Deepseek R1模型本地部署(ollama+cherry studio)、调用硅基流动Deepseek api详细指南(适用于Windows系统)
一、Deepseek R1 模型本地部署
1、本地部署使用到的工具和步骤
(1)工具
(2)步骤
- 使用Ollama安装DeepSeek-R1模型
- 使用Cherry Studio客户端进行模型配置
2、Ollama安装
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。 Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
(1)下载Ollama
官网链接:https://ollama.com/download/
默认为当前电脑的对应的版本,直接下载即可。下载以后,一路安装即可。
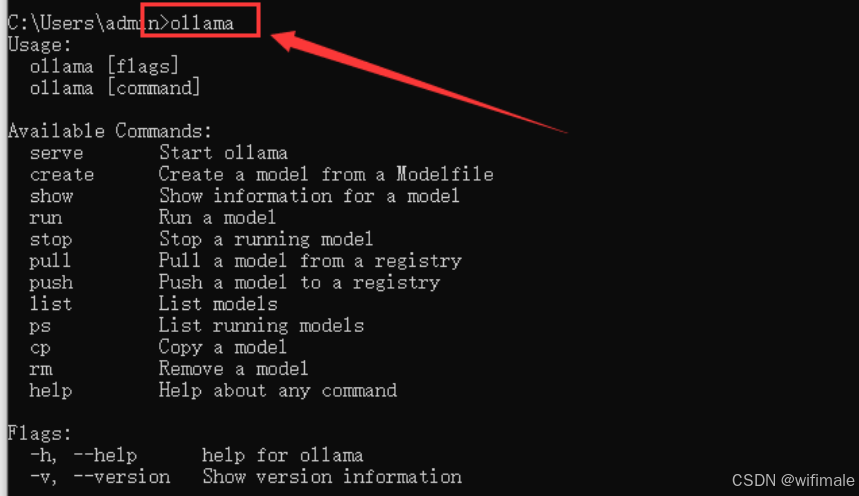
(2)验证Ollama安装成功
打开命令行,输入ollama,如果有回显表示安装成功
3、安装DeepSeek模型
(1)通过Ollama安装模型, 首先打开deepseek-r1的模型安装界面
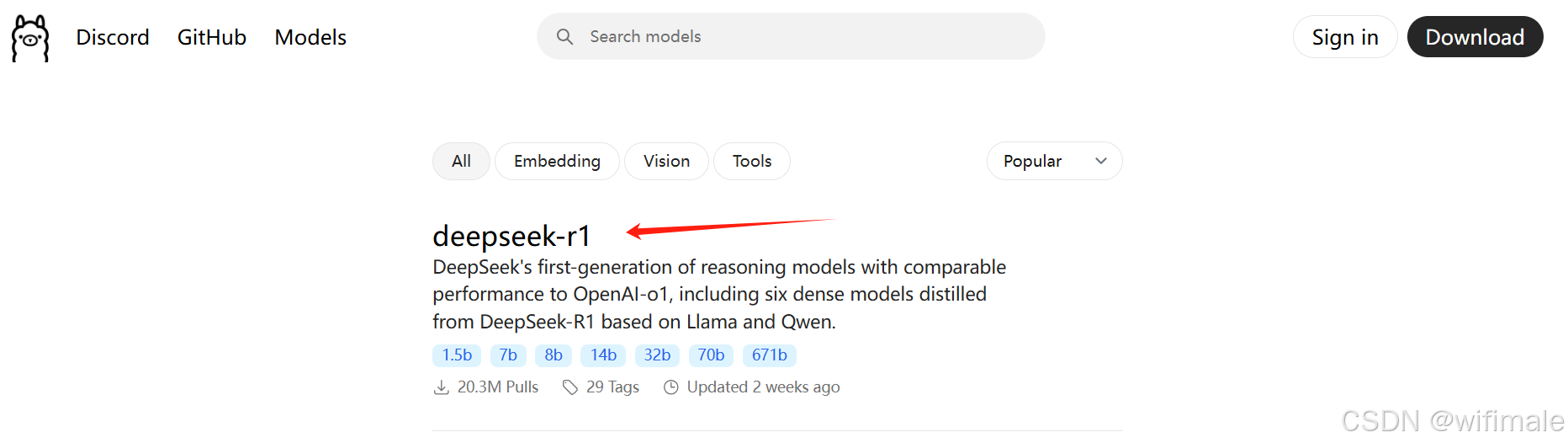
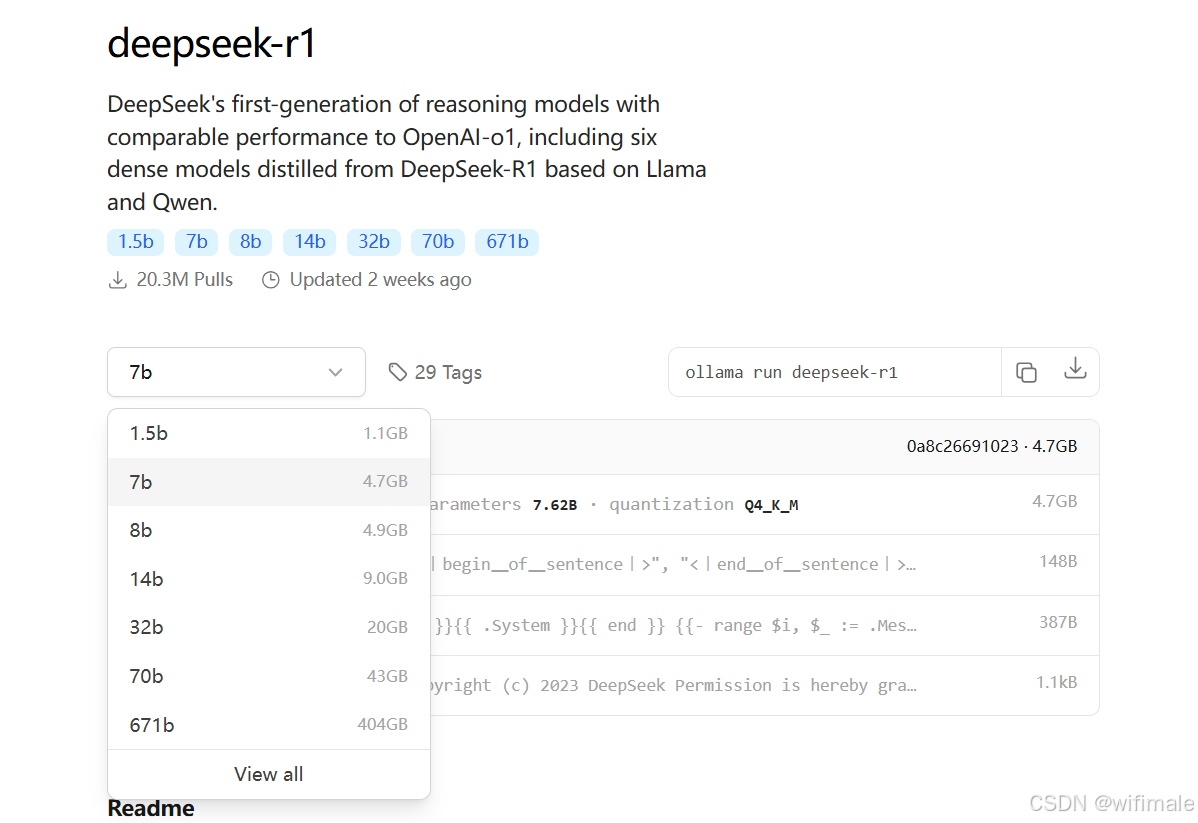
(2)DeepSeek-R1 模型选择建议
根据Deepseek搜索结果整理,以下是 DeepSeek-R1 本地部署模型的版本选择建议表格,综合硬件要求与适用场景:
| 模型规模 | 最低配置要求 | 推荐配置要求 | 备注 |
|---|---|---|---|
| 1.5B | CPU:4核x86/ARMv9 内存:8GB 存储:3.2GB |
CPU:AMD Zen4/Intel 13代酷睿 内存:16GB 显卡:RTX 3050 (可选) |
适用于智能家电控制、工业传感器文本预处理等轻量级任务25 |
| 7B | CPU:8核Zen4/13代酷睿 内存:16GB 显卡:RTX 3060 (12GB显存) 存储:8GB |
CPU:16核以上 内存:32GB 显卡:RTX 4070 Ti Super (16GB显存) |
支持本地知识库问答、代码补全,建议搭配 FP8/INT8 量化加速26 |
| 8B | 同7B配置,显存需求提高10-20% | 推荐增加至 RTX 3080 (10GB显存) | 适合代码生成、逻辑推理等需更高精度的任务78 |
| 14B | CPU:16核至强W7 内存:48GB 显卡:RTX 4090 (24GB显存) 存储:15GB |
双路CPU服务器 内存:64GB 显卡:A5000 (24GB显存) |
企业级文档分析、多轮对话系统,需启用 ZeRO-3 显存优化25 |
| 32B | CPU:32核EPYC 内存:128GB 显卡:双RTX 3090 (48GB显存) 存储:30GB |
服务器级硬件 显卡:A100 (80GB显存) |
医疗诊断、法律咨询等高精度领域,需 PCIe 5.0 NVMe SSD56 |
| 70B | CPU:双路EPYC 9654 内存:256GB 显卡:8xRTX 5090 (256GB显存) 存储:70GB |
多节点分布式集群 显卡:H100 (NVLink互联) |
科研计算、金融建模,建议云部署45 |
| 671B | 64核EPYC集群 内存:512GB 显卡:8xH100 (640GB显存) 存储:300GB |
超算中心级设施 InfiniBand 高速互联 |
国家级AI研究、AGI探索,需专业散热和1000W+电源 |
(3)安装Deepseek模型
在Ollama官网,选择不同的模型,复制安装命令。例如选择1.5B
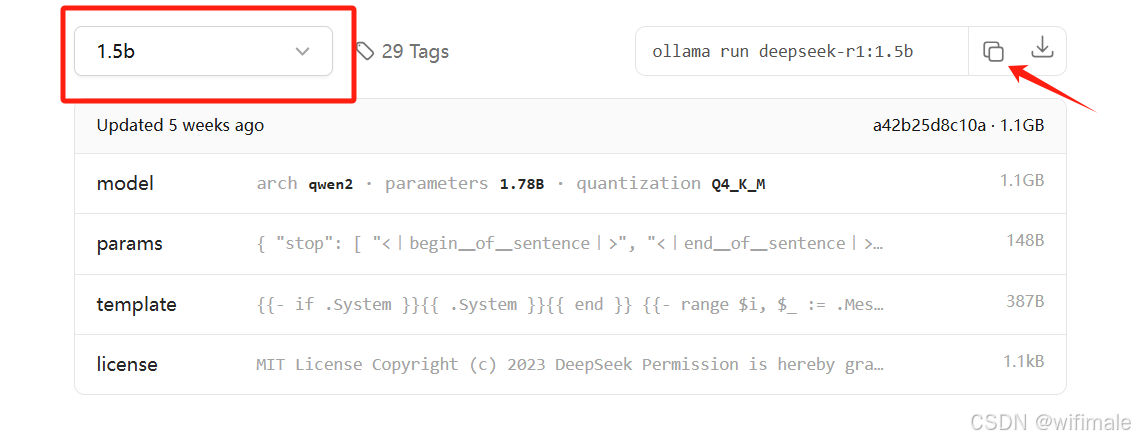
(4)打开cmd,在cmd界面执行命令
# 下载或运行模型,正常ollama不会运行模型的
ollama run deepseek-r1:1.5b

代码执行后完成后,会自动进入到deepseek 1.5B模型的对话聊天框,但是因为界面不美观、以及无法上传附件等,所以使用Cherry Studio软件一起使用。
4、基于Cherry Studio搭建Web UI使用Deepseek
Cherry Studio 是一款支持多模型服务的桌面客户端,内置了超过 30 个行业的智能助手,旨在帮助用户在多种场景下提升工作效率。它适用于 Windows、Mac 和 Linux 系统,无需复杂设置即可使用。
Cherry Studio 集成了主流的 LLM 云服务和 AI Web 服务,同时支持本地模型运行。
Cherry Studio 提供了诸如完整的 Markdown 渲染、智能体创建、翻译功能、文件上传和多模态对话等个性化功能,并具有友好的界面设计和灵活的主题选项,旨在为用户提供全面而高效的 AI 交互体验。
(1)下载cherry studio,并安装
(2)本地模型配置
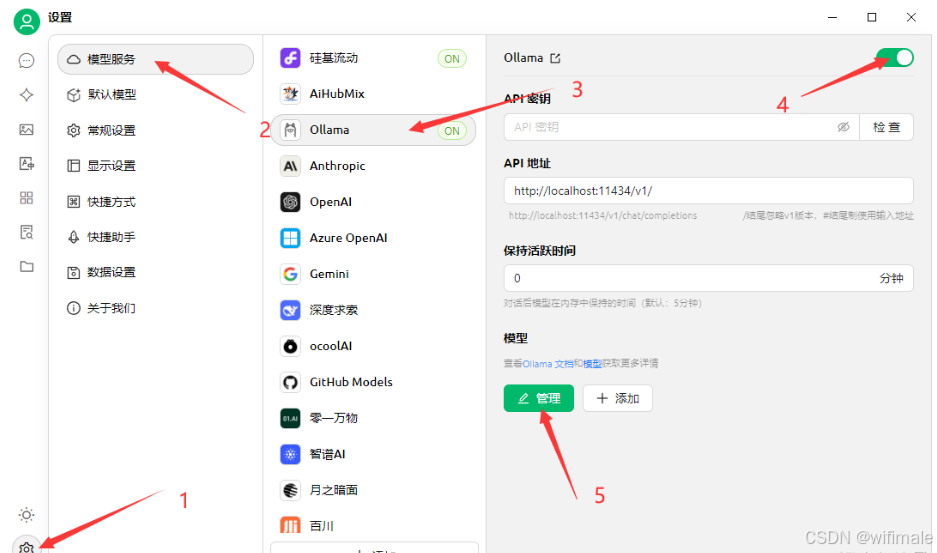
(3)添加下载的Deepseek模型,例如添加了8B 的Deepseek模型
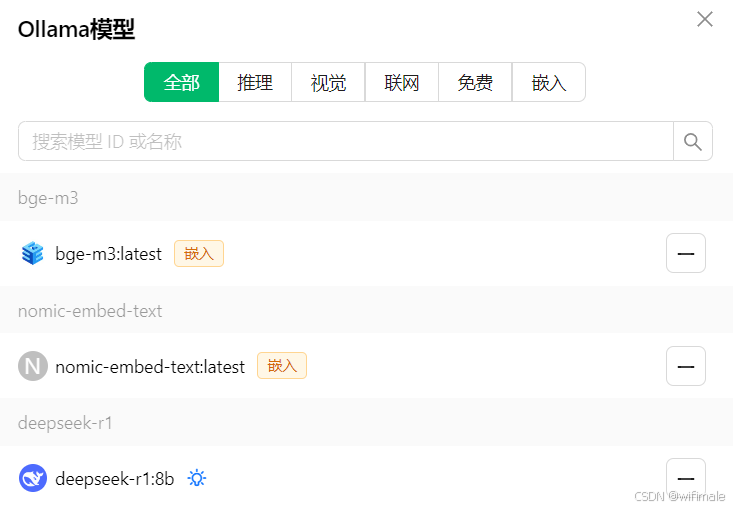
添加完成后,回到对话框位置
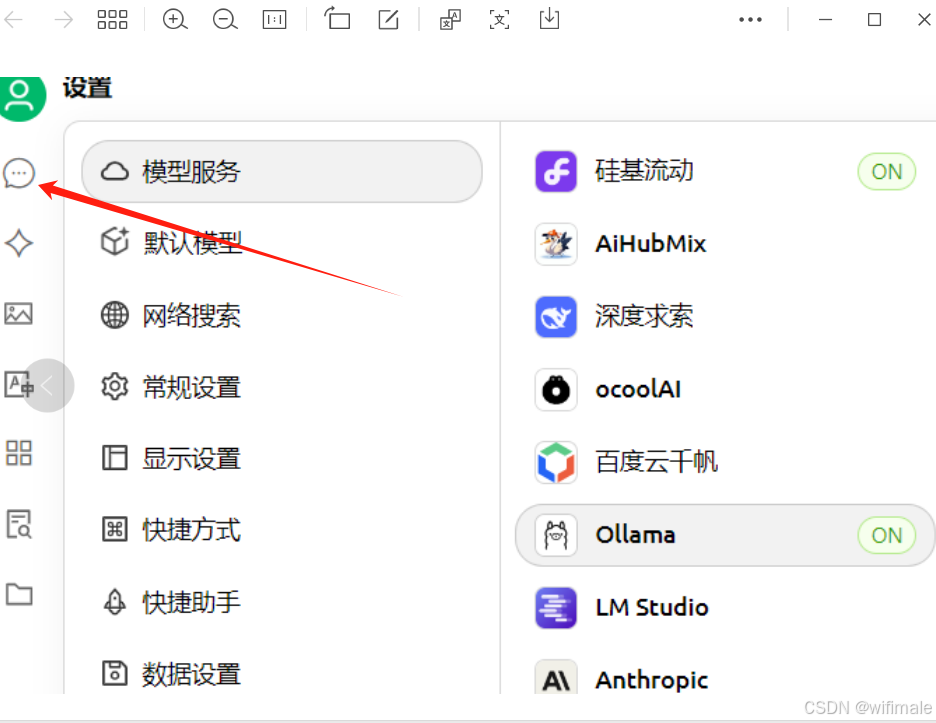
(4)选择Ollama的deepseek模型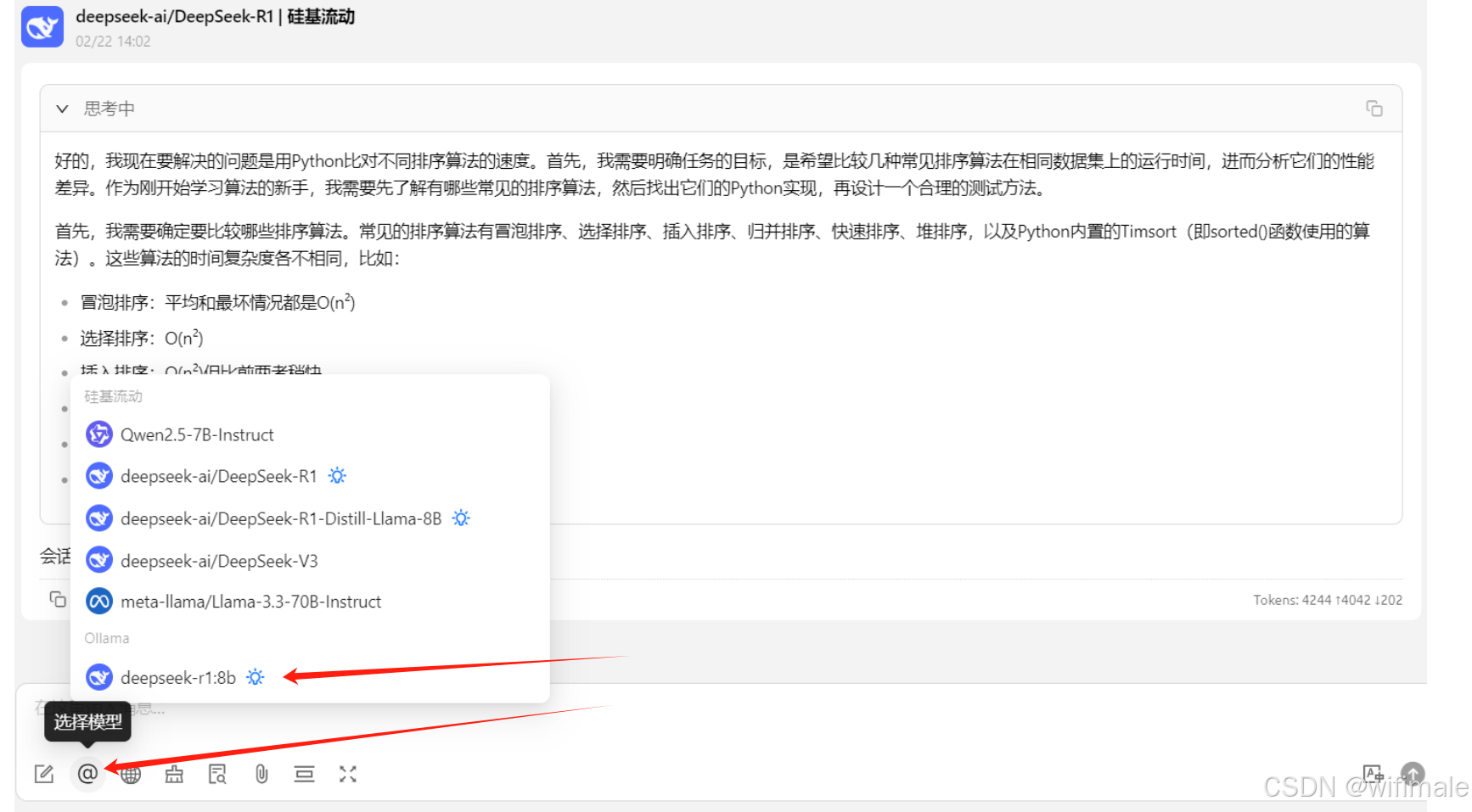
开启对话即可。因本地部署需要依赖于笔记本电脑的内存、gpu等性能指标,所以吃性能有时候性能不足时反馈会慢一点。采用后一个方法,调用api的方法有时候会相对快一点。
(5)番外篇:本地部署数据会保密,可以在本地传入知识库
可以先在本地cmd,执行安装命令:ollama run bge-m3:latest
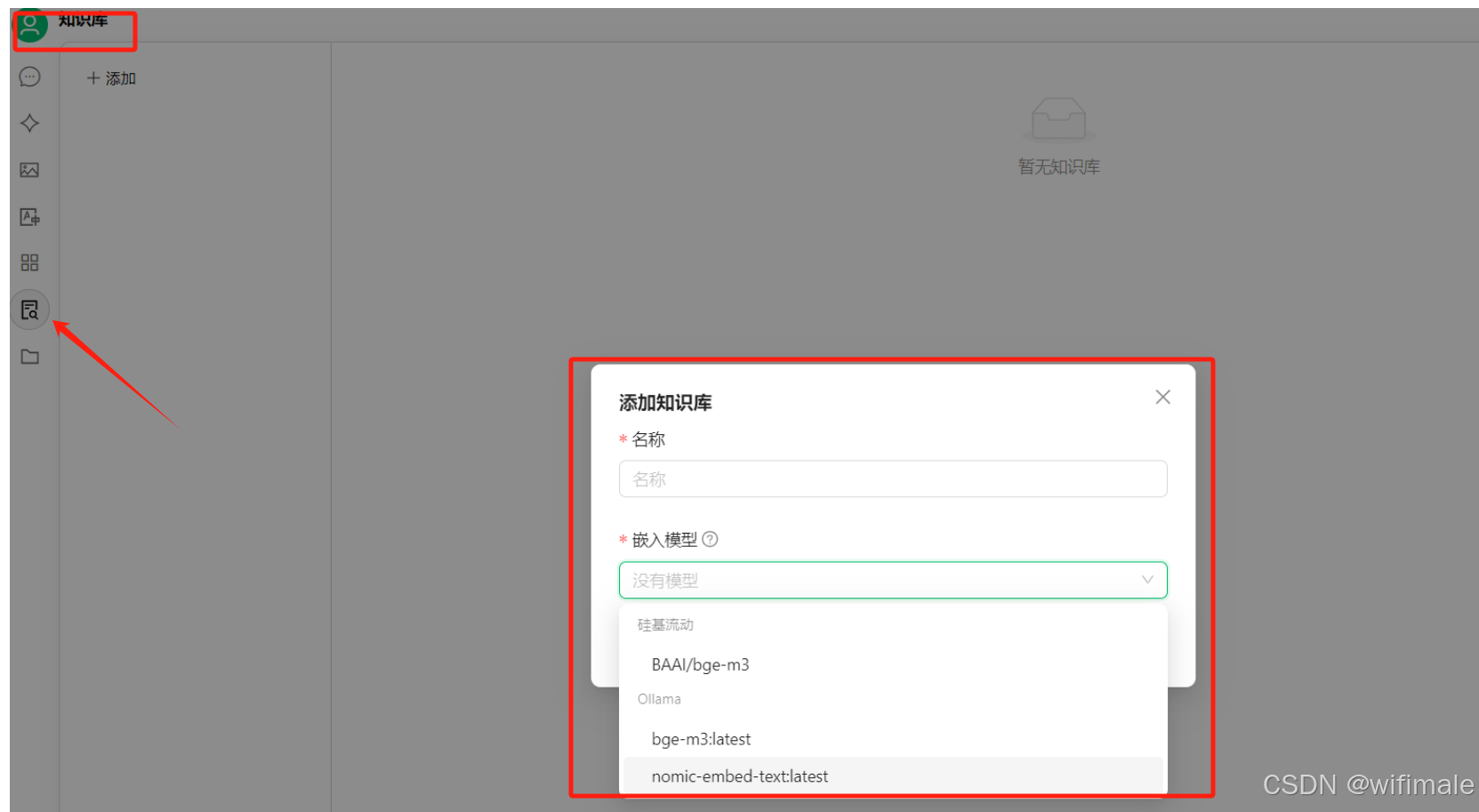
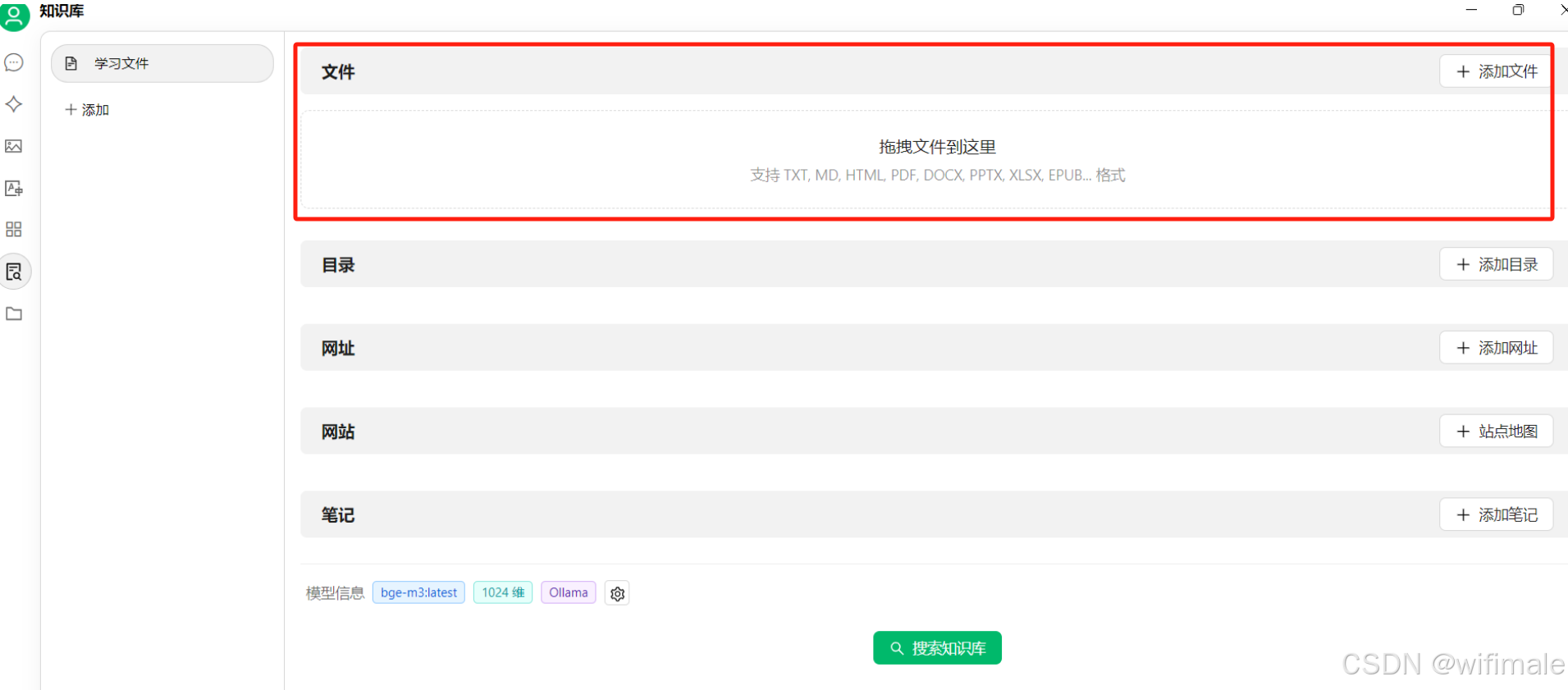
二、调用硅基流动Deepseek api
1、注册硅基流动
注册成功后有14元的赠送,tokens可以使用很多,欢迎使用我的邀请码:t5WcWnAd
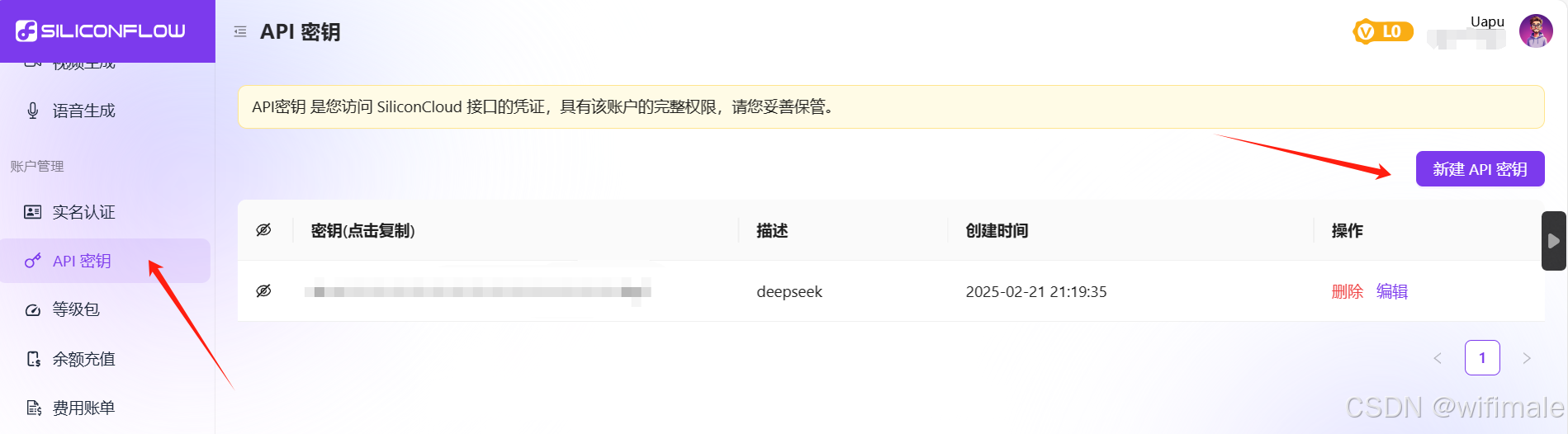
2、新建API密钥
3、cherry studio配置硅基流动的配置
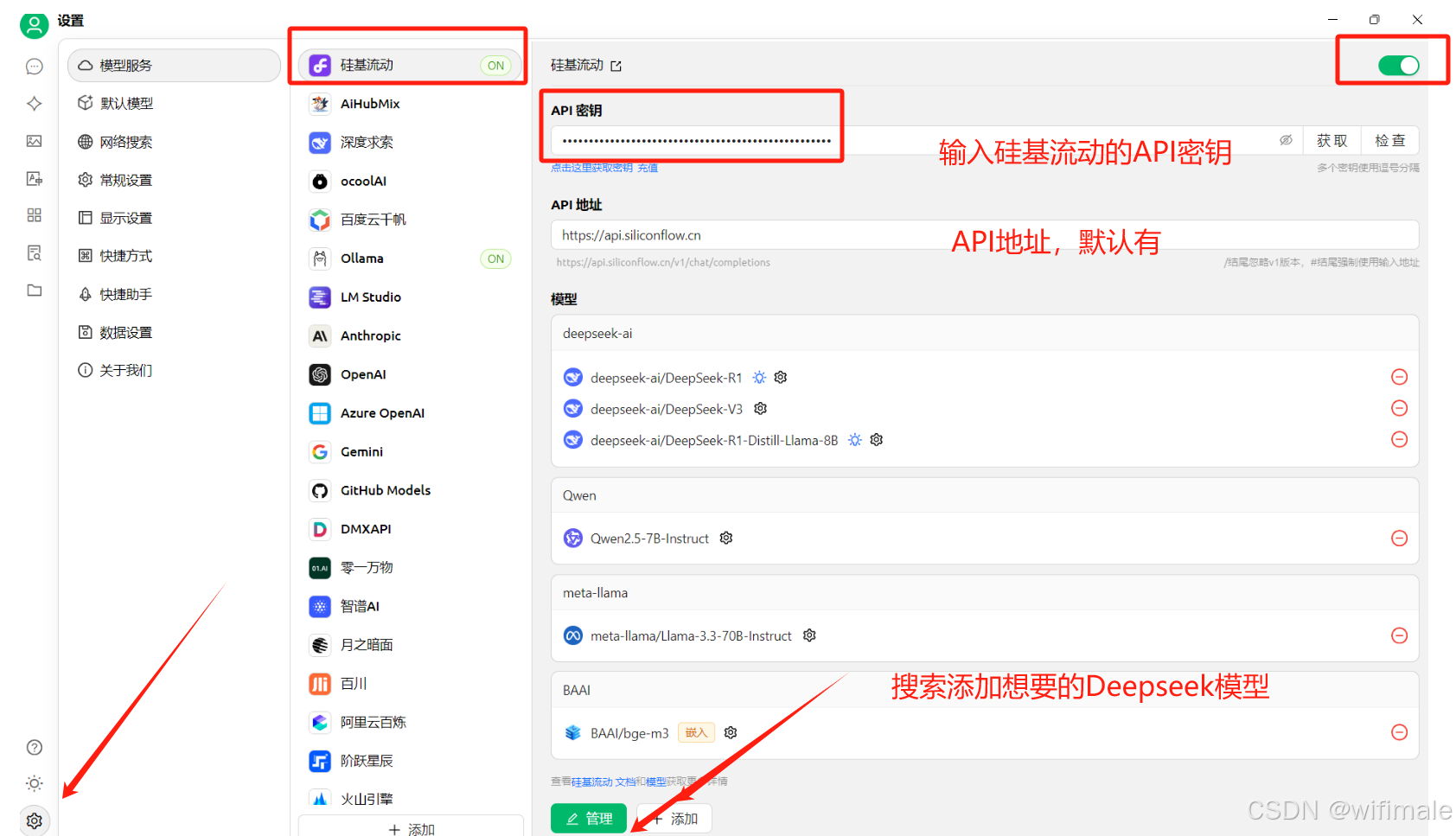
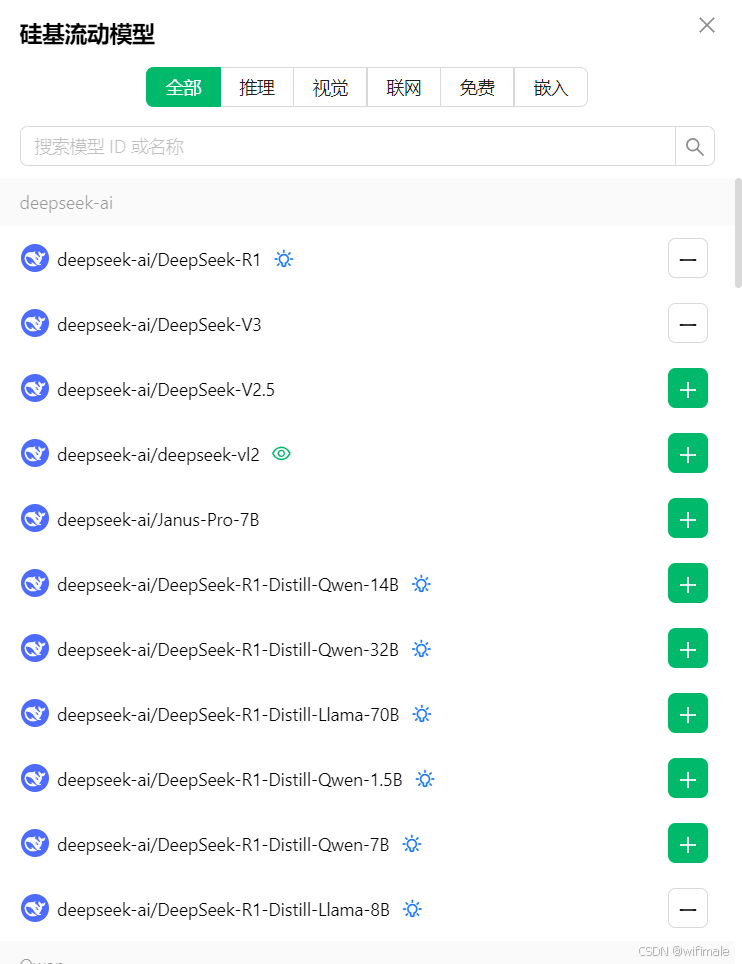
4、选择对应硅基流动中的deepseek模型
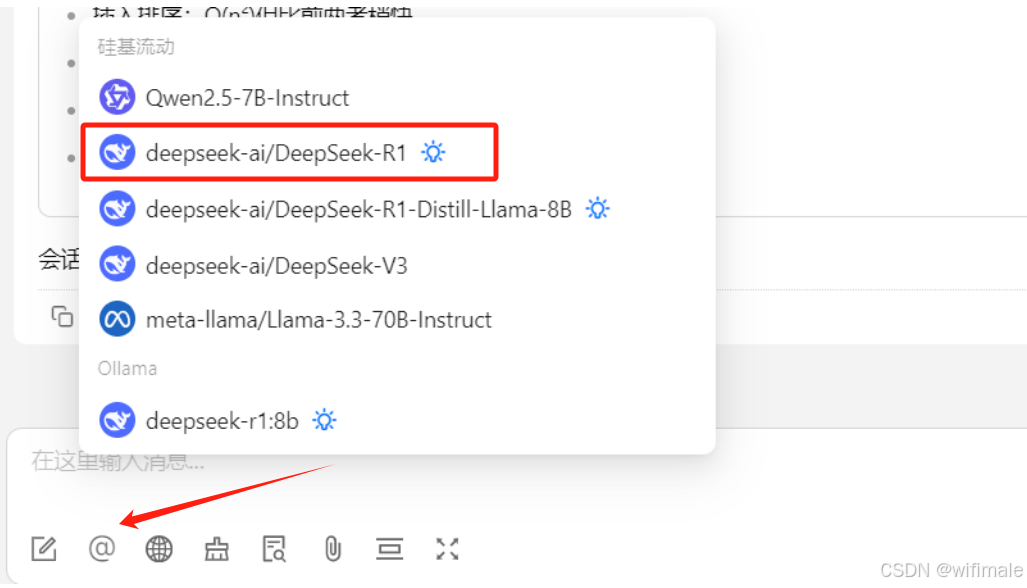
即可开启使用

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)