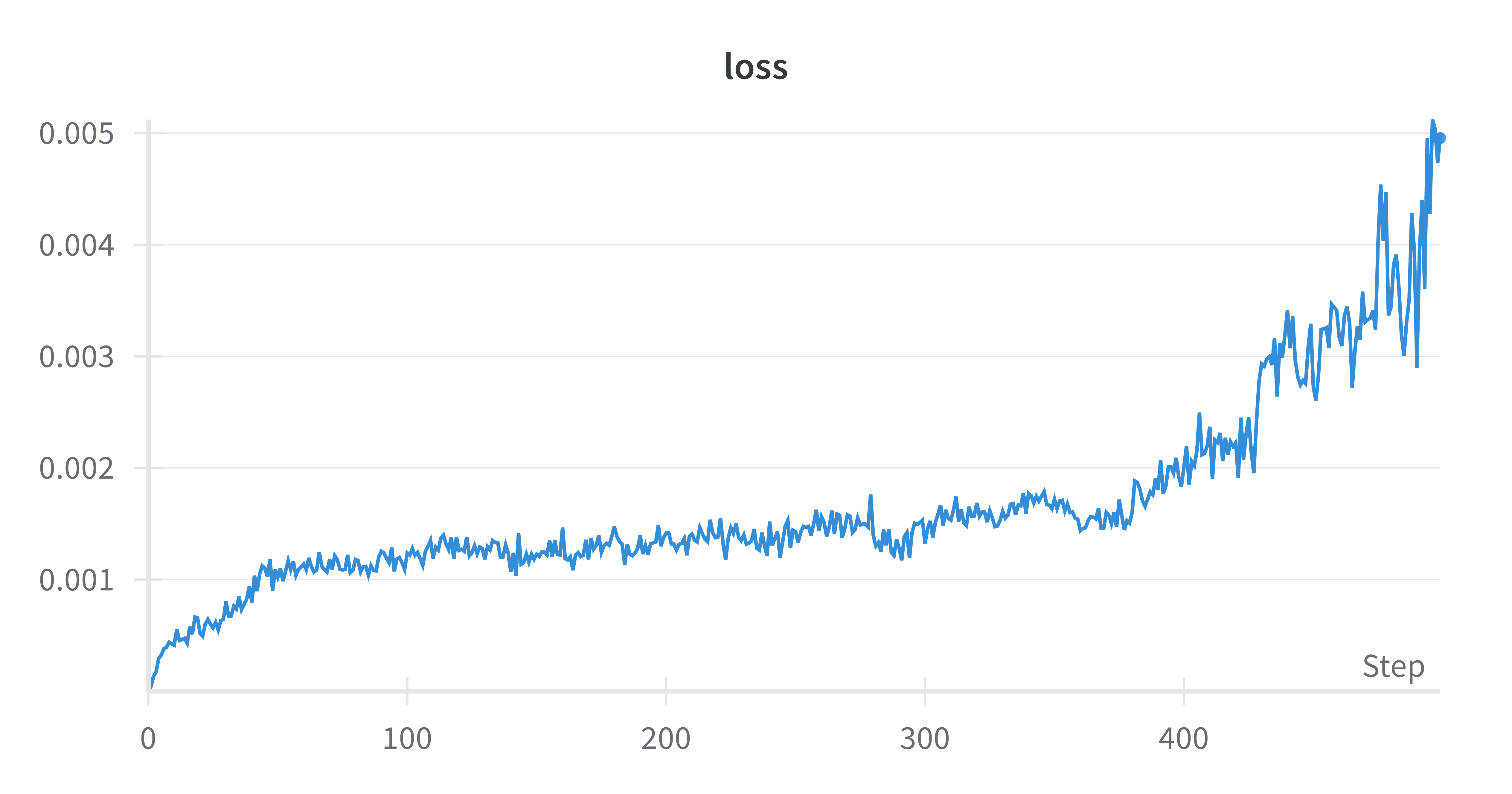
然后再贴上我魔改过的训练结果:
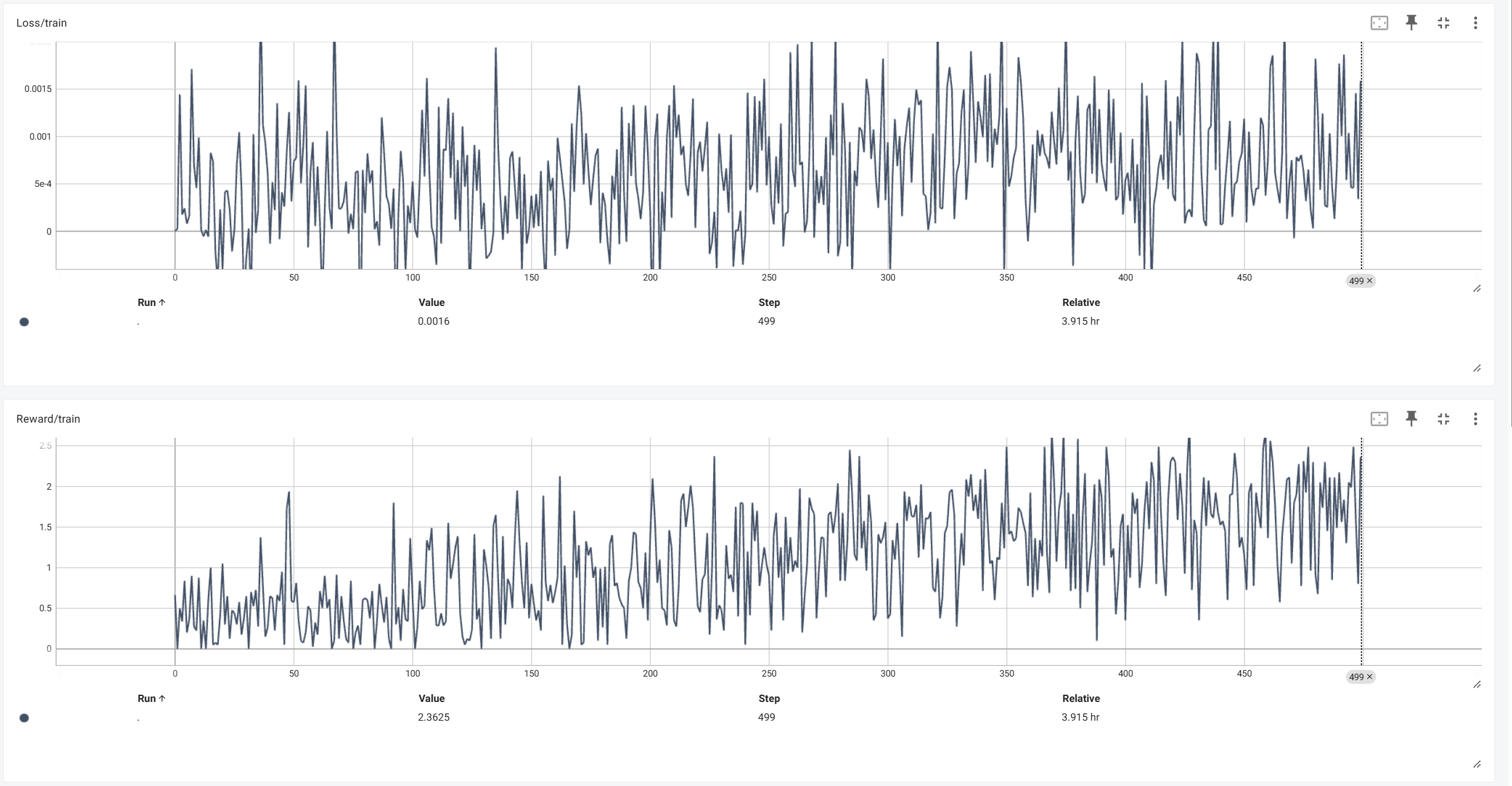
可以看出,原代码的reward和魔改后的reward基本都是呈现一个**“迂回上升”的趋势,原代码的结果可以稳定在2到2.5之间**,而我的魔改后的版本则是稳定在1和2之间。推测是前面设置的num_generations参数比较小导致reward不高,也就是模型实践的次数不够多;不如原代码稳定则推测是由于使用了LoRA训练和batch_size设置的小导致的,batch小了就导致每一步更新的梯度都不够稳定,而LoRA本身就会在训练中引入不稳定。图中的loss其实就是前面的GRPO的目标函数没有加负号的结果,和原代码之间差异的原因应该和reward的差异原因一样。
现在直接调用原代码中的模型评估函数进行对比,可以看到是直接提高了50%的准确率!虽然LoRA和num_generations引入的问题对比原代码实现的90%准确率还有差距,但安慰下自己,也算是学习到东西了!

DLC1
之前本系列一直用的都是lm-evaluation-harness来进行评估,所以为了比较实际上GRPO算法对模型能力的提升,下面对原代码进行了更深入的魔改来验证GRPO的能力。
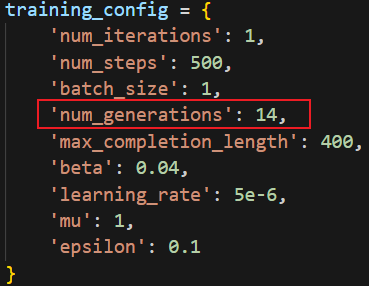
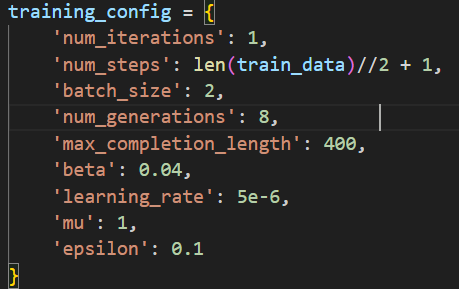
前面已经推测每个样本生成回答个数的num_generations参数太小导致模型训练的效果不佳,所以本次训练使用了下面的参数,并且使用了4张4090进行实验。在这个参数下,训练过程中设定只有batch_size和LoRA与原代码不同了。
同时为了保持与lm-evaluation-harness评测时的prompt一致,分别修改了这个库的GSM8K评测提示词为和本代码的一样,皆为以下形式(其中要求必须有####是因为该库评测时就是根据这个进行正则表达式的匹配):
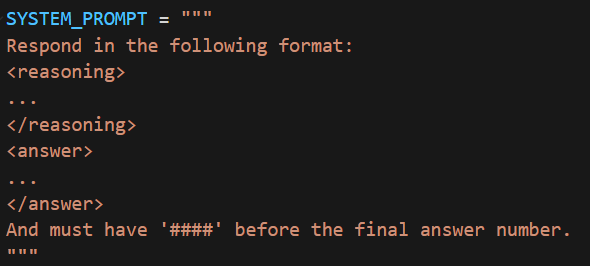
既然修改了格式要求,就必须对给分方法进行修改,所以修改为了下面的形式
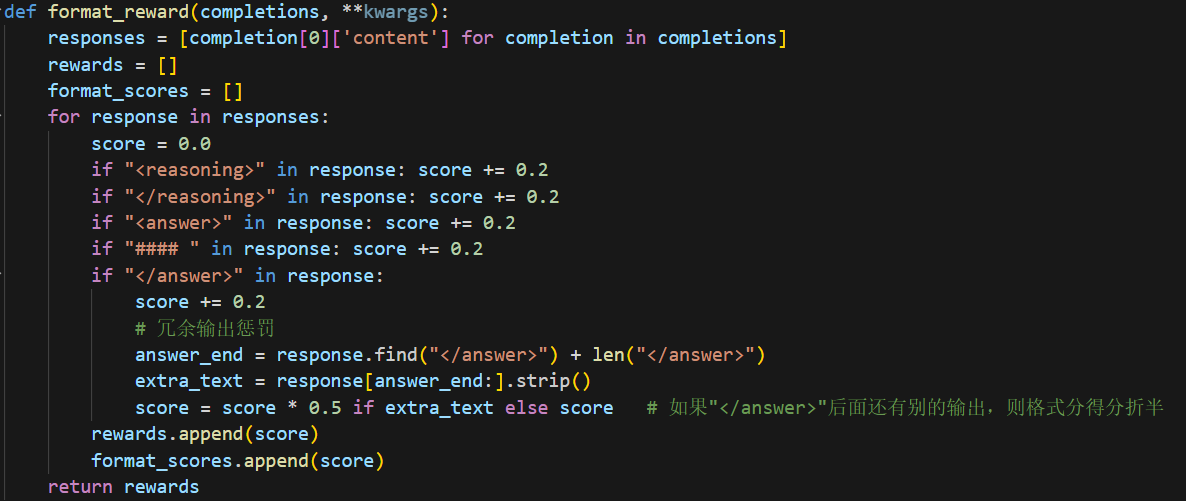
可以看到,不仅对输出中是否包含####进行了判断(存在则加0.2分),同时还对</answer>后如果还输出别的内容进行了惩罚,这也是为了匹配lm-evaluation-harness库评测的妥协,因为这个库会对最后的结果进行提取,如果模型输出太多东西就会提取错误。
下面再贴上这次训练过程的指标变化和平滑后的结果:
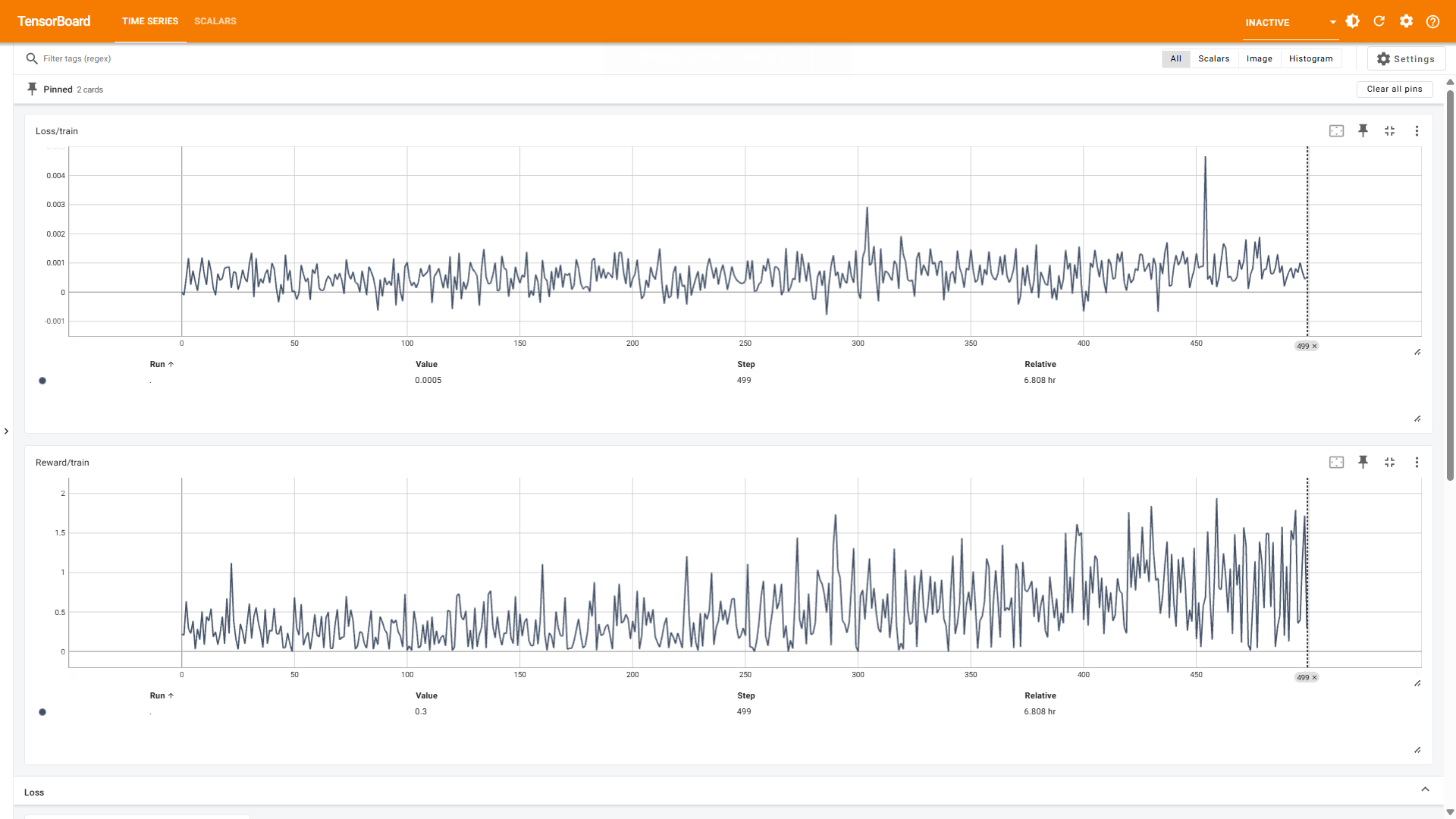
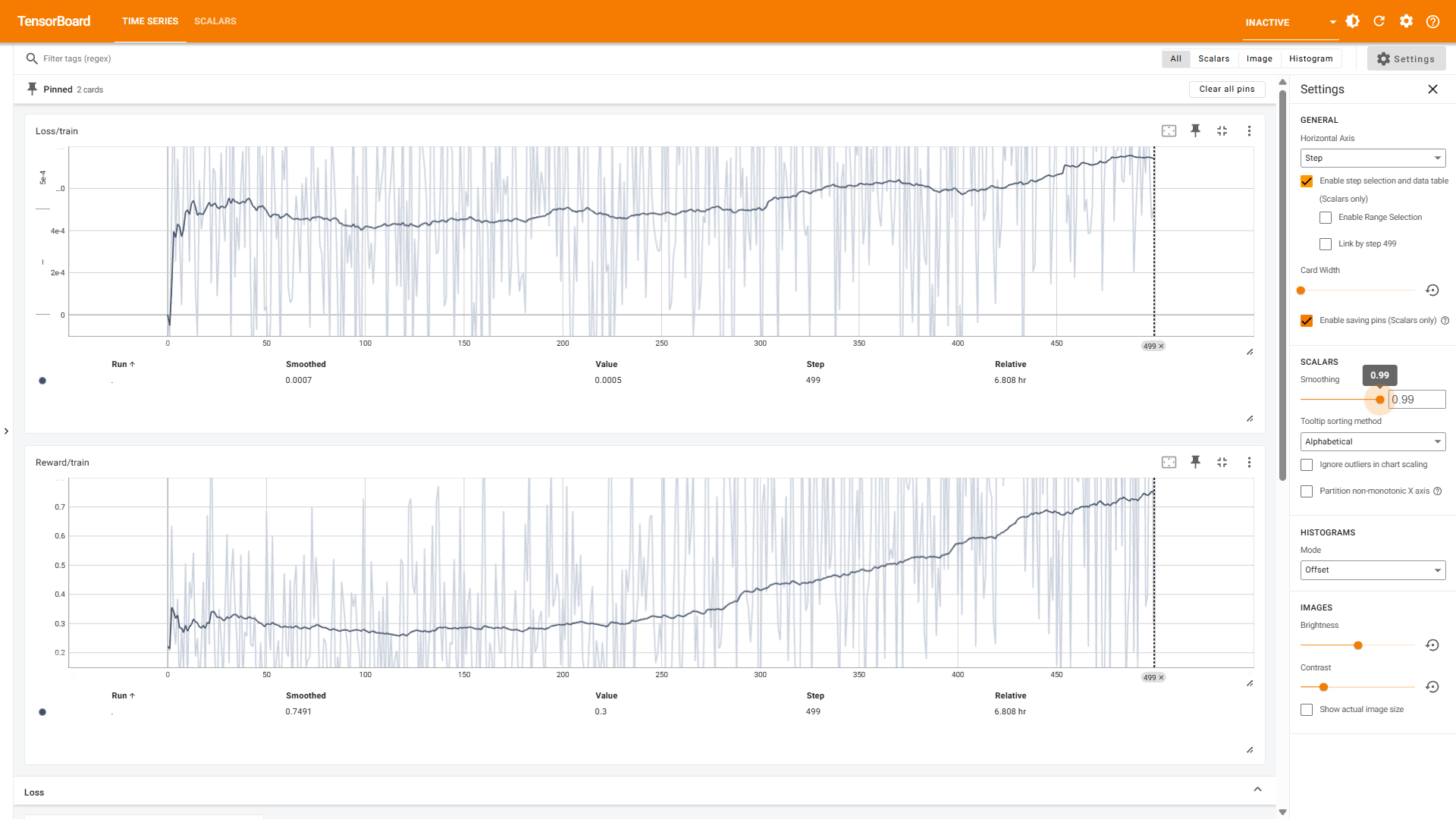
可以看出,总的来说奖励还是在缓慢提高的!
最后就是端上之前使用的lm_eval命令评估的结果:
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| gsm8k | 3 | flexible-extract | 0 | exact_match | ↑ | 0.4314 | ± | 0.0136 |
| strict-match | 0 | exact_match | ↑ | 0.0008 | ± | 0.0008 |
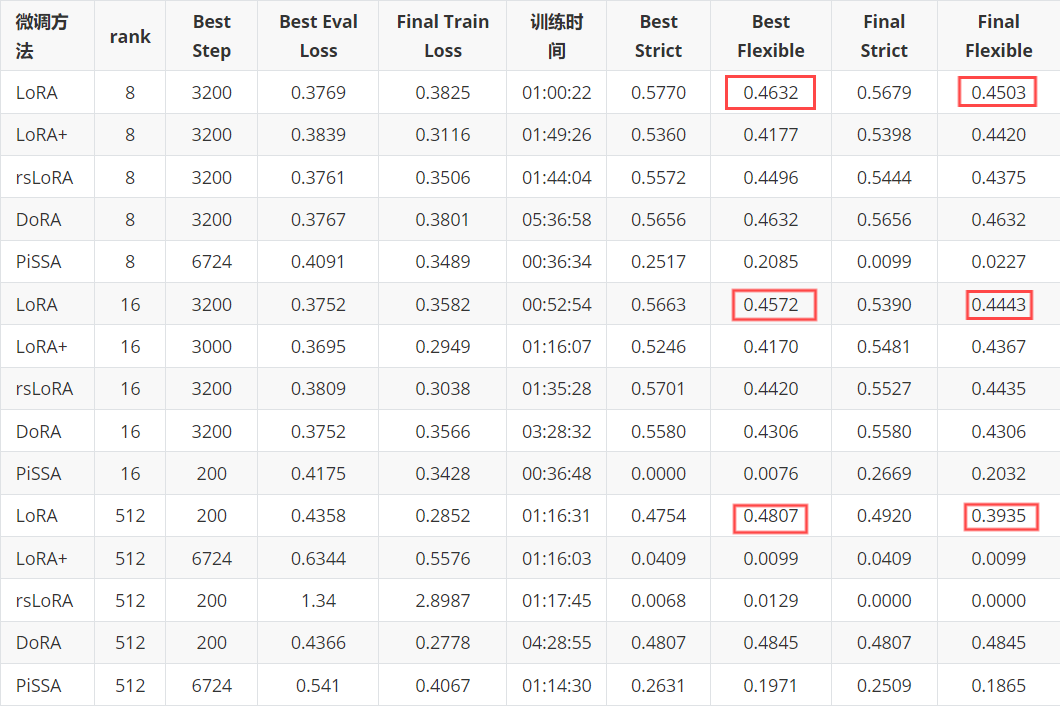
在根据之前LLM基础学习04:LoRA变种原理与实践全解析——LoRA+/rsLoRA/DoRA/PiSSA多方法代码实验与GSM8K评估里的结果。发现flexible-extract下的结果甚至还比原始的LoRA低几个点???
其实不是的,实际上,在上面设置的训练参数中,训练了一轮,一轮里最多只有500步,而一步只训练一个样本,所以实际上只是用了500个样本来对模型进行训练,那我们再来看看这次引用的代码中总的训练样本数有多少个:7443个样本!!!也就是说,仅使用了不到十分一的样本就训练出了接近全样本训练95%以上的效果!!!
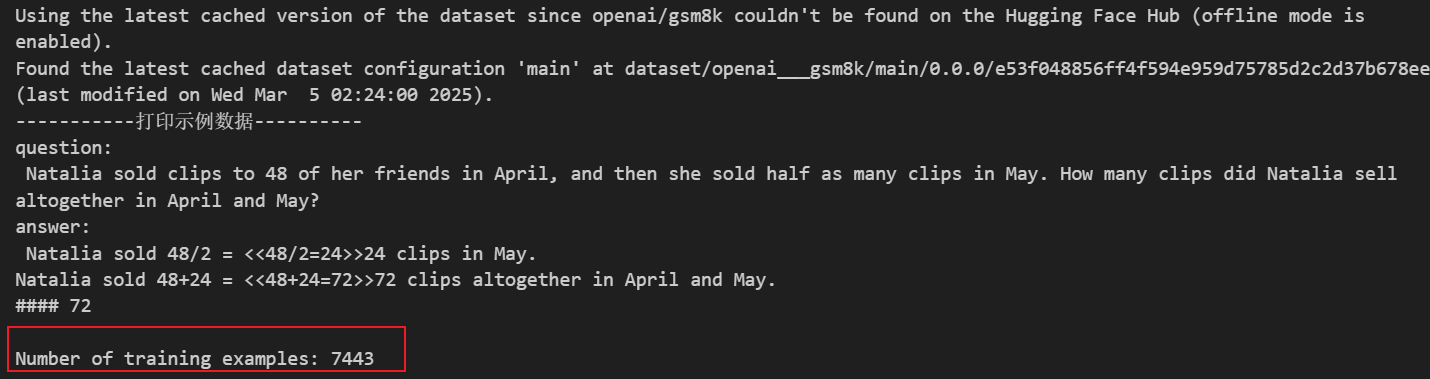
但是这已经要训练8个小时了,而且由于GRPO过程中有个生成句子的部分,所以也没整明白这个怎么更高效的利用显卡来完成分布式训练,下面是训练过程中的显卡占用,可以看出还是有很大的提升空间的。

DLC2
一不做二不休,其余细节不变,直接用下面的配置进行一次训练,通过减少生成的数量num_generations来增加batch_size,虽然由于训练过程中是完全随机抽样,没有保证每个样本都能抽到,但是增加了模型学习的时间和样本数量。
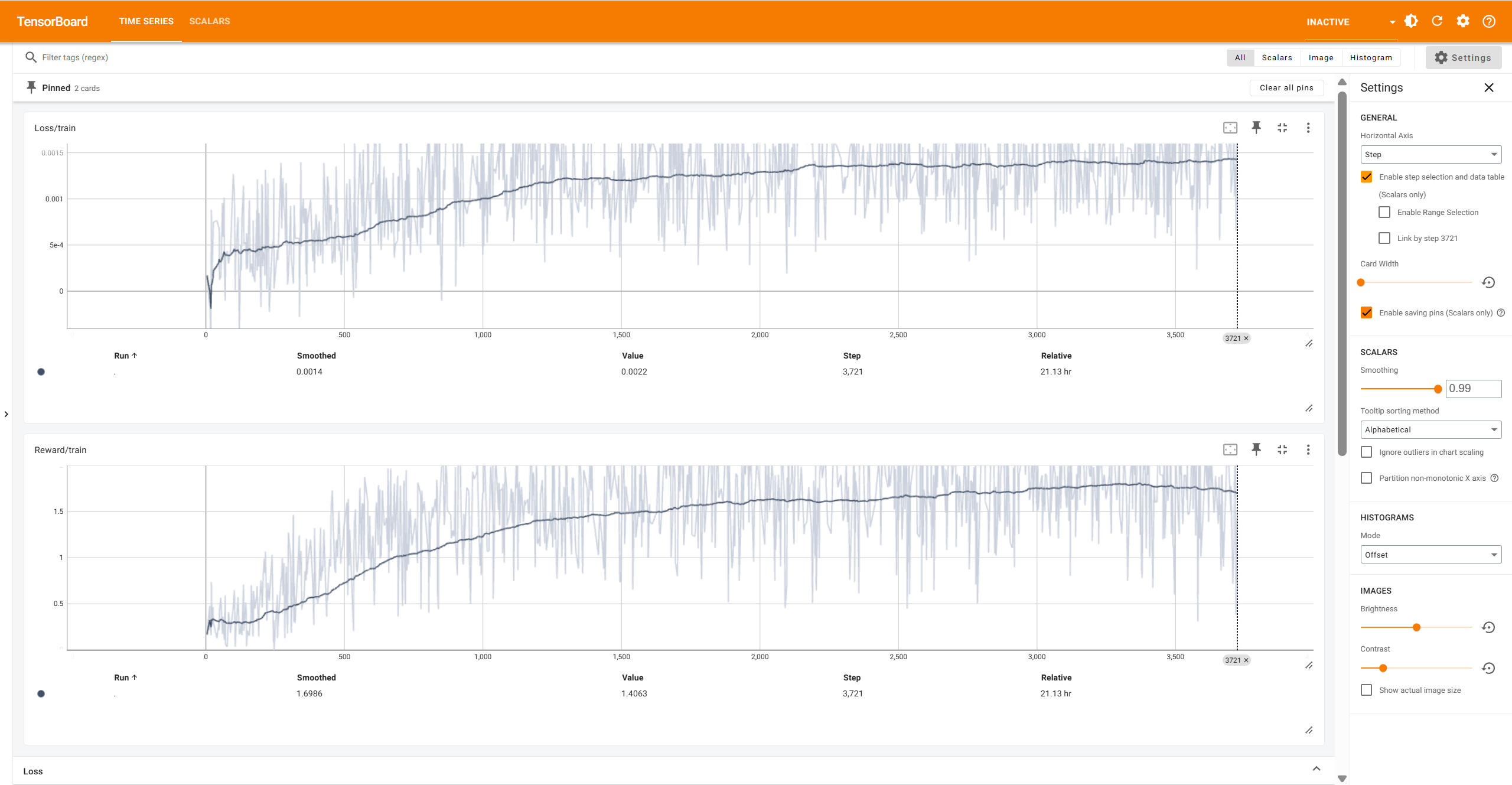
具体的代码就不贴了,这里把训练过程的reward曲线放上来。可以看出,这次训练花了21个小时,大部分时间都用于模型推理上,最终的reward基本稳定在1.6到1.8之间,是DLC1的两倍。
为了和之前的模型对比,这里还使用原代码的测试函数在测试集中选取了前50个样本进行了一次测试:

最后则是继续调用lm_eval命令获取评估效果:
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| gsm8k | 3 | flexible-extract | 0 | exact_match | ↑ | 0.5125 | ± | 0.0138 |
| strict-match | 0 | exact_match | ↑ | 0.0083 | ± | 0.0025 |
可以看出来,在使用lm_eval命令得到的效果上已经有点边际效应的感觉了,但同样是使用LoRA,使用GRPO微调已经比之前所有LoRA的效果要好了,证明这个在LLM上的GRPO确实是有可取之处。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)