
不会吧!不会吧!DeepSeek都火了,你还不理解注意力机制?
DeepSeek火了,同时带火的还有注意力机制。因为DeepSeek提出的多头潜在注意(MLA)机制通过低秩键值联合压缩,显著减少了显存消耗并提高了计算效率。本篇文章不讲MLA,先通俗讲解一下注意力机制的原理,回顾一下这个大模型(或者说Transformer)的核心思想,下一篇再来说MLA。
目录
写在前面
DeepSeek火了,同时带火的还有注意力机制。因为DeepSeek提出的多头潜在注意(MLA)机制通过低秩键值联合压缩,显著减少了显存消耗并提高了计算效率。本篇文章不讲MLA,先通俗讲解一下注意力机制的原理,回顾一下这个大模型(或者说Transformer)的核心思想,下一篇再来说MLA。
一、通俗理解Self-Attention
这里的注意力机制指得是Self-Attention,是Transformer提出的概念。举个例子解释Self-Attention的作用:比如我们看一篇文章,文章很长,但是中心思想可能集中在某几句话,所以这个时候最高效的理解文章含义的一个方式,就是把我们有限的注意力放在那些重要的几句话上,这就是Self-Attention。
比如现在有这么一段话“I ate an apple”,我希望AI可以去理解这段话,这里的核心就是每个单词,比如想理解“apple”这个单词,最简单的方法是翻一下词典,看看这个词是什么意思,很不幸的是我们翻完词典发现这个词有很多种不同的含义(比如apple可以是水果也可以是手机品牌),所以这个时候是不能确定这个词的真实含义的;这时更为精确的方式就是看他的上下文,通过分析上下文,我们才能对这个单词有一个更好的理解,这其实就是我们平时的阅读习惯。
现在我们假定对于每一个单词有一个特征向量,就像下面这样:
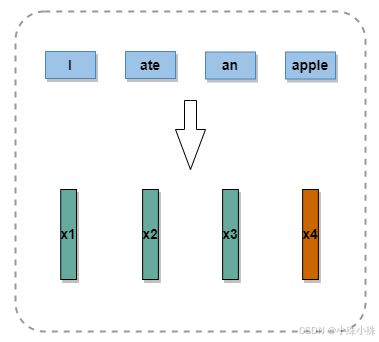
图1
下面为了更好的理解“apple”这个单词在整句话的含义,我们就要去看上下文,去看其它的单词对“apple”的理解影响有多大,当然也包括它自己的含义对自己的影响。然后我们需要量化每个词对“apple”含义的影响。自己对自己的影响肯定是最大的,比如是60%;看到“ate”这个词基本可以确定“apple”是水果,假设影响是20%;剩下两个词影响比较小,比如都是10%,就像下面这样:
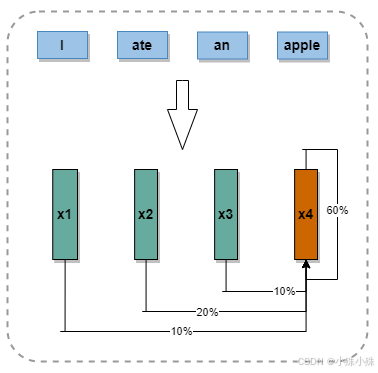
图2
这里的“影响”其实就是“注意力”,就是为了理解“apple”的含义,我需要把多少注意力放在“I”、“ate”、“an”和“apple”身上(以权重的形式表现),有了上下文的注意力权重,就可以做加权平均计算更新后的“apple”的特征向量,类似的句子中的所有单词都可以这样更新自己的特征向量,这个过程就叫做“Self Attention”。
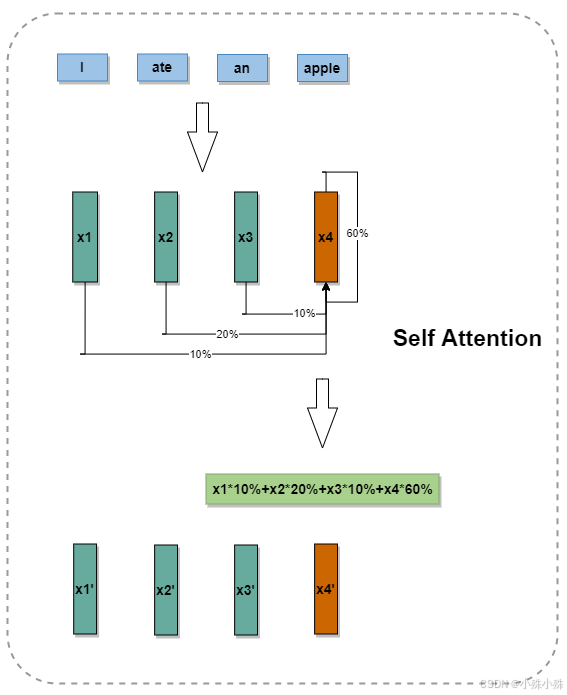
图3
值得一说的是,这里面的10%、20%、60%是通过训练有模型中的一些模块得出来的,细节的话不在这里讨论。
图(3)其实是第一层的向量更新,实际中还会有第二层、第三层甚至几十层的模块堆叠。所以整个的逻辑是,通过第一层可以学到每个单词在上下文中更好的含义(特征向量),然后后面的每一层都会进一步优化这个含义,直到最后一层,每个单词都会得到一个联系上下文的最佳的含义。
二、Self-Attention的工程实现
说完了原理,再简单说一下工程实现:
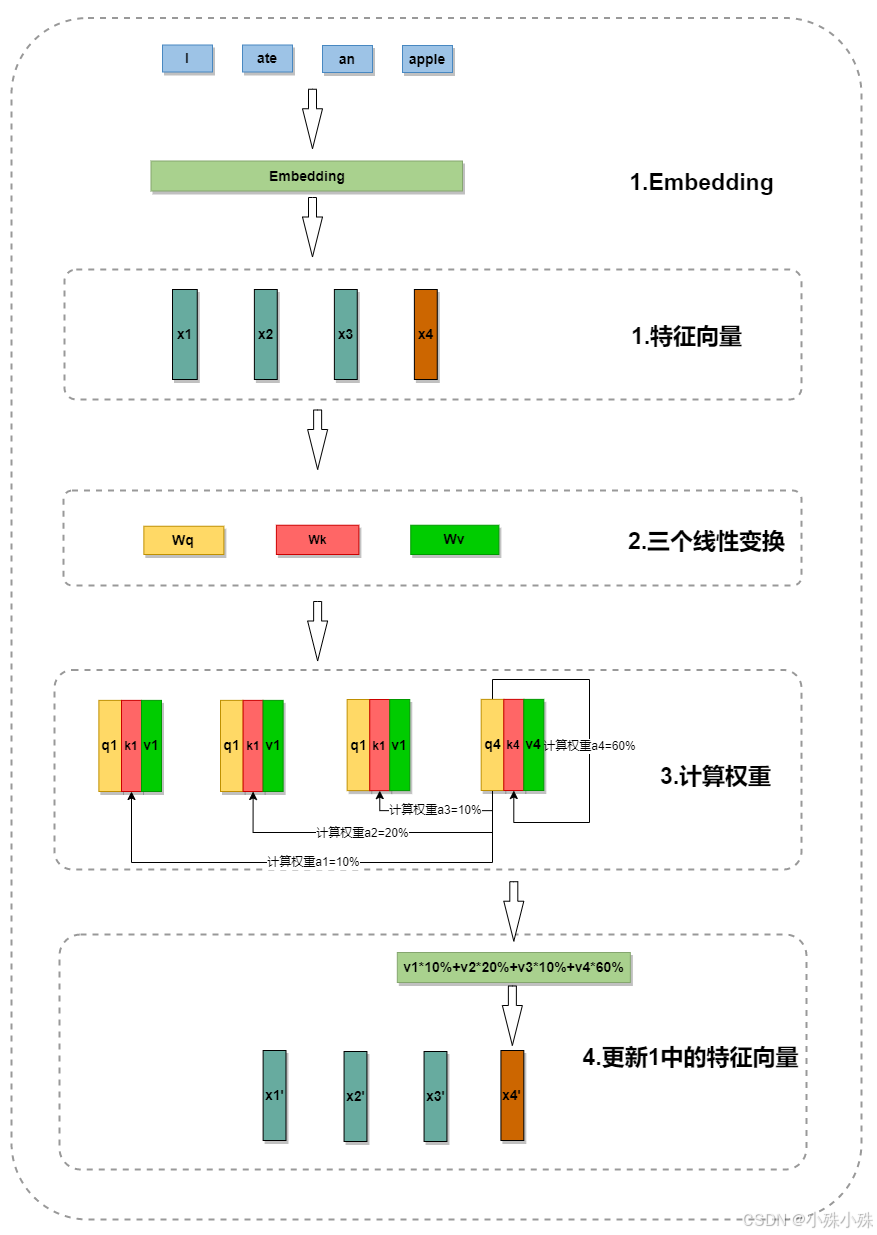
图4
如上图所示,整个实现流程如下:
1. Embedding
每个单词(如 I, ate, an, apple)都会经过Embedding得到一个特征向量,例如:
I 的特征向量:x1
ate 的特征向量:x2
an 的特征向量:x3
apple 的特征向量:x4
这些特征向量是后续生成 K/Q/V 的基础。
2.生成K/Q/V
通过 线性变换,每个单词的输入特征向量会生成对应的 Key(K)、Query(Q)、Value(V):
Query(Q):对应“要查询的目标”,例如 apple 的 Query 向量 q4 (用于理解 apple 的含义)。
Key(K):对应“被查询的上下文”,例如 I、ate、an、apple 的 Key 向量 k1/k2/k3/k4。
Value(V):对应“上下文的实际信息”,例如每个单词的 Value 向量 v1/v2/v3/v4。
数学公式:
![]()
其中 Wq,Wk,Wv 是可学习的权重矩阵。
3. 计算注意力权重
以理解 apple(第4个词)为例:
a.Query(Q):q4代表“我需要理解 apple 的含义”。
b.Key(K):所有词的 k1/k2/k3/k4代表“上下文中的哪些词对 apple 的理解有帮助”。
c.计算相似度:通过q4与每个 ki的点积,衡量 apple 与上下文中其他词的相关性:
d.归一化权重:通过 softmax 将相似度转换为注意力权重(即图中的 60%、20%、10% 等):
4.加权求和更新特征向量
a.Value(V):每个词的 vi携带了实际的信息(例如“ate 表示动作,an 是冠词”)。
b.加权求和:将注意力权重与对应的 Value 向量相乘并求和,得到 apple 的更新后特征向量:
c.与此同时以上方法还会计算每个词的特征向量,更新步骤1中的特征向量。
三、总结
1.注意力机制旨在让模型在处理序列数据(如句子)时,能够动态地关注到不同位置的重要信息。通过模拟人类的“注意力分配”过程,模型可以更高效地捕捉上下文依赖关系,提升对全局信息的理解能力。
2.核心组件:K/Q/V
Query:你想理解什么?(如“apple是什么?”)
Key:上下文中哪些词是线索?(如“ate提示是食物”)
Value:这些线索的具体含义是什么?(如“ate是动词”)
3.权重
每个词(如apple)拿着自己需要查询的意图(q4),去问其它词:“你能帮我多少?”(q1与每个词的Key点乘得到权重得到),然后根据权重(如“ate占比20%”)将每个词的“含义”加权求和得到自己(如apple)新的特征向量。
注意力机制通过 K/Q/V 的动态交互,让模型能够像人类一样,灵活地关注上下文中的重要信息。它是 Transformer 架构的核心,也是大语言模型(如 GPT、DeepSeek)实现高性能的关键技术之一。
注意力机制就简单介绍到这里,关注不迷路(*^▽^*)
还在为找工作烦恼吗,用这个宝藏小程序,拿Offer快人一步!Offer入口》》》

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)