
【DeepSeek-R1背后的技术】系列九:MLA(Multi-Head Latent Attention,多头潜在注意力)
【DeepSeek-R1背后的技术】系列博文:
第1篇:混合专家模型(MoE)
第2篇:大模型知识蒸馏(Knowledge Distillation)
第3篇:强化学习(Reinforcement Learning, RL)
第4篇:本地部署DeepSeek,断网也能畅聊!
第5篇:DeepSeek-R1微调指南
第6篇:思维链(CoT)
第7篇:冷启动
第8篇:位置编码介绍(绝对位置编码、RoPE、ALiBi、YaRN)
第9篇:MLA(Multi-Head Latent Attention,多头潜在注意力)
第10篇:PEFT(参数高效微调——Adapter、Prefix Tuning、LoRA)
第11篇:RAG原理介绍和本地部署(DeepSeek+RAGFlow构建个人知识库)
第12篇:分词算法Tokenizer(WordPiece,Byte-Pair Encoding (BPE),Byte-level BPE(BBPE))
第13篇:归一化方式介绍(BatchNorm, LayerNorm, Instance Norm 和 GroupNorm)
第14篇:MoE源码分析(腾讯Hunyuan大模型介绍)
1 背景
多头潜在注意力(Multi-Head Latent Attention,MLA)是一种改进的注意力机制,旨在提高Transformer模型在处理长序列时的效率和性能。
在传统的Transformer架构中,多头注意力(MHA)机制允许模型同时关注输入的不同部分,每个注意力头都独立地学习输入序列中的不同特征。然而,随着序列长度的增长,键值(Key-Value,KV)缓存的大小也会线性增加,这给模型带来了显著的内存负担。
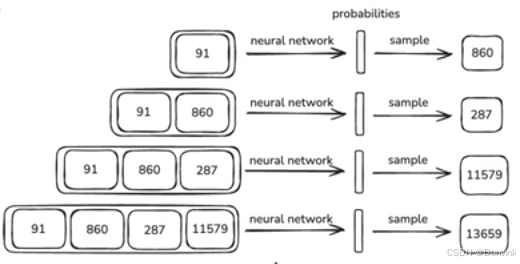
为什么需要KV缓存呢?
因为我们在推理的时候,是将已生成的序列token依次输入解码器中,从而生成下一个预测的token,所以我们需要将已生成的token缓存下来。如下图所示,首先,网络生成了id为91的token,我们把token 91输入网络中,预测出来的是token 860;然后,我们再把token 91和860组成的序列输入网络中,生成token 287;再把token 91、860和287组成的序列输入,生成token 11579;按照这个流程依次操作,直到生成终止符。
为解决MHA在高计算成本和KV缓存方面的局限性,DeepSeek引入了多头潜在注意力(MLA)。多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键值(KV)矩阵,显著减少了内存消耗并提高了推理效率。
-
低秩联合压缩键值:MLA通过低秩联合压缩键值(Key-Value),将它们压缩为一个潜在向量(latent vector),从而大幅减少所需的缓存容量。这种方法不仅减少了缓存的数据量,还降低了计算复杂度。
-
优化键值缓存:在推理阶段,MHA需要缓存独立的键(Key)和值(Value)矩阵,这会增加内存和计算开销。而MLA通过低秩矩阵分解技术,显著减小了存储的KV(Key-Value)的维度,从而降低了内存占用。
MLA通过“潜在向量”来表达信息,避免了传统注意力机制中的高维数据存储问题。利用低秩压缩技术,将多个查询向量对应到一组键值向量,实现KV缓存的有效压缩,使得DeepSeek的KV缓存减少了93.3%。
2 方法
MLA 主要步骤如下:
- 输入映射到潜在空间
给定输入 (其中 n 是序列长度,d 是特征维度),通过映射函数 f 将其投影到潜在空间:
(其中 n 是序列长度,d 是特征维度),通过映射函数 f 将其投影到潜在空间:

f(⋅) 可为全连接层、卷积层等映射模块,潜在维度 k 是显著降低计算复杂度的关键。
- 潜在空间中的多头注意力计算
在潜在空间 Z 上进行多头注意力计算。对于第 i 个注意力头,其计算公式为:
将所有注意力头的输出拼接后再通过线性变换:

- 映射回原始空间
将多头注意力结果从潜在空间映射回原始空间:

g(⋅) 为非线性变换,如全连接层。
整体框架如下图所示:

进一步优化:

3 集中常见的Attention对比

4 示例代码
import torch
import torch.nn as nn
class MultiHeadLatentAttention(nn.Module):
def __init__(self, input_dim, latent_dim, num_heads):
super(MultiHeadLatentAttention, self).__init__()
self.latent_proj = nn.Linear(input_dim, latent_dim) # 映射到潜在空间
self.attention = nn.MultiheadAttention(embed_dim=latent_dim, num_heads=num_heads)
self.output_proj = nn.Linear(latent_dim, input_dim) # 映射回原始空间
def forward(self, x):
# 输入映射到潜在空间
latent = self.latent_proj(x)
# 在潜在空间中计算多头注意力
attn_output, _ = self.attention(latent, latent, latent)
# 映射回原始空间
output = self.output_proj(attn_output)
return output
# 示例输入
batch_size, seq_len, input_dim = 32, 128, 512
x = torch.rand(batch_size, seq_len, input_dim)
mla = MultiHeadLatentAttention(input_dim=512, latent_dim=128, num_heads=8)
output = mla(x)
5 关键优势
- 计算效率:潜在键值数量远少于原始序列,复杂度从 (O(n^2)) 降至 (O(nm))((m \ll n) 为潜在变量数)。
- 长序列处理:适合处理长文本、高分辨率图像或视频数据。
- 全局信息捕捉:潜在键值可学习到数据的全局结构,提升模型泛化能力。
6 应用场景
- 自然语言处理:长文档翻译、文本摘要。
- 计算机视觉:图像生成(如ViT变体)、视频理解。
- 语音处理:长音频序列建模。
7 对比与变体
- 与传统多头注意力:MLA通过潜在空间压缩减少计算量,而非直接处理所有输入元素。
- 与Linformer/Performer:类似低秩近似目标,但实现方式不同(如潜在变量生成 vs 核方法或投影矩阵)。
- 变体扩展:可结合稀疏注意力、层次化结构进一步优化。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)