
AI声音克隆GPT-SoVITS之ollama语音脚本openWebUI本地TTS输出过程记录
最后借这次测试,聊几句ai做生产力的看法。我觉得AI已经来到了量变的时间节点。原先我觉得AI未来可期,是因为它在通用领域既取代不了高等人才,又没中间层职员好用,还没基层牛马劳动力便宜,所以绝大部分的行业无法真正地把AI当生产力来用。但是现在deepseek接入这个接入天天上新闻,ai在开始铺量之后,尤其是大厂竞争的内卷,openAi官宣gpt5免费开放使用,ai不久将来会取代某些人行业某些底层的人
前言:
今年春节,我本打算把没玩过的ai语音ai绘画尝试一下,见识当下的开源成果,我翻出了去年浮动在我首页被我收藏AI声音克隆——GPT-SoVITS,跟B站视频逐步操作,不得不说出来效果很惊艳,让我这种铁耳朵人士高呼神了!
那几天我正在部署本地大预言模型玩deepseek,突发奇想,我能不能用ollama本地部署的deepseek和GPT-SoVITS结合起来,让deepseek生成文字,让GPT-SoVITS进行朗读。接下来好几天我都琢磨此事,连我玩ai绘图的计划也吹了,sd装了一年至今不会用......(´_ゝ`)然而并没有什么卵用,好几天搜刮确认了想法是可行的,但是没找到方法,网上也没有教程。
我跟风玩ai,很多专业术语和大段代码小白也不懂,最初我的想法只是GPT-SoVITS能接入openwebUI 就好了(因为我是ollama+openWebUi部署),可连捣鼓几天没有下文,我就把这个念头搁置了,再后来就每天捡一点碎片化的知识看,在看别的教程,忽然悟到了一些灵感,于是换了一个思路打通了任督二脉!
我写这篇笔记第一部份gptsovits使用1月底写的,第二部分接ollama是二月上写完,第三部份卡了很久二月中测试成功,现在做出一个可以分享的版本。在感谢花儿大佬的开源,和刘锐大佬修改的接口包,多亏各位大佬无私开源, 才能让我们普通互联网用户也能吃上ai这口热饭。
特别说明,我这二和三的部分都是建立在一能成功运行推理出音频的基础上,软件对显卡有4g以上的要求,如果本身运行 gpt-sovits 都有问题,后面都可不用看了。
第一部分:GPT-SoVITS网页端生成语音之图片版
这是我跟b站教程截图做的笔记,以免我后面再用这个软件忘记怎么操作,会的可以跳过,如果想要详细的教程可以见gptsovits的作者花儿不哭开源界面。
RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)![]() https://github.com/RVC-Boss/GPT-SoVITSGPT-SoVITS是一个开源的声音克隆项目,通过少量的样本数据实现高质量的语音克隆和文本到语音转换。 该工具特别适用于需要快速生成特定人声的场景,可以帮助用户在没有或只有少量目标说话人语音样本的情况下,训练出能够模仿该说话人声音的模型。
https://github.com/RVC-Boss/GPT-SoVITSGPT-SoVITS是一个开源的声音克隆项目,通过少量的样本数据实现高质量的语音克隆和文本到语音转换。 该工具特别适用于需要快速生成特定人声的场景,可以帮助用户在没有或只有少量目标说话人语音样本的情况下,训练出能够模仿该说话人声音的模型。
优点:快捷高效,作用:克隆声音,读小说、做桌宠、文本语音生成神器
1.下载花儿大佬的环境整合包,傻瓜式解压后,在文件目录下双击go-webui.bat。会弹出一个9874端口页,如果没有跳转就手动输入一下地址 localhost:9874
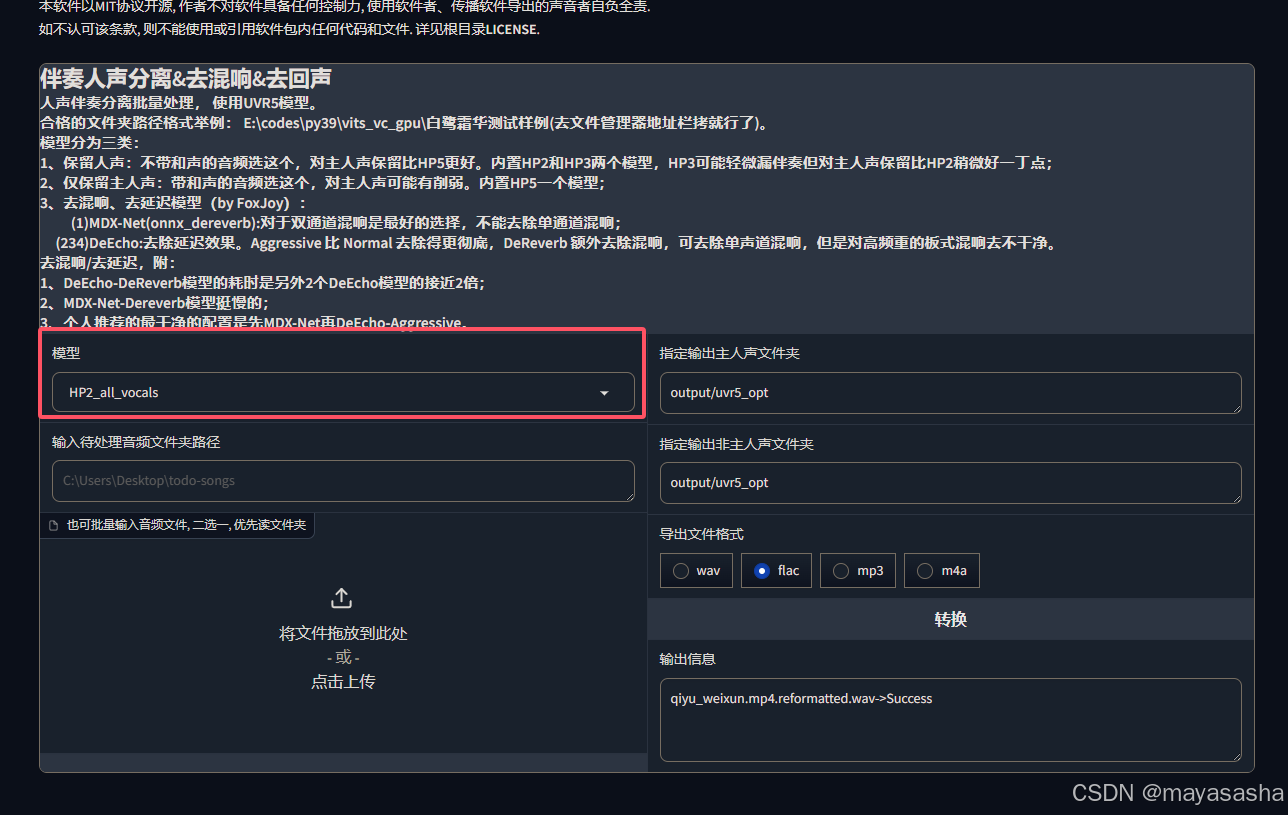
2.第一步是分离一个声音文件文件中的人声和bgm,如果有纯净的干音可以跳过这一步。
操作:开启UVR5_web,在9873端口的页面分离需要ai解析的声音,上传音频 ,选择模型,点击转换,得到人声和bgm,会放在软件路径output\uvr5_opt
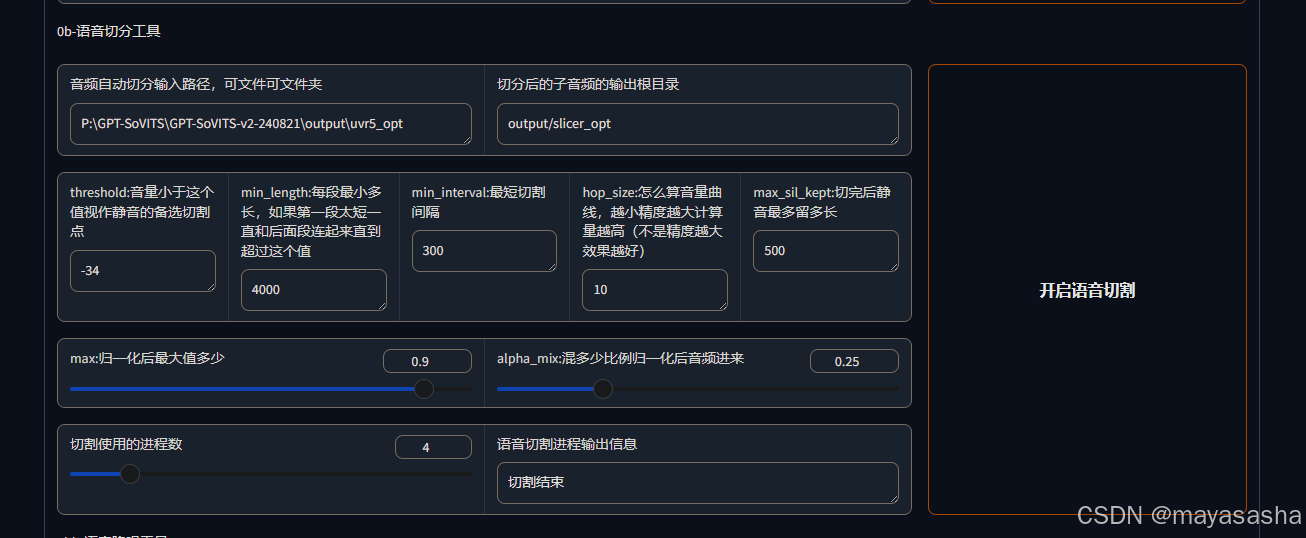
3.第二步把原声语音切割3-5s的音频,方便AI学习。
操作:回到9874端口页,关闭UVR5输入路径,在音频自动切分输入路径填入纯净人声的路径(如果按照默认操作步骤来,全程不用改路径),开启语音切割,这步会把大段语句切成每句话形势
4.第三步是语音识别文字,方便后续的矫正核对
操作:下一步开启离线批量ASR,注意这里输一次就会覆盖掉之前的文件,注意保存之前的文件

5.第四步开始听录核准语音文字,打标就是让ai学习字该怎么读
操作:选择开始打标弹出新的9871的窗口,一边听音频一边矫正文字 ,修改时要提交结果,再选择下一页全部听完,可以删除掉不是自己想要的声音,只留下优质的片段。删除要先点yes再删除

6.最后提交,关闭9871界面,返回9874关闭webUi
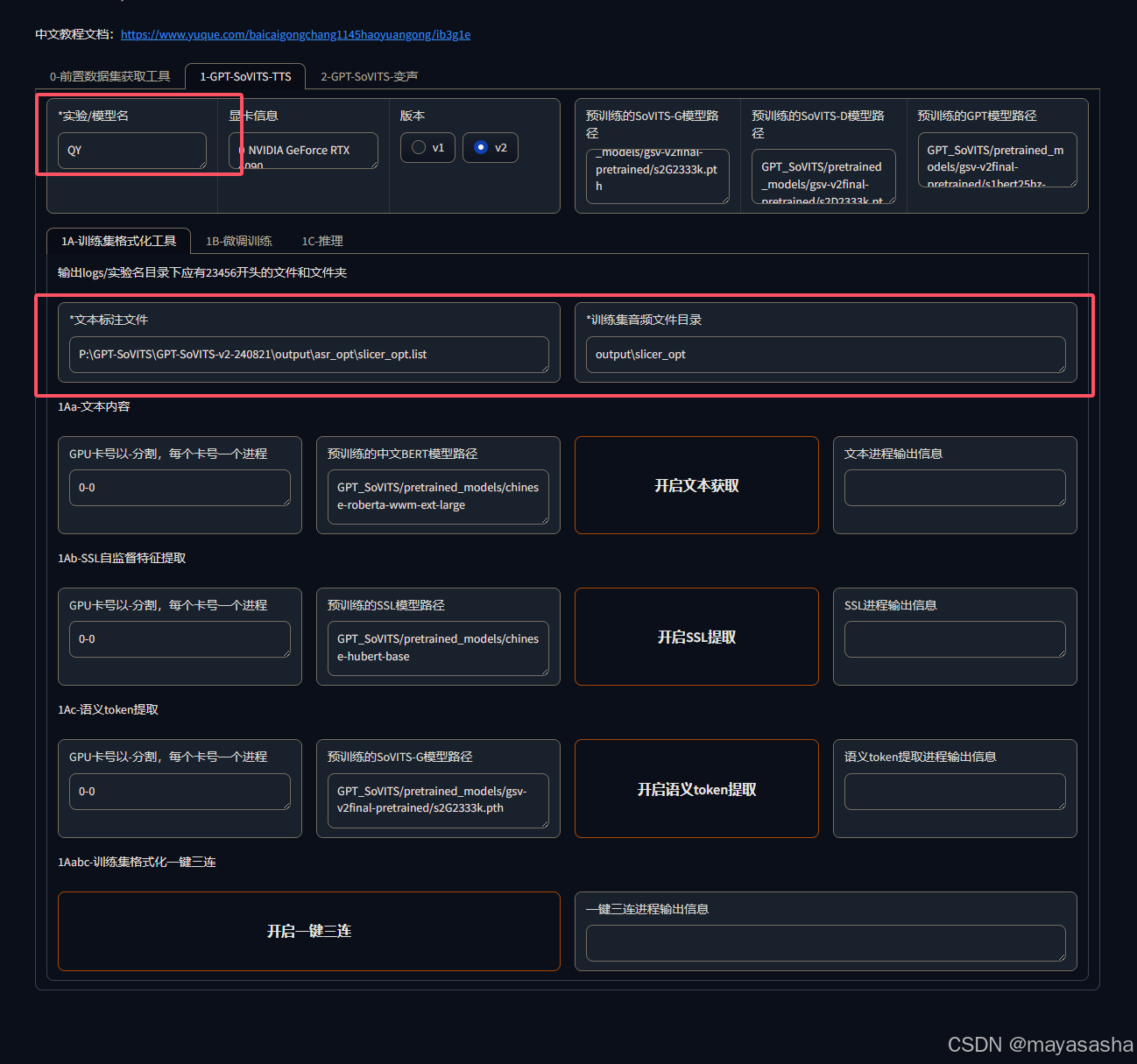
7.来到选项卡第二项——1-GPT-SOVITS-TTS界面,开始训练AI
填写你的模型名,检查路径地址,开启一键三连,等待训练结果
默认的情况,路径不用改,等到右下角显示进程结束
8.这一步是训练的核心,菜单标签-选择1B-微调训练
先选择sovits训练,等待训练完,再选择gpt,不要一起点。
设置batch_size,sovits训练建议batch_size设置为显存的一半以下,高了会爆显存
成功的话能在软件目录SoVITS_weights_v2,GPT_weights_v2看到模型文件
更加详细的教程见花儿大佬的:整合包教程
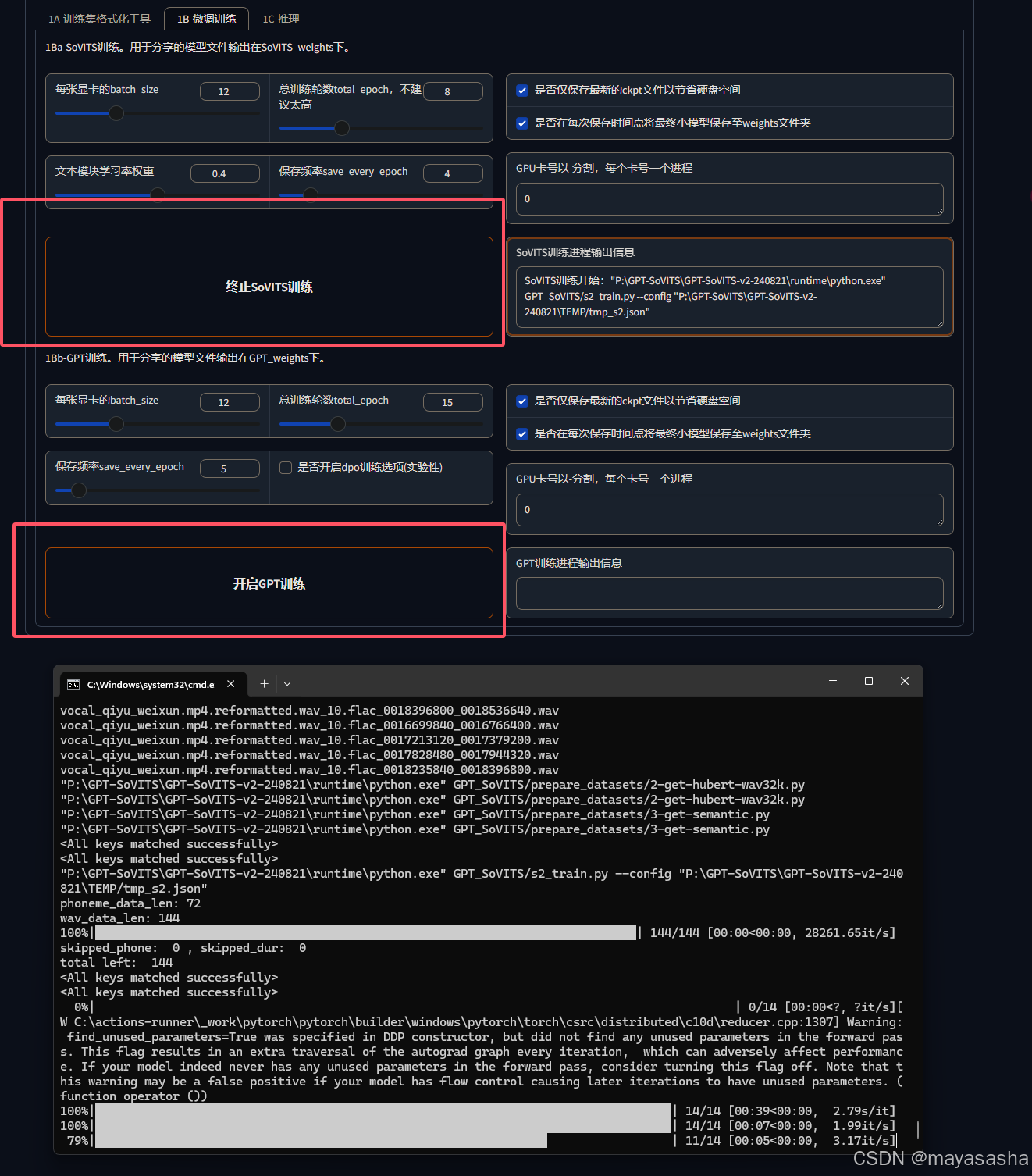

9.到了使用的这一步,需要切换标签至1C-推理选项卡
刷新模型可以看到上一步自己训练出的模型列表,作者提到e代表训练的轮数,s代表步数。但是这也并不意味着越高效果越好,还是要用耳朵检测。
开启TTS推理,打开新的窗口9872端口页面
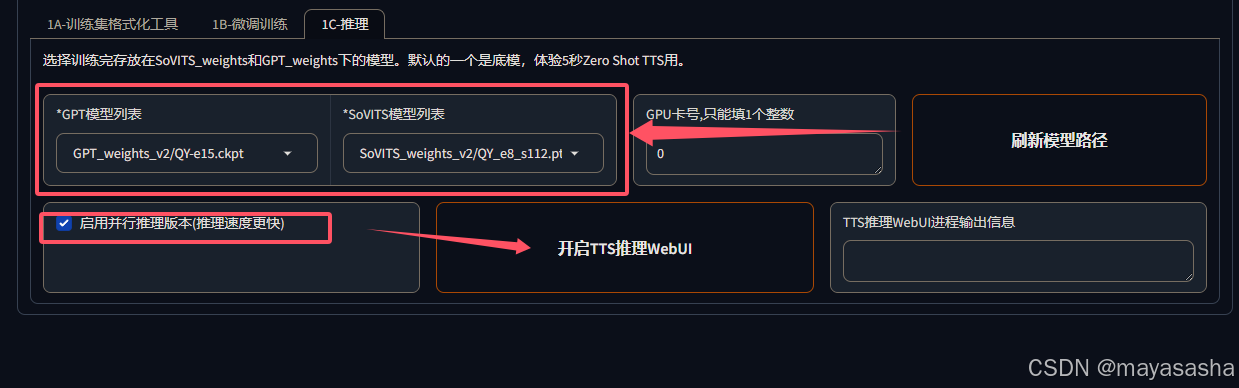
10.导入音频这一块涉及语气调整,这一步很重要!
基本上你导入的片段是什么语气,它生成音频就是什么语气,导入的声音可以从刚才切割的片段中拖入,拖入的音频不能超过10s。
合成之后可以听效果。训练缓存的数据在TEMP\gradio
最后视频教程作者提到,如果你不注重质量,可以直接跳转到最后一步,模型选第一个,直接进行声音克隆。
但我不太明白这两种方式质量差有多少?
总结:GPT-SoVITS说一个声音模仿的软件,如果想自己训练也行,不想训练可以直接导入别人分享的训练好的声音模型,进行文字转语音的合成。下一步的学习,是研究怎么训练出精度更高的声音模型,然后再研究情绪微调处理。
笔记的视频教程:你的声音,现在是我的了!- 手把手教你用 GPT-SoVITS 克隆声音!_哔哩哔哩_bilibili
下载地址:整合包及模型下载链接
第二部分:GPT-SoVITS与本地Ollama结合(python版)
这个方法是刘锐大佬视频里演示API接口调用给我的启发,他在花儿大佬修改加入了可以一键开启GPT-SoVITSapi接口的启动器,我这里用ollama接GPT-SoVITS的时候用的是他的接口,花儿大佬原版的整合包理论上也是能的,但是我第一次用原版遇到了报错,图省事我用了刘悦大佬的包调用的接口。
接口包下载地址,来自刘悦的技术博客:夸克网盘分享GPT-SoVITS-V2,参考音频使用,接口api调用,接入大模型,接入开源阅读3.0,TTS,声音克隆,文字转语音,花佬开源_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1nM4m1y7Sx/?spm_id_from=333.1387.search.video_card.click&vd_source=e0e4e4122d077cc783600ddc34cdbd00
https://www.bilibili.com/video/BV1nM4m1y7Sx/?spm_id_from=333.1387.search.video_card.click&vd_source=e0e4e4122d077cc783600ddc34cdbd00
因为我最终的目的是让GPT-SoVITS接入本地部署的ollama里AI问答中,实现文本转语音,我最开始的思路让ollama在python可以输出大模型回复→之后GPT-SoVITS在python输入能够进行语音朗读的转换→获取deepseek的输出回复给到GPT-SoVITS输入转换输出语音→安装python依赖播放声音的库让python获取生成的语音自动播放→同时加入正则过滤,优化语音,免得deepseek思考过程重复朗读。
操作为运行ollama,运行GPT-SoVITS-v2的接口.bat,确保两个服务正常运行,python正常建立项目即可,没有特殊的版本要求,如果报错一般是前两者服务没启动,检查接口cmd内是否有报错内容,如果环境报错,检查是不是提示有缺少的依赖库没装。
python --version检查当前运行的 Python 环境路径用到的:
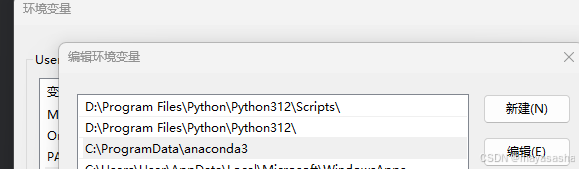
python -c "import sys; print(sys.executable)"如果窗口显示了pip 安装成功,运行时仍然提示找不到模块,说明现在Python运行环境和pip时安装环境不一致,检查系统环境变量,最上面的优先级最高,我pychram使用的是我本地python的解释器,python3.12路径就和我的anaconda3环境冲突了,之前修改过anaconda3的编译器放在前面。
下一步我基础代码上,加入了循环语句让大模型这次生成之后开始下一次对话。之后又遇到了新的问题,由于输入音频我用的是固定名output.wav,导致下次音频生成后,上一次的文件还没释放,文件显示被占用无法覆盖生成语音。而我又不想给修改音频命名规则,输出很多的缓存文件,它最好是一次对话结束删除一次,以此循环。这里我询问了AI,尝试了好多方法,命名的文件释放的问题始终未解决、不同文件名时间戳的临时文件不好管理、或者第三方库安装带了新的环境错误。多次尝试都还不行后,GPT推荐我换一个声音的库,这种方式可以实现跨平台,但是需要先pip install pygame,安装pygame的库。
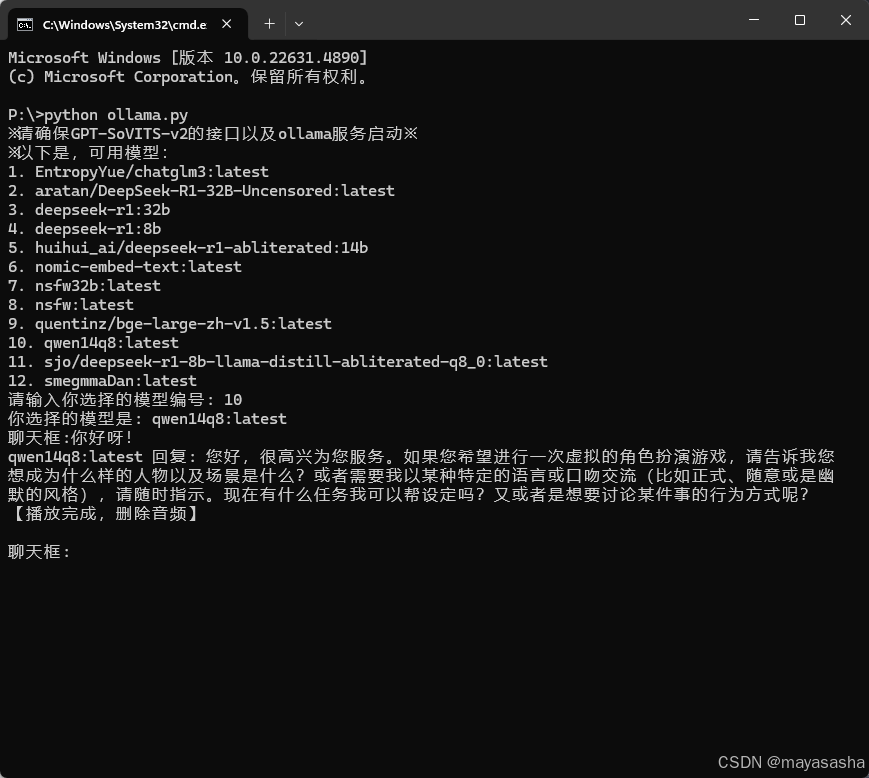
之后,我打算做成交互式,让脚本一开始运行时先选择和哪个模型对话,这里我调用了ollama默认的查询接口,如果你的端口不是ollama默认的是需要修改的。localhost:11434/v1/models的接口查询我用ollama部署的所有模型,通过找ID列表排序供。
最后,对原始代码做了一个优化,我用Windows 自带的模块替换了pygame,这么做的好处是无需安装其他库的方法,缺点是无法在其他平台运行,最终代码修改如下:
import os
import requests
import re
import multiprocessing
import winsound # 导入 winsound 模块
# Ollama API 地址
Ollama_api_url = "http://localhost:11434/api/generate"
# Gptsovits API地址
Gptsovits_api_url = "http://127.0.0.1:9880/tts_to_audio/"
# 获取所有ollama模型
def get_models():
url = "http://localhost:11434/v1/models"
try:
response = requests.get(url)
if response.status_code == 200:
data = response.json()
models = data.get("data", [])
model_ids = [model.get("id") for model in models if model.get("id")]
model_ids.sort() # 排序模型 ID
return model_ids
else:
print(f"请求失败,状态码: {response.status_code}")
return []
except Exception as e:
print(f"请求出现错误: {e}")
return []
# 播放音频文件
def play_audio(file):
try:
winsound.PlaySound(file, winsound.SND_FILENAME) # 使用 winsound 同步播放
except Exception as e:
print("播放进程播放失败:", str(e))
# 选择模型并开始聊天的函数
def chat_with_ai():
models = get_models()
if not models:
print("没有找到可用的模型。")
return
# 打印模型列表并让用户选择
print("※请确保GPT-SoVITS-v2的接口以及ollama服务启动※\n※以下是,可用模型:")
for i, model in enumerate(models, 1):
print(f"{i}. {model}")
try:
choice = int(input("请输入你选择的模型编号: "))
if 1 <= choice <= len(models):
selected_model = models[choice - 1]
else:
print("无效的选择。")
return
except ValueError:
print("无效的输入。")
return
print(f"你选择的模型是: {selected_model}")
while True:
# 请求参数
payload = {
"model": selected_model, # 使用用户选择的模型
"prompt": input("聊天框:"), # 用户输入的聊天内容
"stream": False # 设置为 False 以获取完整的响应
}
# 发送 POST 请求
response = requests.post(Ollama_api_url, json=payload)
# 检查响应状态
if response.status_code == 200:
response_data = response.json()
generated_text = response_data.get("response", "")
# 使用正则表达式过滤<think>标签内容
generated_text = re.sub(r'<think>.*?</think>', '', generated_text, flags=re.DOTALL)
print(f"{selected_model} 回复: {generated_text.strip()}")
# 请求参数
payload = {
"text": generated_text, # 使用大模型生成的内容
"text_lang": "zh",
}
# 发送POST请求
response = requests.post(Gptsovits_api_url, json=payload)
# 处理响应
if response.status_code == 200:
# 保存音频文件
audio_file = "output.wav"
# 检查文件是否存在,如果存在则删除
if os.path.exists(audio_file):
os.remove(audio_file) # 删除已存在的文件
with open(audio_file, "wb") as f:
f.write(response.content)
# 自动播放音频 (使用 multiprocessing 和 winsound)
try:
p = multiprocessing.Process(target=play_audio, args=(audio_file,))
p.start()
p.join() # 等待进程结束 (winsound 会阻塞直到播放完成)
# 删除音频文件 (现在可以确保播放已经完成)
os.remove(audio_file)
print("【播放完成,删除音频】")
print()
except Exception as e:
print("创建播放进程失败:", str(e))
else:
print("失败:", response.text)
else:
print("请求失败,状态码:", response.status_code)
print("错误信息:", response.text)
if __name__ == "__main__":
chat_with_ai()
这个脚本还有个缺点是使用的时候无法更换声线,必须开着ollama服务和Gptsovits接口窗口才能正常工作,想替换声线,必须去config.py里修改,再重启接口api。AI的声音就是你选的参考音频。
SoVITS_weights和GPT_weights声音模型在GPT-SoVITS-v2\GPT_SoVITS\configs\tts_infer.yaml修改,刘锐接口包声音参考修改在config的脚本里。
新建txt保存成py在cmd窗口运行,它第一次打完问题发出后才会把大模型载入显存里,如果是用deepseek32B这种大模型,第一次的生成速度会很慢,连带着语音生成也会比较慢,慢到怀疑它到底有没有在运行,所以我还是保留了最后结束的【播放完成,删除音频】,出现这句话就表示本次对话结束了,不然就还在生成中。建议手动ollama run先把大模型跑起来。
第三部分:GPT-SoVITS与OpenWebUI结合(docker版)
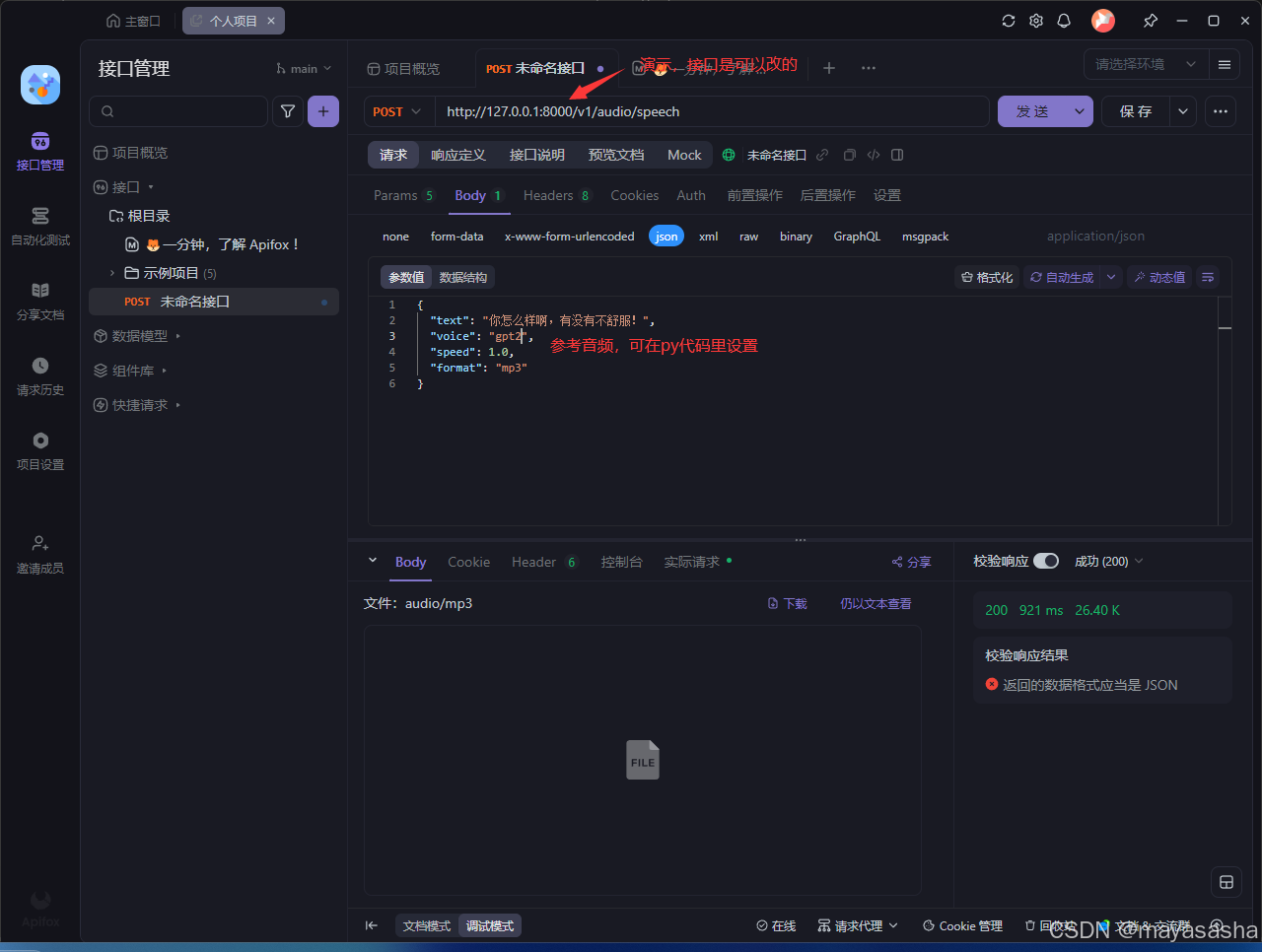
我自己openWebui是通过docker安装的,使用时看到openwebui里内置了openApi文字转语音接口,于是我在二的基础上联想到可不可以把gptsovits本地的api做成一个适配openai接口接入openwebui,但问题是,我对如何编写fastapi兼容openapi一窍不通,这段代码我交给4o和deepseek与Gemini编写。经过两天一夜的努力十几轮的调试bug后,第一个可被post的兼容opanApi的本地gptsovitsTTS请求成功了。
INFO: Received valid request: {
"text": "测试",
"voice": "keli",
"speed": 1.0,
"format": "mp3"
}
gptsovits主要接收两个数据一个是text由大模型生成文字,另一个voice,填写你自己的参考音频名字,其他可随意填写。
import os
import sys
from pathlib import Path
from functools import lru_cache
import uvicorn
import soundfile as sf
from io import BytesIO
import numpy as np
from fastapi import FastAPI, HTTPException
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
BASE_DIR = Path(__file__).parent
sys.path.extend([str(BASE_DIR), str(BASE_DIR / "GPT_SoVITS")])
class ServiceConfig:
REF_AUDIO_DIR = BASE_DIR / "reference_audio" # 参考音频文件夹
CONFIG_PATH = BASE_DIR / "GPT_SoVITS" / "configs" / "tts_infer.yaml"
HOST = "0.0.0.0"
PORT = 9880
from GPT_SoVITS.TTS_infer_pack.TTS import TTS, TTS_Config
@lru_cache(maxsize=1)
def load_tts_pipeline():
tts_config = TTS_Config(str(ServiceConfig.CONFIG_PATH))
return TTS(tts_config)
tts_pipeline = load_tts_pipeline()
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
class TTSParams(BaseModel):
text: str = Field(..., alias="input")
voice: str = Field(..., description="直接使用音频文件名,例如:GPT1.wav")
speed: float = 1.0
format: str = "mp3"
class VoiceManager:
_valid_voices = set()
@classmethod
def initialize(cls):
ref_dir = ServiceConfig.REF_AUDIO_DIR
if not ref_dir.exists():
raise RuntimeError(f"参考音频目录 {ref_dir} 不存在")
cls._valid_voices = {
f.name for f in ref_dir.iterdir()
if f.is_file() and f.suffix.lower() in (".wav", ".mp3", ".ogg")
}
@classmethod
def get_voice_path(cls, voice_file: str) -> Path:
if voice_file not in cls._valid_voices:
raise HTTPException(
status_code=404,
detail=f"音频文件 {voice_file} 不存在,可用文件:{sorted(cls._valid_voices)}"
)
return ServiceConfig.REF_AUDIO_DIR / voice_file
class AudioStreamer:
def __init__(self, tts_generator, media_type: str):
self.tts_generator = tts_generator
self.media_type = media_type
async def stream_audio(self):
sr, audio = next(self.tts_generator)
yield self._encode_audio(audio, sr)
for sr, audio in self.tts_generator:
yield self._encode_audio(audio, sr)
def _encode_audio(self, audio: np.ndarray, sr: int):
buffer = BytesIO()
sf.write(buffer, audio, sr, format=self.media_type)
return buffer.getvalue()
@app.post("/v1/audio/speech")
async def tts_endpoint(params: TTSParams):
try:
ref_path = VoiceManager.get_voice_path(params.voice)
except HTTPException as he:
raise he
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
tts_params = {
"text": params.text,
"text_lang": "auto",
"ref_audio_path": str(ref_path),
"speed_factor": params.speed,
"streaming_mode": True
}
streamer = AudioStreamer(
tts_generator=tts_pipeline.run(tts_params),
media_type=params.format
)
return StreamingResponse(
content=streamer.stream_audio(),
media_type=f"audio/{params.format}",
headers={"Content-Disposition": f'attachment; filename="speech.{params.format}"'}
)
@app.get("/health")
async def health():
return {"status": "OK", "available_voices": sorted(VoiceManager._valid_voices)}
if __name__ == "__main__":
# 初始化语音管理器并扫描音频文件
try:
VoiceManager.initialize()
except RuntimeError as e:
print(f"初始化失败: {str(e)}")
sys.exit(1)
# 显示可用音频文件
print("\n可用的参考音频文件:")
for voice in sorted(VoiceManager._valid_voices):
print(f" - {voice}")
print(f"\n服务启动在 http://{ServiceConfig.HOST}:{ServiceConfig.PORT}\n")
uvicorn.run(app, host=ServiceConfig.HOST, port=ServiceConfig.PORT)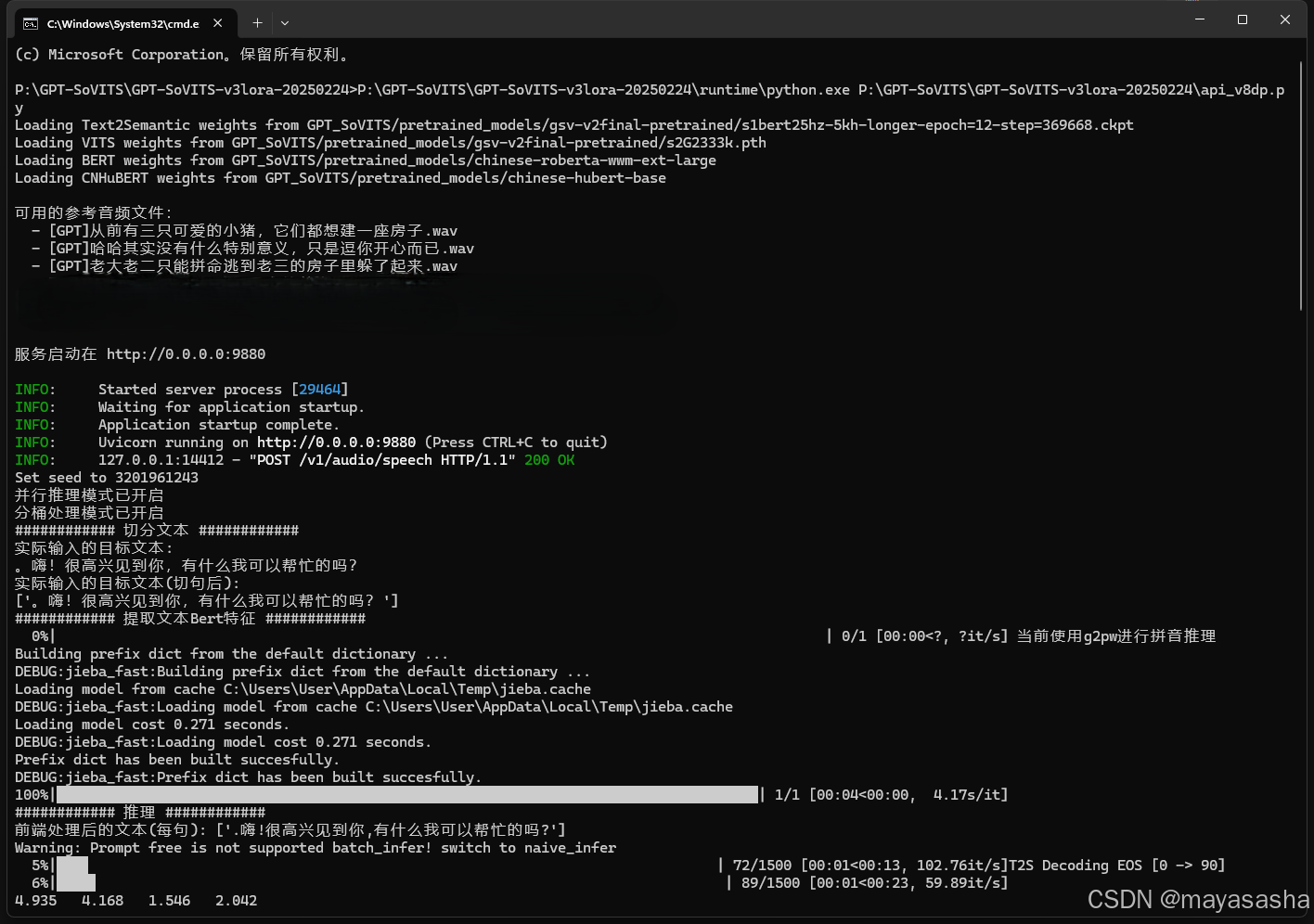
这版代码都是我修整完成的可以用的。原先测试成功的只是可以被post,之后就要考虑openWebUI如何接收和发送请求的问题,docker里的openwebui似乎无法直接我主机地址的接口,openWebui在log里疯狂报错,gptsovits没有任何反应,我不知道问题在哪,问AI就一直让我对 OpenWebUI 的配置修改,给我干懵了,光在docker里找配置,我没整明白位置放在哪,修改配置这个方法我最后也没成功,config的js文件我也没找到。不过,我找了其他的方法让容器访问本地。
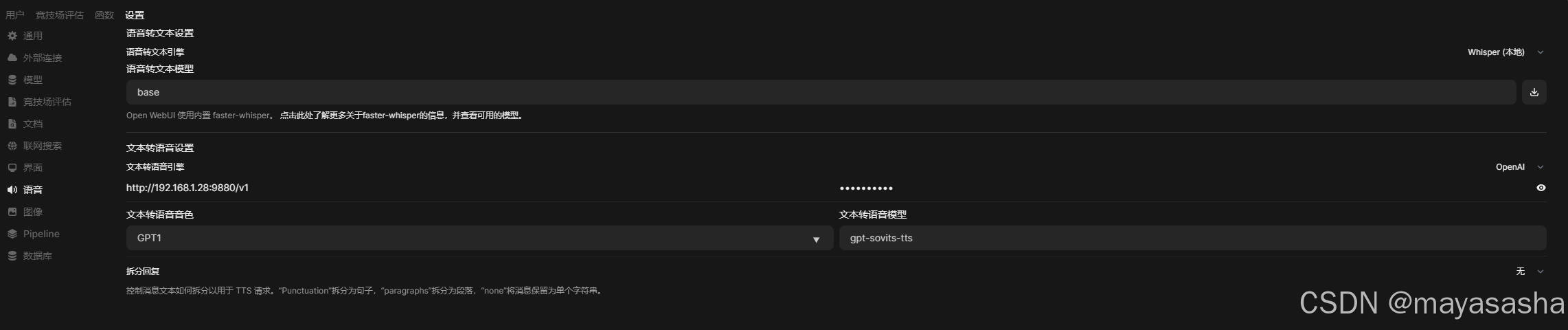
http://host.docker.internal:9880/v1在openWebUI中调用本地tts以下两个是必填项,下图为参考(默认运行是9880,主义下图8000是我后来测试用的端口)
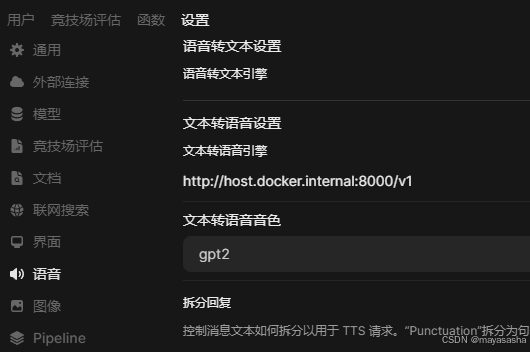
除了把api改成http://host.docker.internal:的前缀,g另外的方法是修改脚本文件本地的host为0.0.0.0,让docker可访问主机,又经过十几轮的调试。至此几十轮的调试终于结束。操作到这我已经精疲力尽了,光代码我就测试了一天一夜。
http://localhost:8000/docs#/
# 端口是我自定义的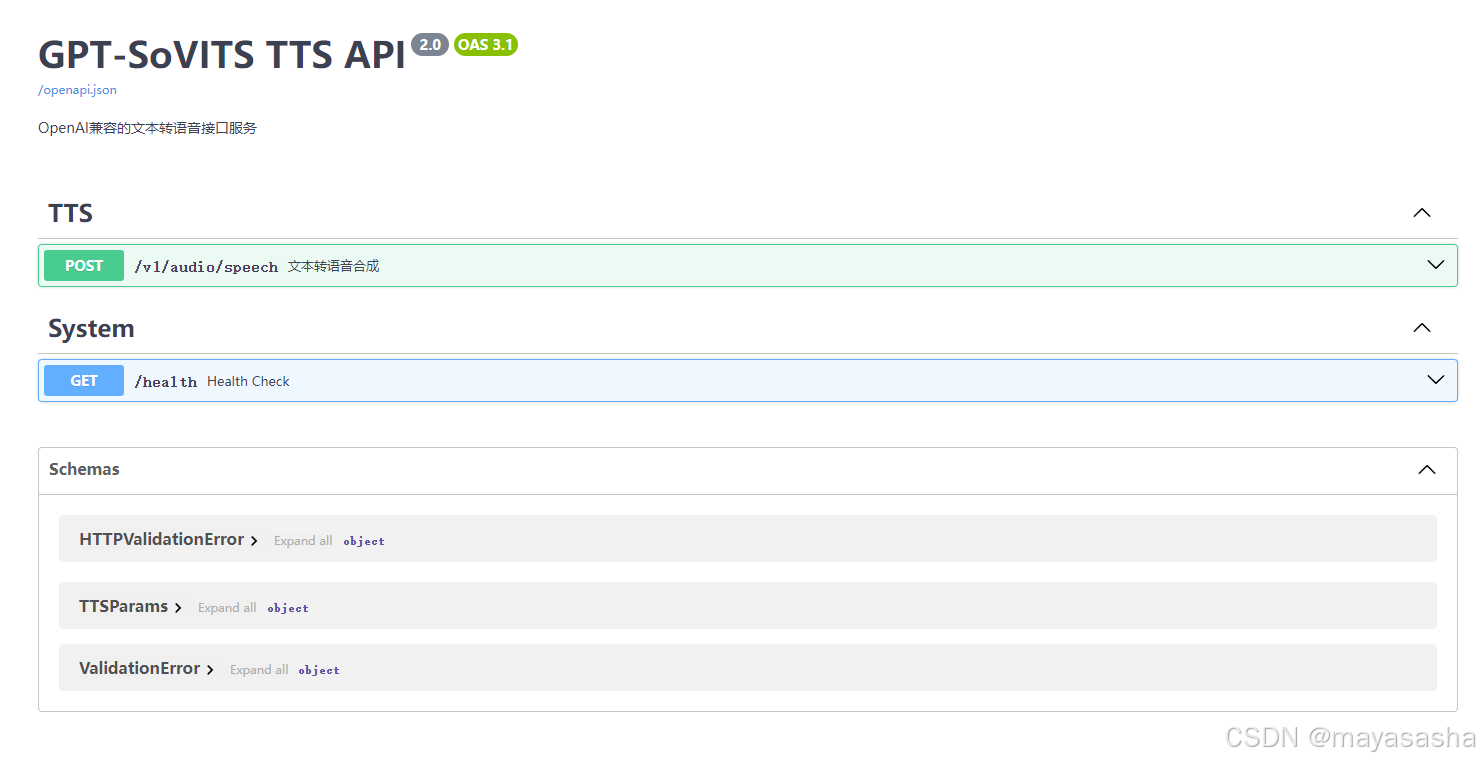
具体过程代码我就不展示了。使用方式:需要自行修改的就是参考音频的路径问题。我这里给出的所有代码都在我电脑测试成功了,不包所有人都能成功。管理员页面文本转语音引擎里填写本地接口,api密码随便写,声音和模型需要下面的py脚本里改。代码在花儿apiv2的基础上全部由AI转写成类兼容openai接口,我分享源代码见下方,供各位大佬拿参考。
import os
import sys
from pathlib import Path
from typing import Union # 添加Union支持
import uvicorn
import soundfile as sf
from io import BytesIO
import numpy as np
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
BASE_DIR = Path(__file__).parent
sys.path.extend([str(BASE_DIR), str(BASE_DIR / "GPT_SoVITS")])
class ServiceConfig:
CONFIG_PATH = BASE_DIR / "GPT_SoVITS" / "configs" / "tts_infer.yaml"
HOST = "0.0.0.0"
PORT = 9880
BASE_MODEL_DIR = BASE_DIR
SOVITS_WEIGHTS_DIR = BASE_MODEL_DIR / "SoVITS_weights_v2"
GPT_WEIGHTS_DIR = BASE_MODEL_DIR / "GPT_weights_v2"
REF_AUDIO_DIR_NAMES = ["reference_audio"]
@classmethod
def get_ref_audio_dir(cls) -> Path:
for name in cls.REF_AUDIO_DIR_NAMES:
ref_audio_dir = BASE_DIR / name
if ref_audio_dir.is_dir():
return ref_audio_dir
default_ref_audio_dir = BASE_DIR / cls.REF_AUDIO_DIR_NAMES[0]
default_ref_audio_dir.mkdir(exist_ok=True)
return default_ref_audio_dir
ServiceConfig.REF_AUDIO_DIR = ServiceConfig.get_ref_audio_dir()
from GPT_SoVITS.TTS_infer_pack.TTS import TTS, TTS_Config
def select_model_from_folders():
def select_model(model_type, model_dir, ext):
models = list(model_dir.glob(f"*.{ext}"))
if not models:
print(f"⚠️ {model_type} 模型文件夹 ({model_dir}) 为空或未找到 .{ext} 文件")
return None
print(f"\n----------------- {model_type} 模型选择 -----------------")
for i, path in enumerate(models):
print(f"{i + 1}. {path.name}")
while True:
try:
choice = input(f"> 请选择 {model_type} 模型 (输入数字序号,留空使用默认): ").strip()
if not choice:
print(f"使用默认配置文件中的 {model_type} 模型\n")
return None
idx = int(choice) - 1
if 0 <= idx < len(models):
print(f"✅ 已选择 {model_type} 模型: {models[idx].name}\n")
return str(models[idx])
print("❌ 输入序号无效")
except ValueError:
print("❌ 请输入有效数字")
gpt_path = select_model("GPT", ServiceConfig.GPT_WEIGHTS_DIR, "ckpt")
sovits_path = select_model("SoVITS", ServiceConfig.SOVITS_WEIGHTS_DIR, "pth")
return gpt_path, sovits_path
def get_user_input(prompt, default=""):
value = input(prompt).strip()
return value if value else default
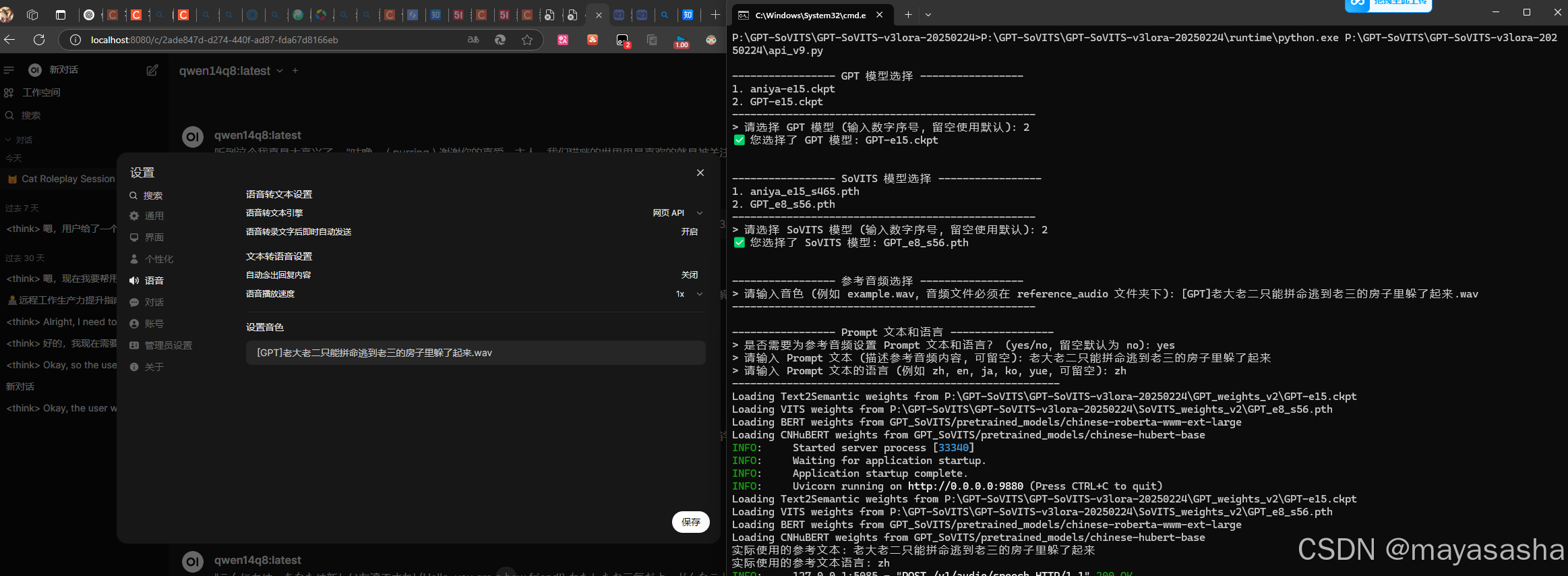
selected_gpt_path, selected_vits_path = select_model_from_folders()
reference_voice = get_user_input("> 请输入参考音频文件名(位于 reference_audio 目录下): ")
use_prompt = get_user_input("> 是否设置 Prompt 文本和语言?(y/n): ").lower() == 'y'
prompt_text = get_user_input("> Prompt 文本(可留空): ") if use_prompt else None
prompt_lang = get_user_input("> Prompt 语言(zh/en/ja/ko/yue): ") if use_prompt else None
def load_tts_pipeline(config_path, gpt_path=None, vits_path=None):
tts_config = TTS_Config(str(config_path))
if gpt_path: tts_config.t2s_weights_path = gpt_path
if vits_path: tts_config.vits_weights_path = vits_path
return TTS(tts_config)
tts_pipeline = load_tts_pipeline(ServiceConfig.CONFIG_PATH, selected_gpt_path, selected_vits_path)
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
class TTSParams(BaseModel):
text: str = Field(..., alias="input")
voice: str
speed: float = 1.0
format: str = "mp3"
gpt_weights_path: Union[str, None] = None # 使用Union
vits_weights_path: Union[str, None] = None # 使用Union
prompt_text: Union[str, None] = None # 使用Union
prompt_lang: Union[str, None] = None # 使用Union
class VoiceManager:
@staticmethod
def get_voice_path(voice_id: str) -> Path:
base_path = ServiceConfig.REF_AUDIO_DIR / voice_id
if base_path.exists():
return base_path
wav_path = base_path.with_suffix('.wav')
if wav_path.exists():
return wav_path
raise ValueError(f"音频文件 {voice_id}(.wav) 不存在于 {ServiceConfig.REF_AUDIO_DIR}")
@app.post("/v1/audio/speech")
async def tts_endpoint(params: TTSParams):
try:
ref_path = VoiceManager.get_voice_path(params.voice)
except ValueError as e:
return {"status": "error", "message": str(e)}, 400
current_tts = load_tts_pipeline(
ServiceConfig.CONFIG_PATH,
params.gpt_weights_path or selected_gpt_path,
params.vits_weights_path or selected_vits_path
)
tts_params = {
"text": params.text,
"text_lang": "auto",
"ref_audio_path": str(ref_path),
"speed_factor": params.speed,
"streaming_mode": True,
"prompt_text": params.prompt_text or prompt_text,
"prompt_lang": params.prompt_lang or prompt_lang
}
if tts_params["prompt_text"]:
print(f"使用参考文本: {tts_params['prompt_text']}")
print(f"参考文本语言: {tts_params['prompt_lang'] or '未知'}")
else:
print("进入朴素推理模式")
def audio_generator():
buffer = BytesIO()
for sr, audio in current_tts.run(tts_params):
buffer.seek(0)
buffer.truncate()
sf.write(buffer, audio, sr, format=params.format)
yield buffer.getvalue()
return StreamingResponse(
audio_generator(),
media_type=f"audio/{params.format}",
headers={"Content-Disposition": f'attachment; filename="speech.{params.format}"'}
)
@app.get("/health")
async def health_check():
return {"status": "OK"}
if __name__ == "__main__":
uvicorn.run(app, host=ServiceConfig.HOST, port=ServiceConfig.PORT)以上如果对你有帮助,能帮我点点火山 api 激活码就再好不过啦~(¯▽¯~)
DeepSeek满血版免费领啦!邀请好友注册和使用,最高双方可获得145元代金券,免费抵扣3625万tokens,畅享R1与V3模型!参与入口:https://www.volcengine.com/experience/ark?utm_term=202502dsinvite&ac=DSASUQY5&rc=D61I3AL4 邀请码:D61I3AL4
总结:
最后借这次测试,聊几句ai做生产力的看法。我觉得AI已经来到了量变的时间节点。原先我觉得AI未来可期,是因为它在通用领域既取代不了高等人才,又没中间层职员好用,还没基层牛马劳动力便宜,所以绝大部分的行业无法真正地把AI当生产力来用。但是现在deepseek接入这个接入天天上新闻,ai在开始铺量之后,尤其是大厂竞争的内卷,openAi官宣gpt5免费开放使用,ai不久将来会取代某些人行业某些底层的人,ai会成为中层内卷的威胁或者是所谓'提升效率的助手"
可问题也就来了,ai取代于没有经验技术的人,达到了及格的水平的,那些新人怎么办?大部分的技术岗位都是从新人一步一个脚印走的,很少人一下子就马上直接跨过初级到 了中级,但是ai在针对某些方面加强训练后就可能是会把新手淘汰掉了,未来不好说,但至少ai现在应用层还是很不完善,我使用ai做生产力感觉是我稍微掌握一些能力我就能用ai做事了,但是一旦涉及到我认知之外的事情了,我们就无法掌控的ai,被ai带着走了。而且当ai真的涉及到你专业的领域之后,你会发现ai是会胡编乱造输出一些信息垃圾的,比如我之前问他一个软件的问题,我其实知道是怎么操作的我只是忘记那个按钮在哪里了,我用10秒就能解决的事情,ai写了1000个字没能解决我的问题,还制造了一下一堆信息垃圾浪费我时间,但是这也不是不能解决了,像我说的针对训练,,每个软件厂家都内置一个ai,或者是联网搜索,我相信等ai铺量和专业化后,那时候真正的变革就真正滴开始了。
现在,假设问ai如何造一辆车,这个车是你知识储备里的,你要造的车是存在的车,并且你知道组装车流程步骤,你拿着准备好的工具问ai如何造一辆车,ai推理你手里的工具,很快地就能指导你造出一辆车。
假设你今天不是造车,想造一个火箭。而你只是普通的司机不是火箭工,你知道火箭在地球上能被造出来,但你不知道它是具体怎么造,用什么造,而ai恰好数据库有造火箭的方法,ai是知道怎么造一个火箭,但是造火箭需要涉及的原理操作太多了,ai会把它知道造火箭的方法用认为你应该知道的方式告诉你,然后你发现ai提供给你方法你并不能用,按照他的方法做一步卡一步,那为什么会出错呢?就像是人问不出认知以外的东西,ai同样也是,ai不知道你不知道的问题,它会默认你是一个火箭工程师或是什么具备造火箭知识的人,它提供的方法会省略“它认为你应该做到的东西”而跳过相当一部份的步骤,但是你并知道ai在这中间跳过了什么,所以你在解决一个错误时问不出真正要问ai的问题,ai也不知道你缺少那一步引起了哪些错误。就好比我只是把文件名打错了,拼错了字,而ai正在反复的修改代码这种无用功。
最后,你对ai说你想造一辆方舟,类似于2012里世界毁灭中国制造的方舟,这个在科幻片里的东西,在现实里没有,你问ai的问的越具体,ai会根据现实的法则推导出这个任务是当下人类可以做的,于是它按照臆想中类似造物的给你一套操作步骤,直到后面你突然会发现这个玩意根本做不出来。
第二部分,我就是在造车的过程,因为我知道这个功能是如何实现的,ai最后在做的其实是帮我验证它。我用了一个下午就搞定最终的代码了,而第三部份我用了三天,本地tts到openwebUi这一部份,我遇到了很多奇形怪状的问题,做出openAi兼容的api的代码思路完全是ai写的,我并不知道这种中间具体是怎么实现的,我和ai身份互换了变成我在帮它验算。我前面也尝试过用deepseek写这部分代码,结果错误越写越多,不知道是我提问的方式不对或是触发了模型幻觉。翻来覆去地改也我几度想放弃,甚至觉得我纯属没事找事。不过好在结果是好的。 我感觉就是越聪明的人用ai会越厉害,越厉害的人用ai会让ai反哺自身变得更强,如果以后更厉害的大模型出现,开启全民ai付费选择的时代,ai究竟是打破信息差,还是进一步拉大人与人之间的落差存在?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)