手把手教你喂养 DeepSeek 本地模型
这里先给AI小白简单科普一下基本概念,便于更好地理解本文中的动手操作。为什么我这里叫“喂养”DeepSeek 本地模型,是因为大模型再强大也有它天然的局限性,比如训练数据不可能包含你的私域数据,而打造自己的本地私域知识库,就需要检索这些数据,具体采用的是RAG(检索增强生成)方法。RAG,英文全称是Retrieval-Augmented Generation。简单来讲,采用RAG就需要把你的私域数
1.基本概念科普
这里先给AI小白简单科普一下基本概念,便于更好地理解本文中的动手操作。
为什么我这里叫“喂养”DeepSeek 本地模型,是因为大模型再强大也有它天然的局限性,比如训练数据不可能包含你的私域数据,而打造自己的本地私域知识库,就需要检索这些数据,具体采用的是RAG(检索增强生成)方法。
RAG,英文全称是Retrieval-Augmented Generation。简单来讲,采用RAG就需要把你的私域数据向量化,然后存储到向量数据库中,支持向量检索配合LLM大模型一起提供更专业的回复。
2.下载 AnythingLLM 软件
官方网站:
- https://anythingllm.com/desktop
下载符合你系统平台的软件,我这里是Apple Intel:
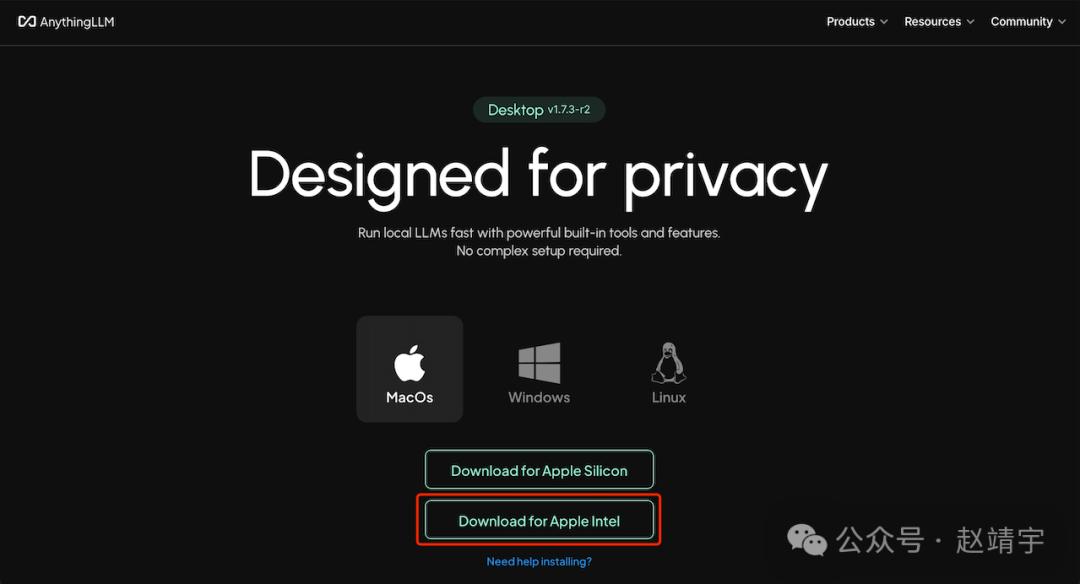
下载好的AnythingLLMDesktop.dmg,dmg文件约300M多点,双击安装并拖至应用程序中:

拖动时可以看到AnythingLLM安装程序有1G大小:

然后打开AnythingLLM,欢迎界面如下:
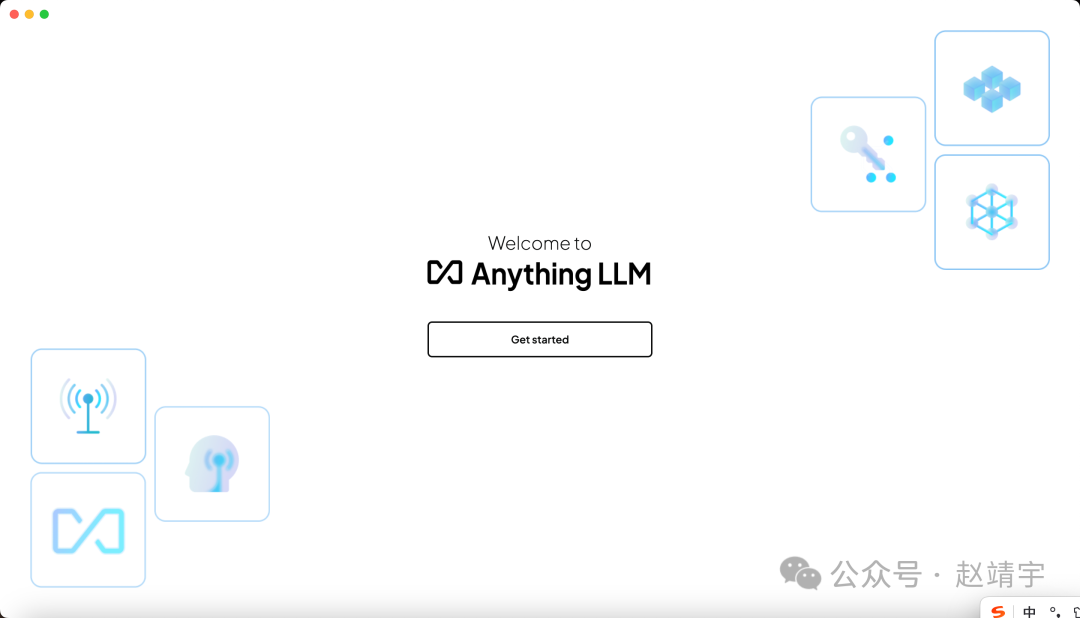
点击Get Started配置首选LLM,这里我们选择上一篇文章已经教大家配置好的Ollama:
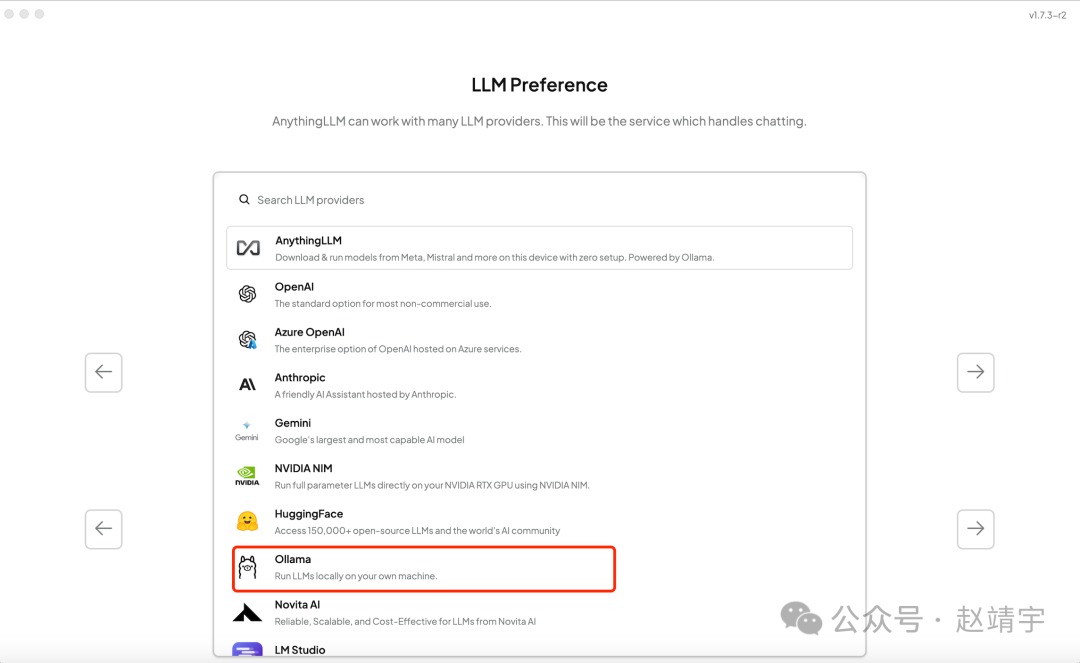
这里注意,需要确保你的Ollama正常运行,否则会报错找不到provider endpoint,如下图:
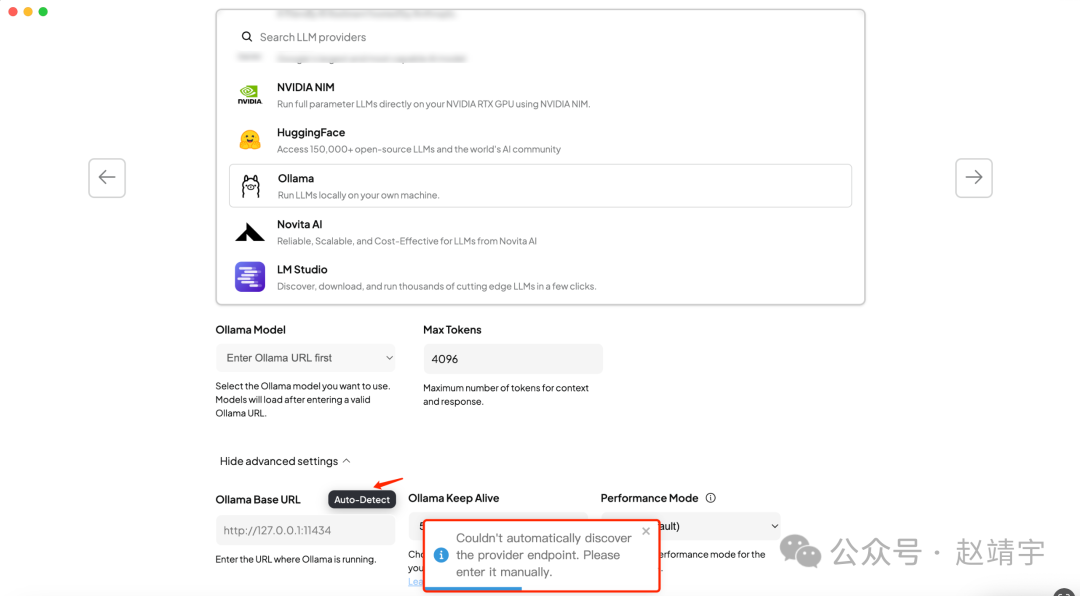
此时就需要检查你的ollama以及可用的本地模型:

修复好之后就可以看到AnythingLLM已经可以正确识别到本地部署的模型:
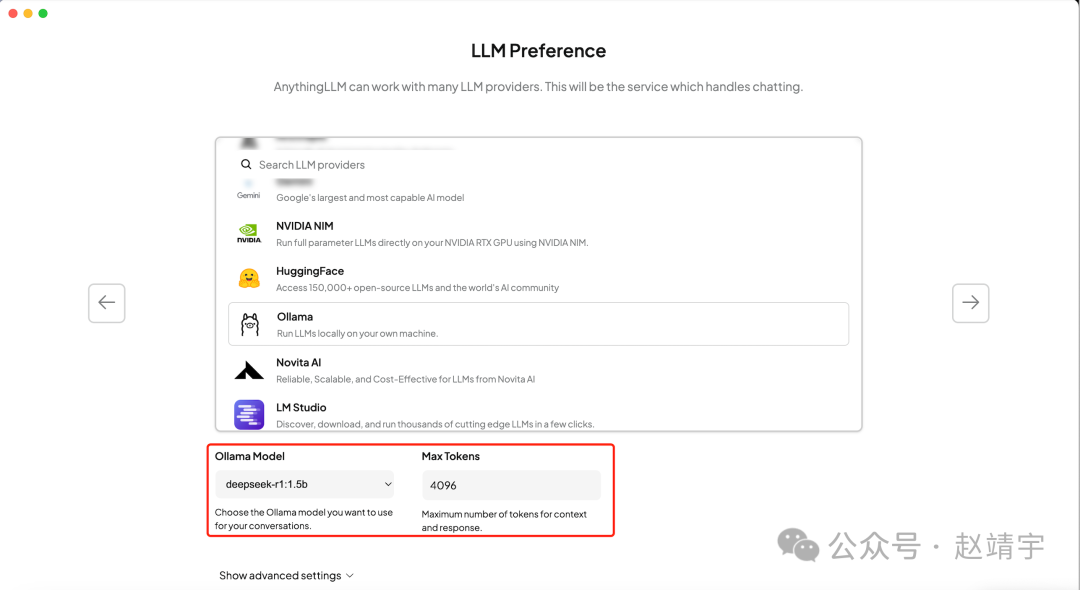
之后可以看到LLM模型选择了Ollama,Embedding默认是AnythingLLM的Embedder,Vector Database默认是LanceDB:

为了不给新手加难度,Embedding和Vector Database我这里都没有进行修改,直接先进入到下一步,是一个survey,笔者是个i人,实在没啥可说的,这里直接跳过了:
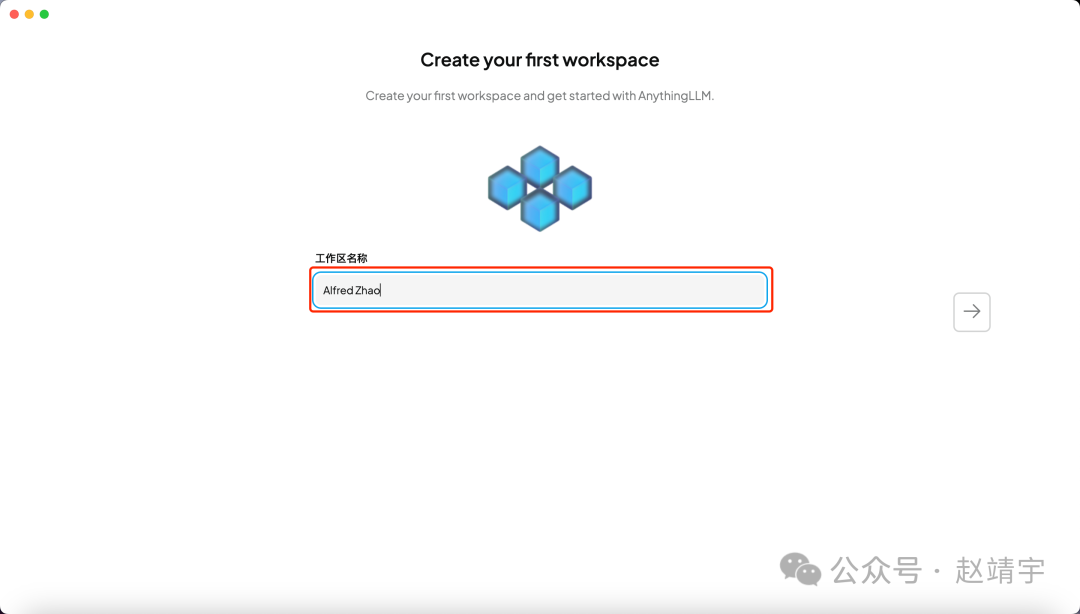
下一步选择工作区名称,你可以随便起名字,我这里就用自己的英文名演示了:
然后就终于进入了主界面:
呼呼,迫不及待的开始测试。
我这里直接设计了一个大模型不可能知道的问题,就是拿我的中文名字去做测试,直接问他“赵靖宇是谁?”
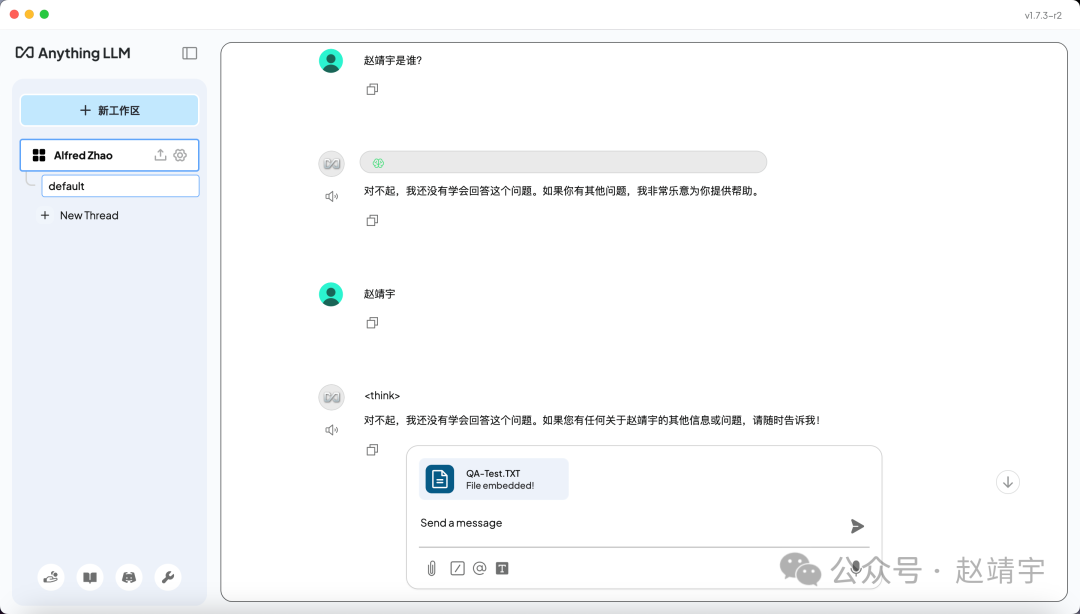
果然,它不知道!
马上开始上传一段TXT文本QA-Test.TXT,其实就是简单包含了我之前在讲公开课时的一段个人介绍,全文也没几句话。开始期待它的表现,上传方式如下,可以看到上传后文件就会自动Embedded!
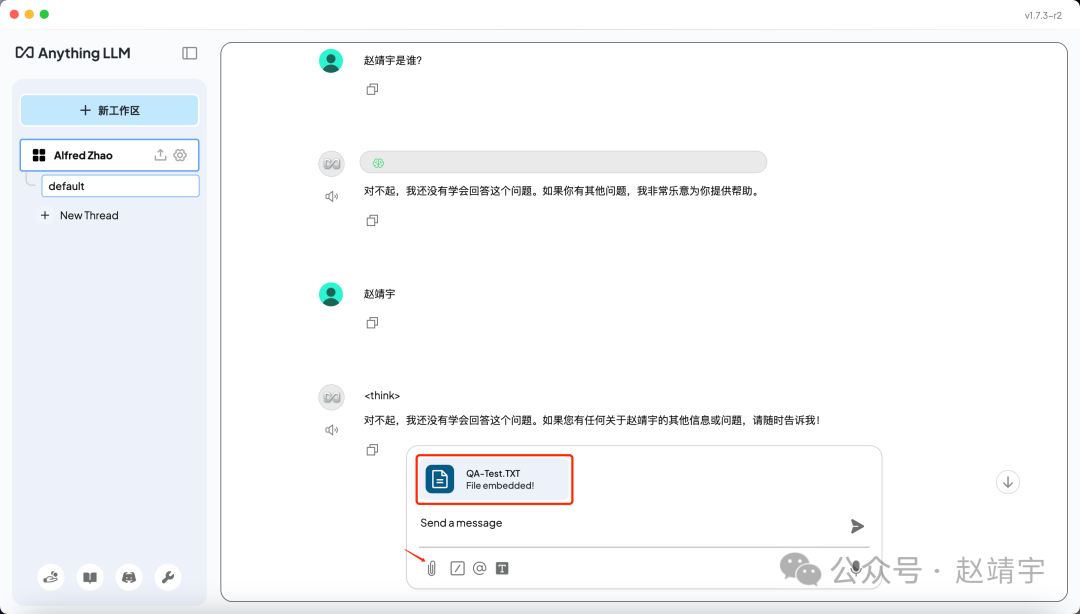
可是…… 这里不太顺利,它居然还是不知道!呜呜呜,我都把小抄给你了你还说不知道,笔者已哭晕……
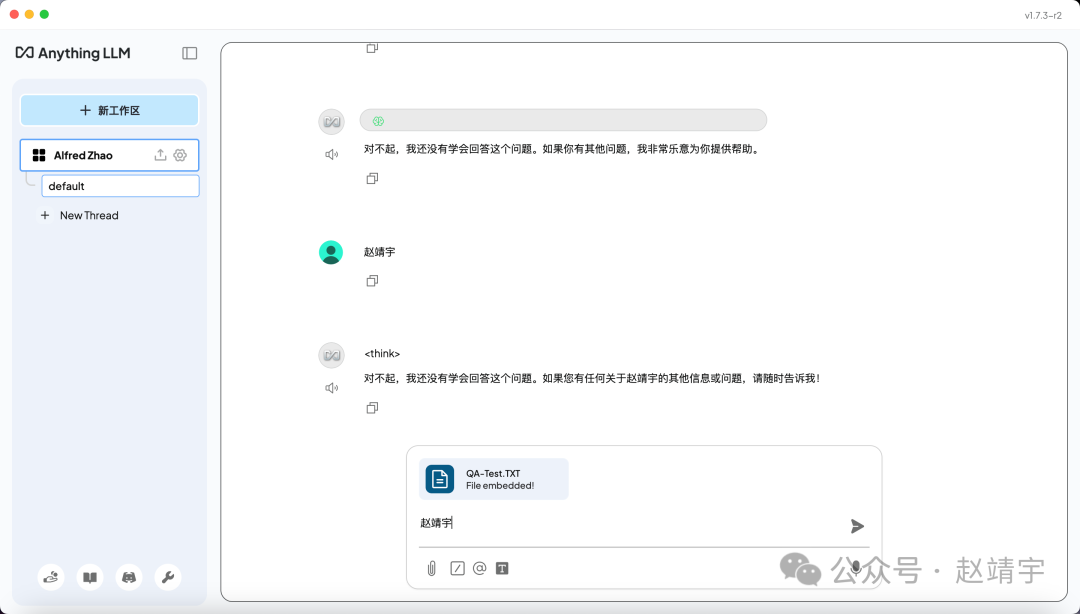
此时只能转而troubleshooting,检索发现不少人都有遇到类似问题,有人甚至直接发结论说本地大模型的模式下,AnythingLLM根本无法识别上传的个人文件,甚至力劝大家别折腾了。。
3.配置 nomic-embed-text 模型
笔者属于不撞南墙不回头的类型,想深挖下问题到底出在哪里?开始逐一检查可能的配置:
1)聊天设置模型选择肯定是没问题,本地大模型 DeepSeek:
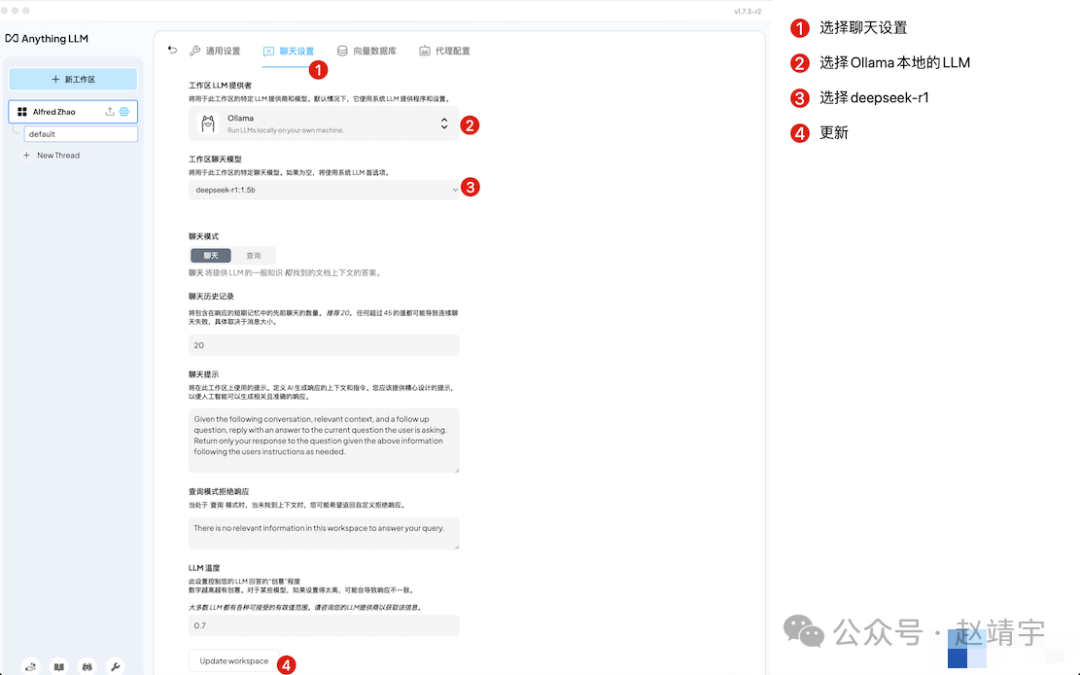
2)向量数据库默认的,向量数量为1:
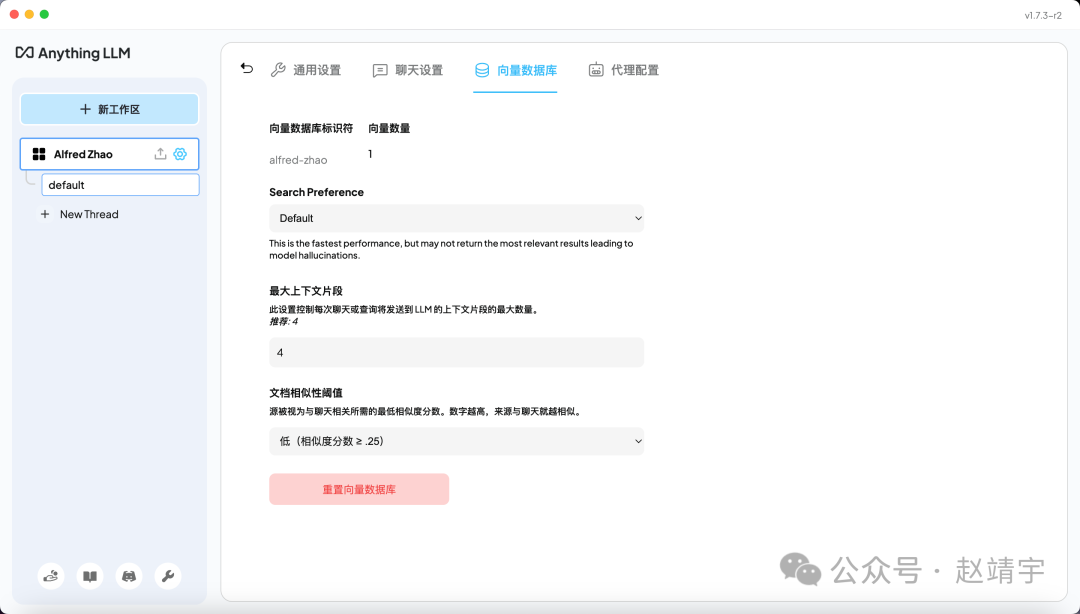
3)代理配置依然选择了本地大模型 DeepSeek:
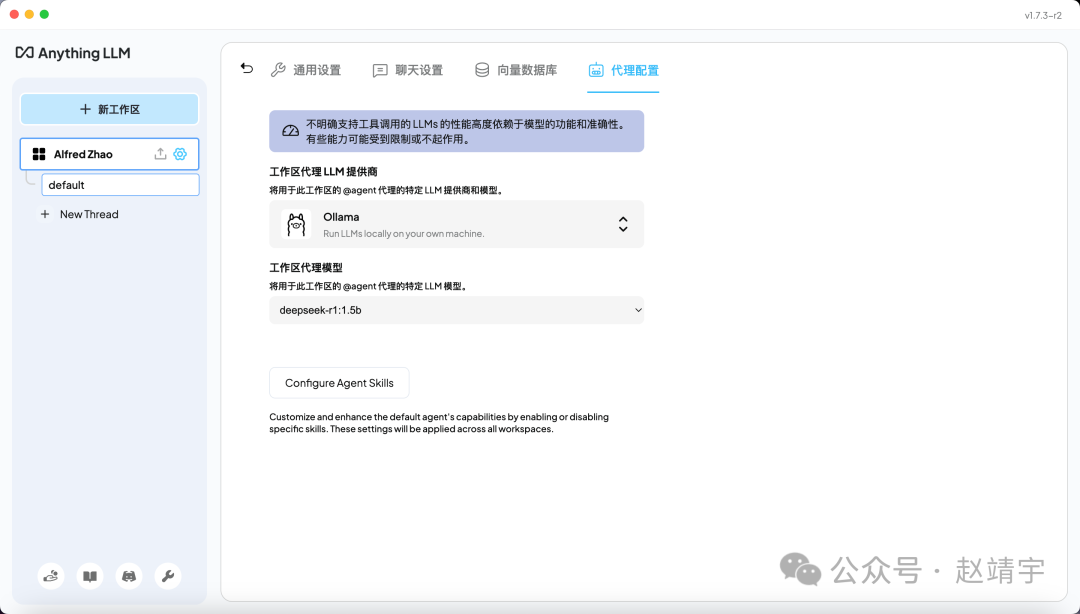
笔者初步判断:
-
1)本地大模型肯定没问题,因为上篇使用Chatbox调用都OK,AnythingLLM对应配置也再次确认了,均正确。
-
2)向量数据库虽然我有更好的选择,笔者就是从事数据库行业,但这里显然还没到那个阶段,默认的即便再拉跨也不至于一个这么简单的文本向量化都搞不定。
-
3)那就剩下 Embedding 用的模型,虽然开始也没怀疑过,但是这样排除下来就这个可能性最大了。要不,换一个试试?
目前 Embedding 采用的是默认的 AnythingLLM Embedder:
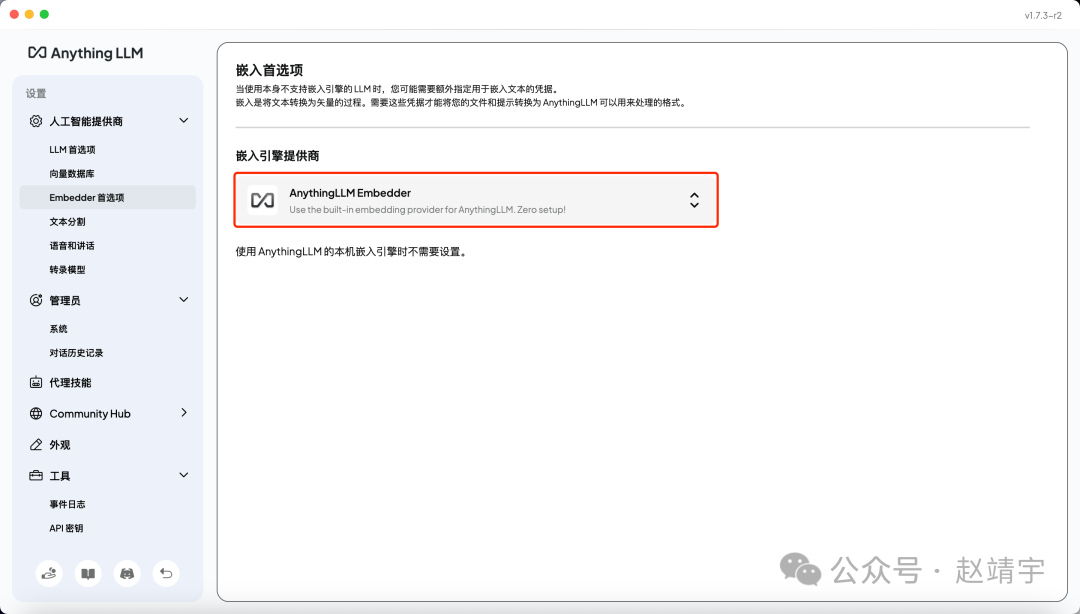
简单research了下,选了另一个Ollama下的nomic-embed-textEmbedding 模型,官方网站:
- https://ollama.com/library/nomic-embed-text
我们可以在terminal下使用ollama直接拉取ollama pull nomic-embed-text:

然后再回到Embedder首选项,在嵌入引擎提供商,选择Ollama,然后在下面的Ollama Embedding Model选择刚刚下载的最新nomic-embed-text:8192,如下图:
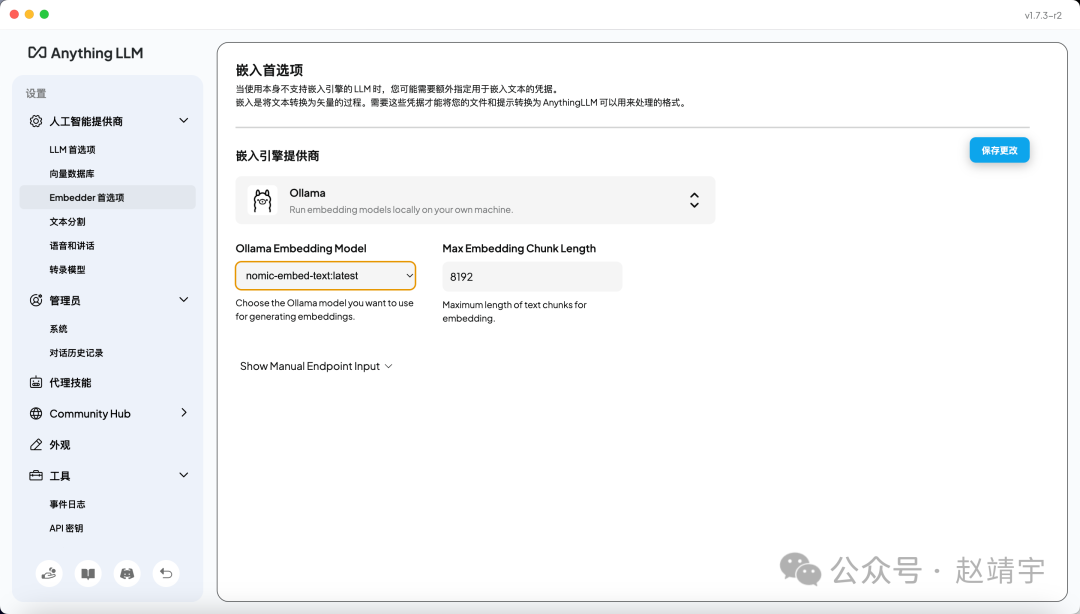
选择好之后点击蓝色的按钮保存更改,会弹出一个比较醒目的Warning,如下图:
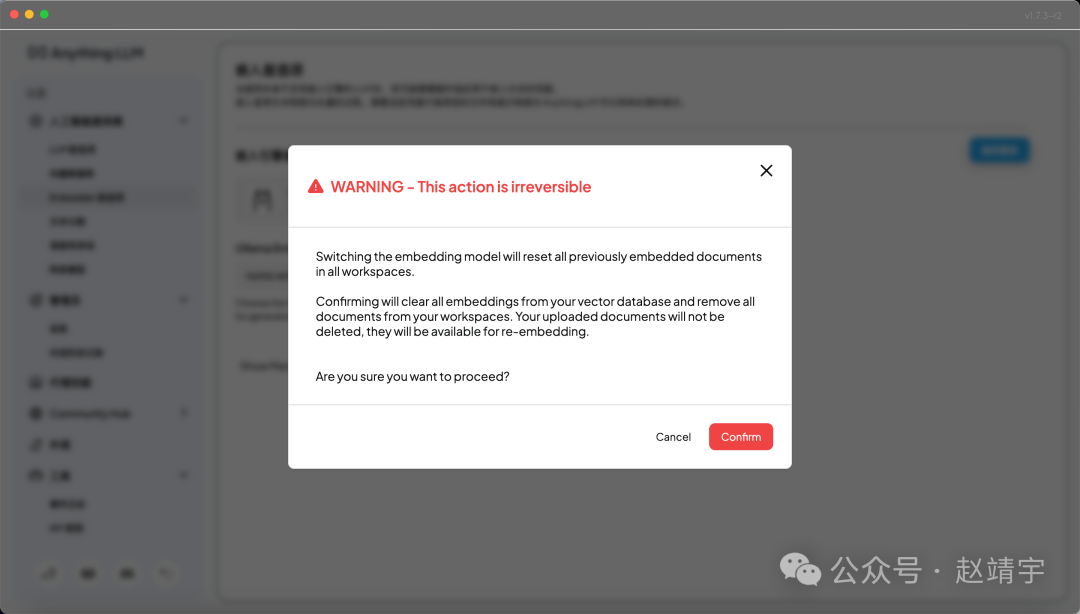
主要是警告你要做的这个更改Embedding模型的操作会重置先前所有embedded的文档,且不可逆转。我这之前的根本没效果,重置就重置,赶紧点击Confirm,迫不及待想看下这个新的Embedder是否有用?
4.演示如何正确喂养个人数据
使用跟之前同样的操作方法,同样的问题赵靖宇是谁?,喂养文本QA-Test.TXT,终于起作用了!
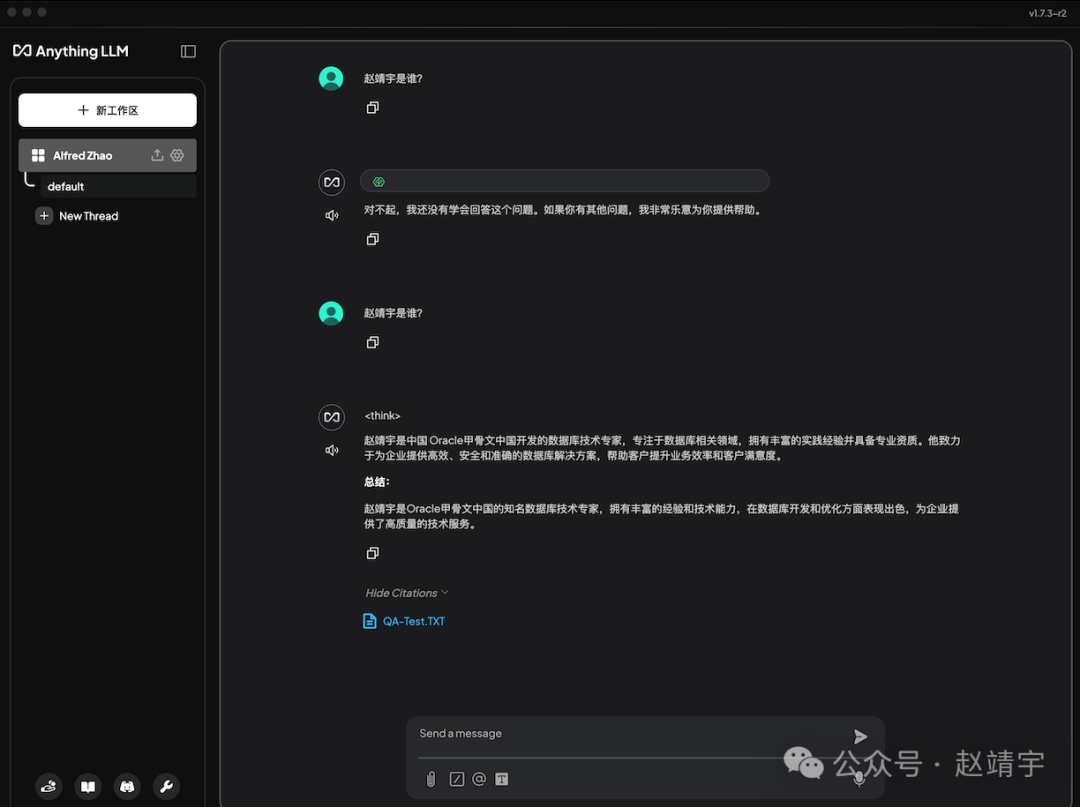
于是兴奋地继续追问:他有几年的工作经验?,又不知道了,当然这个正常,因为我提供的信息里就没有明确提到,可以继续上传其他个人数据,比如说来份PDF格式的个人简历:
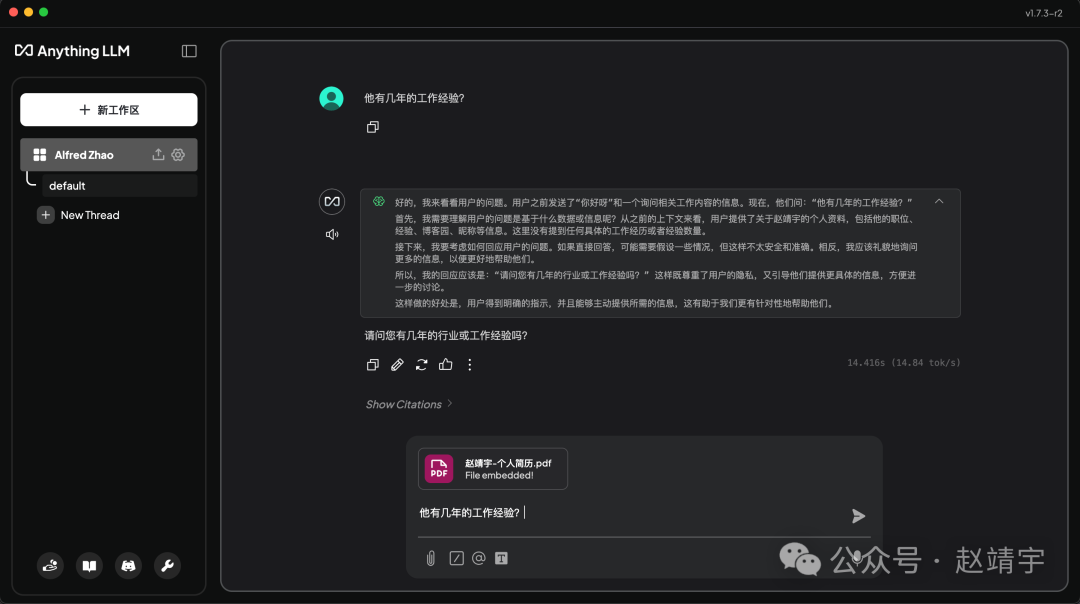
然后继续问些更细节的问题:你知道他的博客地址是什么吗?、赵靖宇有公众号吗?
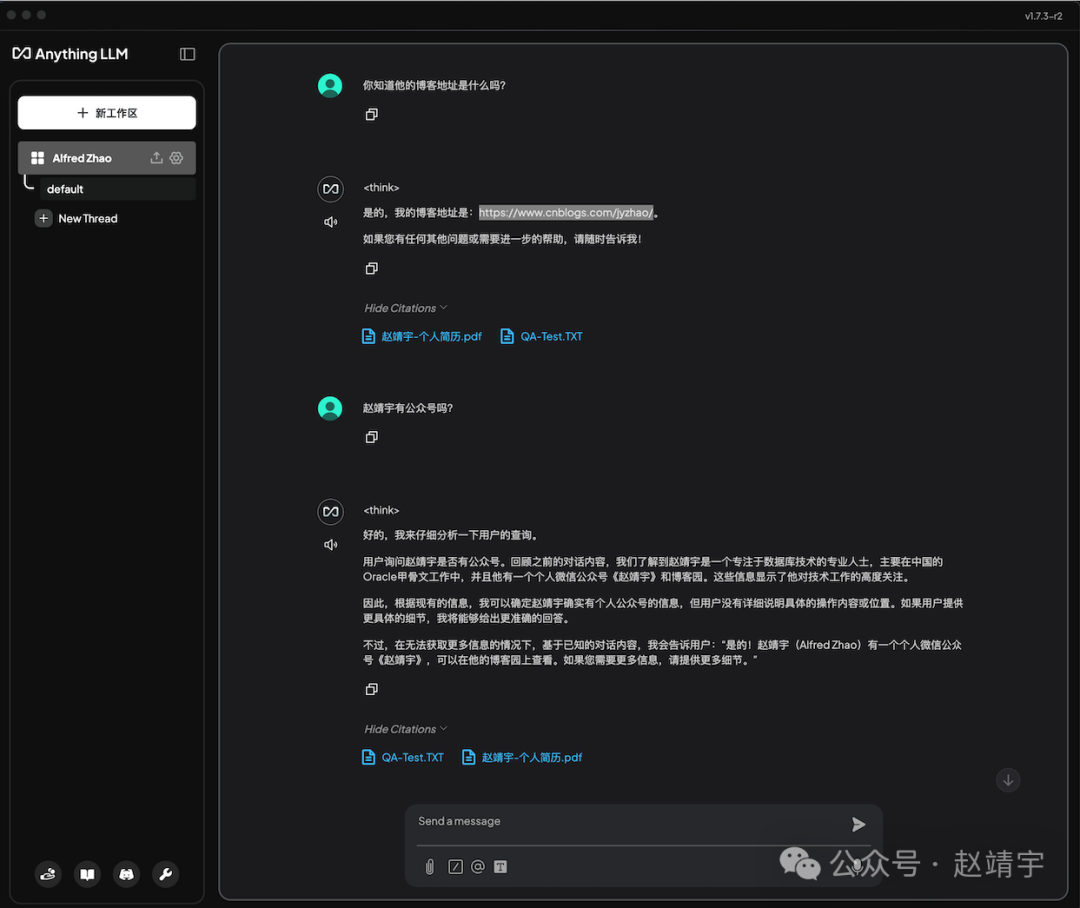
效果还是比较给力的,均给出了正确答案。明确说出我的公众号名称赵靖宇,以及Blog的url地址:https://www.cnblogs.com/jyzhao/,尤其是网址能准确给出还是比较惊喜的。
5.喂养前后效果对比和缺陷
上面已经看到了喂养后的效果显著,但这是否就高枕无忧了呢?
其实不是的,比如我继续测试时发现,当让它帮我总结下简历信息,就看到了较明显的缺陷:
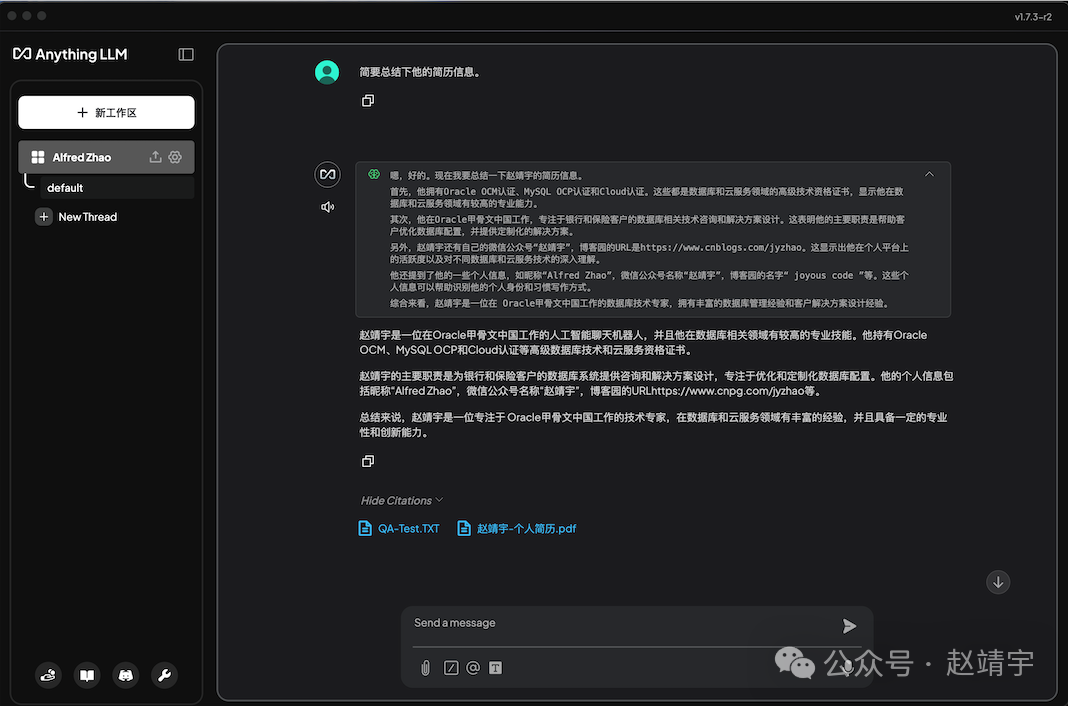
这里有两处明显的错误:而且有一个错误,还是之前单独问它时,回答正确的,具体如下图:
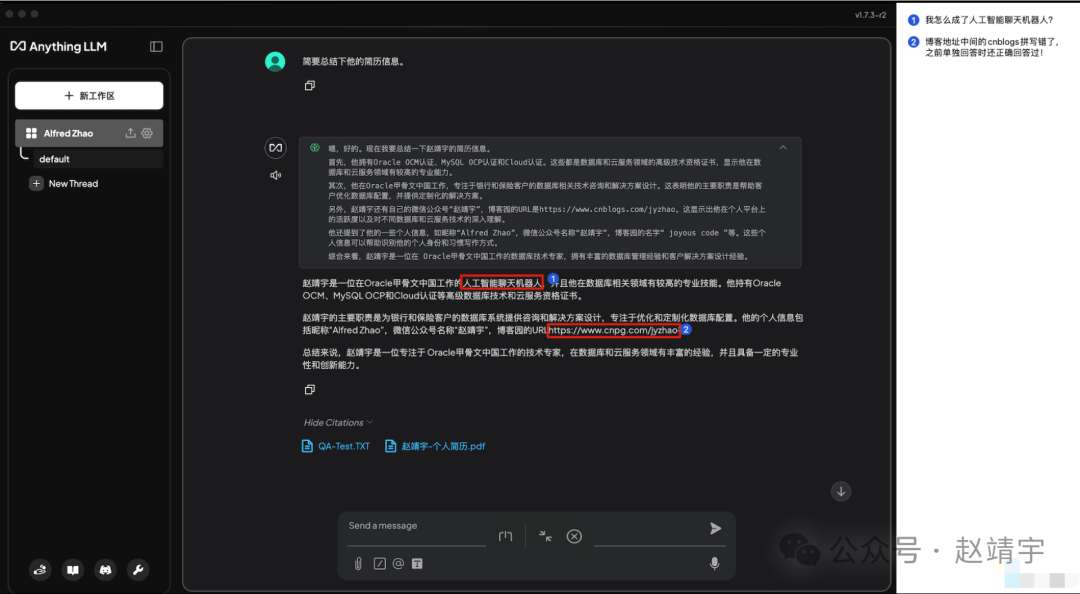
其实这个回复中大部分信息都还OK,可瑕疵也是极为明显的,比如它居然说我是人工智能聊天机器人,然后把之前曾正确回答出的博客网址又给答错了。
这些讹误和不稳定性,原因可能是受限于我本地部署的模型太小,本身能力不足,也可能是Embedding向量化的工作做的还不够好,但总体来说,对于我这台个人电脑能达到这样的效果,已经很是知足了。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 54
54 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)