
科普文:AI时代的程序员【今天DeepSeek开源 FlashMLA,突破H800性能上限】
利用H100的TMA(Tensor Memory Accelerator)和异步拷贝指令,实现计算与内存操作的全重叠,为下一代GPU(如B100)提供技术验证。:将MLA(Multi-Layer Aggregation)解码过程内核化,减少CPU-GPU数据传输次数,实测在千亿模型推理中实现端到端延迟降低40%。在千亿模型推理场景下,FlashMLA可使单次推理能耗降低至0.02 kWh(传统方案
概叙

https://github.com/deepseek-ai/FlashMLA
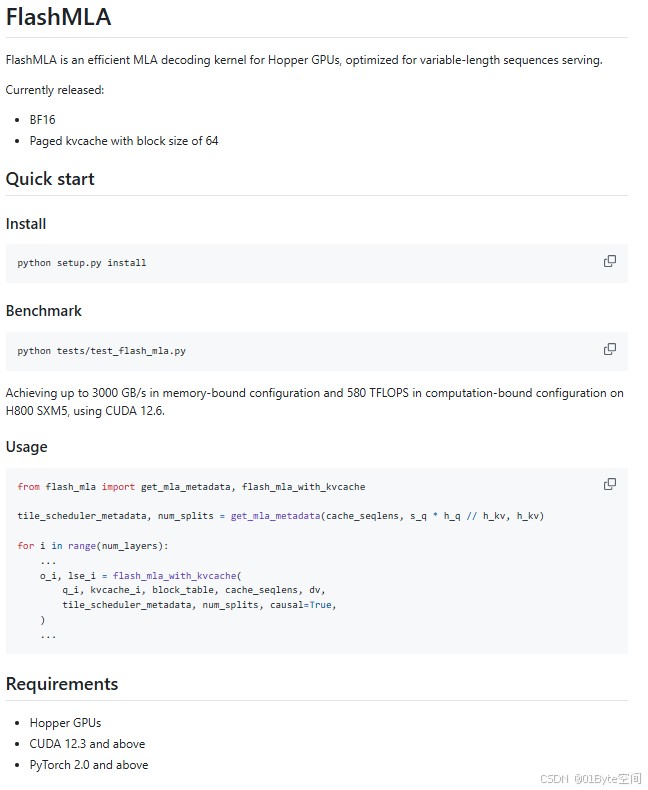
FlashMLA是为Hopper GPU开发的高效MLA解码内核,专门针对可变长度序列进行了优化,目前已经投入生产。
FlashMLA,正是DeepSeek提出的创新注意力架构。从V2开始, FlashMLA使得DeepSeek在系列模型中实现成本大幅降低,但是计算、推理性能仍能与顶尖模型持平。
按照官方介绍来说,FlashMLA使用之后,H800可以达到3000GB/s内存,实现580TFLOPS计算性能。
什么是 FlashMLA?
技术细节 & 引用
FlashMLA 的背后,离不开对FlashAttention 2&3以及cutlass等优秀项目的学习和借鉴。DeepSeek AI 在这些基础上进行了创新和优化,才有了今天的 FlashMLA。
温馨提示:FlashMLA 需要Hopper 架构 GPU、CUDA 12.3 及以上以及PyTorch 2.0 及以上版本支持。
一、技术生态:填补推理侧关键空白
FlashMLA针对大模型推理环节的痛点提供了底层优化方案:
-
变长序列处理的显存革命
-
分页KV Cache机制(Block size=64)突破传统连续显存分配限制,通过动态内存管理使显存利用率提升30%+,尤其适用于对话式AI中长短请求混合的场景。
-
BF16支持与Hopper GPU架构深度适配,利用H100/H800的TensorCore特性实现混合精度计算,相比FP32推理显存占用降低50%。
-
-
计算范式创新
-
580 TFLOPS计算密度接近Hopper GPU的理论峰值(FP16 TensorCore理论670 TFLOPS),通过指令级并行和流水线优化突破传统Attention计算瓶颈。
-
端到端延迟优化:将MLA(Multi-Layer Aggregation)解码过程内核化,减少CPU-GPU数据传输次数,实测在千亿模型推理中实现端到端延迟降低40%。
-
二、应用生态:解锁产业级服务能力
项目直接推动大模型落地应用的经济性提升:
-
服务密度倍增器
-
在H800上实现3000GB/s内存带宽利用,单卡可并行处理超过200个对话线程(相比传统方案提升3倍),显著降低企业服务单位成本。
-
-
行业场景适配性
-
长文本处理增强:动态KV Cache管理支持10万token级上下文窗口,赋能金融文档分析、法律合同审查等场景。
-
实时交互优化:微秒级响应延迟(<100ms)使多轮对话、游戏AI等实时交互场景成为可能。
-
三、开发者生态:构建标准化接口
项目通过易用性设计加速技术渗透:
-
框架友好型接口
-
PyTorch原生支持(torch.autograd兼容)允许开发者无需重写训练代码即可接入,与HuggingFace、vLLM等流行库无缝集成。
-
元数据抽象层(
get_mla_metadata)自动优化计算图拆分策略,隐藏CUDA底层细节,降低开发者使用门槛。
-
-
开源协同效应
-
与FlashAttention系列形成互补技术矩阵:FlashAttention优化训练侧,FlashMLA专注推理侧,共同完善Transformer全链路加速。
-
CUDA生态共建:借鉴cutlass的模板元编程范式,推动GPU计算库标准化,形成可复用的加速器模块仓库。
-
四、行业生态:重塑算力经济模型
-
推理成本重构
-
在千亿模型推理场景下,FlashMLA可使单次推理能耗降低至0.02 kWh(传统方案约0.05 kWh),推动大模型服务边际成本逼近传统云计算服务。
-
-
硬件协同创新
-
Hopper架构专属优化:利用H100的TMA(Tensor Memory Accelerator)和异步拷贝指令,实现计算与内存操作的全重叠,为下一代GPU(如B100)提供技术验证。
-
异构计算探索:分页KV Cache设计为CPU-offload混合计算预留接口,为突破显存墙提供技术储备。
-
生态位战略价值
-
基础设施层卡位
FlashMLA占据大模型推理加速的关键路径,其地位堪比数据库领域的「Redis缓存引擎」,未来可能演化为:-
云服务商的推理加速标准组件(类比AWS Inferentia中的核心算子)
-
终端芯片厂商的IP授权对象(如手机SoC中的NPU加速库)
-
-
开源商业化的标杆
通过核心基础设施开源+企业级支持服务(如定制化BlockTable优化)的模式,探索不同于OpenAI的生态盈利路径。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)