
结合DeepSeek-R1强化学习方法的视觉模型!VLM-R1:输入描述就能精确定位图像目标
VLM-R1 是基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像目标,支持复杂场景推理与高效训练。
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🚀 “图像标注要失业?浙大黑科技让AI用自然语言‘指哪打哪’,蛋白质识别精确到像素!”
大家好,我是蚝油菜花。你是否经历过——
- 👉 标注海量医学图像时,反复框选到腱鞘炎发作
- 👉 电商场景中找“带金属扣的米色包包”,人工筛选耗时2小时
- 👉 科研论文里定位“蛋白质含量最高的区域”,肉眼对比看到头晕…
今天揭秘的 VLM-R1 ,正在用强化学习重新定义视觉定位!这个由浙江大学开源的多模态AI:
- ✅ 听得懂人话:直接输入“左下方破损的轮胎”,秒级输出精准边界框
- ✅ 跨领域通吃:从医疗影像到街景识别,零样本性能吊打传统模型
- ✅ 训练极简:4步完成私有化部署,单张GPU就能跑
更震撼的是,它在食品检测中能通过X光图指出“钙含量最高的鱼骨”,连生物学家都直呼专业——你的图像标注工作流准备好被颠覆了吗?
🚀 快速阅读
VLM-R1 是一款基于强化学习技术的视觉语言模型,能够通过自然语言指令精确定位图像目标,并支持多模态推理。
- 指代表达理解:解析自然语言指令,精准定位图像中的特定目标。
- 强化学习优化:采用 GRPO 技术,在复杂场景下表现出色,提升泛化能力。
VLM-R1 是什么

VLM-R1 是浙江大学 Om AI Lab 开发的一款基于强化学习技术的视觉语言模型,旨在通过自然语言指令精确定位图像中的目标物体。例如,用户可以通过描述“图中红色的杯子”来让模型找到对应的图像区域。该模型基于 Qwen2.5-VL 架构,结合了 DeepSeek R1 的强化学习方法,通过强化学习优化和监督微调(SFT)提升了模型的稳定性和泛化能力。
VLM-R1 不仅在复杂场景中表现出色,还能处理跨域数据,展现出强大的视觉内容理解能力。其高效的训练与推理机制,使其成为开发者快速上手的理想选择。
此外,VLM-R1 的开源性为研究者和开发者提供了完整的训练和评估流程,仅需四步即可开始训练,降低了使用门槛。
VLM-R1 的主要功能
- 指代表达理解(REC):解析自然语言指令,精确定位图像中的特定目标,如根据描述“图中红色的杯子”找到对应区域。
- 图像与文本联合处理:支持同时输入图像和文字,生成准确的分析结果。
- 强化学习优化:通过 GRPO(Group Relative Policy Optimization)技术,提升模型在复杂场景下的表现和泛化能力。
- 高效训练与推理:采用 Flash Attention 等技术,支持单 GPU 训练大规模参数模型,提升计算效率。
- 多模态推理与知识生成:不仅能识别图像内容,还能进行逻辑推理和文本表达,例如识别蛋白质含量最高的食物并解释原因。
- 易用性与开源性:提供完整的训练和评估流程,开发者可以快速上手,四步即可开始训练。
VLM-R1 的技术原理
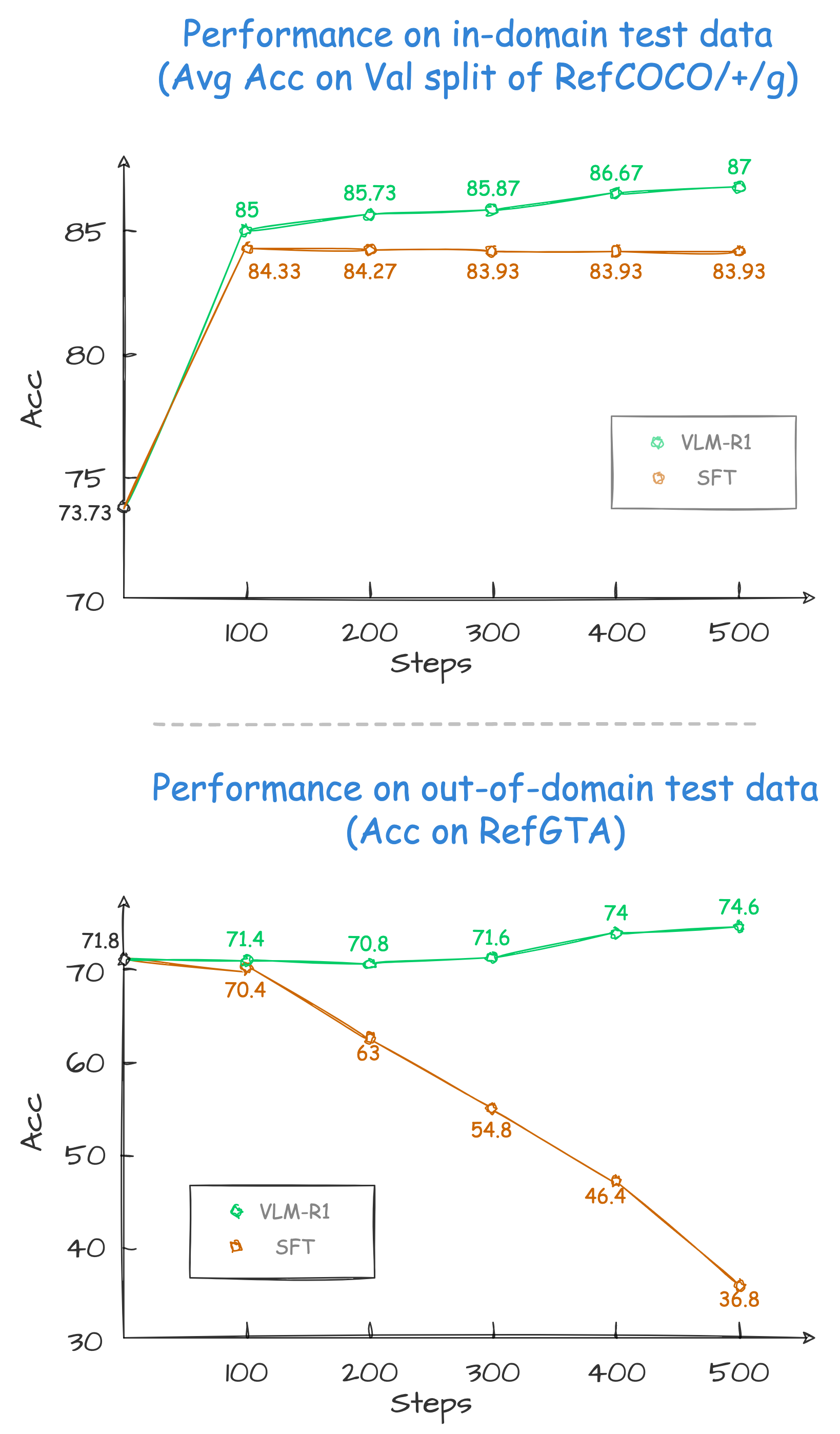
- GRPO 强化学习技术:采用 Group Relative Policy Optimization(GRPO)方法,使模型在复杂场景下自我探索,减少对大量标注数据的依赖。
- 泛化能力与稳定性提升:相比传统的监督微调(SFT)方法,VLM-R1 在领域外测试数据中表现出持续提升的性能,表明其真正掌握了视觉内容的理解能力,而不仅仅是依赖记忆。
- 基于 Qwen2.5-VL 架构:在 Qwen2.5-VL 的基础上开发,通过强化学习优化,在多种复杂场景中保持稳定和高效的性能。
如何运行 VLM-R1
1. 环境搭建
在开始运行 VLM-R1 模型之前,需要配置运行环境。以下是环境搭建的步骤:
conda create -n vlm-r1 python=3.10
conda activate vlm-r1
bash setup.sh
通过上述命令,创建并激活一个名为 vlm-r1 的 Python 环境,并运行 setup.sh 脚本来安装依赖。
2. 数据准备
VLM-R1 模型的训练需要准备图像数据和标注文件。以下是数据准备的详细步骤:
2.1 下载图像数据
下载COCO Train2014 图像数据并解压,将图像文件夹路径记为 <your_image_root>。
- COCO Train2014 图像数据:https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/train2014.zip
2.2 下载标注文件
下载RefCOCO/+/g 和 RefGTA 标注文件并解压。RefGTA 用于域外评估。
- RefCOCO/+/g 和 RefGTA 标注文件:https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/rec_jsons_processed.zip
2.3 配置标注文件路径
在 src/open-r1-multimodal/data_config/rec.yaml 文件中,填写标注文件的路径。例如:
datasets:
- json_path: /path/to/refcoco_train.json
- json_path: /path/to/refcocop_train.json
- json_path: /path/to/refcocog_train.json
3. 模型训练
VLM-R1 提供了两种训练方法:GRPO 和 SFT。以下是两种方法的详细步骤。
3.1 GRPO 方法
运行以下命令以启动 GRPO 方法的训练:
cd src/open-r1-multimodal
torchrun --nproc_per_node="8" \
--nnodes="1" \
--node_rank="0" \
--master_addr="127.0.0.1" \
--master_port="12346" \
src/open_r1/grpo_rec.py \
--deepspeed local_scripts/zero3.json \
--output_dir output/$RUN_NAME \
--model_name_or_path Qwen/Qwen2.5-VL-3B-Instruct \
--dataset_name data_config/rec.yaml \
--image_root <your_image_root> \
--max_prompt_length 1024 \
--num_generations 8 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 2 \
--logging_steps 1 \
--bf16 \
--torch_dtype bfloat16 \
--data_seed 42 \
--report_to wandb \
--gradient_checkpointing false \
--attn_implementation flash_attention_2 \
--num_train_epochs 2 \
--run_name $RUN_NAME \
--save_steps 100 \
--save_only_model true
如果遇到 CUDA out of memory 错误,可以尝试以下方法:
- 设置
gradient_checkpointing为true。 - 减少
num_generations的值。 - 使用 LoRA 方法。
3.2 SFT 方法
首先,克隆LLaMA-Factory仓库并安装依赖:
- LLaMA-Factory 仓库:https://github.com/hiyouga/LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
接着,下载提供的 dataset_info.json、mllm_rec_json.json 和 qwen2_5_vl_full_sft.yaml 文件,分别放置在 LLaMA-Factory/data 和 LLaMA-Factory/examples/train_full 目录中。
最后,运行以下命令以启动 SFT 方法的训练:
llamafactory-cli train examples/train_full/qwen2_5_vl_full_sft.yaml
4. 自定义数据支持
VLM-R1 支持自定义数据的加载,数据格式需为 JSONL 文件。以下是数据格式示例:
{"id": 1, "image": "Clevr_CoGenT_TrainA_R1/data/images/CLEVR_trainA_000001_16885.png", "conversations": [{"from": "human", "value": "<image>What number of purple metallic balls are there?"}, {"from": "gpt", "value": "0"}]}
4.1 注意事项
- JSONL 文件中的图像路径应为相对于
--image_folders指定的文件夹路径。 - 多个数据文件和图像文件夹可以通过
:分隔。例如:
--data_file_paths /path/to/data1.jsonl:/path/to/data2.jsonl \
--image_folders /path/to/images1/:/path/to/images2/
4.2 加载自定义数据
运行以下命令以加载自定义数据:
torchrun --nproc_per_node="8" \
--nnodes="1" \
--node_rank="0" \
--master_addr="127.0.0.1" \
--master_port="12345" \
src/open_r1/grpo_jsonl.py \
--output_dir output/$RUN_NAME \
--model_name_or_path Qwen/Qwen2.5-VL-3B-Instruct \
--deepspeed local_scripts/zero3.json \
--dataset_name <your_dataset_name> \
--data_file_paths /path/to/your/data.jsonl \
--image_folders /path/to/your/image/folder/
5. 模型评估
模型训练完成后,可以使用以下命令进行评估:
cd ./src/eval
# 修改脚本中的模型路径、图像根目录和标注文件路径
python test_rec_r1.py # 用于 GRPO 方法
python test_rec_baseline.py # 用于 SFT 方法
资源
- GitHub 仓库:https://github.com/om-ai-lab/VLM-R1
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 38
38 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)