个人知识库-腾讯ima
现在不说的deepseek好像就没法和人打招呼了,我爸70多了,都知道这个。然后我儿子也知道。这真的是妇孺皆知、童叟皆知道啊。大家已经知道很多大模型了,文心一言,通义千问,豆包,讯飞,智谱,还有混元以及当红炸子鸡deepseek。国外的就更加不用说了。
大模型的热还是要冷静
现在不说的deepseek好像就没法和人打招呼了,我爸70多了,都知道这个。然后我儿子也知道。这真的是妇孺皆知、童叟皆知道啊。
大家已经知道很多大模型了,文心一言,通义千问,豆包,讯飞,智谱,还有混元以及当红炸子鸡deepseek。国外的就更加不用说了。
一键部署大模型
2024那时候我自己还真的在自己的虚拟机上安装过。
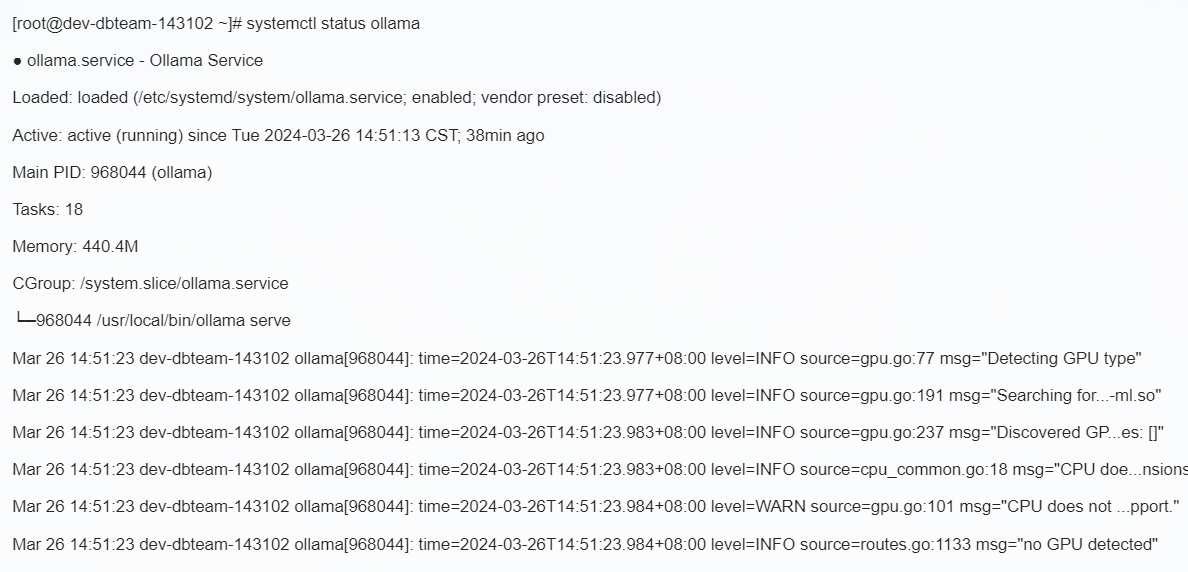
那时候体验了一下这个来龙去脉,那时候不是一键部署。比起现在天天说的,我还是早的。但是受限于当时条件,确实很卡。在这种情况下,大家如果用自己的笔记本做的话,我觉得简直是折磨自己的机器。
而今年deepseek让大家在自己的机器上也可以使用轻量型的模型了,这就大不相同了。
不过我觉得安装部署是一个体验,我们最终是使用。我依然还是坚定的使用文心一言,通义千问,豆包,讯飞,智谱,混元和deepseek的网页版。服务繁忙没事,这么多都能用。其实这么多的竞争也是卷,从资源的角度来说,我觉得大家都是资源的浪费。如果说这是打仗,就是这些之间互相竞争而且还要和国外的竞争。这就和国产数据库一样,力量都分散了。
我也能理解大家想做自己的专属,今天我看到了腾讯ima。这个即可以做自己的专属,还不用本地部署。
它支持多种操作系统和客户端。
我觉得这种挺好,本地不用存储,还有用上属于自己的模型挺好。
下载以后一步步安装就可以了。
形成自己的大模型
然后就把自己电脑中的各种pdf和word上传上去。
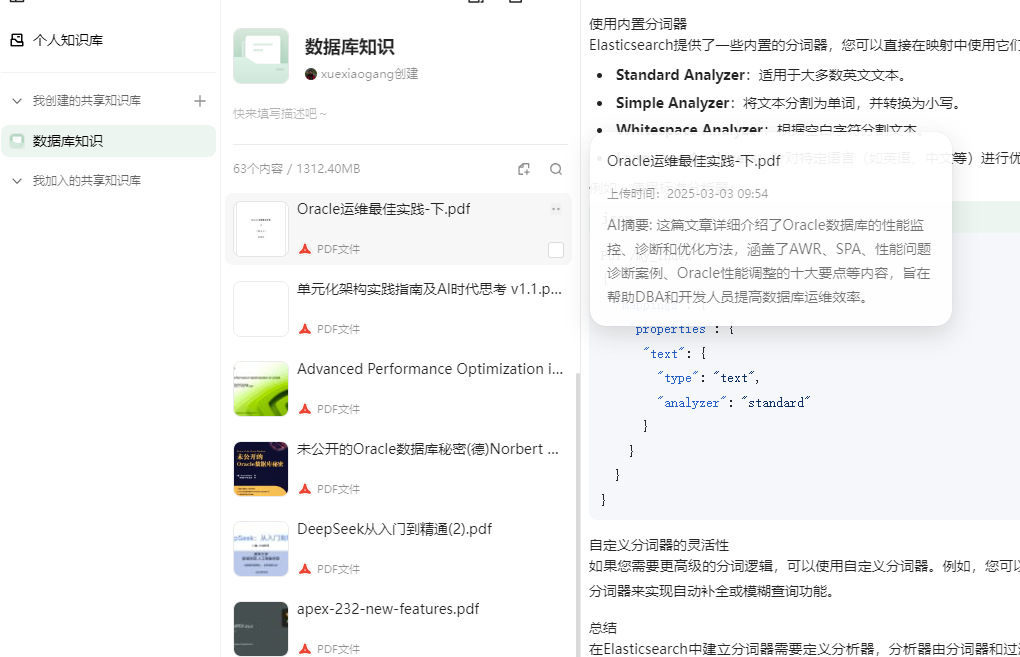
然后就可以在这里问问题了。他有PC版本的,有手机版本的还是有小程序版本的。
IMA-带来的惊喜
惊喜1:只要是一个账户登录,不同机器登录后会话还是共享的。也就是说我上班问的,回家不用重复问了。
惊喜2:而且x86架构和ARM上都可以运行。我公司笔记本和家中笔记本是不一样的。
IMA-已知的问题
问题1:超过100M的文件不能上传。我自己写的书的原稿就大于100M。不少好的资料都会超过100M。尽管可以通过裁剪什么的手段回避一下,但是另外一个问题回避不了。
问题2:目前只能有2G的空间。如今大家的积累文档何止2G。
对于以上问题,我今天早TVP群里反馈了一下,其他TVP老师也提出了相关看法。TVP的运营小姐姐马上说联系IMA团队,把这些意见和建议传递过去。我估计日后会有一定的改善。
目前这样先用着吧。
小结
以上都是个人使用方面的一些想法。
对于有些企业要私有化部署的,我觉得这篇写的可以:
https://mp.weixin.qq.com/s/ICXd4SqjfcN40-cJkfFk4Q
我本人觉得凡事一开始都过热,什么都要,什么都想。但是还是请清醒的看待,合适自己的才行。就像小马过河一样,先了解一下,再尝试一下。别一上来就是号召全体全员 一般来说号召这种一旦号召了,就是一窝蜂去做,最后发现都是一堆债。
从大数据、微服务、中台、区块链、元宇宙哪个不是这样?有几个是好好用的?有几个是用的好的?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)