全面解析DeepSeek算法细节(1) —— 混合专家(Mixture of Expert, MoE)
DeepSeek系列模型算法细节剖析之混合专家(MoE)
混合专家(MoE)
最近打算认真研究下DeepSeek涉及的一些技术,所以开了这个专题,先从今天的MoE开始吧,下一个应该会讲MLA或者MTP。
在正式开始之前,再花一点时间复习下关于MoE的基础知识
什么是MoE
Mixture of Experts是混合专家模型,一般是在transformer block中替换掉MLP(FFNN) layer的结构,一个MoEl ayer主要由以下两部分组成:
- 专家(experts):每个MoE layer中都有许多专家,常见的数量是16,64等,在实际推理时只有其中的几个专家会用到。
- 路由(router):也叫门控网络(gate network),决定将token派给哪个专家处理。
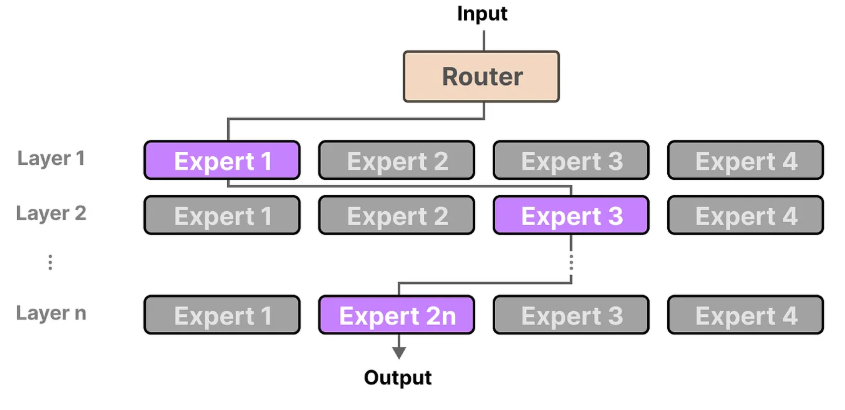
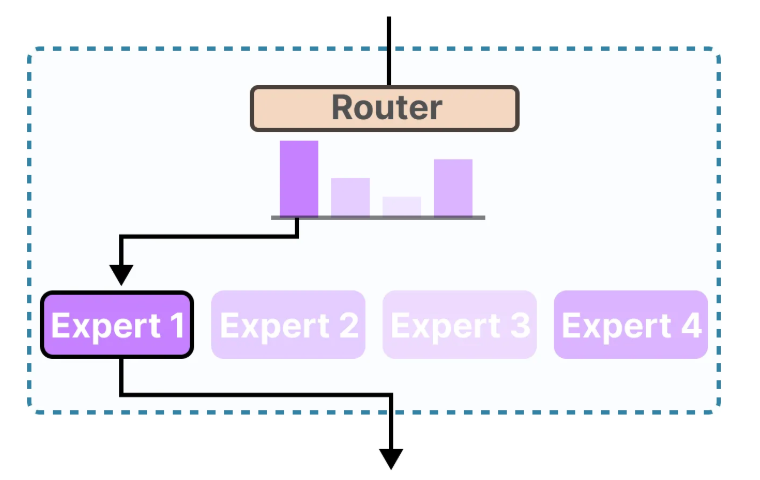
上图是带有MoE的网络大致工作流程,输入到达每一层的时候都会经过一个门控网络将其指派给最合适的专家来处理,最终得到网络的输出。
需要注意的是"专家"这个词可能会给人带来误导,这里并不是指每个专家都有自己擅长的领域,不存在所谓的更擅长心理学的专家或者更擅长计算机科学的专家,对于每个专家来说,他们在训练的时候学习到的是某些语句词法特点,比如某个专家比较擅长处理标点符号,有的专家比较擅长处理动词,ST-MoE的论文中也证实了这点,如下图所示: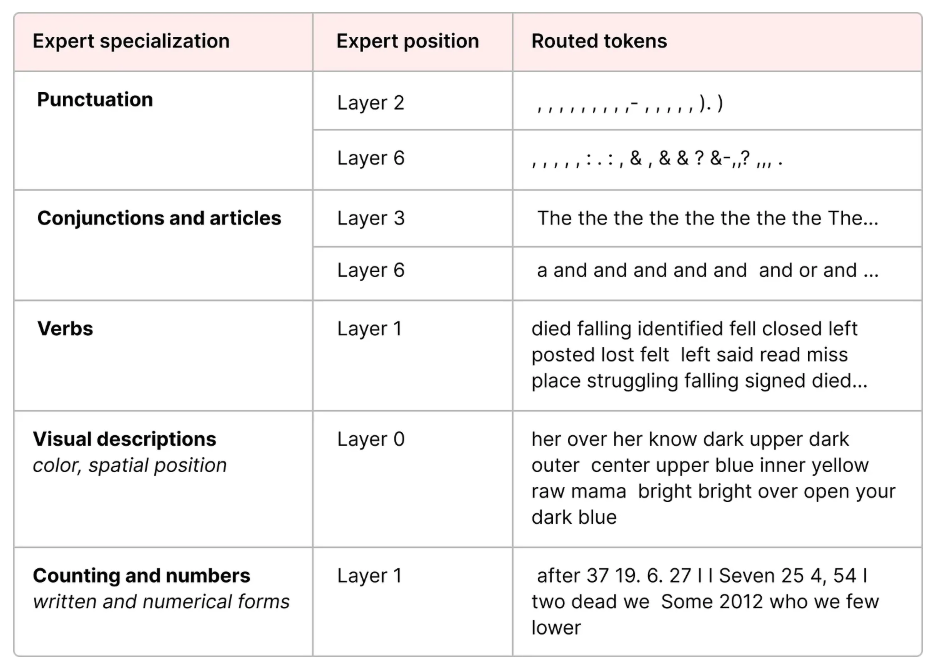
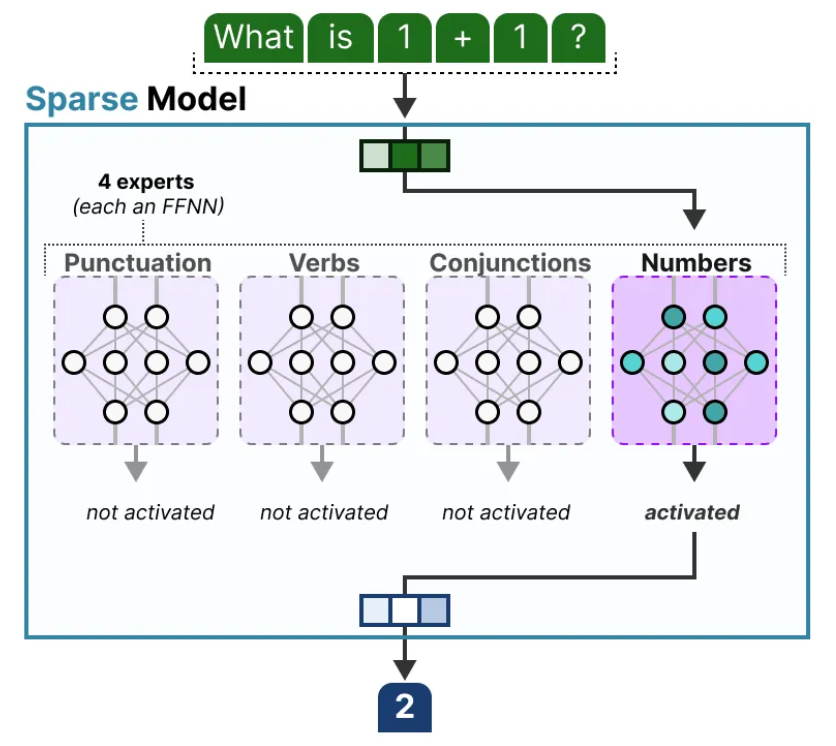
因为第4个专家更擅长处理数字,所以在推理时只使用第4个专家就好了,这里显然采取的是每次只激活1个专家作为例子。
那么如何选择最合适的专家呢?请看下节~
The Routing Mechanism
MLP layer一般是由两个linear构成的,MoE也不例外,router和每个专家本质上也都是FFNN,路由的结果经过softmax操作后会输出一个一维向量,值就代表当前每个专家对该token的置信度,值越高就代表该专家越擅长处理该token,如果采取选择一位专家的策略,那么最后就应该由第一个专家来负责,它的结果再与刚才对应的置信度相乘即可得到这层的输出。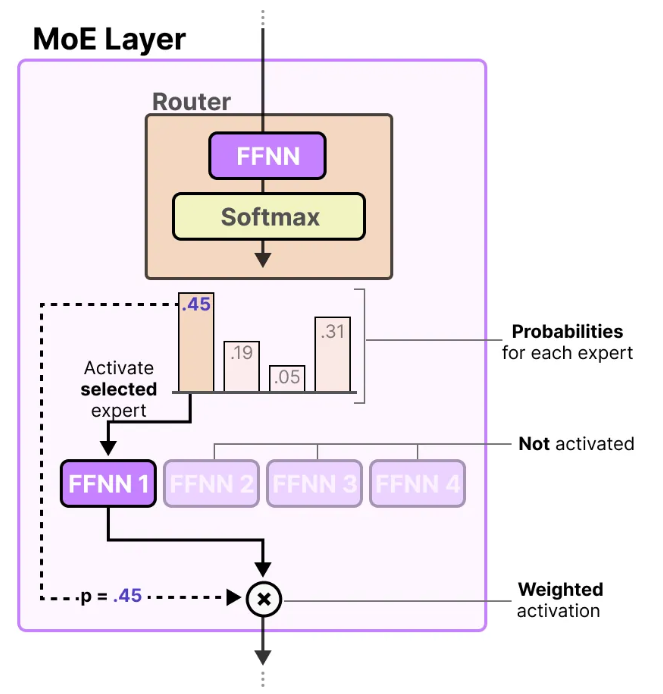
具体来说,对于输入 x x x来说,通过与router的权重矩阵相乘获得输出 H ( x ) H(x) H(x):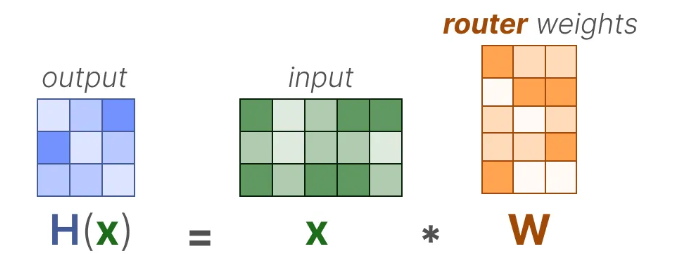
接着通过softmax操作获得每个专家对应的概率分布 G ( x ) G(x) G(x),如下图所示: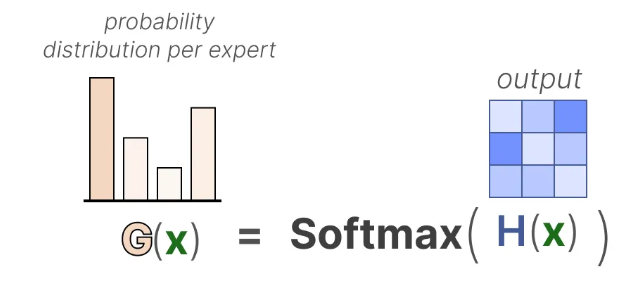
router根据这个概率分布去选择最合适的专家分配给输入。输入经过专家会得到输出 E ( x ) E(x) E(x),最后再乘以刚才对应的概率,就可以得到最终的输出,将每个选中专家的最终输出相加即可得到该MoE layer的输出。(前面的例子是只选择一个专家,一般是选2个)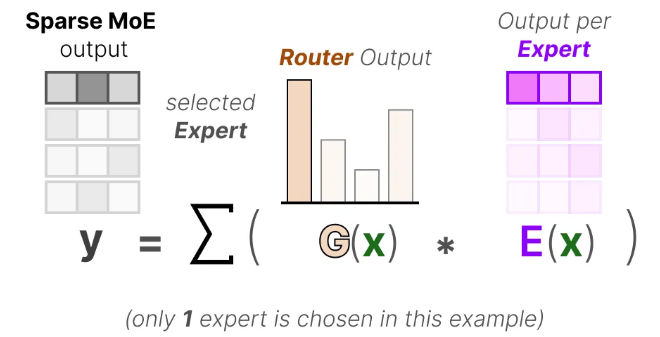
最后再通过图示整体看下MoE部分的计算逻辑。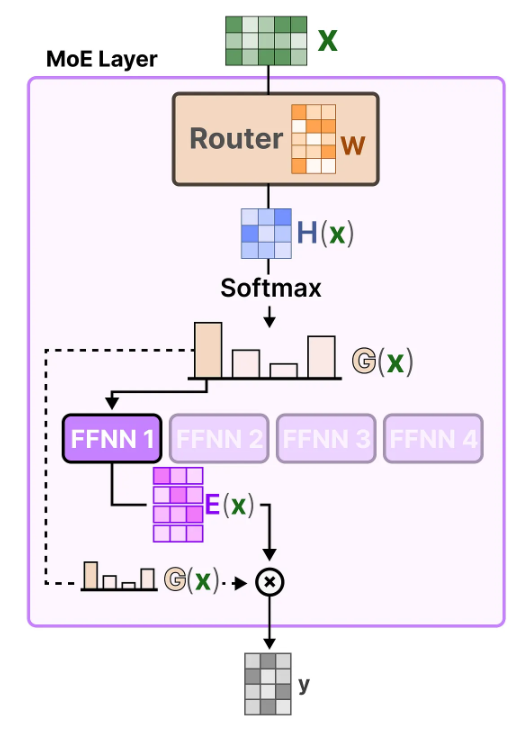
注:不管是训练阶段还是推理阶段,都是通过router去选择专家的
MoE存在哪些问题
由上面的内容应该可以很容易get到一个信息,训练的时候也需要通过路由选择来确定专家,那么也就是说只有被选中的专家才有机会在当前step学习,那我越学越好,越好你就越选我,那我越学越好…最终就会导致有几个专家变成了“全能",所有的输入都会被指派给他们,而其余大部分专家都变成了”砖家“,永远都在摸鱼,训练时啥也没学到。这显然是不合理的。
于是提出了负载均衡这个概念。
负载均衡(Load Balancing)
关于专家负载均衡这部分目前已经有非常非常多的技术,在这里简单回顾两种。
KeepTopK
通过引入一个可训练的高斯矩阵作为噪声,可以避免某个专家总被选择: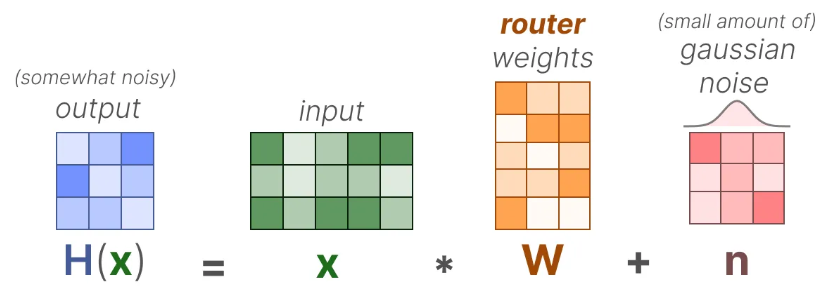
然后,除了选中的专家(比如选择2个),将其余专家的权重都置为负无穷: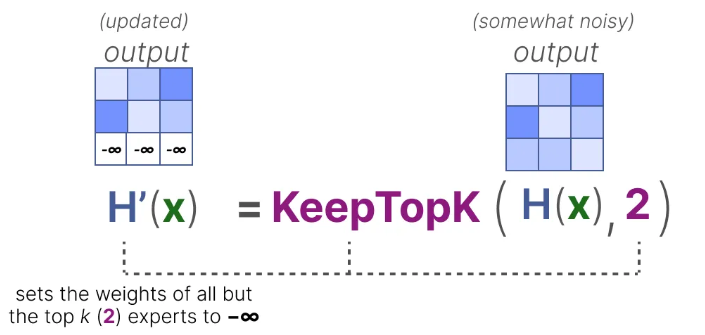
那些置为负无穷的权重,经过softmax后对应专家的概率就会变为0: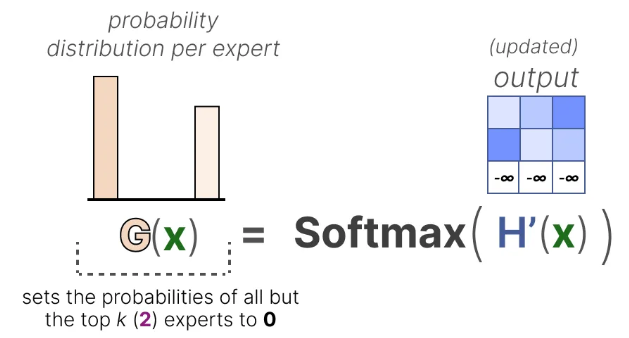
尽管目前有很多替代方法,但是KeepTopK依旧是最受欢迎的方法之一,甚至可以去掉前面的高斯噪声直接使用。
Token Choice
KeepTopK将每个token都指派给1个或多个专家,这个方法叫做token选择: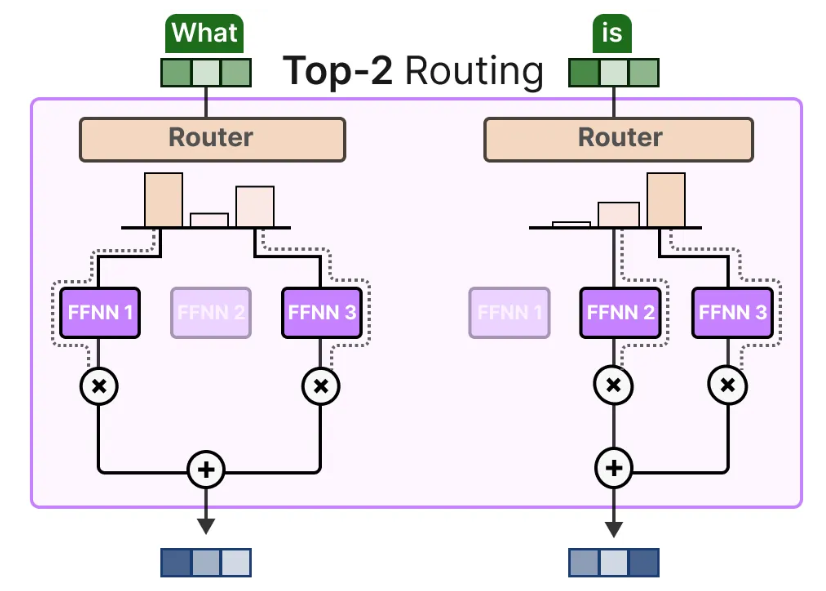
上图中就将每个token分给不同的2个专家(Top-2)进行预测,这样做的好处是显而易见的,可以整合和计算不同专家对每个token的贡献。
专家容量(Expert Capacity)
除了上面所说的专家选择会存在不平衡,token的指派同样会存在不均衡的情况。
这里可能会有同学疑惑,怎么听起来好像还是一回事,简单来讲,专家选择不均衡是指大部分专家都没学到东西,不管什么内容都得他来;而token指派不均衡是指刚好这些输入都是相同类型的,只有某个专家擅长,就会导致该专家一直被选择
比如下图所示,由于输入token都是同一类的内容,导致所有token都被指派给了专家1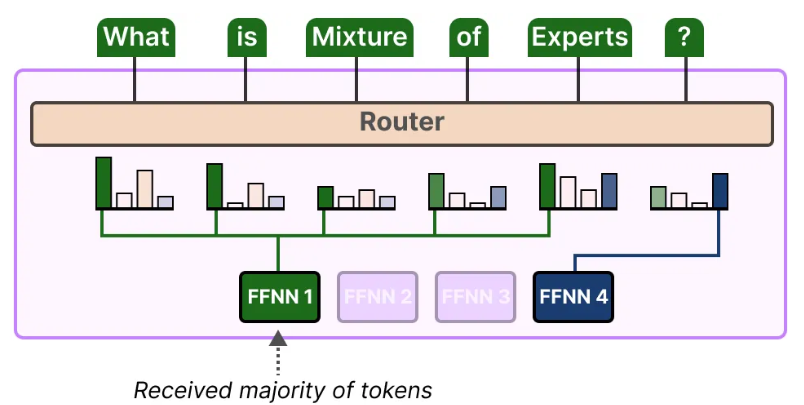
这种情况也会导致对其他专家训练不足的情况出现,影响模型效果性能。
一个最简单的方式就是给每个专家配置一个容量,比如限定每个专家只能被指派3个token,那么多余的token就得被迫指派给其他的专家,虽然现在他可能不擅长,但是训练几次就擅长了。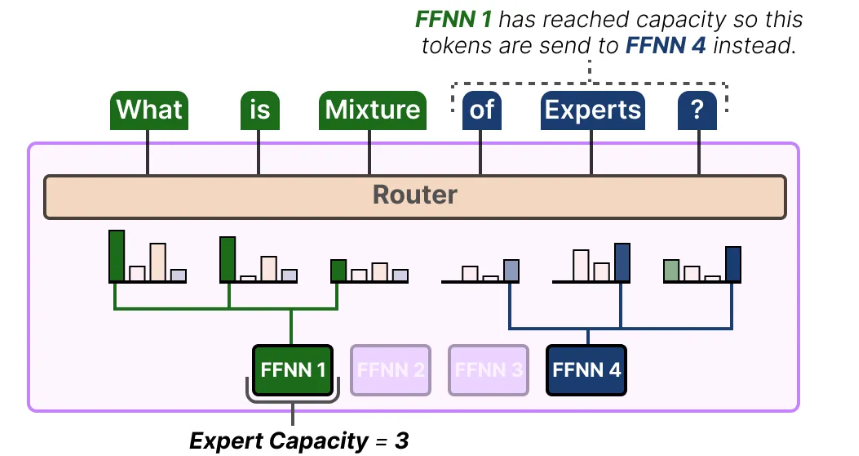
这样做当然也会出现问题,如果专家容量设置的太小,而token数很多,就可能导致某些token最后没有专家可以分配,这时就会发生token溢出,结果就是把它们传给下一层处理。
回顾完了上面这些内容再来看看DeepSeek中是如何在MoE这块做文章的
概述
MoE机制在每次推理步骤中选择性地激活模型总参数的一个子集,在保持模型质量的同时实现计算量的节省。这种方法使得在计算成本没有按比例增加的情况下扩展模型参数成为可能。
DeepSeek - R1改进了DeepSeek - V2的MoE框架,引入了动态专家路由、基于强化学习的负载平衡和增强的稀疏性约束。这些创新使DeepSeek - R1成为可用的最高效且可扩展的开源MoE模型之一。
关键特性
- 基于强化学习的专家路由(einforcement Learning-Based Expert Routing):DeepSeek - R1用基于强化学习(RL)的策略取代静态门控函数,以动态地将token分配给专家。基于RL的路由器通过最大化负载平衡同时最小化路由熵来优化专家选择,从而实现更高效的token - 专家映射。
- 分层熵门控MoE(Hierarchical Entropy-Gated MoE, HE - MoE):专家选择过程通过一个多层门控机制进行优化。token首先经过全局平衡阶段,然后是集群级修剪,最后是每轮熵调整以确保负载平衡。这种方法防止了专家过度专业化并提高了泛化能力。
- 设备约束的专家分配(Device-Constrained Expert Allocation, DCEA):根据可用的计算资源分配专家,减少跨设备通信开销。该模型在受限的设备池中选择专家,降低同步成本并提高训练效率。
- 基于RL调整的负载平衡专家利用(Load-Balanced Expert Utilization with RL-Based Adjustments:):DeepSeek - R1不依赖基于辅助损失函数的偏差项来平衡负载,而是使用RL动态调整专家激活概率。这确保了一致的工作负载分配,而无需额外的损失惩罚,提高了训练稳定性和收敛性。
- 全部token保留(Full Token Retention (No Token Dropping)):与早期为平衡计算负载而丢弃低亲和力token的迭代不同,DeepSeek - R1在训练和推理过程中保留所有token。这确保了在泛化过程中没有信息丢失。
- 跨设备通信优化(Cross-Device Communication Optimization):借助DCEA和分层专家门控,DeepSeek - R1显著减少了设备间通信,使模型延迟降低多达35%。这种优化在不牺牲模型性能的情况下增强了推理效率。
- 动态专家激活(Dynamic Expert Activation):该模型使用学习到的路由策略动态调整专家选择,确保计算资源的高效分配。这使得DeepSeek - R1能够在不增加计算成本的情况下有效地扩展。
- 自适应专家专业化(Adaptive Expert Specialization):通过纳入基于熵的约束,DeepSeek - R1确保专家在保持一定灵活性的同时保持专业化。这种动态专业化提高了准确性和效率。
从DeepSeek - V2到DeepSeek - R1的演进
DeepSeek - V2中的专家混合(MoE)
- DeepSeek - V2引入了一种名为DeepSeekMoE的专用MoE架构,该架构在保持强大性能的同时,优化了模型训练效率和推理吞吐量。此架构改进了专家选择、路由和负载平衡策略,以减少计算开销。下面我们详细阐述DeepSeek - V2中MoE特定机制,将其分解为各个组件。
DeepSeekMoE的基本架构
- DeepSeekMoE设计有细粒度的专家分割和共享专家隔离,这在减少冗余的同时增加了专业化程度。DeepSeek - V2中的MoE架构由以下部分组成:
- N s N_s Ns个共享专家,处理所有token。
- N r N_r Nr个路由专家,根据门控函数为token选择性激活。
- 每个token由固定数量 K r K_r Kr的路由专家处理。
- MoE层的输出计算如下:
h t l = u t + ∑ i = 1 N s F F N i ( s ) ( u t ) + ∑ i = 1 N r g i , t F F N i ( r ) ( u t ) h_t^l = u_t + \sum_{i = 1}^{N_s} FFN_i^{(s)}(u_t) + \sum_{i = 1}^{N_r} g_{i,t}FFN_i^{(r)}(u_t) htl=ut+∑i=1NsFFNi(s)(ut)+∑i=1Nrgi,tFFNi(r)(ut)- 其中:
- F F N i ( s ) FFN_i^{(s)} FFNi(s)表示共享专家。
- F F N i ( r ) FFN_i^{(r)} FFNi(r)表示路由专家。
- g i , t g_{i,t} gi,t是门控函数,确定token t t t的专家选择。
- 其中:
- 门控函数如下:
g i , t = { s i , t , s i , t ∈ Top - K r ( { s j , t ∣ 1 ≤ j ≤ N r } ) 0 , otherwise g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{Top - }K_r(\{s_{j,t} \mid 1 \leq j \leq N_r\}) \\ 0, & \text{otherwise} \end{cases} gi,t={si,t,0,si,t∈Top - Kr({sj,t∣1≤j≤Nr})otherwise- 其中 s i , t s_{i,t} si,t是softmax加权的token - 专家亲和力:
s i , t = Softmax i ( u t T e i ) s_{i,t} = \text{Softmax}_i(u_t^T e_i) si,t=Softmaxi(utTei) - 其中 e i e_i ei是专家 i i i的质心。
- 其中 s i , t s_{i,t} si,t是softmax加权的token - 专家亲和力:
设备受限路由
- MoE模型中的主要计算瓶颈之一是由专家并行性引入的通信开销。为解决此问题,DeepSeekMoE实施设备受限路由,限制token的专家可分布的设备数量。
- 关键实现细节:
- 每个token首先选择亲和力分数最高的 M M M个设备。
- 最终的 K r K_r Kr个专家仅从这些选定设备中选择。
- 实际上,设置 M ≥ 3 M \geq 3 M≥3可确保性能接近无限制路由,同时显著减少跨设备通信。
负载平衡的辅助损失
- DeepSeek - V2采用多种辅助损失来确保专家的平衡利用,避免某些专家过载而其他专家未充分利用的情况。具体如下:
- 专家级平衡损失:
- 为防止路由崩溃(即只有一部分专家得到训练的情况),DeepSeek - V2最小化:
L ExpBal = α 1 ∑ i = 1 N r f i P i L_{\text{ExpBal}} = \alpha_1 \sum_{i = 1}^{N_r} f_i P_i LExpBal=α1∑i=1NrfiPi - 其中:
- f i f_i fi是路由到专家 i i i的token比例。
- P i P_i Pi是选择专家 i i i的平均概率。
- α 1 \alpha_1 α1是控制损失强度的超参数。
- 为防止路由崩溃(即只有一部分专家得到训练的情况),DeepSeek - V2最小化:
- 设备级平衡损失:
- 为在设备间均匀分配计算,DeepSeekMoE将专家分配到 D D D个设备组,每个组在单独的设备上运行。平衡损失为:
L DevBal = α 2 ∑ i = 1 D f i ′ P i ′ L_{\text{DevBal}} = \alpha_2 \sum_{i = 1}^{D} f_i' P_i' LDevBal=α2∑i=1Dfi′Pi′ - 其中 f i ′ f_i' fi′和 P i ′ P_i' Pi′汇总了设备 i i i上所有专家的使用统计信息。
- 为在设备间均匀分配计算,DeepSeekMoE将专家分配到 D D D个设备组,每个组在单独的设备上运行。平衡损失为:
- 通信平衡损失:
- 此损失确保每个设备接收大致相等数量的token,防止因通信负载过大导致的瓶颈:
L CommBal = α 3 ∑ i = 1 D f i ′ ′ P i ′ ′ L_{\text{CommBal}} = \alpha_3 \sum_{i = 1}^{D} f_i'' P_i'' LCommBal=α3∑i=1Dfi′′Pi′′ - 其中 f i ′ ′ f_i'' fi′′和 P i ′ ′ P_i'' Pi′′衡量发送到设备 i i i的v比例。
- 此损失确保每个设备接收大致相等数量的token,防止因通信负载过大导致的瓶颈:
- 专家级平衡损失:
节点受限路由(NLR)
- DeepSeek - V3引入了节点受限路由(NLR),以在大规模MoE训练中进一步优化通信开销。NLR不是允许token被分派到模型中的任意专家,而是限制每个token可与之通信的节点数量。路由机制为每个token最多选择 M M M个节点,确保以最小化节点间同步的方式分配专家。
M = ∑ i = 1 N max { s j , t ∣ j ∈ node i } M = \sum_{i = 1}^{N} \max\{s_{j,t} \mid j \in \text{node } i\} M=∑i=1Nmax{sj,t∣j∈node i} - 这种方法显著减少了跨节点通信开销,从而加快了训练和推理时间。
改进的专家选择机制
- DeepSeek - V3通过纳入基于sigmoid的token - 专家亲和力函数来改进专家选择,取代了DeepSeek - V2中使用的基于softmax的机制。新函数定义为:
s i , t = σ ( u t T e i ) s_{i,t} = \sigma(u_t^T e_i) si,t=σ(utTei)- 其中 e i e_i ei是专家 i i i的质心, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是sigmoid激活函数。然后选择过程对前 K r K_r Kr个专家分数进行归一化:
g i , t = g i , t ′ ∑ j ∈ Top - K r g j , t ′ g_{i,t} = \frac{g_{i,t}'}{\sum_{j \in \text{Top - }K_r} g_{j,t}'} gi,t=∑j∈Top - Krgj,t′gi,t′
- 其中 e i e_i ei是专家 i i i的质心, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是sigmoid激活函数。然后选择过程对前 K r K_r Kr个专家分数进行归一化:
- 此修改防止了极端的专家选择概率,从而实现更好的负载平衡和专业化。
具有分层门控的增强稀疏性约束
-
为避免过度专业化并促进泛化,DeepSeek - V3引入了分层门控。与传统的前 K K K门控不同,此方法在多个级别应用稀疏性约束:
- 全局选择:初始选择 N g N_g Ng个专家的粗略级别。
- 集群级修剪:在选定集群内进一步筛选专家以获得 K r K_r Kr个专家。
- 基于熵的调整:根据熵约束调整专家激活概率,以避免极端稀疏性。
-
从数学上讲,基于熵的调整按如下方式修改门控分数:
g i , t = g i , t × ( 1 − λ ⋅ H ( g 1 : N , t ) ) g_{i,t} = g_{i,t} \times (1 - \lambda \cdot H(g_{1:N,t})) gi,t=gi,t×(1−λ⋅H(g1:N,t))- 其中 H ( ⋅ ) H(\cdot) H(⋅)是熵函数, λ \lambda λ是控制均匀选择和专业化之间权衡的正则化系数。
无token丢弃策略
- DeepSeek - V2实施了一种token丢弃策略,以平衡每个设备的计算量。然而,DeepSeek - V3增强的负载平衡机制消除了token丢弃的需要,确保在训练和推理过程中100%保留token。这提高了泛化能力,并避免了模型更新期间的信息丢失。
DeepSeek - R1中的改进
- DeepSeek - R1对MoE框架进行了多项重大改进,提高了计算效率、负载平衡和推理准确性。这些改进建立在DeepSeek - V3的优化基础上,整合了基于强化学习的路由策略、熵控制门控和细粒度专家专业化。下面,我们将详细介绍DeepSeek - R1中关键的MoE创新。
基于强化学习(RL)的自适应专家路由
- DeepSeek - R1引入了基于RL的专家路由,摒弃了DeepSeek - V3中使用的静态路由方法。DeepSeek - R1不是纯粹基于通过softmax函数计算的token- 专家亲和力来选择专家,而是纳入了学习到的RL策略,以动态地将token分配给专家。
- 数学公式:
-
专家选择函数被公式化为一个RL策略优化问题,其中为token t t t选择专家 e i e_i ei的概率基于token嵌入 u t u_t ut动态调整:
g i , t = π θ ( e i ∣ u t ) g_{i,t} = \pi_{\theta}(e_i | u_t) gi,t=πθ(ei∣ut) -
其中 π θ \pi_{\theta} πθ是基于上下文嵌入选择专家的策略网络。优化目标遵循广义优势估计(GRPO):
J GRPO ( θ ) = E q ∼ P ( Q ) , { o i } i = 1 c ∼ π θ [ 1 G ∑ i = 1 C min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , A i , clip ( ⋅ ) ) − β D KL ( π θ ∣ ∣ π ref ) ] J_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i = 1}^{c} \sim \pi_{\theta}} \left[ \frac{1}{G} \sum_{i = 1}^{C} \min \left( \frac{\pi_{\theta}(o_i | q)}{\pi_{\theta_{\text{old}}}(o_i | q)}, A_i, \text{clip}(\cdot) \right) - \beta D_{\text{KL}}(\pi_{\theta} || \pi_{\text{ref}}) \right] JGRPO(θ)=Eq∼P(Q),{oi}i=1c∼πθ[G1∑i=1Cmin(πθold(oi∣q)πθ(oi∣q),Ai,clip(⋅))−βDKL(πθ∣∣πref)] -
其中 D KL D_{\text{KL}} DKL对策略更新进行正则化,以防止剧烈变化。
-
- 实现细节:
- 基于RL的路由器通过最大化专家负载平衡和最小化路由熵来学习最优的v分配。
- 它惩罚过度加载特定专家的情况,同时激励跨层的均匀激活。
- 在路由函数中引入动态偏差项,以进一步根据训练反馈调整专家选择。
- 这种方法实现了自适应的token - 专家映射,在保持准确性的同时优化了推理速度。
分层熵门控专家混合(HE - MoE)
- DeepSeek - R1通过引入分层熵门控专家混合(HE - MoE)增强了前K个专家的MoE路由。DeepSeek - R1没有在token级别应用单个前K门控函数,而是实施了一个多层门控机制:
- 全局选择:首先使用softmax亲和力评分将token路由到由 N g N_g Ng个专家组成的初始池中。
- 集群级修剪:在选定的池中,二级门控机制根据熵约束对专家进行修剪。
- 最终专家分配:使用调整后的概率函数选择前 K r K_r Kr个专家,该函数纳入了对熵敏感的惩罚项。
- 最终的门控函数修改如下:
g i , t = Softmax i ( u t T e i ) 1 + λ H ( g 1 : N , t ) g_{i,t} = \frac{\text{Softmax}_i(u_t^T e_i)}{1 + \lambda H(g_{1:N,t})} gi,t=1+λH(g1:N,t)Softmaxi(utTei)- 其中 H ( ⋅ ) H(\cdot) H(⋅)是熵函数, λ \lambda λ控制正则化强度。
- 关键优势:
- 通过确保token更均匀地分布,防止专家过度专业化。
- 减少某些专家主导训练的模式崩溃情况。
- 根据任务复杂性调整门控阈值,动态缩放稀疏性。
设备受限专家分配(DCEA)
- DeepSeek - R1通过纳入设备受限专家分配(DCEA)改进了DeepSeek - V3的节点受限路由,DCEA根据GPU/TPU的可用性和互连带宽限制专家分配。
- 算法:
- 每个token首先选择亲和力分数最高的设备子集。
- 专家被限制在这些设备上,减少设备间同步开销。
- 最终的专家仅在受限的设备池中选择,最小化跨节点通信。
M = ∑ i = 1 N max { s j , t ∣ j ∈ device i } M = \sum_{i = 1}^{N} \max\{s_{j,t} \mid j \in \text{device } i\} M=∑i=1Nmax{sj,t∣j∈device i}
- 结果:
- 设备间通信延迟降低35%。
- 训练动态更稳定,因为专家保留在本地计算节点上。
- 带宽消耗更低,提高了训练效率。
基于RL调整的负载平衡专家利用
- 为确保均匀的负载平衡,DeepSeek - R1引入了基于自适应负载的路由调整,取代了DeepSeek - V3基于辅助损失的平衡策略。
- DeepSeek - R1不是通过最小化专家选择偏差项来显式平衡,而是使用基于RL的方法动态调整门控概率:
如果专家 i i i过载, b i ← b i − γ b_i \leftarrow b_i - \gamma bi←bi−γ,否则 b i ← b i + γ b_i \leftarrow b_i + \gamma bi←bi+γ。 - 相较于辅助损失的优势:
- 收敛更快,因为它避免了为平衡约束进行额外的梯度更新。
- 专家选择更稳健,因为它在多个训练步骤中进行适应。
- 这确保了一致的工作负载分配,而无需严格的辅助惩罚。
消除token丢弃策略
- 与DeepSeek - V3使用token丢弃来平衡每个设备的计算不同,DeepSeek - R1通过动态优化专家激活阈值完全消除了token丢弃。
- DeepSeek - R1没有移除低亲和力token,而是使用基于强化学习的专家重新分配策略将token重新分配给替代专家。
- 优势:
- 在训练和推理过程中100%保留token。
- 由于所有token都有助于学习,泛化能力更强。
- 没有上下文信息丢失,从而生成更连贯的内容。
对比分析
- DeepSeek - R1代表了MoE框架的最先进迭代,建立在DeepSeek - V2和DeepSeek - V3引入的优化基础之上。下面,我们比较这三个版本的关键MoE特性,突出在效率、专家路由、负载平衡和推理性能方面的改进。
| 特性 | DeepSeek - V2 | DeepSeek - V3 | DeepSeek - R1 |
|---|---|---|---|
| 动态专家激活 | ✘ | ✔️(基于偏差选择) | ✔️(基于强化学习选择) |
| 设备受限路由(DLR) | ✔️ | ✔️(节点受限路由) | ✔️(设备受限专家分配) |
| 负载平衡辅助损失 | ✔️ | ✘(基于偏差调整) | ✘(基于强化学习自适应平衡) |
| 基于强化学习的路由 | ✘ | ✘ | ✔️ |
| 专家选择的分层门控 | ✘ | ✔️ | ✔️(基于熵调整) |
| 改进的专家选择机制 | ✘ | ✔️(基于sigmoid) | ✔️(强化学习优化选择) |
| 跨设备通信减少 | ✔️(设备受限路由) | ✔️(节点受限路由) | ✔️(使用DCEA延迟降低35%) |
| 为计算效率的token丢弃 | ✔️ | ✘(无token丢弃) | ✘(无token丢弃) |
| 稀疏激活策略 | ✔️(前K门控) | ✔️(分层前K门控) | ✔️(分层熵门控MoE) |
| 训练稳定性 | 中等 | 高 | 非常高 |
| 推理速度优化 | 中等 | 高 | 非常高 |
| 负载平衡策略 | 基于损失的平衡 | 基于偏差的自适应平衡 | 基于强化学习的自适应平衡 |
数学公式
- DeepSeek - R1中的专家选择过程遵循一个门控函数:
G ( x ) = softmax ( W g x ) G(\boldsymbol{x}) = \text{softmax}(\boldsymbol{W}_g\boldsymbol{x}) G(x)=softmax(Wgx)- 其中 W g \boldsymbol{W}_g Wg是一个可训练的权重矩阵。
- 最终输出计算如下:
y = ∑ k ∈ K G k ( x ) E k ( x ) \boldsymbol{y} = \sum_{k\in\mathcal{K}} G_k(\boldsymbol{x})E_k(\boldsymbol{x}) y=∑k∈KGk(x)Ek(x)- 其中:
- K \mathcal{K} K表示前 K K K个被选择的专家。
- E k ( x ) E_k(\boldsymbol{x}) Ek(x)是专家 k k k执行的计算。
- G k ( x ) G_k(\boldsymbol{x}) Gk(x)是门控概率。
- 其中:
负载平衡损失
- 为确保专家的均衡利用,DeepSeek - R1应用了一个负载平衡损失:
L balance = λ ∑ k ( n k N − 1 K ) 2 \mathcal{L}_{\text{balance}} = \lambda \sum_{k} \left( \frac{n_k}{N} - \frac{1}{K} \right)^2 Lbalance=λ∑k(Nnk−K1)2- 其中:
- n k n_k nk是分配给专家 k k k的token数量。
- N N N是一个批次中的token总数。
- K K K是每个token的活跃专家数量。
- 其中:
- 此外,一个熵正则化项可防止对专家的过度依赖:
L entropy = − γ ∑ k G k ( x ) log G k ( x ) \mathcal{L}_{\text{entropy}} = -\gamma \sum_{k} G_k(\boldsymbol{x}) \log G_k(\boldsymbol{x}) Lentropy=−γ∑kGk(x)logGk(x)- 其中 γ \gamma γ控制熵的强度。
参考文献:
https://arxiv.org/pdf/2405.04434
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
https://arxiv.org/pdf/2209.01667
https://aman.ai/primers/ai/deepseek-R1/
https://brunomaga.github.io/Mixture-of-Experts
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
https://arxiv.org/pdf/2407.06204

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 62
62 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)