DeepSeek揭秘 V3/R1 推理系统,成本利润率高达 545%
DeepSeek 在开源周第六天发布了 V3/R1 推理系统的优化细节,通过跨节点的 EP 驱动批量扩展、计算与通信重叠以及负载均衡等技术手段,大幅提升了系统的吞吐量并降低了延迟。每个 H800 节点每秒可处理 73,700 个输入 tokens 和 14,800 个输出 tokens,统计涵盖网页、APP 和 API 的所有负载。
人工智能咨询培训老师叶梓 转载标明出处
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
更多分享,关注视频号:sphuYAMr0pGTk27 抖音号:44185842659
DeepSeek 在开源周第六天发布了 V3/R1 推理系统的优化细节,通过跨节点的 EP 驱动批量扩展、计算与通信重叠以及负载均衡等技术手段,大幅提升了系统的吞吐量并降低了延迟。每个 H800 节点每秒可处理 73,700 个输入 tokens 和 14,800 个输出 tokens,统计涵盖网页、APP 和 API 的所有负载。
大规模模型推理的效率瓶颈
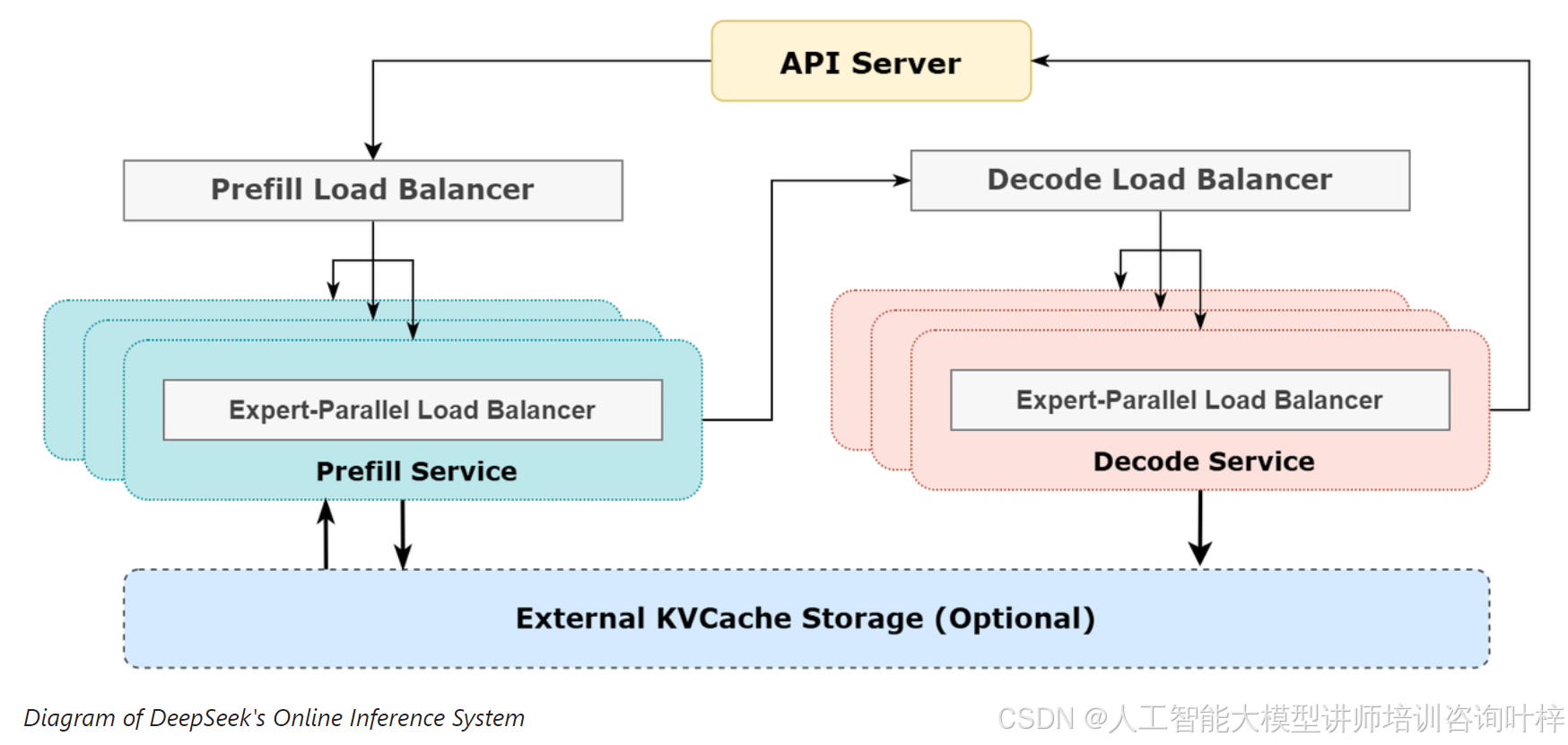
DeepSeek-V3/R1 模型采用了大规模的专家并行(EP)架构,这一架构虽然能够显著提升计算效率,但也带来了系统复杂性增加、通信开销增大以及负载不平衡等问题。具体来说:
-
通信开销:大规模跨节点的 EP 导致节点间通信频繁,增加了通信延迟。
-
负载不平衡:在多节点并行计算中,如果某个 GPU 负载过高,就会成为性能瓶颈,导致其他 GPU 空闲,资源利用率低下。
-
推理效率:如何在大规模并行环境下实现高效的推理,同时保持低延迟和高吞吐量,是亟待解决的问题。
优化方法:计算与通信的协同优化
DeepSeek 团队通过一系列创新的方法,成功解决了上述问题:
-
计算-通信重叠机制
为了隐藏通信延迟,DeepSeek 团队采用了双微批处理策略。在预填充阶段,将请求批次拆分为两个微批次,交替执行,使得一个微批次的通信成本可以隐藏在另一个微批次的计算过程中。在解码阶段,由于不同阶段的执行时间不平衡,团队进一步细分注意力层,并采用五阶段流水线,实现了无缝的通信-计算重叠。 -
负载均衡策略
针对大规模并行带来的负载不平衡问题,DeepSeek 团队设计了多种负载均衡器:-
预填充阶段负载均衡器:平衡核心注意力计算和分发发送负载,确保每个 GPU 的计算量均匀。
-
解码阶段负载均衡器:平衡 KVCache 使用和请求分发负载,避免某个 GPU 过载。
-
专家并行负载均衡器:针对 MoE 模型中高负载专家的问题,优化专家计算负载分配,减少 GPU 之间的负载差异。
-
-
大规模跨节点专家并行
DeepSeek-V3/R1 模型的高稀疏性要求极高的整体批次大小,以确保每个专家有足够的批次大小,从而提高吞吐量和降低延迟。团队在预填充阶段和解码阶段分别采用了不同级别的并行策略,充分利用 GPU 资源。
性能与成本分析
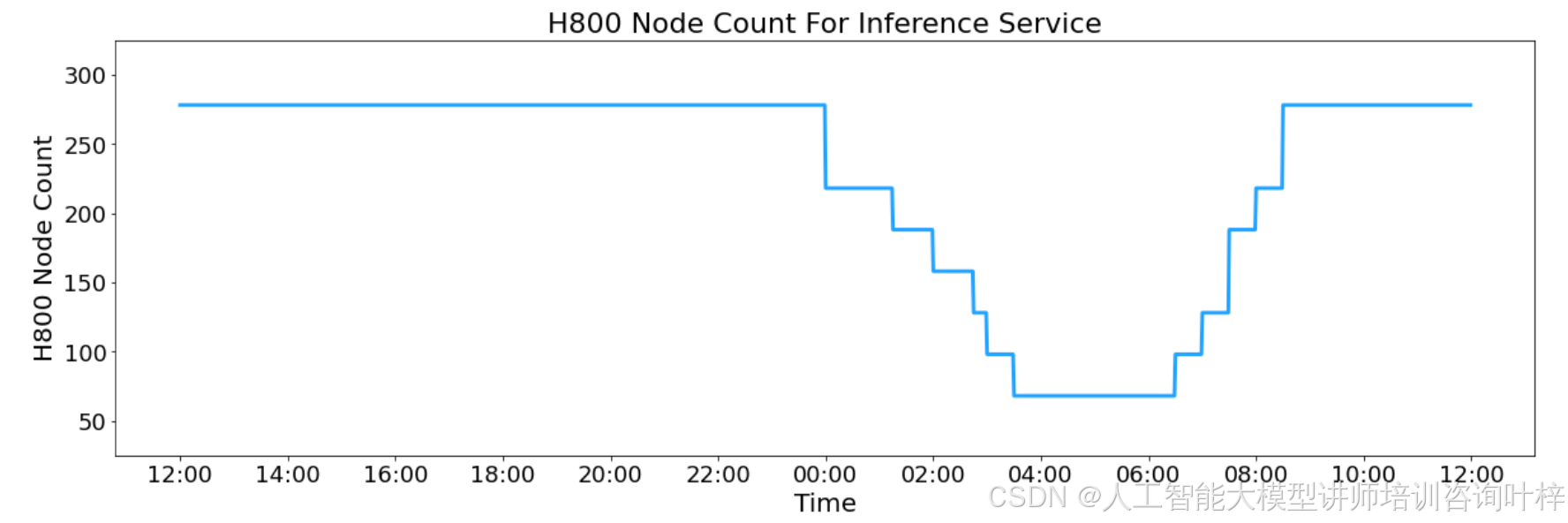
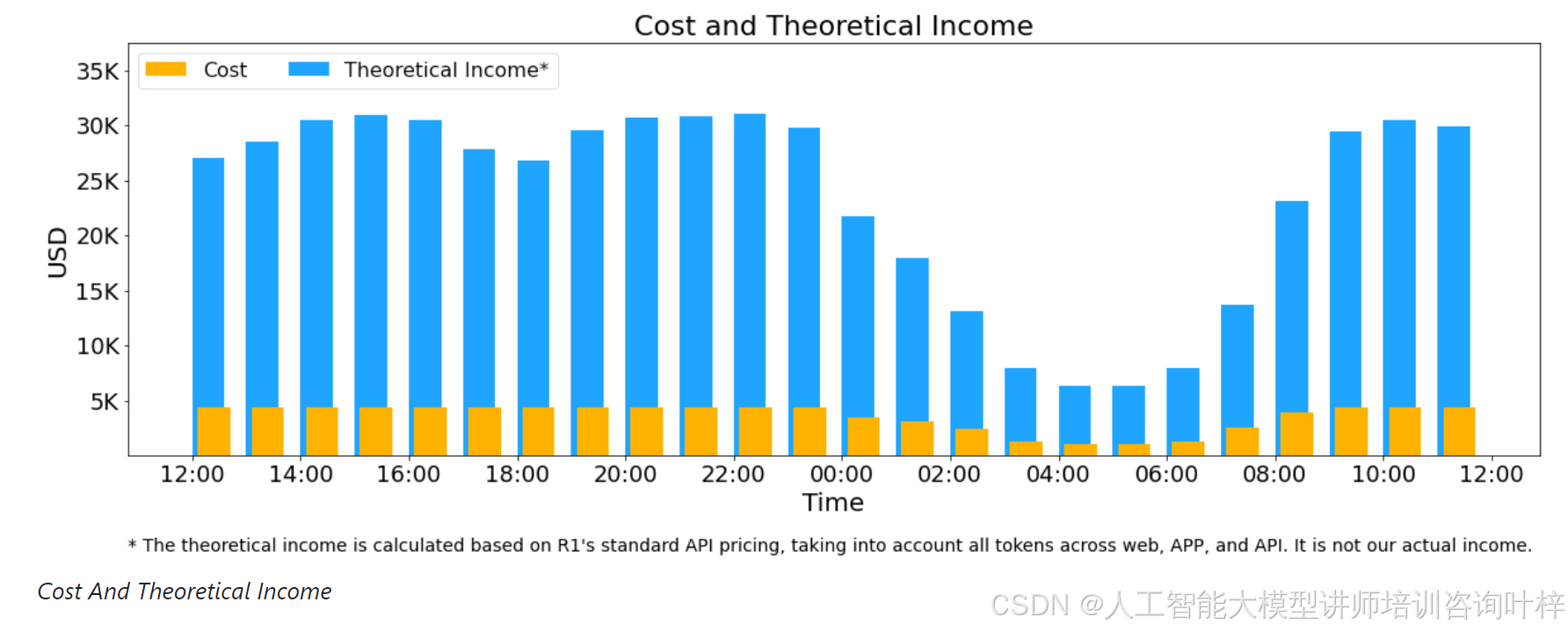
DeepSeek 的推理服务运行在 H800 GPU 上,采用与训练一致的精度。在过去的 24 小时内,V3 和 R1 推理服务的峰值节点占用达到了 278 个,平均占用 226.75 个节点。假设每个 H800 GPU 的租赁成本为每小时 2 美元,每天的总成本约为 87,072 美元。
然而,由于 DeepSeek-V3 的定价低于 R1,且部分服务(如网页和 APP 访问)仍免费,实际收入远低于理论值。尽管如此,DeepSeek 团队通过优化资源分配和负载均衡,显著提高了系统的整体效率和资源利用率。
DeepSeek 团队通过创新的计算-通信重叠机制、负载均衡策略以及大规模专家并行设计,成功解决了大规模模型推理中的效率瓶颈问题。这些优化方法不仅提高了系统的吞吐量和响应速度,还显著降低了通信延迟和资源浪费,为大规模 AI 模型的推理提供了新的解决方案。
项目链接:DeepSeek-V3/R1 推理系统

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)