本地DeepSeek大模型:从搭建到Java应用,一站式开发指南!
最近,大型语言模型(LLM)的热度持续攀升,各种令人惊艳的应用层出不穷。相信不少开发者和企业都跃跃欲试,希望将大模型的能力融入到自己的产品和服务中。然而,高昂的API调用成本、数据安全顾虑以及网络延迟等问题,常常让大家望而却步。
最近,大型语言模型(LLM)的热度持续攀升,各种令人惊艳的应用层出不穷。相信不少开发者和企业都跃跃欲试,希望将大模型的能力融入到自己的产品和服务中。然而,高昂的API调用成本、数据安全顾虑以及网络延迟等问题,常常让大家望而却步。 别担心,今天我们就来聊聊如何将强大的 DeepSeek大模型 搬到本地,并借助 SpringAI框架 ,用 Java 轻松驱动,让大模型真正触手可及。
从环境准备到代码实战,本地DeepSeek模型全攻略
1. DeepSeek模型本地搭建:让AI能力近在咫尺
首先,我们要解决的是大模型的本地部署问题。DeepSeek模型以其卓越的性能和开源友好的态度,成为了本地化部署的理想选择。那么,如何才能顺利地在本地搭建起DeepSeek模型呢?
1.1 认识DeepSeek模型:强大且全面的AI助手
DeepSeek大模型,正如其名,以“深度探索”为目标,在自然语言处理领域展现出强大的实力。它不仅能理解和生成流畅自然的文本,还能胜任代码编写、知识问答、创意写作等多种任务。其核心优势在于:
-
卓越的性能:DeepSeek模型在多个评测基准上都表现出色,展现了强大的语言理解和生成能力。
-
多模态支持:不仅限于文本,DeepSeek模型也在图像识别、语音处理等领域有所涉猎,展现了全面的AI能力。
-
丰富的预训练模型:官方提供了多种预训练模型,方便开发者根据不同场景快速选择和应用。
-
良好的扩展性和兼容性:易于集成到现有系统中,支持多种部署方式,为本地化部署提供了便利。
这些特性使得DeepSeek模型成为企业和开发者进行本地AI应用开发的有力工具。
1.2 环境准备:工欲善其事,必先利其器
在开始搭建之前,我们需要做好充分的环境准备。就像盖房子打地基一样,一个稳定高效的运行环境是成功部署DeepSeek模型的关键。
-
硬件设备:
-
GPU: 强烈建议配备高性能GPU,例如 NVIDIA Tesla V100 或更高型号。GPU是加速模型推理的核心,直接影响模型的运行速度。
-
内存: 至少 64GB 内存,更大的内存能确保模型和数据能够顺利加载,避免内存溢出。
-
存储: 建议 500GB SSD 固态硬盘,高速的存储可以加快模型加载和数据读取速度。
-
操作系统:
-
推荐使用 Linux 发行版,例如 Ubuntu 20.04 LTS 。Linux系统对深度学习框架的支持和优化更完善,社区资源也更丰富。
-
软件环境:
-
Python: 确保安装 Python 3.8 或更高版本。Python是深度学习领域的主流编程语言。
-
CUDA 和 cuDNN: NVIDIA GPU 的驱动和加速库,用于支持GPU加速计算。版本需要与你的GPU和深度学习框架兼容。
-
Docker: 建议安装最新版本的 Docker 。Docker 可以帮助我们容器化部署 DeepSeek 模型,简化环境配置,提高部署效率。
-
开发工具: 例如 PyCharm 或 VSCode,以及版本控制工具 Git,方便代码编写和管理。
-
网络连接: 稳定的网络连接用于下载模型文件、依赖库和 Docker 镜像。
思考题: 你目前的环境是否满足上述要求?如果硬件资源有限,是否有降低模型规模或者采用模型量化等方案来降低硬件需求?
1.3 本地搭建详细步骤:一步一步,轻松搞定
环境准备就绪,我们就可以开始正式搭建 DeepSeek 模型了。这里,我们以使用 Docker 容器部署为例,因为它能极大地简化部署过程。
- 获取源码和预训练模型:
-
访问 DeepSeek 官方 GitHub 仓库,克隆项目源代码。
-
根据你的需求,下载合适的预训练模型。DeepSeek 提供了多种模型选择,例如文本生成、代码模型等。
-
将下载的预训练模型文件放置在项目指定的目录下,通常会在文档中说明。
- 配置环境变量:
-
CUDA_VISIBLE_DEVICES: 指定使用的 GPU 编号,例如0表示使用第一块 GPU。 -
MODEL_PATH: 预训练模型文件的存放路径。 -
进入项目根目录,找到并编辑
.env文件。 -
根据你的实际环境配置环境变量,例如:
-
确保所有配置项都根据你的环境进行了正确设置。
- 启动 Docker 容器:
-
确保你已经安装了 Docker Compose 工具。
-
在项目根目录下,检查
docker-compose.yml文件,确认端口映射等配置是否符合你的需求。 -
执行命令
docker-compose up -d即可在后台启动 DeepSeek 模型的 Docker 容器。
- 验证模型状态:
-
启动成功后,可以通过浏览器访问指定的端口(通常在
docker-compose.yml文件中配置,例如http://localhost:8501),查看 DeepSeek 模型的前端界面是否正常加载。 -
你也可以使用 Postman 等 API 测试工具,向模型的 API 接口发送请求,验证模型是否正常工作。
- 性能优化(可选):
-
根据你的应用场景和硬件资源,可以调整模型的推理参数,例如
batch size、max sequence length等,以达到最佳性能。 -
如果资源有限,可以尝试减小
batch size来降低显存占用。
代码示例:Docker Compose 文件 (docker-compose.yml 示例)
version: "3.9"
services:
deepseek-model:
image: deepseek/deepseek-llm # 镜像名称,请参考官方文档
ports:
- "8501:8501" # 将容器的 8501 端口映射到主机的 8501 端口
environment:
- CUDA_VISIBLE_DEVICES=0
- MODEL_PATH=/path/to/your/pretrained/model # 替换为你的模型路径
volumes:
- ./models:/path/to/your/pretrained/model # 将主机模型目录挂载到容器
注意: 上述 docker-compose.yml 文件仅为示例,具体的镜像名称、端口配置和模型路径需要根据 DeepSeek 官方文档进行调整。
1.4 常见问题与解决方案:扫除障碍,一路畅通
在本地搭建过程中,可能会遇到一些问题。别担心,这里我们总结了一些常见问题和解决方案,帮助你快速排除故障。
-
Docker 容器无法启动:
-
使用
docker-compose logs命令查看日志,排查具体错误信息。 -
检查依赖服务是否正常启动,例如 GPU 驱动、CUDA 等。
-
确认 Docker 镜像是否已正确拉取,必要时重新构建镜像。
-
模型加载失败 (“Model not found” 等错误):
-
检查
.env文件中的MODEL_PATH环境变量是否配置正确,路径是否指向预训练模型文件。 -
确认预训练模型文件是否完整,尝试重新下载。
-
性能瓶颈明显 (推理速度慢、显存占用高):
-
调整模型推理参数,例如降低
batch size和max sequence length。 -
升级硬件设备,例如增加 GPU 数量、扩大内存容量。
-
考虑使用模型量化、剪枝等技术来优化模型性能。
-
API 调用异常 (使用 SpringAI 框架调用 API 时):
-
仔细阅读 DeepSeek 模型 API 文档,确认请求格式、参数是否正确。
-
检查 Java 项目中是否已正确引入 SpringAI 和相关依赖库。
-
使用 Postman 等工具模拟 API 请求,逐步定位问题。
温馨提示: 遇到问题时,善用日志信息,仔细检查配置,耐心排查,相信问题总能迎刃而解。
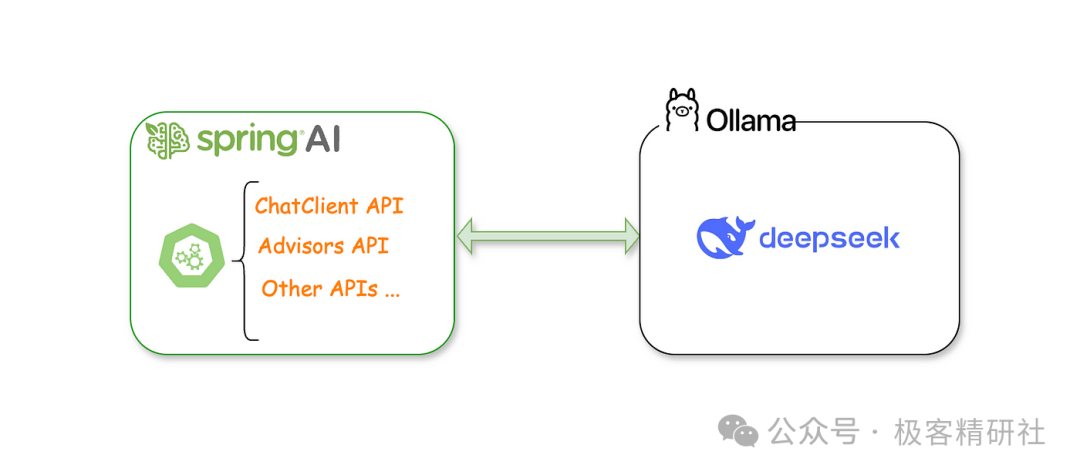
2. SpringAI 框架集成:Java 应用的AI引擎
成功搭建本地 DeepSeek 模型后,下一步就是将其集成到我们的 Java 应用中。 SpringAI框架 的出现,让这一过程变得异常轻松和高效。
2.1 SpringAI 框架简介:Spring Boot 的AI翅膀
SpringAI 是一个基于 Spring Boot 的扩展框架,旨在简化 AI 模型的集成和应用开发。它为开发者提供了以下便利:
-
无缝集成 Spring 生态: SpringAI 继承了 Spring Boot 的优点,例如依赖注入、自动配置等,可以轻松地与现有的 Spring 应用集成。
-
简化模型调用: SpringAI 抽象了底层模型 API 的复杂性,提供了简洁易用的接口,方便开发者调用各种 AI 模型,包括 DeepSeek。
-
丰富的工具和插件: SpringAI 提供了模型管理、监控、性能优化等一系列工具和插件,帮助开发者更好地管理和维护 AI 应用。
-
开箱即用: SpringAI 提供了丰富的 starter 组件,可以快速集成各种 AI 模型和服务。
对于 Java 开发者来说,SpringAI 无疑是连接 AI 世界的桥梁,让我们可以更专注于业务逻辑的实现,而无需过多关注底层 AI 模型的细节。
2.2 配置 SpringAI 调用本地 DeepSeek API:搭桥铺路
要让 SpringAI 框架能够调用本地部署的 DeepSeek 模型 API,我们需要进行一些配置。
- 引入依赖库:
在pom.xml文件中添加 SpringAI 和相关依赖。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>最新版本号</version> <!-- 请替换为实际版本号 -->
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- 其他 SpringAI 相关依赖,例如 DeepSeek 的 starter (如果官方提供) -->
</dependencies>
注意: 请根据 SpringAI 官方文档,选择合适的版本号和 DeepSeek 相关依赖。目前 SpringAI 社区正在积极发展,对 DeepSeek 的支持也在不断完善中。
- 配置 API 接口:
在application.yml或application.properties文件中配置 DeepSeek API 的相关信息。
spring:
ai:
deepseek:
api-url: http://localhost:8501/api/v1/deepseek # DeepSeek API 地址,根据实际情况修改
timeout: 30000 # API 请求超时时间,单位毫秒
提示: api-url 需要根据你本地 DeepSeek 模型部署的实际地址进行修改。端口号和路径需要与 Docker Compose 文件中的配置保持一致。
- 创建客户端类:
创建一个 Java 类,用于封装调用 DeepSeek API 的逻辑。可以使用 Spring 提供的RestTemplate或WebClient发送 HTTP 请求。
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
@Component
public class DeepSeekClient {
@Value("${spring.ai.deepseek.api-url}")
private String apiUrl;
private final RestTemplate restTemplate = new RestTemplate();
private final ObjectMapper objectMapper = new ObjectMapper();
public String generateText(String prompt) throws Exception {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
// 构建请求体
java.util.Map<String, Object> requestBody = new java.util.HashMap<>();
requestBody.put("prompt", prompt);
String jsonInput = objectMapper.writeValueAsString(requestBody);
HttpEntity<String> entity = new HttpEntity<>(jsonInput, headers);
// 发送 POST 请求
ResponseEntity<String> response = restTemplate.postForEntity(apiUrl, entity, String.class);
// 处理响应结果
JsonNode rootNode = objectMapper.readTree(response.getBody());
return rootNode.get("generated_text").asText(); // 假设 API 返回 "generated_text" 字段
}
}
代码解释:
-
@Component: 将DeepSeekClient类声明为一个 Spring 组件,可以被 Spring 管理和注入。 -
@Value("${spring.ai.deepseek.api-url}"): 将配置文件中的spring.ai.deepseek.api-url属性值注入到apiUrl变量中。 -
generateText(String prompt)方法: -
构建 HTTP 请求头,设置
Content-Type为application/json。 -
构建请求体,将
prompt放入请求体中,并转换为 JSON 字符串。 -
使用
RestTemplate发送 POST 请求到 DeepSeek API。 -
解析 API 返回的 JSON 响应,提取生成的文本内容。
2.3 SpringAI 调用示例:文本生成,一触即发
有了客户端类,我们就可以在 Java 代码中轻松调用 DeepSeek 模型 API 了。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringAiDeepseekApplication implements CommandLineRunner {
@Autowired
private DeepSeekClient deepSeekClient;
public static void main(String[] args) {
SpringApplication.run(SpringAiDeepseekApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
String prompt = "请写一篇关于未来科技的文章";
String generatedText = deepSeekClient.generateText(prompt);
System.out.println("生成的文章:\n" + generatedText);
}
}
代码解释:
-
@SpringBootApplication: 标准的 Spring Boot 应用入口。 -
@Autowired private DeepSeekClient deepSeekClient;: 将之前创建的DeepSeekClient组件注入到SpringAiDeepseekApplication类中。 -
run方法: -
定义一个
prompt(提示语)。 -
调用
deepSeekClient.generateText(prompt)方法,获取 DeepSeek 模型生成的文本。 -
打印生成的文本内容。
运行 Spring Boot 应用,你将在控制台看到 DeepSeek 模型生成的关于未来科技的文章。
2.4 API 调用性能优化:更上一层楼
虽然 SpringAI 框架已经足够高效,但在实际应用中,我们仍然可以采取一些性能优化策略,进一步提升 API 调用的效率和稳定性。
-
批量处理请求:
对于需要处理大量请求的场景,可以将多个请求打包成一个批量请求发送给 DeepSeek API。这可以减少网络请求次数,降低服务器压力。 -
异步调用机制:
使用 Spring 的@Async注解或 Reactor 框架,将 API 调用改为异步执行。这样可以避免阻塞主线程,提高系统的吞吐量和响应速度。 -
缓存中间结果:
对于一些常用的 prompt 和模型输出结果,可以进行缓存。下次遇到相同的请求时,直接从缓存中返回结果,避免重复调用 API。 -
优化模型参数:
根据实际应用场景,调整 DeepSeek 模型的推理参数,例如batch size、max sequence length等,找到性能和资源消耗的最佳平衡点。
3. Java 直接调用 DeepSeek API:更灵活的选择
除了使用 SpringAI 框架,我们也可以直接使用 Java 代码调用 DeepSeek 模型 API。 这种方式更加灵活,可以更精细地控制 API 调用的细节。
3.1 Java 调用 API 基础知识:HTTP 请求的奥秘
Java 调用 DeepSeek 模型 API 的核心是发送 HTTP 请求并处理响应。 我们需要了解以下基础知识:
-
HTTP 协议: Hypertext Transfer Protocol,超文本传输协议,是互联网上应用最广泛的网络协议之一。API 调用通常使用 HTTP 协议进行通信。
-
HTTP 请求方法: 常用的有 GET、POST、PUT、DELETE 等。DeepSeek 模型 API 通常使用 POST 方法接收请求。
-
HTTP 请求头: Header,包含请求的元数据信息,例如
Content-Type(内容类型)、Authorization(认证信息) 等。 -
HTTP 请求体: Body,包含请求的具体数据,例如 API 参数、输入文本等。
-
HTTP 响应: 服务器返回的响应,包括状态码 (例如 200 表示成功, 404 表示未找到, 500 表示服务器错误) 、响应头和响应体。
-
JSON 数据格式: JavaScript Object Notation,一种轻量级的数据交换格式,API 接口通常使用 JSON 格式传输数据。
3.2 Java 调用 API 代码解析:手写 HTTP 请求
下面是一个使用 Java 原生代码 (不依赖 SpringAI) 调用 DeepSeek 模型 API 的示例。
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
import com.fasterxml.jackson.databind.ObjectMapper;
public class DeepSeekApiCall {
public static void main(String[] args) throws Exception {
String apiUrl = "http://localhost:8501/api/v1/deepseek"; // DeepSeek API 地址
String prompt = "请写一首关于春天的诗";
// 1. 构建请求体 (JSON 格式)
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("prompt", prompt);
ObjectMapper objectMapper = new ObjectMapper();
String jsonInput = objectMapper.writeValueAsString(requestBody);
// 2. 创建 HttpClient
HttpClient client = HttpClient.newHttpClient();
// 3. 构建 HttpRequest
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(apiUrl))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(jsonInput, StandardCharsets.UTF_8))
.build();
// 4. 发送请求并获取响应
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 5. 处理响应结果
if (response.statusCode() == 200) {
String responseBody = response.body();
JsonNode rootNode = objectMapper.readTree(responseBody);
String generatedText = rootNode.get("generated_text").asText();
System.out.println("生成的诗歌:\n" + generatedText);
} else {
System.out.println("API 调用失败,状态码: " + response.statusCode());
System.out.println("响应内容: " + response.body());
}
}
}
代码解释:
-
使用 Java 11 引入的
HttpClient发送 HTTP 请求。 -
HttpRequest.newBuilder()构建 HttpRequest 对象。 -
.uri(URI.create(apiUrl))设置 API 地址。 -
.header("Content-Type", "application/json")设置请求头。 -
.POST(HttpRequest.BodyPublishers.ofString(jsonInput, StandardCharsets.UTF_8))设置请求方法为 POST,并设置请求体为 JSON 字符串。 -
client.send(request, HttpResponse.BodyHandlers.ofString())发送请求并同步等待响应。 -
处理 HTTP 响应状态码,如果成功 (200),则解析 JSON 响应体,提取生成的文本。
3.3 Java 调用异常处理与调试技巧:排错指南
在 Java 调用 API 的过程中,可能会遇到各种异常。良好的异常处理机制和调试技巧至关重要。
-
网络连接异常: 例如
ConnectException、SocketTimeoutException。 -
解决方案: 检查网络连接是否正常,API 地址是否正确,防火墙是否阻止了请求。可以添加重试机制,处理 transient 的网络问题。
-
数据解析异常: 例如
JsonParseException。 -
解决方案: 检查 API 返回的 JSON 数据格式是否符合预期,代码中解析 JSON 的逻辑是否正确。
-
API 调用异常: 例如 HTTP 状态码非 200。
-
解决方案: 根据 HTTP 状态码和响应体中的错误信息,排查具体问题。例如 400 Bad Request 表示请求参数错误, 401 Unauthorized 表示认证失败, 500 Internal Server Error 表示服务器内部错误。
-
调试技巧:
-
日志记录: 使用 SLF4J 或 Logback 等日志框架,记录请求和响应信息,方便排查问题。
-
断点调试: 在 IDE 中设置断点,单步调试代码,查看变量值和程序执行流程。
-
抓包工具: 使用 Wireshark 或 Fiddler 等抓包工具,抓取网络请求和响应数据包,分析网络通信过程。
3.4 Java 调用安全性考虑:安全护航
在生产环境中,API 调用的安全性至关重要。我们需要考虑以下安全因素:
-
HTTPS 加密传输: 使用 HTTPS 协议进行 API 通信,防止数据在传输过程中被窃听或篡改。
-
API 密钥管理: 如果 DeepSeek API 需要 API 密钥进行认证,需要安全地管理 API 密钥,避免泄露。可以使用环境变量、密钥管理工具或 Vault 等安全存储 API 密钥。
-
输入验证和过滤: 对用户输入进行严格的验证和过滤,防止恶意输入注入攻击 (例如 SQL 注入、跨站脚本攻击)。
-
访问控制: 限制 API 访问权限,只允许授权用户或服务调用 API。
总结:本地AI,触手可及的未来
通过本文的详细介绍,相信你已经掌握了 DeepSeek 大模型的本地搭建方法,以及如何通过 SpringAI 框架和 Java 代码调用 DeepSeek API。 从环境准备到代码实战,我们一步一步地探索了本地 AI 应用开发的完整流程。
本地部署 DeepSeek 大模型,不仅能降低 API 调用成本,还能更好地保护数据隐私,并提供更低的延迟。 结合 SpringAI 框架,Java 开发者可以更便捷地将大模型能力融入到企业级应用中,构建更智能、更强大的系统。
实践建议:
-
从小规模开始: 先在本地环境搭建和测试 DeepSeek 模型,逐步扩大规模。
-
持续优化性能: 根据实际应用场景,不断优化模型参数和 API 调用策略,提升性能。
-
关注安全问题: 在生产环境中,务必重视 API 调用的安全性,采取必要的安全措施。
-
探索更多应用场景: DeepSeek 大模型拥有广泛的应用前景,例如智能客服、内容创作、代码生成等,积极探索更多应用场景,发挥大模型的价值。
开放性思考:
-
随着硬件成本的降低和模型压缩技术的进步,本地大模型部署是否会成为未来的主流趋势?
-
SpringAI 框架在简化 AI 应用开发方面还有哪些潜力可以挖掘?
-
如何更好地平衡本地部署的灵活性和云端服务的可扩展性?
希望这篇文章能帮助你迈出本地 AI 应用开发的第一步,开启你的 AI 探索之旅! 期待你在评论区分享你的实践经验和想法,让我们共同进步!
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献100条内容
已为社区贡献100条内容

所有评论(0)