【AI时代】一起了解一下大模型训练过程中,数据集处理的Tokenizer和chat_template
最近在对DeepSeek-R1-Distill-Qwen-14B模型做SFT训练,期间遇到一个问题:我使用R1蒸馏之后的数据去微调模型时,反而使模型丧失了推理能力,这让我百思不得其解,猜测肯定是数据集在处理过程中出现了什么问题,所以决定详细了解下数据集处理过程。
背景
最近在对DeepSeek-R1-Distill-Qwen-14B模型做SFT训练,期间遇到一个问题:我使用R1蒸馏之后的数据去微调模型时,反而使模型丧失了推理能力,这让我百思不得其解,猜测肯定是数据集在处理过程中出现了什么问题,所以决定详细了解下数据集处理过程。
我的训练数据集模板如下:
[
{"role": "system", "content": "..."},
{"role": "user", "content": "..."},
{"role": "assistant", "content": "<think>...</think>..."}
]
我使用了大概70K的数据集,训练完之后,模型回答竟然没有了CoT过程,如下: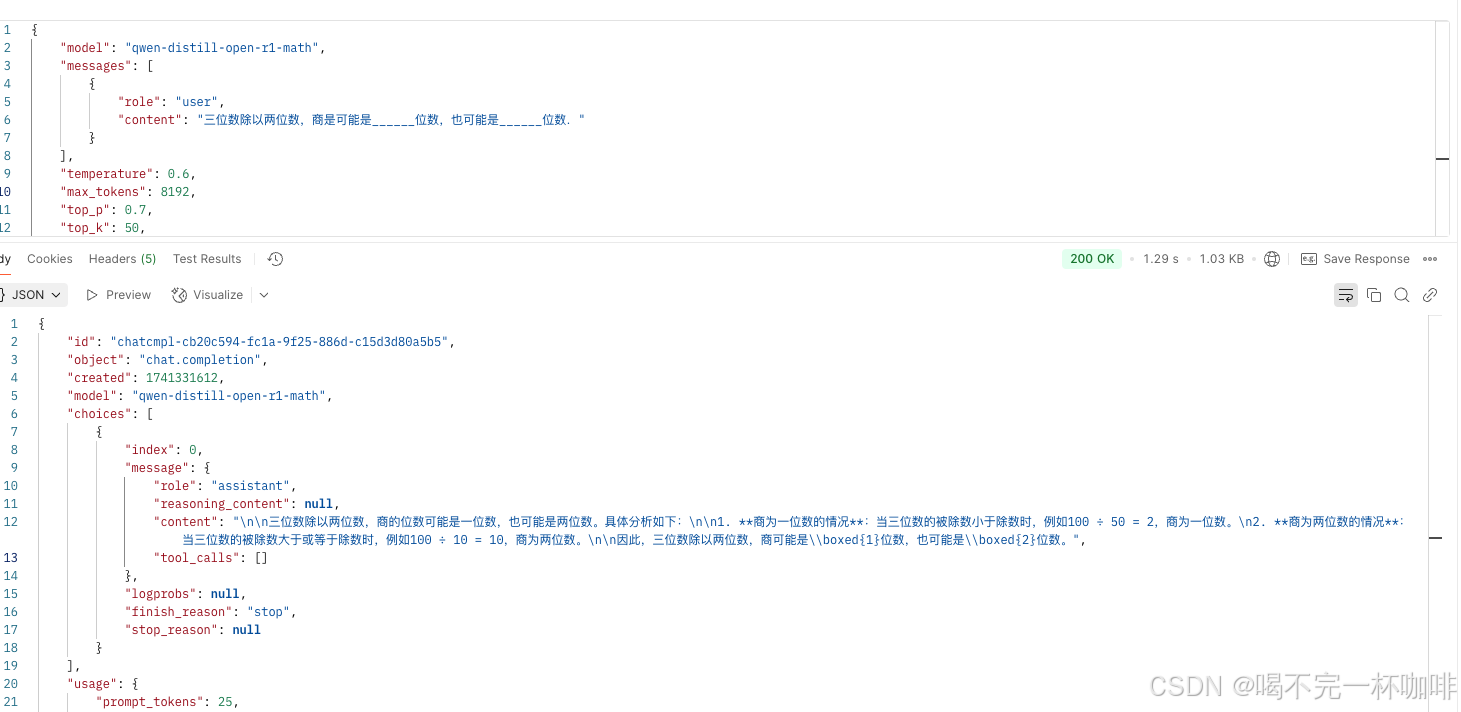
回答任何过程都没有了<think>…</think>标签,所以肯定是我数据集中这部分内容丢失了,怎么丢失的?我们来一探究竟。
认识几个文件
要了解数据集的处理,我们需要认识几个模型目录中的文件
tokenizer.json
任何一个大模型文件的目录,结构都类似如下:
主要是模型的权重文件,还有一些配置文件,先来看看tokenizer.json,这个文件主要是一个token分词的字典,key就是我们常见的文本,value是数字,也就是大模型认识的token: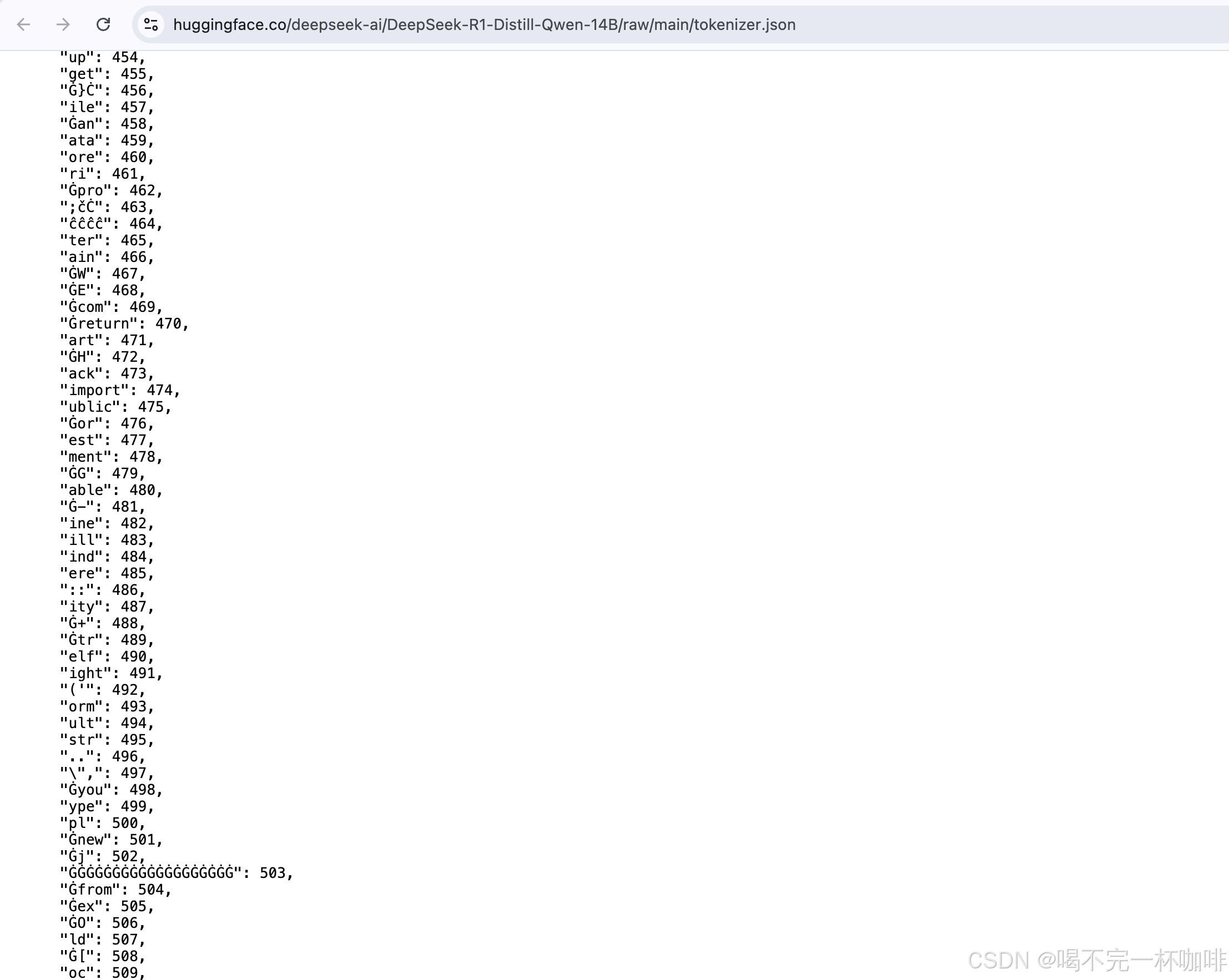
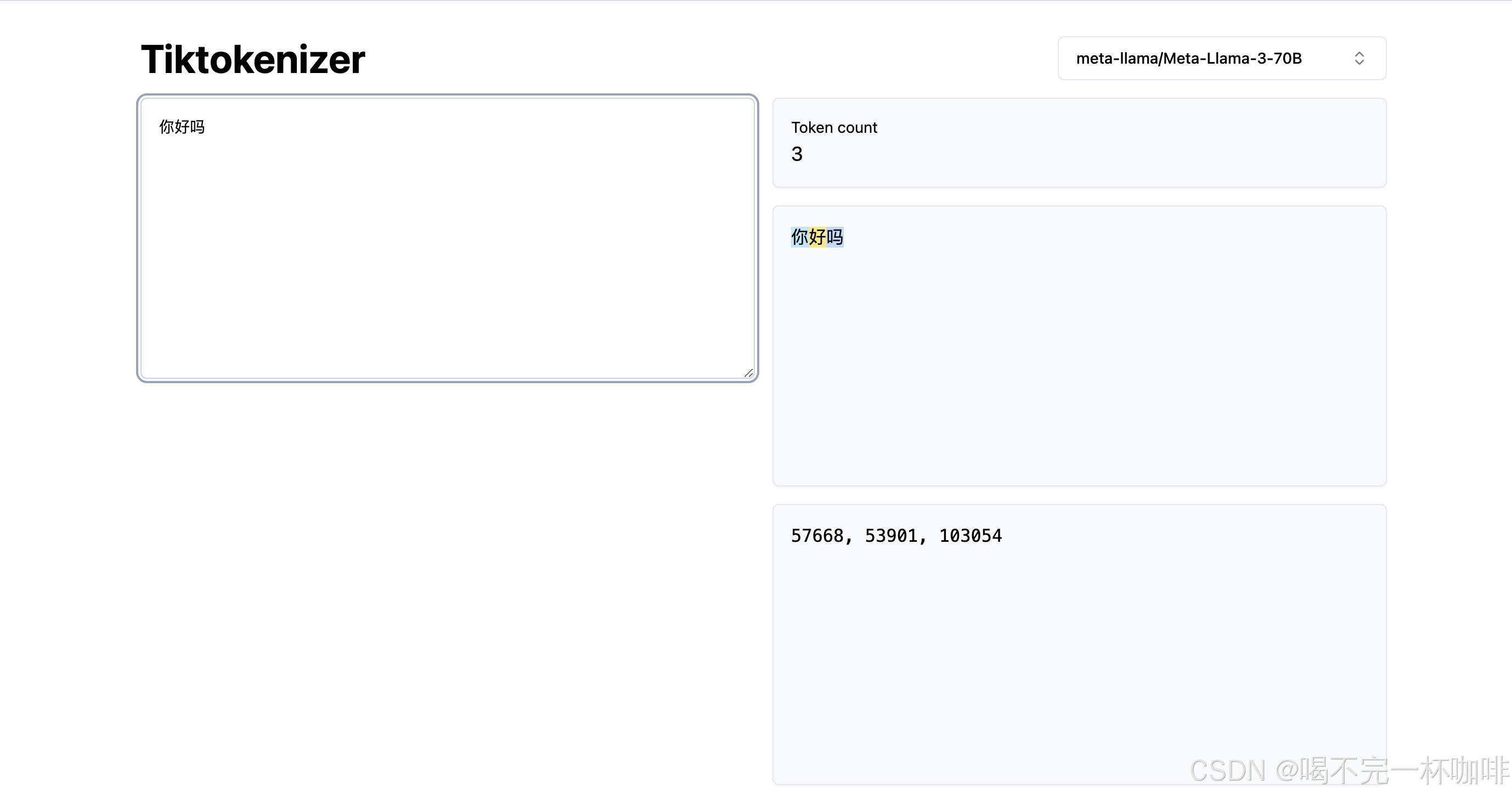
不同的模型有不同的分词规则,所以同样的文本,不同模型产生的token数和token都会不一样:
同样的一段文本:你好吗,这是llama的,会被拆成3个token:
这是DeepSeek的,会被拆为两个token: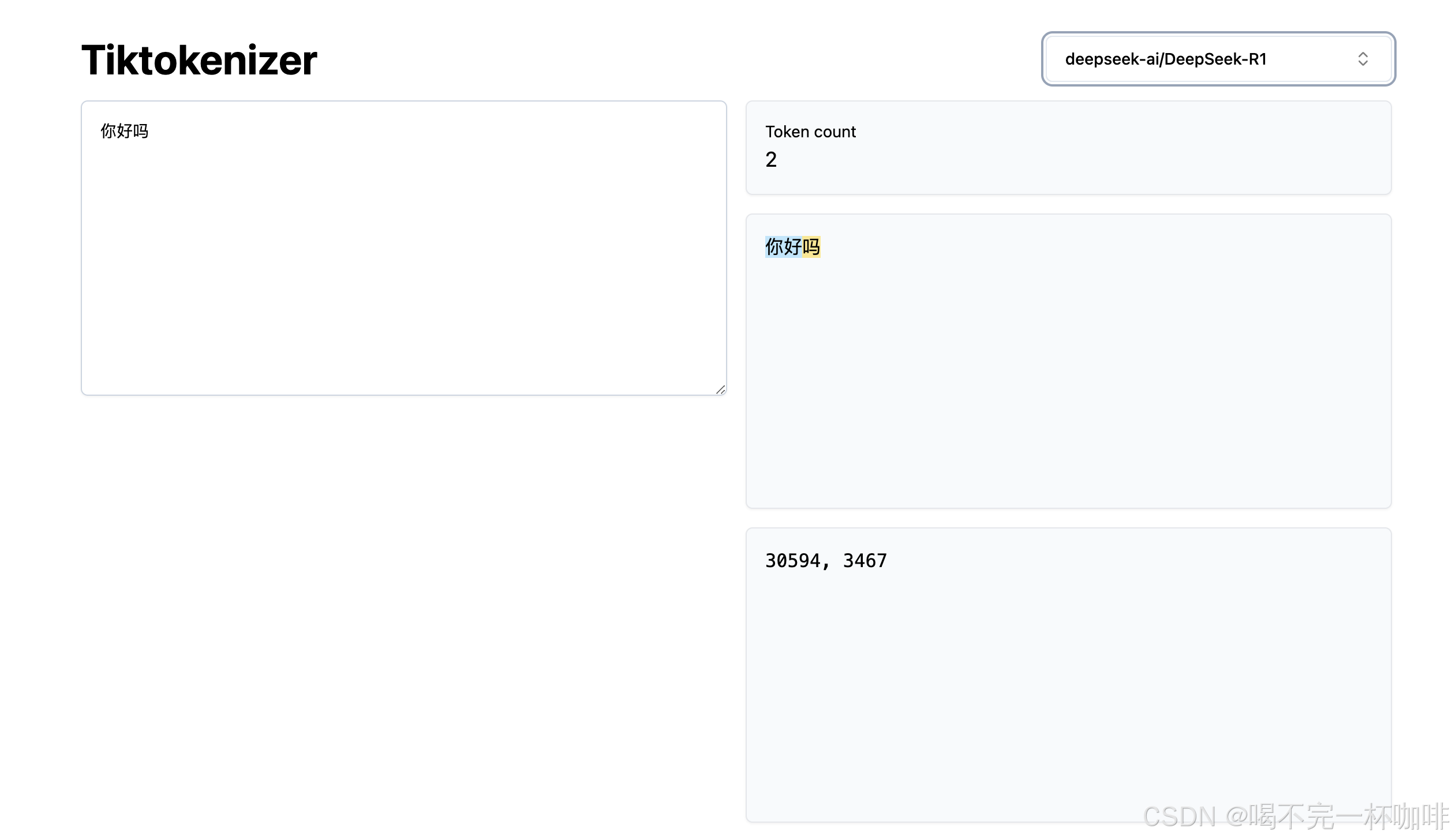
这就是因为各自用的Tokenizer不同,不同的字典,不同的分词规则,当然,如果你有兴趣,也可以训练自己的Tokenizer。
tokenizer_config.json

这个文件看似没多少内容,但是很重要,首先是定义了两个特殊的token,<|begin▁of▁sentence|>和<|end▁of▁sentence|>,注意中间的竖线是全角的,没想到吧,这两个token代表一段文本的开始和结束,让大模型知道何处为开始,什么时候该停下,最重要的是chat_template,这段json,定义了这个chat模型的数据处理规则,当你向模型提问的时候,模型根据这个template,将原始内容,转换为大模型认识的格式,后面会详细说明。
解读chat_template
首先,这段代码是一段jinja2代码,是一个python的模板引擎,看着是有点陌生,但是也就是一些简单的逻辑处理、数据提取,下面是逐行的解读:
{# 检查 add_generation_prompt 变量是否被定义,如果未定义,则将其设置为 false #}
{% if not add_generation_prompt is defined %}
{% set add_generation_prompt = false %}
{% endif %}
{# 创建一个命名空间对象 ns,用于存储一些状态变量和系统提示信息 #}
{# is_first:标记是否为第一个工具调用,初始值为 false #}
{# is_tool:标记当前是否处于工具输出状态,初始值为 false #}
{# is_output_first:标记是否为第一个工具输出,初始值为 true #}
{# system_prompt:存储系统提示信息,初始值为空字符串 #}
{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}
{# 遍历 messages 列表,查找角色为 'system' 的消息 #}
{# 如果找到,将该消息的内容赋值给命名空间对象 ns 的 system_prompt 属性 #}
{%- for message in messages %}
{%- if message['role'] == 'system' %}
{% set ns.system_prompt = message['content'] %}
{%- endif %}
{%- endfor %}
{# 输出起始标记 bos_token 和系统提示信息 #}
{{ bos_token }}{{ ns.system_prompt }}
{# 再次遍历 messages 列表,根据消息的角色进行不同的处理 #}
{%- for message in messages %}
{# 处理角色为 'user' 的消息 #}
{%- if message['role'] == 'user' %}
{# 将 is_tool 标记设置为 false,表示当前不是工具输出状态 #}
{%- set ns.is_tool = false -%}
{# 输出用户消息,格式为 '<|User|>' 加上消息内容 #}
{{ '<|User|>' + message['content'] }}
{%- endif %}
{# 处理角色为 'assistant' 且内容为空的消息(即工具调用消息) #}
{%- if message['role'] == 'assistant' and message['content'] is none %}
{# 将 is_tool 标记设置为 false,表示当前不是工具输出状态 #}
{%- set ns.is_tool = false -%}
{# 遍历消息中的工具调用列表 #}
{%- for tool in message['tool_calls'] %}
{# 如果是第一个工具调用 #}
{%- if not ns.is_first %}
{# 输出工具调用开始标记、工具类型、工具名称、工具参数等信息 #}
{{ '<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>' }}
{# 将 is_first 标记设置为 true,表示已经处理过第一个工具调用 #}
{%- set ns.is_first = true -%}
{# 如果不是第一个工具调用 #}
{%- else %}
{# 输出工具调用信息,并在最后添加工具调用结束标记和句子结束标记 #}
{{ '\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>' }}
{{ '<|tool▁calls▁end|><|end▁of▁sentence|>' }}
{%- endif %}
{%- endfor %}
{%- endif %}
{# 处理角色为 'assistant' 且内容不为空的消息 #}
{%- if message['role'] == 'assistant' and message['content'] is not none %}
{# 如果当前处于工具输出状态 #}
{%- if ns.is_tool %}
{# 输出工具输出结束标记、助手消息内容和句子结束标记 #}
{{ '<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>' }}
{# 将 is_tool 标记设置为 false,表示工具输出状态结束 #}
{%- set ns.is_tool = false -%}
{# 如果当前不是工具输出状态 #}
{%- else %}
{# 获取助手消息的内容 #}
{% set content = message['content'] %}
{# 如果消息内容中包含 '</think>' 标签 #}
{% if '</think>' in content %}
{# 截取 '</think>' 标签之后的内容 #}
{% set content = content.split('</think>')[-1] %}
{% endif %}
{# 输出助手消息,格式为 '<|Assistant|>' 加上处理后的消息内容和句子结束标记 #}
{{ '<|Assistant|>' + content + '<|end▁of▁sentence|>' }}
{%- endif %}
{%- endif %}
{# 处理角色为 'tool' 的消息 #}
{%- if message['role'] == 'tool' %}
{# 将 is_tool 标记设置为 true,表示当前处于工具输出状态 #}
{%- set ns.is_tool = true -%}
{# 如果是第一个工具输出 #}
{%- if ns.is_output_first %}
{# 输出工具输出开始标记、工具输出内容和工具输出结束标记 #}
{{ '<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>' }}
{# 将 is_output_first 标记设置为 false,表示已经处理过第一个工具输出 #}
{%- set ns.is_output_first = false %}
{# 如果不是第一个工具输出 #}
{%- else %}
{# 输出工具输出内容和工具输出结束标记 #}
{{ '\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>' }}
{%- endif %}
{%- endif %}
{%- endfor -%}
{# 如果当前处于工具输出状态,输出工具输出结束标记 #}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' }}
{% endif %}
{# 如果 add_generation_prompt 为 true 且当前不是工具输出状态,输出 '<|Assistant|>' 标记 #}
{% if add_generation_prompt and not ns.is_tool %}
{{ '<|Assistant|>' }}
{% endif %}
如果你认真看完这段解读,应该就知道我训练出来的模型,没有推理过程了,正是因为这一句: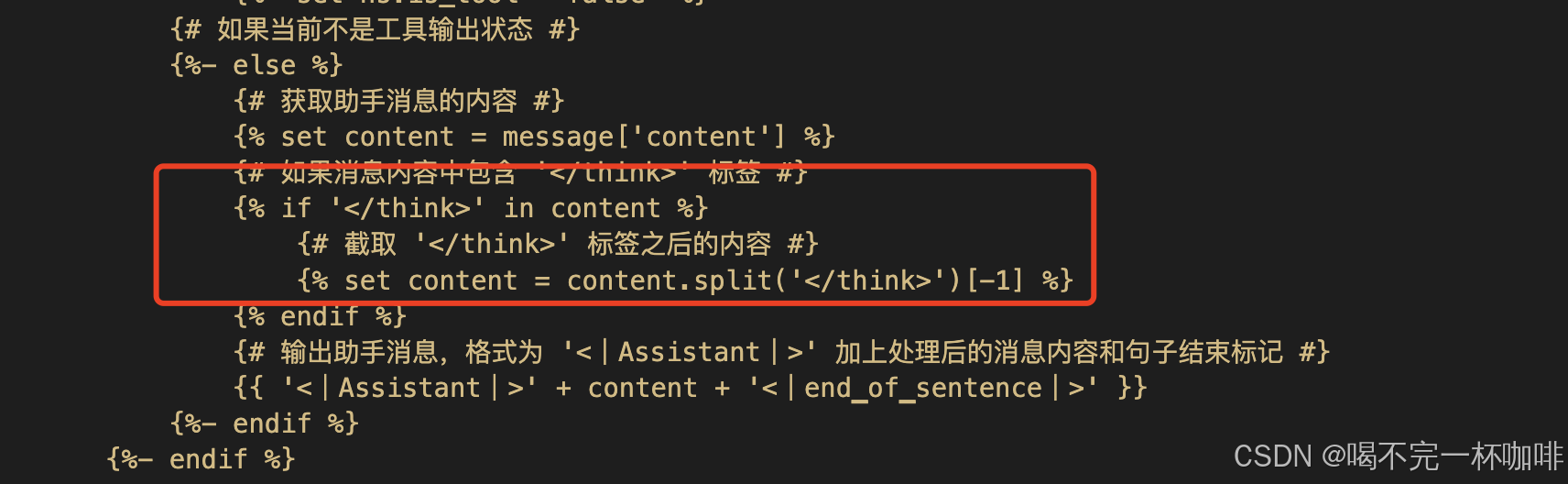
也就是说,我的推理过程被干掉了!
为什么要这么做呢,官方有一些说明: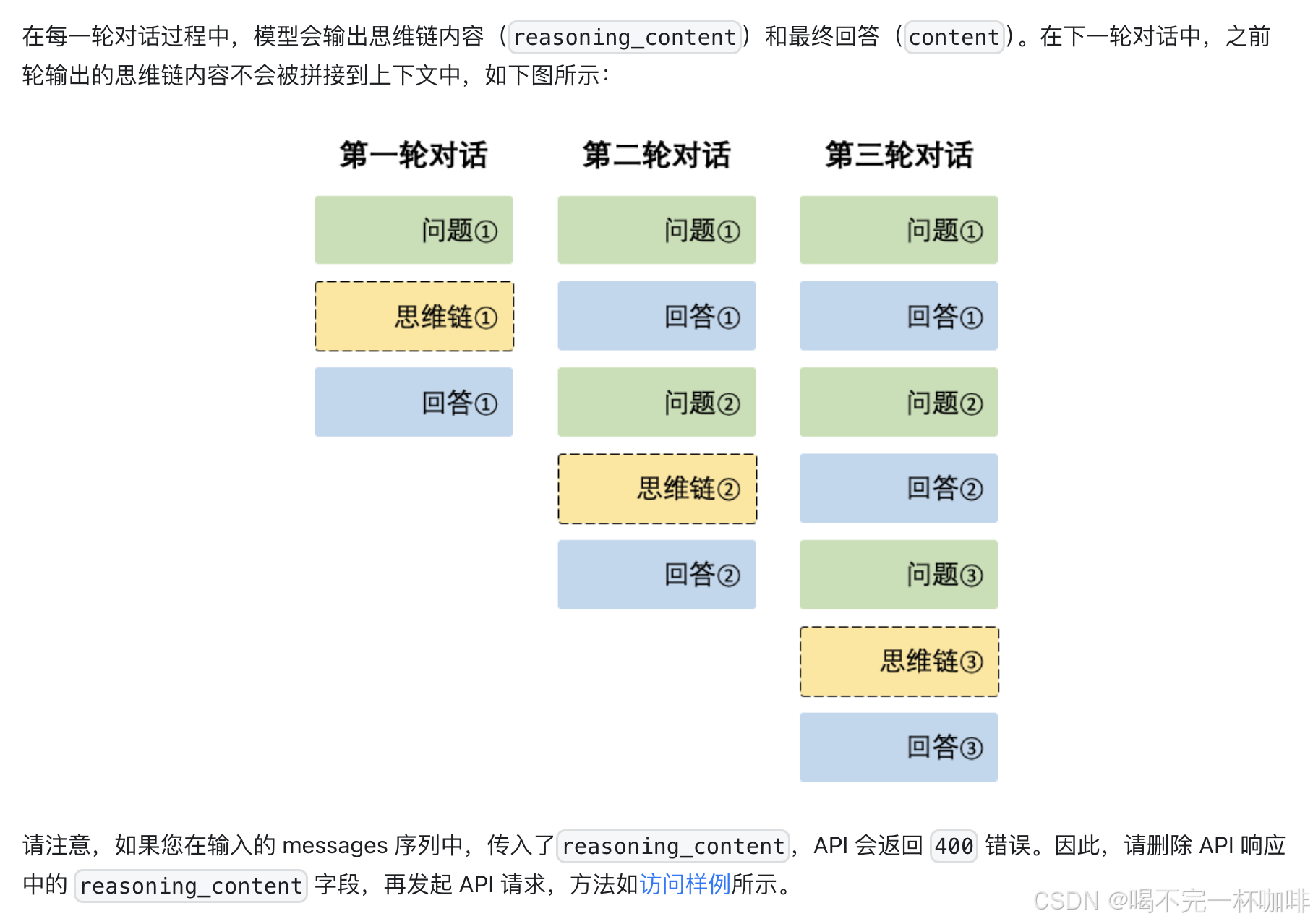
其实就是为了避免多轮对话过程中,推理过程被多次引用,一是没必要,二是增加了token消耗。
测试玩玩
from transformers import AutoTokenizer
# 加载本地分词器
tokenizer_path = "/A800POC/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B" # 替换为你的本地分词器路径
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
text = '你好'
tokens = tokenizer.encode(text)
print(f'text: {text}, tokens: {tokens}')
输出:
text: 你好, tokens: [151646, 108386]
其中151646代表<|begin▁of▁sentence|>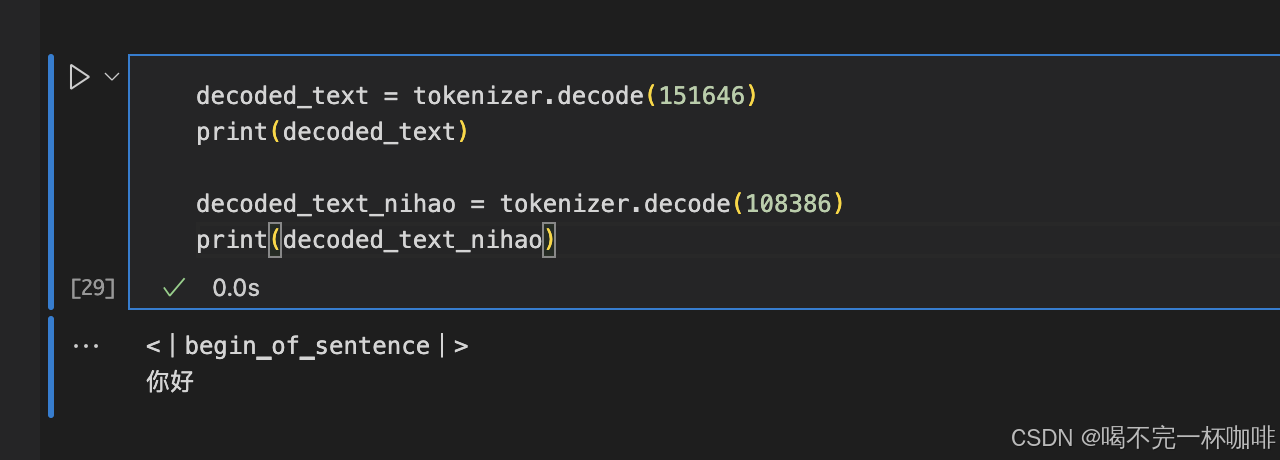
可以打印chat_template看看,有些模型是没有格式化的:
print(tokenizer.chat_template)
应用chat_template:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "<think>我好像不认识你啊,但是既然你给我打招呼了,我还是礼貌一点吧</think>I'm doing great. How can I help you today?"}
]
tokenizer.apply_chat_template(messages, tokenize=False)
输出:
"<|begin▁of▁sentence|>You are a helpful assistant.<|User|>Hello, how are you?<|Assistant|>I'm doing great. How can I help you today?<|end▁of▁sentence|>"
这么一看就很明确了,我的思考过程确实被截取掉了,tokenize=True的话会直接转为token。
今天是周六,妇女节,祝女士们节日快乐~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)