科普文:AI时代的程序员【DeepSeek-R1学习】
DeepSeek-R1 是一款基于强化学习驱动大型语言模型的推理能力提升的模型,是DeepSeek团队通过大规模强化学习(RL)和蒸馏技术开发的第一代推理模型。DeepSeek-R1是由深度求索(DeepSeek)公司开发的推理模型,发布于2025年1月20日,采用强化学习技术提升推理能力,并且在数学、代码和自然语言任务中表现出色。它的诞生源于对传统语言模型在复杂推理任务中局限性的认识,旨在通过创
概叙
DeepSeek-R1 是一款基于强化学习驱动大型语言模型的推理能力提升的模型,是DeepSeek团队通过大规模强化学习(RL)和蒸馏技术开发的第一代推理模型。
DeepSeek-R1是由深度求索(DeepSeek)公司开发的推理模型,发布于2025年1月20日,采用强化学习技术提升推理能力,并且在数学、代码和自然语言任务中表现出色。
它的诞生源于对传统语言模型在复杂推理任务中局限性的认识,旨在通过创新的训练方法提升模型在数学推理、代码生成等需要精确逻辑推理的任务中的表现。
DeepSeek-R1的发布标志着中国AI技术从跟随者向引领者的转变,其开源策略和技术突破正重塑全球AI竞争格局。随着国产芯片适配深化及行业应用拓展,该模型或将成为通用人工智能(AGI)发展的重要推手。
-
发布时间与主体
- 正式版发布于2025年1月20日,由幻方量化旗下AI公司深度求索(DeepSeek)研发,同步开源模型权重 。
- 预览版(DeepSeek-R1-Lite)早于2024年11月20日上线,支持网页端使用。
-
模型定位
- 专为推理任务优化,尤其擅长数学、编程竞赛(如AIME、codeforces)、逻辑推理等高复杂度场景,性能与OpenAI o1正式版相当 。
- 采用MIT开源协议,允许自由使用、修改和商业化。
-
核心技术
- 大规模强化学习(RL):后训练阶段通过极少标注数据提升模型能力,突破传统依赖海量数据训练的范式 。
- 智能训练场:动态生成题目、实时验证解题逻辑,推动模型自主学习并迁移方法论(如将几何反证法用于代码检测) 。
-
模型规格
- 基础大模型:671B参数(6710亿),支持国家级科研、气候建模等超高精度需求。
- 蒸馏小模型:包含1.5B、7B、14B、32B、70B等版本,覆盖轻量级任务(短文本生成)到专业级应用(金融预测),平衡性能与成本 。
- 科普文:AI时代【DeepSeek-R1基础:DeepSeek-R1 1.5b、7b、70b、671b是几个意思,Token又是啥】-CSDN博客
- 硬件适配:从消费级显卡(如RTX 3060)到商用GPU集群(如A100/H100)均支持,32B及以上版本需高性能服务器 。
-
性能突破
- 在2025年1月的大模型竞技场(Arena)中,综合排名第三,风格控制类任务与OpenAI o1并列第一(得分1357 vs. 1352) 。
- 数学竞赛AIME和编程竞赛评测表现超越GPT-4o。
-
成本优势
- 训练成本仅为OpenAI同类模型的1/10,API服务价格低至1元/百万tokens(缓存命中时),性价比显著 。
- 通过量化技术(如1.73bit)降低显存需求,671B全参模型显存占用从404GB压缩至158GB,支持主流GPU部署 。
-
开源生态
- 提供6个蒸馏模型(如32B、70B),赋能中小开发者,降低AI应用门槛。
- 与京东云、七牛云、国家超算中心等平台合作,支持“开箱即用”的云端推理和私有化部署。
1. 模型核心技术
-
混合专家系统(MoE)
采用 6710 亿参数的混合专家架构,每个推理标记激活约 370 亿参数,通过动态路由机制实现计算资源的高效分配。该架构在保持模型容量的同时,显著降低单次推理的计算成本。 -
多阶段训练框架
模型训练流程包含四个核心阶段:- 预训练阶段:基于 DeepSeek-V3 基础模型进行语言建模
- 监督微调(SFT):使用 60 万条长链思维(CoT)数据优化指令遵循能力
- 强化学习阶段:通过 GRPO 算法(Group Relative Policy Optimization)优化推理准确性与语言一致性
- 蒸馏阶段:将推理能力迁移至 15 亿 - 700 亿参数规模的轻量级模型
科普文:AI时代【DeepSeek核心技术、使用建议】作者丨 腾讯工程师 Tommie-CSDN博客
科普文:AI时代【漫谈DeepSeek及其背后的核心技术】作者丨 朱凯旋(易询)-CSDN博客
科普文:AI时代DeepSeek【DeepSeek-R1论文:蒸馏技术有效提升小型模型能力】-CSDN博客
-
强化学习 (RL) 驱动的推理能力: DeepSeek-R1 证明了大型语言模型 (LLM) 的推理能力主要可以通过强化学习来实现,从而减少对大规模监督微调 (SFT) 的依赖。这与传统观点认为广泛的 SFT 对于高级 LLM 能力至关重要有所不同。DeepSeek-R1采用了纯强化学习训练策略,无需监督微调(SFT),展现出了强大的推理能力。这种训练方法使得模型能够自发地重新评估和优化推理步骤,从而实现高效的推理。
-
冷启动数据与多阶段训练:为了优化模型性能,DeepSeek团队引入了冷启动数据和多阶段训练方法。冷启动数据使得模型在训练初期能够更快地收敛,而多阶段训练则进一步提升了模型的推理能力和可读性。
-
蒸馏技术:DeepSeek团队还探索了蒸馏技术,将大型模型的推理能力传递到小型模型,使得小型模型在推理任务中也能表现出色。这种技术有助于降低模型的应用成本,并推动AI技术的民主化进程。
-
群组相对策略优化 (GRPO): DeepSeek-R1 使用 GRPO,这是一种新颖且高效的强化学习算法,替代了传统的 PPO 等方法。GRPO 简化了 RL 训练过程并增强了可扩展性,有助于高效训练。
-
多头潜在注意力 (MLA): 集成 MLA 显著降低了计算和内存效率低下的问题,尤其是在长上下文处理方面。通过将键-查询-值矩阵投影到低维潜在空间,MLA 优化了注意力机制,同时不影响性能。
-
FP8 量化: 使用 FP8 量化可将内存需求降低 75%,并降低计算成本,与使用 FP32 相比。
- DeepSeek-R1 相关的主要算法公式

2. 模型训练步骤
DeepSeek-R1 的训练流程分为三步:
- 语言建模:基于海量网络数据训练基础模型。
- 监督微调 (SFT):提升模型的指令遵循与问题解答能力。
- 偏好调整:对齐人类偏好,生成最终可用模型。
其中,长链推理监督微调数据的获取与标注尤为复杂,但其带来的效益却对模型的推理能力提升极为显著。
强化学习创新
-
GRPO 优化器
相比传统 PPO 算法,GRPO 采用组内相对奖励机制,直接利用平均奖励作为基线,消除对独立价值函数的需求。该方法在 AIME 2024 评测中使模型准确率从 15.6% 提升至 71.0%,多数投票场景下达到 86.7%。 -
双奖励驱动机制
- 准确性奖励:强制要求数学 / 编程类问题按指定格式输出,确保结果正确性
- 语言一致性奖励:通过<think>等结构化标记规范推理过程的可解释性
关键技术创新
-
冷启动数据策略
在强化学习前引入少量高质量 CoT 数据进行初步微调,有效解决纯强化学习模型(如 R1-Zero)存在的语言连贯性问题。该策略使模型在 STEM 领域问题解决能力达到 OpenAI o1-1217 水平。 -
自进化推理能力
模型展现出独特的 "自我验证" 特性,能自主增加推理步骤长度(平均增加 3.2 步)以提升复杂问题解决准确率。该特性在数学证明类任务中表现尤为显著。 -
全链路优化机制
采用 "预训练→RL→微调→RL" 的多轮迭代模式,通过拒绝采样技术持续修正模型行为。这种循环训练框架使模型在 HumanEval 评测中的代码生成准确率提升 27.3%。
3. 模型构建关键技术亮点
- 长链思维链数据:在训练过程中,使用了 60 万个长思维链推理示例,克服了传统标注成本高昂的瓶颈。
- 中间推理模型的运用:通过 R1-Zero 模型生成优质推理数据,从而提高了推理任务的有效性。
- 大规模强化学习 (RL):在没有标签数据的情况下,通过强化学习算法训练推理模型,实现了高效的结果输出。
4. 模型核心能力
- 推理能力:DeepSeek-R1 在多个推理 benchmark 上取得了媲美甚至超越闭源模型的性能,并展现了推理能力可蒸馏至小型模型的特性。
- 多任务处理能力:DeepSeek-R1 不仅具备推理能力,还在各类非推理任务上有着良好的表现。这得益于其在训练过程中引入了实用性奖励模型与安全性奖励模型,使得模型在输出的同时,遵循一定的伦理规范。
- 长链推理:DeepSeek-R1-Zero 模型通过群体相对策略优化 (GRPO) 和基于规则的奖励机制进行训练,主要包括两类奖励:准确性奖励和格式奖励。准确性奖励评估模型输出的正确性,格式奖励则确保模型的思考过程符合设定的标签要求。
5. 模型应用场景
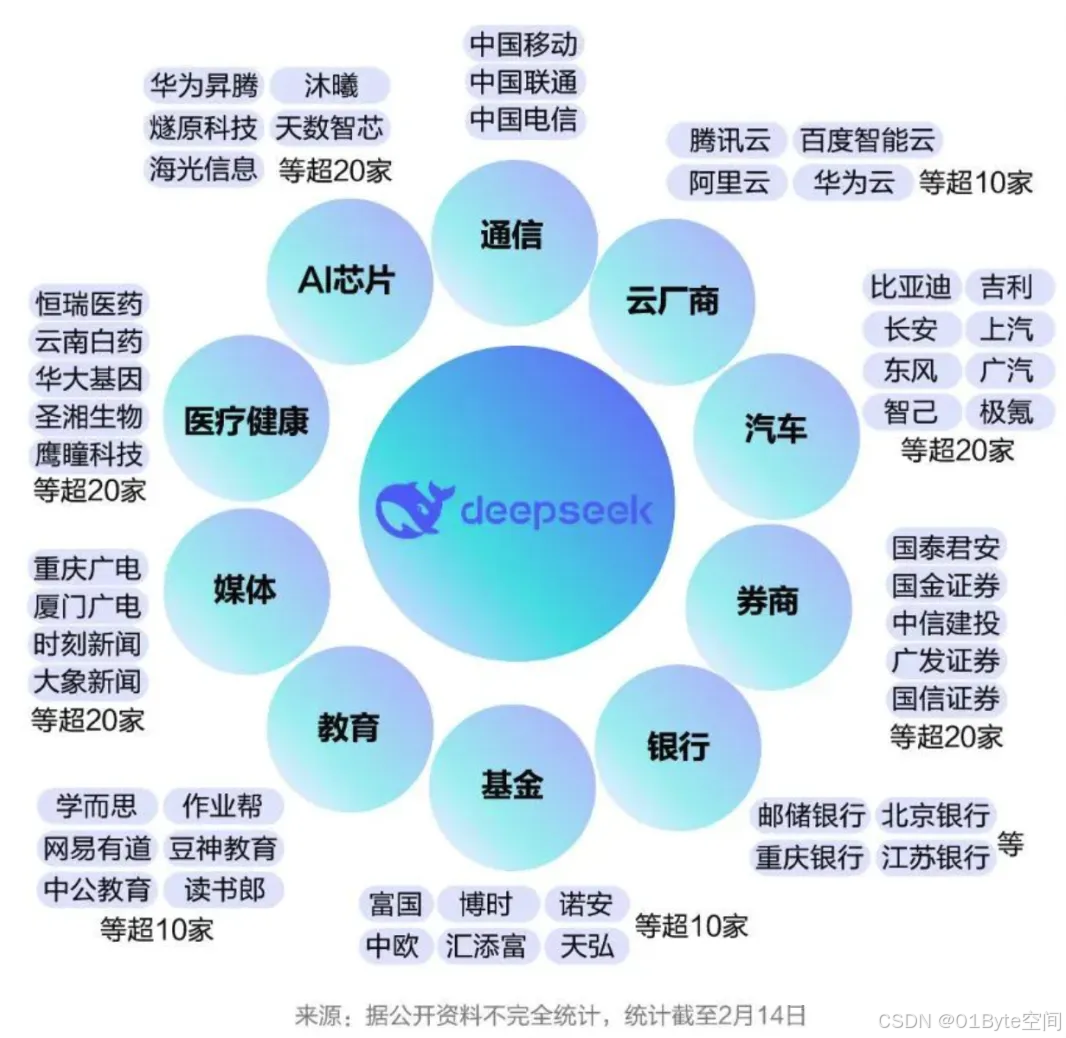
- 高频应用:客户服务(自动咨询、退款处理)、个性化推荐(电商、音乐)。
- 中频应用:教育(作业批改、虚拟导师)、医疗(初步诊断、健康监测)、金融(智能投顾、欺诈检测) 。
- 专业场景:代码生成、科研分析(如基因组学、气候建模)。
DeepSeek-R1 的应用场景包括但不限于:
- 教育领域:用于智能辅导、课程生成等。DeepSeek-R1在教育领域具有广泛的应用前景。它能够为学生提供个性化的学习辅导,帮助他们解决数学问题、理解编程概念等。此外,它还可以作为教师的教学辅助工具,提高教学效果和学生的学习效率。
- 客服领域:用于智能客服、问题解答等。
- 研究领域:用于学术研究、数据分析等。
- 实时信息检索:DeepSeek-R1能够直接从网络检索数据,提供实时、准确和上下文相关的信息。这使得它成为研究人员、专业人士和普通用户在进行实时信息检索时的强大工具。
- 数学与编程任务:DeepSeek-R1在数学和编程任务中表现出色。它能够快速给出数学问题的答案,并详细展示思考过程。同时,它还能迅速编写代码,并清晰地解释每一行代码背后的逻辑。这使得它成为编程初学者的理想助手。
6. 未来展望
- 技术持续优化:DeepSeek团队将继续优化DeepSeek-R1的推理路径,提高模型的可解释性和效率。这将有助于进一步拓展模型的应用场景,并提升用户体验。
- 更多领域应用:随着技术的不断发展,DeepSeek-R1有望在更多领域得到应用。例如,在科学研究、医疗诊断等领域,它可以帮助研究人员进行数据分析、疾病诊断等任务,为科学研究和社会进步做出贡献。
- 数据隐私与伦理问题:随着DeepSeek-R1的广泛应用,数据隐私和伦理问题也将日益凸显。DeepSeek团队将认真思考和应对这些问题,确保模型的安全、可靠和合规使用。
7.学习路径
通过系统的学习和实践,可以逐步掌握DeepSeek-R1的操作和优化方法,为机器人应用场景打下坚实基础。
科普文:AI时代的程序员【AI时代,程序员如何面向AI编程?】-CSDN博客
-
入门学习
- 阅读官方文档和技术博客,了解DeepSeek-R1的基本架构和功能。
- 通过简化的示例项目练习,如简单目标识别或移动任务。
-
深入理解
- 学习相关AI算法(如SLAM、强化学习等),掌握其在机器人中的应用。
- 分析DeepSeek-R1的源代码,理解模块间的交互和数据流向。
-
项目实践
- 参与或创建自己的项目,尝试集成新的传感器、算法或任务逻辑。
- 利用社区资源和教程进行不断探索和优化。
-
持续学习与发展
- 关注技术更新,了解行业动态,与其他开发者交流分享经验。
- 持续优化项目,提升机器人性能和功能范围。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)