deepseek学习:我用ai写代码之python实现并行调度
带着问题去学习,会让你事半功倍,在开始之前我们先讨论一个问题,如果我们想同时调启一个命令多次,我们会怎么办,这个时候会想到python的两个模块multiprocessing和thread,
这两个模块帮我们实现了并行,好,问题解决......但是我们需要看到另一个问题,我们如何控制并行数量呢,如果一个子程序需要运行一百次,一千次,一万次,难道我们要直接全部运行起来吗?
答案肯定不,所以我们要想办法把这件事解决,然后我开始询问deepseek
我现在有一个子函数名字叫p_w_time,这个函数有一个参数,我每次调用这个函数都需要向这里面传入一个值,我需要并行调度这个子函数多次,我有以下要求:
1、可以手动控制并行调度的数量
2、在并行调度数量内,一个子进程执行成功之后,另一个子进程开始执行
3、最后需要返回执行成功和执行没有成功的进程
from concurrent.futures import ThreadPoolExecutor, as_completed
import traceback
def p_w_time(param):
"""示例子函数(需替换为实际业务逻辑)"""
try:
# 这里写你的实际业务逻辑
if param % 2 == 0: # 模拟失败条件
raise ValueError(f"参数{param}触发异常")
return f"参数{param}处理成功"
except Exception as e:
raise # 将异常抛给调用方
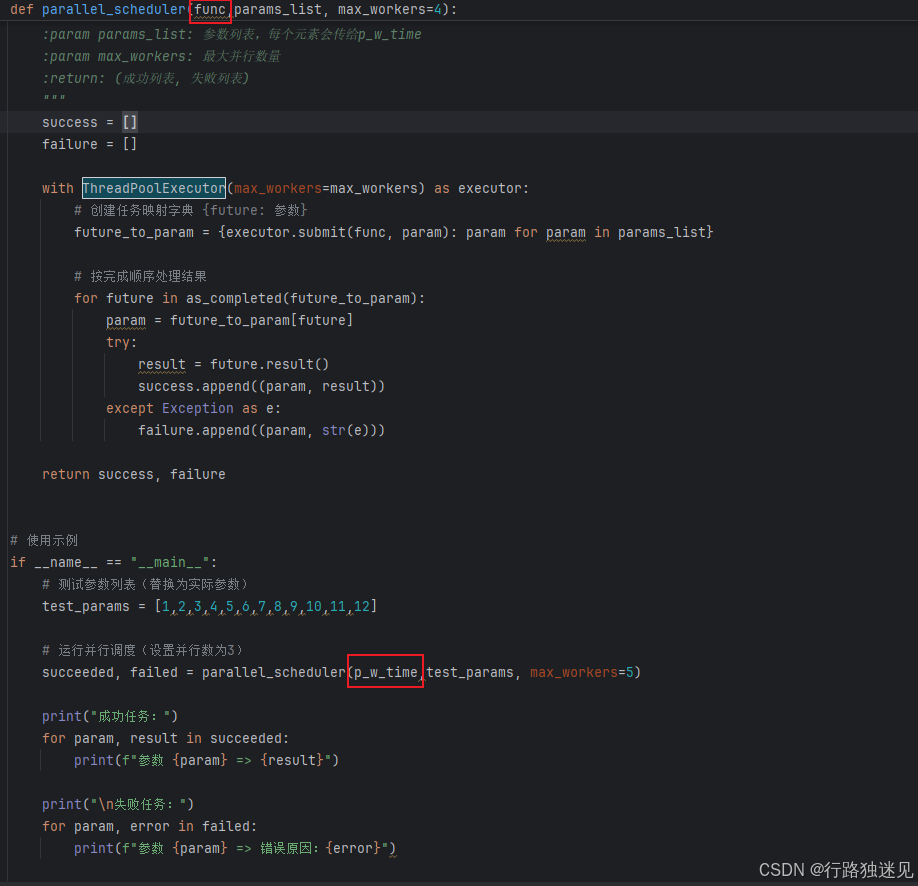
def parallel_scheduler(params_list, max_workers=4):
"""
并行调度器
:param params_list: 参数列表,每个元素会传给p_w_time
:param max_workers: 最大并行数量
:return: (成功列表, 失败列表)
"""
success = []
failure = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 创建任务映射字典 {future: 参数}
future_to_param = {executor.submit(p_w_time, param): param for param in params_list}
# 按完成顺序处理结果
for future in as_completed(future_to_param):
param = future_to_param[future]
try:
result = future.result()
success.append((param, result))
except Exception as e:
failure.append((param, str(e)))
return success, failure
# 使用示例
if __name__ == "__main__":
# 测试参数列表(替换为实际参数)
test_params = [1, 2, 3, 4, 5, 6]
# 运行并行调度(设置并行数为3)
succeeded, failed = parallel_scheduler(test_params, max_workers=3)
print("成功任务:")
for param, result in succeeded:
print(f"参数 {param} => {result}")
print("\n失败任务:")
for param, error in failed:
print(f"参数 {param} => 错误原因:{error}")关键特性说明
-
并发控制
- 通过
max_workers参数精确控制并行数量(第23行) - 使用
ThreadPoolExecutor实现线程池管理
- 通过
-
执行顺序保证
as_completed方法确保完成一个任务立即处理结果(第28行)- 实际并行度始终保持不超过
max_workers
-
结果处理
- 成功结果存储格式:
(参数值, 返回结果) - 失败结果存储格式:
(参数值, 错误信息) - 自动捕获所有异常类型(第31-32行)
- 成功结果存储格式:
我们再微调一下整体程序,为了保证能够随时调用任何一个函数,我们将函数作为参数传入:
为了方便测试,我们加入了休眠2秒和打印时间两个逻辑: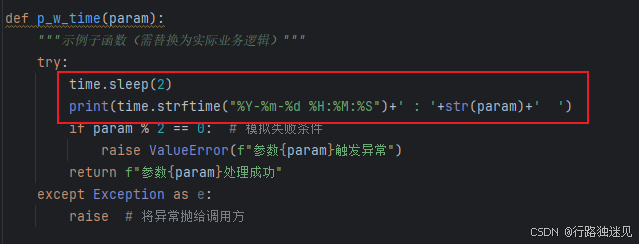
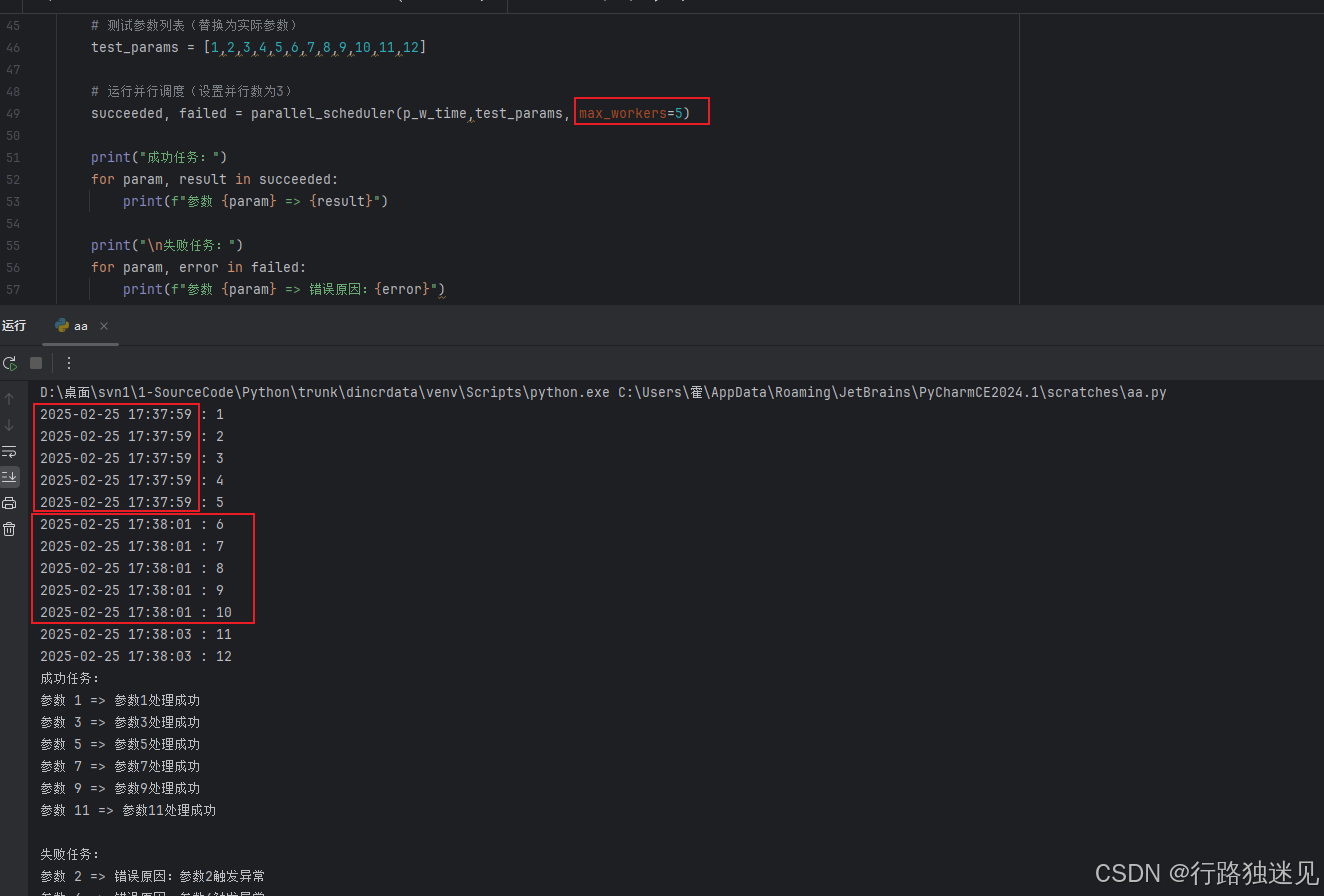
这里选择了5个的并行度,看时间打印时间也是每5个的时间是相同的,符合我们的规则1,
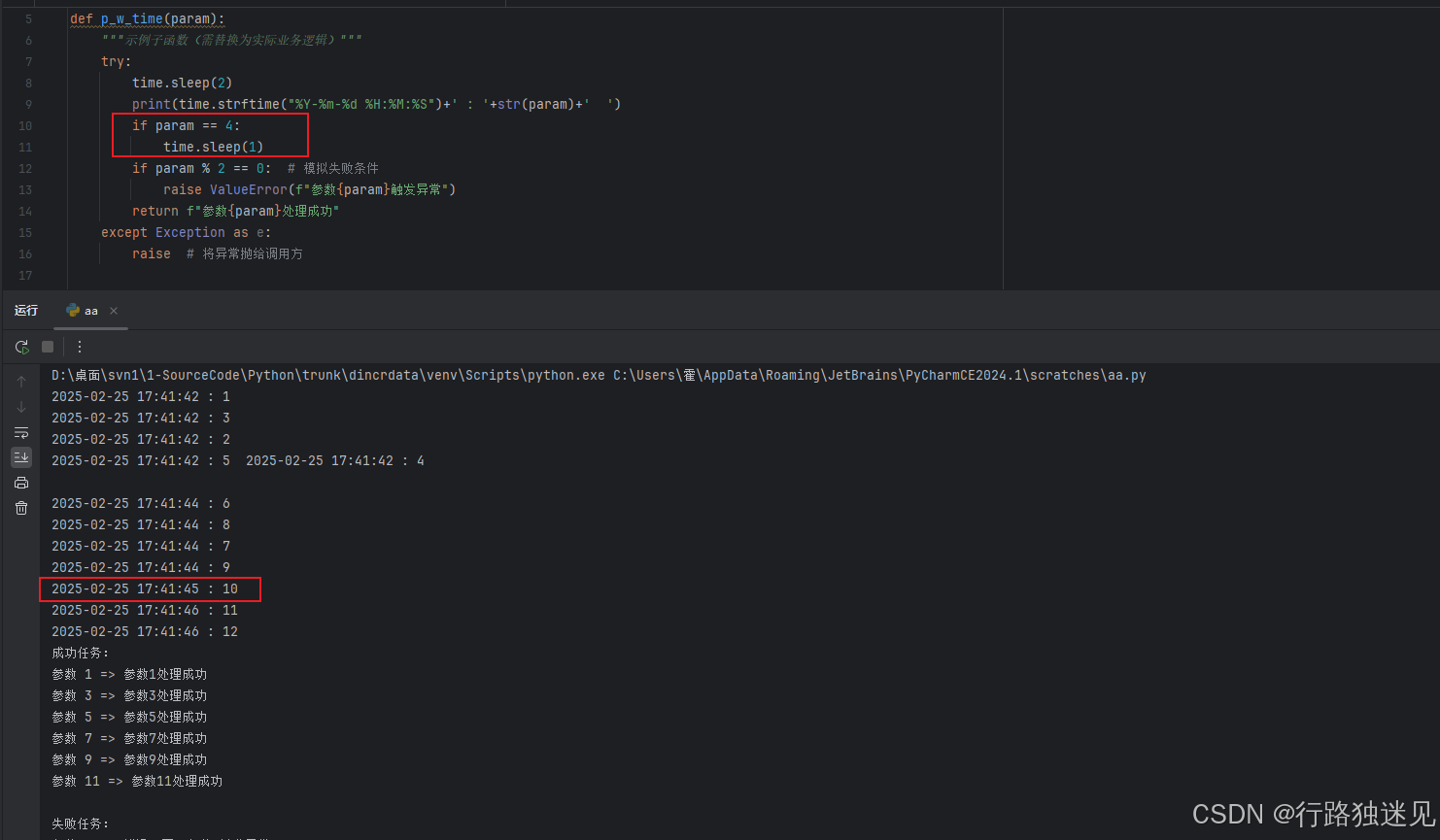
为了方便测试规则2,这里让某一个进程等待1秒,符合一个程序执行成功之后,再执行下一个:
返回参数在确认之后也没有问题:
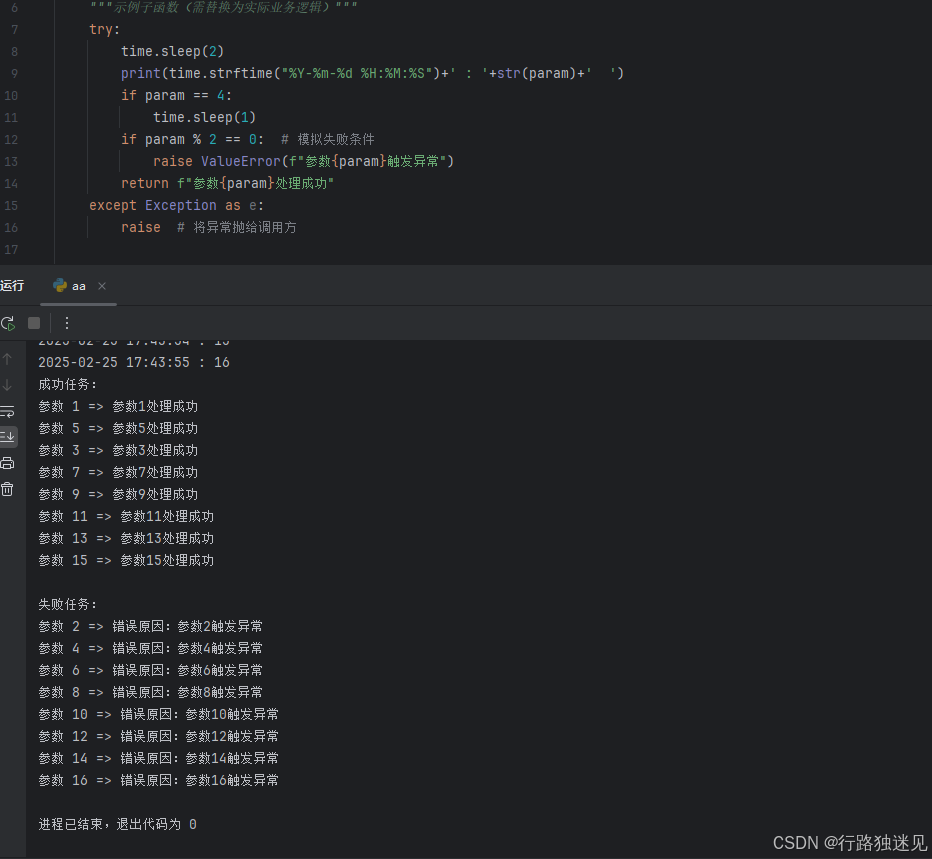
这样一个完整的程序通过deepseek就写完了,下面附上源码和一些deepseek指令性学习的连接:
from concurrent.futures import ThreadPoolExecutor, as_completed
import traceback
import time
def p_w_time(param):
"""示例子函数(需替换为实际业务逻辑)"""
try:
time.sleep(2)
print(time.strftime("%Y-%m-%d %H:%M:%S")+' : '+str(param)+' ')
if param == 4:
time.sleep(1)
if param % 2 == 0: # 模拟失败条件
raise ValueError(f"参数{param}触发异常")
return f"参数{param}处理成功"
except Exception as e:
raise # 将异常抛给调用方
def parallel_scheduler(func,params_list, max_workers=4):
"""
并行调度器
:param params_list: 参数列表,每个元素会传给p_w_time
:param max_workers: 最大并行数量
:return: (成功列表, 失败列表)
"""
success = []
failure = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 创建任务映射字典 {future: 参数}
future_to_param = {executor.submit(func, param): param for param in params_list}
# 按完成顺序处理结果
for future in as_completed(future_to_param):
param = future_to_param[future]
try:
result = future.result()
success.append((param, result))
except Exception as e:
failure.append((param, str(e)))
return success, failure
# 使用示例
if __name__ == "__main__":
# 测试参数列表(替换为实际参数)
test_params = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]
# 运行并行调度(设置并行数为3)
succeeded, failed = parallel_scheduler(p_w_time,test_params, max_workers=5)
print("成功任务:")
for param, result in succeeded:
print(f"参数 {param} => {result}")
print("\n失败任务:")
for param, error in failed:
print(f"参数 {param} => 错误原因:{error}")《DeepSeek赋能职场》完整手册包含:
12类职场场景详细操作指南
CO-STAR/RGTO双框架提示词模板库
50+商业实战案例分析
清华大学团队独家研发笔记
复制
/~176c35uAND~:/
链接:https://pan.quark.cn/s/d7b092de1e38
复制整段内容,打开最新版「夸克APP」即可在线阅览,支持5倍速高清播放与电视投屏

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)