科普文:AI时代【DeepSeek-R1基础:DeepSeek-R1 1.5b、7b、70b、671b是几个意思,Token又是啥】
那么这里的DeepSeek-R1 1.5B、7B、8B、14B、32B、70B、671B是什么意思?这些都是模型的参数数量,单位是B,是指十亿(billion)。在AI模型中,参数数量是一个关键指标,参数越多,模型通常越强大,但也越需要更多的计算资源,因此671B更被称作“满血模型”。下面我们看看每个版本的参数数量以及它们的意义和适用场景。DeepSeek-R1 1.5B、7B、8B、14B、32
概叙
DeepSeek-R1 是一款基于强化学习驱动大型语言模型的推理能力提升的模型。
科普文:AI时代DeepSeek【ollama本地傻瓜式安装deepseek-r1】_630的显卡可以装deepseek嘛-CSDN博客
在前面ollama本地安装DeepSeek-R1,有一个选项:
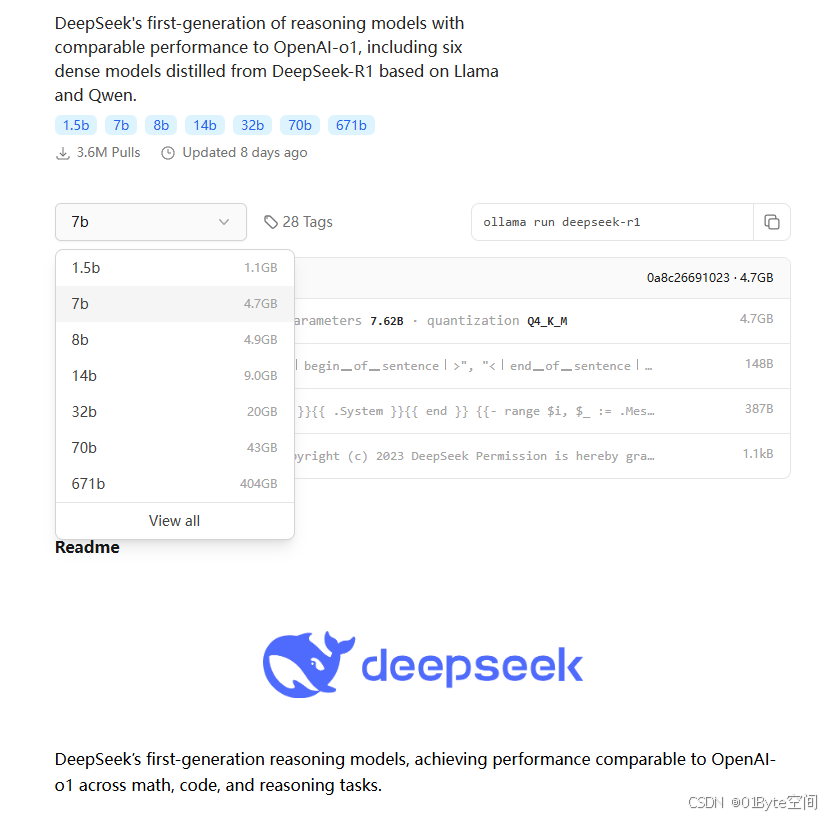
那么这里的DeepSeek-R1 1.5B、7B、8B、14B、32B、70B、671B是什么意思?
这些都是模型的参数数量,单位是B,是指十亿(billion)。
在AI模型中,参数数量是一个关键指标,参数越多,模型通常越强大,但也越需要更多的计算资源,因此671B更被称作“满血模型”。
下面我们看看每个版本的参数数量以及它们的意义和适用场景。
DeepSeek-R1 1.5B、7B、8B、14B、32B、70B、671B 是指不同规模的深度学习模型,数字代表了模型的参数数量(以十亿计)。参数越多,模型越强大,但对计算资源的需求也越高。以下是对这些版本的详细解释:
1. 参数数量解释
- 1.5B: 1,500,000,000 参数,适合基础任务,如简单文本生成。
- 7B: 7,000,000,000 参数,适合日常对话和基本复杂任务。
- 8B: 8,000,000,000 参数,性能略强于7B,处理更复杂的任务。
- 14B: 14,000,000,000 参数,适合中等复杂度的任务,长文本处理。
- 32B: 32,000,000,000 参数,适合更高复杂度的任务,需要较强的硬件支持。
- 70B: 70,000,000,000 参数,适合复杂任务,运行需求较高。
- 671B: 671,000,000,000 参数,最大版,适合极其复杂的任务,需高性能计算资源。
2. 参数数量的意义
- 模型能力: 参数越多,模型处理复杂任务的能力越强,生成内容质量更高,准确性更优。
- 资源需求: 参数越多,运行模型所需的计算资源越高,硬件需求更严格,如需要高性能GPU。
- 速度与延迟: 大模型运行推理速度较慢,但输出质量更高;小模型速度快,适合实时应用。
3. 特点及适用场景
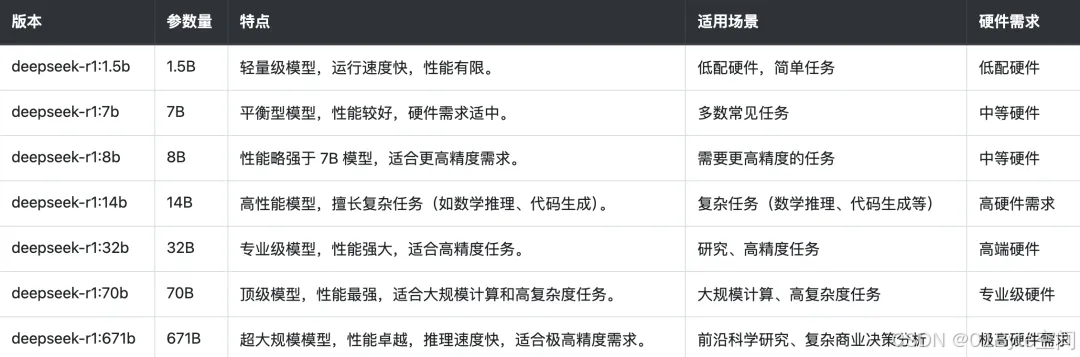
- 小模型(1.5B、7B): 适合轻量任务,如个人用户的文本生成、基础对话。
- 中模型(8B、14B): 适合中等复杂任务,如长文本处理、代码生成。
- 大模型(32B、70B): 适合复杂任务,如深度问答、多轮对话。
- 超大模型(671B): 适合极其复杂任务,如高深学术分析、企业级应用。
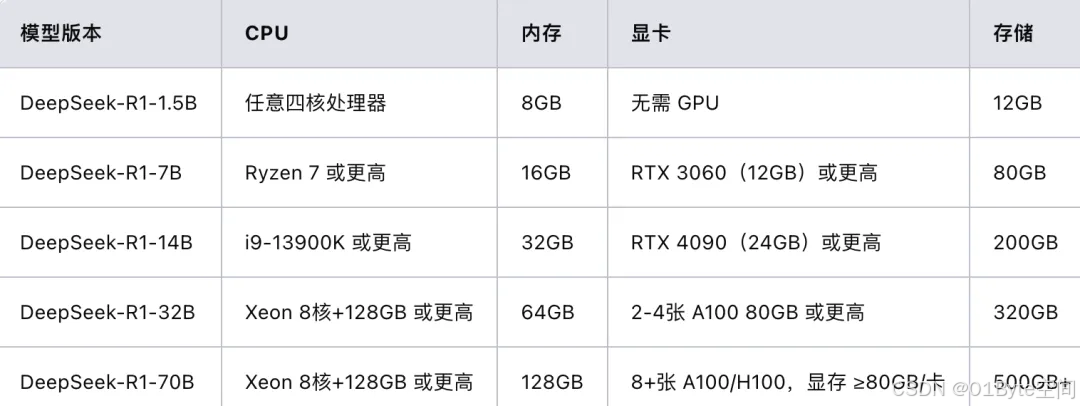
DeepSeek不同版本的配置要求如下:
-
DeepSeek-r1-1.5b
- CPU: 最低4核
- 内存: 8GB+
- 硬盘: 256GB+(模型文件约1.5-2GB)
- 显卡: 非必需(纯CPU推理)
- 适用场景: 本地测试,简单任务,如文本摘要、翻译、轻量级对话系统等。
- 预计费用: 2000-5000元
-
DeepSeek-r1-7b/8b
- CPU: 8核
- 内存: 16GB+
- 硬盘: 256GB+(模型文件约4-5GB)
- 显卡: 推荐8GB+显存(如RTX 3070/4060)
- 适用场景: 本地开发与测试,中等复杂度任务,如NLP、代码生成、逻辑推理等。
- 预计费用: 5000-10000元
-
DeepSeek-r1-14b
- CPU: 12核
- 内存: 32GB
- 硬盘: 256GB+
- 显卡: 推荐16GB+显存(如RTX 4090或A5000)
- 适用场景: 企业级复杂任务,长文本理解与生成。
- 预计费用: 20000-30000元
-
DeepSeek-r1-32b
- CPU: 16核
- 内存: 64GB+
- 硬盘: 256GB+
- 显卡: 推荐24GB+显存(如A100 40GB或双卡RTX 3090)
- 适用场景: 高精度专业领域任务,多模态任务预处理。
- 预计费用: 40000-100000元
-
DeepSeek-r1-70b
- CPU: 32核
- 内存: 128GB+
- 硬盘: 512GB+
- 显卡: 多卡并行(如2x A100 80GB或4x RTX 4090)
- 适用场景: 科研机构或大型企业,高复杂度生成任务。
- 预计费用: 400000+元
-
DeepSeek-r1-671b
- CPU: 64核
- 内存: 512GB+
- 硬盘: 512GB+
- 显卡: 多节点分布式训练(如8x A100/H100)
- 适用场景: 超大规模AI研究或通用AGI探索。
- 预计费用: 2000000+元
4. 总结:参数量越大越好吗?
参数量越大模型越聪明,那是不是直接用最大的参数量就完事了?
现实中,参数量大 ≠ 适合所有场景,得具体问题具体分析,根据实际情况和当前需求来定。
- 选择模型: 根据具体任务需求和硬件条件选择合适的模型版本。
- 资源配置: 确保硬件能够支持模型的运行,如高参数模型需要高性能计算资源。
- 性能权衡: 在速度和质量之间选择,权衡任务的实时性与输出质量。
通过以上信息,您可以了解不同参数规模的DeepSeek-R1模型的特点和适用场景,从而更好地选择适合自己需求的版本。
Token:人工智能领域,文本处理核心单元
在自然语言处理(NLP)和大语言模型中,Token 是文本处理的最小语义单位。
其特点包括:
- 拆分机制:将输入文本分解为单词、子词或标点符号等基本单元(例如英文中约 3-4 个字母构成一个 Token,中文约 1-1.8 个汉字对应一个 Token)
- 模型处理流程:语言模型通过 Token 化将文本转换为数字序列,完成语义理解和内容生成
- 性能指标:模型处理速度常以「Tokens / 秒」衡量,类似视觉模型的 FPS 指标
在 DeepSeek 中,Token 是自然语言处理的核心计量与处理单元,其定义和应用涵盖技术实现与商业计费两个维度:
技术定义与处理机制
-
语义分割单位
Token 是模型处理文本的最小语义单元,承担文本编码与解析功能。对于中文场景,1 个 Token 约对应 0.75-1.8 个汉字(例如 “我爱北京天安门” 分解为 7 个汉字对应 9 个 Token)。英文场景中,1 个 Token 通常对应 4 个字符或 0.75 个单词。 -
编码与预处理流程
开发者需通过 Tokenizer 将原始文本转换为 Token ID 序列。例如,使用 Hugging Face 的AutoTokenizer工具时,需执行以下操作:from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('deepseek-model-name') token_ids = tokenizer.encode("这是一个测试句子", add_special_tokens=True)
-
此过程自动完成大小写标准化、特殊字符处理,并生成包含分隔符(如
[CLS]、[SEP])和掩码标记(如[MASK])的结构化序列,以适应分类、遮蔽预测等任务需求。
商业计费与优化策略
-
计费模型
- 输入 / 输出分离计费:调用 API 时,用户输入的 Prompt 和模型生成的 Response 均独立计算 Token 数量。例如,生成 3000 字文章约消耗 4500 个输出 Token。
- 分层定价机制:
- 聊天模型:输入 Token 费用为 0.5-2 元 / 百万,输出 Token 为 8 元 / 百万。
- 推理模型:价格翻倍,输入 1-4 元 / 百万,输出 16 元 / 百万。
- 缓存优化:若请求内容命中缓存(类比 “预制菜”),输入费用可降至 0.5 元 / 百万;未命中则按标准 2 元 / 百万计费。
-
成本控制建议
- 通过预训练模型优化 Token 使用效率,减少冗余文本生成。
- 利用火山引擎、阿里云等第三方平台提供的接入服务(价格约为官网 50%),并关注新用户赠送 Token 额度(如 50 万 - 100 万)。
- 监控缓存命中率,通过复用高频请求内容降低单位成本。
技术演进与行业影响
DeepSeek 采用 MoE(Mixture of Experts)架构提升处理效率,通过动态分配 “专家模型” 处理特定任务(如数学计算、文本生成),在降低能耗的同时优化 Token 利用率。此技术升级支撑了近期价格调整(如输出 Token 费用暴涨 300%),反映行业从补贴转向商业化的趋势。开发者需权衡模型性能与成本,选择适合的接入方案。
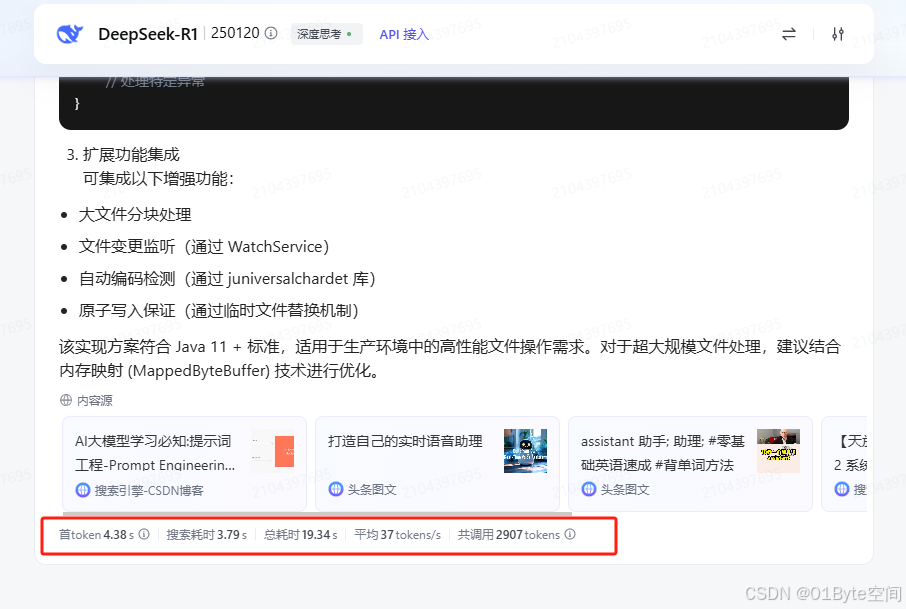
下面是火山引擎提供的满血模型响应速度:
首token4.38s
搜索耗时3.79s
总耗时19.34s
平均37tokens/s
共调用2907tokens

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)