「源力觉醒 创作者计划」百度开源“文心大模型4.5系列模型”,从业务场景横向纵向对比ERNIE-4.5-VL-28B-A3B-Paddle5种模型
在大数据AI人工智能时代,信息和流量是最大的财富,相较专有闭源模型带来直接的商业利润,以DeepSeek为代表的开源模型通过卓越性能+免费开源的低部署成本,一跃成为人工智能时代的基础设施,为未来发展带来更多可能。同时,开源大模型在凝聚全球开发者、建设智力共同体、快速优化模型能力、本地化部署适配各类场景等各个方面具有闭源模型无可比拟的优势,更有潜力塑造行业标准,营造出一个能够源源不断培育顶级科技产品
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
一、前言:
在大数据AI人工智能时代,信息和流量是最大的财富,相较专有闭源模型带来直接的商业利润,以DeepSeek为代表的开源模型通过卓越性能+免费开源的低部署成本,一跃成为人工智能时代的基础设施,为未来发展带来更多可能。
同时,开源大模型在凝聚全球开发者、建设智力共同体、快速优化模型能力、本地化部署适配各类场景等各个方面具有闭源模型无可比拟的优势,更有潜力塑造行业标准,营造出一个能够源源不断培育顶级科技产品的开放生态,同时也能通过云服务和硬软件等各种方式创造出不输于闭源模型的商业价值。

本人工作开发中一直使用的是Comate一站式智能编程助手,另外,百度智能云千帆AppBuilder也是有一段时间了,对于文心大模型的体验一直是比较不错的,今天趁此机会来实际评测一下“文心大模型4.5系列模型”,更加深入的体验与交流一下。
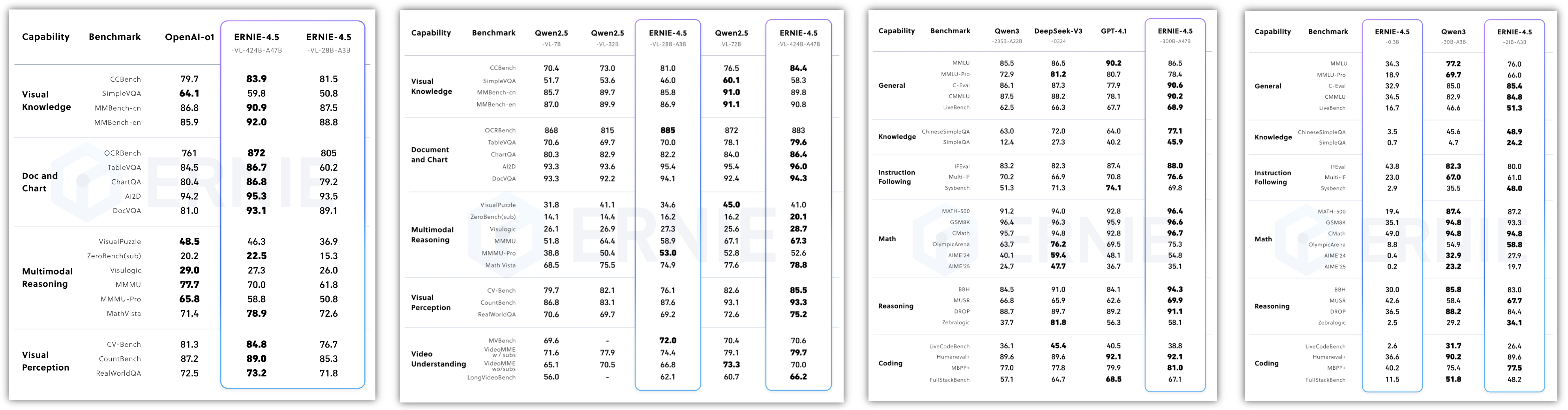
就在前几天6月30日,百度正式开源“文心大模型4.5系列模型”,文心是百度自主研发的产业级知识增强大模型,以创新性的知识增强技术为核心,从单模态大模型到跨模态、从通用基础大模型到跨领域、跨行业持续创新突破,构建了模型层、工具与平台层,大幅降低人工智能开发和应用门槛,加快人工智能大规模产业化进程并拓展人工智能技术边界,文心大模型,其中开源模型,具体统计的如下:

此次“文心4.5系列开源模型”一共22款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型,文心4.5系列模型均使用飞桨深度学习框架进行高效训练、推理和部署,预训练权重和推理代码完全开源,模型权重按照Apache 2.0协议开源,支持开展学术研究和产业应用。此外,基于飞桨提供开源的产业级开发套件,广泛兼容多种芯片,降低后训练和部署门槛。
ERNIE-4.5-VL-424B-A47B-Paddle是基于 PaddlePaddle 框架构建的模型,适用于复杂多模态任务场景,支持文本与视觉理解,备强大的图文生成、推理和问答能力。
二、“文心4.5系列开源模型”模型环境部署:
本文测试均以“DAMODEL”丹摩一站式智算平台,拥有丰富的算力资源与基础设施助力AI应用的开发、训练、部署。
2.1 PaddlePaddle(飞桨):
飞桨(PaddlePaddle)是“百度”推出的开源深度学习平台,集成深度学习核心框架、工具组件和服务平台为一体的技术先进、功能完备的开源深度学习平台,已被中国企业广泛使用,深度契合企业应用需求,拥有活跃的开发者社区生态,提供丰富的模型集合,并推出全类型的高性能部署和集成方案供开发者使用。
2.2 FastDeploy(高效模型部署):
FastDeploy 是基于飞桨的大模型快速高效部署套件,提供了一行代码开箱即用的多硬件部署体验,使用接口兼容vLLM和OpenAI协议,针对 ERNIE 4.5 模型部署提供了多级负载均衡的多机PD分离部署产业级方案,支持丰富的低比特量化推理、上下文缓存、投机解码等加速技术,提供模型加载、参数配置、接口调用等功能。
2.3 模型环境部署硬件要求:
在部署ERNIE-4.5相关模型时,哪怕是“ERNIE-4.5-0.3B”也需要具备较强的硬件支持,尤其是GPU显卡资源(推荐在80G以上),以下是本文在云实例上测试使用的服务器硬件相关配置信息:

2.4 云算力平台创建GPU实例环境准备:
因为需要较强的硬件资源,一般本机的配置不足以进行搭建与测试,现在有许多的算力云平台(“DAMODEL”丹摩一站式智算平台)可以提供AI算力及GPU服务器租用和GPU云主机租用的算力租赁平台,适用于各种AI深度学习、高性能计算、渲染测绘、云游戏等算力租用各种场景。
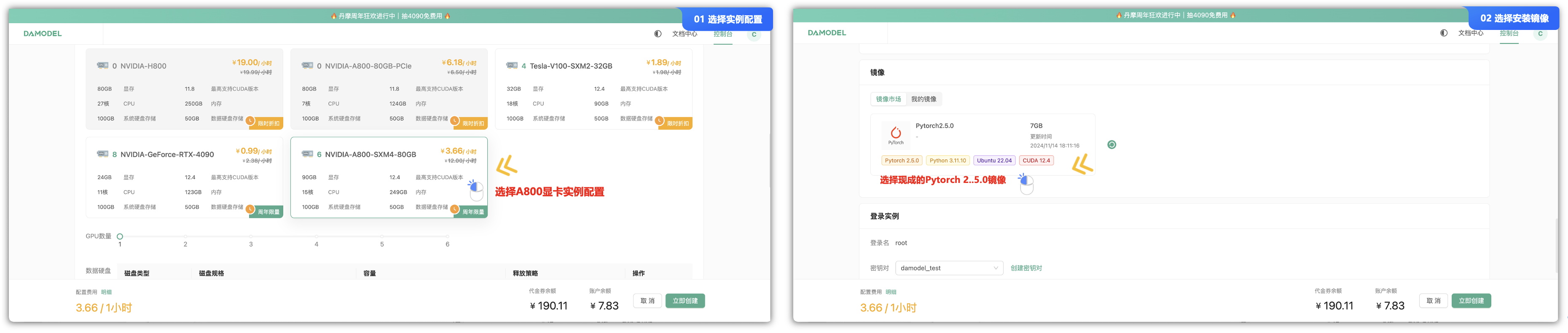
首先登录“DAMODEL”丹摩一站式智算平台的控制台,这里先创建一个GPU云实例,在此之前已经踩过很多坑了,这里直接总结能够直接使用的方案:
- ①. 菜单栏“GPU云实例”中,选择“创建实例”,选择“NVIDIA-A800-SXM4-80GB”实例配置,按量计费的模型,费用可以看到不到4块钱一小时,也在可控范围内。
- ②. 在镜像中,我们可以直接选择官方提供的“Pytorch 2.5.0”的镜像源即可,里面包含了一些基础的Python 3.11.10、CUDA 12.4等软件,不需要再从0到1安装相关依赖。
- ③. 创建云实例成功后,我们可以这实例连接的方式,这里有2种方式:一种是SSH密钥连接,一种是JupyterLab可视化的工具来连接(推荐)。
- ④. 进入JupyterLab可视化的工具的shell命令控制台中进行操作。
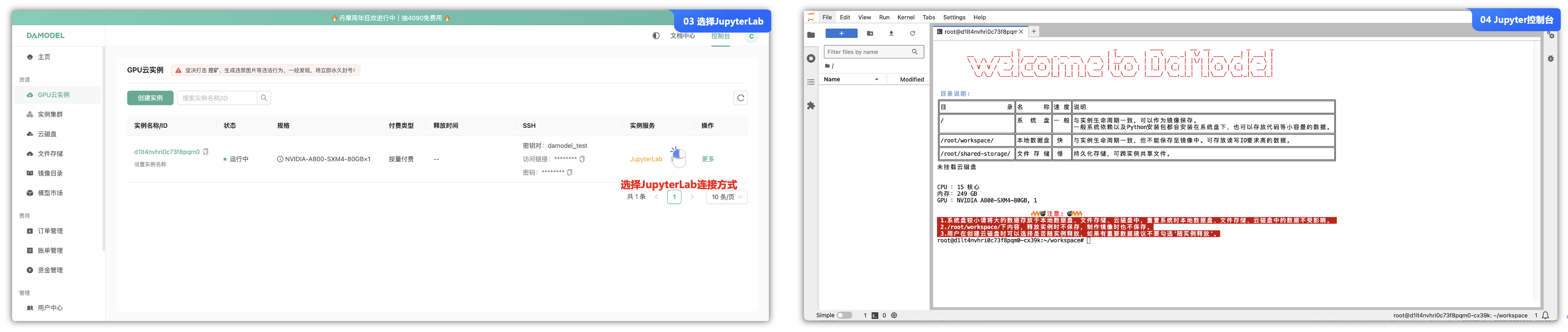
当然,可以选择自己合适的云算力云平台来进行实验。
2.5 三步曲极速安装依赖:
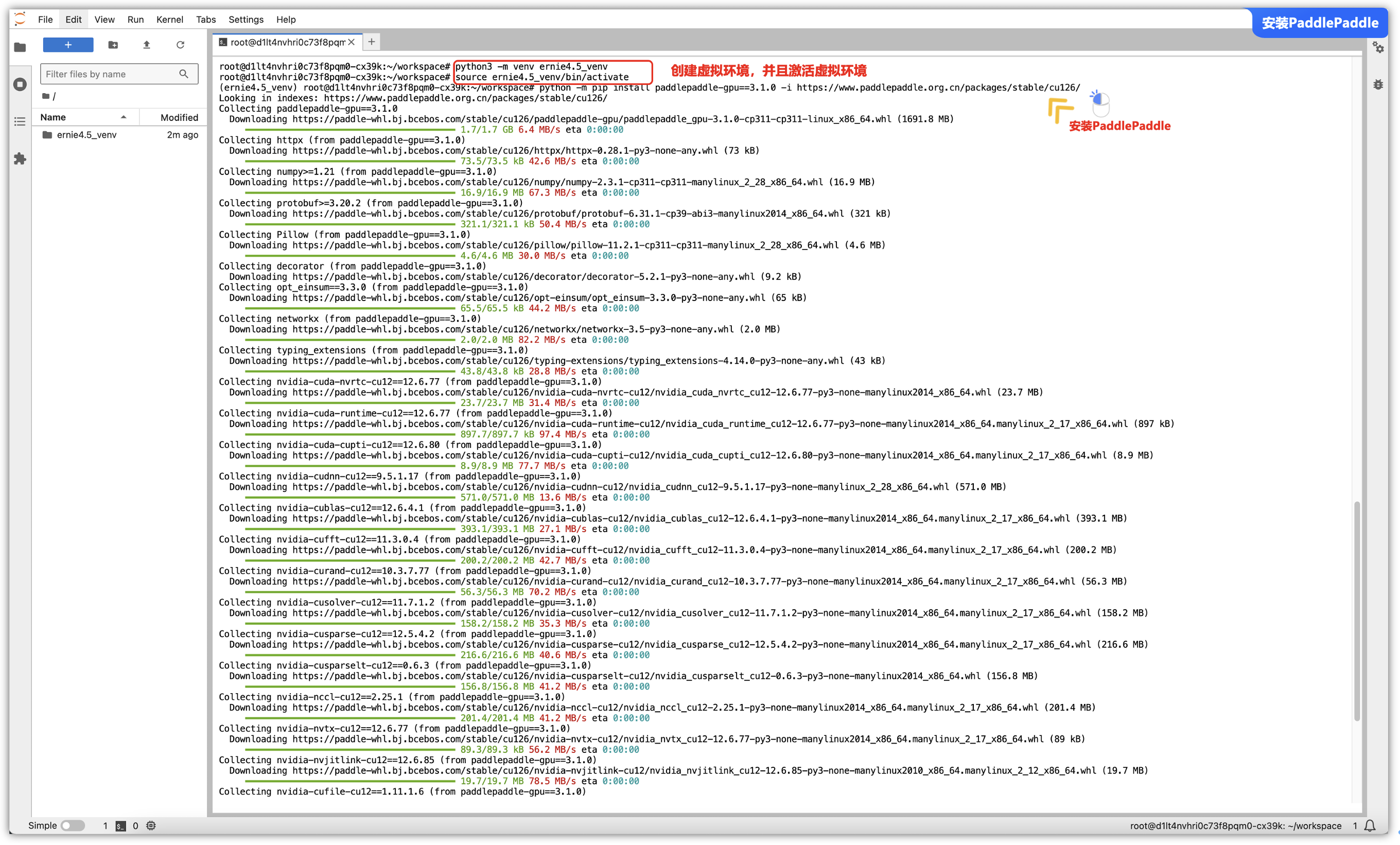
第一步 – 安装虚拟环境:
由于一些权限、避免污染本机环境的问题,推荐使用python的虚拟环境,允许在同一台计算机上为不同的项目安装不同版本的Python解释器以及不同的库,而不会互相干扰,这样可以避免库之间的冲突,使得项目依赖更加清晰和可控。
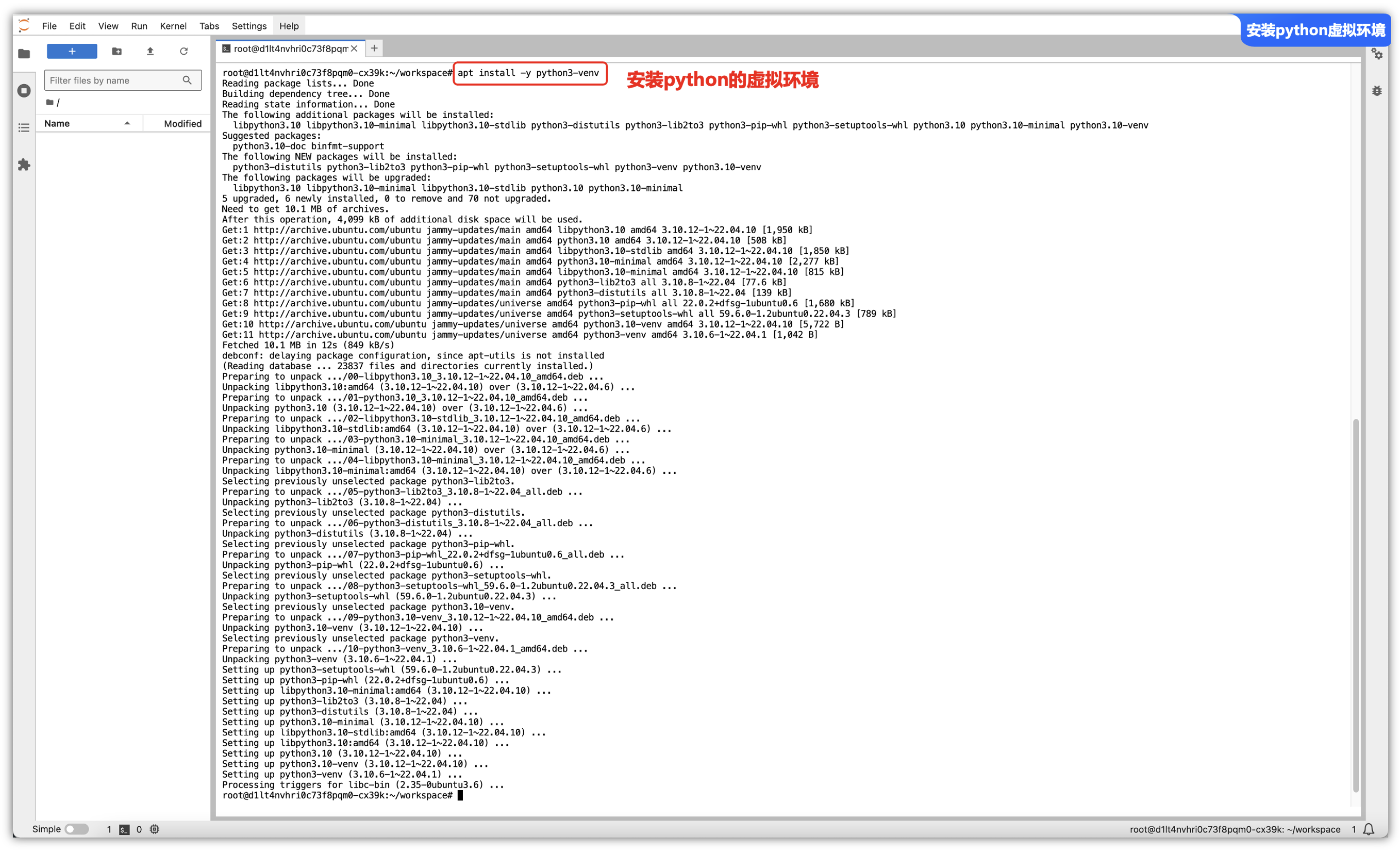
安装完成python虚拟环境后,我们可以进行创建一个虚拟环境并且激活这个虚拟环境,后续的所有操作就在这个虚拟环境中进行操作:
sudo apt-get install -y python3-venv
python3 -m venv ernie4.5_venv
source ernie4.5_venv/bin/activate
第二步 - 安装“PaddlePaddle-GPU” 版本:
确保安装与Paddle-GPU匹配的CUDA驱动,不同Gpu的安装命令不一样,可以根据具体环境选择正确的 CUDA 版本(如 cu113、cu118、cu126),按照自己的情况进行安装,不同Gpu的安装命令:
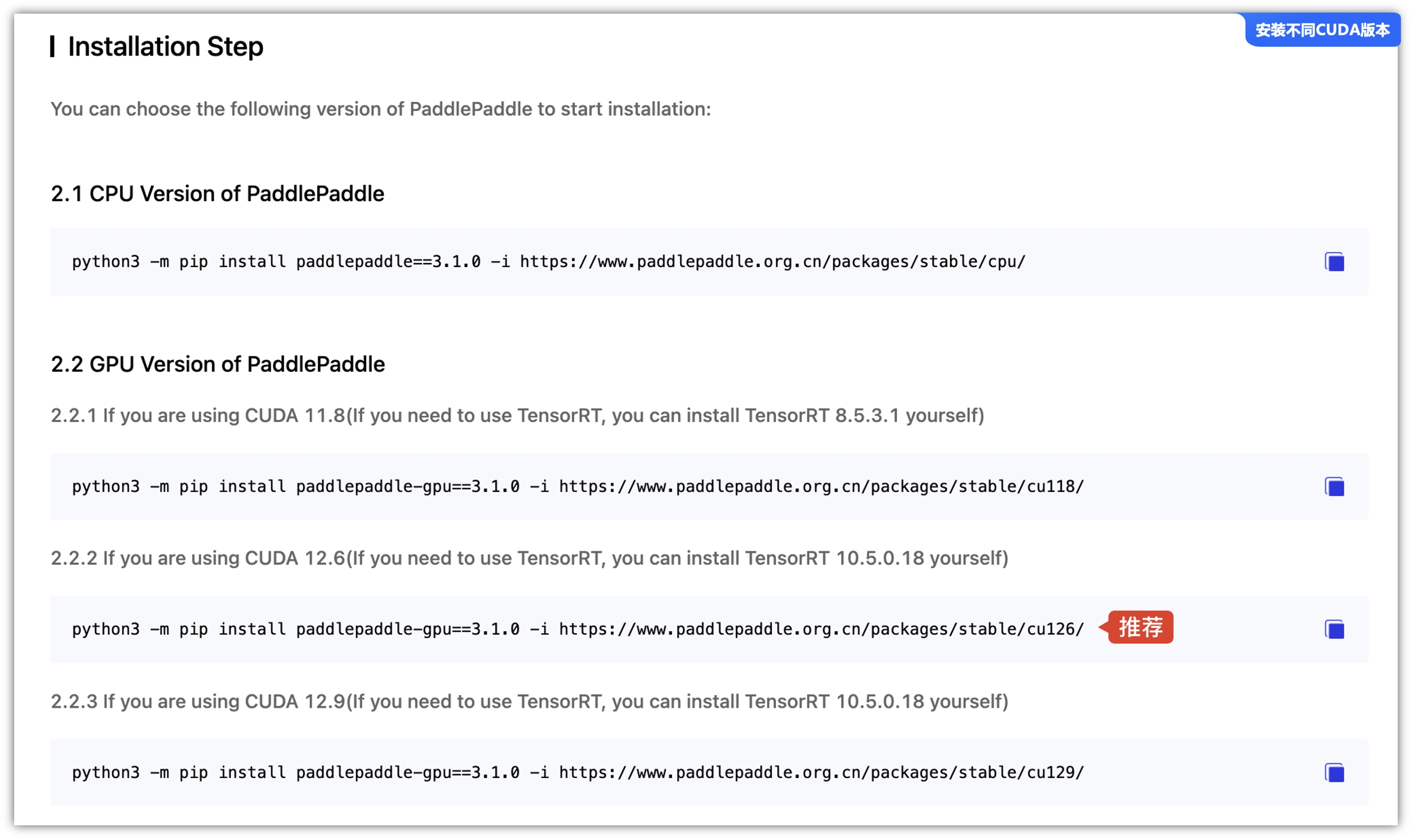
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
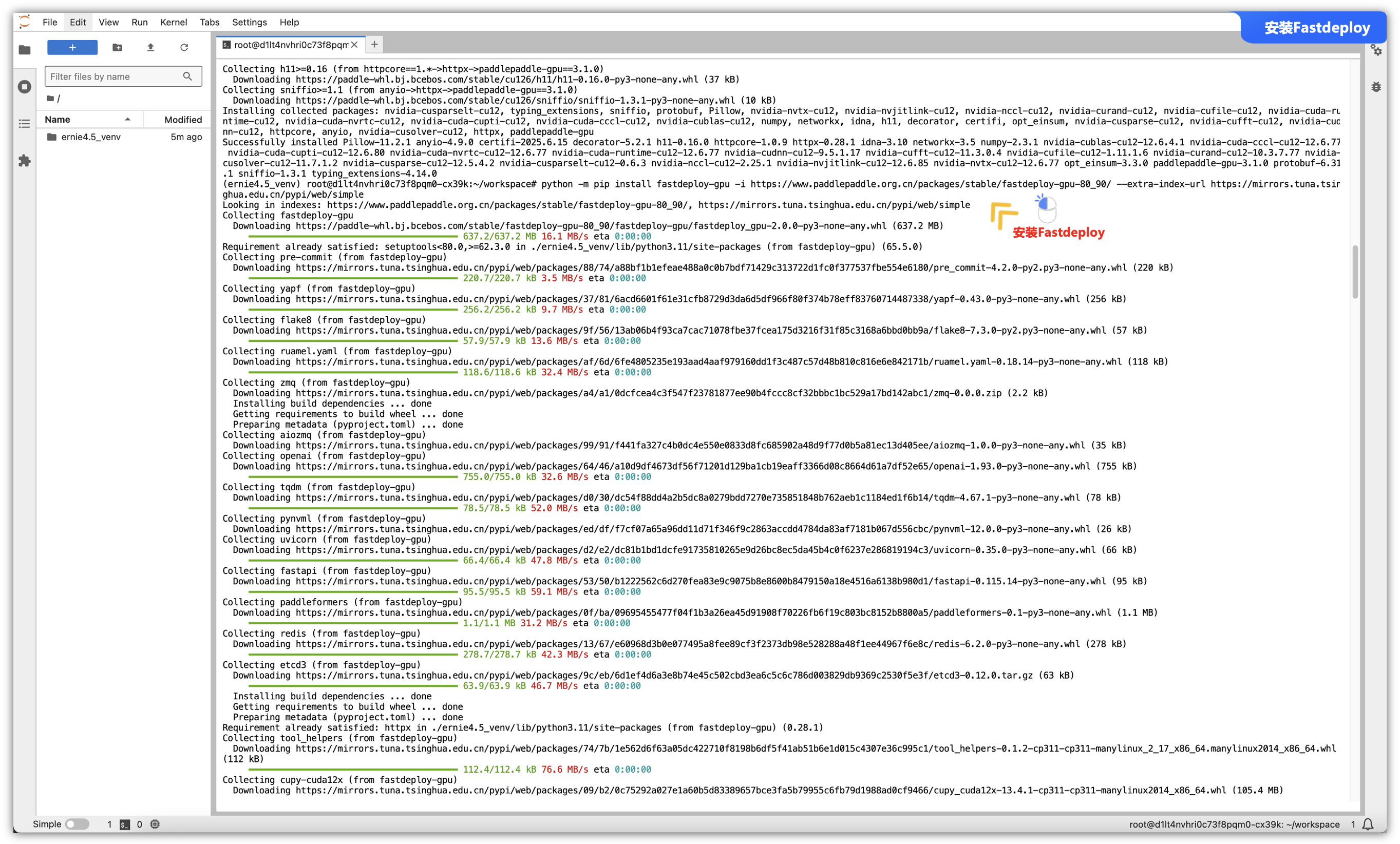
第三步 - 安装“Fastdeploy”:
同理,也需要像上面一样区分不同gpu的安装命令不一样,如针对 SM80/90 架构(如 A30/A100/H100)使用如下命令安装 FastDeploy:
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-86_89/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
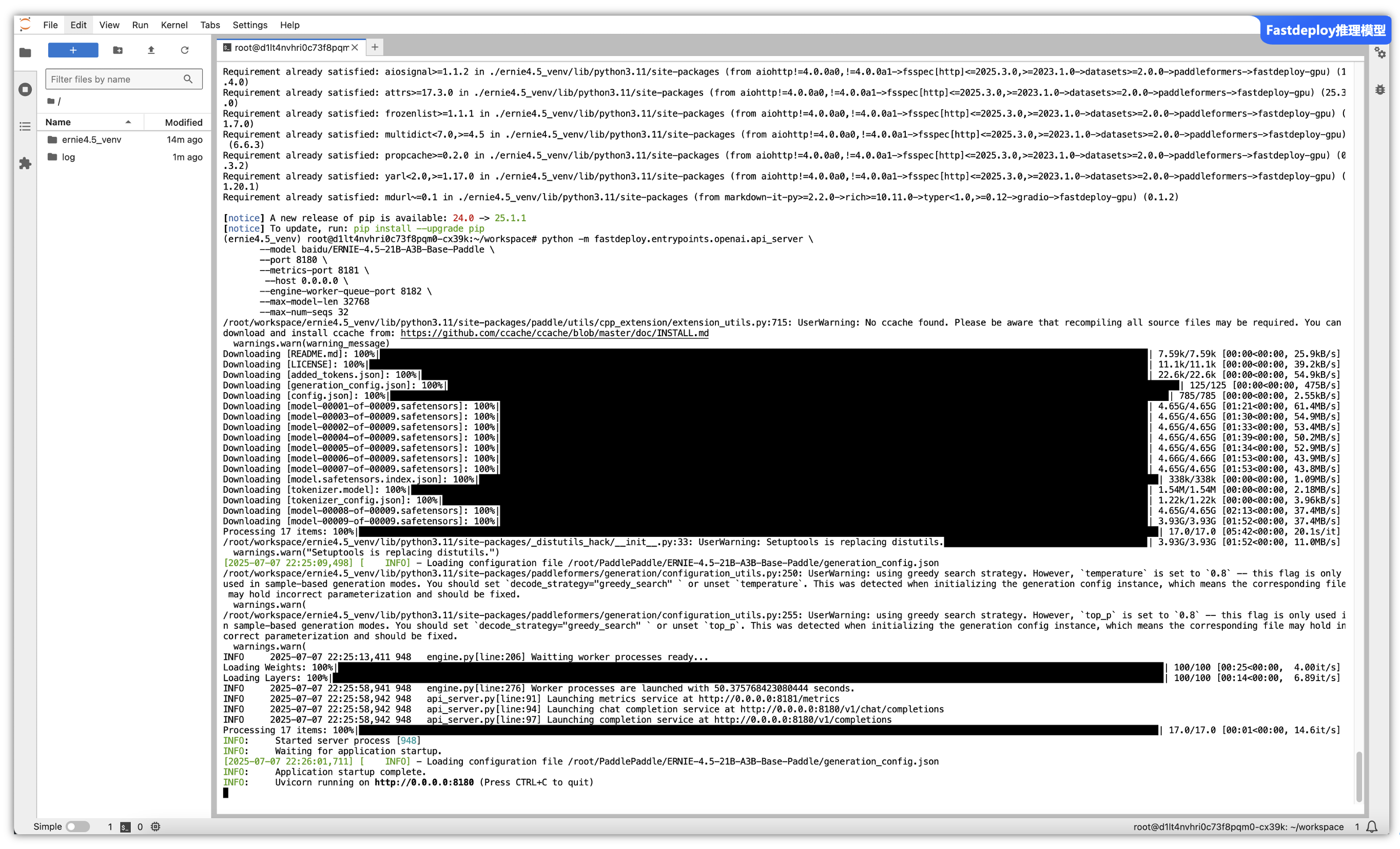
第四步 - FastDeploy 推理:
借助FastDeploy 快速部署服务,注意: 对于单卡部署,至少需要 80GB 的 GPU 内存(使用Tesla-P40 6G内存一直提示Failed to launch worker processes内存太低了):
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-21B-A3B-Base-Paddle \
--port 8180 \
--metrics-port 8181 \
--host 0.0.0.0 \
--engine-worker-queue-port 8182 \
--max-model-len 32768
--max-num-seqs 32
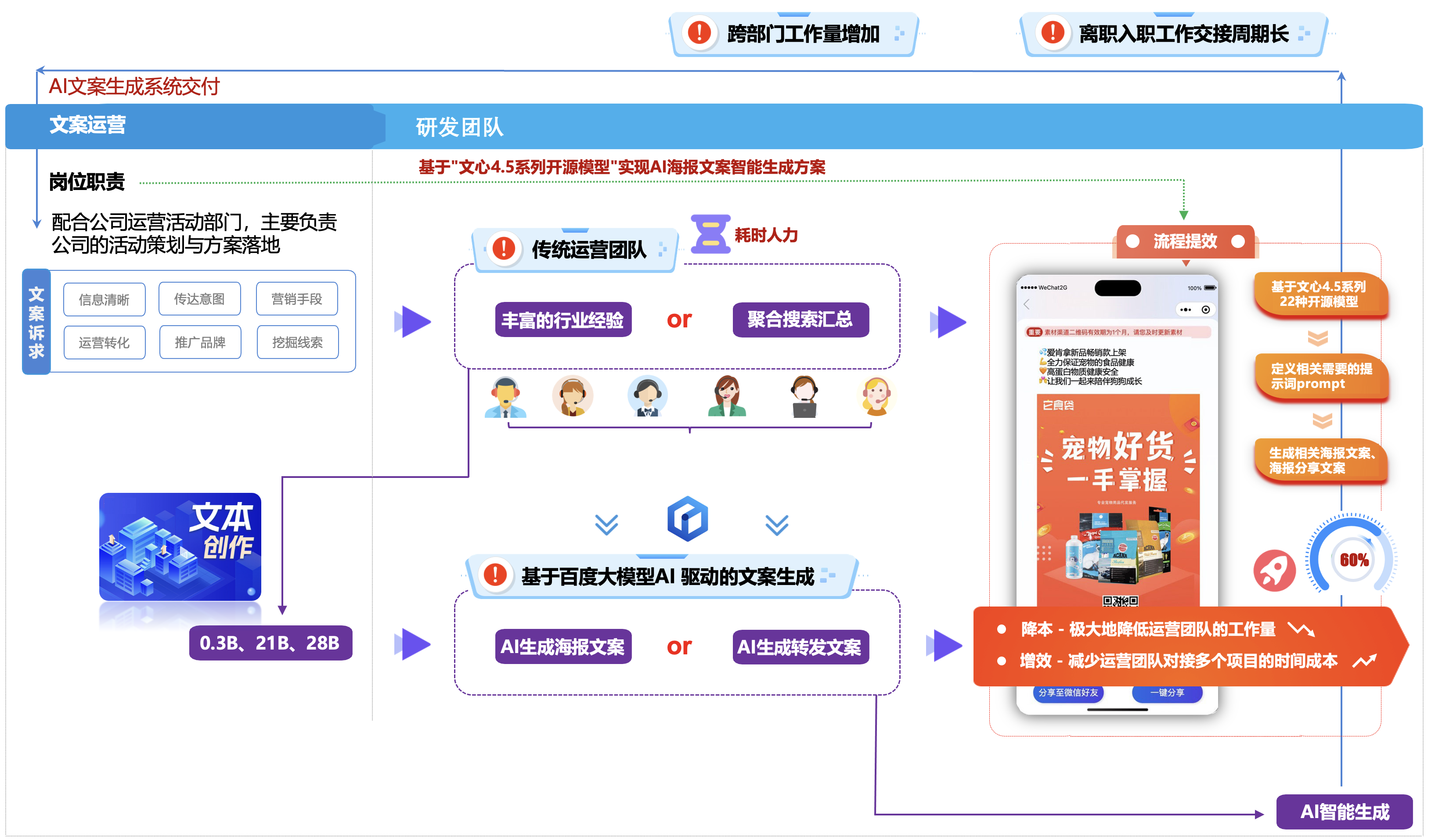
三、实际业务场景评测说明:
文案内容可以帮助企业更好地推广品牌和产品,还可以帮助企业更好地说明自己的产品和服务,为潜在客户提供解决方案,从而吸引更多的客户,促进企业的发展,文案在企业社交媒体运营中具有不可或缺的作用。
互联网产品的核心点就是流量为王,为了配合公司运营活动部门,主要负责公司的活动策划与方案落地,高效的激发流量并进行转化,经常需要使用小程序中的海报功能用于业务推广,而且活动的类型也比较繁杂,比如说库存清理、新品上市、阶梯式折扣、促销活动、秒杀活动等等。
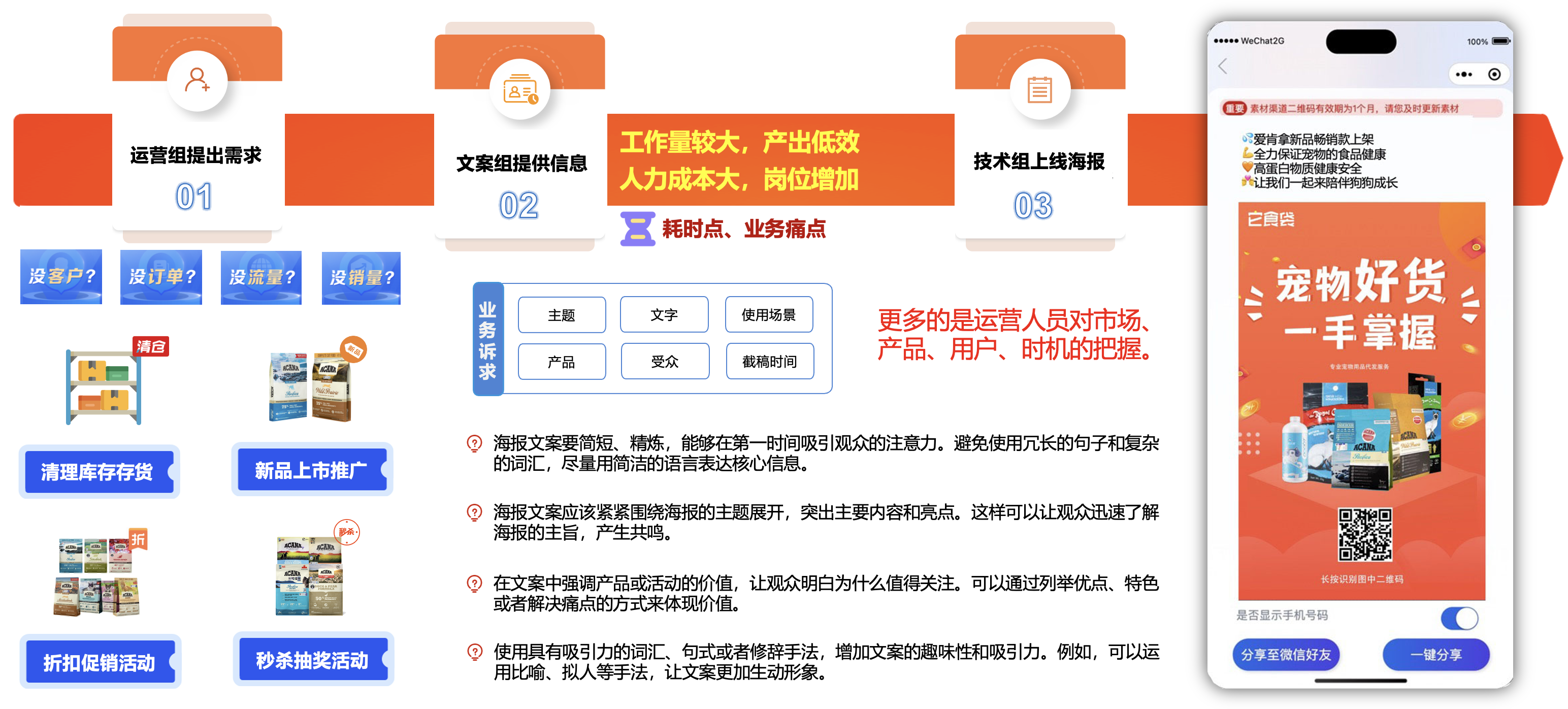
但是,想要写好海报文案和分享文案需要很多的技巧,以确保信息清晰、吸引人,并能有效传达意图。同时,也需要花费大量的时间来思考,通常运营人员需要大量百度一些文案来参考,非常的耗费时间、人力、资源。
【公司实际业务设计方案】:
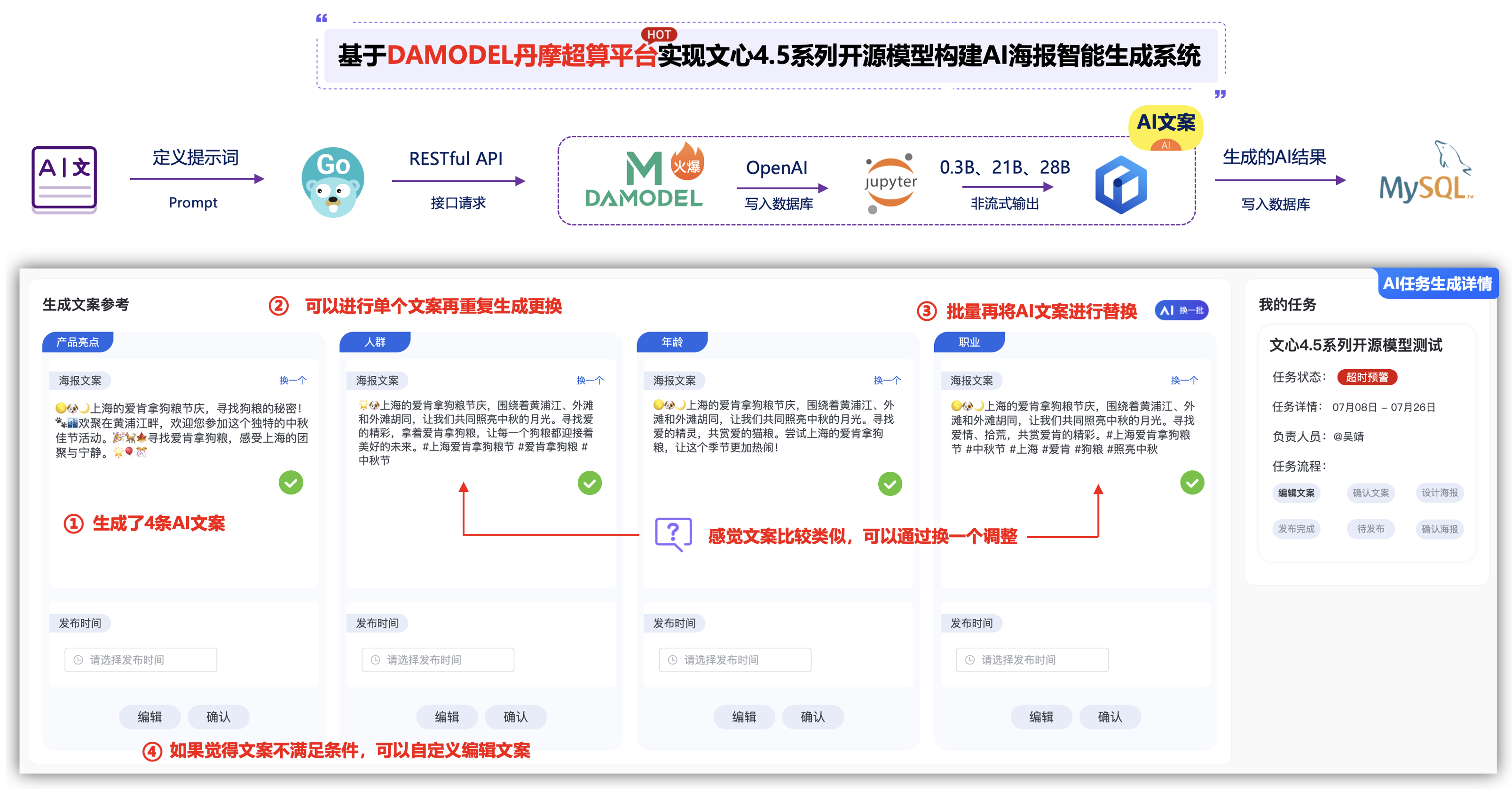
通过对大模型的学习,发现能够通过给出一些提示词Prompt(提示词),即可以自然语言AI生成需要分析出需要的结果,那么企业内部是通过一些提示词来调用“豆包”的大模型AI来生成所需要的海报、分享的文案,顺着这个思路,我们大概梳理一下功能实现的步骤,思路是如下:
- ①. 定义好提示词,即生成文案的主题、使用场景、受众等信息。
- ②. 通过调用“豆包Agent智能体”来AI生成相关需要的海报、分享的文案。
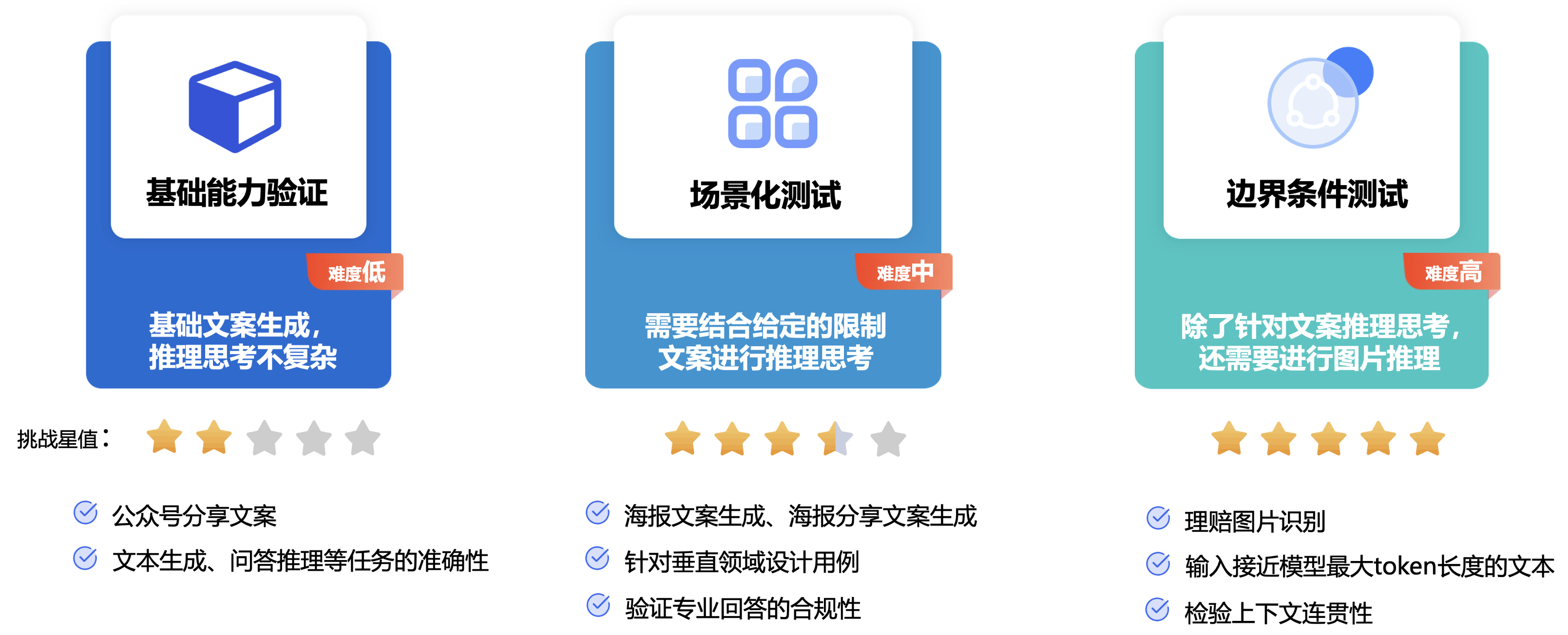
3.1 “文心4.5系列开源模型”横向场景测评:
横向场景评测,指相同的厂商的大模型(“文心4.5系列开源模型”)系列,找出几个比较重点的模型来进行实际测试与比较,以下是选出了三种模型配置的详细信息如下,可以看到0.3B与A3B系列还是有明显的差距的,另外28B明显是支持多模态的。
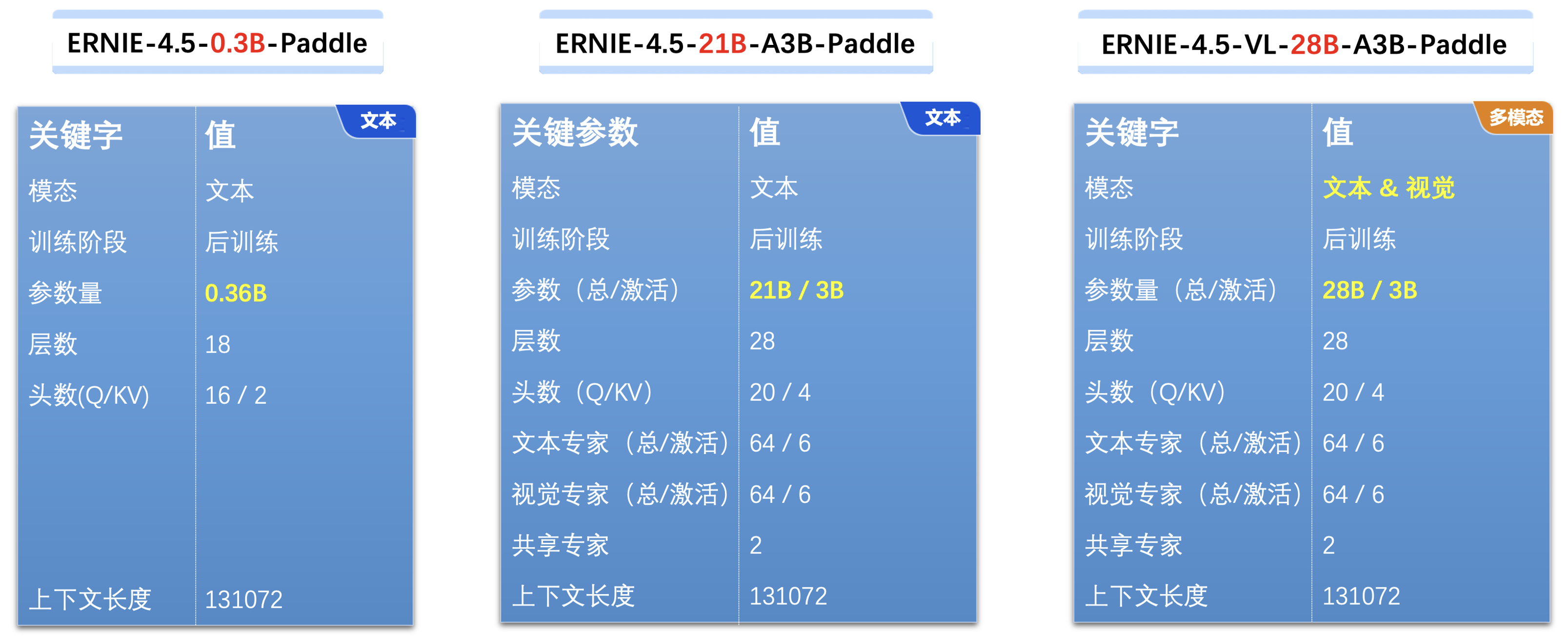
整体对三个模型进行了测试,这里是整体的架设过程的基础数据,可供参考。
四、基础能力测试 - 微信自定义卡片文案生成对比:
微信公众号页面提供了转发给朋友的功能,如果没有设置隐藏“发送给朋友”,就可以转发给朋友,在微信公众号开发中,实现网页分享时的自定义卡片展示是提升用户体验和传播效果的重要手段,实现包含自定义Logo、标题和描述的分享卡片功能。

相关大模型prompt - “帮我生成爱肯拿产品购买的微信分享标题和分享文案,标题控制在10个字左右,文案内容控制在15个字左右”。
4.1 ERNIE-4.5-0.3B-Paddle实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
帮我生成爱肯拿产品购买的微信分享标题和分享文案,标题控制在10个字左右,文案内容控制在15个字左右
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-0.3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()

- ①. 响应效率:最大2.02秒、最小0.14秒、平均0.939秒
- ②. 质量准确性:最大3.5分、最小1分、平均2.35分
- ③. 结果解析:
-
- 时间来看的话,基本在1-2秒可以完成
-
- 有一个文案有emoji表情支持
-
- 大部分文案控制在15字以内
-
- 格式都比较官方、统一
-
- ④. 问题点:
-
- 所有生成文案均看不出与宠物行业有关
-
- 大部分没有将标题与文案进行对应分离
-
- 少量结果包含其它解释文案
-
- 最后一个文案字数超标了
-
4.2 ERNIE-4.5-21B-A3B-Paddle实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
帮我生成爱肯拿产品购买的微信分享标题和分享文案,标题控制在10个字左右,文案内容控制在15个字左右
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-21B-A3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()

- ①. 响应效率:最大5.59秒、最小2.99秒、平均4.282秒
- ②. 质量准确性:最大7分、最小5分、平均5.8分
- ③. 结果解析:
-
- 生成时间基本上比0.3B模型要慢一倍
-
- 所有文案是与宠物行业相关
-
- 所有文案控制在15字以内
-
- 格式都比较官方、统一
-
- ④. 问题点:
-
- 所有生成文案太书面
-
- 大部分没有将标题与文案进行对应分离
-
- 少量结果包含其它解释文案
-
- 最后一个文案字数超标了
-
4.3 ERNIE-4.5-VL-28B-A3B-Paddle实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
帮我生成爱肯拿产品购买的微信分享标题和分享文案,标题控制在10个字左右,文案内容控制在15个字左右
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-VL-28B-A3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()


- ①. 响应效率:最大11.65秒、最小8.76秒、平均10.204秒
- ②. 质量准确性:最大10分、最小7分、平均8.8分
- ③. 结果解析:
-
- 生成时间基本上在10s左右
-
- 所有标题和文案没有重复爱肯拿
-
- 格式都书面语,且带有人性化一点
-
- ④. 问题点:
-
- 生成文案的时间适中,平均在10秒
-
- 包含大量的解释性文案与思考逻辑
-
- 少量结果包含emoji表情
-
- 生成文案普遍质量偏高
-
4.4 DeepSeek-V3实测结果如下:
import requests
import json
import time
content = """
帮我生成爱肯拿产品购买的微信分享标题和分享文案,标题控制在10个字左右,文案内容控制在15个字左右
"""
if __name__ == '__main__':
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "z7oTlikfxSQHMjnCWwbR_dyvV2cRU-adVZJWPQ" # 把yourApiKey替换成已获取的API Key
for i in range(3):
print(f"\n执行第{i+1}次:")
start_time = time.time()
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-V3", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": content}
],
"stream": False,
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# Print result.
print(f"状态码:{response.status_code}")
print(f"响应内容:{response.text}")
end_time = time.time()
execution_time = end_time - start_time
print(f"执行时间:{execution_time:.2f}秒\n{'-'*50}")

- ①. 响应效率:最大5.88秒、最小1.38秒、平均3.682秒
- ②. 质量准确性:最大3分、最小1分、平均1.9分
- ③. 结果解析:
-
- 生成时间基本上比0.3B模型要慢一倍
-
- 大部分文案是与宠物行业相关
-
- 所有文案太简短,控制在10字以内
-
- 格式稍微比较正式一点
-
- ④. 问题点:
-
- 所有生成文案太简短
-
- 选择性更少一点,只生成了1-2条文案
-
- 一半的结果包含其它解释文案
-
4.5 DeepSeek-R1实测结果如下:
import requests
import json
import time
content = """
帮我生成爱肯拿产品购买的微信分享标题和分享文案,标题控制在10个字左右,文案内容控制在15个字左右
"""
if __name__ == '__main__':
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "z7oTlik43cEtdVZJWPQ" # 把yourApiKey替换成已获取的API Key
for i in range(10):
print(f"\n执行第{i+1}次:")
start_time = time.time()
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-R1", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": content}
],
"stream": False,
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# Print result.
print(f"状态码:{response.status_code}")
print(f"响应内容:{response.text}")
end_time = time.time()
execution_time = end_time - start_time
print(f"执行时间:{execution_time:.2f}秒\n{'-'*50}")


- ①. 响应效率:最大39.54秒、最小21.27秒、平均29.911秒
- ②. 质量准确性:最大7分、最小3分、平均5.3分
- ③. 结果解析:
-
- 生成时间基本上都比较久
-
- 所有文案是与宠物行业相关
-
- 格式都非标准化,偏向于人性化一点
-
- ④. 问题点:
-
- 生成文案的时间太久了,平均在30秒
-
- 包含大量的解释性文案与思考逻辑
-
- 少量结果包含其它解释文案
-
- 少部分生成文案存在语句问题
-
4.6 横向/纵向模型对比(5种不同的大模型进行对比):
本次测评的模型主要有开源的ERNIE-4.5系列(ERNIE-4.5-0.3B-Paddle、ERNIE-4.5-21B-A3B-Paddle、ERNIE-4.5-VL-28B-A3B-Paddle
)以及其他主流开源模型:如DeepSeek-V3、DeepSeek-R1等,分别从通用能力(基础能力验证)、推理能力(场景化测试)、多模态任务能力(边界条件测试)等五个维度来测评和对比模型的性能指标。

五、场景化测试 - 微信小程序好友/朋友圈海报文案与海报分享文案生成:
微信小程序的好友/朋友圈海报文案与海报分享文案生成功能,是通过自动化工具整合图文设计、动态数据绑定及社交传播能力,为用户快速创建适配微信社交场景的推广素材的系统级解决方案,是一个专为营销推广设计的工具,主要帮助用户快速创建吸引人的社交分享内容。此功能特别适合电商、教育、本地生活类小程序,通过降低用户分享成本,快速激活私域流量传播。

相关大模型prompt提示词内容:
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
5.1 ERNIE-4.5-0.3B-Paddle实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-0.3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()
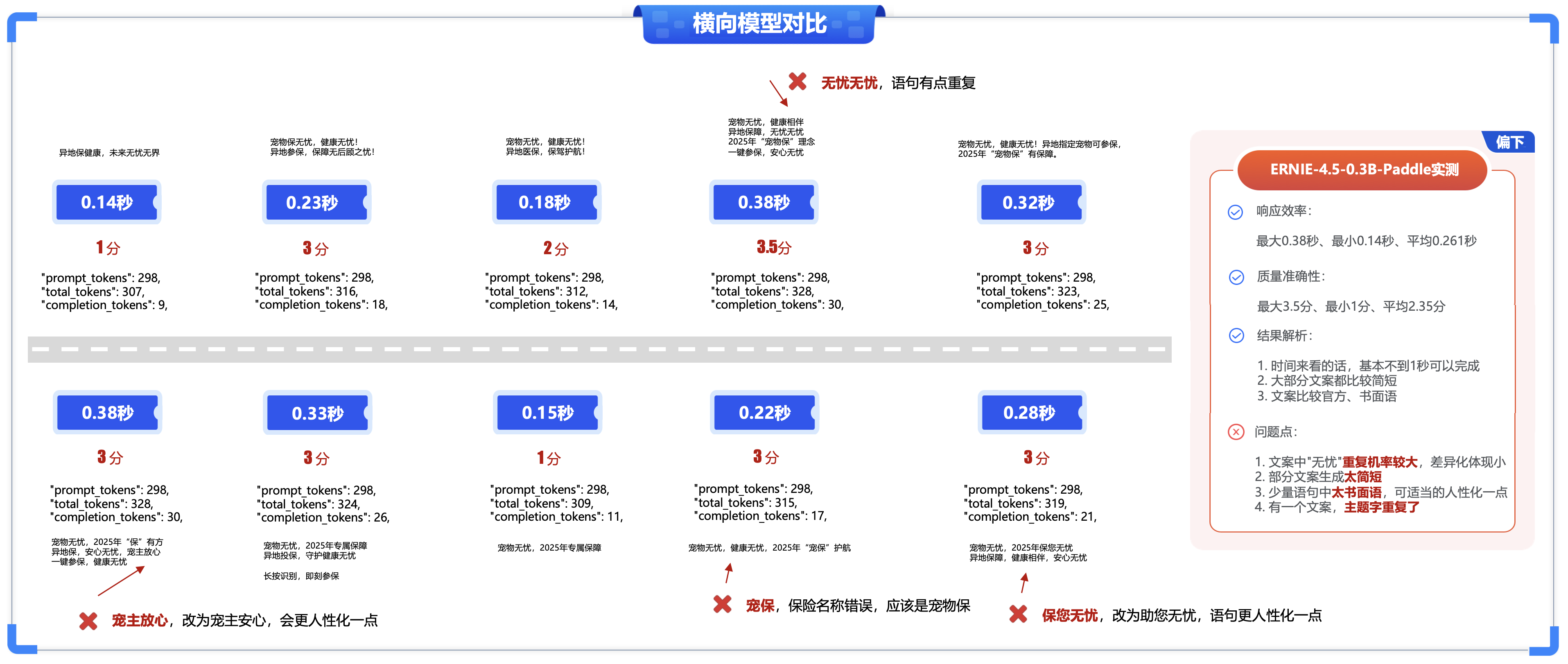
- ①. 响应效率:最大0.38秒、最小0.14秒、平均0.261秒
- ②. 质量准确性:最大3.5分、最小1分、平均2.35分
- ③. 结果解析:
-
- 时间来看的话,基本不到1秒可以完成
-
- 大部分文案都比较简短
-
- 文案比较官方、书面语
-
- ④. 问题点:
-
- 文案中"无忧"重复机率较大,差异化体现小
-
- 部分文案生成太简短
-
- 少量语句中太书面语,可适当的人性化一点
-
- 有一个文案,主题字重复了
-
5.2 ERNIE-4.5-21B-A3B-Paddle实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-21B-A3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()

- ①. 响应效率:最大3.65秒、最小2.93秒、平均3.41秒
- ②. 质量准确性:最大6.5分、最小6分、平均6.2分
- ③. 结果解析:
-
- 生成时间基本上比0.3B模型要慢2-3秒
-
-
- 会将本条生成文案的依据返回回来
-
- 文案的重复率较低
-
- 格式都比较官方、比较统一
- ④. 问题点:
-
- "宠物保"需要加上2025
-
- 会返回生成文案的依据,增加token
-
- 最好直接返回需要的结果
-
5.3 ERNIE-4.5-VL-28B-A3B-Paddle实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-VL-28B-A3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()
- ①. 响应效率:最大11.65秒、最小8.76秒、平均10.204秒
- ②. 质量准确性:最大10分、最小7分、平均8.8分
- ③. 结果解析:
-
- 生成时间基本上在10s左右
-
- 所有标题和文案没有重复爱肯拿
-
- 格式都书面语,且带有人性化一点
-
- ④. 问题点:
-
- 生成文案的时间适中,平均在10秒
-
- 包含大量的解释性文案与思考逻辑
-
- 少量结果包含emoji表情
-
- 生成文案普遍质量偏高
-
5.4 DeepSeek-R1实测结果如下:
“文心4.5系列开源模型”Python代码调用大模型实例参考:
import requests
import json
import time
from datetime import timedelta
content = """
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
"""
def main():
# 设置API端点
url = f"http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "ERNIE-4.5-VL-28B-A3B-Paddle",
"messages": [
{
"role": "user",
"content": content
}
],
"temperature": 0.7, # 可选参数:控制响应随机性
"max_tokens": 2000 # 可选参数:最大生成长度
}
for i in range(10):
print(f"\n执行第{i+1}次:")
print("-" * 50)
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
except requests.exceptions.ConnectionError:
print(f"连接错误: 无法访问 {url},请确保服务已启动且端口开放")
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,原始响应: {response.text}")
except Exception as e:
print(f"发生未知错误: {e}")
print("-" * 50)
print(f"第{i+1}次执行完成\n")
if __name__ == "__main__":
main()


-
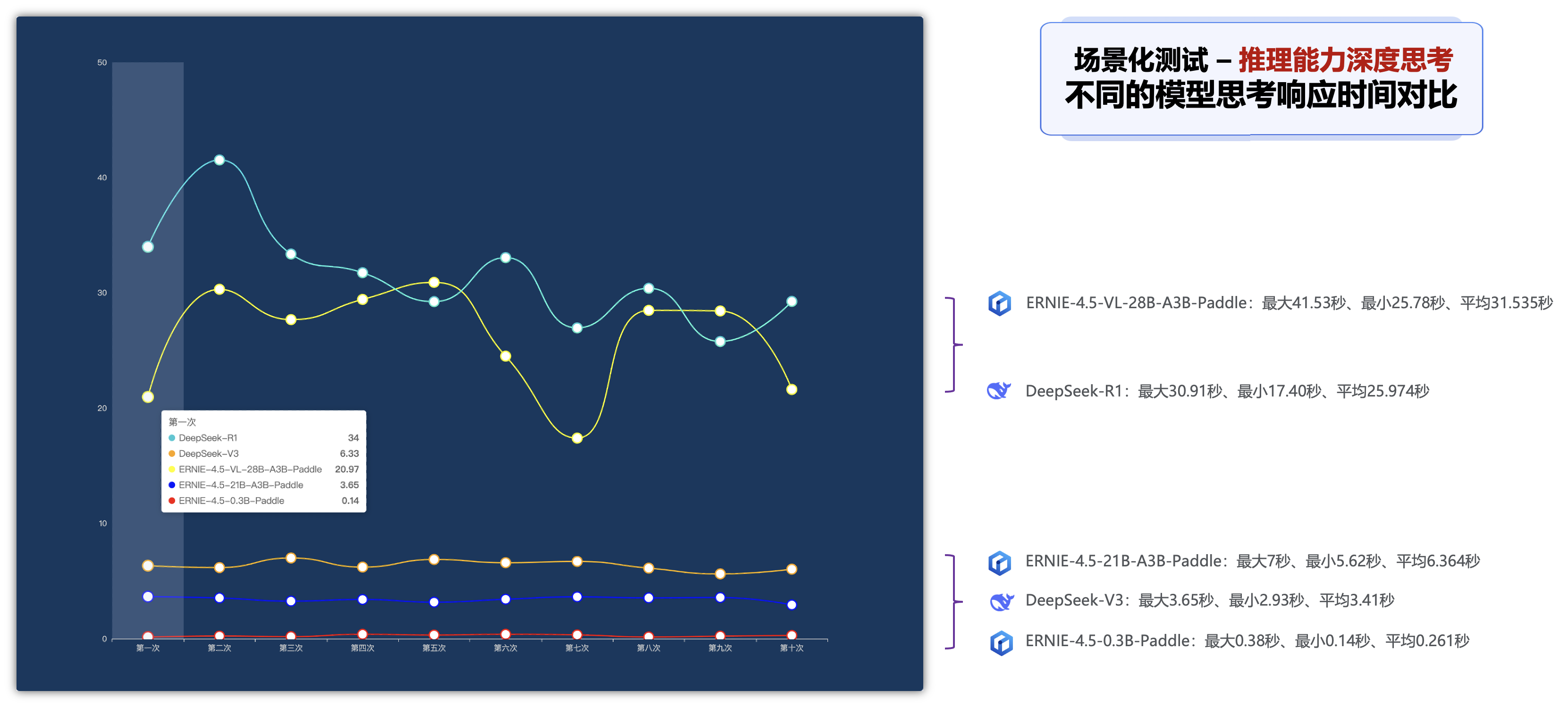
①. 响应效率:最大30.91秒、最小17.40秒、平均25.974秒
-
②. 质量准确性:最大9分、最小7分、平均8.1分
-
③. 结果解析:
-
- 生成时间基本上在25s左右
-
- 思考的过程,有针对学生人群
-
- 部分思考将学生转化为宠物主人,比白领、城市人员转化要稍微好点
-
-
④. 问题点:
-
- 生成文案的时间比较长,平均在25秒
-
- 包含大量的解释性文案与思考逻辑
-
5.5 DeepSeek-V3实测结果如下:
import requests
import json
import time
content = """
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
"""
if __name__ == '__main__':
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "z7oTlikfxSQHMjnCWhs-O2MTbjK4DSiso43cEtdVZJWPQ" # 把yourApiKey替换成已获取的API Key
for i in range(3):
print(f"\n执行第{i+1}次:")
start_time = time.time()
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-V3", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": content}
],
"stream": False,
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# Print result.
print(f"状态码:{response.status_code}")
print(f"响应内容:{response.text}")
end_time = time.time()
execution_time = end_time - start_time
print(f"执行时间:{execution_time:.2f}秒\n{'-'*50}")

- ①. 响应效率:最大7秒、最小5.62秒、平均6.364秒
- ②. 质量准确性:最大3分、最小1分、平均2.25分
- ③. 结果解析:
-
- 生成时间基本上在6秒左右
-
- 所有文案生成的关键词会自动更换
-
- 所有文案都返回了关键词
-
- 格式都比较偏口语一点
-
- ④. 问题点:
-
- 所有生成文案基于关键词好多错误,所以基于的文案生成会理解错误
-
- 有一个文案没有返回海报文案
-
- 有一个文案语句上下文不通畅
-
5.6 DeepSeek-R1实测结果如下:
import requests
import json
import time
content = """
1.融合产品亮点综合创作
2.使用标点符号,创造紧迫感
3.海报文案严禁出现表情
4.按照以下步骤进行创作:
-梳理输入关键词
-明确海报针对人群
-找到关键词链接点,确定创意主题
-结合植入2025年“宠物保”产品亮点或理念
-生成精彩海报文案
## 示例
----------
关键词梳理:学生、保障、健康、保险、2025年“宠物保”
针对人群:学生群体
创意主题:为未来宠物健康保驾护航
产品亮点:异地指定宠物可参保、有保可保门槛低
海报文案:
学生无忧,健康未来
异地医保,保障无界限
带病可保,守护每一份希望
立即参保,为未来加分
长按识别 即可参保
----------
## 限制:
- 严格按照步骤分析
- 严格按照示例格式生成文案,只按照格式不按照内容生成。
- 严格围绕输入的信息为主题combined with产品亮点创作文案。
- 仅能从产品亮点中生成文案。
- 文案必须严格控制在 3行到4行,不超过30个字。
- 无论输入什么只输出文案,严禁输出其他信息。
- 严格执行输出书面话文案
"""
if __name__ == '__main__':
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "z7oTlik43cEtdVZJWPQ" # 把yourApiKey替换成已获取的API Key
for i in range(10):
print(f"\n执行第{i+1}次:")
start_time = time.time()
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-R1", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": content}
],
"stream": False,
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# Print result.
print(f"状态码:{response.status_code}")
print(f"响应内容:{response.text}")
end_time = time.time()
execution_time = end_time - start_time
print(f"执行时间:{execution_time:.2f}秒\n{'-'*50}")


-
①. 响应效率:最大41.53秒、最小25.78秒、平均31.535秒
-
②. 质量准确性:最大6分、最小3分、平均4.15分
-
③. 结果解析:
-
- 生成时间基本上在30秒左右
-
- 所有文案生成的关键词会自动更换
-
- 所有文案都返回了思考文案
-
- 格式都比较偏口语一点
-
-
④. 问题点:
-
- . 所有生成文案基于关键词好多错误,所以基于的文案生成会理解错误
-
- 所有文案都会返回思考数据信息
-
- 有二个文案语句上下文不通畅
-
5.7 横向/纵向模型对比(5种不同的大模型进行对比):
本次测评的模型主要有开源的ERNIE-4.5系列(ERNIE-4.5-0.3B-Paddle、ERNIE-4.5-21B-A3B-Paddle、ERNIE-4.5-VL-28B-A3B-Paddle
)以及其他主流开源模型:如DeepSeek-V3、DeepSeek-R1等,分别从通用能力(基础能力验证)、推理能力(场景化测试)、多模态任务能力(边界条件测试)等五个维度来测评和对比模型的性能指标。

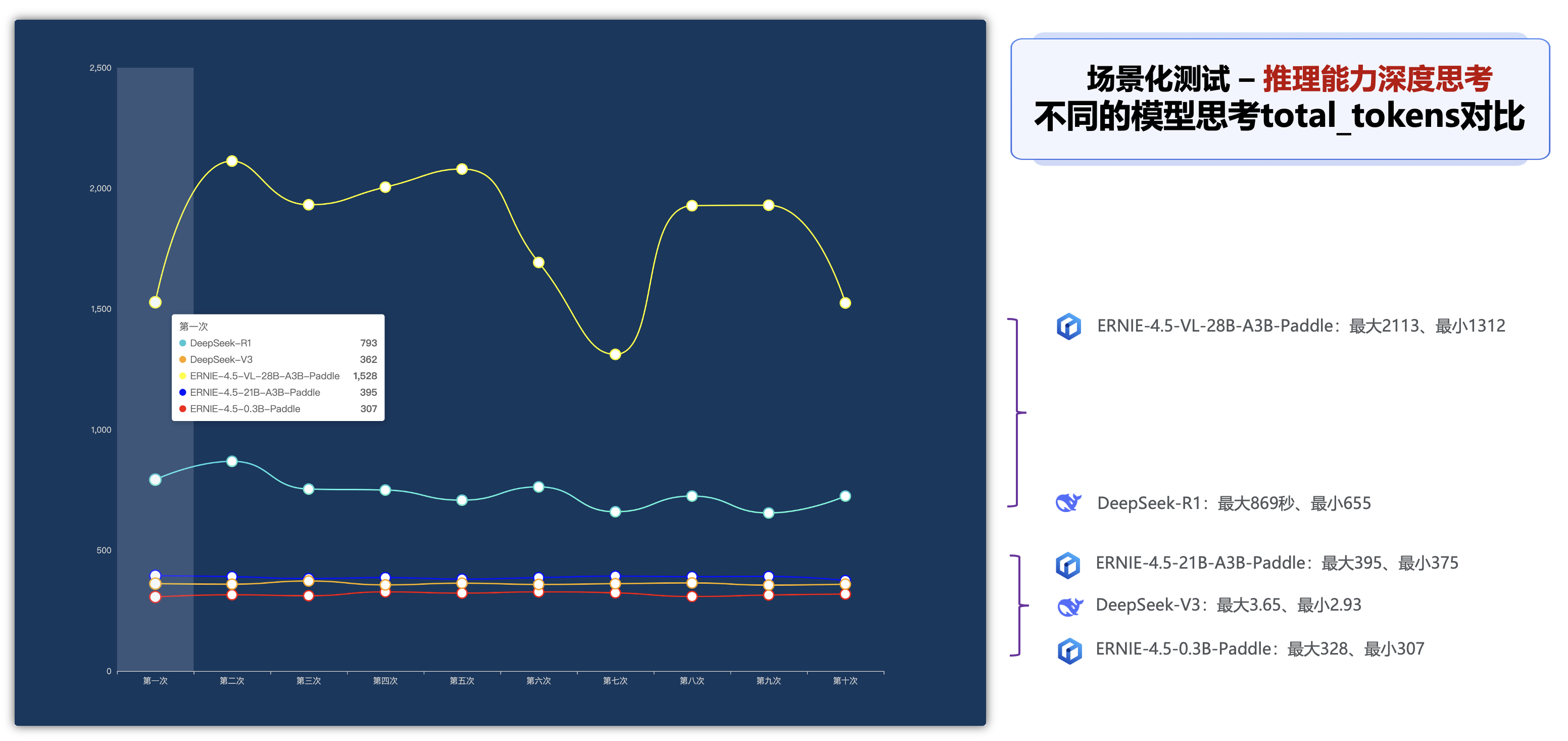
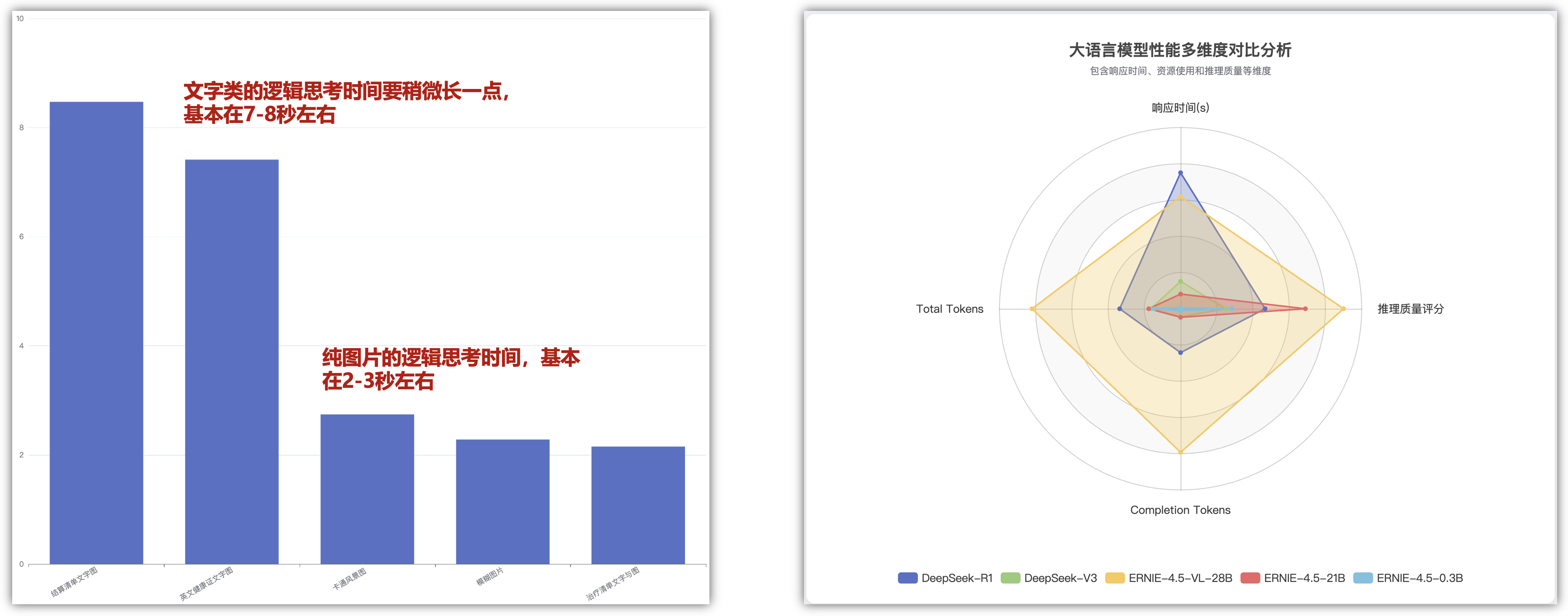
深度思考推理能力各个纬度指标分析:
在深度思考的推理能力的场景下,可以查看以下5种模型的深度思考需要花费的时间,比如响应时间、total_tokens、completion_tokens、推理质量的不同指标的对比排名:
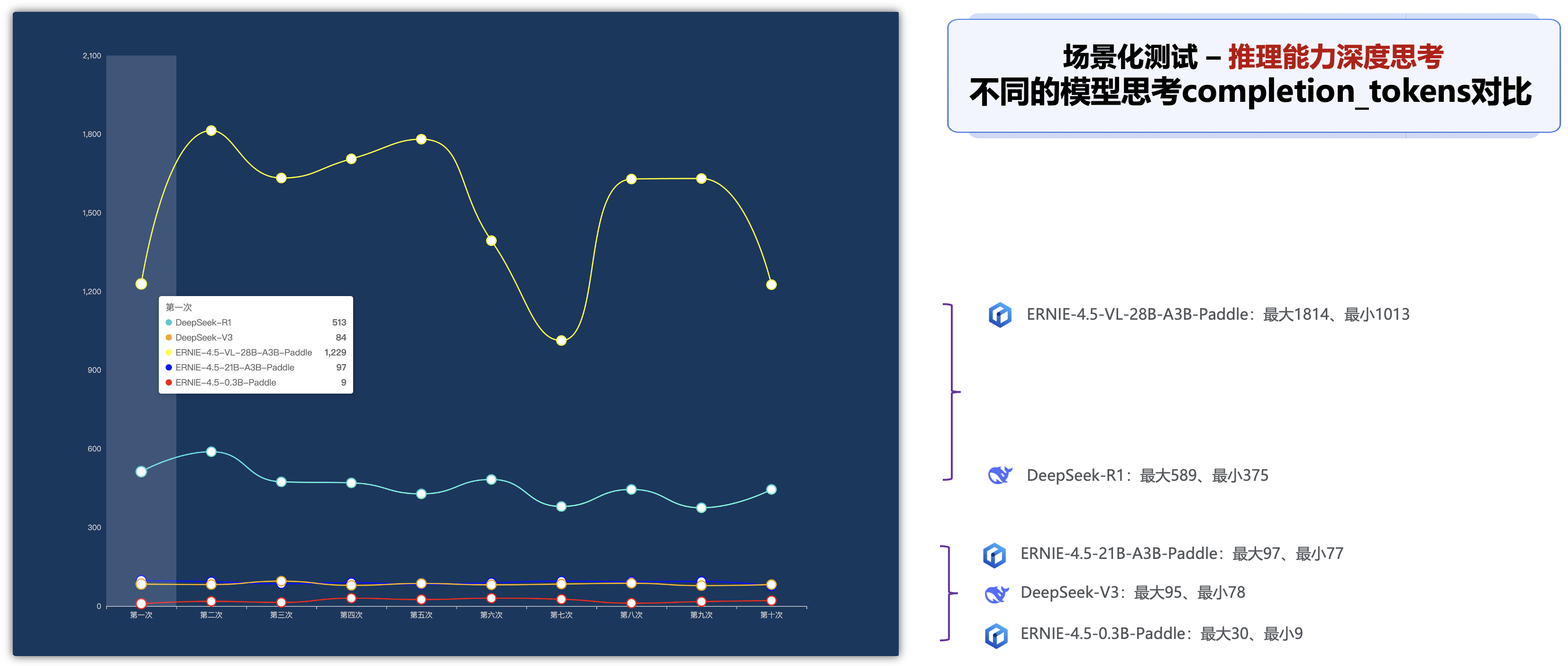
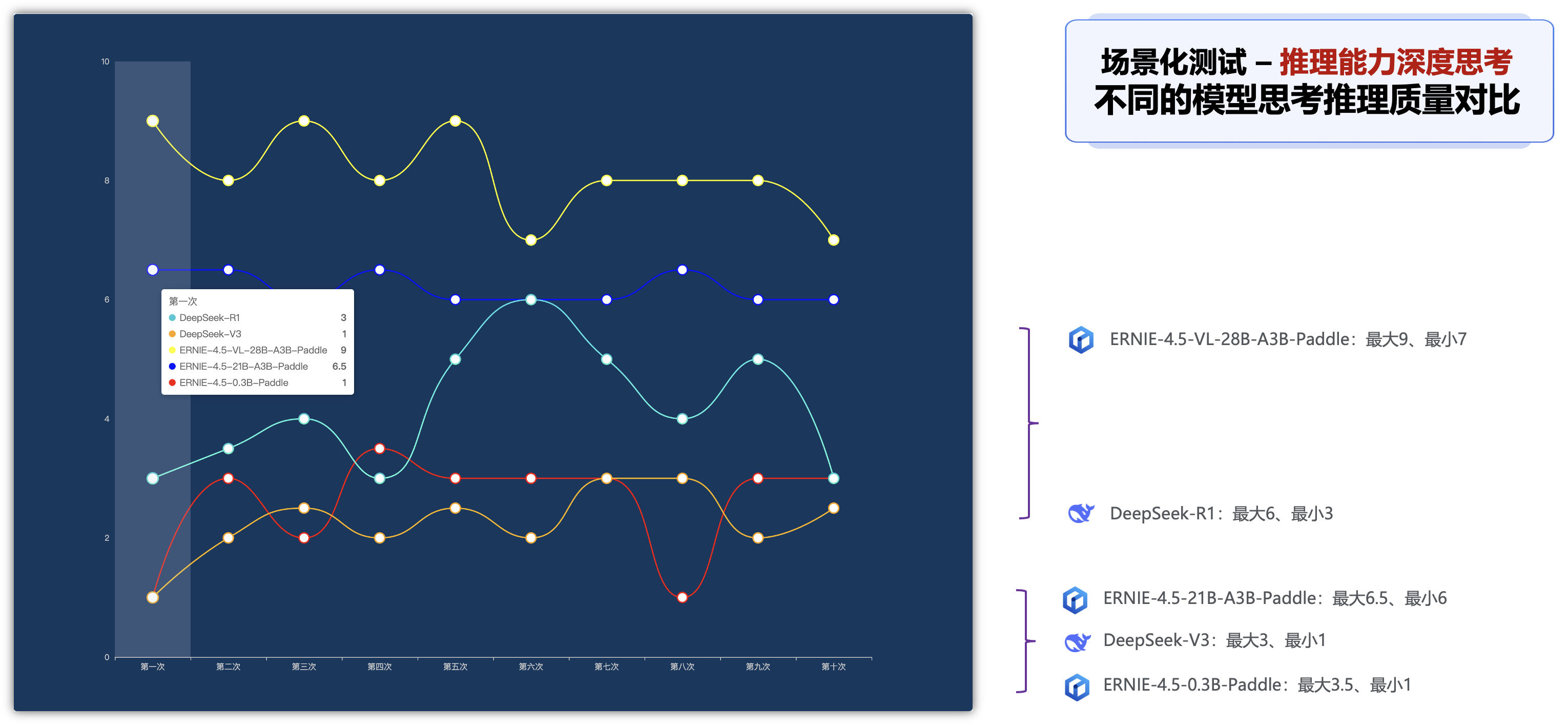
六、边界条件测试 - 理赔材料OCR识别判断是否属于理赔材料:
由于上传理赔的各种材料种类太多,一个页面需要上传近90张图片,靠人力来进行排查太耗费精力了,该技术通过取代人工筛选、分类、核验环节,将理赔资源集中于高价值决策场景,已成为保险业降本增效的核心基础设施。
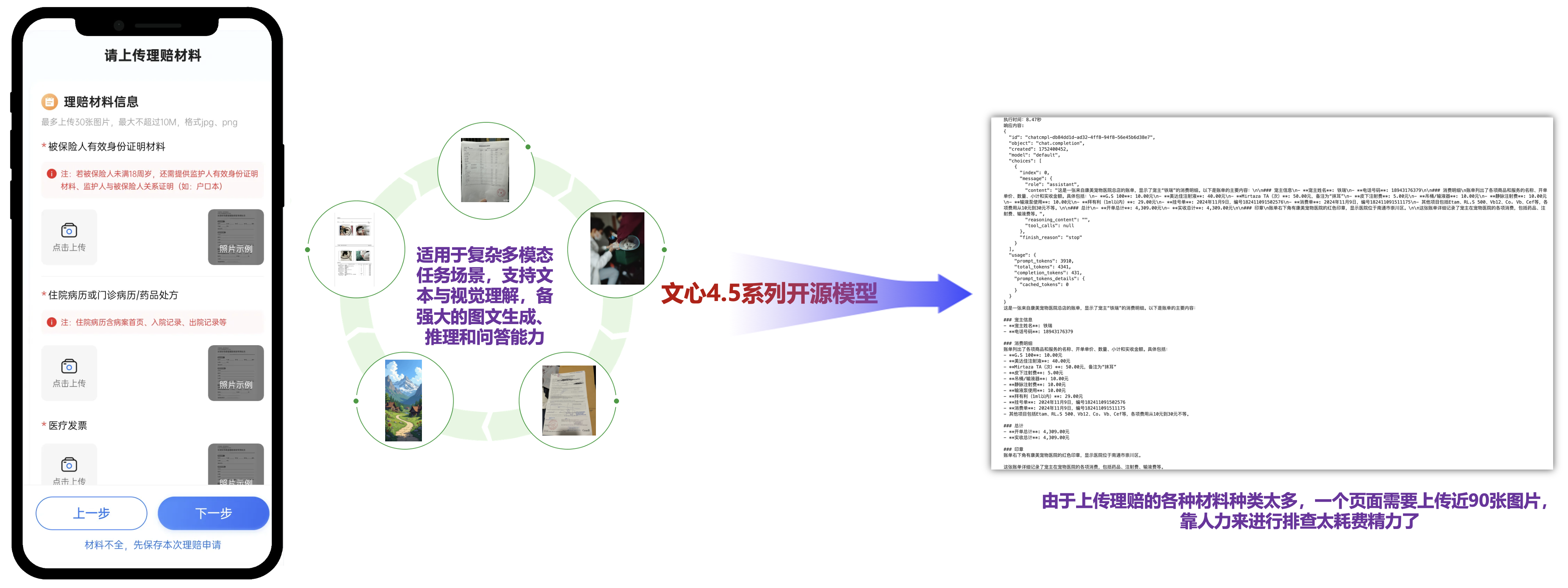
ERNIE-4.5-VL-424B-A47B-Paddle和ERNIE-4.5-VL-28B-A3B-Paddle都是基于 PaddlePaddle 框架构建的模型,适用于复杂多模态任务场景,支持文本与视觉理解,备强大的图文生成、推理和问答能力。
6.1 ERNIE-4.5-VL-28B-A3B-Paddle识别理赔材料 – 结算单:
import requests
import json
import time
url = "http://127.0.0.1:8180/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "./312jfdksjkfare.jpg"
}
},
{
"type": "text",
"text": "描述这张图片"
}
]
}
],
"metadata": {
"enable_thinking": False
}
}
if __name__ == "__main__":
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
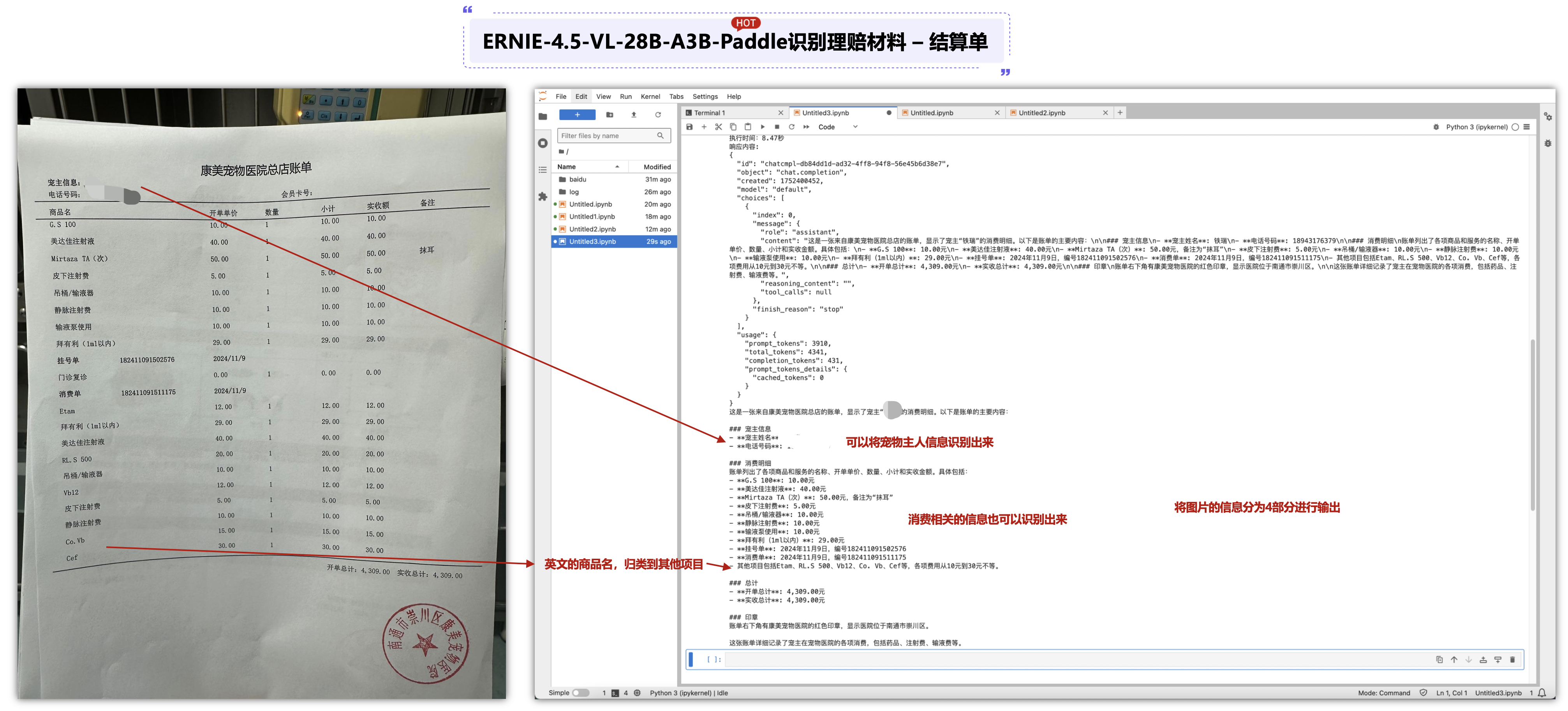
这里可以将图片的信息分为4部分进行输出,第一将可以将宠物主人信息识别出来,第二将消费相关的信息也可以识别出来,可以看到一般来说中文的都会显示出来,英文的药品最后7个,直接使用其它项目总结输出。
6.2 ERNIE-4.5-VL-28B-A3B-Paddle识别理赔材料 – 结算单:
import requests
import json
import time
url = "http://127.0.0.1:8180/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "./32189438943fsafdsureiwla.jpg"
}
},
{
"type": "text",
"text": "描述这张图片"
}
]
}
],
"metadata": {
"enable_thinking": False
}
}
if __name__ == "__main__":
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)
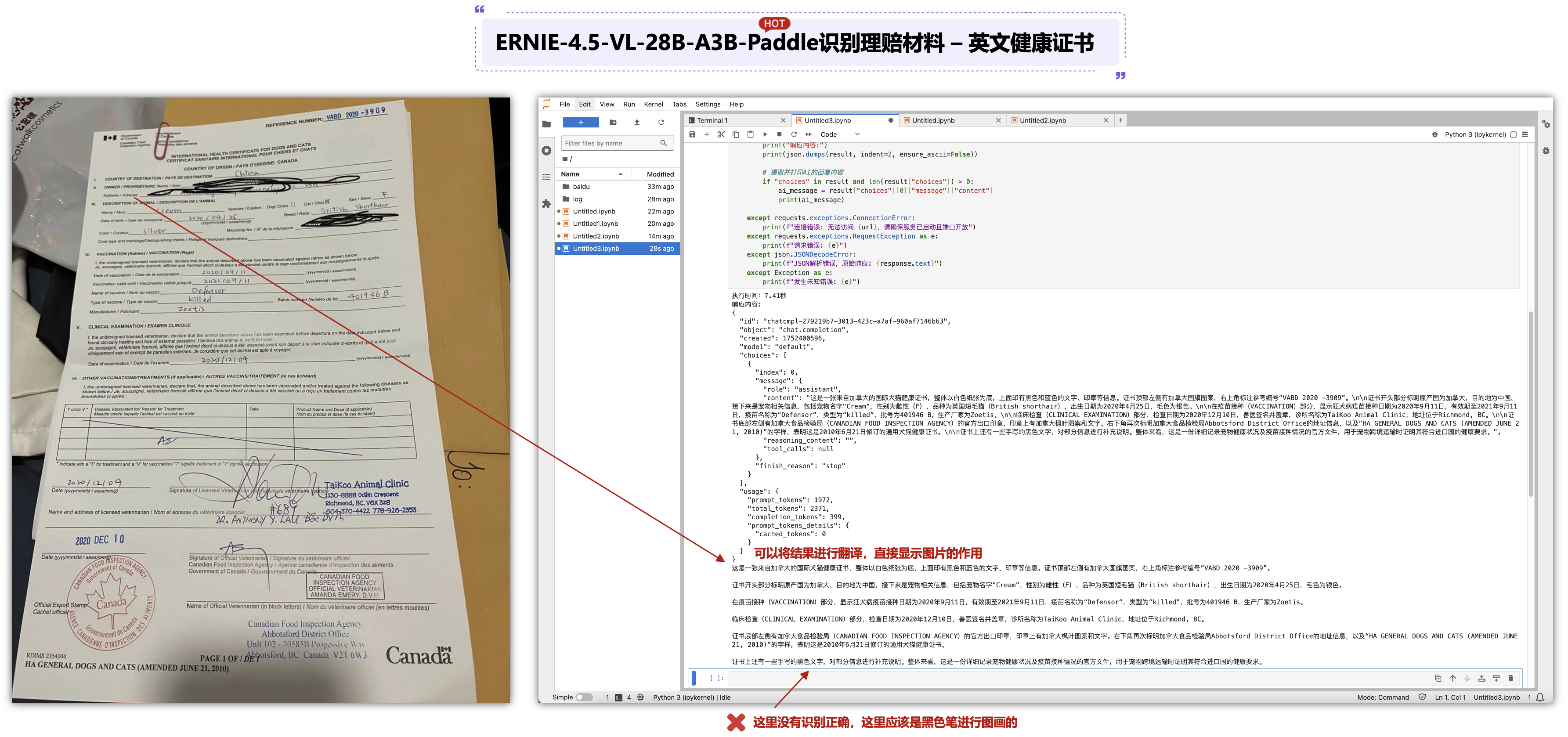
这里可以将一个英文的健康证书也可以进行识别出来,对于英文不太好的业务员来讲,也是可以进行辅助的,可以看到图片有些字也比较小,通过ERNIE-4.5-VL-28B-A3B-Paddle大模型是可以进行分析的,另外,有一点识别错误的是图片中黑色笔涂画的,给出的答案是黑色文字是对部分信息进行补充说明。
6.3 ERNIE-4.5-VL-28B-A3B-Paddle识别理赔材料并返回JSON格式:
import requests
import json
import time
url = "http://127.0.0.1:8180/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "./489894342319049032.png"
}
},
{
"type": "text",
"text": "描述这张图片"
},
,
{
"type": "text",
"text": "判断一下图片是否符合宠物理赔要求的申请的资料(包括病例、账单、费用清单、治疗清单),只需要返回一个json就行,其中包含这张图片的详细的描述,另外一个是返回是否的值"
}
]
}
],
"metadata": {
"enable_thinking": False
}
}
if __name__ == "__main__":
try:
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 记录请求结束时间并计算耗时
end_time = time.time()
execution_time = end_time - start_time
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print(f"执行时间:{execution_time:.2f}秒")
# 打印响应内容
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print(ai_message)

上面可以看到我们通过ERNIE-4.5-VL-28B-A3B-Paddle可以识别出来图片的内容,而且识别的正确率也是达到99%,那么,可以再增加一个条件进行大模型的判断,这张图片是不是符合宠物理赔申请的资料呢?进过测试也是能够正解识别成功的。
{
"type": "text",
"text": "判断一下图片是否符合宠物理赔要求的申请的资料(包括病例、账单、费用清单),只需要返回一个json就行,其中包含这张图片的详细的描述,另外一个是返回是否的值"
}
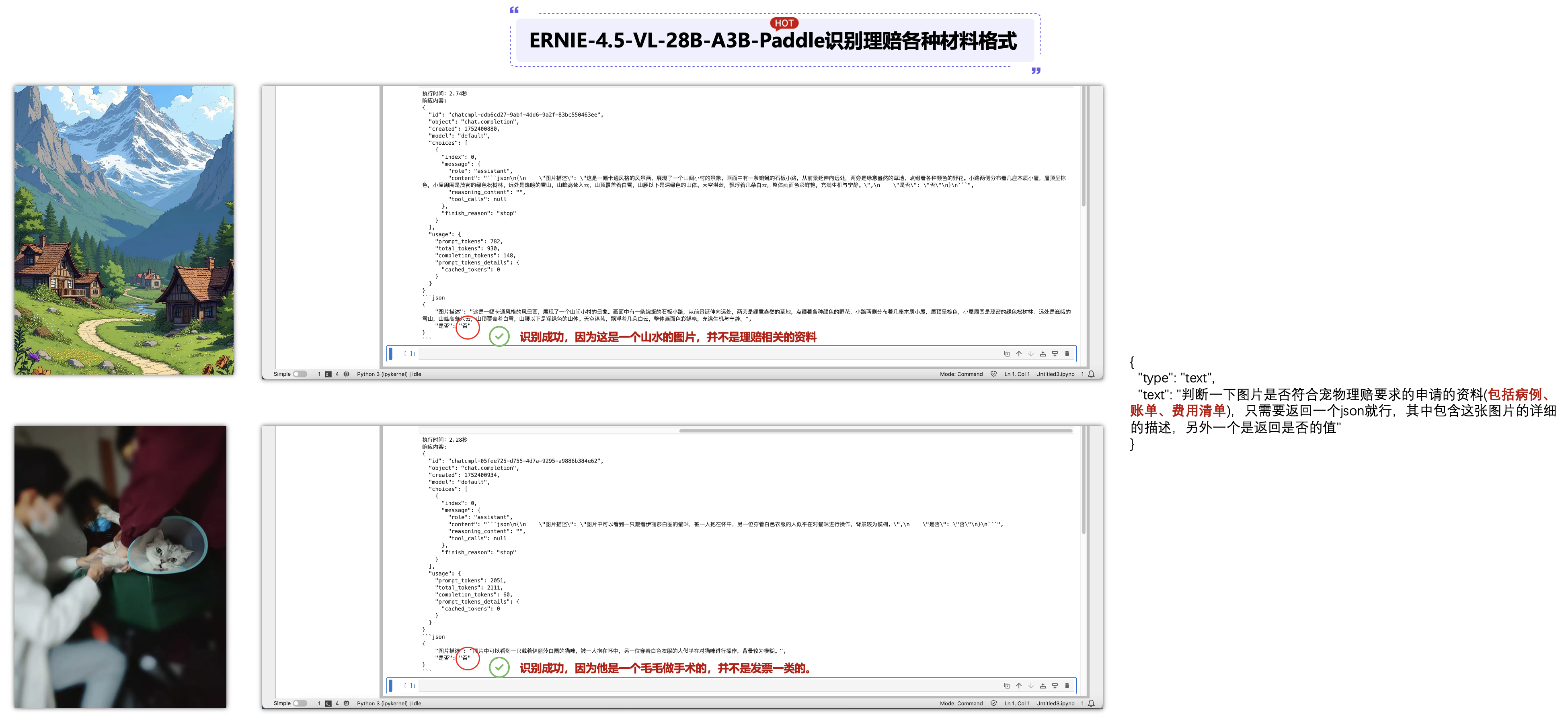
那么我们再上传2张并非理赔材料格式的图片,可以看到ERNIE-4.5-VL-28B-A3B-Paddle可以识别出来图片的内容,也可以判断下面这张图片也是比较模糊的,还是能识别一个白色的人对这个猫进行操作(非常厉害了),这里上传了2张(一张是山水图,一张是毛毛手术图),ERNIE-4.5-VL-28B-A3B-Paddle都能进行识别成功。

最后,我们再上传一张猫猫做手术的治疗请单,可以看到ERNIE-4.5-VL-28B-A3B-Paddle可以识别出来图片的内容,但是判断时将这个图片判断为“否”,那么我们只能再修改提示词,将治疗清单也算进去,可以再次识别时,我们可以成功进行识别了“是”,由此可见,识别不成功时,可以适当增加了判断条件,需要不断的进行摸索提示词。

一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)