DeepSeek的“加速挂”,绕过芯片护城河!论文硬核细节解读
大家好!我是羊仔,专注AI工具、智能体、编程。羊仔之前也和大家分享过不少AI工具,但DeepSeek这匹“黑马”着实让人眼前一亮。它不仅在短短两个月内就训练出了一个参数量高达6710亿的巨型语言模型,而且训练效率还比那些巨头们高出10倍!这是什么概念?简直就是开了加速挂!今天羊仔就想跟大家聊聊这个话题,看看DeepSeek的硬核骚操作到底是怎么回事。
大家好!我是羊仔,专注AI工具、智能体、编程。
羊仔之前也和大家分享过不少AI工具,但DeepSeek这匹“黑马”着实让人眼前一亮。
它不仅在短短两个月内就训练出了一个参数量高达6710亿的巨型语言模型,而且训练效率还比那些巨头们高出10倍!

这是什么概念?简直就是开了加速挂!今天羊仔就想跟大家聊聊这个话题,看看DeepSeek的硬核骚操作到底是怎么回事。
一、论文里的硬核细节
那DeepSeek到底是怎么做到这么快的呢?
DeepSeek论文的一个技术细节揭开了谜底:他们在训练过程中对英伟达的H800 GPU进行了重新配置。
具体来说,他们从132个流式多处理器(SM)中,专门划分出20个用于服务器间的通信任务,而不是传统的计算任务。
这种操作是通过PTX(Parallel Thread Execution)实现的,他们竟然绕过了常用的CUDA编程,直接用更底层的PTX编程来优化!

(⬆️DeepSeek-V3 Technical Report)
PTX是什么?PTX是英伟达GPU的一种中间指令集架构,位于高级编程语言(如CUDA)和底层机器码之间。
简单来说,PTX就像是一种“接近硬件”的语言,能够对硬件进行更精细的控制,目的是突破硬件对通信速度的限制,从而榨干每一滴性能。
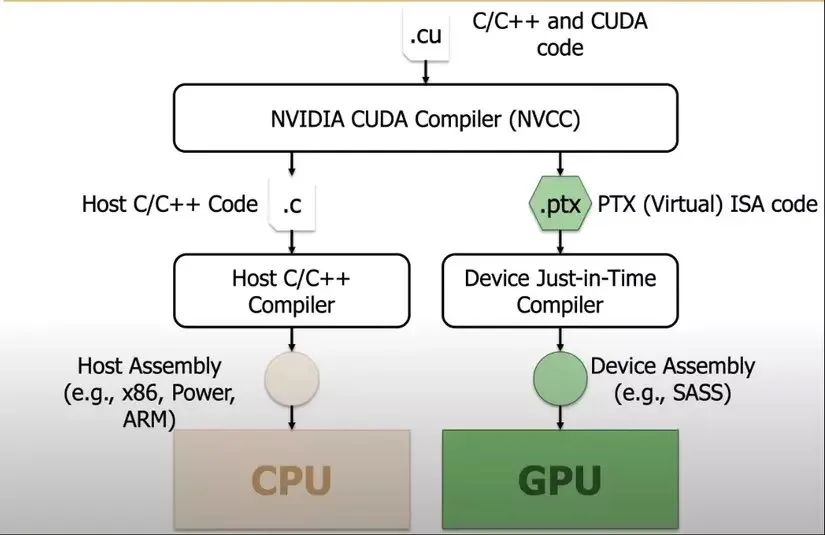
它允许开发者进行更细粒度的优化,比如寄存器分配、线程级别的调整等,这些优化在CUDA这种高级语言中是很难实现的。
这就好比一个顶级厨师,不满足于使用现成的厨具,而是自己动手打造更趁手的工具,做出更美味的菜肴。
如果你对DeepSeek的论文感兴趣,想深入研究,可在后台回复【deepseek论文】自取,包括V3模型和R1模型的论文,羊仔都已经整理好了。
二、英伟达的“护城河”还在吗?
DeepSeek的这波操作,让不少人开始质疑:英伟达的CUDA,这个AI界的“金字招牌”,它的“护城河”还在吗?
毕竟,如果DeepSeek能用PTX实现如此大的性能提升,那其他公司是不是也能效仿呢?
羊仔也思考了很久,觉得这个问题还真不好说。CUDA虽然好用,但毕竟还是一种高级语言,对硬件的控制力有限。
PTX这种底层编程虽然难度更大,但潜力也更大,未来会不会有更多公司选择“剑走偏锋”,走上PTX这条路呢?
三、羊仔亲身经历
说到底层优化,羊仔也想起自己之前的一次经历。
那时候羊仔正在做一个图像处理项目,需要对图像进行大量的计算,一开始,羊仔用的是现成的库函数,速度很慢。

后来,尝试用底层语言重写了部分代码,虽然花了不少时间,但最终程序的运行速度提升了好几倍!
那次经历让羊仔深刻体会到,底层优化虽然辛苦,但效果是真的香!
四、DeepSeek的未来
DeepSeek的成功,无疑给AI行业带来了新的启示,它证明了在硬件资源有限的情况下,通过极致的优化也能取得惊人的成果。
未来,DeepSeek会不会开源它的PTX优化方案,引领一波新的技术潮流呢?我们拭目以待吧!

五、羊仔说
通过DeepSeek的硬核骚操作,羊仔想给各位开发者朋友一些建议:
1. 不要只局限于高级编程语言,可以尝试学习一些底层编程技术。
2. 底层优化虽然难,但潜力巨大,回报往往远超投入的。
共勉!
欢迎关注羊仔,一起探索AI,成为超级个体!
记得点赞,收藏,转发,你的每一次互动,对羊仔来说都是莫大的鼓励。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)