DeepSeek启示:深度揭秘基于PTX的GPU底层优化技术
在撰写本文期间,恰逢DeepSeek“开源周”,目前已有FlashMLA、DeepEP和DeepGEMM 三个项目完成开源。这些项目中涉及的PTX优化技术也值得关注。具体而言,FlashMLA项目通过BF16支持和分页kvcache等技术提升了Hopper GPU上的解码性能;DeepEP项目通过优化NVLink和RDMA转发,提供了高效的专家并行通信库;DeepGEMM项目采用JIT编译和TMA
01

概 述
近日,DeepSeek连续不断地开源了多个项目,一时间引发了关于GPU底层优化的热潮,这在如今国内算力被广泛打压的背景下,给我国在现代高性能计算(HPC)和人工智能(AI)领域带来了希望,其中尤其引人瞩目的是关于底层PTX优化技术引入,这在一定程度上绕过CUDA的性能限制,引领了未来 AI 计算优化领域的新方向(DeepSeek引入了众多优秀的机制来提高速度,比如NSA即本地稀疏注意力机制、非对称域带宽转发设计机制和通信内核优化机制等等,本文主要探讨底层的PTX优化技术)。使用PTX优化技术在一定程度上打破了英伟达CUDA技术的垄断、降低了算力成本、提升算力性能等,对未来AI的发展产生了重要影响,并且推动AI计算走向去中心化、小型化和高效化。PTX优化技术的应用场景也将会不断拓展,从边缘计算到自动驾驶,乃至医疗影像和AR/VR,都有望看到PTX的身影。本文将分析DeepSeek开源项目中所涉及的优化技术,并详细探讨PTX技术、PTX优化方法以及代码实现。
DeepSeek的成功在于通过一系列创新技术显著提升了深度学习模型的训练和推理效率,突破了大规模数据处理和复杂模型训练中的性能瓶颈。其论文详细介绍了核心技术,包括分布式计算优化、混合精度训练、自适应内存管理以及利用PTX进行GPU底层资源优化。例如,DeepSeek通过PTX实现高效的线程调度、内存优化和寄存器管理,从而最大化GPU的计算性能。这些技术使得其能够高效处理超大规模数据和复杂模型,同时显著降低了资源消耗。
尽管DeepSeek公开了部分技术细节,但其底层优化实现尚未完全披露,这引发了广泛的猜测。例如,可能涉及更高级的动态精度调整、智能内存管理、定制化硬件支持以及PTX指令级的优化等“黑科技”。为了揭示这些底层优化的潜力,我们的研究旨在探讨DeepSeek如何通过底层优化技术显著提升深度学习性能。本文将重点分析PTX在GPU计算中的关键作用及优化实践。首先,我们将简要介绍PTX技术,接着通过代码示例详细展示PTX优化策略,阐明其如何显著提升计算效率。通过这种深入的分析,我们还将分析DeepSeek开源项目中涉及到的优化技术(主要为PTX底层优化技术),以及探讨PTX优化对深度学习、科学计算等领域的深远影响,并进一步探讨其在推动高效计算架构发展中的重要意义。
02
PTX技术简析
PTX是NVIDIA提供的一种中间语言,用于CUDA编程模型。它位于高级CUDA C/C++代码和最终GPU机器代码(SASS)之间,作为硬件与程序之间的桥梁。PTX语言提供了一个低级别的抽象层,让开发者可以直接控制GPU的计算资源,同时又避免了过于依赖硬件架构,使得CUDA程序能够在不同的GPU架构上高效运行。
2.1 PTX的编译与执行过程
PTX代码是CUDA程序的中间表示。当开发者编写并编译CUDA程序时,CUDA编译工具链(nvcc)首先将CUDA C/C++源代码生成PTX代码,然后再转化为相关的机器代码(SASS)。
下图是NVCC编译CUDA的流程图,其过程分为离线编译和即时编译,离线编译如蓝色虚线框内所示。CUDA源程序(即xxx.cu文件)在编译前的预处理会被分为两部分:主机端(host)代码和设备端(device)代码。从图中我们可以看到,NVCC首先将.cu中的device部分交由右边流程处理(CUDA专用Compiler),host部分则交由左边流程处理(CPP/C专用Compiler),最后再将它们合并到一个object文件中。接着使用nvlink、fatbinary、Compiler对代码做进一步处理,最后使用Host Linker将主机端和设备端的目标文件(即主机目标文件test.o/test.obj和设备目标文件a_dlink.o/a_dlink.obj)合并生成最终的可执行文件a.out。
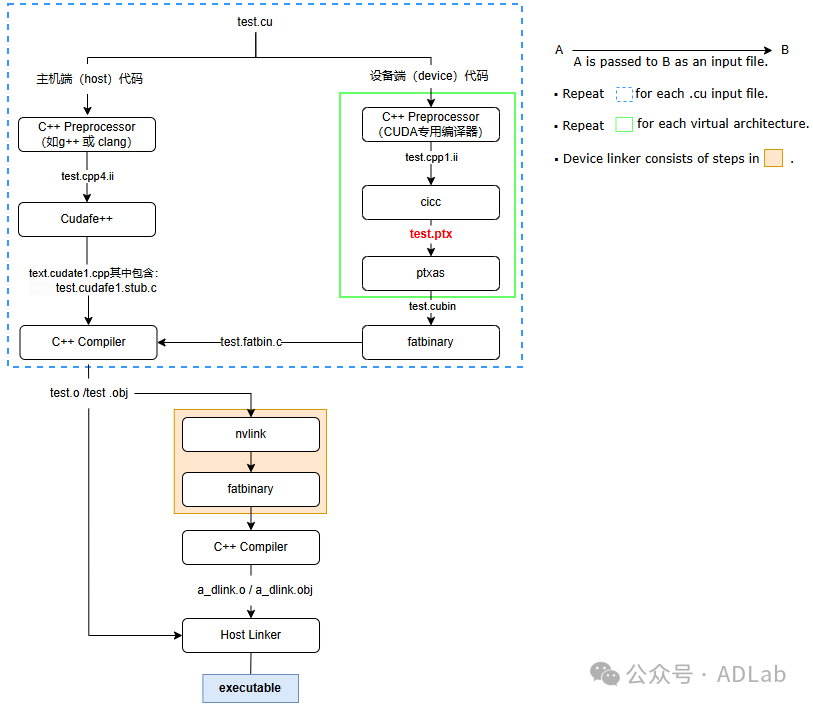
此外,NVCC编译时还可以通过-arch=sm_xx或-code=sm_xx(如sm_86)参数来指定编译时的虚拟架构或目标代码架构,生成相应的PTX。需要注意的是,此方法会直接生成SASS,跳过运行时PTX编译步骤。NVCC编译与运行流程图如下(指定具体架构)。
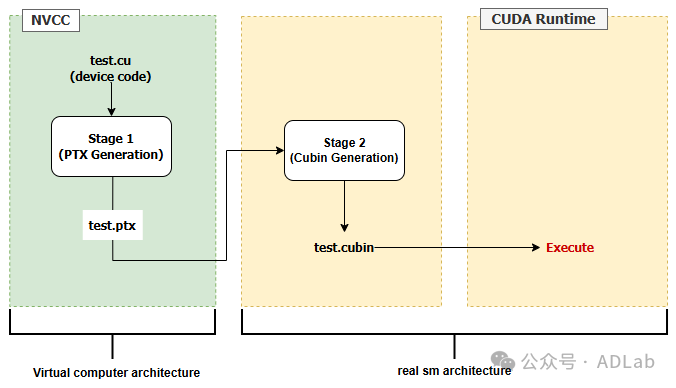
最终,生成的机器代码(cubin文件)被加载到GPU中执行,利用GPU的并行计算能力处理数据和执行任务。
2.2 PTX****示例代码及解释
为了更好地理解PTX的工作原理,我们将通过一个简单的CUDA程序示例来说明。该程序的主要功能是实现向量加法操作。我们将展示CUDA C++代码,并分析由nvcc编译器生成相应的及优化后的PTX代码。
CUDA C++ 代码:向量加法
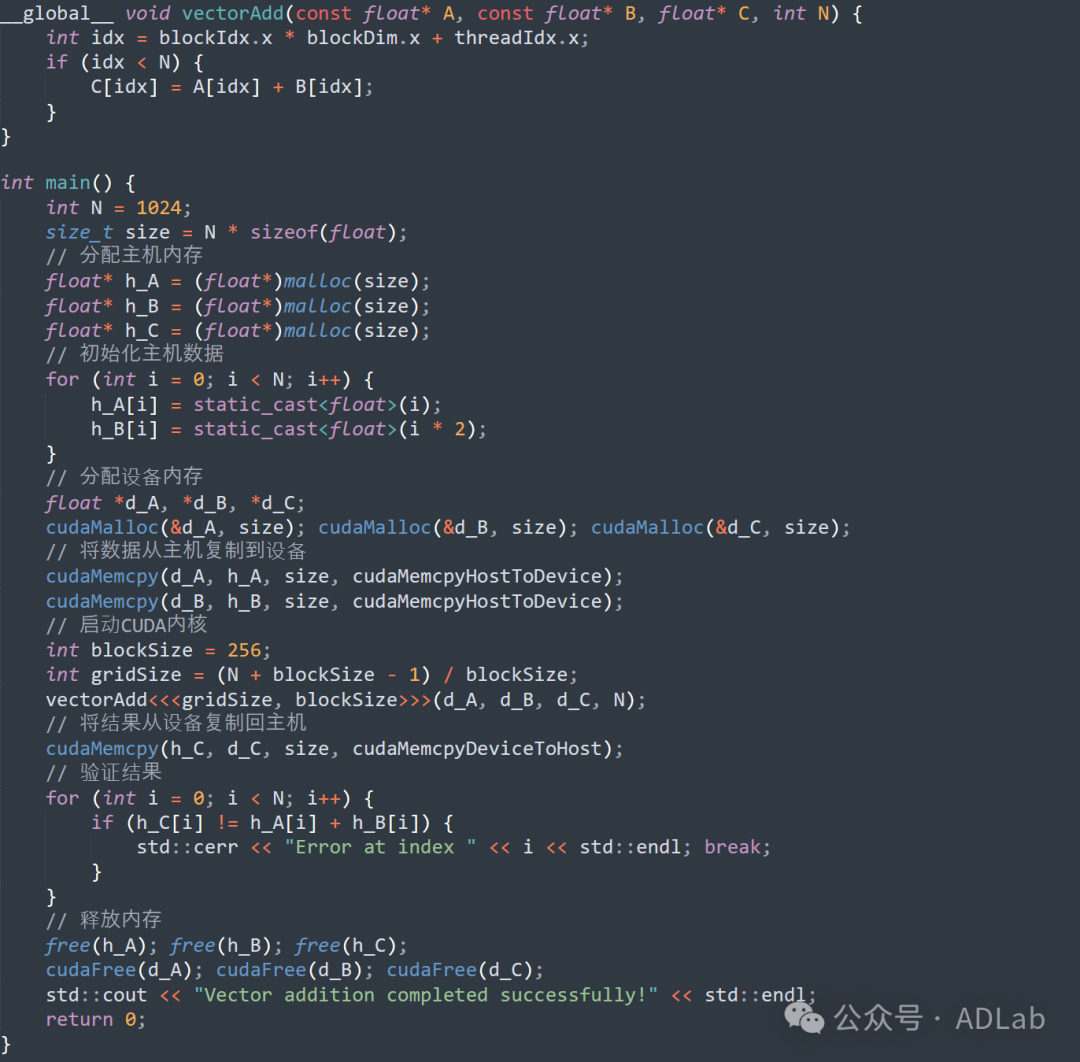
当上述程序被nvcc编译器编译时,会生成相应的PTX代码。具体如下图所示。
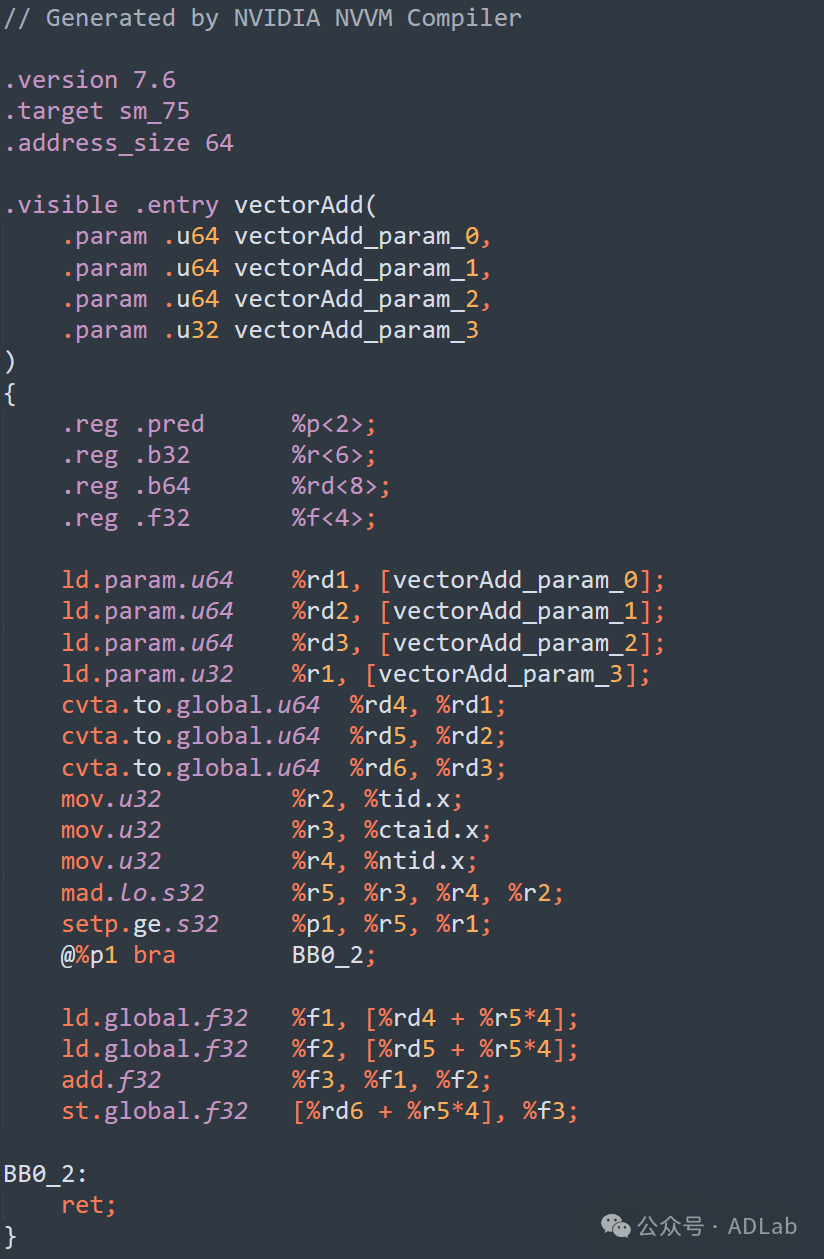
以上PTX代码的具体解析如下表所示:
|
元素类型 |
PTX代码元素 |
说明/描述 |
|
版本和目标架构 |
.version 7.6 .target sm_75 |
PTX版本为7.6 目标架构为sm_75(Turing架构) |
|
内核函数声明 |
.visible .entry vectorAdd .param .u64 vectorAdd_param_0, ... |
声明一个可见的内核函数vectorAdd 声明函数的参数(指针和标量) |
|
寄存器声明 |
.reg .pred %p<2>; .reg .b32 %r<6>; .reg .b64 %rd<8>; .reg .f32 %f<4>; |
声明2个谓词寄存器 声明6个32位整数寄存器 声明8个64位整数寄存器 声明4个32位浮点数寄存器 |
|
加载参数 |
ld.param.u64 %rd1, [vectorAdd_param_0]; 类似地,加载其他参数到寄存器%rd2、%rd3和%r1 |
加载第一个参数(指向向量A的指针) |
|
地址转换 |
cvta.to.global.u64 %rd4, %rd1; |
将通用地址转换为全局地址空间中的地址 |
|
线程和块索引计算 |
mov.u32 %r2, %tid.x; mov.u32 %r3, %ctaid.x; mov.u32 %r4, %ntid.x; mad.lo.s32 %r5, %r3, %r4, %r2; |
加载线程ID 加载块ID 加载块中的线程数 计算全局线程ID |
|
边界检查 |
setp.ge.s32 %p1, %r5, %r1;@%p1 bra BB0_2; |
检查全局线程ID是否超出向量长度 |
|
向量加法 |
ld.global.f32 %f1, [%rd4 + %r5*4]; ld.global.f32 %f2, [%rd5 + %r5*4]; add.f32 %f3, %f1, %f2; st.global.f32 [%rd6 + %r5*4], %f3; |
加载向量A的元素 |
|
退出 |
BB0_2: ret; |
退出点标签 |
正如我们前面所提到的,PTX是NVIDIA GPU的底层汇编语言,直接编写或优化PTX代码,如通过减少全局内存访问、使用寄存器优化、优化指令选择、利用共享内存等常见的PTX优化策略,则能够实现更细粒度的性能调优。基于这些优化策略对向量加法PTX代码的优化版本如下图所示。
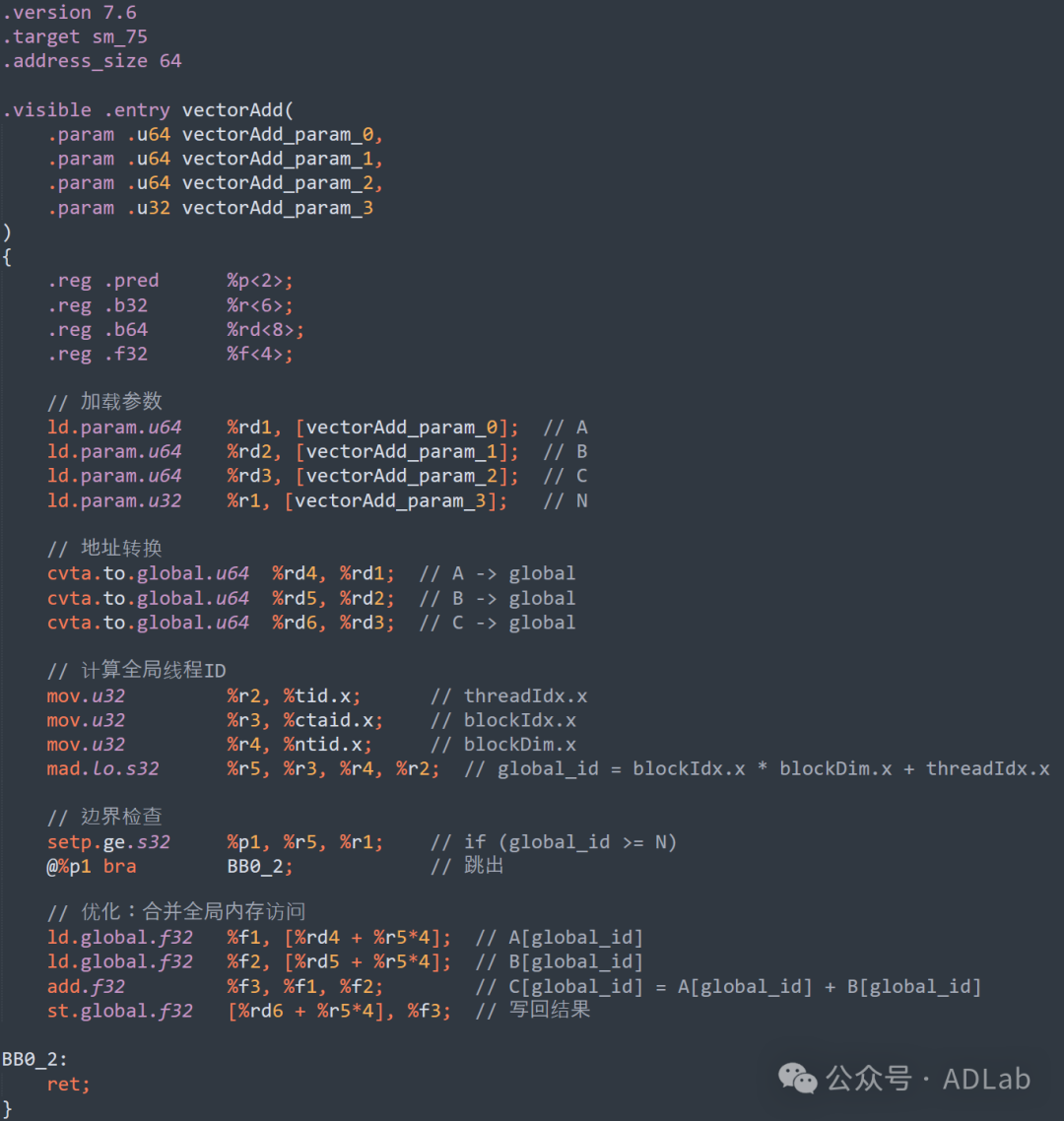
如果向量加法的数据量较大,我们还可以将数据分块加载到共享内存中,以减少全局内存访问次数。下图是使用共享内存进一步优化的版本。
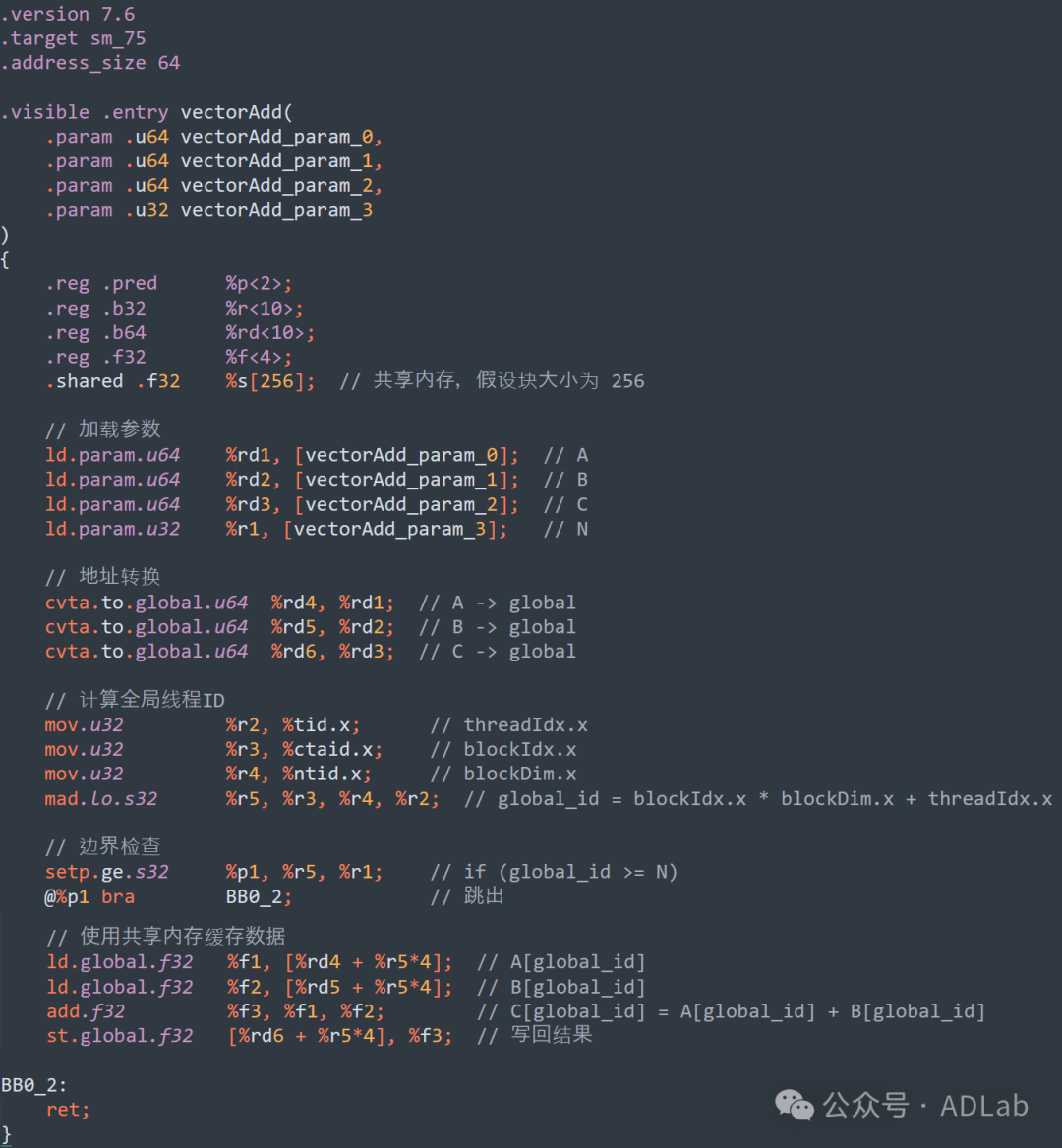
通过上述分析,我们可以看出,CUDA编译器生成的代码仍然存在显著的优化空间。通过直接操作和编写PTX代码,开发者可以更加精细地控制硬件资源,从而实现更高效的性能优化。接下来,我们将通过具体的代码案例,演示如何通过PTX优化策略,进一步提升程序的执行效率。
03
PTX优化技术实战
从前面的PTX示例代码可以看出,精细化优化PTX代码能显著提升程序性能。PTX作为低级别抽象层语言,让开发者能直接控制GPU计算资源。以向量加法为例,通过减少全局内存访问、寄存器优化和合理利用共享内存等策略,PTX代码执行效率大幅提升,这验证了PTX优化策略的有效性,也说明深入了解PTX工作原理对优化CUDA程序至关重要。
基于此,接下来将深入探讨PTX优化策略,包括指令级、内存层次、线程调度、控制流及硬件资源优化等方面,结合代码案例展示实际应用中的性能突破。目标是为帮助开发者高效利用GPU计算能力,在复杂计算任务中发挥GPU优势,达到理想性能表现。下文将按类别阐述各优化策略及其实现方式,助力开发者掌握PTX优化精髓,灵活应用于CUDA程序开发,提升程序运行效率。
3.1 指令级优化
(1)FMA(乘加融合指令)优化
现代NVIDIA GPU(如Ampere/Hopper架构)的每个流式多处理器(SM)均配备专用FMA(Fused Multiply-Add)单元。FMA指令在单周期内完成乘法和加法操作,相比独立指令可提升2倍计算吞吐量。该优化尤其适用于线性代数运算(如矩阵乘法)和物理模拟中的向量计算。以下是优化前后的代码对比:
优化前(分离指令):

优化后(FMA指令):

从上面代码可以看出,将两个独立的单精度浮点指令(乘法和加法)替换为一个FMA指令后,指令数量减少一半,寄存器利用率也得到提高,因为在FMA指令中无需单独存储中间结果。
(2)向量化内存访问
NVIDIA GPU的全局内存控制器支持单次128位(v4.f32)或256位(v8.f32)宽位宽事务。向量化加载可将多个标量操作合并,减少内存事务次数。例如,使用ld.global.v4.f32相比四次ld.global.f32可减少75%的全局内存请求。
优化前(标量加载):

优化后(向量化加载):

从优化前后的代码可以看出,向量化加载指令,可以将多个标量操作合并为一个操作,从而显著减少内存事务的次数。以加载四个连续的单精度浮点数为例,使用ld.global.v4.f32指令相较于连续执行四次ld.global.f32指令,可以将全局内存请求次数减少75%。这不仅可以降低内存访问的延迟,还能提高L1缓存线的利用率(可达100%),并且在理论上将内存带宽的利用率提升4倍,从而在内存密集型的计算任务中显著提升性能。
3.2 内存层次优化
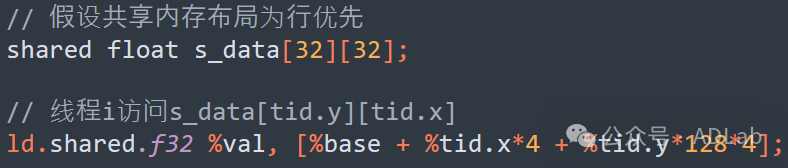
(1)共享内存Bank冲突消除
NVIDIA GPU的共享内存划分为32个独立Bank(Ampere架构),每个Bank位宽4字节。当同一Warp内的多个线程访问同一Bank不同地址时,将触发Bank冲突导致串行化访问,从而显著增加访问延迟。例如下面的示例代码:
优化前:
优化后(转置存储):
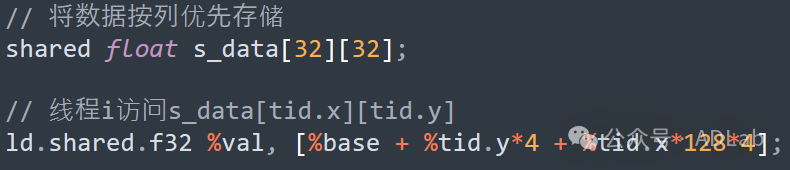
当一个Warp内的32个线程同时沿X方向访问以行优先布局的共享内存矩阵时,由于步长为4字节,所有线程会访问同一个Bank,引发32路串行访问,延迟可达32个周期。为了解决这个问题,可以通过转置存储的方式重新组织共享内存中的数据,使得线程的访问步长变为512字节(如使用列优先布局),从而确保每个线程访问不同的Bank,实现完全并行的访问,将延迟大幅降低。
(2)数据预加载
通过提前将数据从高延迟内存(全局内存)加载至低延迟存储(共享内存或寄存器),可以在计算单元执行当前任务的同时异步加载下一批数据,实现计算与内存访问的重叠。这种技术可以有效隐藏内存延迟,特别适用于数据复用率较高的场景,如卷积运算或矩阵乘法。例如下面的代码示例:
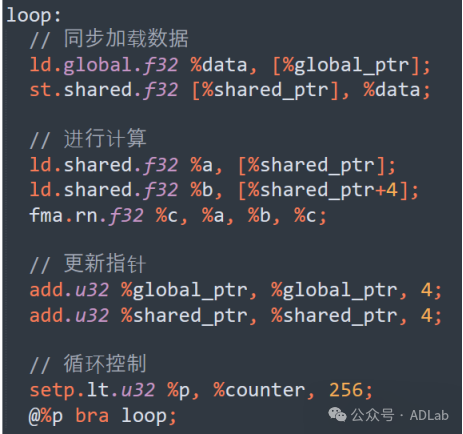
优化前(同步加载):
优化后(双缓冲预加载):
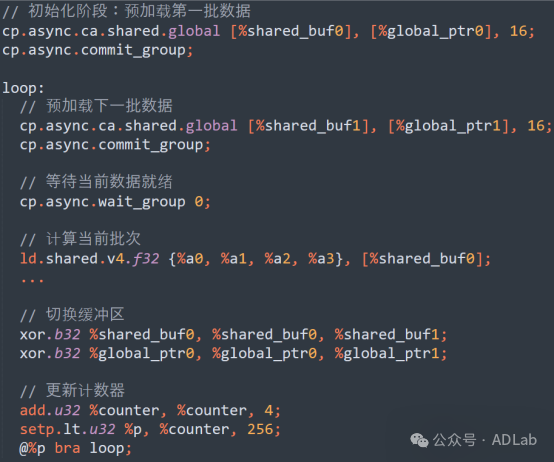
与未优化的同步加载版本相比,使用双缓冲预加载技术可以避免计算与加载的串行执行问题。在双缓冲机制中,两个共享内存缓冲区被交替用于数据加载和计算,而异步指令(如cp.async)则用于非阻塞的内存传输。此外,向量化加载指令(如ld.shared.v4.f32)可用于进一步提升共享内存的吞吐量,确保数据能够快速地从共享内存中加载到寄存器中以供计算使用。
3.3 线程调度优化
(1)Warp Occupancy优化
Occupancy指每个SM中活跃Warp数与理论最大值的比率。较高的Occupancy可以更好地隐藏指令延迟,但需要在寄存器和共享内存的使用之间进行平衡。如果线程块中每个线程使用的寄存器数量过多或者共享内存的使用量过大,都会导致Occupancy的下降。
优化前:

问题诊断(通过nsight compute):如果每个线程使用了64个寄存器,那么根据GPU的硬件限制,最大Occupancy可能只有25%;同时,共享内存用量达到8KB也会限制每个线程块内的线程数。
优化方案:
A. 寄存器压缩:复用寄存器,减少生命周期

B. 共享内存动态分配:

通过寄存器压缩技术,如复用寄存器或减少寄存器生命周期,以及采用共享内存的动态分配方式,可以显著提高Occupancy。在优化后,Occupancy可能从25% 提升至66%,从而使每个SM 中的活跃Warp 数量从32增加到64,进而能够在相同的时间内执行更多的线程束,提升GPU的整体计算效率。
(2)Warp同步原语
在一些需要线程之间进行通信的场景中,使用共享内存进行线程通信时,可能会触发Bank冲突,并且需要多次访问内存来完成数据的同步。例如下面的代码:

优化方案(Warp Shuffle):

线程内求和操作通常需要将数据存储到共享内存中,然后利用barriers进行同步,之后再通过循环的方式汇聚结果。然而,这种方法需要多次访问共享内存,不仅增加了访存次数,还会受到Bank冲突的影响,降低同步的速度。相比之下,使用Warp级同步原语,如Warp Shuffle,可以完全避免共享内存的访问。通过shfl_sync指令,可以快速地在同一个Warp内的线程之间交换数据,并且整个操作可以在极少的指令周期(如4个周期)内完成,同时无需担心Bank冲突的问题。这对于那些需要频繁进行线程间数据交换和同步的计算任务来说,可以显著提升性能。
3.4 控制流优化
(1)编译器指令优化
通过使用编译器指令(如:#pragma unroll)来指导编译器自动展开循环,可以减少分支指令(如:bra)和条件判断(setp)的开销,同时暴露更多的指令级并行(ILP)机会。示例代码如下:
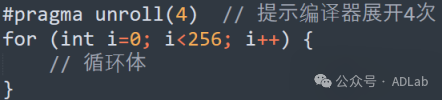
(2)手动展开策略
当编译器无法自动优化(如存在复杂依赖)时,手动展开可精确控制指令流。
优化前代码(未展开):
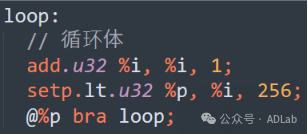
优化后(手动展开):

通过手动展开循环4次,可以消除循环控制逻辑,减少分支语句的执行次数,从而降低分支误预测率,提升IPC(每周期指令数)。
3.5 Warp级别优化
(1)Warp级别任务分配
将不同的任务(如IB发送、NVLink接收或矩阵乘法)分配给不同的Warp,避免块级同步的瓶颈,提高GPU利用率。Warp级别的任务分配的代码示例:
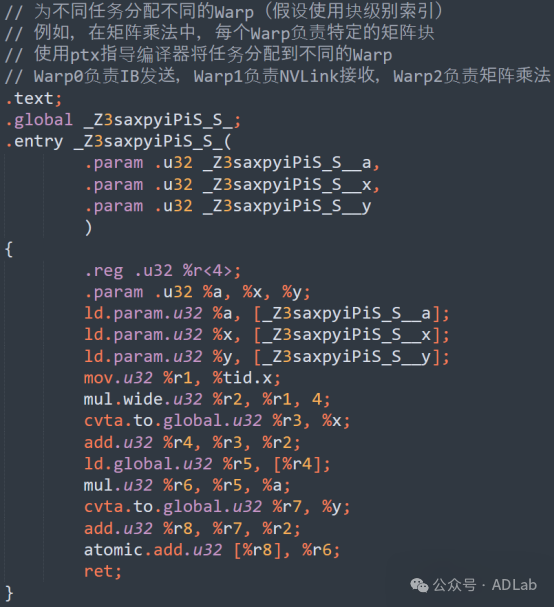
(2)通信和计算重叠
通过在同一个块或多个SM中调度不同的Warp来重叠通信和计算任务,动态调整用于不同任务的Warp数量,基于实时工作负载进行优化。一个通信和计算重叠的代码示例:
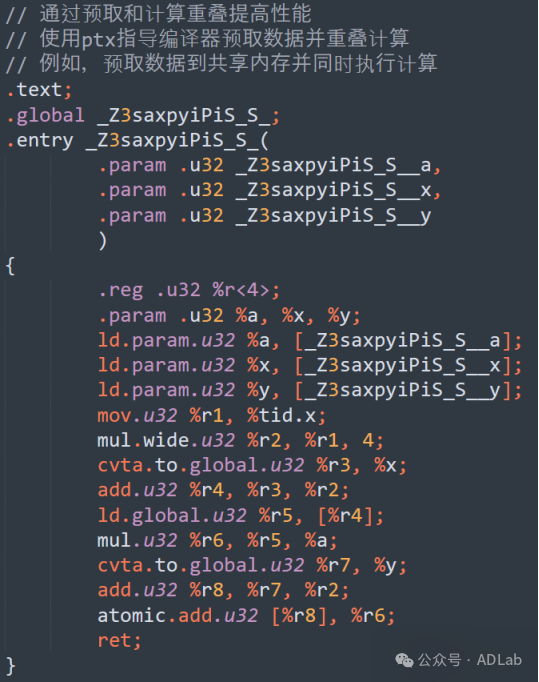
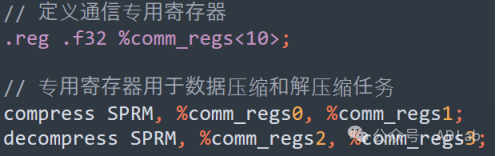
3.6 硬件资源优化
在训练DeepSeek V3模型时,DeepSeek对英伟达H800 GPU进行了重新配置,将132个流处理器中的20个专门用于服务器之间的通信,优化数据压缩和解压缩,减少互连瓶颈。PTX层面的资源分配的示例代码如下:
通过上述对PTX优化策略及代码案例的详细阐述,我们可以看到优化策略涵盖了从指令级、内存层次、线程调度到硬件资源分配和流水线优化等多个层面,通过具体的代码示例展示了如何在实际应用中实现这些优化。
04
DeepSeek优化思路概述
在撰写本文期间,恰逢DeepSeek“开源周”,目前已有FlashMLA、DeepEP和DeepGEMM 三个项目完成开源。这些项目中涉及的PTX优化技术也值得关注。具体而言,FlashMLA项目通过BF16支持和分页kvcache等技术提升了Hopper GPU上的解码性能;DeepEP项目通过优化NVLink和RDMA转发,提供了高效的专家并行通信库;DeepGEMM项目采用JIT编译和TMA加速等技术,实现了高效的FP8 GEMM计算。其中开源社区对FlashMLA项目优化方法做了进一步的探讨,这里也引用过来以提供给读者作为技术参考,其中涉及Hopper异步拷贝强化、共享内存Bank冲突优化等,以提升内存带宽利用率、计算吞吐量和指令发射效率。下文将重点介绍这些项目中的PTX层优化策略。
4.1 FlashMLA项目
2月24日,DeepSeek “开源周”的首个开源项目为FlashMLA。FlashMLA是针对NVIDIA Hopper架构GPU设计的高效MLA解码内核。下面展示了其中一段代码:
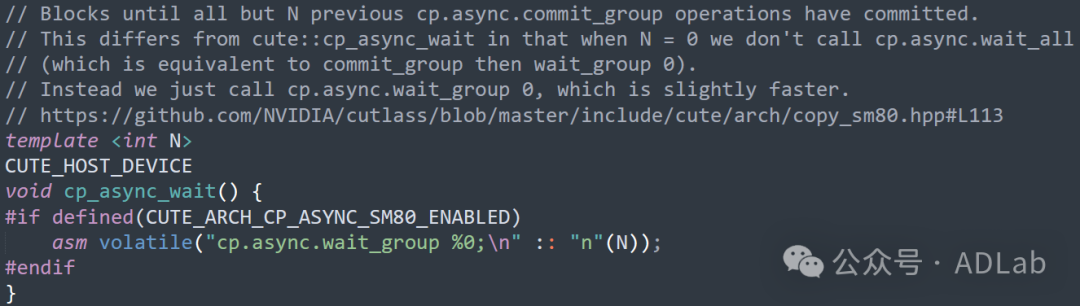
通过使用PTX指令cp.async.wait_group实现了一个高效的异步内存拷贝等待机制。允许开发者在GPU上提交多个异步内存拷贝操作,并指定等待的内存拷贝操作数量,从而优化了GPU的内存访问和计算性能。例如,当N=0时,仅调用cp.async.wait_group 0,这比调用cp.async.wait_all更快。
4.2 DeepEP项目
2月25日,DeepSeek发布了“开源周”的第二个开源项目DeepEP,该项目是一个针对混合专家Mixture-of-Experts(MoE)和专家并行(EP)的通信库,提供高吞吐量和低延迟的all-to-all GPU内核,这些内核也被称为MoE分发和合并,其可使得数据在多个GPU间快速传输,减少通信时间。此外其通过支持低比特操作如FP8格式,显著降低计算和存储需求,提升整体效率,并针对非对称域带宽转发,提供优化内核,适合训练和推理Prefill任务,允许直接内存访问,减少CPU介入。DeepEP的优化确保数据在不同域之间高效传输,特别适用于大规模混合卡的分布式训练。
在DeepEP项目的csrc/kernels/ibgda_device.cuh文件中,包含了与PTX优化相关的代码。以下是对这些代码的描述:
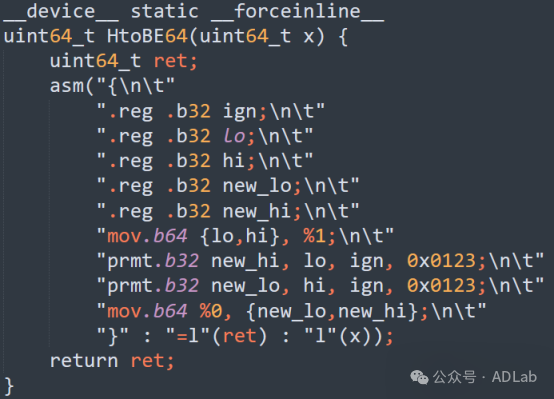
HtoBE64函数实现了将64位无符号整数从主机字节序高效转换为大端字节序的功能,通过PTX指令直接在GPU上进行64位无符号整数的字节序转换,避免了数据传输到主机进行转换的开销,提高了性能。
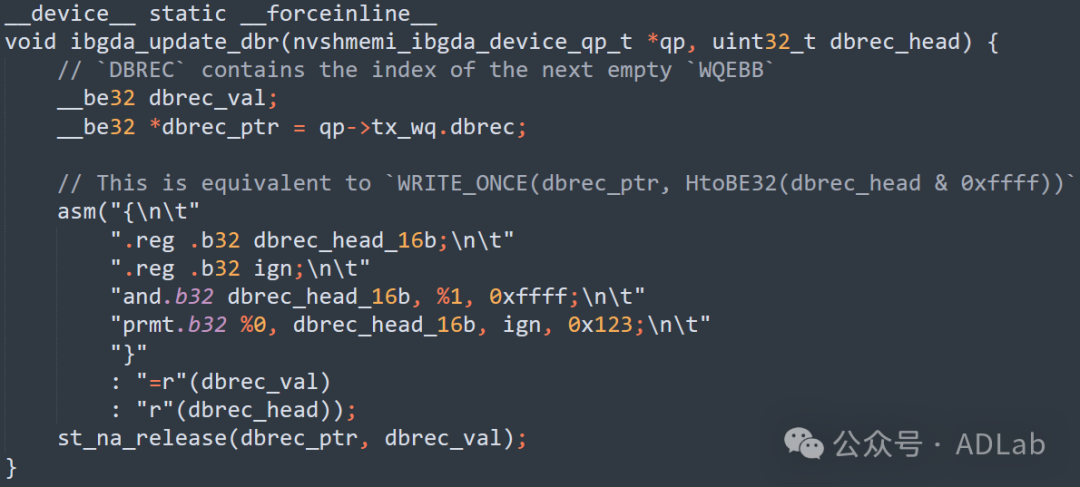
ibgda_update_dbr函数实现了更新设备队列的DoorbellRecord的功能,使用PTX指令直接在GPU上处理和写入数据,更新设备队列的DoorbellRecord,确保了数据的一致性和可见性,同时减少了主机干预。
4.3 DeepGEMM项目
2月26日,DeepSeek发布了“开源周”的第三个开源项目DeepGEMM。DeepGEMM是一个针对FP8 GEMM的高效库,支持细粒度缩放,适用于Dense和MoE模型。该项目采用JIT编译和TMA加速等技术,实现了高效的FP8GEMM计算。为了提高效率,该项目使用了一些PTX优化代码,例如下图所示:
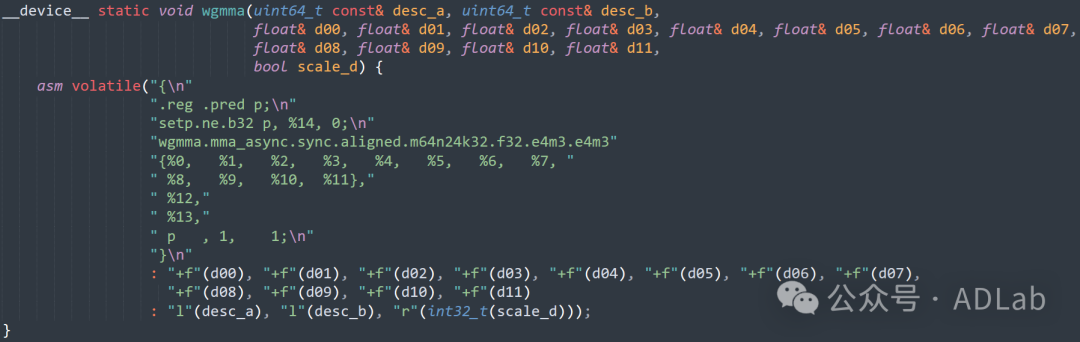
该函数通过使用.reg指令定义预测寄存器p,结合setp.ne.b32指令设置条件,以及wgmma.mma_async.sync.aligned指令进行异步矩阵乘法,实现了高效的计算优化。
4.4 社区中的一些优化策略
在FlashMLA项目中有一个issues,对DeepSeek项目提出了一系列建设性的优化策略,其中包含Hopper异步拷贝强化、共享内存Bank冲突优化等,以提升内存带宽利用率、计算吞吐量和指令发射效率。这里引用过来,给读者作为技术参考(链接:https://github.com/deepseek-ai/FlashMLA/issues/26)。
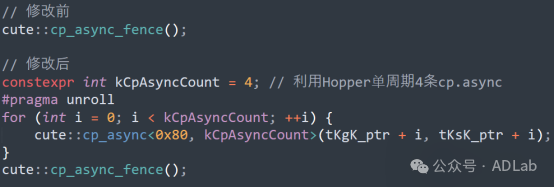
(1)Hopper异步拷贝强化
利用Hopper单周期发射4条异步拷贝指令的特性,提升SMEM填充吞吐量。
(2)共享内存Bank冲突优化
调整P矩阵布局,确保每线程访问64字节对齐的连续内存,减少bank冲突。

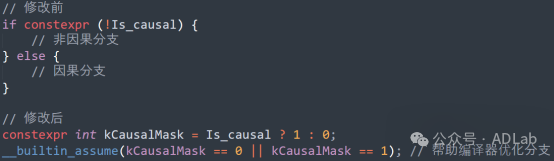
(3)动态指令流优化
通过__builtin_assume提示编译器优化条件分支。
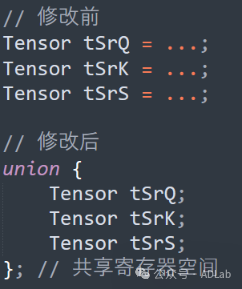
(4)寄存器压力优化
对临时张量使用联合存储,减少寄存器占用。
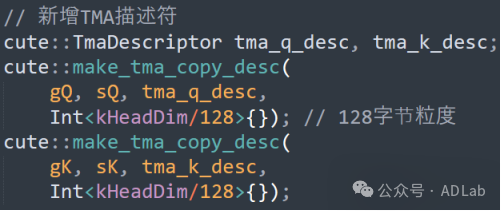
(5)TMA加速全局内存访问
利用Hopper的Tensor Memory Accelerator (TMA) 加速大块数据传输。
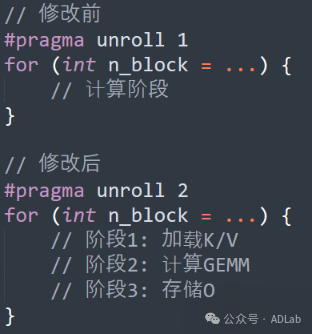
(6)软流水线优化
引入软件流水线策略,增加指令级并行。
(7)混合精度计算优化
利用Hopper硬件加速的混合精度转换指令。
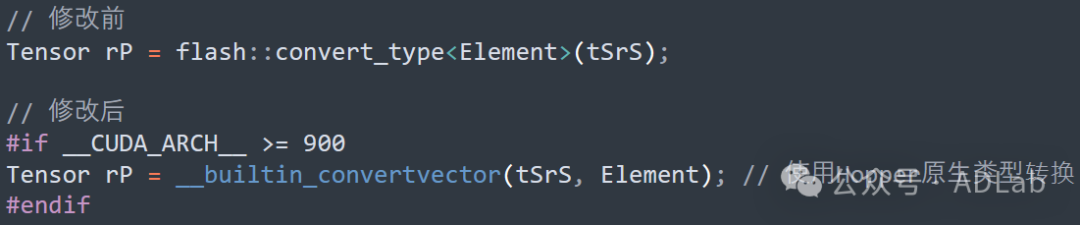
(8)动态资源分配
根据头维度动态调整线程数,优化资源利用率。

(9)指令调度优化
手工调优关键矩阵乘法的PTX指令调度。

(10)缓存提示指令
利用Hopper L2缓存控制指令优化数据局部性。

(11)性能预期
通过上述优化组合,预计可在以下方面提升:
-
内存带宽利用率提升15-20%,达到3500+ GB/s
-
计算吞吐量提升10-15%,达到650+ TFLOPS
-
指令发射效率提升20-30%
-
寄存器压力降低15-20%
建议使用Nsight Compute进行迭代验证,重点关注:
-
stall_long_sb 指标(内存等待)
-
smsp__sass_inst_executed指令分布
-
l1tex__t_sectors_pipe_lsu_mem_global_op_ld全局加载效率
05
总 结
本文详细探讨了PTX的内在机制、PTX的GPU优化技术、优化策略和相关的一些优化案例并分析了近期DeepSeek开源项目中所涉及的一些优化技术。我们知道PTX的GPU优化可以为AI计算性能的突破提供有力支撑,国内外各科技公司也都在研究PTX的GPU优化的更多可能性,其中,我国AI公司深度求索推出的DeepSeek模型,在PTX优化创新方面取得了巨大成效。比如在模型训练中,使得训练时间显著缩短,使得推理速度实现了倍数级增长,并且有效提高了训练能效比。DeepSeek的这一创新在AI行业引起了广泛的关注和震动,有人认为这一创新可能颠覆传统高投入的AI开发路径,深刻影响AI的发展趋势,为未来AI计算领域指明新方向。
针对PTX进行优化,理论上可以更充分地利用GPU的硬件资源,从而提升 AI模型的训练和推理性能。AI模型的性能将进一步提升,训练速度更快,推理效率更高,这将为更大规模、更复杂的AI应用提供可能。
同时,随着这一创新的应用,很可能打破NVIDIA在AI加速领域的垄断,使得AI应用的成本大幅下降,更多中小型企业和开发者将能够参与到AI应用的开发中来,从而加速AI技术的普及,AI的应用场景将不断拓展,从边缘计算到物联网,从自动驾驶到机器人,从医疗影像到基因组学,从增强现实(AR)到虚拟现实(VR),我们会随处看到AI的身影。
再者,打破NVIDIA的垄断,将为国内其他硬件厂商提供更多机会,促进AI加速硬件市场的多元化竞争。AI加速将不再局限于NVIDIA的CUDA生态,而是可能出现多种技术路线并存的局面。这将为国产AI芯片厂商带来发展机遇,助力实现AI产业链的自主可控,提升国家在AI领域的战略竞争力。
此次DeepSeek针对PTX的优化创新标志着中国在AI领域的自主创新进入新阶段,美国芯片制裁反而倒逼中国企业在算法和架构上实现突破。这种技术突破不仅为AI行业树立了新的标杆,也为未来AI的发展提供了新的思路和方向,启明星辰ADLab会持续关注深度求索和国内外其他AI科技公司在GPU优化方面的新动向。
网络安全工程师(白帽子)企业级学习路线
第一阶段:安全基础(入门)
第二阶段:Web渗透(初级网安工程师)

第三阶段:进阶部分(中级网络安全工程师)


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)