DeepSeek开源周第三日:DeepGEMM,简洁高效重构AI算力法则
—— DeepGEMM:简洁、高效,用约300行CUDA代码重构AI计算的底层法则
什么是DeepGEMM呢?
用官方的介绍就是DeepGEMM是一个库,专为干净高效的FP8通用矩阵乘法(GEMM)而设计,具有精细的缩放,正如DeepSeek-V3中所建议的那样。它支持普通和混合专家(MoE)分组的GEMM。该库用CUDA编写,通过在运行时使用轻量级的Just-In-Time(JIT)模块编译所有内核,在安装过程中不需要编译。简单来说就是一个专为FP8通用矩阵乘法(GEMMs)设计的简洁高效库,让你的矩阵算法 又快、又准。
DeepGEMM技术亮点
今天,依旧是保持“高性能、低成本”的风格特点,对本次开源技术提炼的亮点要素有以下几个:
-
高性能
在Hopper架构的GPU上,DeepGEMM能够实现高达1350+FP8 TFLOPS的性能
-
简洁、轻量型
核心内核函数约 300 行代码,但性能却优于专家调优的内核
-
即时编译JIT
采用完全即时编译的方式,这意味着它可以在运行时动态生成优化的代码,从而适应不同的硬件和矩阵大小。
-
无重依赖
这个库设计得非常轻量级,没有复杂的依赖关系,可以让部署和使用变得简单。
-
支持多矩阵布局
支持密集矩阵布局DenseGEEM和两种 MoE 布局,这使得它能够适应不同的应用场景,包括但不限于深度学习中的混合专家模型。
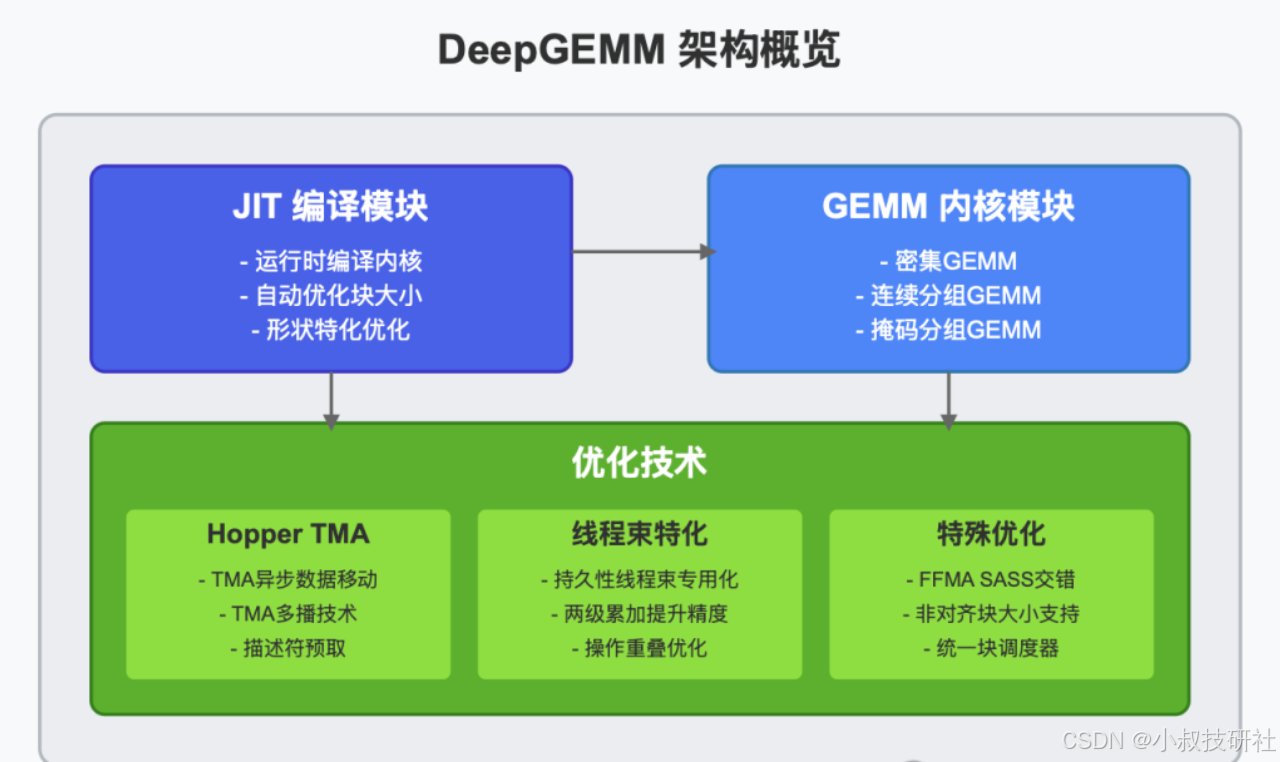
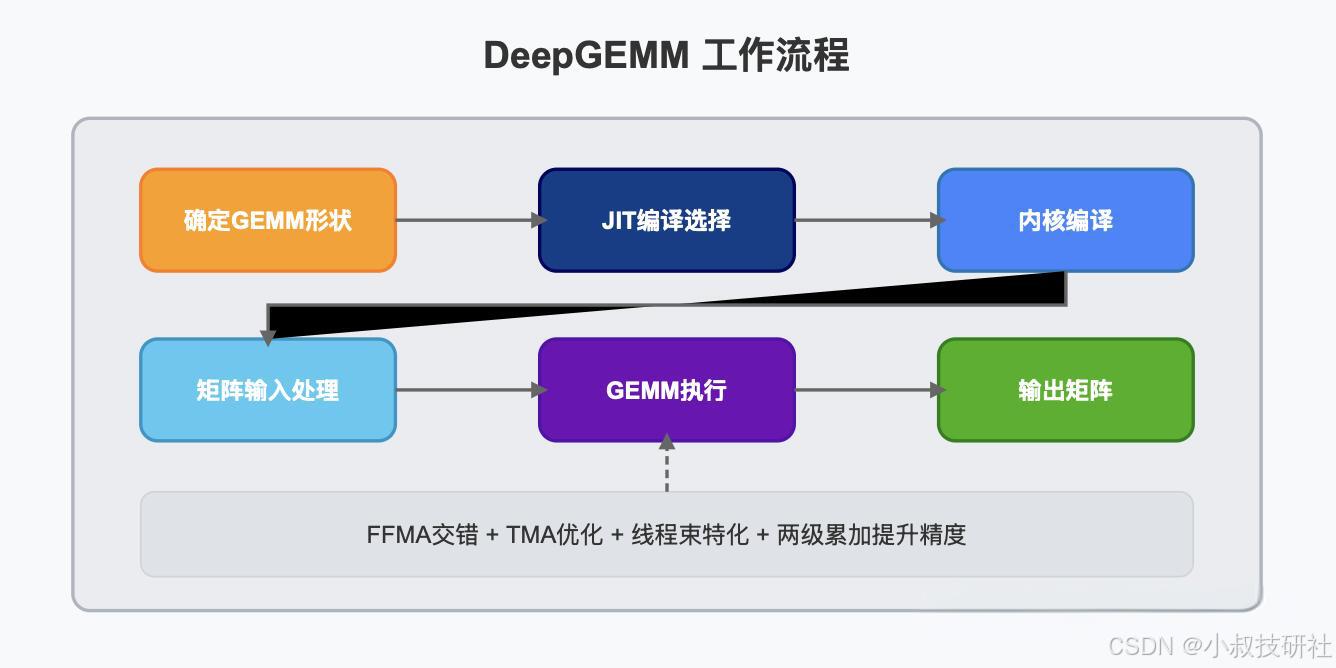
最令人惊叹的是,虽然借鉴了CUTLASS和CuTe的一些概念,但DeepGEMM避免了过度依赖它们的模板或代数,DeepGEMM在各种矩阵形状上的性能与专家调优库相当甚至更好,这让它成为学习Hopper FP8矩阵乘法和优化技术的绝佳资源。
性能表现
DeepGEMM在H800上使用NVCC 12.8测试了DeepSeek-V3/R1推理中可能使用的所有形状(包括预填充和解码,但不包括张量并行)。所有加速指标都是与基于CUTLASS 3.6的内部优化实现相比计算得出的。
普通GEMM(非分组)性能数据:

分组GEMM(连续布局)性能数据:

开源生态与意义
社区贡献
DeepGEMM 采用 MIT 协议开源,团队明确欢迎社区针对特殊矩阵形状提交优化 PR,并已集成 CUTLASS 3.6 的先进特性
行业影响
-
为中小团队提供低成本部署千亿参数模型的可行性,训练成本预计降低 50%
-
推动 FP8 计算生态发展,弥补当前开源社区在低精度矩阵运算领域的工具链缺口
-
DeepGEMM的开源为整个AI社区提供了宝贵的资源。它的简洁设计使开发者能够更容易地理解和学习FP8矩阵乘法和优化技术,从而将推动整个领域的进步。
快速入门
系统要求
- 硬件:支持
sm_90a的 Hopper 架构 GPU - 软件:
- Python 3.8 或更高版本
- CUDA 12.3 或更高版本(推荐 12.8 以获得最佳性能)
- PyTorch 2.1 或更高版本
- CUTLASS 3.6 或更高版本(可通过 Git 子模块克隆)
开发
# 必须克隆子模块
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# 创建第三方库(CUTLASS 和 CuTe)头文件的符号链接
python setup.py develop
# 测试 JIT 编译
python tests/test_jit.py
# 测试所有 GEMM 实现(常规、连续分组和掩码分组)
python tests/test_core.py安装
python setup.py install实用工具
除核心内核外,库提供以下工具函数:
deep_gemm.set_num_sms: 设置使用的最大 SM 数量deep_gemm.get_num_sms: 获取当前 SM 最大数量deep_gemm.get_m_alignment_for_contiguous_layout: 获取连续布局的分组对齐要求deep_gemm.get_tma_aligned_size: 获取 TMA 对齐所需大小deep_gemm.get_col_major_tma_aligned_tensor: 获取列主序的 TMA 对齐张量
环境变量
| 变量名 | 类型 | 说明 |
|---|---|---|
DG_CACHE_DIR |
字符串 | 存储编译内核的缓存目录(默认 $HOME/.deep_gemm) |
DG_NVCC_COMPILER |
字符串 | 指定 NVCC 编译器路径(默认从 torch.utils.cpp_extension.CUDA_HOME 查找) |
DG_DISABLE_FFMA_INTERLEAVE |
0/1 | 禁用 FFMA 交错优化 |
DG_PTXAS_VERBOSE |
0/1 | 显示 PTXAS 编译器的详细输出 |
DG_PRINT_REG_REUSE |
0/1 | 打印 FFMA 交错细节 |
DG_JIT_PRINT_NVCC_COMMAND |
0/1 | 打印 NVCC 编译命令 |
DG_JIT_DEBUG |
0/1 | 打印更多调试信息 |
更多示例和细节请参考测试代码或 Python 文档。
想查看更多详细版参数请参考官方GitHub地址:https://github.com/deepseek-ai/DeepGEMM
期待接下来的几天还会有什么惊喜!!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)